NLP 在智能消防接处警系统中的应用研究
2023-02-10雷兴豪
雷兴豪,董 雷
(1.武汉邮电科学研究院 湖北武汉 430000;2.武汉理工光科股份有限公司,湖北 430000)
随着我国城镇化进程的加快,城市灾害呈现出增长的趋势,城市展现出极大的脆弱性。为尽快适应和应对“全灾种、大应急”的需要,同时也为了适应当前信息化、智能化时代下的接处警需求,消防智能接处警系统中运用自然语言处理技术,根据接处警数据,对警情信息中的关键信息进行识别。结合云计算、大数据分析技术,有利于消防警务人员快速定位真实案情,避免假警,从而使消防救援资源得到合理分配,同时提升消防部门的快速响应能力与作战能力。现阶段,①现有接处警系统警情信息录入以及力量调派效率偏低,接警员仅能手动选择资源力量,手动录入警情信息,在高强度接警压力下容易出现调度资源分配不合理的情况;②警情定位信息缺失,受当时技术条件、支撑环境的影响,定位手段单一,部分位置信息仍是系统默认值或与实际位置偏差较大,无法保证位置信息的有效性和准确性,影响处置效率;③接处警人员在高强度作业下,可能会出现关键信息未询问,某些可辅助决策的信息未记录等问题[1]。因此,采用自然语言处理、机器学习等技术进行警情信息提取,可提高消防部门的接警效率,具有重要意义。
近年来,具有强大特征提取能力、较低人工依耐性、较强泛化性的神经网络在众多领域都有广泛的应用,其中,在命名实体识别领域中,常见的有BiLSTM-CRF[2-4]模型、GRU-CRF[5-7]模型,这两种模型考虑了句子上下文信息,使得词向量包含了语义信息,GRU 参数少,训练速度更快。但在中文命名实体识别任务中,以上模型都难以表示词的多义性,为此,文中提出了预训练模型的新方法,该方法既包含多样化的语义和句法信息,又包含了上下文信息,因此,提出一种基于ALBERT[8]预训练模型应用于警情要素实体识别任务中;构建了ALBERT-BiLSTMCRF[9-12]模型,通过与BERT 模型对比进行实验发现,基于BERT[13-15]的模型在识别准确率上略高于ALBERT 模型,但是在接处警场景中需要综合考虑训练速度、预测速度、警情要素实体识别的准确率、召回率和F1 值,ALBERT 也能取得相对很好的效果。
1 相关工作
截至目前,国内将自然语言处理技术运用于消防接处警系统中的案例较少。林晓冬[16]提出结合自然语言处理的文本相似度分析等算法模型,提出以机器学习的方法代替人工分析,利用相似度等算法对警情数据进行分析。消防警情文本没有公开的语料库,使用的语料数据是在现有湖北省消防警情信息系统的基础上自行构建的部分数据集,又通过爬虫工具爬取某网站上关于近些年部分有关消防警情的报道信息,以此构建了消防警情领域的数据集,构建步骤如下[16]:
1)数据预处理,利用正则表达式从某地强降雨出动情况汇总表中剔除文本中含有的空格以及多余的语句,从而提取出符合消防警情文本要求的字段,再利用网络爬虫技术爬取某网站相关警情报道信息,对其做同样处理。
2)实体类别的确立,文中实体为五类,分别为警情地点、组织机构、事故车辆类型,事件类型、燃烧对象。考虑到地点信息较多,文中利用开源COCONLP工具提取句子中的地点信息,构造关于地点的字典,关于事故车辆类型、事件类型、燃烧对象类型较少,可考虑手动创建。
3)标注体系,实验所用标注体系为BIO(实体联合标注的一种标注方式),其中B 为命名实体开始部分,I 为命名实体中间部分,O 为非命名实体部分。标注方案如表1 所示。

表1 标注方案
4)利用数据增强计算对消防警情文本数据集进行数据增强,实体增强后的数据如表2 所示。

表2 增强后各类型数量
2 ALBERT-BiLSTM-CRF模型
针对消防警情文本数据集,构建了ALBERTBiLSTM-CRF 模型,该模型先由ALBERT 预训练模型得到各序列文本中字词的表征向量,该词向量融合了通用领域内的语义信息,再输入到BiLSTM(双向长短词记忆模型)层,BiLSTM 层可以获得句子语义编码,再通过CRF(条件随机场)层进行解码,依据标签之间的合理性关系得到消防警情文本实体信息最优的标记序列。模型结构如图1 所示。
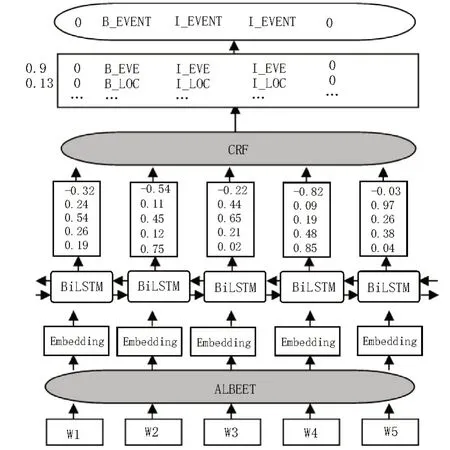
图1 ALBERT-BiLSTM-CRF模型结构
2.1 ALBERT模块
BERT 采用具有强大特征提取能力的双向Transformer 在大规模通用领域语料库上训练得到的预训练模型,再针对下游具体的NLP 任务进行微调,BERT 在设计时已经针对多种不同的NLP 任务,融合设计了遮蔽语言模型和下一句预测模型,在捕捉到词法特征和句子级别特征的同时,还能对各个位置单词进行并行处理计算,在多个下游NLP任务中都取得很好的效果。BERT 预训练模型结构如图2所示。

图2 BERT预训练模型结构
ALBERT(A Lite BERT)与BERT 类似,其参数相比同级别的BERT 模型参数要少的多,ALBERT 对BERT 进行了三种优化[17-18],分别为:①因式分解嵌入层矩阵(Factorized Embedding Parameterization);②跨层参数共享(Cross-layer parameter sharing);③用NOP 代替BERT 中的NSP。
在实际消防接处警场景应用中,需要考虑模型的预测速度、训练速度,所以考虑将ALBERT 模型应用到消防警情文本信息抽取上。
2.2 BiLSTM模块
LSTM是RNN(Recurrent Neural Network,循环神经网络)的一种特殊类型,由Hochreiter和Schmidhuber[19]提出。LSTM 是在RNN 的基础上改进而来的一个模型,其缓解了传统RNN 训练时产生的梯度消失问题,且能捕捉到较长距离的依赖关系,非常适合用于对时序数据建模。LSTM 计算过程如图3 所示。
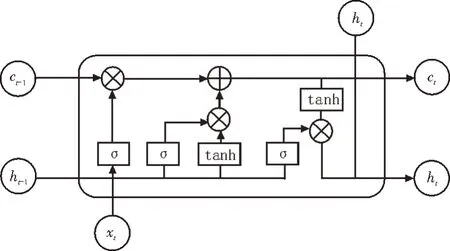
图3 LSTM的计算过程
LSTM 计算包括以下三个部分。
1)遗忘门:选择需要丢弃的信息,输入为前一时刻隐藏层状态ht-1和当前输入词xt,计算公式如式下:
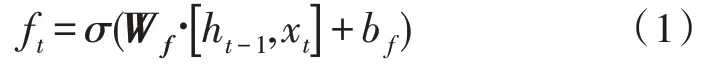
其中,Wf和bf分别为权重矩阵和偏置项,σ为激活函数。
2)记忆门和当前单元状态:通过选择需要保留的信息,对当前单元状态计算,为临时单元状态,ct-1为上一时刻的单元状态,输出为当前时刻单元状态ct,计算过程可表示为:
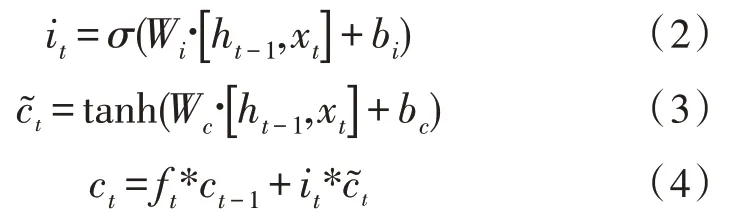
3)输出结果和当前隐藏状态:当前时刻输入词为xt和当前时刻单元状态为ct,输出为输出门的值和当前隐藏状态,计算过程为:
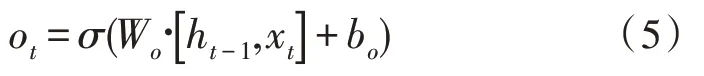

从LSTM 计算过程中可知,单向LSTM 神经网络模型只能对历史信息进行记录,进行序列标注任务中的单个字或者词与所在句子的上下文信息都有关,Bi-LSTM 神经网络模型,就是将前向LSTM 和后向LSTM 隐藏层都连接到同一个输出层[20-21],得到拼接后的字向量ht=这样可以在命名实体识别任务中取得更好的效果。
2.3 CRF模块
由于BiLSTM 模型对于每个词标签的输出概率是独立的,不具备学习文本实体各个标签之间转移特征的能力,可能会出现一个句子中相同的标签相连接,而CRF 和LSTM 结合就可以考虑标签之间的顺序性,以获得最佳的标签序列。对于每一个序列,即每一个句子,X={x1,x2,x3,…,xn} 表示无序字符序列,y={y1,y2,y3,…,yn} 表示句子的标签序列,最优标签序列计算公式如下:
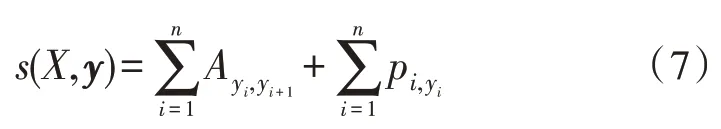
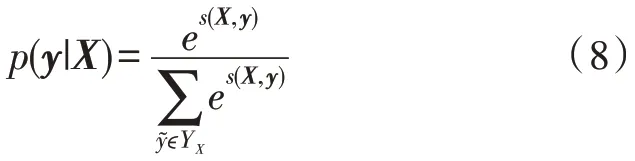
其中,YX表示输入序列X所有可能出现的序列观测值的集合,表示实际真实的标记值,该标记序列的似然函数为:
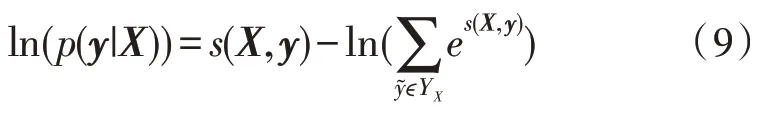
文本序列的最大化标签序列输出的概率用式(10)表示:
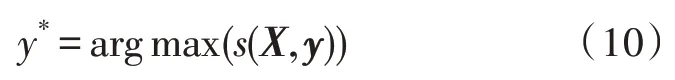
3 实验及结果分析
3.1 评估指标
该实验采用自然语言处理中的通用评价标准,即准确率P(Precision)、召回率R(Recall)和F1(F1-measure)三个指标对消防警情文本信息提取结果进行评价衡量,计算公式分别为:


3.2 实验设置
警情要素提取数据集包括地理位置信息、组织机构名称、车辆类型、事件、燃烧物五类命名实体,将数据中的60%作为训练集,20%作为验证集,剩下的20%作为测试集ALBERT 版本为albert_tiny 版本,参数量为1.8 MB,ALBERT 模型的最长序列长度选择为512,优化算法为Adam 算法,学习率为0.001,batch_size 为8,LSTM 隐藏层单元为100 个,dropout 为0.5,MAX_SEQ_LEN=128,epoch 为100,Gradient_clip 为5,结果为多次实验取得。BERT 版本为BERT 的中文预训练模型,参数量108 MB,其中batch_size为128,LSTM 隐藏层单元为200 个,其他参数同ALBERT。
3.3 实验结果与比较
ALBERT-BiLSTM-CRF 模型和BERT-BiLSTMCRF[16-17]模型训练的F1值如图4所示。其中,ALBERT模型在67 个epoch 时F1 值最大为81.660%,而BERT模型在28 个epoch(对应图中的count)时F1 值最大为82.130%。
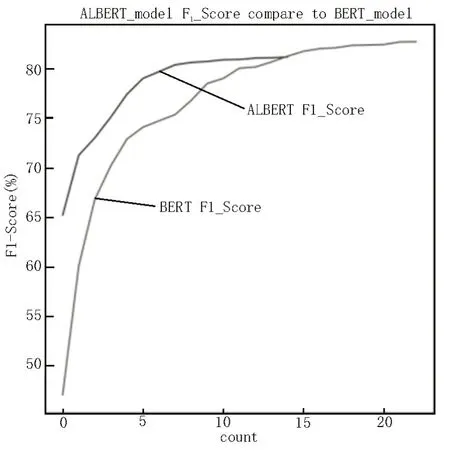
图4 ALBERT-BiLSTM-CRF模型和BERT-BiLSTM-CRF模型的F1值曲线
在测试集上的loss 曲线如图5 所示,可以看出BERT 模型在28 个epoch 时已经降到最低,ALBERT经过67 个epoch 趋于稳定,波动很小,说明该模型对警情文本识别效果良好;同时可以看出,ALBERT 模型和BERT 模型的loss 差距很小。两模型的训练时间及预测速度对比如表3 所示,ALBERT 模型的训练速度是BERT 模型的10 倍,预测速度是其2 倍。由图4、5和表3可知,在接处警系统中采用ALBERT模型也能有较好的效果。警情要素识别效果如图6所示。
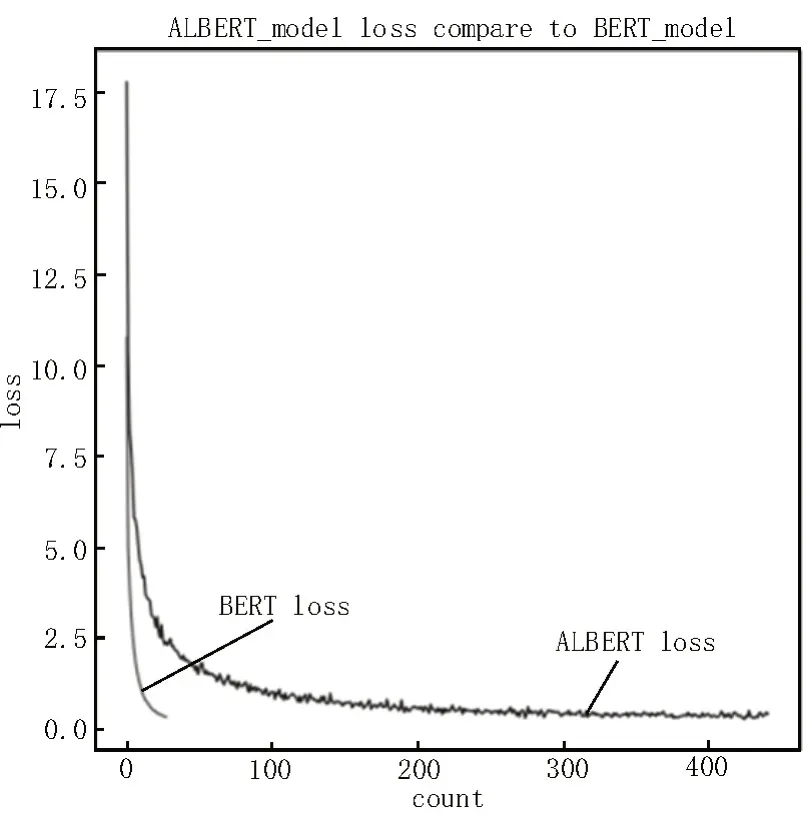
图5 Test_loss曲线图

图6 警情文本识别效果

表3 模型对比
经上述实验,五类实体的准确率、召回率、F1 值如表4 所示。
从表4 中可以看出,事件、车辆、燃烧物实体的准确率较高,而组织机构名称和地理位置信息可能存在大量的缩略词以及歧义等干扰信息[22],在没有较大规模的数据集时,预测的难度稍大,准确率较低。

表4 不同类型命名实体识别结果
4 结束语
针对消防消防警情文本,提出基于ALBERT 预训练模型的ALBERT-BiLSTM-CRF 深度学习模型,并对消防警情文本采用数据增强技术,对比了基于BERT 中文预训练模型的BERT-BiLSTM-CRF 模型,在消防警情要素实体识别任务中取得较好的结果,F1 值为81.660%,说明消防警情文本实体识别可以提高接处警的效率。由于该领域需要对语音信息文本进行快速提取,对于警情文本实体识别任务,需要较快的预测速度,ALBERT-BiLSTM-CRF 模型的F1 值仅比BERT-BiLSTM-CRF 模型小5%左右,而ALBERT-BiLSTM-CRF 模型预测速度是BERT 模型的2 倍左右。同时由于该模型训练参数量少,训练速度为BERT 模型的10 倍左右,因此可以大大减小时间开销。ALBERT 模型和BERT 模型都需要一定规模的数据来训练,针对数据量不足、实体类别少的问题,未来会考虑扩充数据集,通过标记更多的命名实体参与训练,进一步提高准确率,同时在接处警系统中提升接警效率。
