基于基因表达式编程的煤矿地表变形预测模型的研究与实现
2023-02-11张志伟尹文亭李彦鹏
张志伟 尹文亭 李彦鹏
(1.江西应用技术职业学院,江西 赣州 341000;2.吉安职业技术学院,江西 吉安 343000)
0 引言
目前,国际形势越来越严重,能源问题也越来越突出。煤炭作为国家的重要能源储备,合理有效地开发利用煤炭资源具有重要的战略性意义。但因早期煤炭的过度开采,引起的地表沉陷等问题也变得越来越严重,这就要对煤矿地表沉陷问题有足够的重视。
影响地表变形的因素非常复杂,如煤炭的地下开采、地质条件、地下水的分布情况等都会对地表产生影响,从而造成地表变形。因此,选取合理有效的预测方法是对地表进行变形预测的关键。现阶段,关于煤矿地表变形预测的模型有很多,但大多数都不是很理想,有的模型要用到较多的数据,有的模型误差比较大,有的模型预测精度不高。
基于此,本研究将基于基因表达式编程的预测模型运用到煤矿地表形变中,并对预测模型进行研究分析,取得了不错效果。
1 基因表达式编程
1.1 基因表达式编程
基因表达式编程(Gene Expression Programming,GEP)是葡萄牙Ferreira博士提出的一种新算法,该算法结合了GA和GP算法的优点,现阶段该算法的应用范围非常广[1]。目前,包括但不限于医药学、智能化学、预测股票、产量评估、灾害预测、测绘地理信息、经济趋势预测等,GEP都得到了成功的运用,并取得了不错的效果。但GEP预测研究模型还未涉及煤矿领域。基于此,本研究对基于基因表达式编程的预测模型在煤矿领域中的应用进行研究。
1.2 基因表达式编程算法
基因表达式编程(GEP)是一种比较年轻且高效的新型算法,关键在于其创造性地发明了能表达任何树形结构的染色体[2]。
首先,对GEP算法中一系列的基本参数进行设置,包括染色体中基因的个数、基因的长度、各种遗传算子的参数值,并通过GEP编程随机生产一个代表不同个体的初始化种群[3]。然后,利用适应度函数进行评估,判断其是否满足结束条件,如果满足,输出最优个体。否则,对种群进行重组、移位等。最后,再对新一代种群进行适应度评估,不断重复上述过程,直到找到全局最优解,即问题的最优解为止。其流程图如图1所示。
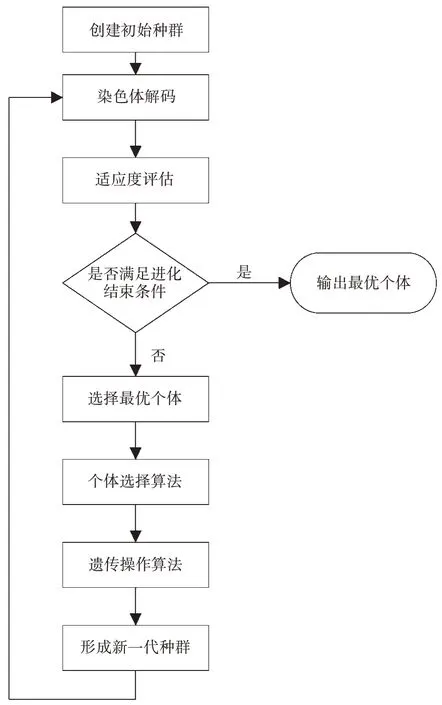
图1 GEP算法基本流程图
对构建一个变形监测预测模型,其数据处理是重中之重[4],数据的主要处理流程如图2所示。首先对变形数据进行滤波、平稳化等数据预处理,处理过的数据也就是用于建模的数据。紧接着对其执行GEP算法,通过设置参数对其进行暂停、继续等控制操作,从而得到最优个体的基因编码方式。最后将基因编码转换为对应的表达式树,得到预测模型的函数表达式。同时,利用历史观测的变形监测数据对函数表达式进行分析评价和检验,最后输出结果。并与其他变形监测预测模型进行比较分析,最后得出结论。
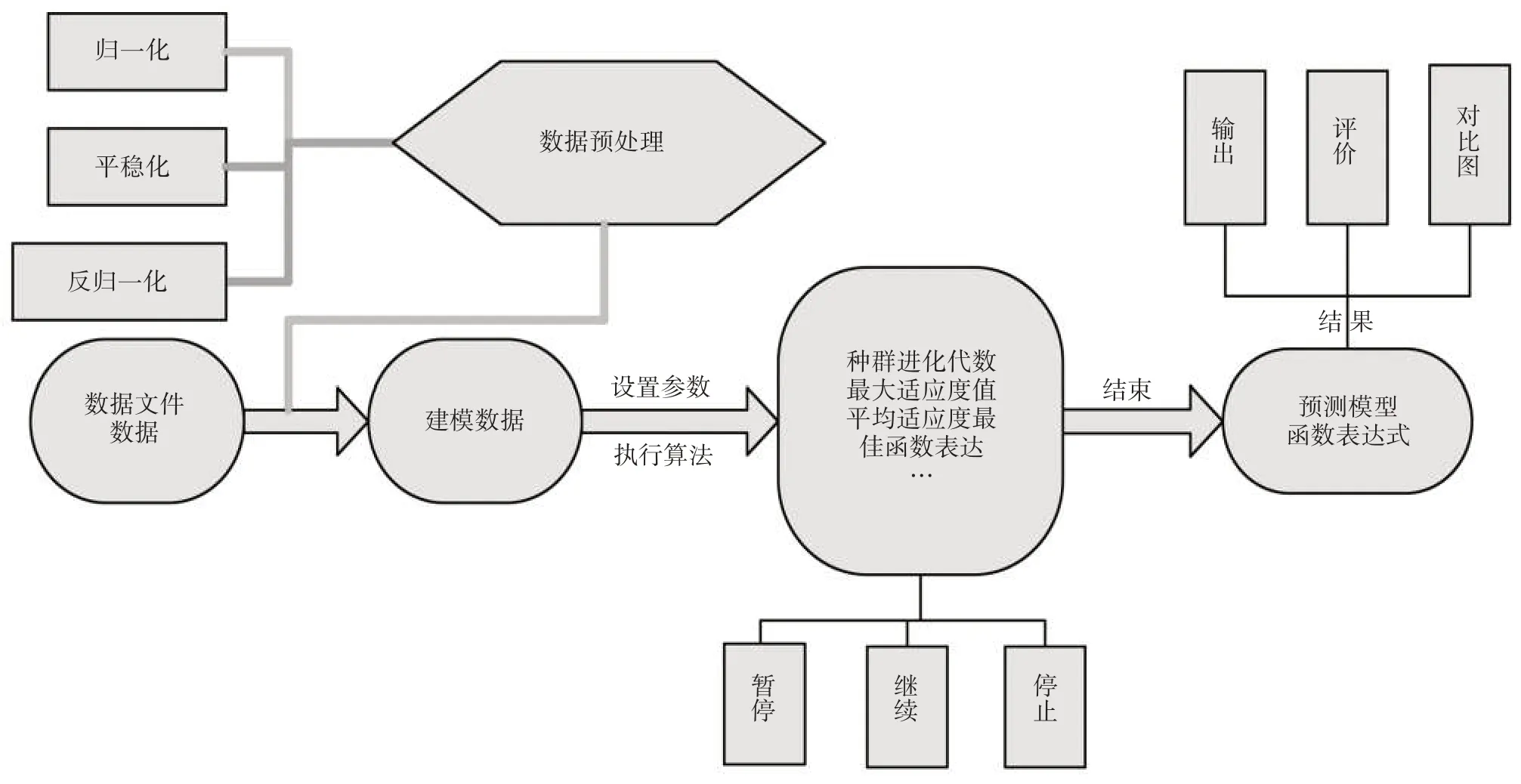
图2 GEP变形预测数据流程图
1.3 基于Fibonacci数列的加权预处理
由于影响煤矿变形的因素复杂多变,同时还有高频噪声,必须对其进行预处理[5],通过引入了Fibonacci数列对变形监测数据进行加权预处理。
假如j≤M,hj=Fibo(j)/totalweight,否则hj=0。
其中,totalweight=Fibo(1)+Fibo(2)+…+Fibo(M)。
则线性滤波的输出见式(1)。
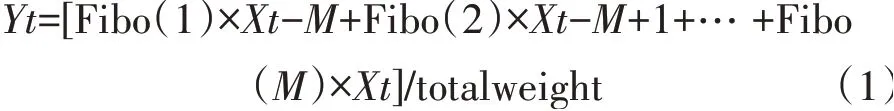
利用GEP进行预测时,M为窗口宽度w-1。
算法一:Fibonacci加权预处理规范

算法二:传统的GEP滑动窗口预测法规范性

Fibonacci加权滑动窗口预测法(FWASWPM)是对上述两种算法的结合[6],即变形监测数据经过算法一(Fibonacci加权预处理)的处理后,将其得到的预处理数据输入到算法二(GEP滑动窗口预测法)中进行GEP的滑动窗口预测,便可得到一个公式f,用f来预测未来的平均值,然后将得到的结果代入到公式(1)中,即可得到预测值。
2 实践应用
2.1 工程概况
王楼煤矿位于山东省济宁市,南北长11 km,东西宽5~13.5 km,面积约为96.08 km2,其中湖区面积为52.77 km2、陆地面积为43.31 km2。煤矿区内公路四通八达,济宁-鱼台公路自井田西部穿过,乡村级公路连接成网,另外在井田东北部有京福和日荷高速公路通过。矿区地理位置优越,交通方便。
受煤矿委托,分别沿煤矿走向、倾向布设了一条和两条观测线,总计埋设了106个观测点。从2012年7月2日到2013年12月12日共进行了25次变形观测,得到原始的变形监测数据,为研究工作提供可靠的基础数据。其中,倾向线一的最大沉陷值是22号点的400 mm,倾向线二的最大下沉值是24号点的369 mm,走向线三的最大下沉值12号点的407 mm。本研究选择下沉值最大的走向线三12号点为研究对象,其他各点利用类似方法进行预测分析。其中,垂直位移用的是S2型水准仪,平面位置变形观测采用尼康2″级830型全站仪。
2.2 基于GEP的煤矿地表变形预测模型的建立
2.2.1 数据处理。对数据的处理是能否建模成功的关键[7],本研究利用Fibonacci数列对变形监测数据进行加权预处理。其中,用于建模的数据是观测点变形最大的12号点,总计25期的原始观测数据。利用前20期数据进行建模,后面5期进行模型精度检验,如表1所示。
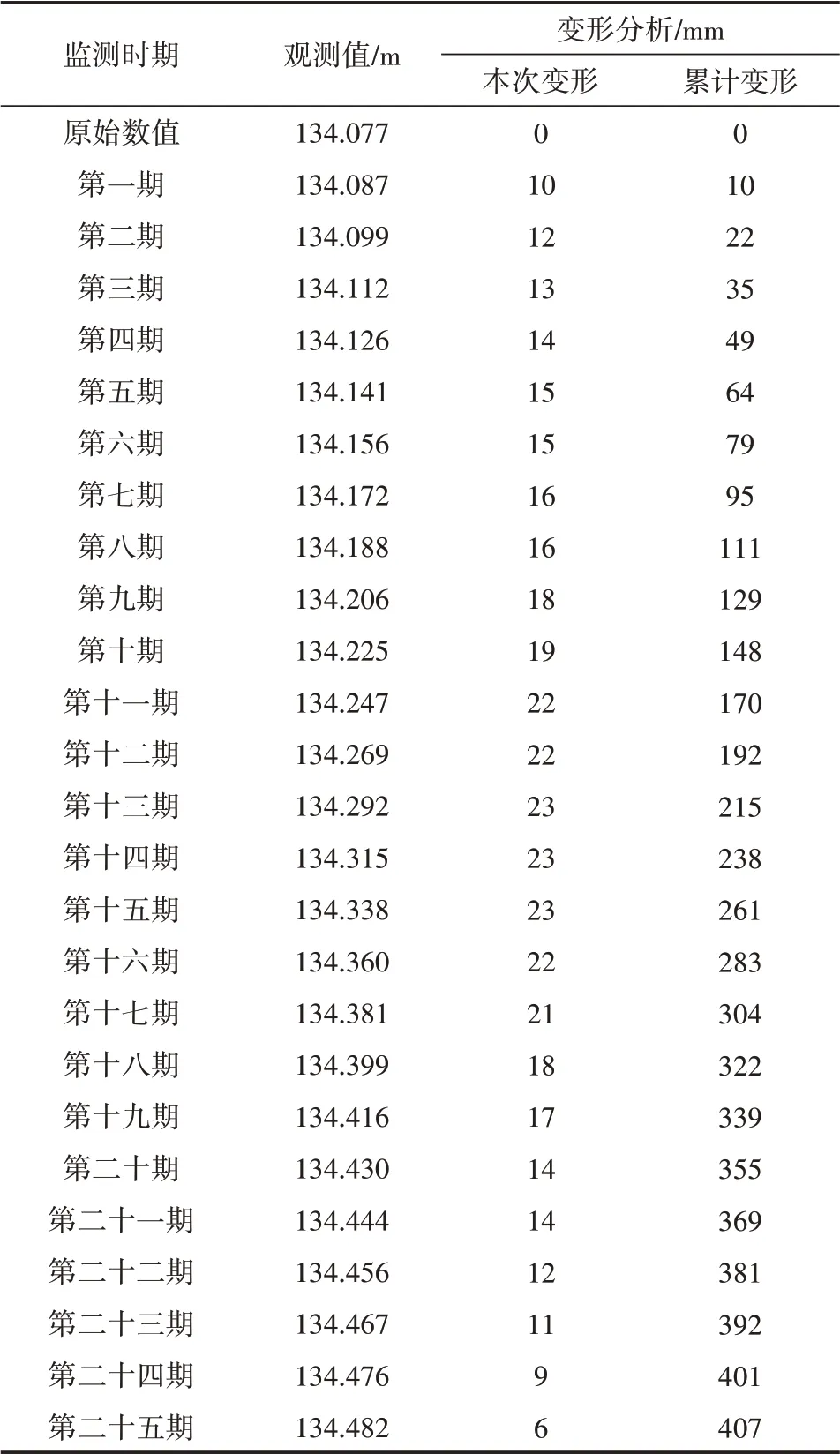
表1 原始观测数据
2.2.2 种群的初始化。模型必须有一定数量的初始化种群,种群的初始化实际上是确定GEP中的函数集合(F)和终结符集合(T)[8],一旦得到来自F和T的符号,就可随机产生初始种群的染色体。即基因的头部可用F和T中的元素,而基因的尾部则只能使用终点符号[9]。本研究选取的函数集合(F)为基本的数学函数{+,-,×,/,sqrt,exp,sin,cos},设定终结符集合(T)为滑动窗口大小一致的五个数据组成,分别用来表示。确定了函数集合和终结符集合后,染色体结构可使用函数集和终点集的符号随机产生,不用其他东西来监控结构的完整性。由此,完成了种群初始化的工作。
2.2.3 GEP各种参数设置。在预测模型建立前,要对初始化种群进行一系列的遗传操作[10],这就要求必须对遗传操作的各种参数进行有效的设置,从而能更快、更精确地得到预测模型的函数表达式,建立准确的变形监测预测模型。本研究设置的遗传基本参数见表2。

表2 遗传操作参数设置
2.2.4 适应度函数。适应度函数的选取至关重要[11],本研究选取的适应度函数见式(2)。
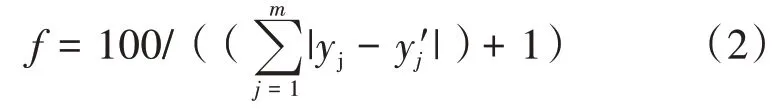
式中:f为适应度函数;yj为观测数据;yj'为利用表达式得到的yj的估计值。
2.2.5 预测函数模型发现。基于此,本研究利用C#语言进行编程,并对建模的前20期数据进行种群初始化,在此基础上进行一系列的遗传操作[12],然后对其进行适应度评价,选出优势个体继续进行适应度函数值比较,直到得到最优个体,从而得到预测模型的函数形式,然后利用最后五期的数据对模型的准确度进行检验、评价,得到最终的变形监测预测模型。本研究建立的基于GEP的煤矿地表变形预测模型的窗口应用程序如图3所示。
图3 预测模型窗口设计
2.3 结果分析
利用建立的模型对后五期变形值的预测步骤如下[13]。先利用第十六到第二十期的数据分别代表从而预测出第二十一期的数据值,利用第十七到二十一期数据预测第二十二期数据,依次类推,最后得到基于GEP的预测模型后五期的预测值如表3所示。

表3 GEP预测模型数据对比表
为了能更好地检验其预测的精确度、准确度,对后五期预测值的绝对误差和相对误差进行计算,如表4所示。
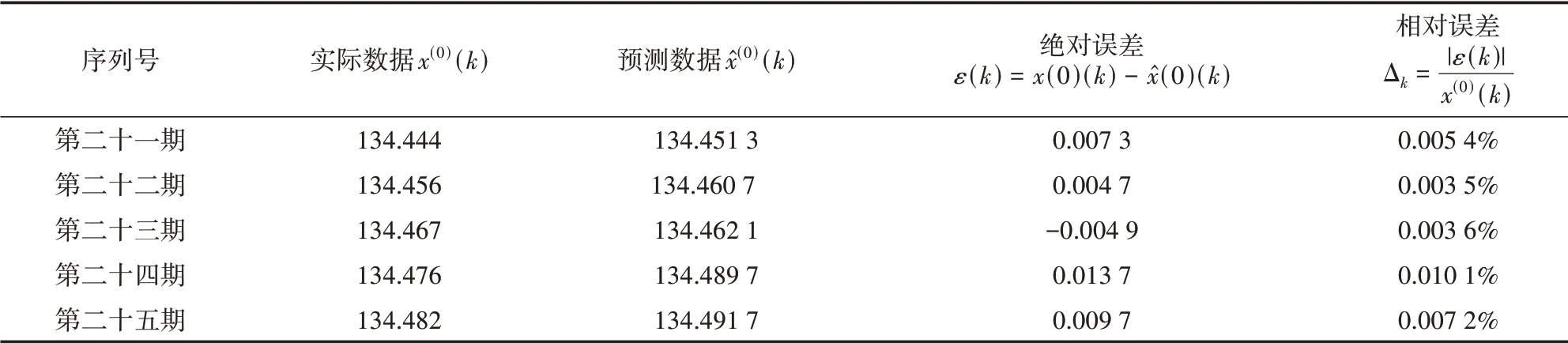
表4 GEP预测模型后五期预测值和误差
结合表4,得到基于GEP的煤矿地表预测模型预测值和实际值的对比图,如图5所示。其预测值在实际值附近波动,由此能更好地对煤矿地表变形进行预测分析。
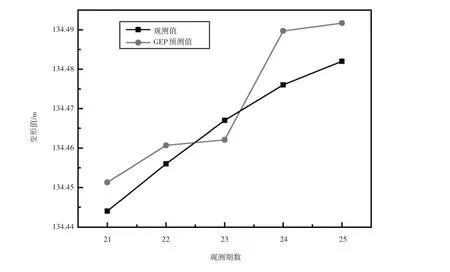
图5 GEP预测模型变形预测对比图
综上所述,在基于煤矿地表变形数据有限的基础上,利用GEP进行变形预测是可靠的,GEP的一个优势是能采用较小的种群规模去解决较为复杂的问题,且其预测的数值在实际观测值上下浮动,具有一定的可靠性。
3 结语
本研究针对煤矿地表变形数据具有高频噪声的特点,利用Fibonacci加权滑动窗口预测法对其进行预处理,结合GEP编程的优点,建立基于基因表达式编程的煤矿地表预测模型,并对最后5期的数据进行预测分析,取得了较好的效果,说明预测模型具有较好的可靠性,为煤矿地表的变形预测提供一个较好的方法。
