基于超级网络理论的谣言检测模型研究
2023-02-08郭晓晨
郭晓晨
(安徽工商职业学院 管理学院,合肥230041)
随着计算机技术的飞速发展,新浪微博等几个主流的社交网络平台为人们自由发表意见提供了渠道.这些社交网络平台在带来了便利的同时,也带来了一些严重的安全问题,而谣言检测则是其中一个关键的研究领域.谣言的传播会引起严重的社会问题并扰乱公共秩序,因此设计和优化能够准确、及时地检测谣言极其重要.现有的谣言检测模型一般基于用户信息或帖子内容等特征进行研究[1-3],但是仍然缺少系统的模型联合考虑多种特征来进行谣言检测.本研究基于超级网络理论提出了一种新颖的谣言检测模型,构建了一个三层的超级网络以描述微博帖子的特征,并基于此提出了一个谣言分类器以进行谣言检测.
1 谣言特征
Twitter和新浪微博是两个主要的微博平台,而不同平台(数据集)中的谣言之间存在着差异.由于现有的大多数研究都将Twitter作为研究对象,因此将新浪微博平台作为研究对象,探讨谣言检测问题.微博辟谣公众号所提供的年度谣言统计信息有益于我们的特征选择过程,主要考虑以下三类主要特征.
第一类是与用户有关的特征.微博用户的大部分信息(例如性别、年龄、账号类型、位置、关注数和关注度)都可以直接在个人页面找到.此外,用于发布微博的客户端程序类型也是一个显著的特征.大多数传播谣言的用户实际上只是一些被谣言蒙蔽了双眼的普通用户,因此对这一特定用户群的检测是重要的研究重点领域.
第二类特征是与内容有关的特征.与微博内容相关的特征包括了内容是否包含网址、问号出现的频率、任意词和暂定词的数量,其中大部分是根据关键词计算的.与内容有关的特征是判断某个微博帖子是否为谣言的重要依据.另外,诸如转发和评论数量等内容扩散特征也是需要考察的重要因素.
第三类是与心理有关的特征.基于心理的特征对于在线情感分析非常重要,因此考虑将此类特征应用于谣言检测中.之前的研究普遍认为只有拥有负面情绪的帖子才能成为谣言,然而一个帖子所包含的心理很复杂,部分谣言也可能会有积极的情绪.
2 谣言检测模型
2.1 超级网络模型
超级网络可以全面描述复杂的关系,运用超级网络理论可以从微博帖子中挖掘和发现更多有用的信息.此外,得益于超级网络独特的多层次、多维度、多属性的优势,可以更好地反映互联网舆情的复杂性和动态性.[4]建立了一个具有三层子网络的超级网络:社交子网络、心理子网络和关键词子网络,创建谣言的谣言检测系统,如图1所示.
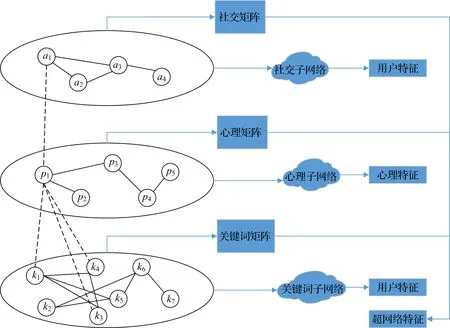
图1 超级网络模型
在本超级网络中,所有子网络都是无向网络.位于同一子网络内的边是正常边,连接不同子网络的边称为超级边.一条超级边表示一个完整的帖子,其中包括该帖子的用户、心理和内容.[5]如图1所示,超级边(虚线)所表示帖子是由用户a1发表的帖子,其心理为p1,由关键字k1、k3和k4组成.分别用矩阵S、P和K来表示不同子网络中的邻接关系,其中矩阵元素的值为0表示节点之间没有连接,元素值为1表示有连接.对于社交子网,社交矩阵是根据用户之间的关注关系建立的.例如,在图1中,用户a2关注了用户a1,因此Sa1a2=Sa2a1=1.采用基于词典的方法判定帖子的心理,考虑的心理情绪包括认同、否认、怀疑、愤怒和兴奋.在大多数情况下,一条帖子可能会包含不止一种心理情绪,例如,愤怒和否认心理经常同时出现.心理矩阵P是根据一个帖子所包含的情绪来建立的.如图1所示,p1和p2同时出现在一个帖子中,所以有Pp1p2=Pp2p1=1.在关键词子网中,建立了谣言词典.该词典以微博辟谣公众号近期检测到的谣言为关键词,经过分词处理后,选取出现频率最高的前200个词组成词典.基于谣言词典来构建的关键词矩阵,如图1所示,帖子包含关键词k1、k3和k4,因此有Vk1k3=Vk3k1=Vk4k1=Vk1k4=Vk3k4=Vk4k3=1.
2.2 超级网络特征
基于谣言检测超级网络,可以创建一组新的特征,称为基于超级网络的特征,即社会子网聚类系数、心理复杂性、谣言关键词密度和超级边相似度.社会子网聚类系数衡量特定用户在社交子网内的聚集程度,其计算方式为
(1)
其中:Ci是用户i的聚类系数,k是连接到用户i的用户数,n是这k个用户之间实际存在的边数.心理复杂性反映了帖子的心理复杂程度,其计算方式如下所示:
(2)
其中:Φm是帖子m的心理复杂度,Pim是帖子m中的第i个心理,N是帖子m内的心理总数.谣言关键词密度代表帖子内谣言关键词的密度,其计算方式为
(3)
其中:Ωm为帖子m的谣言关键词密度,khm为帖子m中包含的第h个谣言关键词,M为帖子m内谣言相关关键词的总数.超级边相似度反映了帖子的相似程度.首先定义帖子m和帖子o之间的Jaccard系数,其计算方式为
(4)
基于该系数,定义了一个相似度矩阵B.基于相似度矩阵,可以通过下述公式计算超边的相似度:
(5)
其中:Πm度量超边m的相似度.
2.3 检测分类过程
采用超级网络模型对特征进行分类,以获得所选特征的结构.对于第二组特征,尽管超级网络理论对特征结构建立过程做出了贡献,但它也允许我们提出一些新的特征,这些特征可以衡量不同子网络内部和之间的关系,而这些是以前的工作尚未考虑的.结合上述的社交子网聚类系数、心理复杂度、谣言关键词密度和超级边相似度,最终选择了29个特征.
提出的谣言检测模型架构如图2所示.首先,采用爬虫技术从微博网站中获取数据.选择了几个热门话题,根据一些相关的关键词,抓取了所有相关的微博帖子,其中包括用户信息和内容.每个主题的所有帖子构成一个数据集,然后根据微博辟谣公众号发布的经过验证的所选话题的谣言,将每个数据集分为两个方面:真实帖子和谣言.此外,本模型还有识别异常用户的功能.
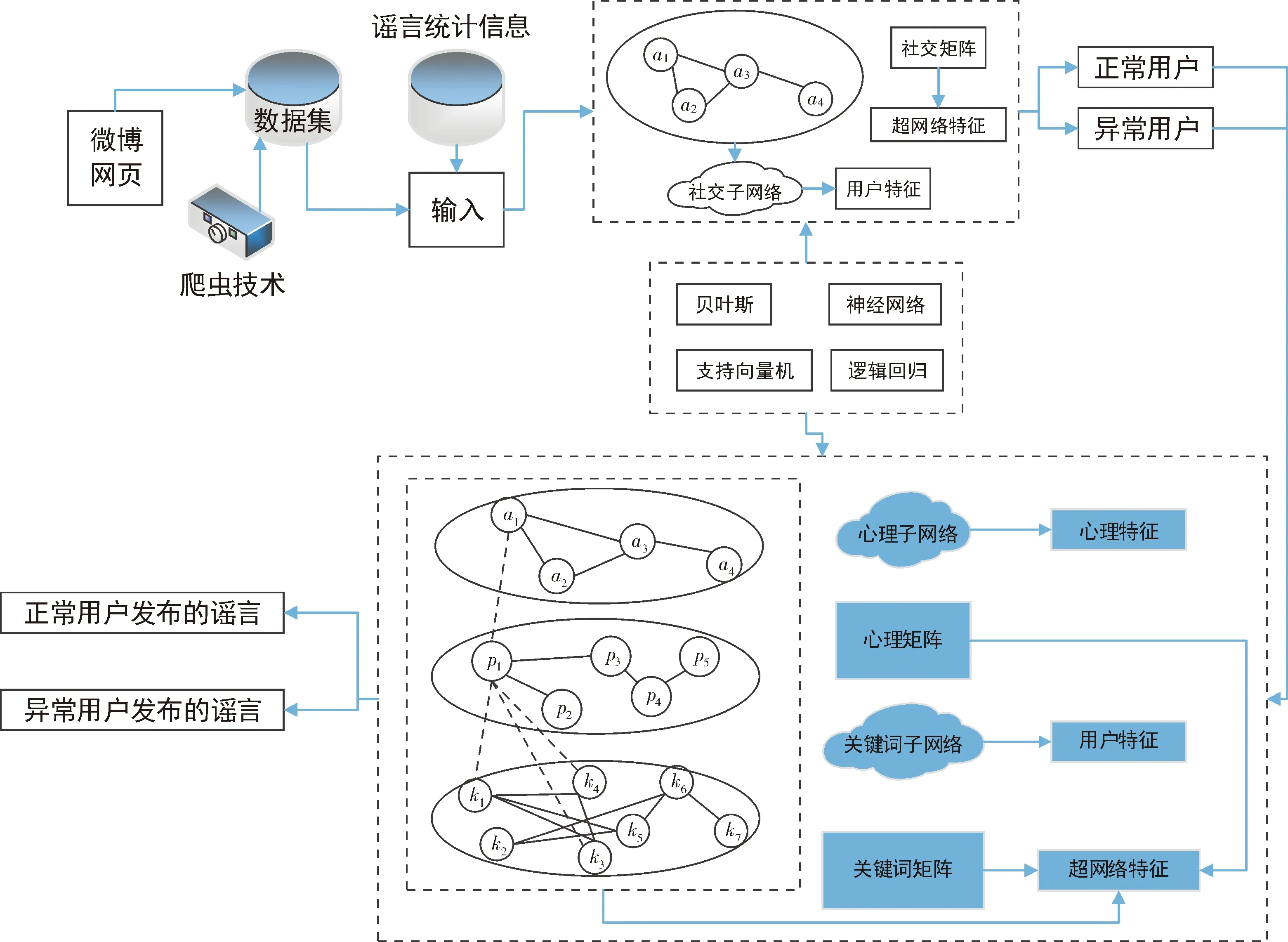
图2 谣言检测流程
考虑以下四类情况:发布谣言的普通用户、发布谣言的异常用户、发布真实信息的普通用户和发布真实信息的异常用户.根据与用户有关的特征和社交子网聚类系数,将每个数据集分为两组:正常用户和异常用户.由此可知,这是一个二元分类问题.使用朴素贝叶斯、神经网络、支持向量机和逻辑回归这四种机器学习方法来训练用户分类器.
利用与心理有关的特征、与内容有关的特征和基于超级网络的特征(除社交子网聚类系数外),结合上述四种机器学习方法,训练谣言分类器进行正常用户群和异常用户群内的谣言检测.
3 实验评估
实验所使用的数据集包含了三个热点话题的75 580个帖子及相应的用户帐户信息.将每个数据集分为训练数据集和测试数据集.为了评估所提出的谣言检测模型的准确性,使用了准确度α、精确度β、召回率χ和 Fa-度量η四个指标,其定义如式(6)所示.选择了两个现有的谣言检测模型(即EveRumor谣言检测模型[4]和ML-based谣言检测模型[5])与提出的SNTRumor进行比较.
(6)
每个算法进行50次实验,取平均值作为最终结果.表 1展示了不同算法的检测性能结果.由结果可知,无论是使用哪一种分类器,所提出的SNTRumor模型都具有最好的表现.与EveRumor和ML-based相比,SNTRumor不仅考虑了用户、内容和心理特征,还考虑了超级网络的特征,因此可以有效提高谣言检测的性能.
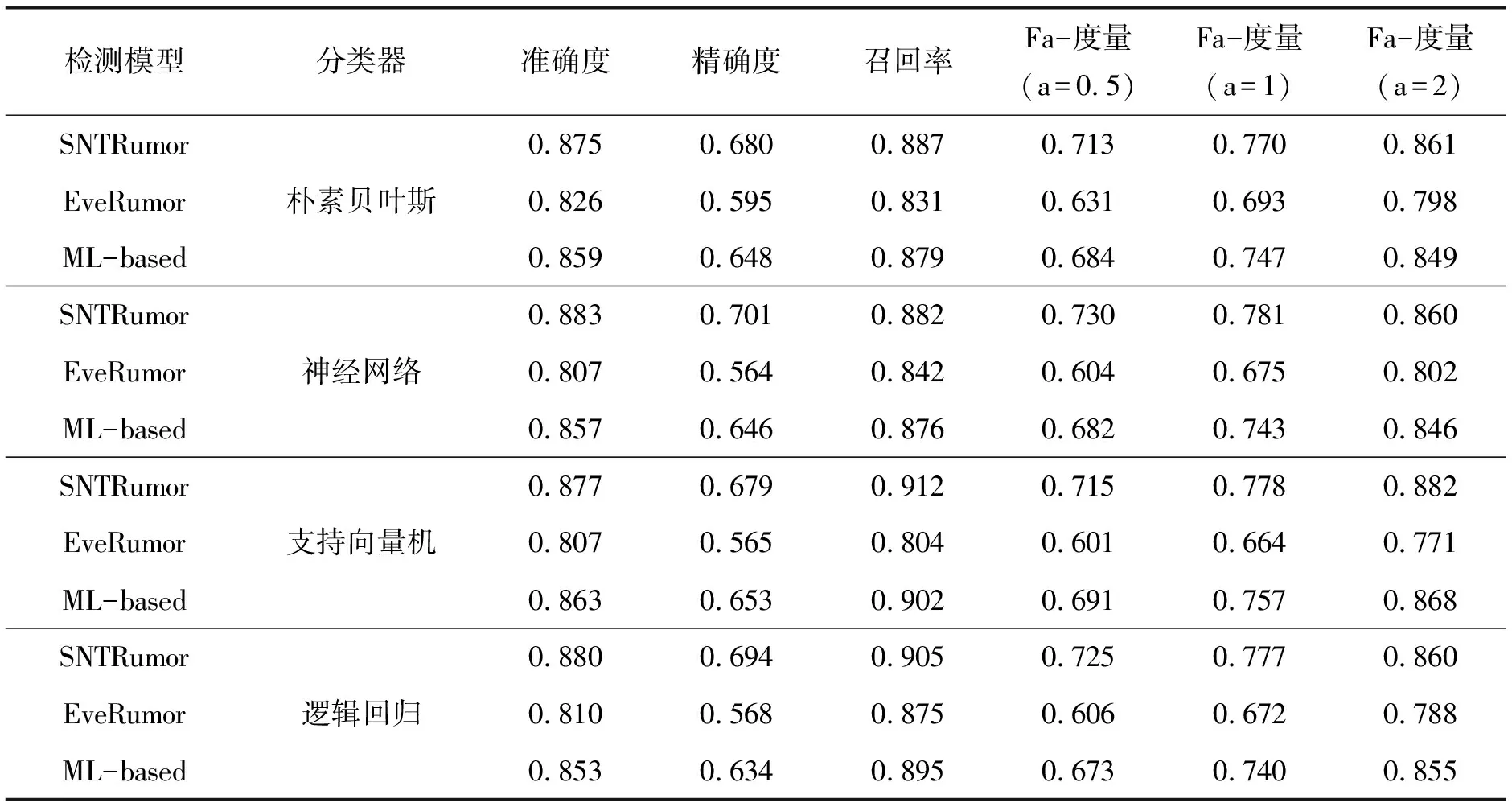
表1 检测结果对比
4 结语
本文系统地将超级网络理论应用于谣言检测问题中,提出了谣言检测模型.提出了一组新的特征,重点关注不同特征之间的关系,以全面描述微博帖子.由实验结果可知,与现有的模型相比,提出的谣言检测模型表现出更好的性能.在未来的研究中,将考虑更多的经典理论来探讨谣言检测问题,并通过改进分类方法来提高检测性能.
