基于CNN与Transformer混合模型的口罩人脸识别方法*
2023-02-02姜绍忠姚克明王中洲郭复澳
姜绍忠, 姚克明, 陈 磊, 王中洲, 郭复澳
(江苏理工学院 电子信息工程学院,江苏 常州 213001)
0 引 言
为了防止新型冠状病毒肺炎(COVID—19)疫情扩散,在公共场合人们都会佩戴口罩,这对人脸识别造成了巨大的挑战。自Turk M等人提出Eigenface[1]以来,人脸识别一直是研究的焦点。深度学习使模型可以学习到用于人脸识别的高鉴别度的面部特征。口罩遮挡给人脸识别带来更大的挑战,由于鼻子、嘴巴这2个重要人脸特征被破坏,导致超过半数人脸特征不可用,并且给人脸关键点位置信息带来大量噪声,因此,口罩人脸识别成为人脸识别算法的一大难题[2]。用深度学习解决口罩人脸识别的难题,首先想到的就是通过增强数据集来提高现有算法对口罩人脸识别的准确率,文献[3]通过混合戴口罩和不戴口罩的人脸数据集来对模型进行训练以提高现有人脸识别模型性能。文献[4]利用Triplet loss对在混合数据集上预训练的模型进行微调,进一步提高人脸识别模型对口罩人脸识别的准确率。随着注意力机制在视觉邻域被广泛地研究,其思想也被带到口罩人脸识别的研究中来,文献[5]采用裁剪,并结合注意力模块使网络更多地关注眼部周围地特征,该方法能够很好地提高对口罩人脸识别的准确率,但却降低了无遮挡场景下人脸识别的性能。文献[6]采用双路的训练策略,提出上半人脸分块注意力,通过这种训练策略引导网络更多地关注到上半人脸。
近一年来,Transformer模型由于具有自注意力(self-attention)模块强大的全局建模能力,而在计算机视觉中取得了显著的成效,但模型的参数量大,空间复杂度高,导致Transformer模型需要大量的数据进行训练,训练成本非常高,且由于缺乏正确的归纳偏置,模型的泛化能力较差,难以移植,这也导致难以将模型部署到下游任务中去。将Transformer与卷积神经网络(convolutional neural network,CNN)结合能够取得更好的效果[7~10]。
本文提出一种基于CNN与Transformer混合模型的口罩人脸识别方法,该方法能兼顾戴口罩人脸识别和不戴口罩人脸识别任务。主干特征提取网络使用的是CNN与Transformer的混合模型CoAtNet[11],在卷积模块引入空间注意力机制模块,使模型能够更多地关注到未被遮挡的人脸部分,提取更多用于身份识别的鲁棒信息,构建分类器时使用了Sub-center Arcface[12]损失函数,进一步优化了模型的识别效果。该方法能结合CNN与Transformer的优点,提高模型的泛化能力和识别准确率。
1 CNN与Transformer的混合模型
综合考虑模型的泛化能力和模型的容量,最终采用如图1所示的架构,输入的图像为112×112三通道的三原色(RGB)彩色图像,其中,Stage0为经典卷积,Stage1和Stage2阶段为堆叠的MBConv模块,经过卷积模块后,图像进入空间注意力模块,然后,送入相对自注意力模块(relative self-attention block)Stage3和Stage4,最后,将图像表示为特征向量,送入Sub-center Arcface分类器中,对人脸进行分类。
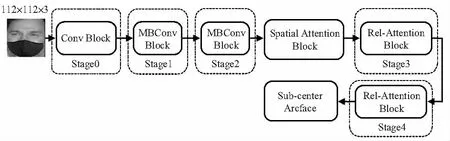
图1 整体结构
1.1 主干特征提取网络
谷歌在MobileNet[13]架构中引入了深度可分离卷积(depthwise separable convolution),由于使用1×1卷积,需要的计算量大大减小。在MobileNetV2[14]中又引入了倒置残差(inverted residuals)和线性瓶颈(linear bottleneck)层。卷积操作可表示为
(1)
其中,xi,yi∈RD,分别为在位置i上的输入与输出,L(i)为i的邻域,也即为卷积处理的感受野。
Self-attention的感受野是整个特征图,并根据(xi,yi)之间重新归一化的成对相似度计算权重
(2)
式中G为全局空间,Ai,j为注意力权重。以上2个公式有以下几个特性:
1)Depthwise卷积核是一个静态值的输入独立参数,而注意力权重动态地取决于输入的表示。因此,自注意力更容易捕捉不同空间位置之间复杂的关系交互,是处理高级概念时最想要的属性;
2)注意给定任何位置对(i,j),对应的卷积权重只关心它们之间的相对位移,即i-j,而不是i或j的具体值。由于使用绝对位置嵌入,标准Transformer(ViT)缺少此属性,这部分解释了当数据集不是很大时,CNN通常比Transformers更好;
3)感受野的大小是自注意力和卷积之间最重要的区别之一。Transformers拥有全局感受野,然而,一个大的感受野需要更多的计算,在全局注意力的情况下,复杂性图像尺寸的平方倍,这是应用自注意力模型的基本权衡。
综上所述,最优架构应该是自注意力的输入同时具有自适应加权和全局感受野特性以及CNN的平移不变性。所以选择在SoftMax初始化之后或之前将全局静态卷积核与自适应注意力矩阵相加,混合卷积和自注意力的计算公式可表示为
(3)
1.2 空间注意力机制
MBConv中含有通道注意力SE(squeeze and excitation)[15],通道注意力部分能使更多有利于识别任务的特征通道的权重得以增加,其他特征通道的权重得以抑制。然而,遮挡人脸识别任务中,更应该重点关注空间上的信息,例如眼睛、眉毛、额头部分的纹理信息,因此,引入了空间注意力(spatial attention)机制来加强特征提取网络。
空间注意力机制的详细描述如下,对于输入的特征图F∈RC×H×W使用尺寸为(H,1)的Pooling kernel沿着水平方向做平均池化操作,使用尺寸为(1,W)的Pooling kernel沿着垂直方向做平均池化操作,因此,高度为h时,第c个通道的输出为
(4)
同样的,宽度为w的第c个通道的输出为
(5)
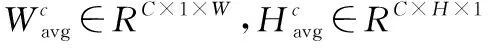
F′=F⊙W′⊙H′
(6)
其中,⊙为对应位置元素相乘,F′为注意力输出。
通过对水平方向和垂直方向上的平均池化,空间注意力模块捕获到这两个方向上的长依赖关系,并且其中的一个方向上保存了另一个方向上的精确位置信息,这有助于网络定位到感兴趣的区域,如图2所示。
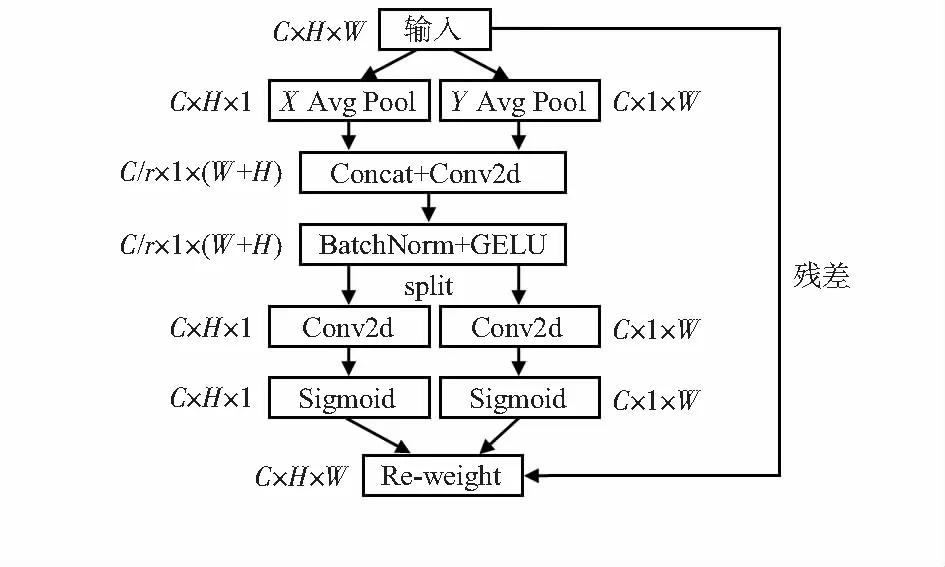
图2 空间注意力模块
1.3 改进的Arcface损失函数
ArcFace经过特征提取网络提取到的人脸特征向量x映射到超球体上,并压缩相同人脸特征向量x的余弦距离,扩大不同人脸特征向量x的余弦距离
(7)
其中,s为超球体的半径,θ为权重W和人脸特征向量x之间的夹角,yi则是第i个人的标签,且权重W与人脸特征向量x都要进行归一化。ArcFace通过在此夹角上添加一个间距m,进一步增大了不同人脸特征之间的余弦间隔,这样做可以使模型学习到的特征具有更强的判别能力。尽管ArcFace已经显示出其在高效和有效的人脸特征嵌入方面的能力,但这种方法假设训练数据是干净的。然而,事实并非如此,尤其数据集规模较大时。在本文使用了Sub-center ArcFace,它提出了为每个身份使用子类的思想,放宽了类内约束,可以有效的提高噪声下的鲁棒性。
Sub-center ArcFace具体实现的方式是,为每个身份设置一个足够大的K,基于对xi∈R512×1上嵌入的特征和所有的子中心W∈RN×K×512的L2归一化步骤,通过矩阵乘法WTxi得到子类的相似得分S∈RN×K,然后对Subclass-wise的相似度得分S∈RN×K采用最大池化得到类的相似度S′∈RN×1。Sub-center ArcFace损失函数可以表示为
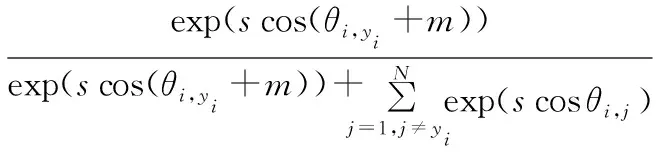
(8)
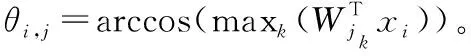
2 实验过程与结果分析
本节将介绍本文使用到的数据集,以及对数据集所做的处理,模型训练方法,然后分析实验结果,验证本文算法的有效性。所述的模型在Windows10下进行训练,使用GPU为单个NVIDIA GTX 3060,训练时的批量大小设置为64,优化器采用SGD,初始学习率设置为0.01。
2.1 数据集
本文使用了一个给标准人脸添加口罩的工具,MaskTheFace通过定位人脸关键点,计算人脸角度,有效地为人脸模拟添加口罩,将已有的大规模人脸数据集转换为人工合成的口罩人脸数据集,如图3所示,由于现有真实世界人脸口罩数据集规模较小,只适合用来做模型的评估,而不能用于训练。CASIA-WebFace[16]是最常用的人脸识别训练集之一,是一个包含10 575不同个人的494 414张人脸图片的大规模人脸数据集。在添加口罩之前先使用MTCNN[17]将CASIA-WebFace当中的人脸图片对齐并裁剪为112×112大小,可以避免人脸关键点检测时因为口罩遮挡而失效。验证集采用MaskTheFace在LFW[18]上生成的口罩人脸数据集LFW-Masked,以及真实的口罩人脸数据集MFR2。MFR2是一个包含269张人脸图片,53个ID的小规模真实人脸数据集,其中,每一个人都包含了佩戴口罩和未佩戴口罩的人脸图片。本文在谷歌上搜索了一些图片将该数据集扩充到76人,518张图片作为真实口罩人脸测试集,命名为RMF(real masked-face)。

图3 数据集准备
2.2 实验结果
基于CNN的模型选用Mobilefacenet[19]和Resnet50[20],基于Transformer的模型选用ViT损失函数选用Arcface。将其与本文提出的算法作为对比。如表1所示,可以看出,不仅在未带口罩的人脸识别上,本文算法在准确率上有所提升,在佩戴口罩的人脸识别上,本文算法远远优于目前最先进的算法。其中,ViT模型的识别效率较低,是因为采用的CASIA-WebFace数据集数据量较少,基于纯Transformer的模型需要大规模的数据和大量的时间进行训练才能达到最优的效果,这无疑增加了大量的成本,由于条件的限制故无法使ViT性能达到最优,也证明了混合模型的优越性。
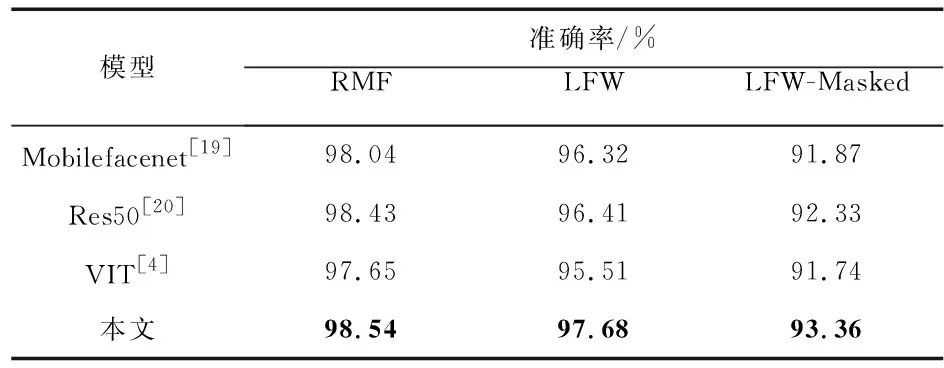
表1 在LFW-Masked和RMF上与最先进方法的比较
2.3 消融实验
在LFW-Masked和RMF数据集上做了消融实验,如表2。具体来说,将CoAtNet作为基线(baseline)网络,然后给网络添加空间(spatial)注意力模块,再将损失函数替换为Sub-center Arcface。实验中均使用相同的设置进行训练。当添加了空间注意力机制后,网络的准确率在LFW-Masked和RMF上分别提升了0.86个百分点和0.67个百分点。此外,在使用了Sub-center Arcface之后模型的准确率在LFW-Masked和RMF分别提升了0.53个百分点和0.51个百分点。本文算法之所以能取得更好地表现,得益于添加的空间注意力机制,使网络的关注点更集中于未被遮挡的人脸特征,且使用的损失函数能够更好地对口罩人脸进行分类。

表2 在LFW-Masked和RMF上的消融实验结果
如表3所示,比较CoAtNet与其他引入卷积操作的Transformer主干网络的模型容量,每秒浮点运算的次数和在RMF上的准确率。本文实验中,将这些模型的Tiny版本,在CASIA-WebFace和WebFace-masked上进行训练,然后在LFW-masked上测试准确率。可以看出,CoAtNet能够很好地结合CNN与Transfomer模型地优点,提高了人脸识别的准确率,并且Transformer模型在有口罩遮挡这种大面积的遮挡人脸识别中能够起到很好的识别效果,且CoAtNet模型的参数量不大,计算复杂度较低,模型的总体性能较其他融合CNN结构的Transformer网络更优。
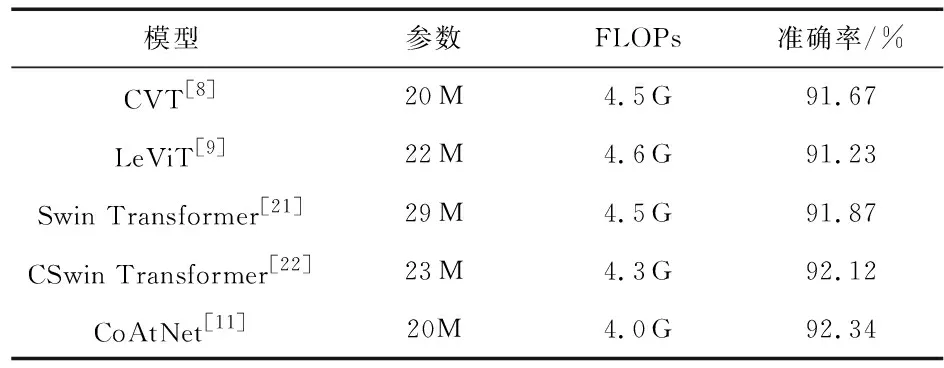
表3 不同混合模型在RMF上的对比实验
3 结束语
本文将CNN与Transformer混合网络用于训练口罩人脸识别模型,在卷积模块引入空间注意力模块,使模型能够更多地关注到未被遮挡的人脸部分,提取更多用于身份识别的鲁棒信息,损失函数使用了Sub-center Arcface,进一步提升了模型识别的精度。该方法很好地结合了CNN与Transformer的优点,提高了模型的泛化能力和识别准确率。分别在LFW和LFW-Masked上的精度达到98.54 %和97.68 %,实验表明,该模型能够同时兼顾戴口罩和不戴口罩的人脸识别。
