基于SSA-SVM 的煤矿瓦斯监测预警模型研究
2023-02-01张朝,冯锋
张 朝,冯 锋
(宁夏大学 信息工程学院,宁夏 银川 750021)
近年来,随着我国科学技术的高速发展,煤矿生产百万吨死亡率有了明显下降,但与欧美发达国家相比,我国的煤矿管理水平还存在较大差距。在煤矿生产事故中,瓦斯事故所造成的伤亡占比是最高的,因此,众多学者针对该领域开展了相关研究。刘浩等[1]给出了大数据背景下矿井水害案例库系统建设方法,提高了煤矿水害防治的信息化水平;赵延超等[2]将大数据可视化分析引擎应用到煤矿水害监测预警系统中,在很大程度上满足了水害数据监控的展示需求;张洪亮[3]提出了基于大数据的煤矿违规行为识别系统,以此助力煤矿企业在生产过程中及时消除安全隐患;张俭让等[4]提出了基于云计算的矿井瓦斯监测预警系统,并且利用监测数据特征进行了瓦斯浓度预警研究。此外,目前关于煤矿瓦斯的检测研究也取得了不少成果。崔兰超等[5]提出了基于无线传感网络的煤矿瓦斯监测系统,其可以实现远程预警;俎全江[6]提出了基于MCU 的煤矿瓦斯监测系统,该系统主要利用微处理器来实现井下数据的处理与分析,从而提高了煤矿安全生产的可靠性;贾佳等[7]提出了基于多元信息簇融技术的煤矿瓦斯监测系统。综上所述,已有研究主要是基于单一技术来实现对煤矿瓦斯数据的监测,并且监测数据的存储和挖掘工作存在一定的局限性,因此,本文将物联网、云计算和大数据技术相结合,构建了新的煤矿瓦斯监测预警模型,以期能够弥补单一煤矿瓦斯监测方法存在的弊端。
1 物联网、大数据及云计算技术
1.1 物联网技术
物联网起源于媒体领域,被称为信息技术产业的第三次革命。物联网的主要作用是通过互联网和传感器将人与人、人与物、物与物按照约定协议连接起来,其主要包括传感技术、RFID 技术、嵌入式系统、智能技术和纳米技术等。在人们日常生产生活中,人与人、物与物之间时刻在产生数据,这些数据又组成了大数据。物联网技术处在数据时代的最前端,可以将现实世界与数字世界连接起来,其体系框架如图1 所示。

图1 物联网技术体系框架图
1.2 大数据技术
目前为止,大数据没有统一的概念。麦肯锡全球研究所曾这样定义:大数据是一种数据的集合,其获取、管理、存储和分析的能力远远超过传统数据库的规模[8]。大容量(large volumes)、多样性(variety)、快速性(velocity)和准确性(veracity)构成了大数据的4V 特征。数据的可变性、复杂性和价值性又是大数据技术的主要特征。大数据技术链接着物联网技术和云计算技术,物联网技术用于产生数据,组成数据集合;云计算技术则负责分析、处理、挖掘大数据的规律和价值。
1.3 云计算技术
从狭义上讲,云计算是一种提供分散资源的网络,“云”就是链接这些资源的网络;从广义上讲,云计算是一种网络服务,其将许多计算资源收集起来并组成一个资源集合,然后通过软件来实现资源的调动与分配。云计算具有可虚拟化、动态可扩展、灵活度高、可靠性高等特点,其服务类型可分为基础设施即分类、平台即服务和软件即服务[9]。云计算的技术框架如图2 所示。

图2 云计算技术框架图
2 模型设计
2.1 煤矿瓦斯数据
在煤矿生产过程中,工作人员会监测到不同类型的数据。以宁夏宁东某煤矿为例,煤矿瓦斯监测数据表现出以下特点。
(1)数据监测点多。如该煤矿二号生产井的瓦斯监测点多达138 处。
(2)数据整体稳定。在安全生产过程中,各瓦斯监测点的数据差异不大,较为稳定。
(3)数据具有突变性。在生产过程中,煤矿瓦斯监测数据整体呈稳定状态;而当开采面有瓦斯喷出时,监测数据会发生突变。
2.2 瓦斯预警模型关键技术
2.2.1 数据预处理 瓦斯数据由矿井底部的传感器采集而来。在数据采集过程中,环境及设备使用情况不确定等因素会造成一些脏数据,而这些数据会进入矿井采集数据集合。为了提高数据质量,减少不必要的数据误差,在数据送至云端之前,首先要对其进行预处理。常用的数据预处理方法有数据清洗、数据集成、数据转换和数据消减。具体如下。
(1)数据清洗。数据清洗主要面向3 种数据:缺失数据、噪声数据和不一致数据。在数据清洗过程中,对于缺失数据,一般采用忽略记录、手动补全、默认值填补、均值填补等方式进行处理;对于噪声数据,常用的数据处理方法有聚类分析法、回归法、人机结合等;对于不一致数据,通常情况下人们会利用数据与外部存在的某些联系加以解决。
(2)数据集成。为了便于进行数据的后续处理以及为数据处理工作提供完整的数据基础,系统需要将多个数据源数据组合成数据集合。然而在数据集成过程中,可能会出现数据模式集成、数据冲突检测与消除、数据冗余等问题。
(3)数据转换。采集或收集的数据往往会出现形式不规范等问题,因此,需要对这些数据进行归并以得到便于进行数据处理的合法形式,这就是数据转换。常见的数据转换策略包括数据规格化处理、数据属性构造处理、数据离散化处理和数据泛化处理。
(4)数据消减。大规模数据处理会耗费很多计算资源和时间,这种数据处理方式不宜用于需要及时得到分析结果的场景。数据消减就是对数据进行“瘦身”的一种技术,该技术可以对原有数据集进行凝练,得到一个拥有原数据特征的精简数据集,这样不仅能够提高数据挖掘效率,还能保证分析结果与原数据集基本相同。常见的数据消减方法有数据聚合、位数消减、数据压缩和数据块消减。
2.2.2 Hadoop 分布式计算平台 Hadoop 分布式计算平台具有高可靠性、高效性、高扩展性、高容错性及低成本等特点,其可以合理调用计算资源,运行大规模集群计算平台[10]。分布式文件存储系统(HDFS)和分布式离线计算框架(MapReduce)是Hadoop 分布式计算平台的核心功能组件。其中,HDFS 具有能够处理大数据、实现流式处理、在商用服务器上运行等优点[11]。在访问应用程序数据时,HDFS 具有较高的吞吐量,因此对于底层数据存储系统来说,HDFS 是很好的选择。MapReduce 可用于大规模数据集的并行操作,其核心思想是将输入数据集切割成多个数据块并将其分配给主节点下的各子节点,然后完成数据的计算和处理,最后对各子节点的计算结果进行积分以得到最终结果。Hadoop 平台的生态系统如图3 所示。

图3 Hadoop平台生态系统图
2.3 SSA-SVM算法
本文提出的瓦斯预警模型采用了将麻雀搜索算法(SSA)和支持向量机(SVM)相结合的SSA-SVM预测算法,并且利用SSA 确定了支持向量机的惩罚因子c和核参数g。
2020 年,J.K.Xue 等[12]根据麻雀觅食习惯行为提出了麻雀搜索算法。该算法根据麻雀种群的特点,将系统种群分为发现者、警惕者和探索者,其能够搜寻到最适合模型的c和g,具有稳定性好、搜索速度快等优点。
支持向量机主要应用于分类场景,最常见的是二分类问题,其最重要的参数是c和g。若参数选取不合适,会影响分类效果,而SSA-SVM 算法是基于SSA 良好的性能来确定c和g的。
SSA-SVM 算法流程图见图4,执行步骤如下。
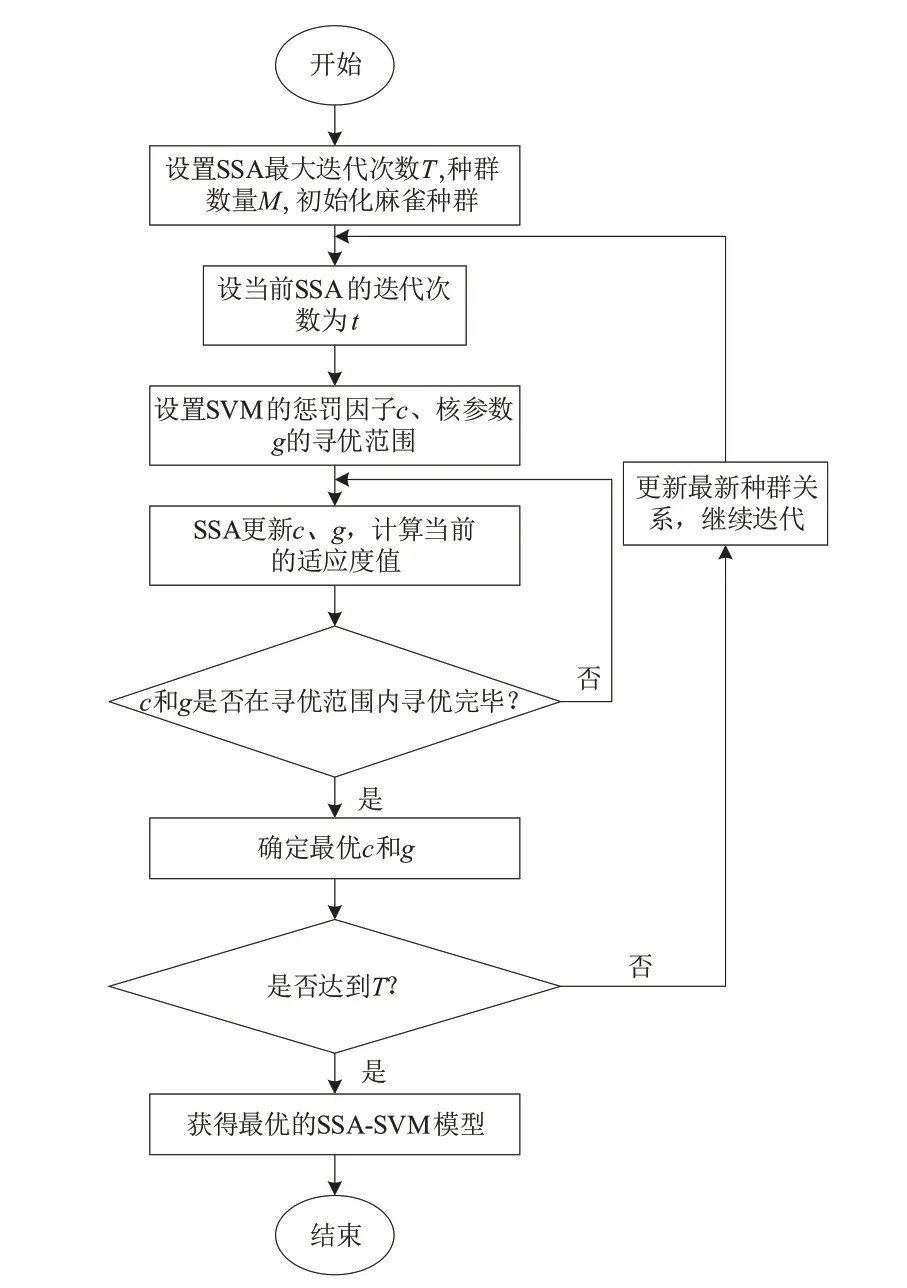
图4 SSA-SVM算法流程图
(1)根据采集数据,选择煤矿瓦斯预警模型的训练集和测试集并对数据进行归一化处理。
(2)设置SSA 初始参数:最大迭代次数T、麻雀种群数量M。
(3)设置SVM 参数c和g的寻优范围。
(4)初始化麻雀种群并计算种群适应度。
(5)迭代开始,更新c和g,计算适应度值并记录当前最佳位置和最优值。
(6)在给定的寻优范围内判断c和g是否寻优完毕。若寻优完毕,执行步骤7;否则,执行步骤5。
(7)当系统达到最大迭代次数T时,寻优结束,此时可以确定SSA-SVM 算法所需的最优参数;否则,返回步骤5,继续迭代。
(8)算法结束。
2.4 模块组成
本文提出的煤矿瓦斯预警模型主要由数据采集模块、数据存储和处理模块、用户模块3 部分组成。
2.4.1 数据采集模块 数据采集模块主要由传感器和通信网络组成。通常情况下,各个矿井都要接入瓦斯浓度、温度、湿度等传感器,并且系统会通过通信传输网络将传感器采集的数据传送至云处理服务器。以宁东某矿井为例,该矿井使用的数据传感器多达138 组,每组包含甲烷(CH4)、二氧化碳(CO2)、一氧化碳(CO)、硫化氢(H2S)和温度5 种传感器,每次采集的数据量为690 个。若每分钟记录1 次采集数据,每天将产生496 800 个数据。数据采集模块示意图如图5 所示。表1 列举了5 种传感器在某一时间段内所采集的部分监测点数据。此外,为了保证数据的可靠性和生产安全性,值班人员会定期在监测点进行手工抄表并检查设备的运转情况。

表1 部分采集数据

图5 数据采集示意图
煤矿瓦斯预警模型采用ZigBee 技术将采集到的数据传输到地面。ZigBee 具有自组网能力强、自恢复能力强等特点,可以用于矿井定位、追踪、追溯等领域,其主要包括以下两部分功能。
(1)网络初始化:确定网络协调器;信道扫描;设置网络ID。
(2)节点加入:查找协调器;发送关联请求命令;协调器处理;发送数据请求命令;回复确认。
2.4.2 数据处理与存储模块 数据采集模块从矿井中采集到大量数据,系统需要对这些数据进行处理和存储。首先,系统将数据上传至本地数据库,再对其进行清理、整合、转换和缩减操作;处理后的数据通过以太网传输到云平台,由Hadoop 平台对这部分数据进行挖掘和分析;最后再将数据存储在云端,并且系统会定时清理存储数据。数据存储和处理示意图如图6 所示。

图6 数据存储与处理示意图
2.4.3 用户模块 用户模块是煤矿瓦斯预警模型的重要组成部分,煤矿安全生产状态都是由该模块呈现给用户的。用户模块采用B/C 模式,具体包括登录模块、用户管理模块、环境预警模块和环境监测模块(图7)。其中,登录模块基于信息库对访问者进行信息确认,判断访问者是否有权限进入系统,访问者登录成功后可以查看权限范围内的生产状况;用户管理模块主要负责用户权限下发和日常用户信息维护等内容,其中管理员拥有最高管理权限;环境预警模块会根据监测数据发出报警,并且其设有误报警人为消除功能;环境监测模块的主要功能是通过传感器对井下数据进行采集并给出正常的参数范围,该模块采集的数据在经过预处理后被传至云端,用作数据挖掘与分析。用户模块操作流程图如图8所示。此外,本文提出的SSA-SVM 模型不但设有PC 端管理界面,而且还具有移动端管理程序,以便于管理人员随时了解煤矿安全信息。

图7 功能模块图

图8 用户操作流程图
3 结果与分析
根据《煤矿安全规程》及矿井所测数据,本文将预警等级分为4 级,如表2 所示。本实验共采用4 120 组数据,其中训练集数据为4 000 组,每个预警等级的训练集数据为1 000 组;测试集数据为120 组,每个预警等级的测试集数据为30 组。

表2 模型预警等级
本次实验设置:M=20,T=20;g和c的寻优范围为2-5~25,并且得到最优值c=28.236 1,g=32。实验结果如图9 所示,SSA 适应度曲线如图10 所示。由图9 和图10 可知:SSA-SVM 算法对于边界的数据分类存在一定的改进空间;对于数据区分明显的类别,该算法的预测准确率达到91.667%,说明其性能良好。

图9 实验结果

图10 SSA适应度曲线
4 结论
本文基于物联网、大数据和云计算技术,提出了SSA-SVM 煤矿瓦斯预警模型。该模型的主要功能:对采集到的煤矿生产数据进行预处理;将预处理后的数据传输至云端并对其进行数据挖掘和分析;对实时数据进行监测,判定当前生产环境下的煤矿瓦斯安全等级。本文提出的SSA-SVM 模型虽然具有较高的准确率,但依然存在部分需要改进的地方。如在SSA 中,初始值设置和群体数量是影响寻优的关键环节,如何保证参数的合理性是后续研究中值得思考的问题。此外,在煤矿生产中,一旦发生安全事故,首先要确定生产者的具体位置以便于帮助其快速逃生,而目前很多关于井下定位的研究只是对定位算法进行了加权处理,没有将环境因素对定位的影响考虑在内,因此存在不同程度的定位误差,需要进一步展开相关研究。
