基于特征融合的正常语音和低语语音分类系统
2023-02-19艾斯卡尔艾木都拉
王 睿,艾斯卡尔·艾木都拉
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830017;2.新疆大学 多语种信息处理实验室,新疆 乌鲁木齐 830017)
0 引 言
低语是一种很常见的发音方式,在公共场合为避免信息泄漏或者打扰到周围的人,人们常常会使用低语进行交流。20世纪50年代展已开对低语的研究,从对低语的发音方式、特征表现、与正常语音之间特征差异的研究,到低语语音识别、低语转换成正常语音、低语说话人识别/判别、低语端点检测、生成伪低语等方向的研究。
低语研究是语音研究中的一个热门方向[1-2],但关于低语与正常语音分类系统的研究比较少。A.H.Poorjam等人提出了一种基于在噪声信号的Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)上培训的回归模型,该方法在不同噪声条件下为各种语音类型提供了准确的估计和一致的相似性[3];Z.Raeesy等人使用长短期记忆网络模型(Long Short-Term Memory,LSTM),从对数滤波器组能量(Log-Filterbank Energy,LFBE)学习低语特性,并进行低语语音检测,得到不错的效果[4]。
虽然分类器的研究较少,但是低语与正常语音的分类器是有必要的,分类器可以用于前期准备数据部分,因为低语的发音方式比较特别,有些人在录制低语数据时可能无法保证全程保持低语状态,导致该条语音录制无效,如果是准备建立一个低语语料库,可以先使用分类器将录制的语音进行初步筛选,减轻人工负担;或者是用在识别系统,当有两个识别系统——低语和正常语音的识别系统,可将该分类器放在前端用于区分低语和正常语音,非常适合应用在日常生活语音助手当中,判别用户的使用状态,提高用户使用语音助手的使用感和幸福感。由于目前低语语料库包含语音数较少,有些模型需要大量的语料,于是有些学者提出使用伪低语语音[5-6]。伪低语可以从正常语音转换也可以合成,这时分类模型可以当作伪低语生成的评判标准之一,检验伪低语语音生成的合格度以及准确度。
本文将探讨基于深度学习网络的低语与正常语音分类方法,首先创建一个有低语与正常语音的语料库,为后期实验打下坚实基础;其次,分析找出来3个在低语和正常语音上表现出明显差异的特征;最后通过分析提出使用特征融合的方式,在卷积神经网络(Convolutional Neural Networks,CNN)基础上搭建一个分类系统。
1 数据库创建
1.1 数据准备
语音的数据库是整个语音识别研究的基础和对象,一个优秀的语音数据库需要从多方面进行规范设计[7-8],例如发音规范、数据采集环境规范、音段长短规范、声学及语音学特征平衡规范等。由于汉语低语语音的研究比较少,并没有优秀的中文低语语音库作为参考,为了保证研究的顺利进行,本文自行建立了一个包含低语和正常语音的汉语语料库。根据现实需求,该语料库中的语音语料都是8位数字串,数字串是11位数字随机打乱组合而成,数字包括:1,2,3,4,5,6,7,8,9,!(中文中特有的口音1读作yao)。
语料库通过实习公司所制作的专业录音软件录制,数据均为所实习公司所有,该软件安装在公司员工的个人手机上,方便员工录制。数据录制为16 kHz,8 bit,WAV格式存储。
录制语音前,制定了录制标准,有以下几点:
1)确保在安静的环境下录制语音;
2)录制时要确保数字串的完整性,先点击录制按钮,再开始读语音,8位数字读完之后,再松开按钮;
3)录制低语时,要在录制全程保持低语状态,控制声带不要振动。
在确定好录制标准后,收集公司员工资料,确定录制人员,录制人年龄控制在20~50岁之间,并且要求口齿清晰,普通话标准,能够准确地发出低语语音,确保录制的数据较为完整,避免浪费资源。
1.2 数据库制作
所有的录音结束后,收集整合所有数据,并采取人工筛选语音的方式来确保音频的质量。筛选前统计每人录制总体语音条数和参与录制的人员。由于中途有人请假或者忘记录制数据的情况,所以每个人的数据数量是不同的,先将数据录制过少的人筛除,然后通过人工听语音筛除录制不规范的语音。筛除语音的标准和录制标准一样,数字串是完整的,背景没有噪声,低语录制过程全程保持低语状态。筛选的目的是确保低语数据库中只包含低语且在一条语音中只包含同一种发音方式,从而确保数据的准确性。
参与的人数和录制的语音条数如表1所示。
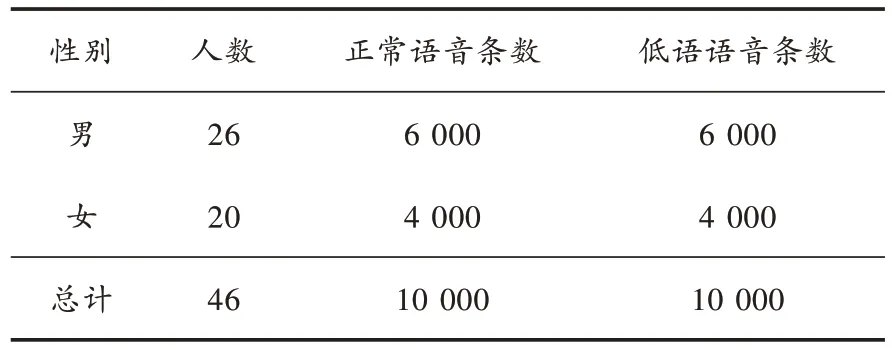
表1 语料库包含人数及语音条数
将正常语音和低语语音分为训练集7 500条语音、测试集1 500条语音和验证集1 500条语音(测试集、训练集、验证集包含相同的说话人),数据的标签没有单独放进CSV文件中,而是以上级文件名作为标签,数据存储结构如图1所示。
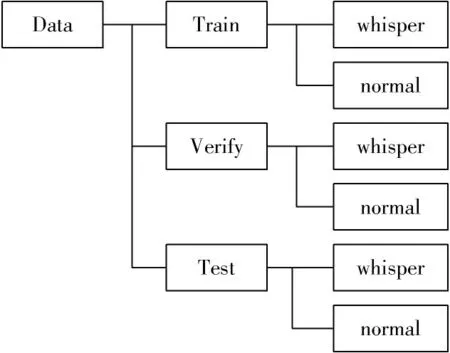
图1 数据存储结构
2 声学特征
在本节中,介绍所用到的声学特征。低语和正常语音发音方式不同,正常说话时,气流正常通过发音腔引起声带振动;而低语发音时声带紧闭气流通过狭小缝隙发出,声带并不振动,而且气流发出时通过发音腔比较困难,这使得发出低语时,发音会变得缓慢。低语和正常语音特征差异明显,于是本次实验选择以下了三种特征:
1)频谱图[9]。频谱图是一种直观的方式,表示信号在特定波形中出现的各种频率随时间变化的信号强度或“响度”。从图2频谱图中不仅可以看到在例如2 Hz与10 Hz时能量是多还是少,而且还可以看到能量水平如何随时间变化。低频部分低语和正常语音差异较大,这是因为低语发音时声带不振动,不能引起共鸣,而没有基频和谐波。频谱可以通过计算能量谱密度或者是功率谱密度(Power Spectral Density,PSD)得到。
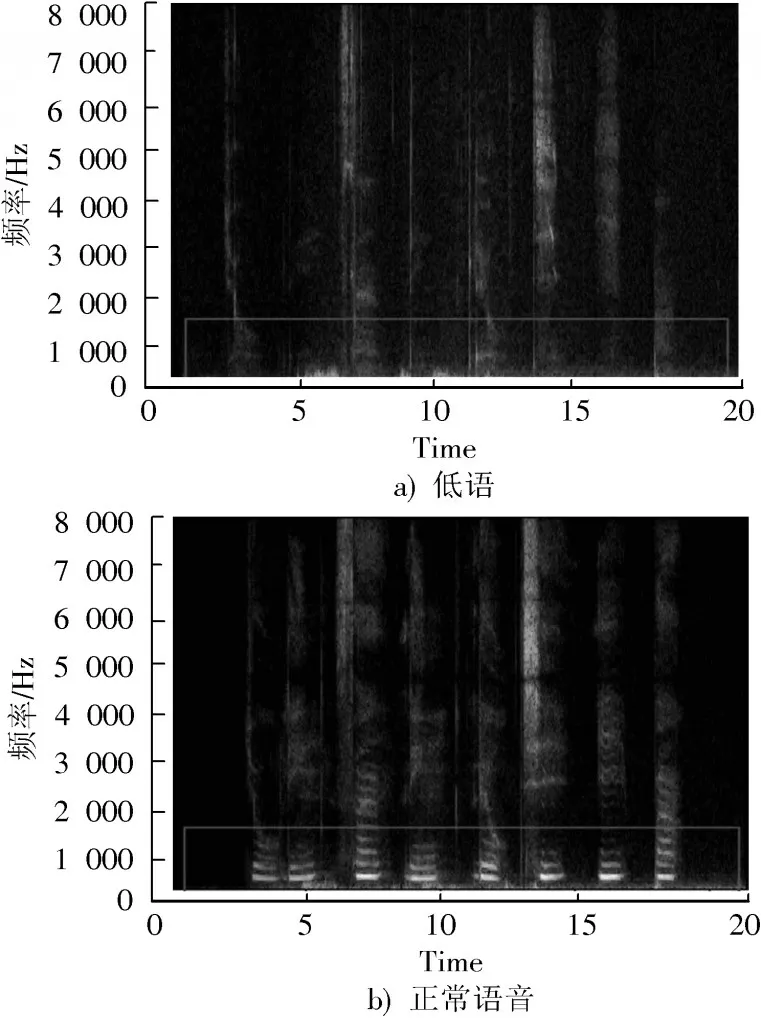
图2 数字串90306718的频谱图
2)频谱平坦度[10]。频谱平坦度也叫作维纳熵,即各个频率分量的几何平均数与算术平均数的比值,计算公式如下:
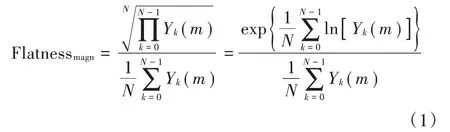
如果各分量的值相当,那么等式比值接近于1,这时认为输入语音是白噪声;如果各分量差异比较大的话,那么等式的比值接近0,一般认为有语音产生。频谱平坦度如果接近1.0表明光谱类似于白噪声,这个特征可以比较明显地区分低语和正常语音。正常语音各分量差异较大,而低语的各分量差异较小,所以选取频谱平坦度作为输入特征。
3)均方根。文献[11]中提出利用RMS分割的语音片段,因为中高均方根段的语音携带有更多的元音信息,而正常语音和低语最大的区别就在于元音发音方式上。一段声音信号的均方根就是声压有效值,声压是指平时所说的声音有多少分贝,低于某一压值,人耳就再也不能觉察出这个声音的存在了。人耳在听低语时,需要发出低语的人靠近人耳尽力地说才能够听得到,所以低语分贝低于正常语音。从图3低语与正常语音的RMS可视化图中可以看出,低语RMS曲线较为陡峭且短暂,正常语音比较平缓且持续时间长。
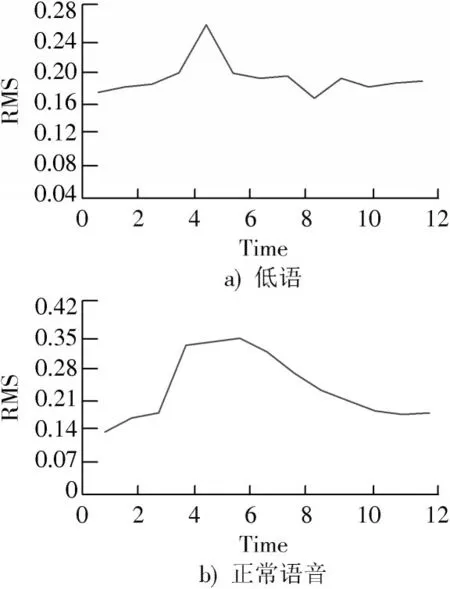
图3 数字6的RMS可视化图
3 实验设置
3.1 模型架构设计
卷积神经网络(Convolutional Neural Networks,CNN)与普通神经网络非常相似,都由具有可学习的权重和偏置常量(Biases)的神经元组成。选择CNN[12-13]是因为CNN在语音情感分类中表现出来良好的效果,而低语与正常语音分类、情感分类有些类似,都是借助语音的某些声学特征学习到特征中的差异,从而进行分类。于是根据CNN的特性构建了分类器模型,模型主要框架如图4所示。该模型包含两个卷积层,卷积层之后有Flatten层,它是从卷积层到全连接层的过渡。卷积层上的过滤器数量为32,每层使用的内核大小为16。激活函数使用softmax。
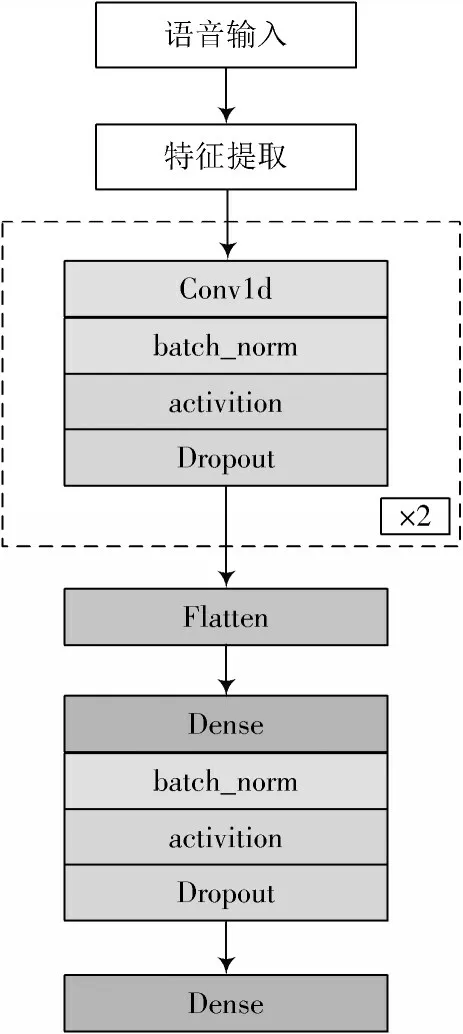
图4 模型总体框架
3.2 评价指标
结果用Accuracy来评价[14-15]。Accuracy指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例,评价公式如下:
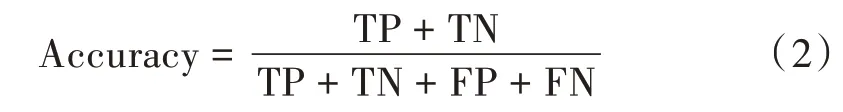
式中:True Positive(TP)表示预测为正例,实际为正例;False Positive(FP)表示预测为正例,实际为负例;True Negative(TN)表示预测为负例,实际为负例;False Negative(FN)表示预测为负例,实际为正例。简单来说就是TP和TN都是预测正确,FP和FN都是预测错误。
4 实验结果与分析
为了验证本文所提出的特征融合方法在正常语音和低语分类的有效性,选择将人眼直观看到的低语与正常语音差异最明显的特征—频谱图的数值当作输入特征,作为本次实验的基线实验。实验所用到的特征通过librosa提取,实验epoch设置为30个,学习率设置为0.005,batch_size设置为16。实验首先分别将3个特征Spectral Flatness、RMS、频谱图当作分类器的特征输入,接着将频谱图和Spectral Flatness特征融合、RMS和Spectral Flatness特征融合分别当作分类器的输入,将5种实验结果进行对比,结果如表2所示。
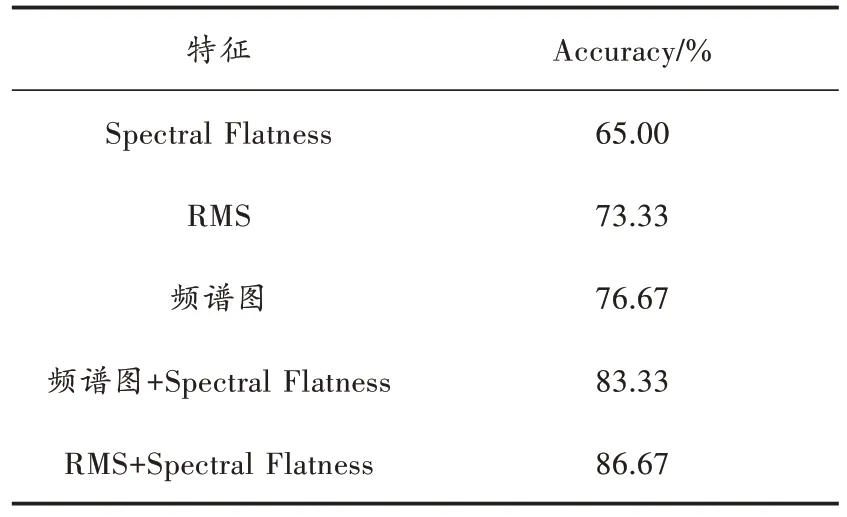
表2 实验结果
由表2可以看到,单独使用频谱图特征,分类效果是76.67%,但将RMS和Spectral Flatness结和起来分类效果可以达到86.67%。表明将RMS特征和Spectral Flatness融合的特征得到的结果要比仅使用频谱图特征效果好。RMS计算的是声音的分贝值,Spectral Flatness计算的是当前帧语音噪声概率,两者都能够比较好地体现出低语与正常语音之间的差异,所以将两者结合效果要比其他特征好。
图5、图6分别为训练集和测试集数据集在epoch上的交叉熵损失和分类精度曲线,展示了30个epoch的训练和验证过程。val_loss开始减少,val_acc开始增加。在这种情况下,绘图显示模型似乎已经收敛。交叉熵损失和准确度的线图都显示出良好的收敛行为。该模型配置良好,没有过拟合或欠拟合的迹象,这意味着构建的模型可以正常学习到特征信息。观察图5、图6发现24个epoch时,模型收敛较好,于是测试epoch数量对分类效果的影响,结果如表3所示。
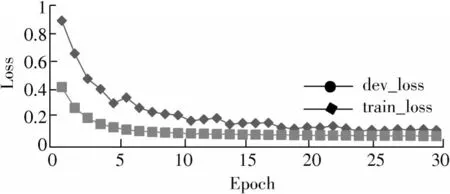
图5 模型的损失过程
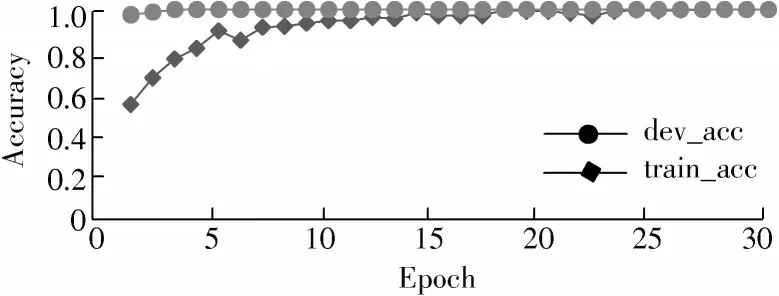
图6 模型的准确度过程
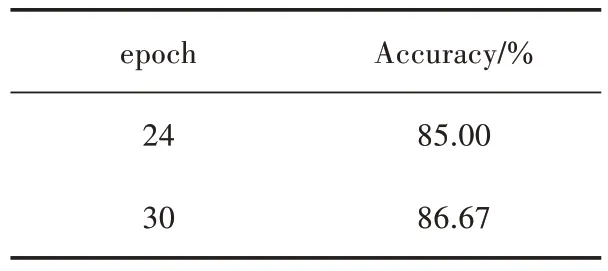
表3 epoch对训练结果的影响
从表3中可以看出30个epoch时,模型分类效果最佳,相较于24个epoch,30个epoch时效果要高1.67%。
5 结 论
本文借助CNN,将特征RMS和Flatness融合当作新特征的方式来区分低语和正常语音。实验结果表明,将两个在低语与正常语音中表现出明显差异的特征进行融合,当作分类系统的新特征,对区分低语和正常语音有一定的帮助。在未来的工作中,将把重点放在利用二维频谱图特征来区分低语和正常语音。频谱图中,在低频部分因为低语和正常语音差异较大,低语没有基频和谐波共振,如果只截取频谱图低频部分当作分类系统特征,应该会提高分类效果,在未来实验中可以进行验证。
