基于BLAP 聚类和多粒度犹豫模糊集的售电套餐推荐方法
2023-02-02马愿谦李启源陈汉忠林振智
马愿谦,李启源,陈汉忠,张 智,林振智,杨 莉
(1. 浙江理工大学机械与自动控制学院,浙江省杭州市 310018;2. 浙江大学电气工程学院,浙江省杭州市 310058)
0 引言
随着电力市场化改革的深入和高质量发展理念的贯彻,对用户而言,其不仅要获得可靠和安全的供电服务,还希望获得多样、便捷的售电增值服务;对售电公司而言,也期望通过售电套餐、节能服务等增值服务增强已有用户黏度,并吸引大量新用户[1]。售电套餐是市场环境下售电公司提高收益、获得市场竞争力的必要手段。澳大利亚[2]、德国[3]、加拿大[4]等国家的电力市场已为用户提供了上千种的售电套餐,中国面向工商业[5]和居民用户[6]也设计了多种形式的电价套餐供用户选择,如文献[7]应用演化博弈理论设计了考虑有限理性用户选择行为的定制化电价套餐;文献[8]提出了售电公司峰谷组合电力套餐零售模式,并构建了考虑用户有限理性的电力套餐设计双层优化模型。然而,随着多样化售电套餐的出现,用户的选择信息成本将随之增加,在此背景下,售电公司如何准确、科学地为用户推荐满足其需求的售电套餐是亟须解决的问题。
现有售电套餐推荐方法可分为直接法和间接法。其中,直接推荐方法多数应用于在线推荐平台,即基于用户用电情况,将成本最低的售电套餐推荐给相应用户,如iSelect[2]、Check24[3]、Power to Choose[4]等平台。此外,文献[9]采用自适应k-medoids 和k-means 聚类算法将用户分为用电行为多变和用电行为规律的用户,以用电成本最小为目标,提出了一种实现阶梯电价套餐和阶梯分时电价套餐推荐服务的方法。直接推荐方法简单、易于实施,但这种方法仅考虑了用户电费成本,忽略了用户评价信息的多样性,如绿电、增值服务等。除直接基于成本的推荐方法外,协同过滤算法[10]也是常用的间接推荐方法,如文献[11]采用模糊c 均值聚类算法对用户进行分类,并基于目标用户与所属类别中历史用户的相似度,以及历史用户对售电套餐的评分,获得目标用户的评分,实现售电套餐的推荐;文献[12]以居民用户家用设备耗电特征表征用户的用电特性,设计了基于贝叶斯混合协同过滤算法的居民售电套餐推荐系统。上述协同过滤算法为售电套餐的推荐提供了思路,其中,准确、高效的样本用户聚类是提高推荐准确度的前提。然而,上述聚类方法均需预先设定聚类数,因而聚类效率和准确度较低。尽管上述间接推荐方法考虑了用户的用电成本、行为特性和偏好,但仅考虑了用户熟悉套餐所有属性的情形,忽略了用户评价时表现出的“亦此亦彼”犹豫模糊状态[13],且由于用户对套餐的了解程度有限,很难给出定量精准的评价信息。此外,由于不同用户知识、文化背景及信息来源的差异性,使得不同用户描述其犹豫模糊信息时的语言评价集粒度不同[14],即用户套餐评价信息呈现出多粒度犹豫模糊特性。综上,如何提高用户聚类的准确度和效率,如何真实准确刻画用户评价信息并等值不同粒度下的评价信息,是售电公司准确量化用户满意度,并为用户精准推荐售电套餐所亟须解决的问题。
为此,本文提出一种基于双层邻近传播(bilevel affinity propagation,BLAP)聚类和多粒度犹豫模糊集的售电套餐推荐方法。首先,基于用户画像标签体系和BLAP 聚类的样本用户集划分方法,为判别与新用户相似的用户提供支撑;然后,构建基于多粒度犹豫模糊语言评价集的样本用户集套餐评价矩阵;接着,考虑用户售电套餐属性权重信息的不完整性,采用犹豫模糊语言加权平均算子(hesitant fuzzy linguistic weighted average operator,HFLWAO)集结用户的评价信息,并将其等值为同一粒度下的评价信息;进而基于相似用户的售电套餐等值评价信息,评估新用户套餐满意度,并对售电套餐进行全排序推荐;最后,以中国某地区用户为对象进行算例分析,验证了所提售电套餐推荐方法的准确性和有效性。
1 样本用户集的划分
1.1 用户画像标签体系的建立
不同类型用户的用能和消费习惯存在差异,其差异体现在不同用户对售电套餐的选购结果不同。本文将构建用户的画像标签体系来反映用户的用电特性,为判别与新用户画像相似的用户提供支撑。本 文 基 于 样 本 用 户 集A={A1,A2,…,Ai,…,AI}的 某 月 负 荷 数 据P={PA1,PA2,…,PAi,…,PAI},以月负荷率、月最高利用小时数、工作日和非工作日峰谷差率均值、峰平谷期负载率均值为标签[15],建立用户画像。其中,Ai为第i个用户,PAi为用户Ai某月的 负 荷 数 据,PAi={PAi,1,PAi,2,…,PAi,v,…,PAi,V},PAi,v为 用 户Ai在 某 月 第v个 时 段 的 负 荷 数 据,V为月总时段数,单个时段的单位为h。各标签的物理意义和定义如表1 所示。值得注意的是,表1 中各标签的时间尺度均为月度,具体含义见附录A。

表1 用户的画像标签体系Table 1 Portrait label system of customers
根据表1 标签构建用户Ai的画像m→Ai=[bAi,lr,bAi,mu,bAi,wd,bAi,nwd,bAi,plr,bAi,slr,bAi,vlr],用 于 反映用户Ai的用能习惯,为判别新用户的相似用户,以及为新用户推荐售电套餐奠定基础。其中,bAi,lr、bAi,mu、bAi,wd、bAi,nwd、bAi,plr、bAi,slr、bAi,vlr分 别 为 用 户Ai的月负荷率、月最高利用小时数、工作日峰谷差率均值、非工作日峰谷差率均值、峰期负载率均值、平期负载率均值、谷期负载率均值。
1.2 基于BLAP 聚类的划分方法
考虑到用户数量较大,为降低计算量,须将画像相似的用户进行聚类。由B. J. Fery 和D. Dueck 提出的近邻传播(affinity propagation,AP)聚类[16]通过传递用户画像包含的“责任度”和“可信度”信息来对用户进行聚类,相比于传统k-means 聚类,AP 聚类具有准确度高、无须预先设定聚类数等优点,但聚类结果受用户规模和设定的自我相似度的影响较大[17]。为此,本文在传统AP 聚类基础上,提出基于用户画像标签体系和BLAP 聚类的样本用户集划分方法,以弥补AP 聚类在样本规模较大时聚类结果准确度较低的缺点,实现对与新用户相似用户的精准判别。
首先,为减小用户规模对聚类准确度和效率的影响,对样本用户集A进行局部分区AP 聚类,即第1 层AP 聚类。将A划分为互不重叠的B个 部 分,表 示 为H1,H2,…,Hγ,…,HB,且 满 足H1∩H2∩…∩HB=∅,H1∪H2∪…∪HB=A。通常,当用户规模超过400 时,AP 的聚类效率会迅速降低[17]。因此,每部分用户数应满足fnum(Hγ)<400,其中,fnum(Hγ)表示用户集Hγ中的用户数,Hγ为A的第γ个划分部分。同时,为进一步提高聚类效率,减少第1 层AP 聚类所得聚类中心数,规定每部分用户数不少于200。因此,初始划分的每部分用户数应满足200 ≤fnum(Hγ)<400。基于划分结果,对每部分用户进行AP 聚类。AP 聚类仅须输入各用户间 的 画 像 相 似 度,Ai和Aj画 像 相 似 度s′ρ(Ai,Aj)表示Aj适合作为Ai聚类中心的程度,用户Aj画像的自我相似度s′ρ(Ai,Aj)通常设为Aj与其他用户画像相似度的中值。考虑到Pearson 相关系数[11]能够有效衡量各用户画像间的相关性和密切程度,本文利用该系数刻画各用户间的相似度,即:

然后,考虑到聚类数受自我相似度的影响较大,为进一步提高聚类结果的准确度,降低设置的用户自我相似度对聚类结果的影响,对第1 层聚类所得的聚类中心集进行自适应AP(adaptive affinity propagation,AAP)聚类[18],即第2 层AP 聚类。自我相似度越大,聚类数越多,因此,为了满足不同情况下对聚类数的需求,每次迭代需对用户自我相似度进行更新,更新步长随聚类数的变化而动态调整[18],即:

式中:ZQ(Ai)为聚类数取Q时用户Ai与其对应聚类中心的紧密程度;dout(Ai)为类间平均距离,表示用户Ai与其他类用户画像间距离的平均值;din(Ai)为类内平均距离,表示用户Ai与所属类别内的其他用户画像间距离的平均值;I为用户总数。
比较不同聚类数对应的聚类质量指标ZQ,av,ZQ,av最大时对应的聚类数为最佳聚类数c*,即:

综上,基于BLAP 聚类的样本用户集划分步骤如下。
步骤1:利用式(1)计算A中各用户画像间的相似度。
步骤2:将用户集A划分为B个部分,以每部分内用户画像相似度中值μm,Hγ作为用户自我相似度,即sρ(Aj,Hγ,Aj,Hγ)=μm,Hγ,其中,Aj,Hγ为Hγ中的第j个用户。
步骤3:对每部分用户进行AP 聚类,获得各部分用户的聚类中心集E1,E2,…,Eγ,…,EB。
步骤4:将每部分用户的聚类中心集组成新的用户集Enew=E1∪E2∪…∪EB。若Enew中的用户数大于400,则返回步骤2,否则,转至步骤5。
步骤5:初始化Enew中用户自我相似度sρ(Aj,Enew,Aj,Enew)=μm,Enew,其中,Aj,Enew为Enew中的第j个用户,μm,Enew为Enew中用户画像相似度的中值。
步骤6:对Enew进行AP 聚类,得到稳定聚类数为QEnew,并基于式(2)确定用户Ai是否属于聚类中 心Aj,Enew。
步骤7:基于步骤6 所得聚类结果,利用式(4)计算聚类质量指标。
步骤8:利用式(3)更新用户自我相似度。
步骤9:判断聚类数是否满足QEnew≤2,若满足,则迭代结束,转至步骤10,否则,返回步骤6 继续迭代。
步骤10:比较不同聚类数下对应的聚类质量指标,由式(5)确定最佳聚类数c*。
基于BLAP 聚类的样本用户集划分思路示意图和对应的流程见附录B 图B1 和图B2。需要说明的是,由于第1 层AP 聚类仅是为了得到初始聚类中心集Enew,第1 层AP 聚类还会在此基础上通过不断更新Enew的自我相似度进行AAP 聚类,最终依据聚类质量指标获得最佳聚类结果,用户初始样本的划分将不会对最终聚类结果产生影响。上述对初始用户样本集A的划分为随机划分,即在满足200 ≤fnum(Hγ)<400 的条件下,随机设定划分的部分数B和每部分用户数fnum(Hγ)。
2 售电套餐评价方法
2.1 基于犹豫模糊语言集的用户套餐评价
设 售 电 套 餐 集 合 为T={T1,T2,…Tj,…,TJ},用户集A={A1,A2,…Ai,…,AI}对售电套餐评价的 属 性 集 为C={CA,1,CA,2,…,CA,k,…,CA,K}。其中,Tj为第j个售电套餐,CA,k为用户集A评价售电套餐的第k个属性,J为售电套餐总数,K为售电套餐属性总数。本文考虑的售电套餐属性为电价、可再生能源比例、增值服务、奖励政策,各属性含义见附录C。
通常,用户评价售电套餐属性时表现出“亦此亦彼”的犹豫模糊状态,且由于其对套餐的了解程度有限,很难给出定量精准的评价信息,因此,本文引入犹豫模糊语言集[19]刻画用户套餐评价信息。
设用户Ai倾向于对套餐属性采取g(Ai)个等级进行评价,即Ai的语言评价集为Lg(Ai)={lg(Ai),0,lg(Ai),1,…,lg(Ai),p,…,lg(Ai),g(Ai)-1},其中,g(Ai)为奇数,表示语言评价集的粒度;lg(Ai),p为语言评价集粒度为g(Ai)时的第p+1 个语言评价量。Lg(Ai)中的元素按照顺序排列,即若p>x,则lg(Ai),p≻lg(Ai),x,其中≻表示优于。
用户Ai基于自身语言评价集Lg(Ai),对售电套餐属性做出评价,评价矩阵为RAi,sx=(rAi,jk)J×K,其中,rAi,jk表示Ai对套餐Tj的属性CA,k给出的犹豫模糊语言评价信息。需要说明的是,考虑到Ai评价时的犹豫 模 糊 状 态,rAi,jk可 包 含 多 个Lg(Ai)中 的 语 言 评价量。
2.2 考虑不完整信息的售电套餐属性权重确定
为集结各用户的售电套餐属性评价信息,需确定套餐属性的权重。售电套餐属性权重反映了该属性在套餐评价中的重要程度。考虑到用户受知识和时间的限制,无法提供权重的确切值,仅能提供不完整信息,如Ai提供的信息为:属性1 比属性2 更重要(ωAi,1>ωAi,2),属性3 与属性4 的重要性之差不小于0.15(ωAi,3-ωAi,4≥0.15)。为保证所得权重能综合反映各属性的重要程度,且对同一属性,如果同一用户对不同套餐的评价差异较大,则该属性应被赋予较大的权重,因此,本文拟采用离差最大化法[20]确定各属性权重ωAi=[ωAi,1,ωAi,2,…,ωAi,k,…,ωAi,K],其中,ωAi,k表示对于用户Ai而言,属性CA,k的权重。可以得到:

式中:ΩAi为用户Ai提供的权重不完整信息;DAi,k为对于第k个属性CA,k,用户Ai对各售电套餐给出的语言评价结果间的偏差程度;DIS(rAi,jk,rAi,qk)为用户Ai对套餐Tj的属性CA,k给出的犹豫模糊语言与对套餐Tq的 属 性CA,k结 果 之 间 的 偏 差 程 度;ψ(min(rAi,jk))=ψ(lg(Ai),p)=p,p=0,1,…,g(Ai)-1。

式中:lg(Ai),zh,αzh为一个语言评价二元组;αzh为用户Ai对售电套餐Tj的评价结果隶属于lg(Ai),zh的程度;zh为集结后的评价信息量角标;h为语言评价量总数。fHFLWAO的详细计算步骤见附录D。
2.3 多粒度犹豫模糊的售电套餐评价信息等值



式中:φij,yzh为用户Ai对售电套餐Tj评价结果隶属于lg(Af),yzh的程度。
综上,考虑多粒度犹豫模糊语言集和权重不完整信息的售电套餐评价流程见附录E 图E1。
3 基于用户满意度的售电套餐全排序推荐
售电公司对套餐的推荐需考虑用户售电套餐满意度,满意度越高,推荐成功的概率就越大。首先,判别新用户的相似用户;然后,计算相似用户售电套餐满意度,再结合新用户与相似用户的相似度,计算新用户售电套餐满意度。
基于1.2 节获得的最佳聚类结果,可判别新用户 的 相 似 用 户 。 设 新 用 户 集 为W={W1,W2,…,Wn,…,WM},其 中,Wn为 第n个 新 用户,M为新用户总数,基于各新用户Wn的画像m→Wn=[bWn,lr,bWn,mu,bWn,wd,bWn,nwd,bWn,plr,bWn,slr,bWn,vlr],计 算最佳聚类数c*下各聚类中心与m→Wn的距离,距离最小者对应类中的用户判定为新用户Wn的相似用户,记 为Anc*={A1,nc*,A2,nc*,…,At,nc*,…,AN,nc*}。 其中,N为与新用户Wn的相似用户总数,At,nc*为最佳聚类数c*下与新用户Wn相似的第t个用户,则新用户Wn与相似用户的相似度矩阵表示为S=(s′ρ(Wn,At,nc*))M×N。需要说明的是,新用户的月负荷数据未知,须通过负荷预测的方法进行预测。
基于第2 章获得的相似用户售电套餐等值评价信息,对用户的评价信息求期望,得到相似用户售电套餐满意度矩阵UA,T=(uAi,T,ij)I×J,其中,uAi,T,ij为用户Ai对售电套餐Tj的满意度,即:
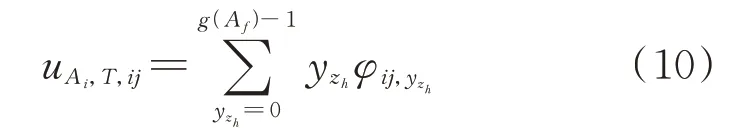
新用户售电套餐满意度取决于相似用户套餐满意度,以及新用户与相似用户的相似度,则新用户Wn对售电套餐Tj的满意度uW,nj为:
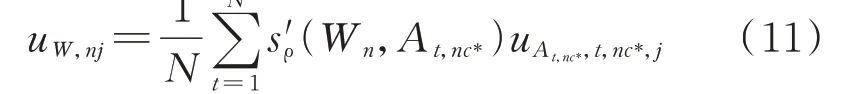
式 中:uAt,nc*,t,nc*,j为 最 佳 聚 类 数c*下 新 用 户Wn中 第t个相似用户At,nc*对售电套餐Tj的满意度。
基于新用户满意度的量化结果,本文提出售电套餐的全排序推荐方法,即售电公司将基于新用户的满意度,对各售电套餐进行排序,将所有的套餐和相应的排序结果推荐给新用户,供新用户选购。
为衡量所提全排序推荐方法的效果,基于排序结果,计算均方根误差,则对新用户Wn的售电套餐推荐结果偏差εn可表示为:
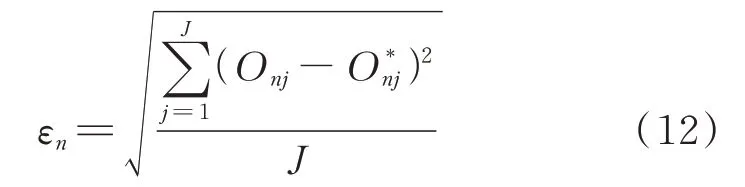
式中:Onj和O*nj分别为对Wn推荐的套餐Tj的实际排序结果和算法所得排序结果。售电套餐推荐的均方根误差εn越小,所提算法的推荐效果越好。
综上,所提套餐推荐方法可分为样本用户集评价信息库构建和新用户售电套餐推荐2 个阶段,实施框架见附录F 图F1,基于BLAP 聚类和多粒度犹豫模糊集的售电套餐推荐流程如图1 所示。
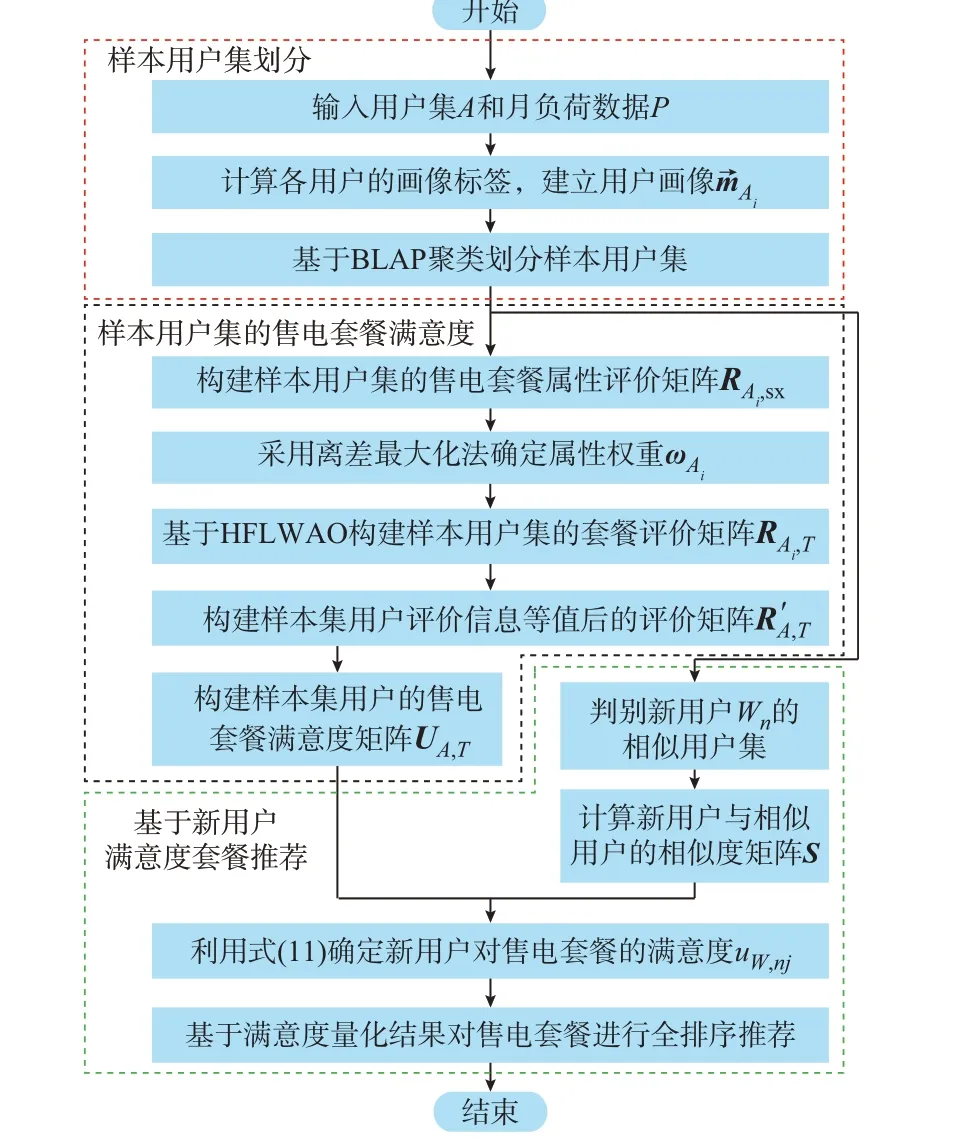
图1 基于BLAP 聚类和多粒度犹豫模糊集的售电套餐推荐流程图Fig.1 Flow chart of electricity retail plan recommendation based on BLAP clustering and multigranular hesitant fuzzy sets
4 算例分析
4.1 算例介绍
以中国某地区用户为例对所提售电套餐推荐方法进行验证分析。以智能电表采集的700 位典型用户A={A1,A2,…,A700}在2020 年1 月1—31 日的负荷数据为基础,采用留一交叉验证法[22]对所提方法进行验证,即每次抽取1 个用户作为新用户,剩余的699 个用户作为样本集。
参考该省交易中心的数据和美国得克萨斯州淘电网套餐数据[4],以及用户实际情况,售电公司为用户提供的套餐集为T={T1,T2,…,T5},各属性信息见附录G 表G1。考虑到本文主要目的是研究套餐的推荐方法,直接将上述负荷数据作为新用户月负荷进行分析。
在试点期间,售电公司对用户进行了问卷调查,收集各用户基于自身语言评价集的评价信息。据统计,用户的语言评价集粒度分别为5、7、9,各粒度下语言评价量含义见附录G。各用户的平均日负荷率、平均日峰谷差率与其对应的语言评价集粒度见附录G 图G1。样本数据集的数据结构见附录G。
4.2 售电套餐的推荐分析
4.2.1 样本用户集聚类分析
将样本用户集随机划分为3 组,取阻尼因子λ=0.8,基于BLAP 算法对样本用户集进行聚类,结果见附录H 图H1,分别为晚高峰型、峰平型、避峰型和双峰型。为探究用户的初始划分对聚类结果和聚类时间的影响,不同划分下最终聚类结果对应的聚类质量指标和聚类数,以及聚类时间分析见附录H。
基于样本用户集聚类结果,计算新用户的画像与晚高峰型、峰平型、避峰型、双峰型聚类中心的距离分别为0.109 5、0.398 5、0.397 6、0.319 7,可判定新用户的相似用户为晚高峰型用户。
4.2.2 售电套餐的推荐与效果评价
基于相似用户售电套餐满意度,以及新用户与各相似用户的相似度,详见附录I,得到新用户售电套餐满意度的归一化结果,如表2 所示。

表2 新用户售电套餐满意度的归一化结果Table 2 Normalization results of satisfaction of new customers with electricity retail plans
由表2 可知,新用户对T4的满意度最大。实际中,该新用户为居民用户,用电时段集中在19:00—22:00,更关注用电成本和电费折扣,且相比于高电能质量增值服务,该类用户对节能管理服务的需求更大,与晚高峰型样本用户集套餐的满意度结果相吻合。可见,本文所得结果与理论分析相一致,说明了所提用户满意度量化方法的准确性。
基于上述结果,售电公司提供给新用户的售电套餐及排序结果如表3 所示。
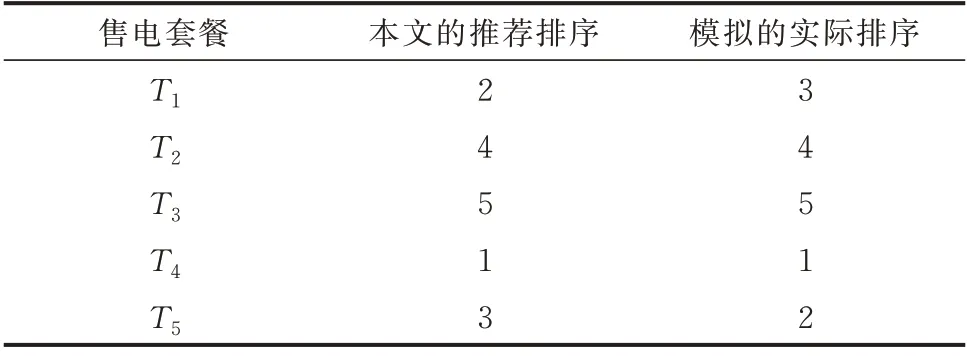
表3 推荐的排序结果和模拟的实际排序结果Table 3 Recommended ranking results and simulated actual ranking results
考虑到各套餐的实际排序结果较难获得,本文将做出如下选择模式的假设来模拟实际选择情况:
选择模式1:在非工作时间耗电量较大的用户更倾向于分时电价套餐。
选择模式2:耗电量较大且较为固定的用户更倾向于阶梯电价套餐。
选择模式3:售电套餐价格相当的情况下,用户更倾向于可再生能源比例较高的售电套餐。
选择模式4:售电套餐价格相当的情况下,对电能质量扰动敏感的用户较关注高电能质量增值服务,而其他用户更关注节能管理服务。
选择模式5:售电套餐价格相当的情况下,用户更倾向于节约成本较多的奖励政策。
基于上述模拟,结合用户实际负荷特性,将各套餐与用户关联,作为套餐的模拟实际排序结果,则新用户套餐模拟实际排序结果如表3 所示。值得注意的是,上述选择模式的假设主要是为了仿真模拟套餐的选择情况。实际中,用户可能存在不同的选择模式,但不影响本文所提售电套餐推荐方法的实施。
由表3 可知,本文方法所得的套餐排序结果与模拟的实际排序结果大部分一致,均方根误差为0.632 5。T1和T5的排序结果有差异是因为在T1和T5的成本相当且增值服务类型和奖励政策相同的情况下,T1的可再生能源比例更高,用户对T1的满意度更高,说明本文方法获得的套餐排序结果符合实际。同理,可随机抽取其他用户作为新用户,得各新用户套餐满意度评价结果见附录I。
4.3 不同方法的比较
4.3.1 不同聚类算法对聚类效果的影响分析
为了验证本文BLAP 聚类算法在聚类效果上的有效性,比较AP[16]、AAP[18]、BLAP 聚类算法在不同用户规模下的最佳聚类数以及聚类质量指标,如图2 所示。
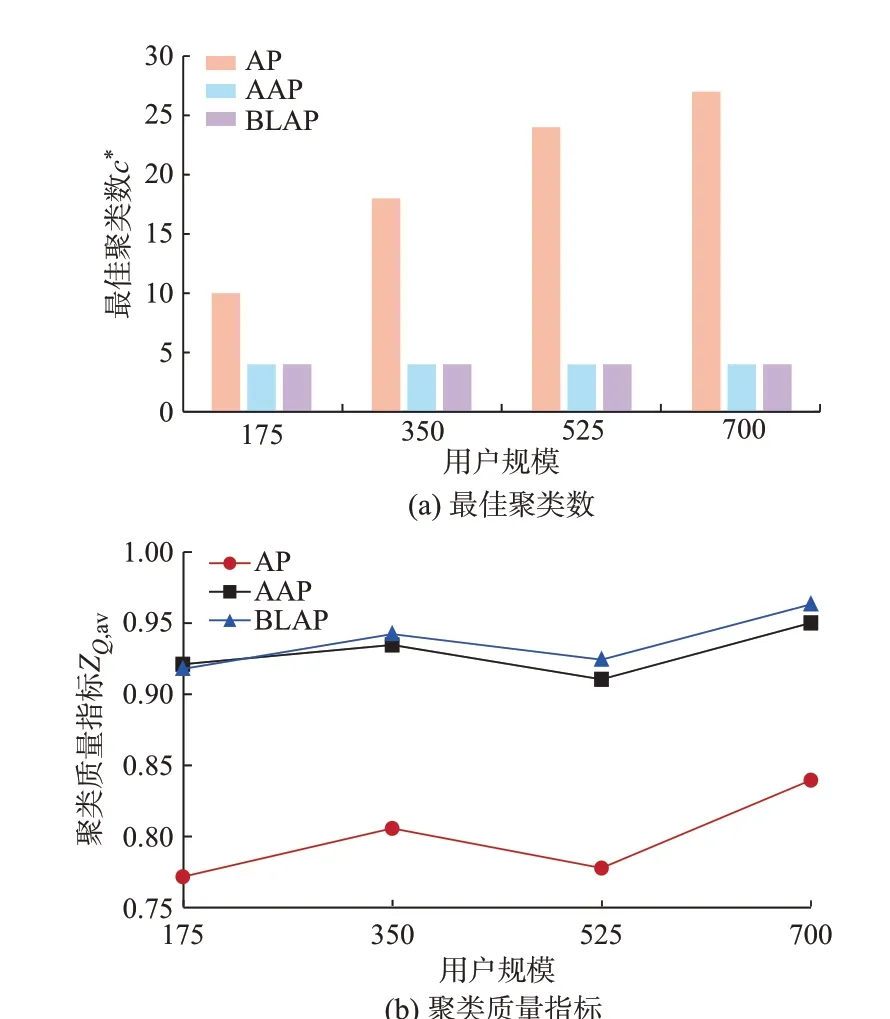
图2 不同用户规模下各聚类算法的最佳聚类数和聚类质量指标Fig.2 Optimal clustering number and clustering quality index of various clustering algorithms with different customer scales
由图2 可知,用户规模越大,AP 聚类算法所得聚类数越多,相比于AAP 和BLAP,其聚类质量指标较低。AAP 和BLAP 的最佳聚类数均为4,AAP的聚类质量指标略低于BLAP,但均大于0.9,聚类结果较为准确。此外,相比于AP 和AAP 聚类算法,BLAP 聚类算法通过将用户进行分区分层处理,降低了时间复杂度,能够处理较大的数据集,而AP和AAP 输入的是所有用户的相似度矩阵,尤其是AAP,每更新一次用户自我相似度,都需要对所有用户的相似度矩阵进行重新输入,复杂度较大。
4.3.2 不同售电套餐推荐方法的比较
为进一步验证所提售电套餐推荐方法的合理性和可行性,将本文推荐方法与以下3 种推荐方法作比较,分别计算各推荐方法下各类新用户的推荐结果如图3 所示。
方法1:售电套餐的评价属性仅考虑成本,对应属性权重为1,其他属性权重为0,基于BLAP 和多粒度犹豫模糊语言评价集的套餐推荐方法。
方法2:不对用户聚类,直接基于所有样本集用户售电套餐满意度以及新用户与样本集用户的相似度来进行售电套餐推荐的方法。
方法3:不考虑各评价属性的差异性,各售电套餐的属性权重相等,基于BLAP 聚类和多粒度犹豫模糊语言评价集的售电套餐推荐方法。
由图3 可见,本文推荐方法所得的排序结果均方根误差最小,均小于1。仅考虑成本的推荐方法所得结果偏差较大,最大为2.178 3。可见,考虑用户评价信息的多样性能显著减小推荐结果的偏差。如果不考虑各用户的差异性,直接根据新用户与所有样本用户的相似度对套餐进行推荐,相比于其他3 种推荐方法,该推荐结果对应的均方根误差最大,推荐效果较差。此外,若不考虑售电套餐各属性的差异,由图3 可知,各类用户的均方根误差均值分别为1.581 2、1.536 0、1.509 9、1.289 1,推荐效果明显低于本文考虑各属性差异性和权重不完整信息的推荐效果。

图3 不同方法下售电套餐推荐排序结果的均方根误差Fig.3 Root mean square error of recommended ranking results of electricity retail plan with different methods
5 结语
本文提出了一种基于BLAP 聚类和多粒度犹豫模糊集的售电套餐推荐方法。该方法具有以下特点:
1)所提出的基于用户画像与BLAP 聚类的相似用户判别方法,具有准确度高、聚类效率高、无须预先设定聚类数等优点,使得判别结果能更有效地反映新用户的负荷特性。
2)采用多粒度犹豫模糊集刻画用户的售电套餐多属性评价信息并将其等值化处理,不仅能更准确地反映用户售电套餐的多样化需求,而且能保证评价结果的准确性与公平性。
3)提出了基于离差最大化模型的属性权重确定方法,并基于HFLWAO 集结用户套餐评价信息,不仅能有效反映用户对售电套餐属性的偏好程度,而且能保证用户评价信息的完整性和可解释性。
4)提出了基于用户满意度的售电套餐全排序推荐方法,实现了售电公司对套餐的精准推荐,有利于售电公司提升用户满意度,增强用户黏性。
需要指出的是,本文仅是在考虑用户评价信息的多粒度犹豫模糊性和权重不完整信息的基础上初步研究了售电套餐推荐方法,推荐方法得到更大规模的试点推行后,还需研究主观打分和客观评价指标相结合的用户满意度量化方法,结合套餐增溢价值、售电公司市场份额等开展售电套餐推荐的研究。
论文研究得到浙江省教育厅一般科研项目(21020073-F)资助,谨此致谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
