中文文本分类模型对比研究
2023-02-20陈海红黄凤坡
陈海红,司 威,黄凤坡
(赤峰学院 数学与计算机科学学院,内蒙古 赤峰 024000)
1 引言
文本分类问题是自然语言处理领域的重要研究问题,可以进行主客观分类、舆情情感分析等。文本分类的模型也是比较多的,本文采用7种方法对中文文本进行二分类(正向情感、负向情感)或三分类(正向情感、中性情感、负向情感)研究对比,找到各种方法的优缺点,并将其应用到舆情情感分析等文本分类领域。
2 数据的准备
我们从网络上收集了很多领域的评论数据,以及日常的微博数据,并对数据进行了预处理,去除多余的空格,表情符号,Html标签等。然后对这些数据进行标注,再将数据转换成各种模型能够识别的格式。模型在使用的时候把这些数据分成开发集(development set)和测试集(test set),开发集又分成训练集(training set)和开发测试集(development test set)。本文中使用的开发集样本数是17130条,测试集样本数是4187条,此外,还收集了停用词典,情感词典(分为正向词典和负向词典),程度副词,否定词典等数据。
3 中文文本分类法
3.1 基于情感词典的分类法
基于情感词典的分类法是对人类的记忆和判断思维的最简单模拟,人类会通过学习来记忆一些基本词汇,如否定词有“不”,积极词有“幸福”“骄傲”,消极词有“讨厌”,从而在大脑中形成一个基本的语料库,然后对输入的句子进行拆分,看看记忆的词汇表中是否存在相应的词,然后根据这个词的类别来判断情感。
这里使用了一种比较简单的算法,将词语的权重值划分为四类,分别为P、N、DaP、DaN。P类型的词语权重值为1,包括积极词语、否定词+消极词语;N类型的词语权重值为-1,包括消极词、否定词+积极词语、积极词语+否定词;DaP类型的词语权重为2,包括程度副词+积极词语;DaN类型的词语权重为-2,包括程度副词+消极词语。并假定情感值满足线性叠加原理,最终算出的权重值在(-∞,+∞)范围内,越大说明越积极。为了方便划分类别,将最终的权重值放入sigmoid函数转换成(0,1)之间的数值。上述方法在测试集上进行测试,最终结果的准确率为60%。
该方法存在的问题:(1)假设了所有积极词语、消极词语的权重值都是相等的,但我们知道中文文本本身带有非常丰富的感情色彩,同为积极/消极词语但语气程度可能是不同的;(2)对否定词和程度副词仅做了取反和加倍,但事实上,不同的否定词和程度副词的权重程度也是不同的;(3)假设了权重值是线性叠加的,但事实上,人脑情感分类是非线性的,不仅仅在想这个句子是什么情感,还会判断句子的类型,整体的结构(主语、谓语、宾语等),甚至还会联系上下文对句子进行判断,基于简单的线性叠加性能是有限的;(4)情感词典没有自动扩充能力,人类获得新知识的手段不仅仅靠他人的传授,还会自己进行学习、总结和猜测,如“喜欢”和“热爱”是积极词语,那么人类就会知道“喜爱”也是积极的词语。
3.2 snowNLP库
SnowNLP是一个python写的类库,可以方便地处理中文文本内容,是受到了TextBlob的启发而写的,它囊括了中文分词、词性标注、情感分析、文本分类、转换拼音、繁体转简体、关键字/摘要提取、文本相似度等诸多功能,像隐马尔科夫模型、朴素贝叶斯、TextRank等算法均在这个库中有对应的应用。SnowNLP对情感的测试值为0到1,值越大,说明情感倾向越积极。
使用SnowNLP对数据进行测试,测试数据有4187条,测试结果以0.5为界,大于0.5的判定为正向,小于0.5的判定为负向,最终的准确率为73%。如果大于0.8判定为正向,小于0.3判定为负向,中间为中性,最终的准确率为67%。
SnowNLP的分词效果没有结巴分词效果好,而且原料是基于几个方向的评论留言,语料文件比较片面,且其中有些语句意向不准确,导致效果并不是特别好,但如果没有其他知识的情况下做中文文本处理,使用SnowNLP是一个不错的选择。
3.3 逻辑回归
逻辑回归是一个非常经典的分类算法,目前仍被广泛应用到各个领域,Bahalul Haque等人利用逻辑回归,根据年龄、性别、国家和地区预测COVID-19导致的个人死亡[1]。
我们首先对文本进行特征提取,提取方法采用TF-IDF(Term Frequency-Inverse Document Frequency),计算公式为:
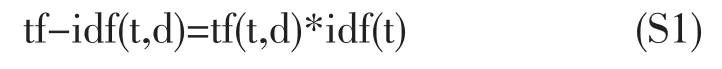
S1是tf值与idf值的乘积,tf(t,d)表示某一篇文档d中,词项t的频度。
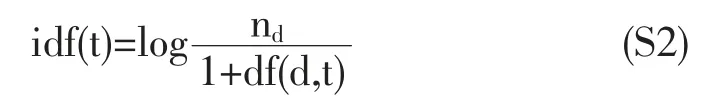
nd表示训练集文本数,df(d,t)表示包含词项t的文档总数。用S1和S2对训练集和测试集文本进行特征提取,在训练集上得到的特征矩阵维度是(17130,41000),这是一个非常庞大的稀疏矩阵。然后使用sklearn中的LogisticRegression[2]对该矩阵数据进行逻辑回归训练,训练参数选择newton-cg作为优化算法,选择1.0作为惩罚系数。训练好的模型应用到测试集上进行测试,测试结果的logloss:0.527,准确率83%。
文本的特征提取是自然语言处理领域的最重要问题,它决定着最终结果的上限。目前word2vec是一种应用较广泛的特征提取方法,它产生了很多变体,应用于很多方面[3,4]。这里我们使用word2vec对文本再次进行特征提取。使用TF-IDF进行特征提取时,它能过滤掉一些常见的却无关紧要的词语,同时保留影响整个文本的重要词语,但丢失了文本上下文之间的联系。使用word2vec进行特征提取时,它会考虑上下文,并且维度更少。首先使用gensim库中的word2vec[5]对1.3G的中文语料进行建模,生成维度为400的词向量,使用该词向量对[‘微积分’,‘统计学’,‘苹果’]进行heatmap分析,发现微积分与统计学具有很多的相似性,与苹果相差很多。

图1 热图分析数值
然后将一个句子中所有词的词向量相加取平均,得到句子向量,再将句子向量输入到上述逻辑回归模型进行训练,并测试。测试结果的logloss:0.617,准确率76%,发现并没有得到比TF-IDF更好的结果。后面第3.4节也使用这个word2vec训练的词向量,得到了不错的结果。
3.4 简单的全连接网络和LSTM模型
深度学习可以帮助我们从多角度提取文本特征,文本的分类问题同样可以使用深度学习模型进行处理。我们先使用keras[6,7]中的Sequential搭建一个简单的3层全连接网络查看效果。在搭建神经网络之前,先在word2vec训练的词向量的基础上对特征数据进行标准化/归一化处理,因为如果某个特征的方差远大于其他特征的方差,那么它将会在算法学习中占据主导位置,导致模型不能像我们期望的那样,去学习其他的特征,这将导致最后的模型收敛速度慢甚至不收敛。
model=Sequential()
model.add(Dense(256,input_dim=400,activation=” relu” ))
model.add(Dense(256,activation=” relu” ))
model.add(Dense(3))
model.add(Activation(” softmax” ))
模型中间加Dropout[8]和BatchNormalization()来防止过拟合,优化器选择adam,损失函数选择categorical_crossentropy,测试结果的logloss:0.453,准确率82%。
CNN(Convolutional Neural Network)和RNN(Recurrent Neural Network)都会将矩阵形式的输入编码为较低维度的向量,而保留大多数有用的信息,但卷积神经网络更注重全局的模糊感知,循环神经网络更注重邻近位置的重构,而自然语言是具有时间序列特征的数据,每个词的出现都依赖于它的前一个词和后一个词。由于这种依赖的存在,我们使用循环神经网络来处理这种时间序列数据更适合。Long Short Term Memory Units(LSTMs)是一种特殊的循环神经网络,从抽象的角度看,LSTM保存了文本中长期的依赖信息。
在使用LSTM建模之前,先测定训练集和测试集中的句子长度,测试结果如图2所示,根据图中的结果,又计算了句子长度小于150的句子总数占61%,句子长度小于210的句子总数占93%,因此选择句子长度为210,在训练的过程中,加入了回调函数,使得模型能够停止在最佳的迭代节点,最终结果如图3所示,在epoch=25时达到了最佳节点。最终测试结果的logloss:0.32,准确率86%。
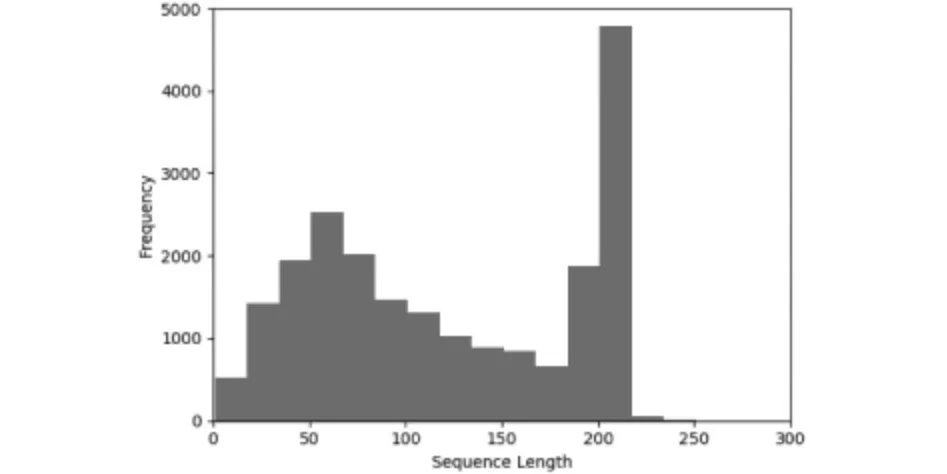
图2 不同句子长度的数量分布
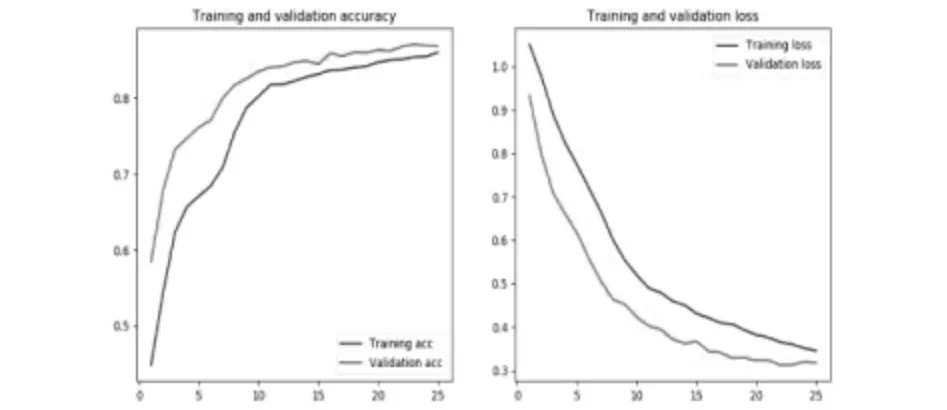
图3 句子长度为210时的acc和loss
3.5 BERT模型
BERT(Bidirectional Encoder Representations from Transformers)模型来源于论文[9],它的网络架构使用的是《Attention is all you need》中提出的多层Transformer结构,它解决了传统模型的一些问题:(1)解决了RNN模型本身的序列依赖结构不适合大规模并行计算的问题;(2)词向量训练模型word2vec在预训练好词向量后就永久不变了,但不同语境中相同的词可能代表不同的含义。BERT词向量包含了双向的语境信息,在很多方面具有比较好的效果,也出现了很多针对它的改进模型。
主要的思路:将一句话进行分词,通过BERT模型之后输出各个分词对应的词向量及CLS对应的词向量,CLS中包含了整句话的信息,然后通过CLS进行类别的判断。最终测试结果的logloss:0.31,准确率88%。
4 结果
F1和精确匹配(Exact Match,EM)是模型性能评价的两个指标。如果预测值与真实值完全相同,则EM值为1,否则为0;F1则是平衡精确率和召回率之间关系的指标,值越大越好。几种方法的EM和F1值如表1所示。测试集数据是一个三分类的数据,标记为1的代表正向情感,标记为2的代表负向情感,标记为0的代表中性情感,个数见表1所示。基于情感词典的思路简单,稳定性强,但精确度不高,需要提取好情感词典,而这一步,往往需要大量的工作才能保证准确率,而且必须要对中文语义足够了解才可以做到。测试时将结果值大于0.8的分类为正向情感,小于0.3的分类为负向情感,其余的分类为中性情感,结果的F1值为49%。SnowNLP的测试结果也是数值,和情感字典一样做三分类划分,F1值是51%。

表1 测试集样本个数
机器学习允许我们在几乎零背景的前提下,为某个领域的实际问题建立模型。在机器学习模型中,BERT模型达到了最高的准确率和最低的loss,表2的BERT模型结果是在learning_rate=2e-5,num_train_epochs=1.0,vocab_size=21128(词表大小)的条件下获得的。使用机器学习模型需要我们对相关框架、算法、知识点足够的了解,如果没有相关方面的知识又想做中文文本分类的话可以使用SnowNLP库。根据表2的结果基于TF-IDF的逻辑回归取得了不错的效果,基于word2vec的逻辑回归使用了平均词向量方法获得句子向量,这种方法的缺点是认为句子中的所有词对于表达句子含义同样重要。因此如果是简单的任务,使用基于TFIDF的逻辑回归将会是不错的选择,总体来讲深度学习的方法精确度更高。
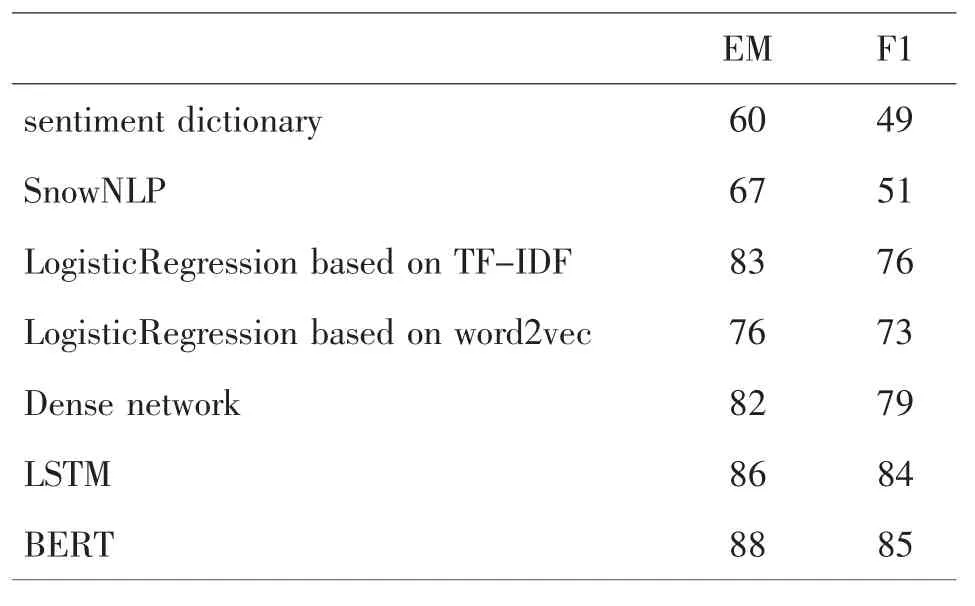
表2 结果对比
5 总结
本文使用基于情感词典的分类方法,SnowNLP库,逻辑回归,全连接神经网络,LSTM,BERT模型等多种方法对相同的文本进行分类研究。我们发现预训练模型虽然在很多时候能取得不错的结果,但需要忍受更大的模型尺寸及更高的延迟,因此在解决具体任务时,传统的普通方法也许能取得不错的结果,而且没有更大的开销。
