改进YOLOv5的高空航拍图像检测方法
2023-02-11谢晓竹
谢晓竹,卢 罡
(陆军装甲兵学院,北京 100072)
1 引言
无人机航拍在战场侦查、交通管制、抢险救灾等军用或民用领域中具有普遍的应用价值。无人机由于其载荷小,飞行高度和轨迹不稳定的特点[1],导致航拍图像目标小,图像模糊,存在遮挡等情况,造成目标背景情况复杂,所含信息量较少,形状特征不易提取,使得针对高空航拍目标检测存在诸多困难。传统的基于滑动窗口的目标检测算法诸如Haar分类器[2-3]、DPM算法[4]使用人工设计的特征提取,滑动窗效率低下,表征能力不强。基于深度学习的目标检测算法构建了多层卷积神经网络,通过对大量样本进行训练,学习目标特征。相对于传统算法,该方法大量使用卷积运算,发挥了硬件计算能力强的特点,深度网络结构提升了模型的检测准确率。
目前,基于深度学习的目标检测算法大致可以分为2种类型[5]:一种是基于候选区域的两阶段目标检测模型(two-stage),另一种是基于回归的单阶段目标检测模型(one-stage)。单阶段目标检测YOLO[6]模型在平衡检测精度和速度方面具有很高的检测性能,是工业领域的首选模型,目前已更新到YOLOv5版本。
无人机航拍目标检测近年来逐渐成为研究热点,主流的数据集有天津大学推出的VisDrone数据集,武汉大学推出的DOTA数据集等,这些数据集都是低空飞行的无人机航拍采集的,对于飞行高度在3 000 m以上的高空航拍图像则缺乏专门的数据集,使得对高空航拍图像的目标检测缺少数据训练。对高空航拍目标,在自然场景图像中性能优异的YOLOv5模型很难较好的提取目标特征,漏检率和误检率较高。为此,以YOLOv5的3.0版本为基础,从以下方面进行改进:建立高空航拍目标数据集对模型进行训练;针对航拍目标特点,使用高斯函数差分[7](difference of gaussian,DoG)多尺度增强图像细节,提升训练效果;针对目标特征难以提取,修改网络结构,使用加权双向特征金字塔网络[8](bidirectional feature pyramid network,BiFPN)代替原来的路径聚合网络[9](path aggregation network,PANet),在原模型3个检测头的基础上再增加一个大尺度检测头,专门用于检测小目标。从而提升模型对高空航拍目标的检测能力。
2 YOLOv5
YOLOv5模型是当前YOLO模型的最新版本,一共有YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x四个网络模型,网络架构分为2个部分:骨干网络(backbone)和Head结构,具体结构如图1所示。
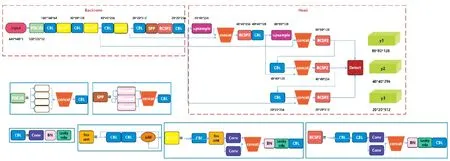
图1 YOLOv5网络结构
图像经过预处理后输入到骨干网络,骨干网络采用特征金字塔[10](feature pyramid networks,FPN)结构自底向上提取特征,并在不同图像细粒度上聚合并形成图像特征,主要由Focus、CBL、BottleNeckCSP和SPP结构组成。Focus结构将输入图像切分成4份,在通道维度上进行拼接,使得特征图尺寸从640×640×3变成320×320×32,图像的宽度、高度信息融合到了通道维度上,可以减少浮点运算,提升训练速度。CBL由标准的卷积模块、归一化和Leaky-ReLU[11]激活函数组成,是模型中的基础结构,进行卷积运算提取特征。BottleNeckCSP由BottleNeck模块堆叠而成,参考了跨阶段局部网络[12](cross stage partial network,CSPNet)思想,解决了冗余梯度信息问题,通过分割梯度流,使梯度流通过不同的网络路径传播。BottleNeck由1×1和3×3卷积组成,可以通过卷积计算灵活改变数据的通道数。在YOLOv5中,设计了2种BottleNeck结构,区别在于是否有shortcut连接。SPP结构参考空间金字塔网络(spatial pyramid pooling networks, SPPNet)[13]将不同尺寸的输入图像统一为相同大小的特征图,先使用卷积使得通道数减半,再经过3个不同尺寸的最大池化层,最后通过拼接使得不同大小的输入在经过池化后特征的宽度、高度保持一致。
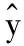
(1)
目标损失同样为二值交叉熵,表示为
(2)
回归损失采用GIOU[14]计算,A为预测框,B为真实框,C为包含A与B的最小凸闭合框,表示为
(3)
总损失为以上3部分损失的加权和,表示为
loss=α·clsloss+β·objloss+γ·giouloss
(4)
3 模型改进
3.1 构建高空航拍数据集
以汽车为目标,通过无人机实飞,飞行高度为3 000~4 000 m,采集1 600余张图像,对其进行手工标注。其中1 300张图像构成训练集,300余张作为验证集。与VisDrone、DOTA等公开数据集比较,高空航拍数据集有以下特点:
1)目标尺度变化剧烈,随着无人机飞行高度、速度和拍摄角度不同,目标尺度会相应发生变化,导致目标提供的细节信息有限。
2)拍摄视野广,背景复杂,包含大量噪声信息,会弱化目标特征,易发生漏检情况。
3)外部环境变化导致拍摄图像质量多变,高空环境下无人机飞行不稳定,造成成像模糊,同时,不良气候也会弱化目标特征。
3.2 多尺度细节增强
高空航拍图像中的目标由于像素点较少,缺乏细节信息,边界特征不清晰,导致模型无法很好识别目标。使用不同尺度下的高斯函数的差分来增加目标细节信息[15],从而提升检测效果。高斯函数表示为
(5)
使用标准差为σ1=1,σ2=2,σ3=4的高斯函数得到3种不同程度的滤波结果,表示为
B1=Gσ1*I,B2=Gσ2*I,B3=Gσ3*I
(6)
I为原图,σ控制着周围像素对当前像素的影响程度,σ越大,远处像素对中心像素的影响程度也越大,选择不同的σ得到3种程度的细节信息,如图2所示,从左至右分别对应σ1、σ2、σ3,σ越来越大,远处像素对中心像素的影响也越来越大,图像也越来越模糊。

图2 高斯滤波成像
将滤波结果与原图差分,得到3种不同程度的细节信息,表示为
D1=I-B1,D2=I-B2,D3=I-B3
(7)
将3种细节信息的加权和合并到原图中,得到I*,表示为
I*=w1×D1+w2×D2+w3×D3+I
(8)
w1=0.8,w2=0.5,w3=0.25,为了突出目标像素,减小周围像素的影响,将w1调大,w3调小,提高目标图像与背景的区分度,突出了低频图像骨架信息,过滤了高频信息,降低了冗余度和计算量,实现去噪。
3.3 改网络结构
以YOLOv5为基础,主要从三方面对模型进行修改:一是修改激活函数;二是使用多尺度特征融合;三是增加大尺度检测头。
YOLOv5在CBL模块中的激活函数是Leaky-ReLU,表示为
(9)
其中,α取值在(0,1)之间,Leaky-ReLU解决了ReLU函数在输入为负的情况下产生的梯度消失问题,但无法为正负输入值提供一致的关系预测。使用Mish[16]作为激活函数:
Mish=x·tanh(ln(1+ex))
(10)
图3为Mish函数图像与其导数,可以看出Mish函数具有无上界、有下界、非单调和平滑的性质。无上界和有下界既避免了函数饱和,防止梯度消失,又提升网络正则化效果;非单调为较小的负输入产生负输出,增加了表现力并改善了梯度流,对不同的初始化和学习速率提供一定的鲁棒性,保证信息不会中断,使得更多神经元学习到参数;平滑能够让信息深入神经网络,使得网络更容易优化。
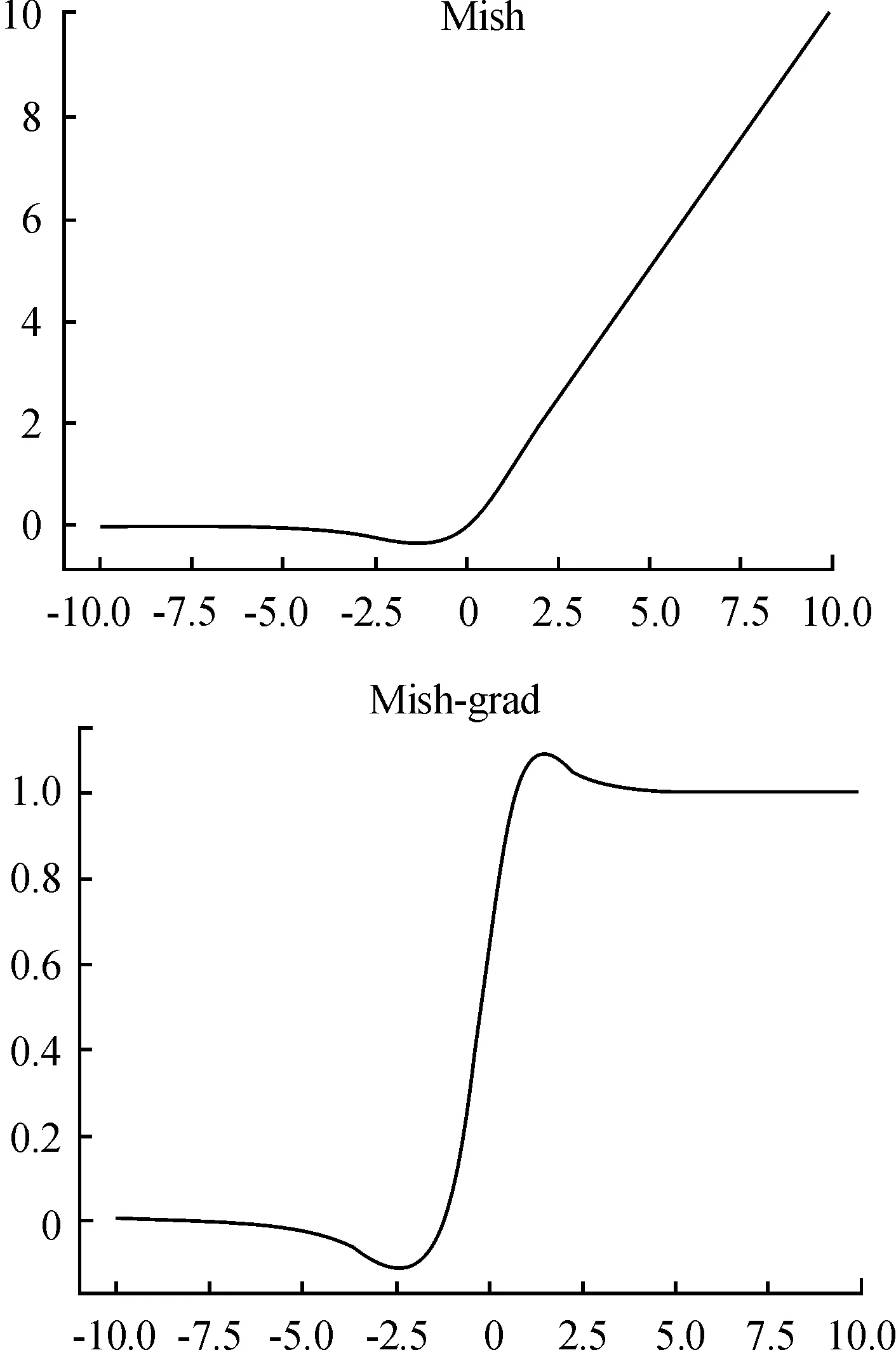
图3 Mish与其一阶导数
BiFPN和PANet都源于FPN。FPN提出了一种自上而下的方法来组合多尺度特征,这是一项开创性的工作,而PANet在FPN的基础上增加了一条自底向上的路径,从而实现了自顶向下和自底向上的双向特征融合,但需要花费更多的参数和计算。
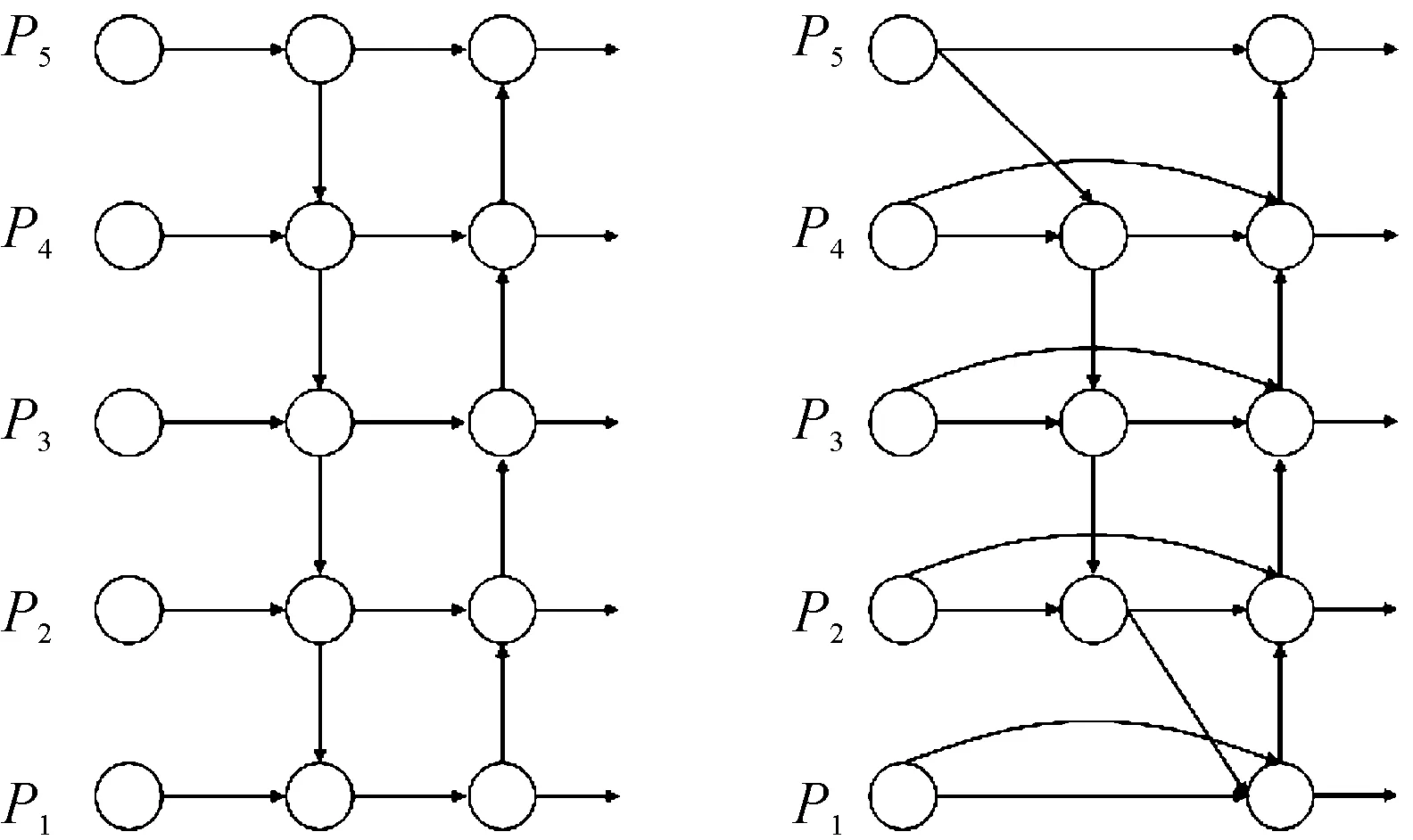
图4 PANet和BiFPN特征融合对比图
(11)
(12)
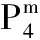
为增强对高空航拍目标的检测能力,在YOLOv5的基础上融合特征,增加大尺度检测头,增强浅层的语义信息,进一步提升对小目标的特征提取和定位能力,具体修改如图5红框所示。
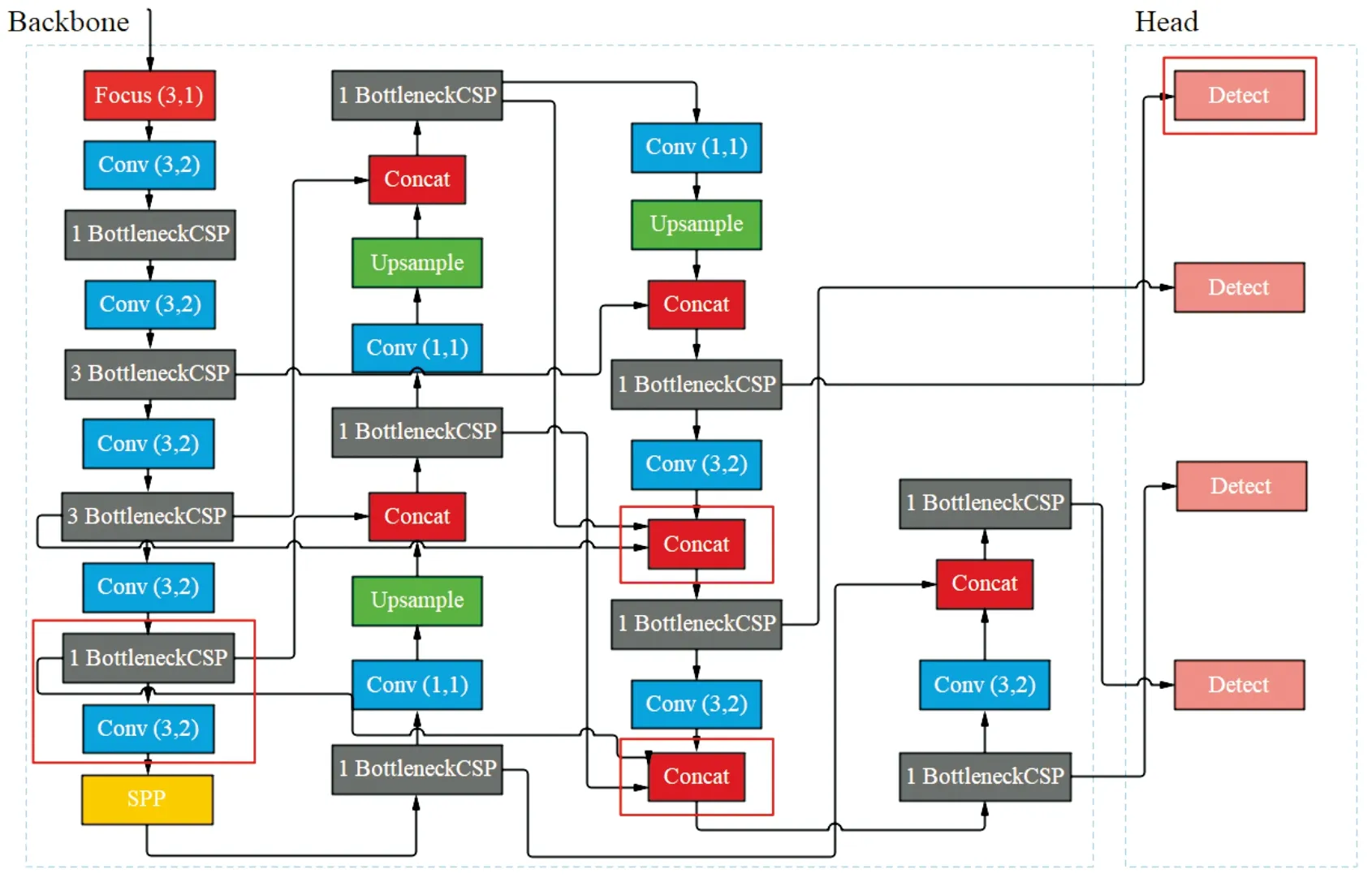
图5 改进后网络结构图
在Backbone提取特征过程中,增加一次卷积,得到10×10×512的特征图,进一步提取深层特征信息。在网络25和28层增加拼接操作,分别将6,19,24层和8,15,27层特征进行融合,通过融合不同层次特征,平衡目标特征和定位精度。在Head部分增加特征尺寸为160×160×64的检测头,用来更好的对小目标进行检测。相较于原模型的7.4×106个参数,修改后的模型参数有1.1×107个,网络深度也由232层增加到326层,新增加的参数和网络层主要是实现多尺度特征融合,该方法在计算时没有采用指数运算,因此模型整体计算量并没有大幅增加。经过更深网络的学习,模型可以更好地平衡目标特征和定位精度,在权重计算时舍去语义特征不丰富的特征,将注意力集中在语义丰富的特征上,以此突出目标的特征。
4 实验结果分析
4.1 实验环境配置
实验环境如表1所示,标注使用labelImg软件。
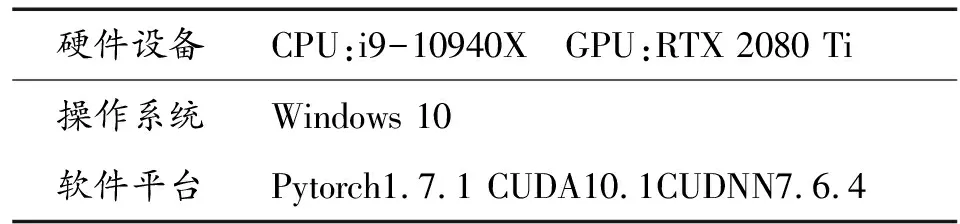
表1 实验环境配置
4.2 评价指标
目标检测领域中,常用评判标准有精确率和召回率的调和平均数F1-score,表示为
(13)
准确率P(Precision),表示为
(14)
召回率R(Recall),表示为
(15)
TP是正确检测出的正样本数量,FP是错误检出的负样本数量,FN是漏检的正样本数量。
平均精度mAP在单目标检测时是AP,是P-R曲线围成的面积。
使用同样的实验环境、训练参数和高空航拍图像数据集,对原模型和改进后的模型分别进行训练,并在验证集中进行分析。
4.3 实验参数选择
YOLOv5模型有28个超参数,分为网络模型相关参数和数据增强相关参数,由于实验数据集的数据量较少且车辆是唯一检测目标,因此启用Mosaic数据增强[17]、单目标检测以获得更好的训练效果。
Mosaic数据增强可以提升数据集的整体质量,将4张图片随机裁剪,裁剪的长宽、位置可以随机变化,再拼接到一张图片上作为训练数据,目标框也随之调整。Mosaic数据增强丰富了检测物体的背景,有利于对小目标的检测,在抽取4张图的情况下,每张图都有不同程度的缩小,原来的目标尺寸也更接近小目标的大小。
设置YOLOv5中的single-cls参数开启单目标检测,由于本数据集中制设置了车辆一个目标,单目标检测可以加速训练并且降低噪音干扰。
4.4 结果分析
图6中黑色表示改进的YOLOv5实验结果,蓝色表示YOLOv5实验结果。由表2和图6看出:改进的YOLOv5模型F1-score比原YOLOv5模型提升了8%,准确率提升了10.3%,mAP提升幅度最大,达到了12.6%,召回率提升6%,说明对YOLOv5模型进行的改进操作对本数据集的检测综合性能更好,准确率,检测精度和漏检率都分别有所提升。
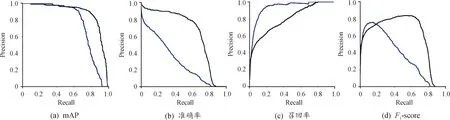
图6 实验结果
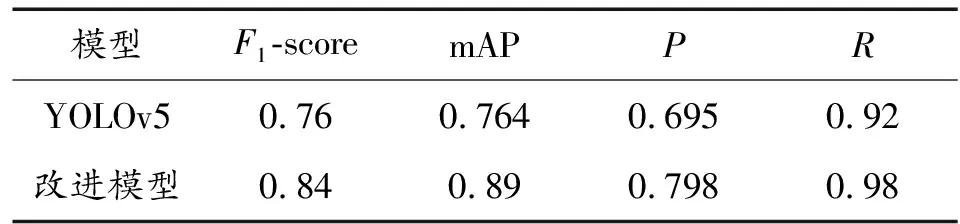
表2 模型性能
分析原因,通过分析数据集图像,选择使用高斯滤波对图像进行多尺度细节增强,突出了目标图像特征,强化了前景与背景的区别,使得模型训练时能够更好的提取目标特征。对网络模型的两点改进,增加小目标检测头提升对小目标的检测效果,BiFPN使得检测准确率和定位精度更高,注意力机制融合了图像上下文信息与局部特征,让模型更聚焦图像中的目标信息。
在VisDrone数据集上进行迁移学习,图7所示为实验结果,右侧为改进的YOLOv5模型,可以看出,我们的模型输出的目标位置更加精确,误检目标减少,整体目标置信度得分也得到提升。对1 920×1 080像素的mp4格式视频进行检测时,帧速率达到25帧/s,可以满足对视频实时检测的要求。

图7 VisDrone实验结果
5 结论
通过增加目标图像细节信息,多尺度特征融合和增加大尺度检测头的方法,建立高空航拍图像数据集对模型进行训练,取得的成果主要有:
在验证集上取得了较好的实验效果,mAP提升12.6%,准确率提升10.3%,召回率提升6%改进效果明显。YOLOv5s的轻量化设计能够保证在移动端的部署,和对视频的检测。
对VisDrone数据集迁移学习后的实验结果整体目标置信度也有提升,说明改进的模型具有较好的普适性,同时也能满足对实时检测的要求。
