基于GA-BP神经网络的搜索引擎数据资产价值研究
2023-02-19党雪宁李明
党雪宁 李明,2
(1.广西科技大学经济与管理学院 广西柳州 545000;2.广西科技大学广西工业高质量发展研究中心 广西柳州 545000)
1 数据资产评估研究的背景及意义
近年来,互联网产业迅猛发展,数据资源比重不断提高,同时数据挖掘、数据分析技术的发展加快了数据资源价值的评估,从而能够最大程度地发挥数据资产的效用。数据资产评估研究存在数据资源庞大难以有效利用、数据资产不能合理评估造成互联网行业发展缓慢、数据资产本身特性造成评估困难等问题。因此,我们需要观察行业发展现状,充分考虑衡量数据资产价值的因素,构建适用于数据资产价值的评估模型,从而提高数据资产价值评估的精确性。
2 数据资产评估研究的理论基础
2.1 数据资产相关理论
孟小峰、慈祥(2013)[1]提出大数据具有规模大、多样性、高速性的特点;张兴旺等(2019)[2]认为数据资源经过加工处理实现价值增值后形成数据资产。具体特征包括:控制、可变现、可计量、可估值、可流通。基于此,将数据资产的特征归纳为非实体性、类型多样性、可变性、权属不清晰等四个方面。对不同行业来说,影响数据资产价值的因素也不同;黄萃(2014)[3]提出不同的定价策略及定价方法的选择会受到获取公共信息的目的、价值估算、成本及融资、市场竞争状况及社会信息公平等五个因素的影响;吴江(2015)在探讨数据交易时,数据产权、数据的有用性数据交易成本、交易机制等会对数据资产价值造成影响。通过总结不同学者的观点,本文认为数据资产与质量、稀缺性、效用等息息相关。
2.2 GA-BP神经网络模型理论
BP神经网络由三部分构成,分别是输入层、隐藏层、输出层。神经网络的每一层由若干个神经元组成,神经元作为BP神经网络的感知器,经过激活函数的处理完成传播过程。BP神经网络由输入、权重、偏置、激活函数、输出等组成。BP神经网络包含正向传播和反向反馈。BP神经网络的正向传播通过激活函数来实现,将训练样本作为输入层,与权重计算加上偏置,经过激活函数的处理,得到的输出结果作为下一次节点的输入,将输出结果与期望值进行比较,结果达不到期望值,不断调整迭代得到满意的结果,将最终的结果进行测试,并应用于适用领域。
遗传算法优化BP神经网络分为BP神经网络结构确定、遗传算法优化和BP神经网络预测3个部分。其中,BP神经网络的结构确定部分根据拟合函数的输入输出参数个数确定BP神经网络结构,进而确定遗传算法个体的长度。遗传算法优化BP神经网络的权值和阈值,种群中的每个个体都包含一个网络所有的权值和阈值,每个个体通过适应度函数计算适应度值,遗传算法通过选择、交叉、变异操作找到最优的适应度值对应的个体。
3 数据资产评估研究案例分析
3.1 百度搜索引擎发展概况
百度公司于2000年1月1日由李彦宏携“超链分析”搜索引擎专利技术在中关村科技园创建,这一技术专利使百度成为国内高科技企业,掌握了世界尖端科学核心技术,也使中国跻身于全球包括美国、俄罗斯、韩国在内仅有的4个具有搜索引擎核心技术的国家之列。百度互联网服务用户达10亿,每天响应数十亿次搜索请求,已成为100余个国家和地区上网民众接收中文信息和服务的重要途径。
3.2 百度搜索引擎价值影响因素的探索
百度搜索引擎价值受网站内在技术、用户角度等多方面影响,通过搜索引擎统计网站,我们尽可能较多的搜集影响搜索引擎数据资产价值的因素,从网站了解到用户因素占了较大的部分,因此本文主要从用户角度出发对搜索引擎价值进行预测,以流量指标作为评价标准,选取浏览量、访客数、IP数、跳出率、平均访问时长、转换次数6个指标作为百度搜索引擎数据资产的价值影响因素。
3.3 百度搜索引擎数据来源及处理
本文将百度搜索引擎包括浏览量、访客数、IP数、跳出率、平均访问时长、转换次数6个指标作为百度搜索引擎数据资产的价值影响因素,将6个指标数值归一化处理作为神经网络输入层。搜集了百度搜索引擎一个月的股票单价,根据股票单价和股数计算预测值,将预测值作为神经网络输出层的训练样本,价值预测计算表达式如下:

其中:
V:百度搜索引擎市场价值;
C:百度搜索引擎价值预测当日股数;
Smax:百度日最高股价;
Smin:百度日最低股价;
T:美元与人民币换算汇率。
本文从百度统计网站统计了百度搜索引擎相关指标样本值,选取2021年10月—11月共计32天的数据,确定了3216个自变量样本数据和32个因变量数据值进行后续的处理。
3.4 神经网络结构设置
3.4.1 传递函数
神经网络的传递函数一般选purelin、tansig、logsig三种传递函数,将其组合成9种不同形式,经过程序处理得到相对应的均方误差,均方误差越小,BP神经网络学习的效果最优,因此选择均方误差最小的tansig、purelin的组合作为神经网络的传递函数。
3.4.2 神经网络层数
神经网络隐藏层个数决定了其结构的复杂程度,本文选择一个相同的网络结构,训练迭代50次,比较网络运行时间和结果精度,通过预测结果得出在误差百分比相近的情况下,双层网络结构均方误差和训练时间最为合适。
3.4.3 各层神经元节点数
本文选取了浏览量、访客数、IP数、跳出率、平均访问时长、转换次数6个指标作为神经网络输入层,即输入层神经元节点数为6。被解释变量为百度输出层节点数为1,表示百度搜索引擎数据资产的市值。神经元隐藏层节点的多少决定了神经网络模型拟合的效果,因此确定合适的隐藏层节点数至关重要。最优的隐藏层节点数确定方式公式如下:
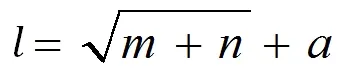
其中:
l:隐藏层节点数;
m:输出单元神经元数;
n:输入单元神经元数;
a:0~10的调节常数;
本文经过查阅相关文献及测试,将第一层隐藏层神经元个数设置为10,第二层神经元个数设置为1。
3.4.4 学习率
本文将学习率初始值确定为0.001,在神经网络学习过程中,用梯度下降法不断调整,直至收敛达到局部最优,得到最终的学习率。
3.5 GA-BP神经网络研究过程
3.5.1 声明全局变量
(1)确定训练集输入数据p和训练集输出数据t
训练集输入数据选取样本数据中前29组数据,即确定一个629的矩阵p。训练集输出数据也就是预测的百度搜索引擎的市值,确定一个129的矩阵t。
(2)输入层、隐藏层、输出层神经元的个数
输入神经元个数R=6,隐藏层神经元个数S1=10,输出神经元个数S2=1。
(3)编码长度

3.5.2 数据归一化
根据归一化数学原理,在Matlab R2018a中运用premnmx()函数进行初始数值的归一化。表达如下:
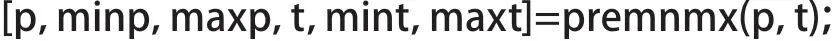
其中:

3.5.3 确定种群个数并初始化种群
设定种群个数popu=50,初始化种群借用功能函数确定过程如下:

通过运行上述程序,得到最优的权值和阈值如下:


3.5.8 计算隐藏层和输出层的输出
用A1表示隐藏层的输出,A2表示输出层的输出
隐藏层tansig函数表达式为:

输出层purelin函数表达式为:
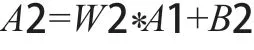
将上述计算的具体数值带入求解,即可得到输出层的输出值。
上述计算在Matlab中表示为:

运行后得出:A1为由1和-1组成的1029的矩阵,A2为129的矩阵。
3.5.9 计算误差平方和
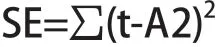
在Matlab中表示为:

运行得误差平方和SE=5.7460*106。
3.5.10 计算适应度值

在matlab中运行得val=1.7403*10-7,适应度值越小,说明寻出来的结果越好,因此用遗传算法优化神经网络评估出来的值是可信的。
4 研究成果分析
4.1 训练结果汇总
在Matlab中用postmnmx()函数将输出的数据反归一化得到预测数据,同时输出测试数据作为真实值,表示如下:

得出的预测值和真实值汇总如表1所示。

表1 预测值和真实值对比
通过表1中预测值和真实值的比较,计算的误差百分比大部分在5%以内,说明GA-BP神经网络模型拟合效果良好,预测的结果可信,因此用该模型预测的结果作为百度搜索引擎数据资产的价值是可行的。
4.2 训练结果分析
根据设置的参数,在软件MATLABR2018a中进行模型的构建和训练,得出遗传算法优化神经网络的预测值与实际值效果如图1所示。
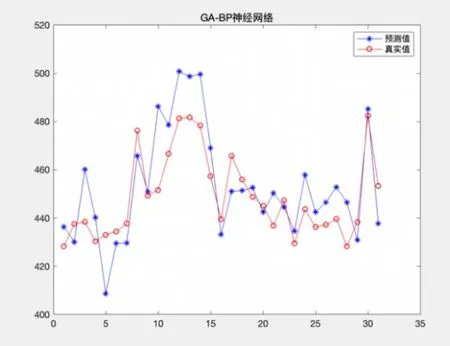
图1 GA-BP神经网络数据拟合图
图1反映两种模型预测结果的大体走势,本文给出了GA-BP神经网络模型评估百度搜索引擎31组数据资产价值的预测值和真实值,因百度公司目前市场份额及财务状况较为稳定,可将31组数据的平均值作为最终确定的搜索引擎数据资产预测的价值,最终计算确定的百度搜索引擎数据资产的价值为452.6万元。通过计算我们可以看出最终确定的预测值与真实值的平均值差值较小,说明模型训练的预测值和真实值的曲线图的拟合效果较好,得出的结论真实可靠,具有较大的参考性。
