GA−CFS结合案例推理的轴承故障诊断
2023-02-09李长伟雷文平董辛旻李永耀
李长伟,雷文平,董辛旻,李永耀
(1.郑州大学机械工程学院振动工程研究所,河南郑州 450001)(2.郑州恩普特科技股份有限公司,河南郑州 450001)
1 引言
在基于轴承振动信号的故障诊断方法中,大多数是基于知识规则的,发展得也较为成熟。但这些诊断方法依然存在一些难以克服的缺点,比如知识的获取较为困难,知识规则库的维护较为复杂等。为了解决这些问题,引入CBR技术。CBR是运用历史上发生过的事情来解决新出现的问题、理解新情况的一种新兴人工智能方法学,是不同于基于知识推理的一种学习模式[1]。CBR比较擅于解决知识缺乏、不便建立模型、存有大量规则之外的结构化或者半结构化的问题。因此利用CBR方法做轴承故障诊断具有较高的应用价值,并且CBR系统解决问题的能力也会随着案例库的扩展而提升,具有较好的成长性。
作为CBR技术核心模块的案例库,对故障诊断结果有着决定性的影响,为了获得较好的案例库模块,则需要对其进行优化。案例库主要是由各个子案例组成,案例库的优化即是对子案例的优化,子案例主要有其属性特征来表征,则最终的优化目标即是对属性特征的优化。
在属性特征优化方面,文献[2]采用Filter 结合Wrapper 的特征选择方法解决特征冗余问题,虽然结合了两者的优点,但计算过程繁琐,耗时较长;文献[3]在特征选取中提出了一种CFS 方法,该方法拥有Filter 和Wrapper 的优点,不仅计算速度快而且还适用于离散型和连续型数据;文献[4]在CBR系统中采用GA算法实现了特征权重优化问题,并取得了一定的效果;文献[5]在语音的识别系统中运用GA−CFS 方法解决特征约减问题,并证明了其可行性。因此,这里在案例推理轴承故障诊断中引入了GA−CFS方法,并利用XJTU−SY 滚动轴承加速寿命试验数据验证了该方法的可行性[6]。
2 基本原理
2.1 案例推理技术
CBR 是将新出现的问题称作目标案例,而将历史上出现的问题称作源案例。CBR先是将已经解决过的目标案例化作源案例,再转过来由源案例指引新的案例求解的一种方法。Kolodner在1983年领导研发了基于案例推理的CYRUS系统,随后在不同领域又产生了PROTOS、HYPO 以及CABARET 等基于案例推理的应用系统。目前CBR过程主要分为4个阶段:案例的检索、复用、修改和保存[7]。当有新案例产生时,基本过程,如图1 所示。首先,要求出案例的特征;其次,在已经利用GA−CFS方法构建好的案例库中使用KNN 算法计算源案例与目标案例之间的相似性,根据两者之间的相似度启用案例的重用或修改或保存机制,最终得到源案例的解。
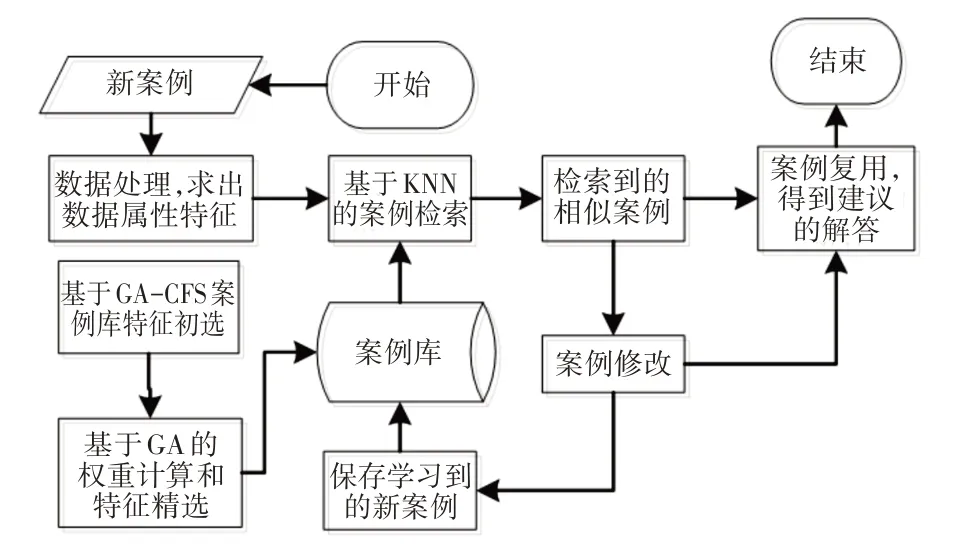
图1 基本流程Fig.1 Basic Process
2.2 相关性特征选择方法(CFS)
CFS是一种关于属性子集价值的启发式评价算法,该算法用于评估特征子集的价值或优点,考虑了单个特征与预测类别标签之间相互关联度。CFS的核心思想有两个方面[3]:(1)优良特征子集与类别标签高度相关;(2)优良特征子集的属性特征彼此之间不相关。该方法计算速度快,不仅适用于离散型的数据还适用于连续型的数据,其属性子集评价函数如下:

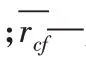
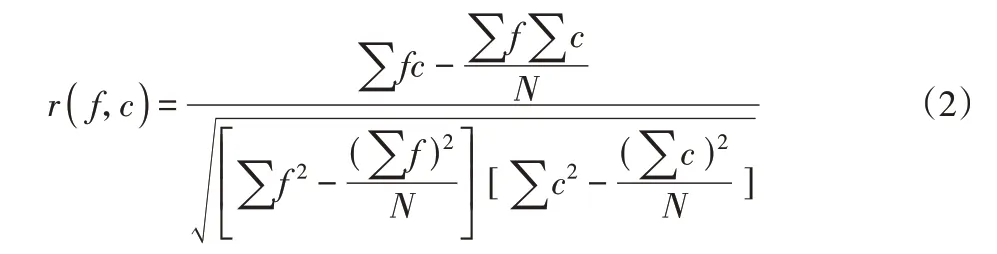
式中:r(f,c)—各个属性特征f与类别c之间的相关系数;N—的是样本总数。属性特征彼此之间相关性系数也适用式(2)。r(f,c)的绝对值越大,说明f和c的相关程度越好,当r(f,c)的绝对值接近于0,则认为f和c之间相关性弱或者完全无关。
2.3 K邻近分类算法
在1961 年Johns 首次将K近邻算法使用在分类问题中,在1967年文献[8]提出K近邻算法,该方法简单有效,也是应用较为广泛的模式识别算法之一。该算法的原理是:假设已经存在一个案例集,当有新案例时,在该已有案例集中找到与新案例相似性最大或者距离最小的K个案例,若这K个案例中的多数均属于某个类别,就把该新案例归为该类别。
对案例推理技术来说,KNN算法的重要性在于以下几方面:
(1)该算法是基于距离的相似性计算方法,简单易于实现,且具有较好的分类性能;(2)该算法给出了案例与空间之间的映射关系;(3)该技术和其他技术融合的能力非常强。
2.4 GA-CFS的属性特征筛选
遗传算法是一种搜索方法,该方法仿照了自然界的自然选择和自然遗传机制[9]。该方法首先通过计算当前群体的最适应值,再根据该值生成新一代群体,通过这样的方法不断的压缩搜索空间,进而找到或者近似找到搜索目标。
筛选过程,如图2所示。

图2 遗传算法基本流程Fig.2 Basic Process of Genetic Algorithm
具体步骤如下[10]:
(1)将参数特征进行编码,染色体长度等于属性特征个数,染色体基因为1时表示选中该属性特征,染色体基因为0时表示未选中该属性特征;
(2)定义适应函数,引入CFS方法,将CFS的计算结果作为适应值;
(3)设定遗传策略,分为设定群体大小,选择、杂交和变异三个遗传算子,确定变异概率和杂交概率等,根据经验设置以上参数的取值范围:群体规模(20~200)、杂交概率(0.6~1.0)、变异概率(0.005~0.1)、选择策略为轮盘赌方式;
(4)设置初始化群体,随机生成一个初始种群,种群规模一般设定在(100~200)之间,并且以最大迭代次数作为停止条件;
(5)计算每个个体适应值;
(6)按照遗传策略,对群体进行遗传操作,生成新一代群体;
(7)判断是否满足要求,或者达到预定迭代次数,否则就返回(6),重复操作,直到满足要求为止。
2.5 GA加权的KNN算法
经过GA−CFS初步筛选后得到了一组优良属性子集,现需要求解各个属性子集中的特征权重,并从该组属性子集其中选出符合要求的子集,实现过程为:利用GA算法实现特征子集的权重计算和选择,GA步骤同1.4,不同之处为:(1)染色体的基因编码采用(0~1)之间的浮点数,表示特征权重大小;(2)采用轴承的诊断准确率为适应度值,该准确率是由加权后的KNN算法得出。最后依据属性子集的诊断准确率得出符合要求的属性子集。
3 分析验证
3.1 案例库的属性特征选取
利用XJTU−SY滚动轴承加速寿命试验数据建立案例库验证这里的方法。该数据包含了3种工况下15个滚动轴承的全寿命周期振动信号,试验滚动轴承型号LDKUER204,采样频率25.6kHz,采样间隔1min,采样点数32768。CBR的案例库中含有1680个轴承案例,其中包含外圈故障案例751个、内圈故障案例167个、保持架故障案例247个、内圈故障和外圈故障共存的案例18个和四个部位故障共存的案例297个,以及正常案例200个。利用文献[11]中的全矢谱技术融合这些双通道数据,得到融合后的时域振动数据和主振矢数据。
在已选择的1680个案例中,分别在时域振动信号和主振矢中提取9个时域特征和11个频域特征[2]。此20个特征的排列顺序依次是峰值、均方根值、峭度、波形因子、脉冲指标、裕度指标、峰值因子、绝对均值、标准差、转频幅值、频域峰值、频域均值、频域标准差、频域均方根值、频域峭度、频域波形因子、频域脉冲指标、频域裕度指标、频域峰值因子、频域重心,即特征序号从(1~20)。
在已选择的20个特征中必定存在特征冗余,这些特征与分类标签相关性差,可能存在反作用,降低分类准确率。依照上文20个属性特征的排列顺序,求出在属性特征个数依次累加时所对应的准确率。如图3所示,可以看到含有不同个数特征时准确率有高有低,充分说明该组属性特征存在冗余性,需要对其进行优化处理。采用GA−CFS方法对属性特征进行粗选,其中种群规模为100,交叉和变异概率分别为0.9、0.1,最大停止迭代次数200。经过计算得到一组属性特征子集及其与类别标签的适应度值。每迭代一次得到一个最优特征子集,被选中的特征在图4中用“*”表示,未选中的特征用空白表示,每一代筛选出的属性子集所对应的适应值,如图5所示。从所筛选出的第23代到200代的特征子集的适应度值保持稳定不变,因此选择前24代特征子集,如图4所示。其中不相同的特征子集共有7个,分别是第1、2、4、5、6、7、23代特征子集。该组特征子集中的关键特征存在差异性,也说明了构成案例库的各个案例存在差异性,且特征之间也并非相互独立。
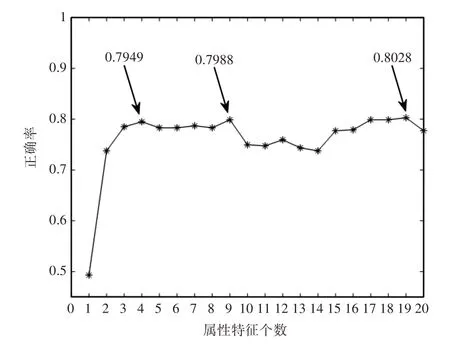
图3 特征个数所对应的正确率Fig.3 The Correct Rate Corresponding to the Number of Features

图4 特征子集筛选Fig.4 Feature Subset Screening
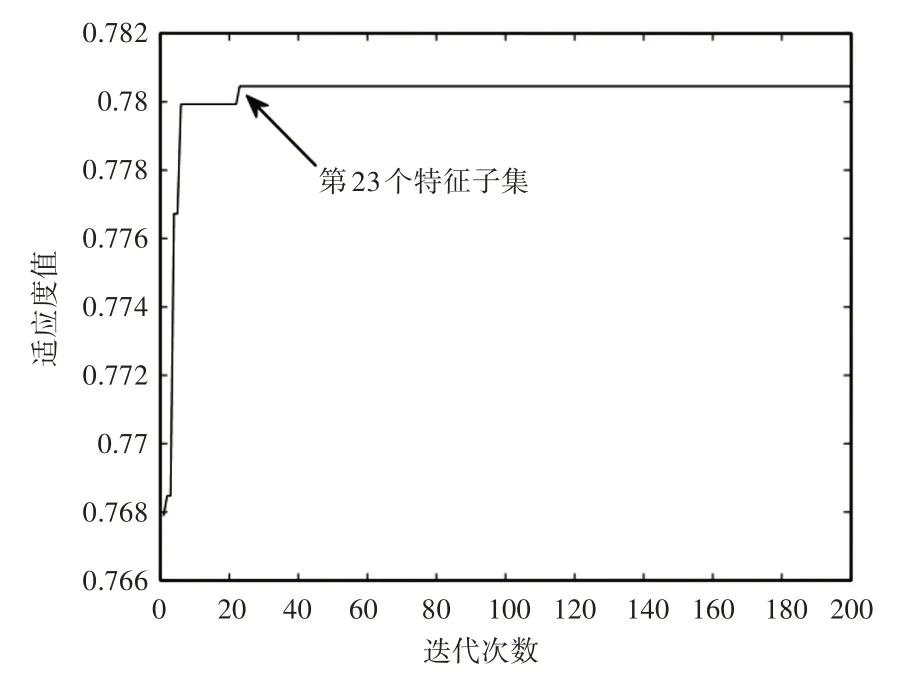
图5 特征子集与其适应度值Fig.5 Feature Subset and its Fitness Value
针对初选的7个特征子集的权重问题,选择GA算法,采用诊断准确率作为适应值,对特征子集做进一步筛选,其中最大迭代次数为200,种群规模为100,交叉和变异概率分别为0.9、0.1。对每个子集的诊断正确率求解10次,然后求取平均正确率,最终结果,如表1所示。在未匹配权重时,经过特征约减后的诊断正确率不仅高于原始子集的正确率,而且特征个数减少至一半以下;在匹配权重之后,各个子集的平均诊断正确率均超过93%。说明在分类计算中进行特征约减和匹配特征权重不仅可以较大程度的降低计算时间,而且可以显著提高诊断正确率。关于特征子集的选择,根据表1对比情况,按照计算时间和准确率的实际需求确定。这里在案例库构建中选择第23代属性特征子集,准确率为0.9373,且特征个数最少。其包含7个属性,分别是波形因子、峰值因子、转频幅值、频域均值、频域波形因子、频域脉冲指标、频域峰值因子。
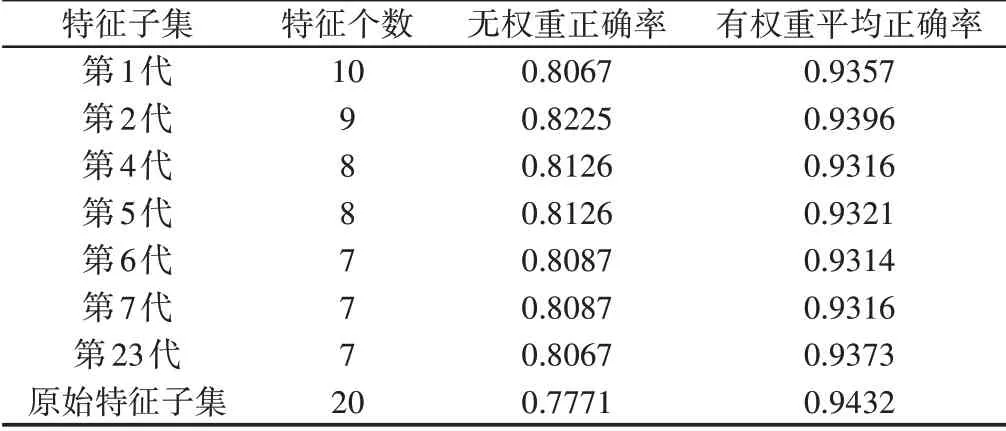
表1 属性特征子集正确率对比Tab.1 Comparison of Attribute Feature Subset Correctness
3.2 GA-CFS结合CBR的轴承故障诊断
这里采用mycbr 建模平台搭建案例推理的故障诊断系统。按照GA−CFS和加权KNN方法,把选好的7个关键特征及权重录入系统的属性设置界面,属性值设置为true,其他属性值设置为false,并选择欧氏距离作为相似性计算方法,如图6所示。
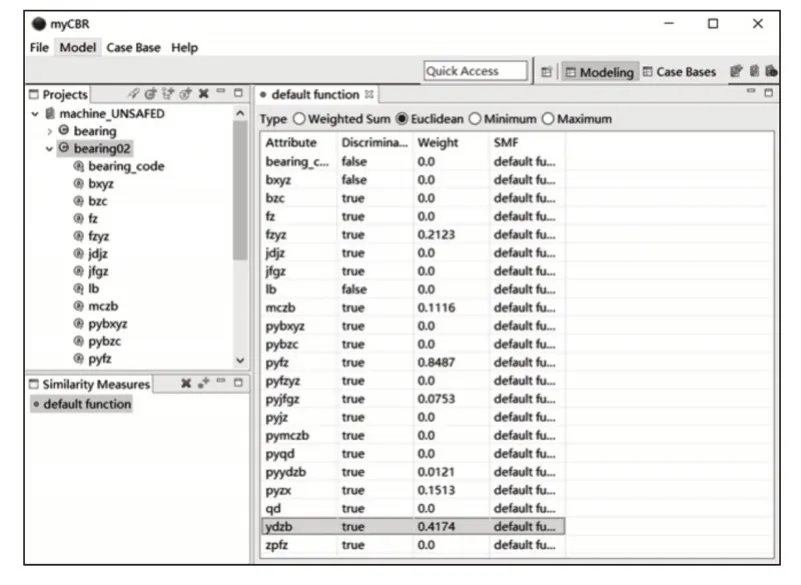
图6 特征选择和权重匹Fig.6 Feature Selection and Weight Matching
然后将这1680个案例录入到案例库中。当有新案例时,求出目其关键特征,填入检索界面,如图7所示。即可以求解出新案例与源案例的相似性,根据相似性是否超过预设的阈值,即可判断是否启用案例重用、修改或者存储机制,得出新案例的解。
图7 案例检索Fig.7 Case Retrieval
4 结论
这里提出了一种GA−CFS结合案例推理的轴承故障诊断方法,设计了GA、CFS和KNN特征选择策略,并运用XJTU−SY滚动轴承加速寿命试验数据搭建诊断系统。该方法不仅获取故障知识容易,而且优化后的特征子集冗余性低。此外,通过GA加权的方式提高了KNN算法的诊断准确率。最终通过实验验证,分类准确率超过了93%,证明了该方法的可行性。
