高频信息对齐的多尺度融合去雾网络
2023-02-17李鹏泽张选德
李鹏泽, 李 婉, 张选德
(陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021)
1 引 言
由于空气中雾霾、气溶胶等媒介因子的存在,户外拍摄的图片总存在对比度降低和颜色失真等质量退化现象,影响后续的计算机视觉任务的执行性能,如遥感、语义分割、目标检测等[1-2]。所以近些年来图像去雾任务引起了研究人员的广泛关注和研究[3-18],其目的是通过给定的有雾图像得到对应的无雾干净图像。
先前的工作如暗通道先验[7]、非局部先验[8]、颜色线先验[9]和颜色衰减先验[10]等都是遵循大气散射模型的假设,估计透射率和大气光值,进而得到对应的无雾图像。上述先验是对大量无雾图像进行观察统计进而人为设计得到的,因此在大多真实场景下并不能保证它们总是成立,间接说明透射率和大气光的不正确估计会直接影响重构出的无雾图像的质量。
随着深度学习的不断发展,大量基于卷积神经网络的方法被用于图像超分辨、图像去噪和图像去雾等图像恢复任务,且被证明是高度有效的,去雾方法包括 MSCNN[11]、Dehaze-Net[12]、AOD-Net[13]、cGAN[14]和 GFN[15]等。基于学习的去雾方法可进一步分为“间接端到端”和“直接端到端”方法。前者如MSCNN,其目的是为了获取大气散射模型的中间参数,即透射率和大气光,然后通过大气散射模型得到无雾图像,而中间参数的估计会造成重构误差的放大,进一步影响最后的重构结果。后者通过网络学习“有雾图像-无雾图像”的直接映射关系,如 AOD-Net、EPDN[16]、MSBDN[17],避免估计中间参数所带来的问题。但大多数此类方法并未使用先验信息,且计算量和参数量过大,对计算机硬件有较高要求。
为将先验信息引入到以数据驱动的深度学习方法中并降低网络对计算机内存和算力的要求,本文提出一个高频信息对齐的多尺度融合去雾网络(Multi-Scale Fusion Dehazing Network for High-Frequency Information Alignment, HFMSNet),其本质是采用循环模式构建生成对抗网络,贡献如下:(1)对生成器的不同深度卷积层中所嵌入的多尺度特征进行融合学习,利用多尺度特征融合带来的性能优势,通过减少网络通道数与缩减基础构建块数目有效减少了HFMSNet的计算量与参数量;(2)对判别器的输入特征进行数据处理,以促使后续的对抗学习实现输入图像与重构图像之间的高频信息对齐;(3)与现有算法相比,HFMS-Net不仅在PSNR、SSIM方面有一定提升,在视觉效果方面也有一定的竞争力。
2 研究背景
2.1 大气散射模型
根据大气散射模型,图像雾霾化过程可用公式(1)描述:

式中第一项表示拍摄目标自身的反射光到达相机传感器的部分,第二项表示大气光经散射和吸收之后到达传感器的部分。其中I、J分别表示拍摄所得有雾图像和对应无雾图像,A表示全球大气光,z表示图像中的像素点,t表示透射率:

其中β表示大气散射系数,d表示场景深度。
2.2 基于先验的方法
传统的基于先验的去雾方法以大气散射模型为基础,主要目标是估计透射率和大气光值,进而通过大气散射模型反向推导出无雾图像。
基于先验的经典方法有暗通道先验、颜色衰减先验、最大化局部对比度方法[18]以及颜色线先验等。暗通道先验基于无雾图像的大多局部块中的像素值至少在一个颜色通道非常小甚至接近于0的假设提出。Zhu[10]等人观察到在有雾图像的局部块中,随着此处饱和度的下降,其亮度值反而会增大,因此会形成一个明显的差异。Tan[18]通过最大化局部对比度来增强图像的视觉效果,达到去雾目的。Fattal[9]发现在RGB颜色空间的局部块中,像素通常呈现一维分布。
上述方法都取得了不错的性能,但先验知识通常是通过统计观察进而人为设计得到的。由于大气光和大气散射系数的多样性,提前设计的先验假设在很多真实情景下并不成立。此外,由于大气散射模型自身的病态性,中间参数的独立估计一般会存在估算误差,直接影响最后的无雾图像质量,发生去雾残留和颜色失真等现象。
2.3 基于学习的方法
随着深度学习不断发展,基于卷积神经网络的方法不断被引入计算机视觉领域[11-17,19-23]。事实证明基于学习的方法对于图像恢复任务非常高效。在图像去雾领域,基于学习的方法大概可分为“间接端到端”和“直接端到端”方法。
“间接端到端”方法是利用神经网络学习大气散射模型的中间参数透射率和大气光,然后利用大气散射模型推导出无雾图像。MSCNN、Dehaze-Net作为此类方法的代表,首先通过网络训练学习估算透射率的能力并通过传统方法得到大气光值,然后基于大气散射模型获取干净无雾图像。MSCNN包括“粗尺度”和“细尺度”两个子网络。“粗尺度”子网络利用图像全局信息学习全局范围内较粗糙的透射率,“细尺度”子网络利用前者的学习结果(即全局透射率)和图像局部信息去细化此透射率。Dehaze-Net通过在网络架构中设计一些特殊的网络层体现先验假设,将现有的先验假设和网络连接起来。上述方法的缺点在于中间参数的独立估计会放大重构误差,影响最后重构图像的质量。
“直接端到端”方法通过网络训练学习有雾图像到无雾图像的直接映射关系,避免了中间参数的估计,近年来提出的去雾网络大部分均采用“直接端到端”设计。AOD-Net通过将透射率和大气光的独立参数估计融合为估计参数K,然后通过K得到无雾图像。cGAN是条件生成对抗网络,通过在判别器的输入中连接原始输入有雾图像来增强判别器的分辨能力,以此增强整个去雾网络的性能。GFN通过对有雾图像分别做白平衡、对比度增强和伽马校正操作得到对应特征图,将对应特征图连接之后作为新的网络输入,网络经过学习得到白平衡、对比度增强和伽马校正操作所得特征图对应的置信图,然后经过门控融合得到最终的重构图像。MSBDN基于U-Net构建,采用增强策略和错误回馈机制去构建增强解码器并解决U-Net存在的下采样导致图像信息丢失的问题。上述方法大多仅依赖数据驱动而忽略了先验信息的利用,且不断加深加宽的网络给计算机带来了严重的计算负担。
HFMS-Net在生成器中进行多尺度特征融合,充分利用网络的中间层特征,通过减少网络通道数与缩减基础构建块数目有效降低了网络对计算机的算力和内存要求,如图1所示。此外,HFMS-Net在判别器中引入纹理信息提取操作,使后续的对抗学习实现输入图像与重构图像之间的高频信息对齐。

图1 模型大小及网络性能之间的关系Fig.1 Relationship between model size and network performance
3 高频信息对齐的多尺度融合网络
本文提出一个高频信息对齐的多尺度融合去雾网络(HFMS-Net),基于生成对抗网络的思想 构 建 。 受 Cycle-GAN[19]启 发 ,HFMS-Net选择类循环模式作为网络主体框架,在普通生成对抗式网络中引入一个逆向生成器去增强网络约束。
HFMS-Net在生成器的不同深度引入多个残差连接以充分利用网络的中间层特征,实现多尺度特征融合,并利用多尺度特征融合带来的性能优势,通过减少网络通道数与缩减基础构建块数目有效减少了HFMS-Net的计算量与参数量。此外,为将图像的先验特征引入网络学习,本网络对判别器的输入特征进行纹理特征提取以促使后续的对抗学习实现输入图像与重构图像之间的高频信息对齐。
HMFS-Net的网络架构如图2所示,采用循环模式设计。在生成器部分,输入有雾图像经正向生成器学习得到去雾图像,网络学习通过对抗损失逼近去雾图像与真实无雾图像的分布。去雾图像或真实无雾图像经逆向生成器得到输入域预测图像,并通过循环一致损失逼近重构有雾图像与输入有雾图像的分布,相似的还有对重构无雾图像与真实无雾图像分布的逼近。对于判别器,初始输入为去雾图像(或真实无雾图像),去雾图像(或真实无雾图像)经纹理信息提取操作得到新的特征,该特征再与去雾图像(或真实无雾图像)级联作为判别器最终的输入,以此通过网络的训练学习混淆由正向生成器学习的去雾图像和真实无雾图像。

图2 HMFS-Net的网络架构Fig.2 Network architecture of HMFS-Net
3.1 生成器
本网络包括两个生成器:正向生成器和逆向生成器。正向生成器的作用是通过有雾图像重构无雾图像,而逆向生成器采用正向生成器的输出作为输入,其目的是通过无雾图像重构有雾图像,以此增强网络的约束性,更大程度地保证网络学习的准确性。
两个生成器结构相同,如图3所示。网络由输入层、两个卷积块、两个残差块以及输出层构成,网络主体采用模块顺序堆叠的架构。对现有方法的研究发现,现有方法往往只考虑最终的重构结果与真实图像之间的差异而忽略了去雾网络不同深度处嵌入的多尺度中间信息,造成大量有用信息丢失。为此,本文通过在两个卷积块和残差块之间引入跳跃连接以实现多尺度特征融合,充分利用学习过程中网络嵌入的有用特征,在一定程度上避免了信息损失。

图3 生成器和判别器的结构Fig.3 Generator and discriminator structure
网络采用有雾图像作为输入Inp,经过一次卷积、残差依次得到结果Conv1、Res1;再通过跳跃连接将输入Inp及一次残差结果Res1进行级联得到Concat1作为二次卷积的输入,进而得到二次卷积、残差的结果Conv2、Res2;同样地,将一次级联结果Concat1及二次残差结果Res2进行级联得到Concat2作输出层的输入,最后经Relu激活层得到去雾结果。
其中涉及到的卷积操作其卷积核大小均为3×3,而通道数依次为 64,64,128,128,3,且步长设置为1避免了下采样操作带来的信息丢失。每个残差块也由如前所述的两个卷积块组成。
3.2 判别器
判别器通过对输入特征进行判断估计而决定输入是否为“真”,即检验判别器输入是真实无雾图像还是由生成器所得的重构图像,若判别器将输入特征判断为假则输出为0,反之非0。当判别器经过数次迭代训练而对生成器的输出和真实无雾图像无法分辨时,则认为网络学习达到收敛,判别器认为对应的生成器已经有足够的去雾能力。
通过观察,同一场景在不同条件下所获取的图像在纹理结构等高频信息上具有一致性,故在去雾网络的学习过程中过分关注颜色信息等视觉属性而忽略纹理结构信息的一致性会导致重构图像具有一定程度的纹理损失。因此,本网络在判别器的开端引入纹理信息提取操作,并与去雾图像/真实图像进行级联以提供视觉信息,以此对齐输入图像和去雾图像的结构信息。
如图3所示,判别器本质采用普通的二分类网络,核心在于对其输入进行纹理信息提取之后再进行后续的特征学习,将重构图像和真实图像分别转换为灰度图像再进行后续特征传递。判别器主体结构采用顺序堆叠的构造,输入特征尺寸为(256,256,4)。判别器主体由输入层、4个卷积块以及输出层构成。此处使用的卷积块与生成器中的有所不同,其输出层为一个全连接层。此外,为了防止过拟合,此处每个卷积块后均接Dropout层,且其舍弃比例经验性地设置为0.3。
网络采用去雾图像/真实图像作为输入,再将输入的去雾图像或真实图像进行纹理信息提取进而得到单通道特征图,然后与输入的去雾图
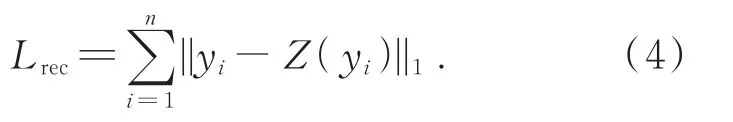
(3)循环一致损失函数。如公式(5)所示,生成器部分采用循环一致损失保持原始图像与重构图像之间的循环一致性,即对于每个训练样本{xi,yi}均有Z(G(xi))≈xi和G(Z(yi))≈yi。


(4)总体损失函数。总体损失函数如公式(6)所示,均衡参数λ设置为10。像/真实图像进行级联得到四通道的特征图,最后将该级联结果作为后续卷积操作的输入得到判别结果。
3.3 损失函数
本网络训练目标与Cycle-GAN相似,定义训练数据集为 {X,Y}={xi,yi}n i=1,采用对抗损失、重构损失及循环一致损失构成总体损失函数。
(1)对抗损失。对于正向生成器G和相应判别器D,其目的是逼近去雾图像与真实无雾图像的分布。如公式(3)所示,以此达到在训练过程中保持纹理结构一致性的目的。
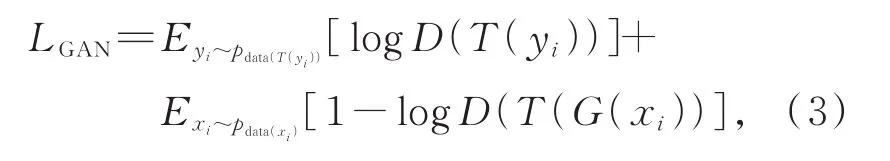
其中T表示对判别器的输入提取纹理信息。
(2)重构损失。逆向生成器Z采用重构损失作为训练目标,以此度量其输入图像及重构图像结构之间的差异性,如公式(4)所示。
4 实 验
本节内容主要分两部分:一是用于展示本文提出的网络与现有去雾网络在合成数据以及真实数据上的定量分析及定性分析结果;二是进行充分的消融实验以凸显本文所引入模块的有效性及对于网络性能提升所带来的影响。
本文在进行对比实验时,依据方法被提出的先后顺序依次为 AOD-Net、cGAN、PMS-Net[20]、PFDN[21]、BCDP[22]。为保证对比的公平性,本文所采用的实验结果均为所采用数据集上的复现结果。
4.1 实现细节
(1)超参数设置。在网络训练中,本文采用Adam优化器并设置固定学习率为0.001,指数衰减率β1和β2分别设置为0.9、0.999。网络共训练120个轮次,批次大小设置为1。
(2)数据集选择。在本网络训练中,随机从RESIDE (REalistic Single Image Dehazing)数据集[23]的 OTS子集中分别选取 3 500对、880对“有雾-无雾”图像用于训练和测试。
(3)数据处理。考虑到图像过大对于网络训练和硬件设备的要求过高,可能会存在内存不足的问题,本网络将训练集中所有图像大小通过随机裁剪的方式设置为256×256,并将像素值范围归一化到[0,1]。
(4)衡量指标。在类似于图像去雾的图像重构任务中,峰值信噪比(PSNR)和结构相似性(SSIM)两个经典指标常常被用来衡量网络的性能。PSNR和SSIM均越大越好,前者越大表示图像的失真越小而有用信息更多,后者越大表示重构图像和真实图像之间的结构相似性越高。因此本文的所有定量分析过程均采用PSNR和SSIM指标做参考。
(5)实验环境。在Windows10系统下,在单张NVIDIA TITAN Xp的GPU上采用Python3.6、Tensorflow2.4.1框架实现。
4.2 对比实验
4.2.1 合成域数据
表1将本文所提网络与其他现有网络在测试集上的定量分析结果(均采用测试集上的平均结果)进行呈现。就PSNR、SSIM而言,在合成数据集中HFMS-Net展现了最好的性能,与PFDN相比,其增幅分别为0.71、0.016。

表1 在合成数据上的定量分析结果Tab.1 Quantitative analysis results on synthetic data
图4给出了合成数据上的视觉效果比较。从图4可以看出:AOD-Net和cGAN存在去雾不干净以及轻微的过饱和现象;PMS-Net、BCDP存在严重的颜色扭曲现象:PMS-Net对天空区域的处理表现极差,BCDP去雾结果的色调整体偏黄;PFDN几乎呈现了非常好的视觉效果,但与干净图像相比,HFMS-Net在目标轮廓结构处更加锐利,保真度更高,如第一行图像中的“公交专用”字样。

图4 在合成数据上的视觉效果比较Fig.4 Comparison of visual effects on synthetic data
4.2.2 真实域数据
图5给出了真实域数据上的视觉效果比较。从图5可以看出,在面对真实的浓雾图像时,AODNet在景深较远处有去雾残留;cGAN存在轻微的颜色失真;PMS-Net则存在严重的颜色扭曲现象,甚至产生了一定程度的块效应;BCDP去雾结果偏黄,甚至产生一定的块效应和伪影;PFDN相比于其他网络呈现了比较好的视觉效果;而HFMSNet也展现了非常有竞争力的去雾效果,对信息的保真度更高,如第一行图像中旅客外套的颜色。

图5 在真实数据上的视觉效果比较Fig.5 Comparison of visual effects on real data
4.3 消融实验
为了表明本文所提网络架构的有效性,设计了以下4组实验并对其进行定量分析以及视觉效果的比较:(1)Model_A:表示网络最初始的状态,包括两个生成器及一个普通的二分类判别器;(2)Model_B:表示在(1)的基础上对其生成器引入两条跳跃连接;(3)Model_C:表示在(2)的基础上对判别器的输入引入纹理信息进行提取操作;(4)Model_D:表示在(3)的基础上将去雾结果/真实图像与纹理提取结果进行级联。
从表2可以看出,当依次引入跳跃连接、纹理信息提取及特征级联操作后,网络在测试数据集上得到的PSNR和SSIM均呈现上升的趋势,尤其是引入跳跃连接后PSNR可得到约0.6的提升,由此可说明通过在不同位置的卷积层处引入跳跃连接进行多尺度特征融合对于网络性能的提升有着很大的优势。此外,引入纹理信息提取及特征级联操作对于网络结构信息及视觉属性的提供也是非常必要的。如图6所示,引入纹理信息提取及特征级联操作使建筑物的轮廓结构变得更加清晰平滑。

表2 消融实验定量结果Tab.2 Quantitative results of ablation experiments

图6 消融实验视觉效果对比Fig.6 Comparison of visual effects of ablation experiments
5 结 论
本文提出了一个高频信息对齐的多尺度融合去雾网络(HFMS-Net),其本质是采用循环模式构建生成对抗网络。HFMS-Net对生成器中嵌入的多尺度特征信息进行融合提取以避免信息丢失,并利用多尺度特征融合带来的性能优势通过减少网络通道数与缩减基础构建块数目有效减少了HFMS-Net的计算量与参数量。对于判别器,网络需对其输入进行纹理信息提取,逼近去雾图像和有雾图像之间的高频信息,使基于数据驱动的网络学习更具物理解释性。
整个网络学习没有涉及任何其他的预训练网络,在保证去雾性能的前提下,在一定程度上缩减了模型架构。与现有方法相比,本文算法将图像先验特征引入网络学习,拥有更低的空间复杂度,参数量显著降低,以PFDN所需内存的1/5取得了更优越的性能。HFMS-Net在参数量降至2 MB的同时PSNR至少提升了0.71。实验证明与现有方法相比,本文提出的网络其性能不仅在合成域数据上有着一定的提升,在真实数据上也取得了一定的效果。
