基于PoseC3D的网球动作识别及评价方法*
2023-02-08周升儒陈志刚邓伊琴
周升儒,陈志刚,邓伊琴
(中南大学计算机学院,湖南 长沙 410083)
1 引言
随着中国经济的不断发展,人民群众的生活水平不断提高,网球运动逐渐从贵族运动演变成了普通群众的运动。由于网球运动在中国的热度与关注度不断地上升,许多高校将网球运动作为基础的体育教学课程。目前高校的网球教学依赖于体育教师的主观观测与指导,国内的主流网球教学方式有快易教学法、渐进法及异步教学法,国外的有多元智慧法和游戏教学法等[1]。以上方法虽然能够有效地提升网球教学质量,但是这些方法严重依赖于网球教师的专业能力,其标准严重依赖于教师的主观评价,客观性较差。而且通过个人的视觉观测来对网球动作进行评价和教学需要花费大量的时间成本和人力成本。因此,提出一种量化的、自动化的网球动作识别及评价方法具有重要的应用价值和现实意义。
随着计算机视觉技术的发展[2,3],已有许多研究尝试通过基于计算机视觉的方法[4]来对人体运动进行分类与评价。目前主流的动作分类与行为识别方法主要有动作识别模型、时序动作检测模型、时空动作监测模型和基于骨骼关键点的动作识别模型[5 - 7]。刘凯源[5]使用了基于C3D(Convolutional 3D network)的方法来对实验室人员的不安全动作进行识别,虽然C3D模型的计算效率高且推断速度快,但是计算颗粒度方面不如其他动作识别模型细致,并不适用于细粒度的网球动作分类与评价。毛堃等[6]使用了Kinect传感器获取人体姿态的深度图形数据,对人体的上肢康复运动进行了评价,但由于来自阳光直射的红外线强度高于Kinect的红外发射器强度,极大地影响了传感器的红外线,从而导致深度流计算失准,并不符合网球动作评价所限定的户外场景。Ren等[7]提出了一种基于三维骨架的深度学习动作识别模型,但三维的人体姿态估计对设备和机器的性能要求十分高,无法满足网球动作的识别与评价的实时性要求。
基于网球动作识别与评价的需求,本文采用ResNet-50[8]来获取人体骨骼关键点数据和检测网球动作,然后将获取到的人体骨骼关键点序列输入PoseC3D(Pose Convolutional 3D network)[9]。将网球动作分为6类:发球、正手击球、反手击球、高压球、削球和网前截击。对分类完的相应动作使用动态时间规整DTW(Dynamic Time Warping)算法进行评价,建立姿态估计与动作分类和评价的混合模型对网球学员的网球动作进行评价,极大地降低了网球教师的工作量与工作难度,有效地提升了网球教学的质量,使网球教学更为量化和自动化。
2 网球动作识别和评价的理论及方法
2.1 基于ResNet-50的姿态估计
人体姿态估计是通过深度学习方法对RGB图像或视频进行处理,从而估计出人体骨骼关键点对应的位置。人体姿态估计的方法主要分为自顶向下的方法和自底向上的方法。自顶向下的方法先识别出人体,然后对每个识别出的人体进行姿态估计。自底向上方法是先识别出人体的骨骼关键点,然后根据算法与模型对人体骨骼关键点进行连接,例如OpenPose[10]使用人体骨骼关键点亲和场(Part Affinity Fields)与人体骨骼关键点置信图(Part Confidence Maps)进行关键点的连接,从而得到最终的人体骨骼关键点识别结果。
本文采用基于COCO数据集训练的ResNet-50姿态估计模型来识别和提取网球运动视频的人体骨骼关键点坐标。COCO数据集[11]全称为Microsoft Common Objects in COntext,简称MS COCO,由32.8万幅图像组成,是一个集目标检测、实例分割、人体骨骼关键点估计和字幕生成于一体的大规模数据集。基于COCO数据集的人体骨骼关键点如图1所示,人体骨骼关键点与人体各部位的对应关系如表1所示,对人体骨骼关键点序列进行处理从而获得最终的网球动作分类与评价。
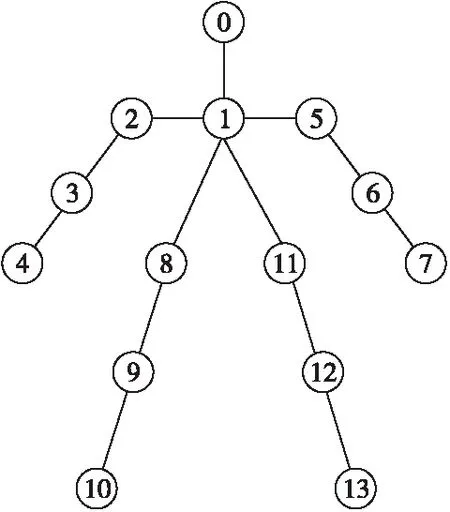
Figure 1 Keypoints of human skeleton图1 人体的骨骼关键点
表2列出了各开源人体姿态估计模型在COCO数据集上的平均性能和平均精度,模型的输入大小均为(3,192,256),其中3表示红色、蓝色、绿色3个颜色通道,192表示图像的宽,256表示图像的长。模型的平均性能是在NVIDIA GeForce GTX 1660 SUPER GPU,Intel® CoreTM i7-8700CPU@3.20 GHz CPU上测出的。从表2可以看出,ResNet-50的平均精度比ResNet-101的低1%,但是在平均性能上比ResNet-101的要高21 fps/s;与性能最差的OpenPose相比,ResNet-50不仅平均精度高了8%,平均性能更是其6倍多。在各开源模型中,权衡模型的精度与性能之后可知,ResNet-50相比较其他模型都更具有优势。因此,本文采用ResNet-50人体姿态估计模型。

Table 1 Correspondence between keypoints of human skeleton and parts of human body

Table 2 Performance of open source human pose estimation models
2.2 基于PoseC3D的动作识别模型
基于姿态估计的人体动作识别方法具有较强的鲁棒性和稳定性,近年来出现了许多基于姿态估计的动作识别方法。ST-GCN(Spatial Temporal Graph Convolutional Network)[12]的原理是将时序卷积网络与图卷积网络相结合,将人体姿态识别所获取的骨骼点序列构造成时空图的方式来提取特征,然后进行动作分类。AGCN(two-stream Adaptive Graph Convolutional Network)[13]总结了ST-GCN的相关缺点,提出了一种自适应的图神经网络,而对不同的动作时,骨架点中所关注的部位也会发生变化,从而提高了整体模型的鲁棒性。但基于GCN(Graph Convolutional Network)的方法既不能很好地处理人体骨骼点序列中的噪声,也不具备较好的泛化性。
Duan等[9]提出的PoseC3D是一种基于CNN(Convolutional Neural Network)的动作识别模型。该模型首先选择二维的人体姿态估计作为模型的输入,然后将提取好的二维人体姿态信息生成为三维热图堆叠作为3D-CNN输入,最终由3D-CNN输出动作的分类结果。PoseC3D网络结构如图2所示,其中,C为关键点个数,T为时序维度,即连续帧热图的数量,H和W分别为热图的高度和宽度。网络的输入为17×32×56×56大小的三维热图,经过若干层卷积操作后输出大小为32×32×56×56的特征,经过ResNet Layer2、ResNet Layer3、ResNet Layer4输出大小为512×32×7×7的特征,再经过池化得到512维的特征向量,最后输入到全连接层执行动作的分类。
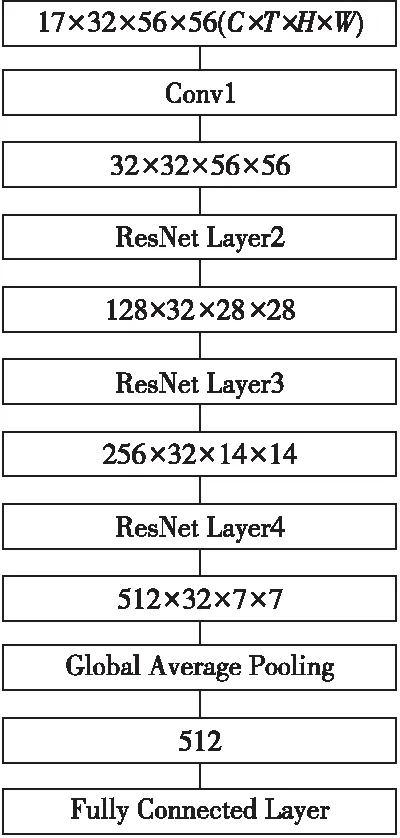
Figure 2 Network structure of PoseC3D图2 PoseC3D的网络结构
2.3 基于动态时间规整的动作评价算法
正文动态时间规整DTW是一种衡量2个长度不同的时间序列相似度的方法[14],是一种基于动态规划的算法,近年来主要应用在时间序列的匹配中。
在时间序列相似性度量中,点对点匹配的相似度计算极易受到序列的移位、错位的影响。使用动态时间规整的方法避免了这一问题。动态时间规整使用了动态规划的方法,即使2个动作序列的长度不一,也可以将2组序列进行对齐和匹配,从而得出动作的评分。如图3所示,2个长度相同的时间序列A={a1,a2,…,a16}与时间序列B={b1,b2,…,b16}进行匹配,A与B长度相等,但在实际的匹配中2个时间序列的长度可以不相等。时间序列之间的虚线表示这2个时间序列相似的点,动态时间规整算法通过相似点之间的和来计算2个时间序列之间的相似度。
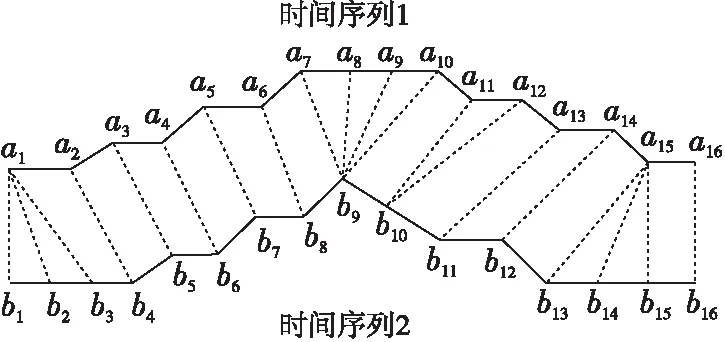
Figure 3 Time warping of two time series图3 2个时间序列的规整匹配
在相似度计算中,A与B之间的相似度计算如式(1)所示:
dij=
(1)
其中,17为通过ResNet-50姿态估计模型所获得的人体骨骼关键点数,每个关键点通过二维坐标来记录;dij表示A中的第i帧与B中的第j帧中的人体17个骨骼关键点之间的总距离。根据式(1)可以得出2个人体骨骼关键点序列之间的DTW距离,如式(2)所示:
(2)
其中,n为时间序列A的长度,m为时间序列B的长度。通过式(2)可以计算出时间序列A与时间序列B之间的规整距离。在DTW距离与网球教练对该动作的评分之间建立起映射关系,映射关系公式如式(3)所示:
Score=100-ρ×DTW(A,B)β
(3)
其中,分数Score的计算为百分制,DTW距离经过归一化处理后为一个0~1的浮点数,ρ和β为确定DTW距离与分数之间映射关系的参数。
2.4 网球动作识别及评价模型
网球动作识别及评价模型由人体姿态识别模型、PoseC3D模型与动作评分算法3个部分组成,如图4所示。

Figure 4 Tennis action recognition and scoring model图4 网球动作识别及评分模型
在人体姿态识别模型中,程序首先调用YOLOv3生成人体检测框,对检测框中的人体使用ResNet-50姿态估计模型生成人体骨架(.json)文件;然后,将(.json)文件通过数据预处理转化为PoseC3D模型可以读取的(.pickle)文件并将(.pickle)文件输入PoseC3D模型中得到网球动作的类别和置信度;最后,根据网球动作的类别通过DTW算法来对该类别的网球动作进行评价。
3 实验验证
3.1 数据集
本文实验所采用的数据集是在网球场采集的视频。视频分辨率为1920×1080,帧速率为30 fps/s。为了保证人体姿态估计模型所输出的人体二维骨骼关键点的准确性,拍摄的角度为网球中线旁45度角,其中发球、反手、削球和正手动作中运动员居于网球底部中线位置;高压球动作中运动员居于摄像头所拍摄的网球场的中间位置;削球动作中运动员居于摄像头所拍摄的右半部分网球场的中间位置。将国家二级网球运动员作为拍摄的对象采集标准动作;将网球初学学员作为拍摄对象采集不标准动作。
3.2 网球动作分类及处理
3.2.1 网球动作分类
根据网球运动的基本技术动作,本文将此模型的网球动作主要分为6类:发球、正手击球、反手击球、高压球、削球和网前截击,图5给出了这6类网球动作的标准姿势示意图。

Figure 5 Six types of standard postures of tennis action图5 6类网球动作标准姿势示意图
3.2.2 网球动作视频细粒度处理
动态时间规整算法能对2个长度不同的时间序列进行匹配,但是时间序列的起始点和终止点对动态时间规整算法的准确度有很大的影响。为了保证网球动作视频序列首尾的一致性,本文对网球动作视频数据集进行了细粒度的划分,按照网球教练对网球技术动作的要求对网球动作的起始点与终止点制定了规则,如表3所示。

Table 3 Rules of tennis action division
将网球原始动作视频输入ResNet-50人体姿态估计模型中,将获取到的人体骨骼关键点按照网球动作划分规则来计算细粒度动作的起始点与终止点,得到了更为准确的网球子动作数据集。
3.3 PoseC3D模型训练
3.3.1 输入数据预处理
PoseC3D模型的输入是为(.pickle)数据格式的文件,所以需要对数据进行预处理并划分出训练集和测试集。
本文使用pose_extraction.py对网球动作视频进行预处理。该程序中集成了ResNet-50姿态估计模型与YOLOv3目标检测模型,将原始的(.mp4)文件生成为(.pickle)文件。(.pickle)文件的部分参数如表4所示。

Table 4 Parameters of pickle file
将生成的包含6个网球子动作的221个视频生成为(.pickle)文件,并按照7∶3的比例划分出训练集和测试集,将训练集和测试集按照划分比例分别生成为.pickle文件。
3.3.2 模型训练
为了提高模型在复杂的网球运动环境中对动作分类的鲁棒性和性能,本文采用Windows 11操作系统,处理器采用Intel® CoreTM i9-12900K CPU@3.90 GHz,显卡采用双路NVIDIA GeForce RTX 3090Ti,64 GB DDR5内存,采用Python3.7编程设计语言完成应用模型的设计与搭建和应用程序的开发。为了使模型的人体姿态估计更加地稳定和准确,YOLOv3检测框的置信度阈值设置为0.8。
在动作分类的实验中,Top1准确率与Top5准确率是极其重要的指标,如式(4)所示:θ为所有的动作种类,action为此次预测所预测的种类,P1,P2,…,Pφ为此次预测的分类结果对应的概率。如果P1~Pφ中所预测的概率最大的动作为action,则此次Top1预测是准确的。
P(action|θ)=arg max{P1,P2,…,Pφ}
(4)
Top5准确率是判定该动作分类概率最大的前5个结果,如果前5个结果包含了预测正确的结果,则Top5的该次预测是准确的。如式(5)所示,首先将预测的动作种类按概率进行排序,排序后的结果为Pr。如式(6)所示,如果预测的前5类动作中包含action,则此次Top5预测是准确的。
Pr=sort{P1,P2,…,Pφ}
(5)
P1≤P(action|θ)≤P5
(6)
用预处理后的数据训练PoseC3D网络,设置轮次数为150,批大小为16,初始学习率为0.2。在模型的训练过程中自适应调整学习率,以获得更好的训练效果。
Top1准确率、Top5准确率、平均类别准确率和学习率伴随迭代次数的变化如图6和图7所示。

Figure 6 Accuracy rates of Top1 and Top5图6 Top1准确率和Top5准确率

Figure 7 Average category accuracy and learning rate图7 平均类别准确率和学习率
从图6可知,随着迭代次数的增加,Top1准确率与Top5准确率均上升。大概在迭代次数为140次的时候,Top1准确率收敛至0.937 5,Top5准确率收敛至0.984 5。
从图7可知,随着迭代次数的增加,平均类别准确率上升。在迭代次数为140次的时候,平均类别准确率收敛至0.944 4。
3.3.3 模型对比实验与结果分析
将预处理后的数据用于基于骨骼关键点的人体动作识别模型ST-GCN与AGCN中。在目标检测模型为YOLOv3,人体姿态估计模型为ResNet-50的条件下,对比实验测试了3种模型在网球动作分类中的效果,测试集为6类网球基本技术动作,其中每类动作20个视频,共120个网球动作视频,对比实验绘制了3种基于人体骨骼关键点动作识别模型在测试集上识别6类网球动作的混淆矩阵,如图8~图10所示,动作预测的Top1准确率与Top5准确率如图11所示。
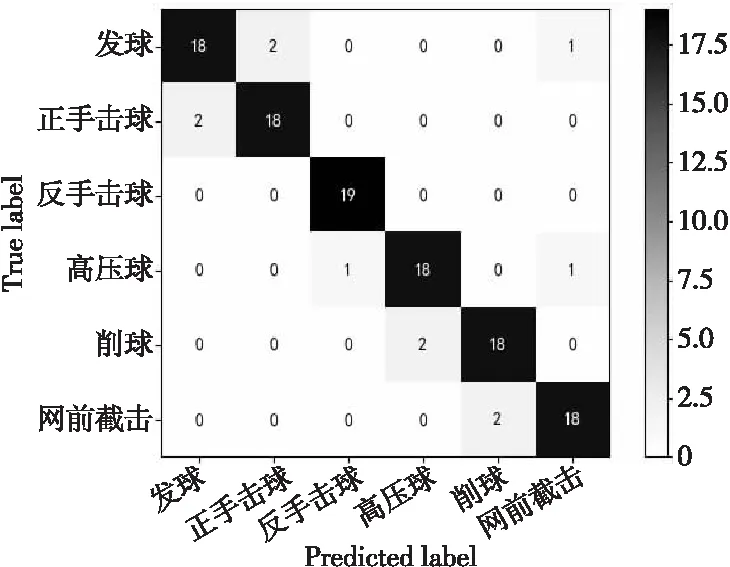
Figure 8 Confusion matrix of PoseC3D model 图8 PoseC3D模型混淆矩阵
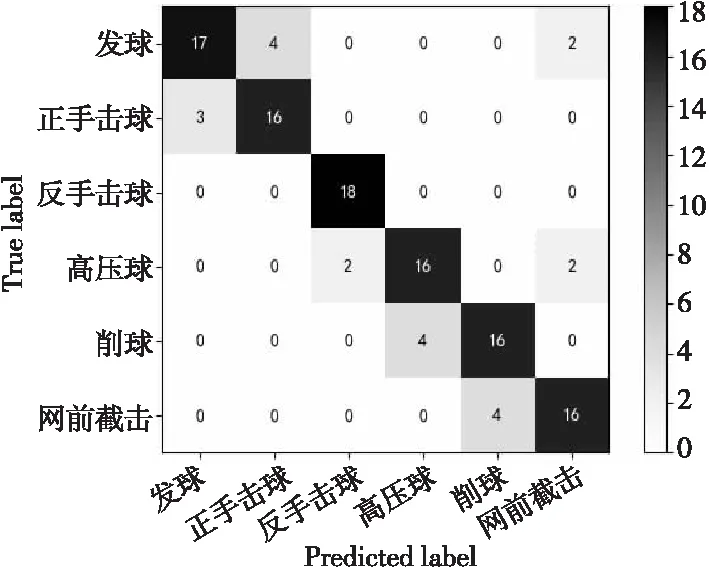
Figure 9 Confusion matrix of AGCN model 图9 AGCN模型混淆矩阵

Figure 10 Confusion matrix of ST-GCN model 图10 ST-GCN模型混淆矩阵

Figure 11 Comparison of three models图11 各模型效果对比
从图11可以看出,PoseC3D模型的Top1准确率为0.908 1,Top5准确率为0.978 0;AGCN模型的Top1准确率为0.825 0,Top5准确率为0.956 6;ST-GCN模型的Top1准确率为0.766 7,Top5准确率为0.929 6。在基于网球动作数据集的动作识别模型中,使用3D-CNN的PoseC3D模型在网球动作分类效果上优于使用GCN模型的ST-GCN与AGCN。
3.4 基于动态时间规整的网球动作评分算法
3.4.1 实验步骤
根据动作的分类结果和动作的人体骨骼关键点数据,本文使用DTW算法来对动作进行评价。算法设置动作评价的满分为100分,具体的算法流程如算法1所示。算法的输入序列A为待评价的人体骨骼关键点序列,B为标准网球动作子动作的模板序列。算法的第1步是建立A={a1,…,an}的矩阵d。算法的第2步是计算矩阵d的值d(i,j),即序列A第i帧与序列B第j帧之间各个骨骼关键点之间的距离和,本文使用欧氏距离来计算2个关键点之间的距离。算法的第3步是在矩阵中寻找一条规整路径D(n,m)使A与B之间的距离最小,该路径的起点是(1,1),终点是(n,m)。算法的第4步是计算动作的最终评价得分,通过建立DTW距离与网球教练对该动作的评分之间的映射关系,本文设置式(3)中的α值为92.4,β值为0.97。
在实际的使用当中,如果PoseC3D判定该网球动作为某类动作,则会用相应动作的模板序列与之进行比对。
算法1DTW算法
输入:待评分序列A={a1,…,an},模板序列B={b1,…,bm}。
输出:动作评价分值。
Step1建立n×m的矩阵d。
Step2根据欧氏距离公式求得d(i,j),d(i,j)为骨骼关键点序列A第i帧与骨骼关键点序列B第j帧各点之间的距离和。
FORiINrange(n)
FORjINrange(m)
d(i,j)=EuclideanDistance(ai,bj);
ENDFOR
ENDFOR
Step3通过动态规划的思想求得从矩阵起点位置(1,1)到矩阵终点位置(n,m)的最短路径D(n,m)。
D(1,1) =d(1,1);
FORiINrange(n)
FORjINrange(m)
∥状态转移方程
D(i,j)=min(D(i-1,j),D(i,j-1),D(i-1,j-1))+d(i,j);
ENDFOR
ENDFOR
Step4将最短路径D(n,m)进行百分制转化,得到最终的动作评分分数。
Score= 100-92.4*D(n,m)0.97
接下来,本文选用了3.2节中的6类网球基本技术动作中的高压球动作作为动态时间规整算法的测试项,采用算法1对高压球动作进行评分,得到的评分结果如图12所示,得分为61.86分。

Figure 12 Scoring result of high pressure ball图12 高压球动作评分结果
3.4.2 评分算法实验结果及分析
本节对基于动态时间规整的网球动作评分算法的有效性进行验证。如表5所示,算法对学员1~学员10共10位学员的6类网球基本技术动作进行测试,并通过教练和评分算法对其进行打分,得分结果向上取整。教练评分为3位专业网球教练对学员的网球动作打分的平均值。

Table 5 Scoring results
根据表5的评分结果,以教练评分与算法评分作为样本变量来进行独立样本T检验。首先建立假设检验来判断算法评分与教练评分是否存在差异:H0:μ1=μ2,表示教练评分与算法评分无显著差异。H1:μ1≠μ2,表示教练评分与算法评分有显著差异;显著性水平α=0.05。独立样本T检验的分析结果如表6所示。
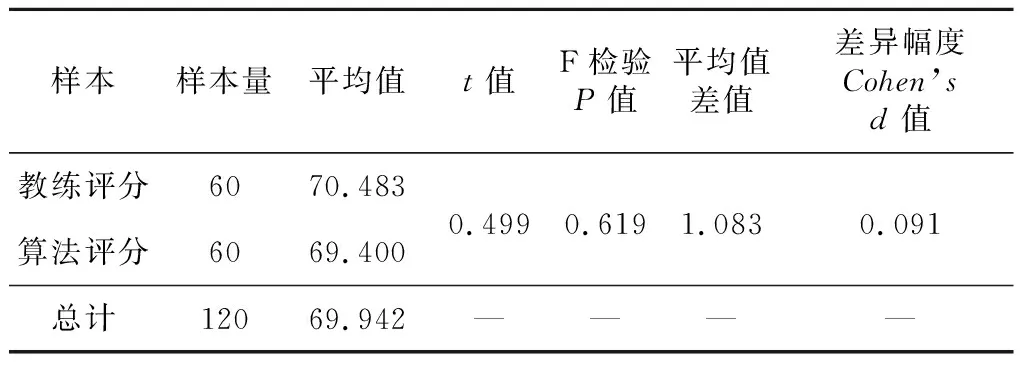
Table 6 Analysis results of independent sample T test
由表6可知,教练评分与算法评分的均值分别为70.483与69.400,F检验的结果P值为0.619≥0.05,因此统计结果不显著,说明教练评分样本与算法评分样本不存在显著差异,其差异幅度的Cohen’sd值为0.091,表明差异幅度非常小。
通过对教练评分与算法评分的数据分析可知,2类评分方法在对6类网球基本技术动作的评分上差异并不明显,算法对学员的评分符合教练对动作的评分要求,能够满足网球教学的要求。
4 结束语
本文提出了一个姿态估计、动作识别和评分模块的混合模型,首先通过基于ResNet-50的人体姿态估计模型从网球运动视频中提取人体骨骼关键点,基于网球动作数据集PoseC3D模型将网球动作进行分类,最后通过DTW算法来对子动作进行评分。模型中的PoseC3D的训练结果和DTW的评分结果表明了该方法具有一定的可行性。且基于骨骼关键点的动作识别模型能够在运动速度快、粒度较细的网球动作分类中达到不错的效果。但是在网球动作的识别中,无论是基于GCN或是基于CNN的方法,均仍有部分局限性,其准确性极其依赖数据集的规模,下一步的研究会扩充数据集,并将强化学习的方法[16 - 18]融合进PoseC3D模型中以提高其分类的准确性。
