基于混合模型的事件触发词抽取*
2023-02-08王兴芬
杨 昊,赵 刚,王兴芬
(北京信息科技大学信息管理学院,北京 100192)
1 引言
作为信息抽取[1]的一部分,事件抽取[2]在舆情分析[3]、自动问答[4]和知识推理[5]等方面具有现实意义。根据自动内容抽取ACE(Automatic Content Extraction)测评会议对事件的定义,事件是指发生了的事情,包含直接引起事件发生的触发词和事件的参与者。事件抽取是指要求人们用人工或自动的方法,从半结构化、非结构化数据中识别出与目标相关的触发词和事件论元。其中,触发词作为事件的核心词,决定着事件的类型,故事件触发词抽取作为事件抽取的子任务具有重要的现实意义。现阶段事件抽取的方法可以分为3类[6]:基于特征的方法、基于结构的方法和基于神经网络的方法。
传统的方法通常为基于特征或结构的方法,大多是利用NLP(Natural Language Processing)工具提取词法特征(如词干、词性、实体信息等)或结构信息(如句内依存关系、句间特征等)。Ahn[7]利用词法特征结合最大熵模型进行事件抽取,将抽取任务模块化后转化为多个串行的子任务。为解决上述所提方法在事件抽取中正反比例不平均和数据稀疏的问题,赵妍妍等[8]在此基础上,同样利用词法特征,首先通过《同义词词林》进行触发词扩展,并构建二元对照表,再利用最大熵模型进行多元分类,完成了事件抽取。然而,文献[8]仍旧没能解决过度依赖语料质量和语料规模的问题。付剑锋等[9]则先对词性、位置等不同特征赋予不同的权重,再利用无监督聚类完成事件要素识别,摆脱了对语料库的过度依赖。为从文本中获取句间及篇幅间的结构信息,Lin等[10]提出了一种概率框架模型完成事件抽取。为从文本中获取句内的结构信息,高源等[11]利用词语词性和依存句法分析路径中的位置、依存句法树结构等信息,构造“触发词-实体”描述对,进而再利用SVM(Support Vector Machine)模型进行分类,完成事件检测和类型识别。为解决生物事件中触发词存在语义歧义的问题,李浩瑞等[12]提取了词性、距离和依存句法等特征,并线性组合SVM模型和随机森林模型,更好地完成了生物触发词检测的任务。这些传统的方法,虽能捕捉事件结构性语法特征,但还未捕捉和利用事件语义特征。
近年来,随着神经网络的发展,在词语语义特征提取层面,研究人员通常采用word2vec[13]方法。在事件抽取领域中,也诞生了诸多基于卷积神经网络CNN(Convolutional Neural Network)[14]或循环神经网络RNN(Recurrent Neural Network)[15]的事件抽取方法。Nguyen等[16]利用传统CNN模型,在不依赖大量外部资源的情况下提取隐式特征。由于传统CNN池化方式只能捕捉句子中一个最重要的信息,有可能错过其他有价值的内容,造成在包含多个触发词的语句上进行事件抽取的效果不佳。为解决此问题,Chen等[17]提出了DMCNN(Dynamic Multi-pooling Convolutional Neural Network)模型,在对初始向量进行卷积操作后,通过对候选触发词的上下两段进行分段最大池化,再将其与语义向量进行拼接,最后利用单层神经网络完成多触发词抽取任务。然而,仅仅利用神经网络模型进行事件的抽取,虽能提取事件语义特征,但仍忽略了事件的结构性语法特征。Nguyen等[18]提出了BiLSTM-GCN(Bidirectional Long Short-Term Memory-Graph Convolutional Network)模型,利用图卷积训练依存句法关系,在DMCNN基础上进一步改进池化方式,融入了实体本身信息,同时也在初始向量生成环节使用了BiLSTM模型。但是,其忽略了不同词语对句子级语义特征的贡献程度不同的情况,故未能完全捕获事件句子级语义特征。为融合事件多维度特征,苗佳等[19]利用CNN-BiGRU(Convolutional Neural Network-Bidirectional Gating Recurrent Unit)模型,通过CNN获取词级特征,通过BiGRU获取句子级特征,提高了事件抽取的效率,更好地完成了事件触发词抽取任务。然而CNN-BiGRU模型忽略了句内各词语之间的语法结构信息。针对中文词汇的歧义问题,丁玲等[20]提出了分层次语义融合模型,首先基于字符序列进行标注,并设计了字符-词语、词语-句子的融合门机制,消除了词汇歧义,最后利用BiLSTM-CRF模型完成事件抽取。类似地,武国亮等[21]提出了FB-Lattice-BiLSTM-CRF(FeedBack-Lattice-Bidirectional Long Short-Term Memory-Conditional Random Field)模型,对仅能捕获字粒度语义信息的BiLSTM-CRF模型进行词语维度和实体维度的信息增强,提取包含命名实体识别的分词结果并将其输入融合了Lattice机制和BiLSTM网络的共享层,进而完成事件抽取任务,更好地解决了中文词汇歧义的问题。然而,分层次语义融合模型和FB-Lattice-BiLSTM-CRF模型在忽视了句内语法结构信息的同时也未将句子级语义特征完全捕获。
综合上述分析可知,现有方法都只侧重事件语义或语句结构的某一方面,未能将事件的结构性语法特征和事件语义特征两者完全捕捉并融合,存在不能够准确表征事件触发词的问题。针对这一问题,本文提出一种集传统方法与神经网络方法优点于一体的混合模型。该模型将事件的结构性语法信息与神经网络所提取的事件语义信息有机融合,能够同时包含事件结构性语法特征与事件语义特征,2种特征融合之后,能够在低维空间中更准确地表示事件触发词,更好地支撑事件触发词抽取任务。
2 混合模型
本文中的事件语义特征是指事件中的每个词语在特定语句中所带有的语义信息,在本文中具体包含词级语义特征[19]和句子级语义特征[19]。事件的结构性语法特征是指事件中的每个词语在其特定语句中的位置及依赖关系,在本文中具体包含位置特征[17]和依存句法特征[12]。
图1给出了事件结构性语法特征和事件语义特征的示例。图1a中,“他离开了家来到学校”中的“离开”为“移动”类型触发词;图1b中,“他离开了工作多年的岗位”中的“离开”为“离职”类型触发词。若忽略事件语义特征,仅考虑事件结构性语法特征,由于“离开”均为依存树结构中的根节点,故无法区分2个触发词类型;若忽略事件结构性语法特征,仅考虑事件语义特征,则在“他离开了工作多年的岗位”中忽略了“工作”一词在句中的结构信息,便会误将其识别为触发词。可见,事件结构性语法特征与事件语义特征在事件触发词抽取任务当中存在融合的必要性。

Figure 1 Examples of event structural grammatical features and event semantic features图1 事件结构性语法特征和事件语义特征示例
本文所提出的混合模型由初始化向量模型和神经网络模型2部分融合而成,其功能分别为向量初始化和事件语义特征提取。初始向量中融合了词语语义特征和事件结构性语法特征;事件语义特征提取由神经网络模型完成,在已融合了事件结构性语法特征的初始向量上,进一步提取事件语义特征,同时也完成了事件结构性语法特征和事件语义特征的融合。混合模型工作过程如图2所示。

Figure 2 Process of hybrid model图2 混合模型工作过程
2.1 向量初始化
对于输入的句子序列,首先将句子进行分词处理,如式(1)所示:
Sentence={w1,w2,…,wi,…,wn}
(1)
其中,n为句子中的词语个数,wi(1≤i≤n)为第i个词语。将句子进行向量化表示为Vsentence,如式(2)和式(3)所示:
Vsentence={V1,V2,…,Vn}
(2)
Vi=[semi,loci,depi]
(3)
其中,Vi为句子中第i个词语的向量化表示,由3部分拼接而成:第i个词语的语义向量semi,表征词语的语义特征;位置向量loci,表征词语的位置特征;依存句法树向量depi,表征词语的依存句法特征。Vi融合了词语的语义特征和事件结构性语法特征。为了便于后续网络模型训练,将句子长度n设为固定长度length,若句子实际长度大于length则直接舍去多出部分,小于length则用零补齐表示向量。
2.1.1 语义向量
在多种自然语言处理任务当中,词语的语义信息都充当了重要角色。考虑目标词的上下文,以及用更少的维度表达目标词的语义信息,本文语义向量表示采用常用的word2vec。word2vec包括Skip-Gram[13]和CBOW[13]2种模型,其中Skip-Gram为利用中心词预测上下文词的模型;CBOW为利用上下文词预测中心词的模型。本文采用Skip-Gram模型,来获得词语的语义向量表示,即semi,并利用Huffman Softmax来提高训练效率。
2.1.2 位置向量
考虑到词语的相对位置会影响其在语句中的结构性作用,进而影响事件触发词的抽取,本文将词语的相对位置信息融入初始向量中。常见的相对位置编码有:正弦位置编码[22]、学习位置编码和相对位置表达[23]。本文采用正弦位置编码,如式(4)和式(5)所示:
PEpos,2I=sin(pos/100002I/d)
(4)
PEpos,2I+1=cos(pos/100002I+1/d)
(5)
其中,pos为词语在句子中的位置,d为位置向量的长度,I指位置向量的一个维度,取值在[0,d)。例如,pos=3,d=30,则该位置词语的位置向量为:[sin(3/100000/30),cos(3/100001/30),sin(3/100002/30),cos(3/100003/30),…]。最终获得词语的位置向量loci。
2.1.3 依存句法树向量
依存句法由法国语言学家Tesniere最先提出。它将句子分析成一棵依存句法树,描述了各个词语之间的依存关系,也指出了词语之间在语法上的搭配关系。这种搭配关系包含了结构性的语法特征。基于此,本文提出一种基于依存句法树的向量表征方式,用于事件触发词抽取任务当中,如图3所示,其中SBV表示主谓关系,VOB表示动宾关系,“买”为核心谓词。
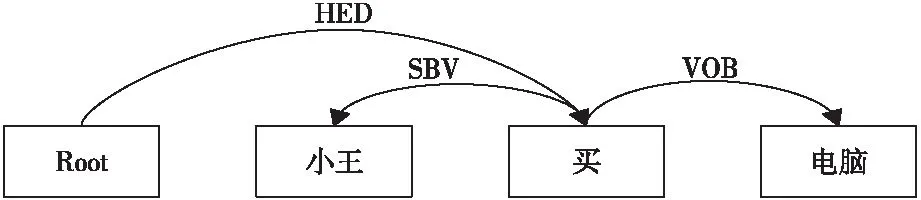
Figure 3 Example of dependency parsing tree图3 依存句法树示例
由于事件触发词为事件的核心词,故其在依存句法树中应该距核心谓词较近,即事件触发词节点在依存句法树结构中深度较浅。本文将词语节点所在依存句法树中的深度进行one-hot编码,最终获得词语的依存句法树向量depi。
2.2 事件语义特征提取
事件触发词抽取是从词语的初始向量中进一步提取特征,进而进行任务分类。本文采用多维度语义特征提取,利用传统CNN进行词级语义特征提取,利用BiGRU捕获句子级语义特征。由于在捕获句子级语义特征的过程中,每一词语对句子级语义特征的影响程度不同,故本文提出一种针对事件触发词抽取任务的E-attention(Events- attention)模型,将其应用于BiGRU,利用BiGRU-E-attention模型完成句子级语义特征提取。从词级语义特征和句子级语义特征2个维度进行特征提取,以更好地支撑事件触发词的抽取任务。
2.2.1 CNN提取词级语义特征
CNN是一种具有表征学习能力的前馈神经网络,利用其卷积过程中的表征学习能力能够捕获目标词与周围词之间的相互关系,从而提取句子中的词级语义特征。其中,卷积是利用多个卷积核滑过句子初始矩阵,与对应位置相乘的过程,具体过程如图4所示。

Figure 4 Extraction of semantic features at the word level using CNN图4 CNN提取词级别语义特征
句子的初始矩阵表示为Vsentence={V1,V2,…,Vn},其中,Vsentence∈Rn×D,D为词语初始向量的维度,n为词语个数。设一个卷积核为u∈Rk×D,其宽度与词语初始向量的维度相同,对Vsentence进行卷积操作,如式(6)所示:
ci=f(u·Vi-k/2:i+k/2+b)
(6)
其中,Vi-k/2:i+k/2表示词语wi周围k个词语的特征;f(·)为非线性激活函数;b为偏置值。若词语左右词语数小于k/2,则用零补全。一个卷积核扫描句子所有词语后,得到该句子的特征,其表示如式(7)所示:
g=[c1,c2,…,cn]
(7)
其中,g∈Rn,n为句子的长度。利用m个不同的卷积核,则得到整个句子的特征矩阵,其表示如式(8)所示:
C=[g1,g2,…,gm]
(8)
其中,C∈Rn×m,C中每一行代表当前词语通过CNN所获取的词级语义特征。
2.2.2 BiGRU-E-attention提取句子级语义特征
RNN是一类用于处理序列数据的神经网络。传统的RNN会随着时间序列长度的增加,发生梯度爆炸和梯度消失等问题,影响学习效果。为解决该问题,LSTM(Long Short-Term Memory network)和GRU(Gating Recurrent Unit)相继被提出。GRU与LSTM在学习效果上相近,但GRU具有更少的权值参数、更快的收敛速度和更好的学习效率,故本文采用GRU模型。GRU模型的前向传播如式(9)~式(13)所示:
zt=σ(Wz·[ht-1,Vt])
(9)
rt=σ(Wr·[ht-1,Vt])
(10)
(11)
(12)
yt=σ(Wo·ht)
(13)

由于单向GRU模型只能记忆已输入的词语特征,无法预测未输入的词语特征,故本文使用双向GRU模型,即BiGRU。将BiGRU两方向的输出结果相加得H=[h1,h2,…,hn]T,hi∈R1×s,H∈Rn×s,s为BiGRU隐藏层神经元的个数。
在获取词语句子级语义特征的过程中,考虑到每一个词语对句子级语义特征的影响程度不同,本文引入了注意力机制,获得了效果更优的句子级语义特征。注意力机制首先应用于翻译任务,取得了优异效果,后续被推广至诸多任务当中。现有注意力机制演变出了dot-product attention[22]、additive attention[24]等多种形式,但上述形式仅能得到句子的整体向量表示,无法在每一个词语向量中融入具有注意力机制的句子级别语义特征,不能应用于事件触发词抽取任务。故本文提出了针对此任务的E-attention模型,其具体实现过程如式(14)和式(15)所示:
P=softmax(H·Wa)
(14)
Q=P*H
(15)
其中,Wa为注意力权重参数,Wa∈Rs;P为各个状态的权重矩阵;Q=[q1,q2,…,qn]T,qi∈R1×s,Q∈Rn×s,每一行为句子中每个词语的句子级语义特征;*表示矩阵按行对应相乘。句子级语义特征提取模型如图5所示。

Figure 5 Extraction of semantic features at the sentence level using BiGRU-E-attention 图5 BiGRU-E-attention 提取句子级语义特征
2.3 触发词抽取
上述词级语义特征为C∈Rn×m,句子级语义特征为Q∈Rn×s,为了充分融合词级语义特征和句子级语义特征,以更准确地表征事件触发词,本文选择的特征融合方式如式(16)所示:
y=[C,Q]
(16)
其中,y∈Rn×(m+s),由C和Q二者拼接而成。事件结构性语法特征和事件语义特征融合于y向量之中,将y向量传入分类器,利用softmax激活函数进行类别选择,完成事件触发词的抽取。分类器如式(17)所示:
O=softmax(y·W+b1)
(17)
其中,W为权重矩阵,b1为偏置值。本文利用混合模型抽取事件触发词的具体流程如图6所示。

Figure 6 Event trigger word extraction using hybrid model 图6 混合模型事件触发词抽取
3 实验与结果分析
3.1 实验数据集
本文实验数据集采用在事件触发词抽取领域最常用的CEC中文突发语料库(https://github.com/manduner/CEC-Corpus)和ACE2005英文语料库(https://catalog.ldc.upenn.edu/LDC2006T06),并将数据集按8∶2比例划分为训练集与测试集。
CEC中文突发语料库是由上海大学语义智能实验室构建的开源数据集。该语料库包含地震、火灾、交通事故、恐怖袭击和食物中毒等5类突发事件的新闻报道,共11 908个突发事件,均用XML语言标注。
ACE2005英文语料库共包含599篇微博、广播新闻、新闻组和广播对话等文档。该语料库共定义了8个大类,33个子类事件。本文将识别子类事件作为任务。
3.2 评价标准
事件触发词抽取包含2个子任务:触发词的位置识别和触发词的分类,即分别转化为句内词语的二分类与多分类任务。
由于数据集的分布不均匀,本文采用F1值作为衡量本文模型整体稳定性的指标,具体计算如式(18)所示:
(18)
其中,precision表示分类任务的准确率,recall表示分类任务的召回率。F1值越大,表示模型的整体稳定性越高。
3.3 实验结果分析
本文将所提混合模型与本领域其他具有代表性的基准模型相对比,同时为探究所提模型的有效性进行了消融实验,其中消融实验的比较对象包括:(1)删除依存句法树向量(no dependency tree);(2)删除依存句法树向量和E-attention模型(no dependency tree or E-attention);(3)采用学习位置编码替代正弦位置编码(learned positional embedding)。
整体而言,本文所提的混合模型在事件抽取任务当中取得的效果优于传统方法和基于神经网络方法的,更加证实了本文混合模型的有效性,以及充分捕捉事件结构性语法特征和事件语义特征的必要性。
表1为CEC中文突发语料库上触发词位置识别结果。由表1可知,在CEC中文突发语料库上,触发词位置识别任务中,本文所提模型虽然准确率较FB-Lattice-BiLSTM-CRF的低了2.27%,但是召回率提高了3.85%,F1值提高了0.86%;本文模型的召回率较no dependency tree的低了0.4%,但准确率提高了0.54%,F1值提高了0.08%。表2为CEC中文突发语料库上触发词分类结果。由表2可知,在触发词分类任务中,本文所提混合模型分类结果的准确率、召回率及F1值均为最高。故在CEC中文突发语料库上,本文模型在事件触发词抽取任务代表性模型对比实验中,具有最高的F1值,效果最优。

Table 1 Position recognition of trigger words on CEC corpus
本文模型相比于FB-Lattice-BiLSTM-CRF有以下几点优势:(1)融入了依存句法信息,能够捕获事件中每个词语在句中的结构性语法特征;(2)在捕获事件句子级语义特征的网络模型中加入了特定的E-attention模型,使得事件触发词的表征过程中,有侧重地关注句中词语,捕获了更为准确的句子级语义特征,取得了更优异的效果。在位置编码中,正弦位置编码相对于学习位置编码,不易受训练集句子过短的影响,故其整体效果优于学习位置编码的。由于在中文事件触发词抽取任务中,存在中文分词歧义的问题,对依存句法分析的准确性有一定影响,故本文模型相比于no dependency tree,在F1值上的提升效果不明显。

Table 2 Trigger word classification on CEC corpus
本文也在ACE2005英文语料库上做了相关实验,并与本领域的代表性模型进行了比较。
由表3可知,在触发词位置识别任务中,本文的混合模型虽然准确率与DMCNN的相比低了6.6%,但召回率提高了8.3%,F1值提高了1.4%。由表4可知,在触发词分类任务中,本文的混合模型虽然准确率与DMCNN的相比低了4.8%,但是召回率提高了12%,F1值提高了1.7%。故在ACE2005英文语料库上,在事件触发词抽取任务代表性模型对比实验中,本文模型具有最高的F1值,效果最优。

Table 3 Position recognition of trigger words on ACE2005 English corpus
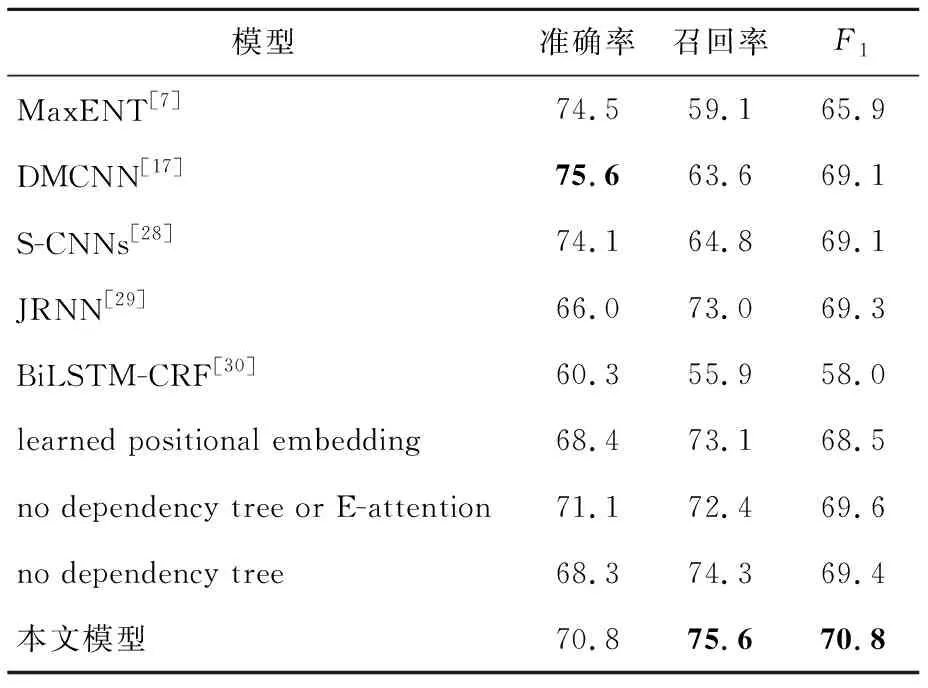
Table 4 Trigger word classification on ACE2005 English corpus
DMCNN在解决句内多触发词问题时,利用了分段池化的技术手段,因此其在触发词抽取的准确率上取得了优异的效果。然而,分段池化却弱化了句内两段间词语的结构性语法特征,导致其在触发词抽取的任务中效果逊于本文所提模型的。
3.4 特征融合探索
为探索多维度特征融合方式对事件触发词抽取任务的影响,本文在CEC中文突发语料库上,对词级语义特征和句子级语义特征的融合方式进行了进一步的研究。现有的特征融合方式主要有特征向量相乘(MUL)[31]、相加(ADD)[31]和拼接(CONCAT)[32]3种方式。分别基于这3种融合方式的实验结果如表5和表6所示。

Table 5 Comparison of feature fusion methods for position recognition of trigger words on CEC corpus

Table 6 Comparison of feature fusion methods of trigger word classification on CEC corpus
在3种特征融合方式中,特征向量拼接的效果明显优于相加和相乘的。经分析,可能有以下2个方面的原因:(1)由于特征向量的相乘和相加的融合方式需要对特征向量先进行维度变换,而维度变换的过程在一定程度上弱化了原始特征;(2)在相乘和相加的过程中,改变了特征的原始值,在一定程度上破坏了特征内部的隐式关系。因此,拼接的特征融合方式展示了其在该任务中的优越性。
3.5 实验参数选取
本文损失函数使用交叉熵函数,优化器选择Adam优化器。该优化器是有效的随机优化方法,能够在学习的过程中自动调整学习率。本文经过反复实验比较,选择出最适合于本文任务的超参数,如表7所示。
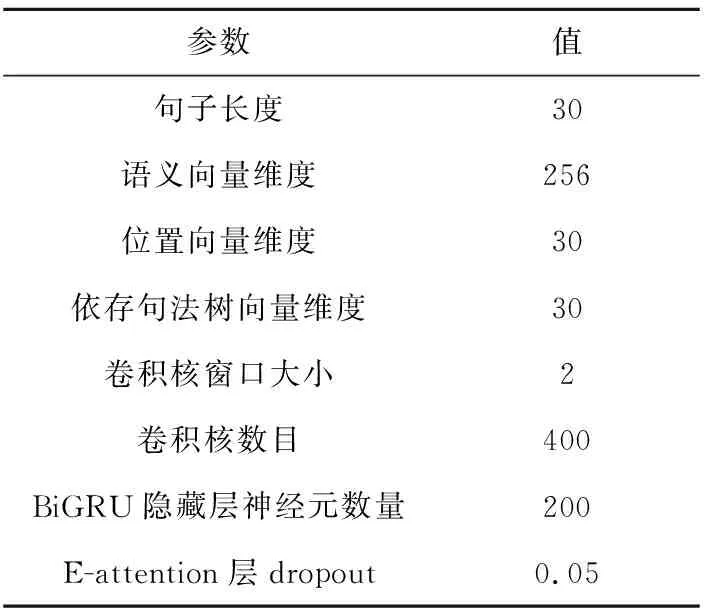
Table 7 Hyper-parameter setting
句子长度的设置对实现事件触发词的准确表征起到了至关重要的作用。因此,对句子长度length的深入探究具有重要的现实意义。如图7所示,在CEC中文突发语料库和ACE2005英文语料库中,句子的长度分布大体相似,整体分布不均匀,其中约85%的句子长度小于30,故设置句子长度为30可以充分表示句子特征。长度不足的句子用全零向量补全,因此句子长度设置为30又可控制句内全零向量的个数,减少了句内噪声。故本文将句子长度length设置为30。

Figure 7 Distribution of sentence length 图7 句长分布
CNN卷积核的窗口大小与事件词级语义特征紧密相关。本文以CEC中文突发语料库上的触发词分类任务为例,对CNN卷积核的窗口大小k的选取进行了深入的研究和分析。如图8所示,当卷积核的窗口设置为2时F1值最大,故当卷积核窗口设置为2时效果最优。卷积核窗口设置过小,无法完全学习词语周围词级别语义特征,窗口设置过大,便会淡化其局部特征,故窗口大小为2的卷积核最为适合事件触发词抽取任务。

Figure 8 Effection of window size on trigger wordsclassification model on CEC corpus图8 CEC中文突发语料库-触发词分类-窗口大小对模型效果影响
4 结束语
针对事件触发词抽取任务,本文提出了一种融合事件结构性语法特征和事件语义特征的混合模型。此模型首先利用初始化向量模型,根据本文所提出的依存句法向量的表征方式,在初始向量中融合了事件结构性语法特征;再利用神经网络模型,在将CNN所提取的词级语义特征与BiGRU-E- attention所提取的句子级语义特征融合的同时,也进一步融合了事件结构性语法特征与事件语义特征。经实验对比可知,相比于其他事件触发词抽取模型,本文模型在中英数据集上的抽取效果均有了进一步的提升。在未来的研究中,将考虑对语句中的不同依存关系进行分类表征,并将其应用在更多其他下游任务中。
