基于边缘云计算的混合并行AI训练机制研究
2023-02-08贺迎先
贺迎先
(安徽三联学院 财会学院,合肥 230601)
近年来,人工智能(Artificial Intelligence,AI)模型和算法受到了学术界和工业界越来越多的关注,并被应用到诸如图像识别、自然语言处理、推荐系统等领域[1-3].此外,随着边缘计算的发展和物联网对AI应用需求的诞生,许多基于实时深度学习的边缘AI应用正在智能医疗、智能机器人和工业物联网等各个领域涌现.作为一种数据驱动的方法,基于深度学习的边缘AI需要有足够的数据样本,以通过深度神经网络提取数据的特征或属性.这些数据样本通常是由通信和计算能力有限的设备产生.因此,如何有效利用边缘设备的通信和计算能力来训练AI模型是在边缘计算环境中提高训练效率需要解决的关键问题.本文提出了基于边缘云计算的混合并行训练框架(Edge-Cloud based Hybrid Parallel Training Framework,ECHPT),ECHPT能有效地将AI模型的训练任务分配到终端设备、边缘服务器和云计算中心,缩短训练时间,实现快速边缘AI学习.
1 ECHPT训练框架设计
本文所提出的ECHPT框架由三个阶段组成:分析、优化和分层训练.在分析阶段,ECHPT首先分别分析设备、边缘和云计算节点中不同模型层的平均执行时间;然后分析模型中每一层输出的大小.ECHPT在边缘云的每个计算节点上进行一次训练迭代,记录不同AI层的执行时间和输出大小.该过程将被重复几十次,然后取平均值以获得稳定的结果.由于模型中每一层的输出大小是固定的,因此只需要记录一次.由于大多数的AI模型具有固定的结构,因此可以以离线方式执行该分析步骤以减少时间开销.
在优化阶段,分层训练优化器选择最佳AI模型分区点,并分别确定终端设备、边缘服务器和云计算中心计算节点的训练样本数量.优化器的目标是最小化AI训练时间,优化器需要考虑:计算节点中不同模型层的分析平均执行时间、模型每一层输出的大小和设备和边缘服务器之间以及边缘服务器与云计算中心之间的可用带宽.
在分层训练阶段,终端设备首先根据优化阶段给出的调度策略将分配的数据样本发送到边缘服务器和云计算中心.随后设备、边缘服务器和云计算中心立即启动它们的预定训练任务(即分配的模型训练模块),并以分层方式进行协作模型训练.
2 ECHPT训练流程
AI模型由一系列不同的层堆叠而成,一层的输出馈入下一层的输入.ECHPT的目标是减少边缘云环境中的整体训练时间.为此,首先定义了三种类型的训练任务,其中,原任务训练了整个AI模型,数据样本为bo;短任务训练了ms个连续层,数据样本为bs;长任务训练了ml个连续层,数据样本为bl.

workers使用数据样本bs在分配的层上执行前向阶段,即通过AI模型进行推理以获得当前模型损失.完成该前向阶段后,workers将输出发送到workero,workero继续在其余层上执行前向阶段.workerl的行为与workers相同,使用数据样本bl.workero使用数据样本bo执行前向阶段.当前向阶段结束后,workero从数据样本B=bs+bl+bo中收集模型损失.
对于每个数据样本,workero从AI模型的最后一层开始反向阶段,即使用损失进行反向传播以获得随机梯度.如果数据样本属于workero,则workero执行完整的后向阶段.如果数据样本属于workerl,则workero在到达ml+1层时将中间结果发送给workerl,workerl继续在其余层上执行反向阶段.同理,workero在到达ms+1层时将中间结果发送给workers.当后向阶段结束时,每个计算节点都会获得所分配层的随机梯度.
workerl和workers将计算出的随机梯度发送给workero.然后workero逐层平均随机梯度,并根据分配给它们的层将平均随机梯度发送给workerl和workers.计算节点分别使用这些随机梯度来更新对应分配层的权重.
3 调度优化模型
ECHPT的核心是调度策略,该调度策略决定了如何分配将模型层和数据样本,以实现最小化训练时间.假设AI模型有N个层,每个数据样本的大小为Q个比特.

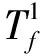

反向阶段结束后,workerl和workers将随机梯度发送给workero.workero根据分配给他们的层将平均随机梯度发送给workerl和workers.权重更新阶段的总时间成本表示为:
(1)

(2)
优化问题(2)的决策变量bo、bs、bl、ms和ml都是非负整数.通过枚举所有的映射关系,计算出每一个映射的最优调度策略,然后找到全局最优调度策略.
4 调度算法设计
优化问题的决策变量都是整数,求解该问题具有挑战性.当变量ms和ml固定时,优化问题将成为整数线性规划问题.因此,通过枚举ms和ml的值,解决由此产生的整数线性规划问题,然后在解决方案中找到最好的一个.
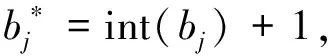
随后,需要确定设备、边缘服务器和云计算中心计算节点与workero、workers和workerl之间的最佳映射策略.对此,可以枚举所有映射,为每个映射找到一个候选的最优调度策略,然后选择训练时间最短的最佳映射策略.
5 实验评估
为了评估ECHPT框架,实验部分使用两个主流的、用于图像分类的神经网络:第一个是LeNet-5,使用CIFAR-10数据集进行训练;第二个是AlexNet,使用ImageNet数据集进行训练.实验使用树莓派作为终端设备,该设备拥有一个四核的ARM处理器和1 GB的内存.使用普通的个人电脑作为边缘服务器,该电脑配备英特尔酷睿i3-10110U处理器和8 GB内存.使用配置有志强W-2223处理器、64GB内存和GeForce GTX 3080Ti显卡的服务器作为云计算中心.实验使用边缘框架、云计算框架、协同框架[4]和JALAD框架[5]作为对比的方案.其中,边缘框架将所有训练数据样本传输到边缘服务器,由边缘服务器完成AI模型训练;云计算框架将所有训练数据样本传输到云计算中心,由云计算中心完成AI模型训练;协同框架同时使用终端设备和云计算中心共同训练 AI模型;JALAD利用边缘服务器和云计算中心共同训练AI模型,并应用数据压缩策略来减少边缘云传输延迟.
首先验证了ECHPT框架在分析AI模型训练延迟的准确性.通过训练AlexNet,获得了实验测量的实际延迟和理论延迟,结果如图1所示.由对比结果可知,实际延迟和理论延迟之间的差别较小,这表明了ECHPT框架在分析训练延迟方面具有较高的准确性.
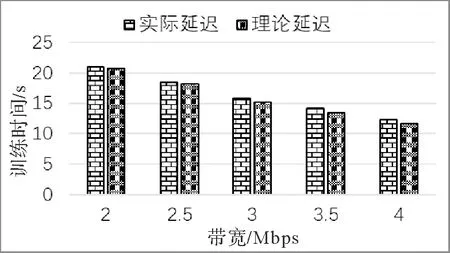
图1 训练时间的分析准确性
图2和图3分别展示了不同边缘云带宽下五种框架一次迭代的平均训练时间.云计算框架的训练时间随着边缘云带宽的增加而降低,而边缘框架的时间成本保持不变.与边缘框架和云计算框架相比,ECHPT框架在训练AlexNet时分别实现了高达2.3倍和4.5倍的加速,而在训练LeNet-5时分别实现了高达1.7倍和6.9倍的加速.在训练AlexNet时,当边缘云带宽较低时,JALAD的表现优于ECHPT.原因是JALAD的数据压缩策略可以大大减少边缘服务器和云计算中心之间传输的数据量,使JALAD在低带宽条件下具有优势.但是,当带宽增加时,通过数据压缩减少通信延迟的优势便不明显,此时ECHPT的性能优于JALAD.
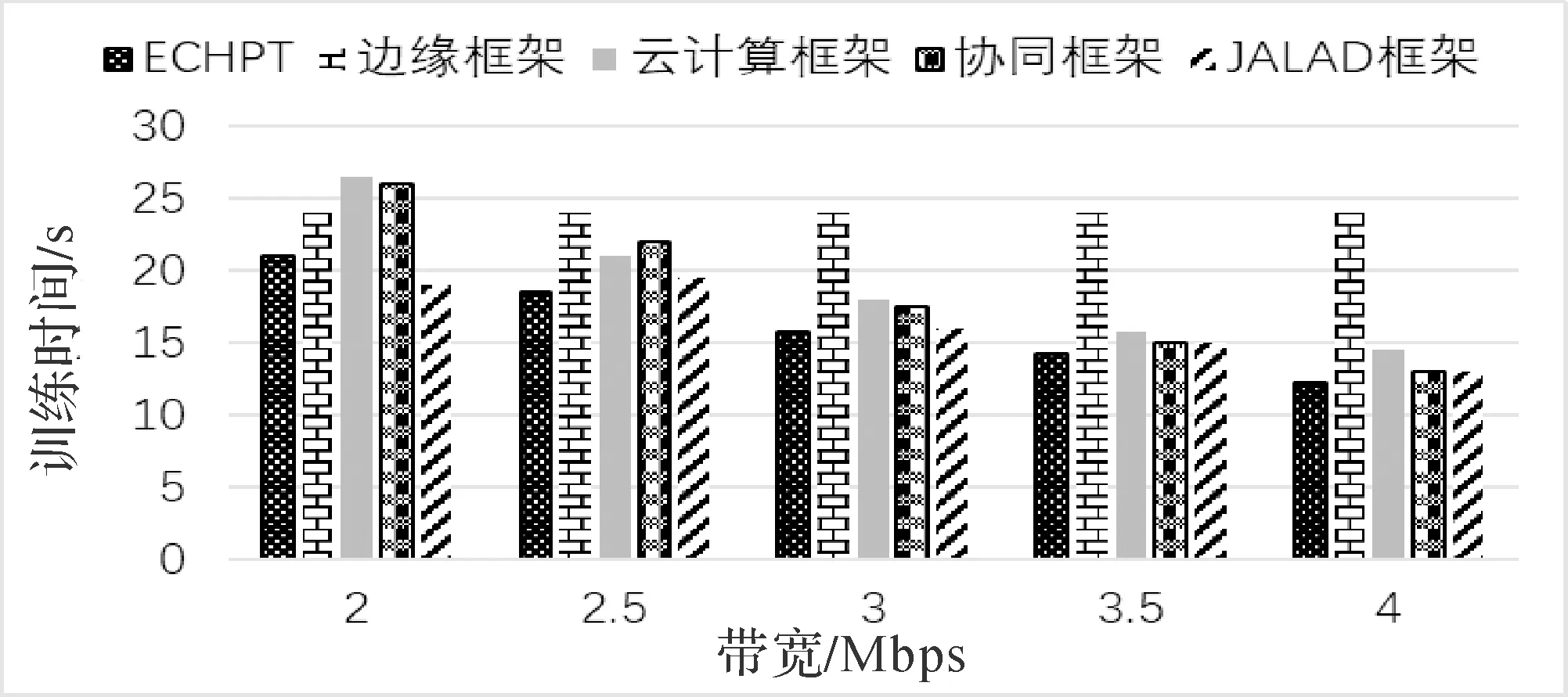
图2 五种框架的AlexNet训练时间对比

图3 五种框架的LeNet-5训练时间对比
6 结语
本文提出了一种用于训练AI模型的混合并行框架——ECHPT,将AI模型训练的调度问题建模为训练时间最小化问题,通过求解该优化问题得到调度策略.实验部分通过将ECHPT与现有的方法相比,验证了ECHPT框架的有效性.实验结果表明,ECHPT框架能够降低AI模型的训练时间.未来的工作将把ECHPT框架部署到多终端设备、多边缘服务器的现实环境中,结合不同的AI模型和应用,进一步评估框架的性能.
