基于注意力机制无监督心脏超声序列图像配准
2023-02-13兰其斌黄立勤
兰其斌,黄立勤
(1. 福建师范大学协和学院,福建 福州 350117; 2. 福州大学物理与信息工程学院,福建 福州 350108)
0 引言
医学图像配准技术是医学图像分析中的关键步骤,是实现医学图像融合、 分割、 对比和重建的前提. 应用图像配准技术可以监测人体内部器官和感兴趣区域的运动轨迹,通过配准心肌组织能够跟踪心脏的运动信息从而监测心脏功能. 超声心动图配准的研究工作在近年取得了一定的进展,大部分的研究主要基于传统非刚性医学图像配准方法. Zagrodsky等[1-2]提出基于互信息的超声图像配准方法,实现了同一病人图进行融合. Woo等[4]在变分框架下,利用强度信息和局部相位信息进行非刚性超声图像配准. Matinfar等[5]提出了基于模型的快速高精度分割,通过计算相应控制点之间的薄板样条(TPS)变换实现超声图像配准. Veene等[6]采用一种多分辨率非刚性配准算法,运用三维三阶B样条估计变形场实现在三维超声图像二尖瓣环跟踪. 基于传统非刚性医学图像配准,由于特征点选取过程繁琐,往往需要人工操作缺乏自动性,对于每一对待配准的图像,传统的配准方法通常从零开始迭代优化代价函数,忽略了同一数据集图像间共享的固有配准模式,限制了配准速度,同时由于参数的维数不是很高,参数化后的近似模型与原问题之间差距较大,使配准精度降低.
随着深度学习的出现,近年来各种计算机视觉任务的算法性能有了显著的进步,基于深度学习的医学图像配准算法也得到了迅猛的发展,由于其端到端的应用方式,高精度的配准成为目前图像配准领域的研究热点. 依据训练方法的不同,基于深度学习的医学图像配准方法分为全监督、 无监督和弱监督等3种模式. 全监督配准模型采用深度神经网络来估计两幅(或一组)图像配准所需的空间变换参数,需要使用ground truth作为参数来指导学习过程,通常采用两种方法来获得,采用传统的配准方法进行估计或使用已知真实变换的模拟图像. 如Eppenhof等[7]通过B样条的方式采样得到密集形变场,并将该形变场作用于真实图像,从而得到变形后的图像. Cao等[8]通过医学图像配准软件ANTs对图像预先进行配准,并将得到的形变场作为训练网络的ground truth. 由于无监督图像配准只需要对浮动图像和参考图像进行训练,预测变形场和变形运动图像,因此成为目前医学图像配准研究的热点. Balakrishnan等[9]提出VoxelMorph配准模型,通过定义均方误差(MSE)相似性测度和形变场平滑约束构成的损失函数,优化Unet网络,实现核磁共振(MR)脑图像无监督配准. De-Vos等[10]通过无监督的训练方式叠加训练几个网络完成仿射、 可形变的配准. Fu等[11]提出一个基于两个空间变换网络(spatial transformer network, STN)的LungRegNet,用于从粗到细的肺电子计算机断层扫描(CT)图像配准. 大多数弱监督配准网络类似于无监督网络,只是在训练过程中需要使用额外的信息,这些信息包括部分形变场信息,掩膜或标签信息. Chen等[12]提出使用语义信息(通过预先训练的分割网络获得的肺小叶和气道掩膜)来指导配准,设计一个两阶段的配准网络,第一阶段在分割掩模上预测粗变形场,第二阶段在血管结构上预测细变形场. Mansilla等[13]提出使用自动编码器从参考和扭曲浮动掩膜中提取全局解剖特征,通过计算其平方欧几里得距离作为额外的全局损失,以助于预测更加真实和准确的结果.
以上基于深度学习的医学图像配准研究主要集中在磁共振成像(MRI)、 CT单模态图像配准及CT-MRI、 MRI-TRUS、 CT-CBCT及2D-3D等多模态医学图像配准. 由于超声图像的公开数据集很少,相应的超声图像配准的论文数量也很有限. 目前仅有两个公开的超声图像大脑数据集RESECT和BITE,只有一篇论文采用公开可用的数据集实现单模超声图像配准[14], 文献[15]中在人工标注的结构上训练卷积神经网络,实现神经外科胶质瘤切除中基于分割的超声容积配准. 本研究在VoxelMorph配准模型基础上,将其应用于心脏超声序列图像无监督配准,并引入通道注意力机制模块对模型加以改进,实验选取不同的相似性损失函数和平滑损失函数,通过数据分析该网络有效提升了配准精度.
1 配准模型研究
1.1 配准模型的结构
由于心脏是在活体内做非刚体运动的柔性组织,与脑图像相比,心脏图像中精确的标记点较少,并且超声图像受到噪声污染,存在斑点噪声且灰度不均匀,对比度低等问题,因此超声心动图的配准较其他器官如肝脏、 脑、 肺部等各脏器的MRI、 CT图像的配准要困难. VoxelMorph配准模型不需要ground truth解剖标志等监督信息,并且具有较高的配准精度及计算速度,故采用VoxelMorph作为配准模型参考架构,引入通道注意模块负责注意力机制,构建配准模型应用于超声心动图像配准.
所采用的配准网络结构如图1所示,主要由注意力机制模块、 Unet卷积神经网络模块及空间转换模块(spatial transformer network, STN)[16]构成. 输入的浮动图像M和固定图像F在通道的维度进行拼接,经过一个引入注意力机制模块的卷积神经网络(Unet编码器-解码器网络)[17], 预测一个从浮动图像到固定图像的配准场(形变场),并使用空间转换网络得到配准后的图像.

图1 配准网络结构
1.2 通道注意力机制模块
近年来,将通道注意力并入卷积块中引起广泛的关注[18-20],具有代表性的是挤压和激励网络(SENet)[21],通过学习每个卷积块的通道注意,从而为各种深层CNN架构带来明显的性能提升. 如图1所示, 在构建Unet网络中添加通道注意机制模块,显式校准特征通道之间的相互依赖性. 注意机制模块具体结构如图2,给定输入特征图X,注意机制模块首先为每个通道独立采用全局平均池化(GAP),然后使用两个全连接(FC)层及非线性Sigmoid函数来生成通道权重.
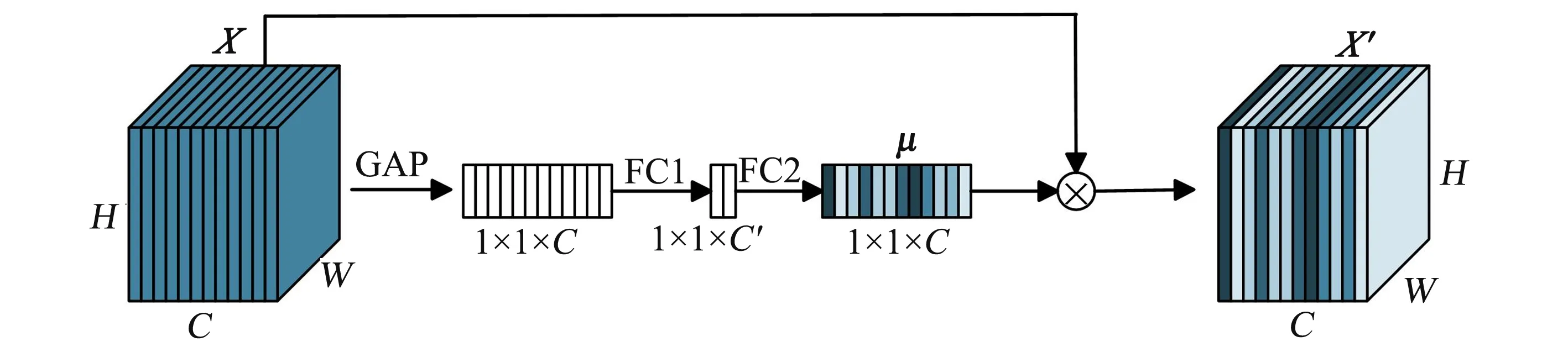
图2 通道注意机制模块
通过注意机制模块获取通道权重μ=[μ1,μ2, …,μc],用于对输入特征图X进行重构,生成新的校准特征图X′,以上过程可以用公式表述为:
μ=Sigmoid(FC2(ReLU(FC1(GAP(X))))),X′=X·μ
(1)
1.3 构造基于注意力机制的Unet网络
Unet整体的流程采用编码和解码架构,分为下采样阶段和上采样阶段,网络结构中包含卷积层和池化层,网络中较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题. 构建的基于注意力机制的Unet结构如图1所示,输入浮动图像和固定图像首先通过左侧编码器模块,包含有四个下采样子模块,模块下方的数字表示其通道数,输入图像的分辨率是160 px×192 px. 首先将输入的浮动图像和固定图像在通道的维度进行拼接. 在左侧编码阶段,每个模块运用32个3×3的卷积核进行特征提取,步长为2(图像尺寸减半),每个卷积层后接激活函数LeakyReLU,因此第1~5个模块的分辨率分别是160 px×192 px、 80 px×96 px、 40 px×48 px、 20 px×24 px和10 px×12 px. 右侧解码器包含四个子模块,分辨率通过上采样操作依次上升,直到与输入图像的分辨率一致. 使用跳跃连接,将编码器中的各子模块的输出特征图经过通道注意力模块得到的新的校准特征图, 并与具有相同分辨率上采样特征图结果进行连接,从而将编码阶段学到的特征经注意力机制模块校准后,直接传播到生成配准特征的解码器模块,作为解码器中下一个子模块的输入. 解码器输出通过两个卷积层输出,得到浮动图像到固定图像的形变场φ.
1.4 空间转换网络(STN)模块
空间转换网络(STN)模块可以插入到现有的卷积神经架构中,使神经网络能够主动地在空间上转换特征映射,不需要对优化过程进行额外的训练监督或修改. 因此,如图1所示在Unet网络中插入空间转换网络,将Unet网络输出形变场φ作用在浮动图像M上,以得到配准输出图像M(φ),并通过最小化M(φ)与F的差来学习最优参数值.
2 构造损失函数
VoxelMorph网络无监督训练策略的损失函数,主要通过基于图像的灰度值来最大化图像之间的匹配程度的目标函数. 损失函数包括相似性损失Lsim和平滑损失Lsmooth两部分. 相似性损失用于衡量图像之间相似性,而平滑损失作用是使产生的形变具有空间平滑性. 无监督损失函数(λ为正则化参数)可以表示为:
Lus(F,M,φ)=Lsim(F,M(φ))+λLsmooth(φ)
(2)
2.1 相似性损失函数Lsim
基于灰度的图像相似度测度主要包括均方误差、 交叉互相关、 互信息(MI)等. 互信息通常用于多模态的图像,因此本研究主要采用均方误差,交叉互相关. 均方误差在医学图像配准中用于表示固定图像F与变换后浮动图像M(φ)灰度值的平均方差期望,表示为:
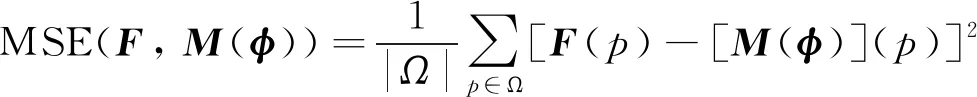
(3)
其中:Ω为图像的面积;φ为图像变形场.
互相关及其变体作为医学图像配准的相似度测度假设待配准图像对应结构的灰度具有线性关系,适用于单模态医学图像之间的配准,全局互相关对于细节的敏感度不如局部互相关,因此采用局部交叉互相关作为图像配准的损失函数,具体表示为:

(4)
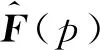
由局部交叉互相关定义相似性损失函数Lsim为:Lsim=-CC(F,M(φ)).
2.2 平滑损失函数Lsmooth
在训练网络过程中,由于最大化图像的相似性测度往往导致产生不连续的变形场,因此通常要对预测的变形场施加空间平滑性的约束,采用变形场梯度的L2范数的平方作为变形场平滑损失函数,具体如下:

(5)
此外,还采用了一种弯曲能量惩罚[22]的正则化方法,通过计算变形场的二阶梯度作为平滑约束项,使变形场局部变换的二阶导数最小,从而产生局部仿射变换,进而增强全局平滑,其公式如下:
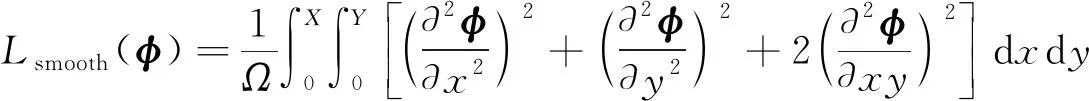
(6)
3 实验与结果分析
实验硬件环境: Intel i5-8300H CPU,GTX1050Ti 显卡; 软件环境为 Windows10操作系统,Cuda9.0,Cudnn 7.3.1. 配准模型的训练和验证均在深度学习算法框架Tensorflow1.13.0环境下完成.
3.1 实验数据及预处理
所采用的心脏B型超声序列图像包含55位病人的心脏超声视频,每一个视频图像的帧数近26帧约为一个心动周期的视频图像. 由于B型超声图像的近区部分受换能器发射波形的振铃影响形成盲区,远区超声图像信噪比较低,图像质量较差,因此实验中选取中部重要临床诊断区域图像用于配准,每一帧图像的大小为160 px×192 px. 并且由于超声图像存在斑点噪声,实验采用中值滤波进行图像预处理.
3.2 参数设置及评价指标
实验配准模型采用Adam优化算法,损失函数相似性损失Lsim和平滑损失Lsmooth项权重比为10∶0.1,设置初始学习率为0.003,batch-size设置为2,训练轮次为1 000次.
采用的配准性能评价指标: 戴斯相似系数(DICE), 用于评估两图像间对应区域的重叠率; 互信息(MI)基于信息论和联合熵度量两图像间统计相关性,MI的度量值越大,两图像间的灰度分布越相似; 结构相似性(SSIM), 其取值范围是[0, 1],值越大表示配准结果越准确; 归一化均方根误差(NRMSE),取值范围是[0, 1],用于衡量配准输出图像和固定图像之间的差异,NRMSE越小表示配准效果越好. 评价指标表达式分别为:

(7)
MI(M(φ),F)=H(M(φ))+H(F)-H(M(φ),F)
(8)
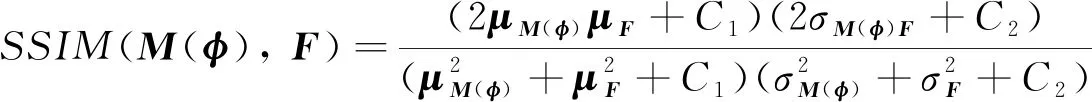
(9)

(10)
式(7)中,对固定图像F与配准输出图像M(φ)各自以其图像灰度均值为阈值进行二值化处理后计算其DICE值; 式(8)中,H(M(φ))及H(F)表示配准输出图像与固定图像的香农熵,H(M(φ),F)表示两幅图像的联合熵; 式(9)中,μM(φ)及μF分别表示两幅图像的均值,σM(φ)、σF分别表示图像的标准差,σM(φ)F表示两幅图像的协方差; 式(10)中,RMSE为均方根误差,所采用的NRMSE即是对RMSE进行归一化处理.
3.3 配准模型的实验验证
实验通过提取任一超声视频的26帧心脏超声序列图像,结合超声心动图像运动周期性,对前20帧进行训练,后6帧作为配准测试,训练及测试过程中选取第N帧作为浮动图像M,第N+1帧作为固定图像(参考图像)F, 测试配准结果如图3所示.
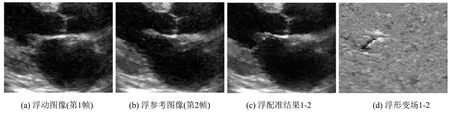
图3 心脏超声序列图像配准结果
由上图所示,第一组图像中局部变形较大,存在局部配准损失,其余四组图像配准效果较好,在实际应用中可以提高帧率来减少相邻帧局部大变形. 采用本研究配准模型,实验中训练1 000轮次所耗费的时间约为200 s左右,在配准测试中每一帧的平均配准时间约为8 ms,据市场调查,目前大多数的中高档次B型超声设备二维成像帧率在50 F·s-1以下,每帧的成像时间大于20 ms,因此该配准速度基本能够满足超声序列图像配准的实时性需求,通过配准可以得到相邻帧心肌组织运动变形场,从而构建运动模型对心脏室壁运动功能分析.
3.4 模型有效性比较实验
为了验证模型的有效性,实验分别对配准前、 采用最优非线性算法SyN运用ANTs配准、 VoxelMorph配准网络和本研究配准模型的配准结果,采用MSE+Grad作为损失函数,计算相关4组图像的平均配准性能评价指标,实验结果如图4所示。从图中可见,本研究基于注意力机制的配准模型的DICE、 MI、 SSIM、 NRMSE等性能指标均优于其他的配准方法.
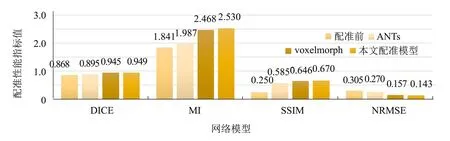
图4 不同网络模型的心脏超声图像配准指标
3.5 配准模型的消融实验
所采用的配准模型,主要工作在于VoxelMorph配准网络模型的基础上引入通道注意力机制模块,采用不同的损失函数实现超声心动图像的配准. 为了验证通道注意力机制模块的有效性,基于两种配准模型,引入通道注意力机制及未添加注意力机制模块的VoxelMorph配准网络模型,选取不同的相似性损失函数和平滑损失函数进行消融实验. 实验基于两种配准模型,分别选取了均方误差(MSE)、 局部交叉互相关(NCC)作为相似性损失函数Lsim,选取公式(5)的Grad、 公式(6)的Bend,以及二者相加的Bend_Grad作为平滑损失函数Lsmooth. 比较相关5组图像的平均配准性能评价指标,结果如表1所示.

表1 消融实验结果
基于表1的数据分析,可以看出引入注意力机制的本研究配准模型的性能指标相对于VoxelMorph配准模型均有一定程度的提升,采用相似性损失函数MSE要优于NCC,平滑损失函数Grad优于Bend及Bend_Grad. 采用MSE+Grad作为损失函数,本研究的配准模型相比VoxelMorph配准网络模型,DICE指标提升了0.42%,MI指标提升了2.5%,SSIM提升了3.7%,NRMSE减小了9%,表明了其配准模型的有效性.
4 结语
通过引入通道注意力机制,构建由注意力机制模块、 Unet卷积神经网络模块及空间转换模块STN构成的配准模型,将其应用于心脏超声序列图像配准. 实验选取不同的相似性损失函数和平滑损失函数,对比VoxelMorph配准模型与本研究配准模型,其相关配准性能指标DICE、 MI、 SSIM、 NRMSE都得到了不同程度的提升. 从配准效果及配准时间分析上看,本研究配准模型基本可以满足心脏超声序列图像配准的实时性的需求,通过配准可以得到相邻帧心肌组织运动变形场,从而构建心肌组织运动学模型. 由于实验所采用的数据集的超声视频图像帧数及实验硬件设备条件有限,改善实验硬件设备配准及增加数据集视频图像的帧数及帧率,有利于提升配准的性能指标,减少配准时间,提升临床应用价值.
