深度层次注意力矩阵分解*
2023-02-08李建红苏晓倩吴彩虹
李建红,苏晓倩,吴彩虹
(1.安徽理工大学人工智能学院,安徽 淮南 232001;2.安徽理工大学安全科学与工程学院,安徽 淮南 232001)
1 引言
随着大数据时代的到来,很多互联网应用使用的数据量也变得越来越大,如何从这些大量数据中获得有效的信息是学术界和工业界急需解决的问题。推荐系统作为信息提取的一种有效方式,已大规模应用于个性化推荐中,例如京东、淘宝和亚马逊等电商平台都部署了推荐系统,为用户提供个性化商品推荐服务。推荐系统的核心是推荐算法,常见的是协同过滤及其扩展算法,包括CF(Collaborative Filtering)[1]、MF (Matrix Factorization)[2 - 3]及张燕平等人[4 - 7]提出的用户声誉推荐算法等。近年来,以深度学习为代表的人工智能技术取得了巨大进展,究其原因是深度学习能够对数据进行学习并获得其特征表示,因此很多研究人员尝试将深度学习技术应用到推荐中,以挖掘用户的潜在偏好信息,从而提升推荐系统的性能。利用RBM(Restricted Boltzmann Machine)[8]和AE(Automatic Encoder)[9,10]等深度学习方法进行个性化推荐,其核心思想都是对输入数据进行学习,以获取用户个性化偏好信息。文献[11]则是在广度和深度学习(Wide and Deep Learning)[12]基础上提出了DeepHM(Deep Hybrid Model), 该文献指出广度和深度学习需要专家设计特征工程模型,并且广度学习没有挖掘数据非线性用户偏好的能力。此外,通过VAE(VAriational Eutoencoder)和CF学习数据分布可以获得用户偏好信息并进行个性化推荐[13]。
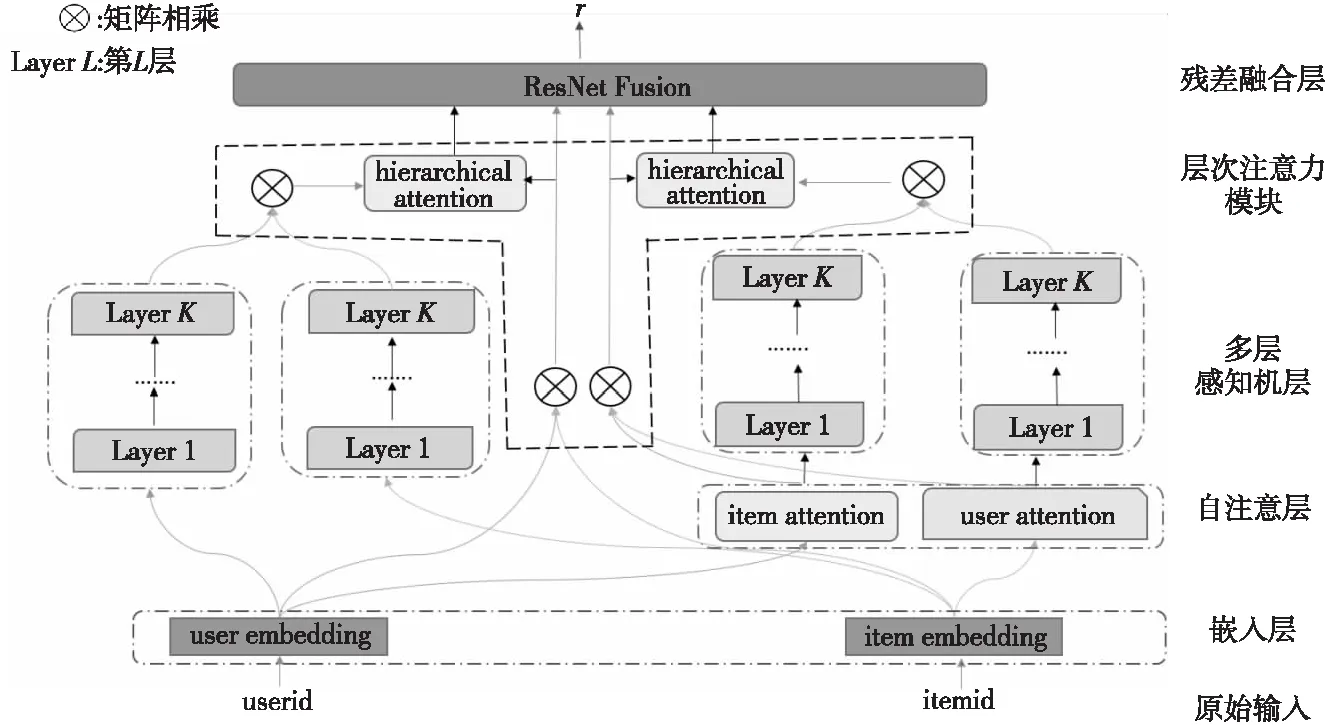
Figure 1 DeepHAMF framework图1 DeepHAMF框架
注意力机制在自然语言处理中能够捕获文本间的关系信息,且文本信息能够很好地刻画用户的个性化偏好信息,因此很多研究人员尝试将文本信息和注意力机制应用于评分预测中。例如,Lü 等人[14]提出的AICF(Attention-based Item Collaborative Filtering),将注意力机制应用于项目文本信息中,获得了较好的推荐效果。此外,Pang等人[15]则提出了ACNN-FM(Attention-based Convolutional Neural Network and Factorization Machines),通过基于注意力的卷积神经网络和分解机获取用户对不同项目的个性化偏好。无论是基于传统模型的推荐算法还是基于深度学习的方法都不能取得令人满意的结果。究其原因有:(1)推荐算法获取用户偏好信息的能力不足;(2)数据稀疏性影响了推荐算法的性能。
为了解决上述问题,本文提出了一种深度层次注意力矩阵分解(DeepHAMF)的新型推荐模型(如图1所示)。该模型对原始输入信息不仅用嵌入操作进行编码,同时使用自注意力机制进行编码,目的是直接得到显式偏好信息;其次,DeepHAMF使用多层感知机训练得到输入信息编码表示后,原始输入信息的矩阵分解和注意力编码之后的矩阵分解结果采用层次注意力机制相结合,得到用户潜在的偏好信息。实验结果表明,相比较其他的评分预测算法,DeepHAMF算法可以取得较好的效果。本文的主要工作可归纳为以下几个方面:
(1) 本文提出了名为DeepHAMF的新的神经网络模型并应用于评分预测中,实验结果验证了该模型的有效性。
(2) 对于原始输入信息进行并行操作:一是采用嵌入操作进行编码;另外采用自注意力机制进行编码,捕获用户显式信息偏好,该部分命名为自注意力层。
(3) 当输入信息进行编码后,送入多层感知机中,利用多层感知机训练得到信息编码表示。原始输入信息的矩阵分解结果和注意力编码之后的矩阵分解结果通过层次注意力机制获得历史行为数据中用户不同项目的偏好信息,该部分命名为层次注意力模块。
(4) 最后通过残差融合层对层次注意力模块、原始输入信息的矩阵分解结果和注意力编码之后的矩阵分解结果进行拟合得到预测结果。
2 相关工作
基于协同过滤的算法包括NMF(Non-negative Matrix Factorization)[16]、RLMC(Robust Local Matrix Factorization)[17]等。这些算法能够挖掘用户间的共同偏好,但是无法获得用户潜在的偏好信息,这样导致推荐效果不佳。随着深度学习的不断发展,研究人员尝试将其应用于推荐中,目的是获得用户潜在的偏好信息,以提高推荐系统的性能。Jia 等人[18]提出的 CF-CNN(Collaborative filtering and Convolutional Neural Networks) 方法将神经网络和协同过滤联合起来进行评分推荐。类似的方法还有DMF(Deep Matrix Factorization)[19]和NRR(Neural Rating Regression)[20]。Qian等人[21]提出的DLSA (Dual Learning Self-Attention)算法结合了双重学习和自注意力机制进行评分预测。另外,Nguyen等人[22]提出了NMC-S(Neural Matrix Completion Summarization)模型,该模型不仅继承了神经网络的预测能力,而且还能够扩展到训练集之外的部分观察样本,故不需要重新训练或微调。还有些研究利用属性信息和深度学习进行个性化信息挖掘[23 - 29]。随着图神经网络[30 - 32]应用于异质网络上,研究人员开始尝试将其与推荐系统相结合。文献[33]提出了RMGCNN (Recurrent Multi-Graph Convolutional Neural Networks),将评分预测问题转换为矩阵填充问题。另外,IGPL (Inductive Graph Pattern Learning)[34]则是利用图神经网络子图匹配模型与归纳学习相结合进行评分预测。
3 DeepHAMF
在开始介绍DeepHAMF前,首先对问题定义进行介绍,以更好地理解本文提出的模型。
3.1 问题定义
推荐算法主要是利用用户和项目之间的交互信息,挖掘出用户对项目的偏好信息,为用户推荐可能感兴趣的项目。黄立威等人[35]给出了如式(1)所示的形式化定义:
(1)
其中,U是用户集合,u表示某个用户;I是项目集合,i表示某个项目;S(·)表示推荐算法,i′u表示用户u感兴趣的项目。本文主要是进行评分预测,其结果为预测评分的值。评分值越高,用户可能感兴趣的程度越高,则推荐性能越好。
3.2 DeepHAMF
DeepHAMF主要包括嵌入层、注意力层、多层感知机层、层次注意力模块和残差融合层。
(1)原始输入:原始输入信息,只包括用户编号和项目编号,分别用userid和itemid表示。
(2)嵌入层:在获得原始输入信息后,需要将其转换为向量表示后才能进行后续操作。因此,通过嵌入层将原始输入信息转换成向量表示,其处理方式如式(2)和式(3)所示:
user_emd=embedded(userid)
(2)
item_emd=embedded(itemid)
(3)
其中,embedded(·)表示嵌入函数,user_emd和item_emd分别表示用户编号和项目编号嵌入操作后的结果。
(3)自注意力层:自注意力机制[36]在自然语言处理等领域取得了不错的效果,因此本文采用自注意力进行编码,并将这层命名为自注意力层。该层处理方法如式(4)和式(5)所示:
(4)
(5)
其中,Softmax(·)表示激活函数,d表示输入向量的维度,user_emd_att和item_emd_att分别表示向量经过注意力层处理后的向量表示。
在输入信息转换为嵌入向量表示后,一部分直接输入到多层感知机中,除此之外,本文还利用注意力层进行学习,这样能够捕获原始输入信息的偏好,究其原因是通过注意力机制能够对用户感兴趣的项目增加相应的权重。
(4)多层感知机层:由于神经网络通过训练后能够利用向量对数据进行特征表示,本文通过多层感知机进行学习表示,这样经过训练后的向量能够表示输入信息。具体操作方式如式(6)~式(9)所示:
(6)
(7)
(8)
(9)

(5)层次注意力模块:经过前面的处理后,通过矩阵分解操作,可以获得原始输入信息的交互信息,具体如式(10)和式(11)所示:
user_item=user_emd⊗item_emd
(10)
user_item_att=user_emd_att⊗item_emd_att
(11)
其中,user_item和user_item_att分别是原始输入矩阵分解结果的向量表示和原始输入注意机制后的矩阵分解结果的向量表示。其目的是通过用户与项目直接交互得到偏好信息。此外,需要将原始输入信息和经过多层感知机的信息进行注意力机制融合,其目的是获取潜在的用户个性化偏好信息。利用多层感知机学到的向量表示通过矩阵分解操作得到交互信息,具体如式(12)和式(13)所示:
user_item_mlp=user_mlp⊗item_mlp
(12)
user_item_attm=user_att_mlp⊗item_att_mlp
(13)
其中,user_item_mlp和user_item_attm分别是利用矩阵分解操作后的向量结果。通过层次注意力分别将注意力结果和多层感知机输出进行层次注意力操作,具体如式(14)和式(15)所示:
uiam=f(user_item_att)·f(user_item_mlp)
(14)
uima=f(user_item_attm)·f(user_item_att)
(15)
其中,uiam和uima分别表示操作后的结果;·表示点乘;f(·)表示激活函数,且激活函数是Linear。
(6)残差融合层:将相关信息(包括模型中原始输入信息、注意力层信息及层次注意力层信息)进行融合并输出预测结果。整个过程如式(16)和式(17)所示:
uira=F(uiam,W)+uiam+H(user_item)
(16)
uiar=F(uima,W)+uima+H(user_item_att)
(17)
其中,F(·)和W分别为残差融合的激活函数和权重;uiar和uira分别表示残差融合层输出结果;H(·)表示维度求和函数tf.reduce_sum(),目的是把向量数据变成一个评分数据。
最后对相关用户偏好信息进行求和并输出评分,如式(18)所示:
r=uira+uiar+U+I+b
(18)
其中,U表示用户偏移量,I表示项目偏置量,b表示全局偏置量,r表示预测结果。
为了更好地优化DeepHAMF算法,本文采用l2正则化项结合惩罚项的方法作为损失函数进行优化,具体的损失函数如式(19)所示:
(19)
其中,μ和θ均为惩罚项系数,φ为常数项系数,R表示用户对项目的实际评分,user_emd和item_emd分别表示用户编号的向量表示和项目编号的向量表示。
DeepHAMF可以表述为对原始输入信息进行如下操作。首先,对原始输入信息除了采用嵌入操作进行编码外,还采用自注意力机制进行编码,可以捕获用户显式信息偏好。对输入信息进行编码后,将其送入多层感知机中,并利用多层感知机训练得到编码表示;其次,与原始输入信息的矩阵分解结果和注意力编码之后的矩阵分解结果通过层次注意力机制获得历史行为数据中用户不同项目的偏好信息;最后,利用残差网络将层次注意力模块、原始输入信息的矩阵分解结果和注意力编码之后的矩阵分解结果进行拟合。
4 模型训练和实验结果分析
4.1 数据集
本文实验中使用的数据集为公开数据集MovieLens 100K(100k)和MovieLens 1M(1m)。100k数据集包含100 000个评分记录;MovieLens 1m数据集包含1 000 209个评分记录。所有的数据集分数都在1~5分。数据集详细信息如表1所示。
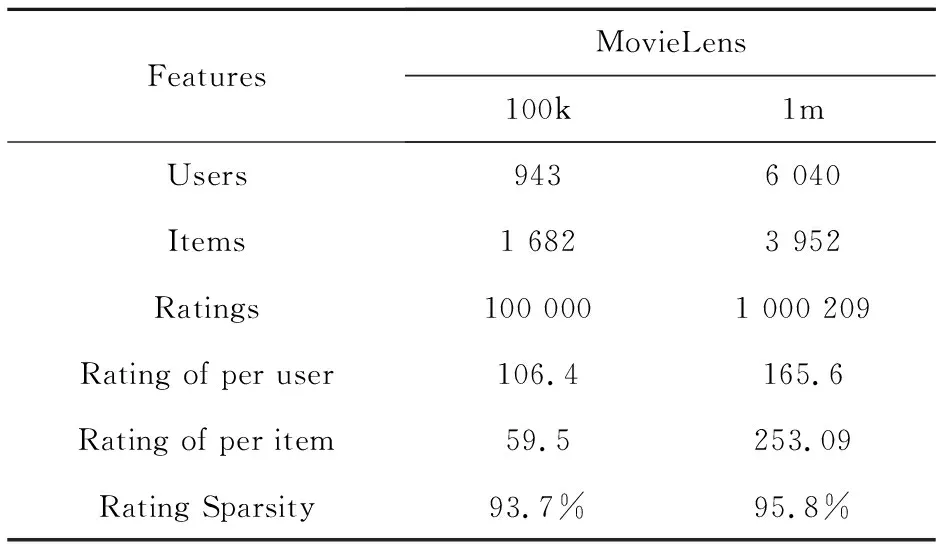
Table 1 Description of MovieLens datasets
4.2 评价指标与对比算法
均方根误差(RMSE)和平均绝对误差(MAE)是推荐系统中广泛使用的评价指标,本文也使用RMSE和MAE来评估DeepHAMF模型的性能。其计算如式(20)和式(21)所示:
(20)
(21)
其中,T表示测试集的大小,R表示用户的真实评分。
为了有效地验证本文模型的有效性,实验部分需回答以下问题:
(1)DeepHAMF与当前主流算法相比性能怎么样?
(2)DeepHAMF与有(无)文本信息的推荐算法和基于注意力的推荐算法相比,效果是否具有竞争性?
(3)DeepHAMF各模块效果如何?
为了充分回答上述问题,本文选取了传统的矩阵分解方法、基于神经网络的算法、基于注意力机制的算法和基于文本算法的模型进行比较,具体有:深度混合评分推荐DeepHM、奇异值分解模型SVD++(Singular Value Decomposition++)、通过对偶自动编码机的表示学习方法ReDa( Recommendation via Dual-autoencoder)、基于卷积神经网络的协调过滤算法CF-CNN、贝叶斯概率矩阵分解BPMF(Bayes Probabilistic Matrix Factorization)、概率矩阵分解PMF(Probabilistic Matrix Factorization)、非负矩阵分解NMF(Nonnegative Matrix Factorization)、基于神经网络预测模型NMC-S、基于抽样偏见和变分估计器模型RLMC、利用用户隐式社交关系推荐算法SR(Social Relations)[37]、联合矩阵填充和图卷积神经网络算法RMGCNN、局部图匹配的归纳模型IGPL、深度矩阵分解DMF、神经评分回归模型NRR、主题注意力的协同过滤算法AICF、基于注意力卷积神经分解机算法ACNN-FM、概率评分自动编码器算法PRA(Probabilistic Rating Auto-encoder)[38]、基于参数自动搜索的推荐算法Auto-S(Auto-Surprise)[39]、凸最小化Frank-Wolfe算法SHCGM(Stochastic Homotopy Conditional-Gradient Method)[40]和动态图推荐算法GCMC-GRU(Graph Convolutional Matrix Completion Gate Recurrent Unit)[41]。
4.3 模型训练参数
DeepHAMF算法只使用用户ID、电影ID和评分信息,不会添加任何其他信息。实验参数设置中使用Adam优化函数,多层感知机层使用3层,每层的神经元个数分别为200,100和10。激活函数使用ReLU函数,最后融合层输出评分值,程序语言是Python3。本文使用TensorFlow深度学习框架实现本文提出的模型。为了减少运行时间,使用NVIDIA RTX2080Ti GPU来加速实验运行。惩罚系数μ和θ均为0.000 1。
4.4 实验结果分析
为了回答问题(1),表2给出了DeepHAMF与当前主流的评分预测算法在MovieLens数据集上的十交叉验证(10-cv)结果。从100k数据集上的结果来看,DeepHAMF模型均有0.5%的性能提升。从1m数据集上的的实验结果来看,DeepHAMF模型在RMSE评价指标上保持了一定的优势,但在MAE指标上DLSA算法取得了不错的结果。原因在于,DLSA算法通过双重学习和自我注意力机制能够充分挖掘用户偏好信息,因此能够获得较好的结果。即使如此,DeepHAMF在RMSE指标上还是优于DLSA的,并且其MAE值仅次于DLSA算法的。此外,结合表1的数据可知,当数据量变大时,数据稀疏性也越来越强。从实验结果来看,DeepHAMF的性能比较好,这也说明DeepHAMF在数据稀疏性较高的情况下也能取得较好的效果。整体来说,本文DeepHAMF确实能够充分挖掘用户的个性化偏好信息,即使在数据稀疏的情况下也能拥有不错的结果。
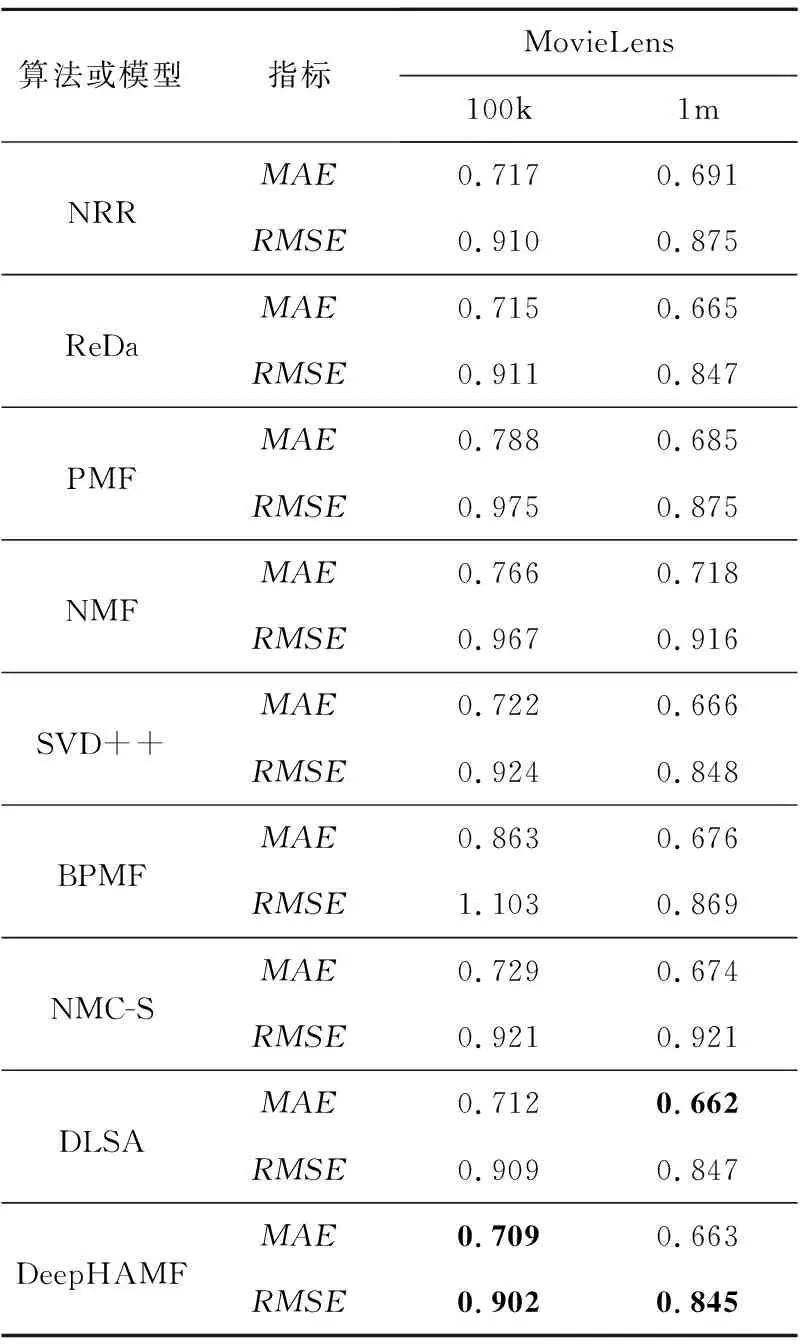
Table 2 Experimental results of DeepHAMF compared to 10-cv rating recommendation algorithms (without text information) on the MovieLens datasets
对于问题(2),表3给出了在MovieLens数据集上进行五交叉验证(5-cv)的结果,DeepHAMF模型无论是在MAE指标上还是RMSE指标上均最优,平均有1%的性能提升。这表明了DeepHAMF模型与不使用文本信息的推荐算法相比,能够取得较好的实验结果。这也表明了本文模型在不使用文本信息的情况下,能够充分挖掘用户的个性化偏好信息,从而获得很好的推荐效果。
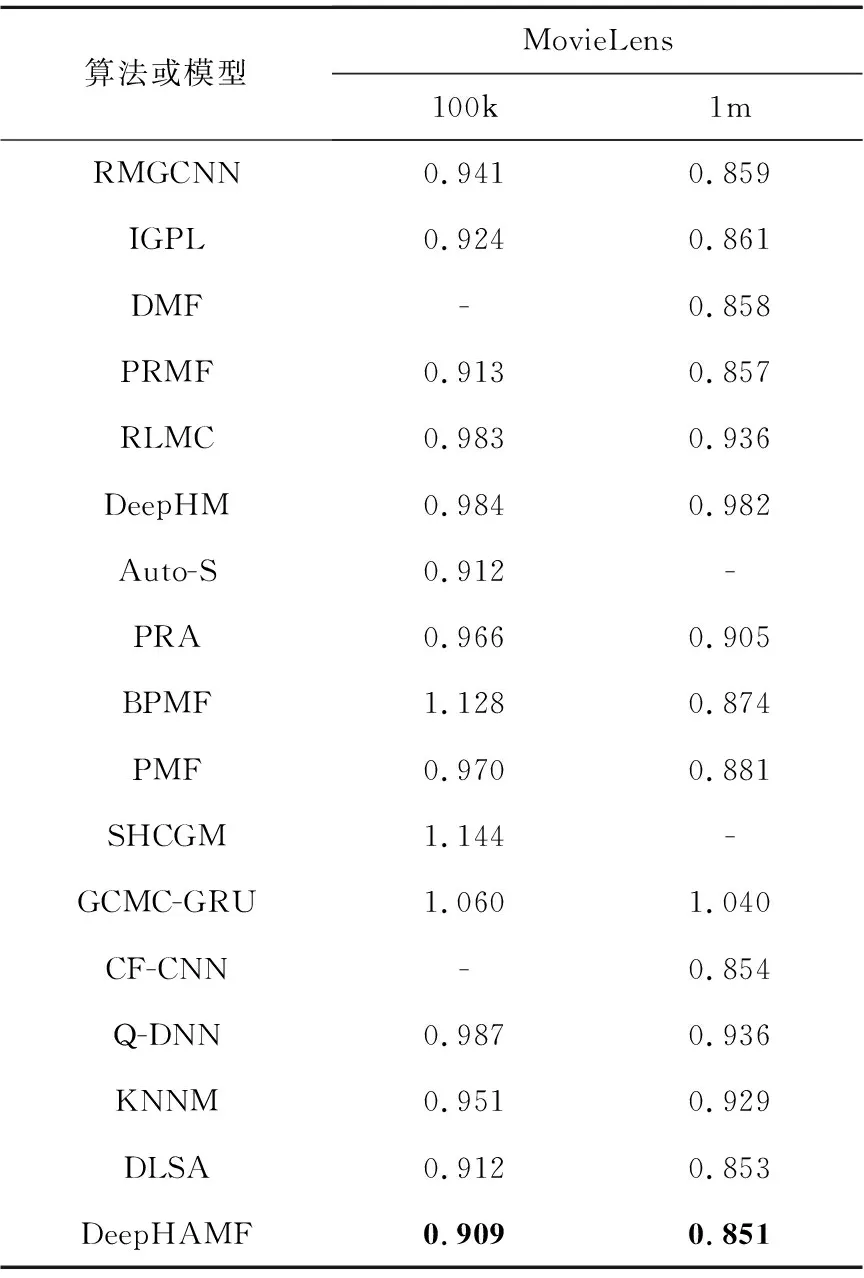
Table 3 Experimental results of DeepHAMF compared to 5-cv rating recommendation algorithms(without text information) on RMSE metrics
表4给出DeepHAMF模型与其他利用文本信息的评分算法进行对比的结果。根据表4的实验结果可知,在MovieLens 100K数据集上,DeepHAMF模型的结果不是最优的。原因是100k数据集相对来说较小而且数据还有一定的稀疏性,导致用户和项目之间的交互信息较少,利用文本信息能够有效刻画用户的偏好,而DeepHAMF没有利用文本信息,故无法充分获取用户的个性化偏好信息。但是,DeepHAMF模型在MovieLens 1M上取得了较好的实验结果,这表明当数据量较大时,即使不使用文本信息,该模型也能够充分挖掘用户的偏好信息而获取较好的推荐效果。与基于注意力的算法(包括DLSA和AFM等算法)相比,DeepHAMF模型拥有较好的结果,这也表明本文设计的注意力模块确实有效。此外,通过表3和表4可以发现,加入文本信息的算法的整体效果要比无文本信息的算法好,但DeepHAMF模型还是能够取得更好的效果。
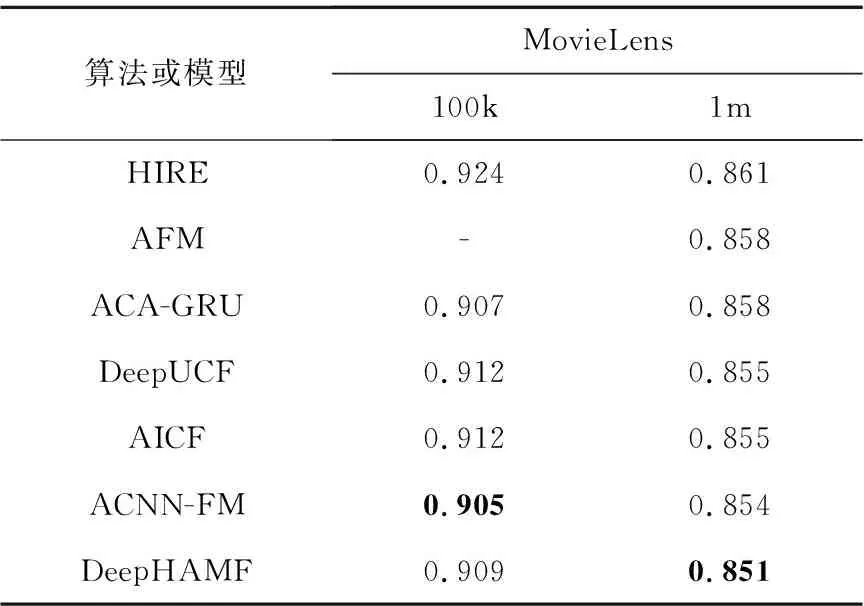
Table 4 Experimental performance of DeepHAMF compared to 5-cv rating recommendation algorithms(based on text information and attention mechanism)
为了验证DeepHAMF模型各个模块的效果,本文进行了消融实验(十交叉验证),对DeepHAMF模型各个模块的作用进行验证。相关模块命名为:自注意力层(DeepHAMF_att)、层次注意力层(DeepHAMF_hatt)和残差层(DeepHAMF_res)。消融实验结果如图2和图3所示。

Figure 2 Results of ablation experiment on 100k dataset图2 100k数据集上消融实验结果
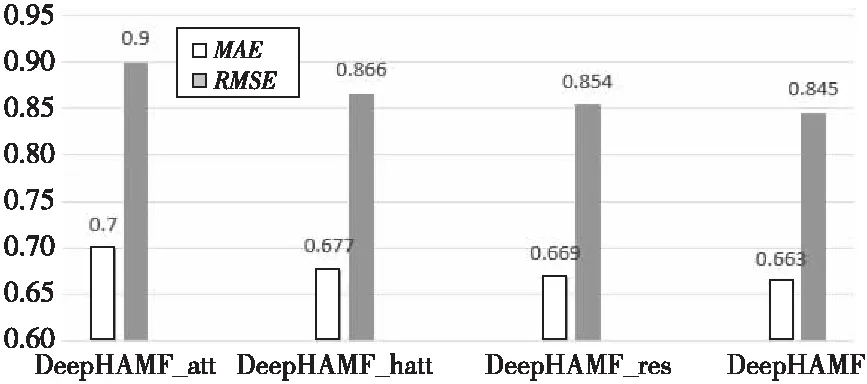
Figure 3 Results of ablation experiment on 1m dataset图3 1m数据集上消融实验结果
根据图2和图3的实验结果可知,DeepHAMF模型的推荐性能逐步提升,层次注意力层和残差融合层的实验结果相比其他模块提升比较明显。原因是因为在层次注意力层不仅通过矩阵分解获得用户的显式偏好信息,还利用注意力捕获用户潜在偏好信息;残差融合层则是对这些模块进行拟合,以充分获得用户的偏好信息。
根据以上实验可知,DeepHAMF对用户与项目的交互信息进行挖掘,以获得用户的偏好信息,然后将其运用于评分推荐中。相比于其他机器学习和深度学习评分预测算法,DeepHAMF拥有更高的推荐精度。
5 结束语
为了充分挖掘用户个性化偏好信息,以达到较好的推荐效果,本文提出了一种名为深度层次注意力矩阵分解(DeepHAMF)的新型推荐模型。该模型可以充分利用用户的评分数据挖掘出用户个性化偏好信息,即使数据稀疏也具有良好的推荐能力。由于添加文本信息可以很好地提升推荐效果,在后续的工作中,将对DeepHAMF模型进行改进,通过添加相关文本信息和算法使其在评分推荐性能上有更好的提升。
