基于决策树算法的专利无效宣告风险特征识别
2023-02-08彭启宁柳炳祥付振康冯广宇
彭启宁 柳炳祥 付振康 冯广宇

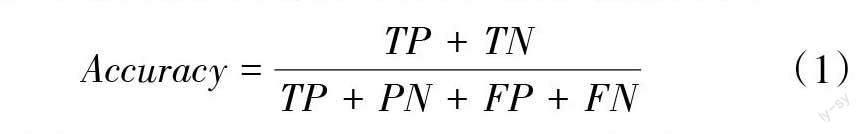
关键词:专利;无效宣告;风险识别;预警体系;决策树
中图分类号:G306 文献标识码:A DOI:10.3969/j.issn.1003-8256.2023.06.002
0 引言
专利是反映科技创新成果的主要客体,是知识产权的重要部分之一,专利无效宣告是保护自身知识产权的重要手段,专利无效宣告的判定已经成为学术界和实务界共同关注的热点,加强专利诉讼和专利侵权研究具有重大意义。近几年,专利申请数量不断增加,专利侵权和专利无效宣告发生的案件数量不断增长。刘蕾[1]认为无效宣告制度有助于纠正专利审查机关的不当授权。与此同时,与之相关的程序和制度等问题更加凸显,倪静[2]认为目前我国专利宣告程序仍然存在程序拖延、冗长,权利无法得到及时救济等突出问题;李新芝等[3]认为我国对专利无效程序中专利文件的修改要求不利于专利权人利用无效宣告程序充分完善其专利文件。根据“十四五”规划[4]中所提出:要着眼于抢占未来产业发展的先机,重点关注和培育先导性和支柱性产业,聚焦新一代信息技术、生物技术、新能源、新材料、高端装备、新能源汽车、绿色环保以及航空航天、海洋装备等新兴产业。因此,构建一套科学的专利无效宣告预警体系,促进新兴产业的发展,进而识别出易发生无效宣告的专利,对于提高我国相关创新主体的创新能力以及研判产业发展方向具有重要意义。
本文以侵权专利为切入点,提出构建专利预警指标体系这一研究问题。在综合分析专利诉讼风险特征影响因素的前提下,结合专利无效宣告的特点,从经济质量、法律质量及技术质量三个维度选取反映专利状况的指标,构建专利无效宣告的风险识别体系,得出导致专利发生无效宣告的指标影响程度排序,进而建立较为精准的专利无效宣告预警指标体系。
1 研究现状
1.1 无效宣告相关研究
经阅读文献可以发现,目前国内对于专利无效宣告的研究主要集中在以下几方面:首先是在法学领域,主要是针对专利无效宣告制度的特点进行一系列讨论,例如李晓鸣[5]指出我国专利无效宣告制度的不足之处,认为相关法律法规对无效宣告各类程序的期限规定不完善并提出一系列完善建议;王瑞龙[6]指出了侵权诉讼中专利权无效抗辩制度弊端,认为专利无效抗辩制度导致专利侵权诉讼周期长并提出了解决方法。但上述文献主要涉及无效宣告判别的各类程序,未涉及导致无效宣告发生的指标研究。其次是经济学领域,主要是针对专利无效宣告对经济市场份额影响进行一系列研究,例如Clifton D J[7]讨论了专利无效宣告与市场份额的关系,认为专利无效宣告倾向与专利市场份额增长率呈正相关,专利的市场份额越高,专利发生无效宣告的可能性越大。但上述文献主要探讨了专利无效宣告与市场价值的关系,未涉及各类指标对无效宣告结果的影响。最后是情报学领域,在竞争情报学中将申请宣告竞争对手的专利无效视作是一种重要的专利战略手段,李睿等[8]指出在技术市场权益的争夺中,优质专利通常是竞争对手申请无效宣告的主要目标。此外,专利无效宣告倾向在不同技术领域所表现的程度不尽相同,Patel P A等[9]发现专利异议率在不同的领域所占比例不同,其中在电气工程领域的异议率在5.3%~9.7%左右;但上述文献并未系统地构建一套完整的无效宣告识别体系。
通过相关研究可知,目前国内外学者对于专利无效宣告的研究,主要集中在专利无效宣告制度的合理性,或是专利无效宣告对不同领域的影响。对于影响专利无效宣告的特征因素研究较为欠缺。
1.2 特征识别模型相关研究
随着学科融合的进一步发展,现如今针对各类专利的识别模型各不相同。对于专利识别的研究主要集中在两个角度,一是利用传统的数学统计分析方法进行研究,例如孙玉艳等[10]利用市场法、成本法、收益法和修正收益法对专利价值进行线性组合和非线性组合预测,得到加权算数平均值组合预测和加权调和平均组合预测两种评估模型;王子焉等[11]利用文献计量、社会网络分析方法从专利价值的内涵、评估指标体系、评估方法三方面对专利价值进行评估。二是利用数据挖掘方法,例如深度学习、机器学习等对专利各类特征进行识别,例如张杰等[12]采用AdaBoost算法对诉讼专利的专利质量进行评价,以及Jee J 等[13]利用人工神经网络方法对制药技术领域专利进行分类,达到识别高质量专利的目的;Kang I S 等[14]提出建立聚类模型来对侵权专利检索,从而建立侵权专利的特征模型,但上述研究均未涉及利用专利特征构建识别。根据已有研究可以发现:目前的专利识别模型主要集中在对专利价值的特征识别和挖掘,对侵权专利和无效宣告专利的特征识别研究较为欠缺,例如蒋启蒙等[15]采用传统统计学中Logistic回归模型对专利侵权诉讼中无效宣告倾向的影响因素展开实证分析。但利用数据挖掘方法对专利无效宣告风险的特征识别研究较为欠缺。本文基于传统侵权专利的分析研究,在侵权专利的基础上对于该专利的无效宣告风险特征进行识别,创新性地提出针对国内侵权专利通过机器学习算法构建专利指标体系研究。通过数据挖掘研究专利诉讼产生的条件、区别分析专利诉讼风险特征不仅具有重要的学术价值,而且对解决我国企业在国内外市场竞争中的专利纠纷冲突、预防专利侵权风险具有十分重要的现实意义。
2 特征选取与研究设计
2.1 特征因素选取
学术界对于专利的各类特性的评估指标选取方式各不相同,袁任远等[16]在对企业风险进行预警时,从宏观、微观以及综合指标因素三维度选取指标科学评定风险等级;郭青等[17]从专利的经济、法律、技术三个方面选取相应的专利质量评价指标,构建了三位一体的专利质量评价指标体系。
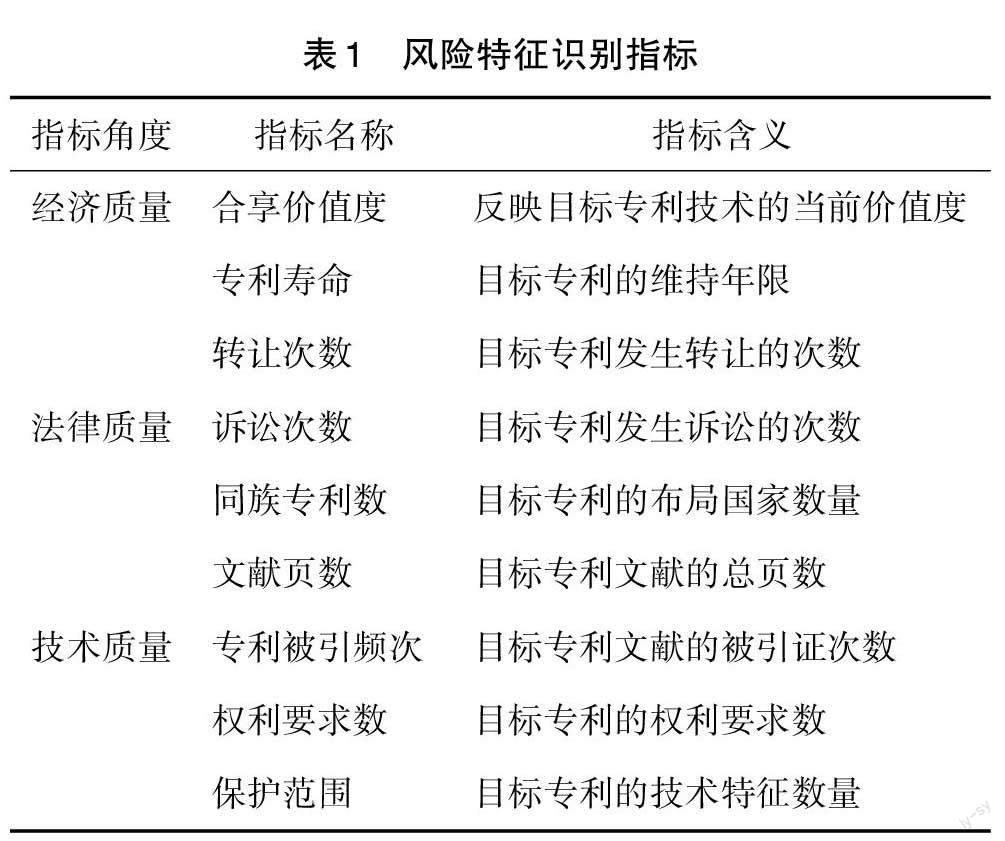
因此,基于已有研究,本文从经济质量、技术质量和法律质量三个维度分别选取三个指标,构建较为完整的侵权专利无效宣告风险特征识别体系,如表1所示。
在经济质量方面,主要选取了“合享价值度”“专利寿命”和“转让次数”,其中“合享价值度”主要是指合享利用自主研发的专利价值模型对专利价值度进行计算,该专利价值模型将专利分为1~10分,分数越高则专利价值越高;“专利寿命”是衡量专利新增利潤的重要依据之一,同时也对专利的技术价格有着重要的影响,赖院根等[18]认为专利寿命反映了创新主体的研发实力和行业技术更新速度;“转让次数”计量专利发生的整体转让情况,武玉英等[19]通过挖掘专利转让加权网络主体信息及结构特征对交易机会进行预测,促进技术供需有效对接。
在法律质量方面,刘星等[20]认为法律因素主要包括专利权的法律状态、稳定性、维持时间、宽度以及专利权人的类型。本文主要选取了“诉讼次数”“同族专利数”和“文献页数”,其中“专利诉讼”发生的主要原因是为了争夺市场,企业或其他创新主体往往通过专利诉讼抑制同类型竞争对手的生产经营规模,袁晓东等[21]指出专利诉讼倾向与产品类型、公司所在国家和诉讼持续时间等都有相关性;“同族专利数”主要体现了相同的专利权人对该项技术的市场分布和合作伙伴或者技术受让人的分布,郭青等[17]认为同族专利数量反映专利质量的高低,同族数量多的专利经受法律考核的能力就越强,专利的质量就越高;“文献页数”主要涉及说明书,权利要求书以及附图,页数越多,所包含的专利内容越多。
在技术质量方面,主要选取了“专利被引频次”“权利要求数”“保护范围”,“专利被引频次”主要反映该专利在后续技术发展中的重要性,并且在一定程度上也反映了发明的经济价值,李春燕等[22]指出如果专利的被引用次数越高,则该专利越能代表该领域的基础技术,可以反映出该专利的技术先进性;“权利要求数”主要体现了专利的保护范围,郭青等[17]认为权利要求数量越多,专利的保护范围越广,专利的质量也越高;“保护范围”主要涉及是指专利权法律效力所涉及的发明创造的范围,Lerner Josh等[23]提出用专利文件中的IPC(国际专利分类号)小类的数量来衡量专利覆盖的技术范围。
2.2 模型选取与评估
2.2.1 研究设计
图1为专利无效宣告预测模型。首先,通过阅读国内外的大量研究文献,对专利无效宣告进行概念的界定,结合指标的可获取性、科学性等因素,选取影响专利无效的指标;通过文献检索的方法,获取影响专利诉讼的指标数据,建立样本库;通过机器学习的监督学习算法——决策树,对样本库中的侵权专利进行分析,对影响专利无效宣告的指标进行分类训练,构建基于机器学习的诉讼专利特征识别模型,并对算法的结果进行参数调整,使得算法模型达到最优效果;通过特征重要程度的对比,对特征的各项指标的重要程度进行对比,获得在不同领域专利无效宣告风险识别的最优选算法指标,得出导致专利发生无效宣告的指标影响程度排序,进而建立较为精准的专利预警指标体系。
2.2.2 决策树模型建立
决策树(Decision tree)也称作判定树,是一类常见的机器学习方法。这是一种典型的分类学习方法,决策树的具体训练方法为:对于专利数据集D={(xp,yn),p=1,2,…,P;n=1,2,…,N},其中xp代表第n 项专利的指标特征,yn代表第n 项专利的类别,P 是每项专利所包含的指标特征数量。首先采用“留出法”(hold out)将数据集D划分为决策树模型的训练集S 和测试集T;其次利用信息熵(Entropy)或者基尼系数(Gini Impurity)找出最佳节点和最佳的分枝方法。决策树生成后,再利用最大深度(max_depth)对决策树确认最优的剪枝参数、叶子节点最少样本数(min_samples_leaf)让分枝会朝着满足每个子节点都包含所规定的样本数的方向去发生以及利用最大特征(max_features)限制分枝时考虑的特征个数。最后,得到目标权重参数(class_weight)对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。
2.2.3 性能度量
采用决策树模型最终完成的任务是专利无效宣告的二分类问题,故本文采用准确率(Accuracy)、平均精確率(Precision)、平均召回率(Recall)、平均F1值(F1)以及ROC 曲线下方的面积(Area Under ROC the Curve,AUC)5个指标对模型的性能进行评价。对于二分类问题,将样例数据根据机器学习的预测类别与实际类别相结合分为真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)、假反例(FalseNegative,FN)四种情况。
准确率是指模型分类正确的专利样本数量与所有的专利样本数量的比值,其计算公式如式(1)所示:
精确率是指检测出某类特征的数量与检测出的所有特征数量之间的比率,衡量的是模型的查准率;其计算公式如式(2)所示:
3 实验及结果分析
3.1 数据来源
“十四五”时期,生物产业主要涉及两个方面,一是生物医药领域,该领域主要以精准药物设计为核心,结合现代生物学、信息技术和材料科学等多个学科,加强基因治疗、细胞治疗、免疫治疗、代谢调控等医疗技术的研发。二是生物制造行业,主要包含能源生物炼制、化工与材料生物制造、生物反应器及装备技术。因此,本文数据选自于北京合享智慧科技有限公司incoPat数据库,构建检索式为:“INDUSTRY1=4 AND ACTION-TYPES=侵权案件”,筛选新兴产业——“生物产业”领域的侵权案件,检索时间截至2022年6月,检索范围为在中国公开并且获得授权的发明专利以及实用新型专利。通过数据筛选,共得到包含853条数据的专利文献数据集。
3.2 无效宣告特征识别
3.2.1 决策树模型构建
(1)数据归一化,划分训练集和测试集
根据整理后的数据可以得到853件侵权专利,其中有效专利286件,无效专利567件。首先,采用数据预处理(preprocessing-StandardScaler)对所设定的九项特征数据进行数据标准化处理,进而让所收集的数据服从高斯正态分布,从而等级化,进而实现数据中心化,公式如(6)所示,x为原始数据,u为平均值,s为标准差,z为归一化数值。为了保证数据集的无偏采样,防止出现“过采样”和“下采样”的情况出现,本文利用SMOTE的过采样算法,即增加一些正例使得正、反例数目接近,然后再进行训练。最后采用“留出法”将数据划分为训练集和测试集。
通过归一化和无偏采样的调整后,将数据集D 划分为包含226个样本的训练集S 和包含908个样本的测试集T。
(2)计算样本划分前的期望信息,确定决策树根节点
经过计算,“被引证次数”的信息增益最大,因此被作为划分属性。
(3)计算每个决策属性信息增益,建立识别模型
根据模型根节点的划分,再依次计算每个决策属性的信息增益,选择最佳节点和最佳的分枝方法,对每一个分枝进行进一步的划分。根据对无效宣告各特征属性信息熵的计算,生成的无效宣告决策树模型。内部节点和叶子节点均用矩形表示。其中,“被引证次数”描述“无效宣告”的概念,其值为“T”或“F”各代表一个类。
(4)确定最大深度,确定最优参数
如果在不加任何限制的情况下,一棵决策树会不断生长,直到衡量不纯度的指标最优,或者没有更多的特征可用时才会停止生长。因此,需要对决策树进行剪枝处理,本文主要采用利用最大深度(max_depth)对决策树确认最优的剪枝参数。如图2所示,利用超参数曲线来判断模型的最大深度。可以看出,最优的剪枝参数取5时,模型的拟合效果已较为优秀。
图3为划分完成后的决策树模型。可以看到,基于信息增益的决策树再建立时以“被引证次数”作为根节点,“权利要求数量”作为子节点。由图3可以看出,对于专利是否会发生无效宣告首先是根据被引证次数对其进行评估,经过数据归一化后,当被引证次数小于或等于-0.79时,该专利不易发生无效宣告风险。反之,当被引证次数大于-0.79时,则需要对权利要求数进行下一步的评估,当权利要求数大于0.376时,则该专利不易发生无效宣告风险。反之,当权利要求数小于或等于0.376时,则需要对该专利的被引证次数进行再次的划分。在对专利进行再次分类后,在决策树模型的第三层,根据被引证次数是否大于或小于等于-0.121将模型划分成了两个分枝:“权利要求数量”和“合享价值度”。在“权利要求数量”分枝中,当权利要求数小于-0.672时,则需要再根据其保护范围进行再次划分。由此可以得出,判断一件专利发生无效宣告的第一条路径:权利要求数量→被引证次数→权利要求数量→保护范围。在“合享价值度”分枝中,当“合享价值度”小于等于1.848时,则需要根据“转让次数”进行再次划分,由此可以看出判断一件专利发生无效宣告的第二条路径:权利要求数量→被引证次数→合享价值度→转让次数;当“合享价值度”大于1.848时,则需要根据“简单同族个数”进行再次划分,由此可以看出判断一件专利发生无效宣告的第三条路径:权利要求数量→被引证次数→合享价值度→简单同族个数。
综上所述,关于识别侵权专利的无效宣告风险主要包含三条路径,分别涉及了“被引证次数”“权利要求数量”等多个方面。因此,构建的专利识别体系覆盖层面较广,极大提高了识别准确率。
3.2.2 特征重要性
图4为模型指标的特征重要程度。由于不同特征对于模型的影响程度不同,因此,需要对所选取特征的信息熵进行分别计算。通过对特征重要程度的分析,能够更好地构建专利无效宣告预警指标体系。
由图4可知,在决策树模型的就九项指标中,“权利要求数量”对于模型分类结果的影响程度最高,影响程度为0.449 949。因此,其对于专利无效宣告的影响程度最大。其次,“被引证次数”对于模型分类结果的影响程度较高,影响程度为0.222 449 8,“被引证次数”对于专利无效宣告的影响程度较为显著;排在第三位的是“诉讼次数”,影响程度为0.090 978;排在第四位的是“保护范围”,影响程度为0.085 511 96;紧随其后的是“合享价值度”,影响程度为0.062 427 31;“简单同族个数”“转让次数”和“文献页数”对专利无效宣告的影响一般,影响程度均在0.05以下;“专利寿命”对于模型分类结果的影响程度最低。
结合决策树的分类路径可以看出,决策树在分类时,主要是根据所选取的特征指标的重要程度进行划分。因此,在判断单件专利发生无效宣告的倾向时,首先应当注重专利的“权利要求数量”和“被引证次数”。其次,关注“诉讼次数”“保护范围”和“合享价值度”对专利无效宣告的影响,最后,再关注“简单同族个数”“转让次数”和“文献页数”。
3.3 模型评估
为了评估本文构建的机器学习模型的性能,采用2.2.3中所述的评估指标。由表2可知,在测试集中,决策树模型的Accuracy、Precision、Recall、F1以及AUC 的评分,其评分均为0.97以上。综合实验分析可以发现,本文构建的决策树的分类模型,在该数据集上表现的拟合度较优,整体性能较为准确。由此可以得出,决策树二分类模型对于专利无效宣告倾向预测上的应用,较为准确。
本文数据主要来源于新兴产业“生物产业”的侵权案件,根据上述模型的运行和评估情况,可以将此模型运用在新兴产业不同的领域,识别不同领域对于专利的无效宣告倾向,提出了一种关于专利无效宣告风险预警的新模型,从而对专利发生无效宣告风险的可能性给予客观以及科学的判别,同时对于知识产权与人工智能算法的跨学科结合研究具有重要的理论意义。
4 结果与讨论
本文根据前人对于专利无效宣告指标体系的相关研究,首先提出了基于经济质量、技术质量和法律质量三个维度9 个指标的专利无效宣告预警指标体系;其次,采用机器学习的决策树二分类模型,从而对专利无效宣告倾向进行分类;最后,数据库选取新兴产业中的生物产业对模型進行实验分析,验证本文构建的专利无效宣告预警体系的有效性及准确性。
通过实证分析得出如下结论:首先,在模型构建时,由于决策树模型是建立在平衡数据的基础上进行分类,但所收集的数据往往是不平衡数据集,则需要对数据进行过采样或欠采样处理,进而提高分类的准确性。其次,在决策树分化时,为了防止决策树的过拟合,含有过多的不必要信息,需要计算模型的最佳节点和最佳的分枝方法,对决策树进行剪枝处理,让模型准确率更加稳定。另外,根据模型的评估结果可以看出,决策树二分类模型在专利无效宣告的预测中效果较好,准确率为0.97左右。最后,根据特征重要程度可以看出,不同的指标对模型分化的影响程度不同,在专利无效宣告的预测中,需要更加注重“权利要求数量”和“被引证次数”对预测结果的影响。因此,根据模型的分枝规则以及特征重要程度的排序,依照文中所描述的三条路径对专利的无效宣告倾向进行预测,可以建立一套较为完整的专利无效宣告预警体系。
综上所述,本文构建的专利无效宣告预测模型以及专利无效宣告的预警体系对我国专利的研究具有一定的科学性以及现实意义,可以为企业以及其他创新主体对于自身专利的情况提供一定的判断依据,为保护自身专利的稳定性提供相应的数据支持。但是,本文构建的预测模型和预警体系也存在一定的局限性:一是在指标的选取上,主要选取定量指标进行模型构建,并未充分考虑定性指标对于专利无效宣告预测的影响,同时识别预测指标体系也需进一步完善。二是在模型的选取上,本文仅采用机器学习中决策树模型,模型较为单一,并未尝试利用其他模型对专利无效宣告预测进行构建。因此,在后续的研究过程中,将对以上两点的进行深入研究,不断完善专利无效宣告预测模型以及构建更加精准的专利无效宣告的预警体系,进一步改进决策树模型,使分析结果更为准确。
