一种新型基于位置服务的隐私保护方案
2023-01-31张才宝奚舒舒马鸿洋
李 兰 张才宝 奚舒舒 马鸿洋
1(青岛理工大学信息与控制工程学院 山东 青岛 266000) 2(青岛理工大学理学院 山东 青岛 266033)
0 引 言
在基于位置服务[1-2](Location-Based Service,LBS)的移动社交网络[3](Mobile Social Networks,MSNs)中,用户通过位置定位设备查询附近的兴趣点(Point of Interest,POI)[4],来满足生活和工作上的需求[5-6]。然而,用户必须主动提供位置信息和查询内容才能使用这种服务,当包含用户隐私信息的日志文件被攻击者窃取后,用户的职业、政治观点和行为模式等很容易被推断出来[7-8]。因此,当务之急是要有效地保护用户的隐私安全。
区域k-匿名技术虽然可以将用户被识别的概率降低到1/k,但这种技术存在部分问题。首先,构建的匿名区域中除查询用户外,其他用户可能出现分布集中的情况,并可能集中分布在查询用户附近,易造成用户位置隐私泄露。其次,匿名区域的构造过程中可能产生冗余空间。最后,匿名区域内的查询请求类型可能过于单一,易造成查询信息泄露。
基于上述原因,本文提出一种新型的基于位置服务的隐私保护方案。首先利用基于球树[9]的匿名区域构造算法(Balltree-Based Anonymous Region Construction Algorithm,BT-RCA)搜索邻居用户,与其他搜索算法相比,球树算法可以提高搜索邻居用户的效率。此外,综合考虑了用户组中距离权重与请求内容权重,在构建的多个用户组中,选择熵最大的一组,有效地保护了移动用户的位置信息和查询内容。最后,通过安全性能分析,进一步验证了该方法在隐私保护方面的有效性。
1 相关工作
位置隐私保护方法根据标准不同可以分为多种类型。本文通过对国内外研究现状的分析,将位置隐私保护方法分为三类:空间隐匿法[10-12]、虚拟定位法[13-15]、基于原语的密码学方法[16-18]。
1.1 空间隐匿法
Gruteser等[10]提出基于四叉树结构的Interval Cloak算法,该算法结合k-anonymity[11]思想,将用户的具体位置信息替代为一个包含至少k个用户节点位置信息的区域向LBS服务器请求查询,将用户被成功推断的概率降低到1/k。
在文献[10]基础上,Mokbel等[12]提出匿名区域构建算法,该算法以Casper模型为基础,利用匿名服务器管理空间索引信息,使得到的矩形匿名空间较Interval Cloak算法更小,提高了算法性能。但当用户数量很少时,Casper算法会因为一直找不到足够的邻居用户导致匿名区域构建失败。
1.2 虚拟定位法
Hong等[13]提出一种将用户真实位置替换为附近路标或相近位置的算法。Kido等[14]在文献[13]的基础上,提出一种匿名通信技术,可以生成多个虚拟位置,并将其与用户的位置信息一并发送给LBS服务器,更好地隐藏用户的位置信息。
Wu等[15]提出了多目标优化算法,综合考虑了查询概率和匿名区域的面积,通过生成的k-1个假位置来实现k-匿名。该算法降低了虚拟位置被过滤的可能性,但算法计算量较大,对MSN用户设备要求较高。
1.3 基于原语的密码学方法
基于原语的密码学方法[16-18]通过对用户与LBS服务器的交互信息加密实现隐私保护目的,可以提供很好的安全性,但用户与LBS服务器通信中计算开销很大,因此这些方案对MSN用户隐私保护可行性较差。
在本文中,BT-RCA利用球树作为空间索引结构,减少搜索邻居用户的时间,保证匿名区域生成过程中不产生冗余空间,并结合用户的距离权重与请求内容权重,有效提高了服务质量。
2 BT-RCA模型
2.1 基本概念
定义1距离度量:用户ui和uj之间的距离度量(本文使用欧几里得距离),定义为:
(1)
式中:x、y分别表示用户位置的经纬度信息。
定义2区域划分:假设Reg是一个半径为r的区域。
如果Reg中的用户与真实用户ureal的距离度量小于r,则称这些用户为ureal的dis_r-邻域用户,表示为:
Ndis_r(ureal)={ui∈Reg|dis(ureal,ui)≤r}
(2)
如果Reg中用户的查询请求内容与真实用户ureal的查询内容不同,则称这些用户为ureal的dis_c-邻域用户,表示为:
Ndis_c(ureal)={ui∈Reg|boolean(ureal,ui)=False}
(3)
式中:boolean()是判断请求内容是否相同的函数。
定义3距离权重:用αi表示dis_r-邻域用户ui的距离权重,定义为:
(4)
用户ui在用户组Ut中的距离权重定义为:
(5)
与文献[19]相比,本文不仅考虑到ui在整个邻居用户中的权重,更考虑到ui在固定用户组中的权重。
因此用户组Ut基于距离的熵为:
(6)
定义4内容权重:用户组Ut的请求内容的权重用βt表示,定义为:
(7)

由此可得用户组Ut的熵为:
HA(T)=H(Ut)+βt
(8)
最后在构建的候选用户组中选择熵最大的一组。
(9)
2.2 系统模型
本文系统架构如图1所示,包括MSN用户、匿名服务器及LBS服务器,并假设匿名服务器是可信的。
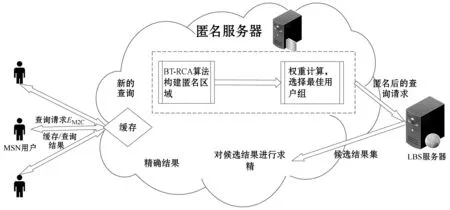
图1 系统架构
(1) MSN用户:MSN用户需要向匿名服务器发送一条查询请求:
EM2C={ID,A,k,c,m,l,Cac,MinC}
(10)
式中:ID表示用户身份;A表示可接受的匿名区域的最小范围;k表示区域匿名度;c表示查询内容;m表示构建候选区域的轮次;l表示用户位置(x,y);Cac表示查询结果是否需要缓存;MinC表示用户组请求类型多样性阈值。
(2) 匿名服务器:主要包括匿名模块、候选结果处理模块和缓存处理模块。
收到用户查询请求后,匿名模块根据请求内容构造球树,完成最近邻用户搜索,并用BT-RCA进行匿名性处理。
LBS服务器的查询结果到达后,候选结果处理模块会对查询结果进行选择,然后将精确结果返回给用户。
为了减轻LBS开销,提出匿名服务器的缓存方案,在查询请求EM2C中加入参数Cac,其中Cac={0,1}。当Cac=0时,表示用户不再需要本次查询结果,结果返回给用户后,匿名服务器便将之丢弃;否则,就将结果缓存。下次查询来临时,匿名服务器先将缓存反馈给用户,用户检查反馈结果,若对结果不满意,则重新发送新的查询。
(3) LBS服务器:LBS服务器收到来自匿名服务器的请求内容后,开始进行查询,然后将结果发送回去。
2.3 球 树
2.3.1球树的建立
构造球树的具体流程为:
(1) 先构建一个可以将所有样本数据包含进去的超球体。
(2) 在球中选择一个点A,A点满足到球心O的距离大于球内其他任何点到点O的距离,再从球内选择一个离A点距离最远的点B,然后将球中剩余点以距离最近为原则分配到A、B上,当所有数据点都正好包含于聚类时,逐个计算聚类的中心和半径。这样,便得到了两个子超球体。
(3) 将得到的每个子超球体均递归执行上述步骤(2),直至球树构建完成。
2.3.2球树最近邻搜索
球树搜索目标点的最近邻方法如下:
(1) 从根节点开始贯穿整棵树查找包含目标点所在的叶子节点,并找出球中距离目标点最邻近的点,此时便可以得出目标点与它的最近邻点的上限的值max,下一步就是对兄弟节点进行检查,如果max与兄弟节点的半径的和小于目标点与兄弟节点中心的距离,则该兄弟节点中不会存在更近的点;否则,必须对兄弟节点下的子树进行检查。
(2) 为了搜索最小邻近的值,当兄弟节点的检查结束后,还需要向父节点进行回溯,直至到达根节点,这时最终的搜索结果就是最小邻近值。
2.4 BT-RCA
为了对用户的位置和查询内容等隐私信息进行有效保护,本文提出BT-RCA,算法的步骤如下:
(1) 用球树搜索算法找到距离ureal最近的3k个邻居用户,存储在长度为3k的队列中。
(2) 球树搜索完成后,如果邻居用户达到3k个,则从3k用户中随机选取k-1个用户与真实用户构成候选用户组,循环执行m次。
(3) 对组内的距离权重与内容权重进行计算,并在m个用户组中选择熵最大的一组。
(4) 如果邻居用户数小于3k或组内请求内容多样性小于MinC,提醒用户重新输入。
BT-RCA伪代码描述如算法1所示。
算法1BT-RCA
输入:真实用户ureal,匿名度k,执行轮次m,请求内容阈值MinC。
输出:匿名区域。
1.初始化队列q,并设置|q|=3k;
2.使用球树算法搜索ureal的最近邻用户;
3.if最近邻用户数量小于3kthen
4.重新设置k;
5.else
6.将最近邻用户设为3k并存入队列q;
7.fori=1tomdo
8.随机从3k用户中选择k-1个用户与ureal组成用户组U;
9.计算HA(T);
10.endfor
11.从m个用户组选择熵最大的一组Umax;
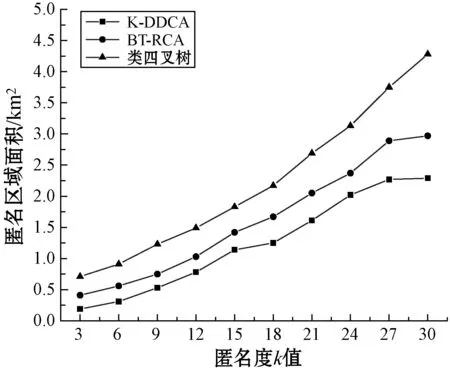
12.if|Ndisc(ureal)| 13.重新设置MinC; 14.else 15.返回Umax; 16.endif 17.endif 目前存在的攻击方式主要为合谋攻击和推理攻击,两种攻击均无法对本文方案造成威胁,现安全性分析如下。 BT-RCA在3k个邻居用户中随机构造用户组U={U1,U2,…,Um},每个用户组包括随机k-1个邻居用户与真实用户ureal,且考虑到用户组的距离权重与请求内容权重,因此组内的任一用户A无法判断真实用户ureal的位置。P(X+A)表示攻击者X与用户A合谋时推断真实用户的概率,有: (11) 式中:preal表示真实用户ureal被识别的概率;pi表示组内任一用户被识别的概率。 攻击者又与用户B合谋,因为用户A与用户B没有联系,所以推断成功的概率为: (12) 因此BT-RCA可以成功抵抗用户合谋攻击。 连续查询时,LBS服务器中有真实用户的查询记录,记为: (13) 匿名服务器利用缓存提供服务,这一过程中,用户与LBS服务器没有联系,因而LBS服务器中的历史离散位置难以关联,为推断用户真实位置方面增加了难度。可以说,缓存的使用成功降低了LBS服务器推断真实用户的概率,有效保护了用户的位置隐私。 算法采用Python编程语言实现,实验环境为2.4 GHz的双核CPU,8 GB内存,操作系统是Windows 10,在Thomas Brinkhoff[20]上进行仿真实验。在Oldenburg地图中部,取大约4 km×4 km区域位置数据,区域划分块数为1 600块,其中20个POIs是随机生成的,用户数量由参数控制。将BT-RCA与K-DDCA[19]和类四叉树算法[21]进行比较。 4.2.1匿名区域面积与k值的关系 空间分辨率[21]指满足MSN用户的匿名要求的最小空间面积与匿名算法最终构建得到的匿名区域面积的比值。 由图2和图3可以看出,三种算法的匿名区域面积随k的增加逐渐增加,空间分辨率逐渐减小。但类四叉树算法使用四叉树作为存储结构,没有充分考虑邻居用户之间的位置关系,k由24变化到30的过程中,该算法产生的匿名区域面积过大,算法的空间分辨率不理想。K-DDCA使用kd树作为存储结构,虽然k值固定时构造的匿名区域面积最小,但在隐私保护中更大的匿名面积意味着更好的隐私保护效果,该算法构造匿名区域面积过小,无法有效保护用户隐私安全。 图2 匿名区域面积与k值的关系 图3 空间分辨率与k值的关系 BT-RCA使用球树进行存储,构造匿名区域的过程中不会产生冗余空间,可以避免不必要的查找。当k由20增长到25的过程中,空间分辨率变化很小,性能较优。该算法构造的匿名区域面积不会太大或者太小,既保证了效率,又避免用户隐私信息的泄露。 4.2.2匿名区域面积与用户数量的关系 图4表示k分别为10和15时,类四叉树算法与BT-RCA构造匿名域面积与用户数量的关系。匿名区域面积随用户数量增加而减小,当用户数量大于1 000时,类四叉树算法与BT-RCA构建的匿名区域面积都逐渐稳定。而BT-RCA利用球树模型,构建匿名区域时不会产生冗余,所以构建的区域面积要比类四叉树算法小,避免不必要的消耗,性能更加优良。 图4 匿名区域面积与用户数量的关系 4.2.3熵与k值的关系 图5表示以熵的形式来表示不同匿名区域构造方案的隐私级别。随着k的增加,类四叉树算法、K-DDCA和BT-RCA的匿名性也随之增加,但BT-RCA性能最优。因为BT-RCA和K-DDCA形成匿名区域过程中没有产生冗余空间,而类四叉树算法则达不到这种效果,攻击者可以根据已有知识排除大量邻居用户,因此在一般情况下,类四叉树算法并不能达到真正的k匿名。与本文算法相比,由于K-DDCA构造的匿名区域过小,因此无法达到最好的隐私保护效果。 图5 熵与k值的关系 以球树作为存储结构,本文提出新型的基于位置服务的隐私保护方案。利用BT-RCA构造匿名区域,综合考虑用户组中的距离权重与请求内容权重,在m个候选用户组中选择熵最大的一组,保证匿名区域中用户分布均匀性和请求内容多样性。最后利用Thomas Brinkhoff进行仿真,验证了算法在用户隐私保护方面的有效性。 算法在用户数量少时效果不佳,以后会考虑如何在用户稀少地区优化该算法。且算法以匿名服务器可信任为基础,因此以后会进行一些有效的策略来约束匿名服务器。3 安全性分析
3.1 抗用户合谋攻击
3.2 抗LBS推理攻击

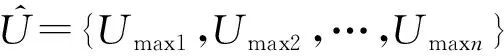
4 实验仿真
4.1 实验环境描述
4.2 仿真结果分析



5 结 语
