NLP和推理引擎下电力基建现场风险区段识别
2023-02-18钱朝军
钱朝军,李 俊,宗 震,张 龙,邬 桐
(1.国网安徽省电力有限公司建设分公司,安徽 合肥 230071; 2.东北大学 信息科学与工程学院,辽宁 沈阳 110819; 3.国网辽宁省电力有限公司经济技术研究院,辽宁 沈阳 110015)
0 引言
当前我国电力建设的主力机型发展方向与输变电分别以高参数、大容量与超/特高压、交直流、长距离为发展方向[1],电力基建现场不同新工艺与新设备被普遍应用。但电力基建现场施工是一个多工种、多层次的交叉作业,临时设备品类较多,存在较多不安全因素,极易产生机械伤害、坍塌以及触电伤害,因此研究一种有效的电力基建现场风险区段识别方法具有重要意义。
2020年,夏宇等[2]最先通过推理链路质量指示(Link Quality Indicator,LQI)和收包率(Packet Reception Rate,PRR)的理论关系,建立更具实际物理意义的双曲正切模型,并提出一种链路质量估计方法。通过指数加权卡尔曼滤波获得更为稳定的LQI估计值,再利用双曲正切模型对链路质量进行定量估计。Akulenko等[3]首次提出了通过自由杆的最低频率来识别缺陷的方法,基于将横截面缺陷建模为已知函数,将近似确定表征其特征的主要参数,通过数值模拟确定振荡模式的特征。
自然语言处理(Natural Language Processing,NLP)技术包含语言学、数学与计算机科学[4],是人工智能与计算机科学领域的主要研究内容,可实现计算机与人之间的自然语言沟通。推理引擎亦可称为推理机,具有推理功能,其优势主要体现在易于理解、易于获取和易于管理[5]。基于此,将NLP技术与推理引擎应用于电力基建现场风险区段识别问题中,提出基于NLP和推理引擎的电力基建现场风险区段识别方法,并对识别过程进行仿真,验证所提方法性能。
1 电力基建现场风险区段识别方法
1.1 电力基建现场描述识别
NLP作为计算机科学以及人工智能领域的主要研究方向,主要应用于计算机同人类之间的高效沟通。NLP技术中包含数种统计方法[6],并以此为基础生成最大熵模型、隐马尔可夫模型、概率上下文无关语法模型、贝叶斯模型以及最小边界距离模型等。基于不同模型在实际应用过程中的主要方向与性能优势,在识别电力基建现场风险描述过程中选用隐马尔可夫模型。
隐马尔可夫模型的主要功能是体现存在隐含位置参数的马尔可夫过程,其在本质上可理解为是一种与时序相关的概率模型[7]。隐马尔可夫模型的状态无法直接获取,但可通过观测向量序列获取,经由概率密度可表现出不同观测向量的不同表现状态,不同观测向量的产生均以相应概率密度分布的状态序列为基础[8]。
隐马尔可夫模型可通过五元组〈D,Y,A,B,π〉表示,其中:
① 状态集合D包含4种状态[9]:词头、词中、词尾和单字成词,这4种状态分别标记为F,M,E,W。
② 观察序列Y表示真实存在的一个状态的有向序列,可通过状态y1,y2,…,yn表示,观测状态具有顺序特性。
③ 状态转移分布A表示状态集合内不同元素间转移的概率值。若当前状态和下一相邻状态分别为f3和f8,则可通过f3,8表示转移概率。
④ 不同状态产生的概率分布可通过B表示。
⑤ 初始状态分布可通过π表示。
根据机器学习方法的差异性,选取监督学习方法确定参数A,B,π。
设定电力基建现场报告训练数据集内包含观测序列和对应的路径序列[10]。
设定初始参数值π,其表达式为:
π=π(m)=P(m1=q1) ,
(1)
式中,m=1,2,…,N,表示t=1时刻下观测值的状态概率;qm=F,M,E,W。
基于统计分析理论,统计电力基建现场报告中不同句子开头第一个字出现的频率,根据第一个字出现的频率统计结果与报告内句子总数的比值确定此字的初始状态F与W的概率情况[11]。
用a(i→j)表示学习状态转移矩阵A的子元素,其值可通过下式确定:
(2)
式中,c表示状态qi转变为状态qj的次数;cz表示状态变化的总次数。在上述过程中仅考虑元素的状态改变,忽略观测值改变。
若以bj(k)表示观测概率分布B的子元素,则为:
(3)
式中,jk和cq分别表示j状态下观测为k的次数和全部状态的总次数。
整体来说,监督学习过程即以频数统计与总数间的比值为基础[12-14],获取对应的概率,以此确定模型参数。利用确定参数后的隐马尔可夫模型实现电力基建现场报告内容分词。
1.2 词频统计
在电力基建现场报告内容分词基础上,采用词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法完成电力基建现场报告内容词频统计。TF-IDF算法通过计算TF与IDF间的乘积,确定语料集内一个字或词的关键度。
(4)
式中,l和L分别表示存在于电力基建现场报告i内的特征项次数和电力基建现场报告i内的总词语数量。
(5)
式中,N和n分别表示电力基建现场报告数量和包含某特征项的报告总数量。
基于式(4)和式(5)确定特征提取函数:
F(w)=TF(w)·IDF(w) 。
(6)
对TF-IDF算法表达式进行归一化处理得到特征项的权重Wij:
(7)
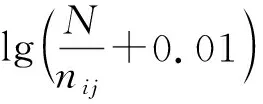
1.3 基于推理引擎的电力基建现场风险区段识别
基于推理引擎的电力基建现场风险区段识别,即以电力基建现场报告内容中的特征项为基础,利用推理引擎模拟思考推理过程,识别电力基建现场风险区段。电力基建现场风险区段识别的本质即对比[15-16],对比的方式可分为对比不同来源的风险报告相互印证和对比当前风险报告与先验知识。先验知识所描述的是原已贮存的知识或经验。
大量电力基建现场风险事例存在于电力领域专家脑内,可表示其思维模式。当电力领域专家面临问题时,其首先回忆以往是否存在相同情况,确定匹配度最高的事例,将以往获取的识别结果为基础,结合当前事例与以往事例的差异性进行优化,获取最新的识别结果。在面临全新情况的条件下,基于一般原理,结合思维,尝试不同方法,基于反馈结果进行优化。基于此,利用事例推理模拟专家思维过程,识别电力基建现场风险最适合的方法[17-18]。推理引擎推理过程如图1所示。

图1 推理引擎推理过程Fig.1 Reasoning process of reasoning engine

基于当前问题描述{Zm,Objm},利用以下过程确定最优经验事例。
针对全部事例n∈serch_set(待搜索事例集合)利用式(8)依照Objm确定事例效用:
φmn=φ(Objm,Hn)=I(Objm,Hn)·G(Objm,Hn),
(8)

依照风险划分事例类别,针对全部风险w∈chan_set(待搜索风险集合),sase_set_w={风险为w的事例},利用式(9)确定不同子集内优良事例的效用均值:
(9)
式中,case_set_gw表示集合case_set_w内优良事例构成的子集;Ngw和Nw分别表示不同集合的元素数量。
搜索最优风险w*=argmaxw∈chan_setEgw[φ]。确定该风险是否发生,若风险未发生,则chan_set=chan_set{w*},再次实施搜索最优风险过程;若风险已发生,则进入识别阶段。
为获取高精度的场景相似度,需对不同条件属性实施标准化处理[19-20],防止不同量纲及各取值空间对相似性度量产生影响。利用式(10)表示归一化的条件属性:
(10)

(11)
式(12)所示为最终经验事例的效用:
∂mn=(Smn)ξ(φmn)ψ,
(12)
式中,ξ和ψ均表示权重调节因子。
利用推理引擎机制检索案例识别出的电力基建现场风险区段,并不一定完全满足当前电力基建业务需求,因此需结合模拟退火思想对推理引擎机制进行优化,实现启发式智能的事例自适应搜索。为实现优化过程,对事例库内不同事例添加一项温度属性t,同时设事例生成时t=1。
通过优化获取的最终案例存储入事例库。
2 实验分析
为验证本文所研究的基于NLP和推理引擎的电力基建现场风险区段识别方法的应用性能,选取某市电力基建工程为应用对象,在Windows XP平台下利用Visual C++6.0编程环境,以SQL Server 2000构建数据库,建立应用对象电力基建现场模型,其中包含1 050个区段。利用本文方法识别应用对象风险区段,仿真结果如下。
2.1 NLP技术仿真
随机选取300份应用对象内不同区段的电力基建现场报告,采用本文方法对报告文本内容进行分词处理,将所获取的分词结果作为标识电力基建现场报告的特征,统计分析整个文本集内不同特征,所得结果如图2所示。
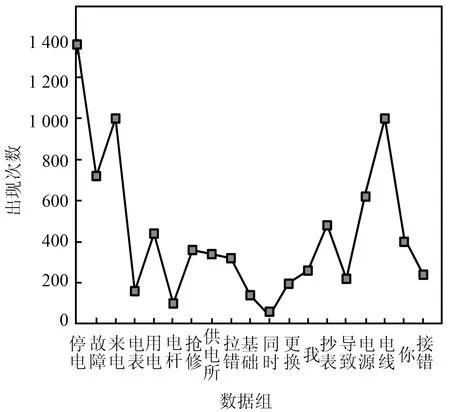
图2 分词结果Fig.2 Word segmentation results
分析图2可知,采用本文方法对所选300份应用对象不同区段的电力基建现场报告进行分词处理,获取停电、故障、来电与电表等分词结果。
为识别、清除应用对象内不同区段的电力基建现场报告文本特征,需对分词结果进行特征降维处理,清除掉对报告文本区分贡献较少的特征,如同电力基建现场风险区段识别关系微弱的特征,降低后续文本特征聚类的复杂度。清除内容主要包括:
① 基本每个电力基建现场报告文本内均出现的词:如“来电”“供电所”与“抄表”等;
② 常用特殊词:主要包括普遍使用的称谓词,如“我”“你”等与电力基建工程无关的词。
③ 词频较低的特征:如“电杆”“同时”等在每个电力基建现场报告文本内出现频次较低的词。
通过对出现频率设定响应的阈值完成特征降维,清除与电力基建工程无关的词汇,留下同电力基建工程相关的关键词。结合实际电力基建工程情况,进一步筛选当前保留的关键词,利用TF-IDF算法确定剩余特征关键性权重值,提取权重较大的特征词频作为应用对象内不同区段的电力基建现场报告文本挖掘的最终结果。
2.2 风险区段识别结果仿真
将以上获取的不同区段的电力基建现场报告文本挖掘的最终结果输入本文方法中的推理引擎内,利用本文方法识别应用对象不同区段风险,利用风险度表示风险识别结果,所得结果如图3所示。
分析图3可知,采用本文方法进行风险区段识别,所得风险识别结果同实际区段风险基本一致,风险识别误差控制在6%以内,误差均值约为3.5%。仿真结果充分说明本文方法具有较高的识别精度。
2.3 能耗仿真
为测试本文方法在区段风险识别过程中的实时能耗,将文献[14]提出的基于大数据的识别方法和文献[15]提出的基于加权开断概率与断开后果严重度的识别方法进行对比,对比3种不同方法进行风险区段识别过程中实时能耗,所得结果如表1所示。
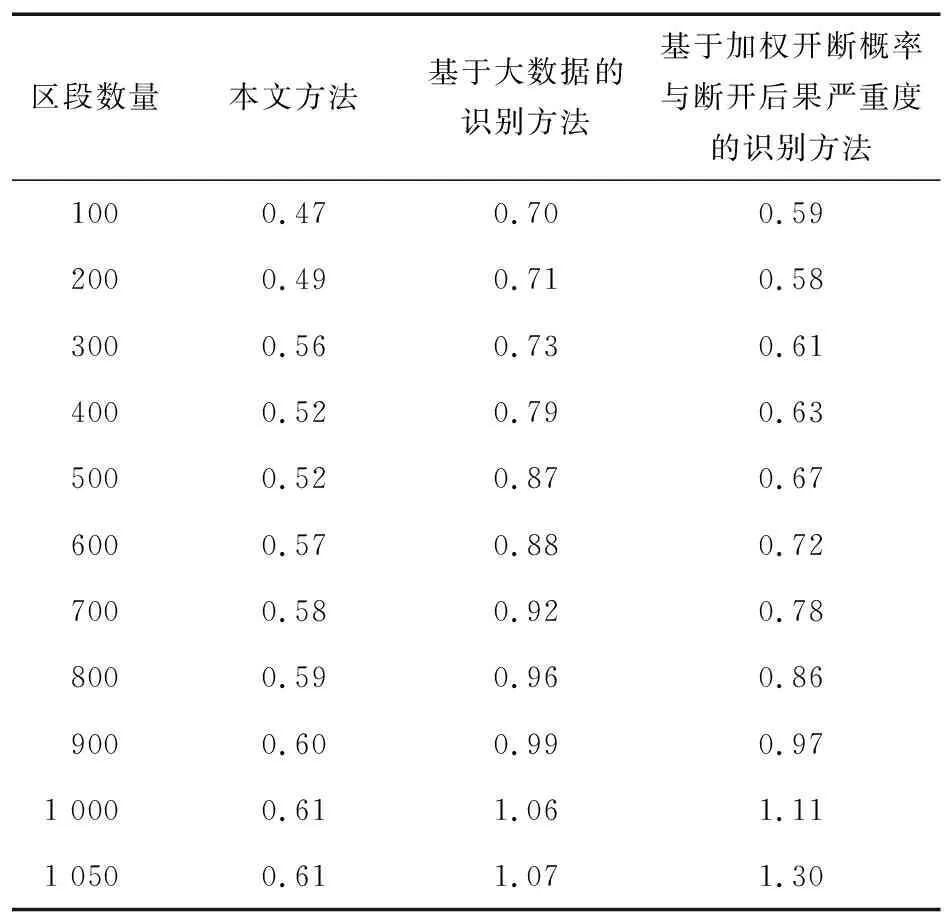
表1 不同方法实时能耗对比结果Tab.1 Comparison results of real-time energy consumption of different methods 单位:J
分析表1可知,本文方法在识别应用对象不同区段风险的过程中,实时能耗范围控制在0.61 J之内,与基于大数据的识别方法和基于加权开断概率与断开后果严重度的识别方法相比,能耗分别降低0.46,0.69 J。实验结果说明本文方法与2种对比方法相比更能节约能源,提升电力基建现场风险区段识别的经济性。
2.4 实际应用性能
利用本文方法识别应用对象不同风险区段,针对应用对象风险区段识别结果确定应用对象薄弱环节,针对不同薄弱环节有针对性地对应用对象进行优化,可降低应用对象的风险,确保应用对象稳定运行。表2所示为应用对象采用本文方法识别风险区段并有针对性完善后,部分区段风险变化结果。

表2 风险度变化情况Tab.2 Change of risk degree
表2中数据充分说明采用本文方法识别应用对象风险区段,并根据识别结果进行针对性优化后,应用对象内各区段风险均有不同程度的下降,由此说明本文方法风险识别效果较好,具有推广价值。
3 结论
本文研究基于NLP和推理引擎的电力基建现场风险区段识别方法,利用NLP技术获取电力基建现场报告文本特征,将其输入推理引擎内,利用推理引擎完成电力基建现场风险区段识别。利用仿真软件对本文方法识别过程进行仿真,结果显示本文方法能够准确识别电力基建现场区段风险。
