基于LightGBM多阶段医疗服务等待时间的预测研究
2023-01-31黄益槐韩乐奇吴成宇
彭 俊 项 薇,2* 谢 勇,3 黄益槐 韩乐奇 吴成宇
1(宁波大学机械工程与力学学院 浙江 宁波 315211) 2(宁波大学先进储能技术与装备研究院 浙江 宁波 315211) 3(抚州幼儿师范高等专科学校 江西 抚州 344099)
0 引 言
我国三甲医院门诊就诊中普遍存在“三长一短”的问题,即“挂号排队时间长、看病等候时间长、取药排队时间长、医生问诊时间短”。有学者统计研究表明门诊患者的医疗诊治时间仅占有门诊总时间的10%~15%[1]。这其中的“三长”极大影响患者对医院医疗服务满意度,也直接造成患者就诊过程排队拥堵现象,影响医疗机构的正常运作管理。
基于不断增长的医疗需求的影响,就诊排队等待现象似乎不可避免。目前,患者和医院依然存在信息不对称的情况,特别是当患者需要进行多项检查及诊治服务时,患者无法获得各科室实时就诊信息,仅依靠经验选择就诊项目进行排队等待。应用预测分析技术可以为医院过度拥挤提供一个解决方案[2-3],把预测出的等待时间等信息通过电子屏幕等移动设备发布给患者,增强患者就诊体验,缓解患者因为焦急产生等待的焦虑,从而提高其满意度。
针对医疗服务等待时间预测问题,依据其复杂性,可提炼成单一服务阶段等待时间预测与多阶段服务等待时间预测这两类问题。单阶段等待时间预测是指这类患者需要知道当前所在科室的实时等待信息,该患者已经在该科室的队列中,我们需要预测该患者所在科室队列的实时等待时间;多阶段服务等待时间预测是指这类患者需要接受系列的就诊服务,过程中有多重排队队列选择,不仅需要知道当前所在科室的实时等待信息,还需要获取下一流程所在科室的等待信息乃至在医院的总逗留时长。通过文献综述发现,现有的服务等待时间预测研究主要为单阶段等待时间预测,少有针对多阶段服务等待时间预测的相关文献。
国内学者朱启东[4]基于科室、挂号时间、是否为工作日、月份、医生、同科室候诊人数、当天本科室挂号总人数和是否为节假日8个变量建立BP神经网络患者候诊时间预测模型。张会会[5]基于医疗信息系统数据将星期、是否周末、科室、卡号类型、卡号类型、预约时段等变量提取出来,分别利用线性回归、Lasso回归、随机森林回归、K最近邻回归四种方法建立患者等待时间预测模型,随机森林和K最近邻回归精度最高,平均绝对误差低至13分钟左右。何跃等[6]将患者挂号月份、时间段、科室队列人数和科室队列流速作为预测模型的自变量,建立基于BP神经网络急诊科室患者等待时间预测模型,其研究显示队列流速对患者等待时间影响较小。
国外研究主要侧重于急诊科室患者等待时间的预测,与之相关的文献采用了大量的统计方法。Austin等[7]基于患者年龄、性别、患者紧急情况、病情程度、是否为工作日等15个变量使用分位数回归模型预测患者在请求急诊服务科多久到达医院。Poole等[8]使用正则化模型(Ridge and Lasso)和随机森林回归预测患者急诊候诊时间。Champion等[9]通过使用简单的移动平均、滚动平均方法计算出等待时间的算术平均值来构建预测模型。Pianykh等[10]将科室队列人数、最近的3位病人平均等待时间、队列流速等作为输入变量,建立线性回归模型预测患者等待时间。Ang等[11]使用正则化回归模型预测病情较轻患者等待时间。Arha[12]基于时间类变量(如这一天是星期几、患者几点到达等)、急诊科室快速通道的状态、患者类型、患者地点位置等变量,构建基于正则化回归方法(Lasso、Ridge、Elastic Net、SCAD和MCP)和随机森林的患者等待时间预测模型。
综上所述,总结对患者等待时间统计建模输入的变量:主要可分为时间类、患者类型、科室类型、挂号方式、地点位置5类变量,具体如表1所示。现有的研究主要采用移动平均、回归分析和神经网络三类算法,具体如图1所示。移动平均模型仅利用本身的历史数据进行预测,数据需求简单,但也因此忽略了其他因素的影响;神经网络算法可解释性较差同时需要大量的历史数据;而经典的回归分析方法如正则化方法、分位数回归、K最近邻、决策树等预测技术由于欠拟合导致预测性能欠佳,同时也不适用在大数据样本的预测。本文将选取医疗服务等待时间的预测问题为研究对象,引入基于LightGBM算法实现多阶段服务等待时间的预测。

表1 统计预测建模输入变量
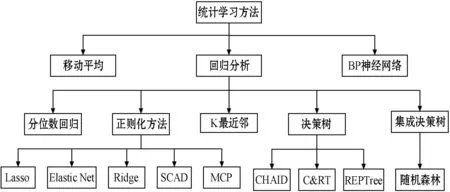
图1 统计学习预测方法
1 相关方法
1.1 LightGBM原理
LightGBM算法属于Boosting集成算法中的一种,Boosting是机器学习中集成学习算法的一个分支,是目前经典的用于预测的机器学习算法,由Schapire[13]提出,其主要思想是将多个弱监督学习模型进行有机组合得到一个性能更好更全面强监督学习模型,即便是某一个弱学习器得到了错误的预测,其他的弱学习器也可以将错误纠正。常见的机器学习Boosting集成算法有Adaboost、GBDT、XGBoost和LightGBM。Adaboost和GBDT都是经典的Boosting决策树算法,XGBoost在GBDT基础上进行了一定改进,使其性能得到提升。XGBoost算法虽然强大,但是由于XGBoost算法迭代次数和特征维度有很大关系,当样本数据维度增加,每次迭代需要遍历全部的数据样本,在这种情况下XGBoost算法效率显著降低。为了应对大数据样本的挑战,还需要对XGBoost进行优化。LightGBM是微软2017年提出的新的Boosting框架模型[14],LightGBM算法在XGBoost基础上进一步进行了以下改进:
(1) 梯度单边采样技术:梯度单边采样技术(Gradient-based One-Side Sampling,GOSS)可以剔除很大一部分梯度很小的数据,只使用剩余的数据来估计信息增益,从而避免低梯度长尾部分的影响。由于梯度大的数据对信息增益更加重要,所以GOSS技术在较之传统GBDT少很多的数据前提下仍然可以取得相当高的预测精度[15]。
(2) 独立特征合并技术和直方图算法:独立特征合并技术(Exclusive Feature Bundling,EFB)实现互斥特征的捆绑,以减少特征的数量,因为在高维特征的数据样本中,很多样本的特征存在互斥的情况,EFB技术识别并对这些特征进行捆绑。另外,在GBDT和XGBoost算法中,最耗时的步骤是利用预排序(Pre-Sorted)的方式在排好序的特征值上枚举所有可能的特征点,然后找到最优划分点,而LightGBM中使用直方图算法替换了传统的Pre-Sorted以减少对内存的消耗,直方图算法的思路是将连续的特征值进行装箱处理,装箱处理其实就是离散化连续的特征值,而对于类别特征,一种取值就是一个箱,这样处理的好处是在节点分裂时,XGBoost和GBDT中需要遍历所有离散化的值,而在LightGBM中只要遍历箱。因此LightGBM更加高效,占用内存更低。
(3) 不同于XGBoost和GBDT采用基于按层生长的决策树成长方式,又叫做level-wise策略。LightGBM算法中单个决策树的节点分离方法是基于叶子分裂的,又叫leaf-wise策略,这样的好处是不会对许多分裂增益过低的节点进行遍历搜索,降低了对计算资源的消耗。
1.2 预测分析过程
本文预测分析过程如图2所示,首先基于SIMIO获取相关数据,对数据进行独热编码及标准化预处理后使用Lasso、Ridge、GBDT、XGBoost和LightGBM算法建立预测模型,使用随机搜索选择参数,最后通过对比选出最佳模型。
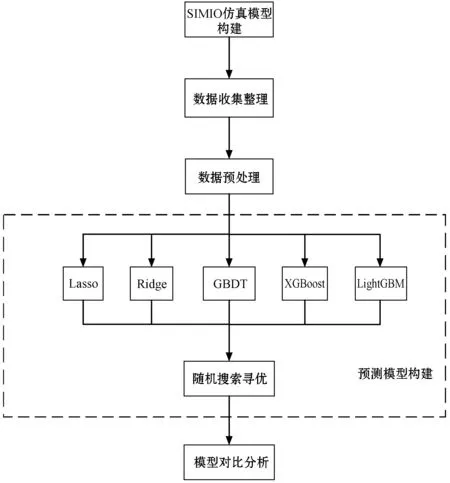
图2 预测分析过程
2 构建多阶段患者服务等待时间预测模型
2.1 预测问题描述
将患者服务等待时间定义为患者在医院接受服务时间以及等待时间之和。医院各科室队列人数的实时状态S、患者诊疗流程中的科室构成O是影响患者服务等待时间的主要因素。
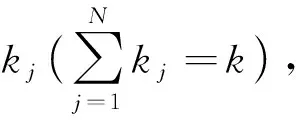
(1)
所以,多阶段患者服务等待时间可用式(2)表示,因为无法知道公式的具体形式,因此采用LightGBM算法建立回归模型预测患者服务等待时间。
F=f(k1,k2,…,kn,p11,p12,…,p1n,…,pMnM)
(2)
2.2 基于SIMIO训练样本的收集
对宁波某妇幼保健院以及宁波多家医院的调研发现,目前医院的HIS系统与排队系统独立运作,无法直接获取多阶段的原始数据,本文采用SIMIO软件进行仿真,获取模型训练集和验证集数据。
仿真首先需要仿真目标,本文基于文献[16]建立仿真模型获取相关实验数据。论文中以大连某体检中心实际工作流程为基础,对于患者的就诊流程、患者到达分布、人员设备配置、各科室服务时间、排队过程均有详细说明。
对于建模输入变量,本文主要考虑患者和医务人员两方面的影响,主要包括时间类(患者到达时间)、科室类(各科室队列人数类、患者检查项目)这2大类变量对患者等待时间的影响,具体变量和变量类型如表2所示,通过SIMIO中添加触发器并加入write step模块将实验相关数据输出成.csv文件格式。对于上述共17类数据,服务等待时间是我们的预测目标,进入队列时间既可获取进入队列时刻,也可与完成时间计算得到患者的服务等待时间,其他14个变量为输入模型中的因变量,将仿真模型运行60天后汇总得到样本共计8 110条。

表2 变量类别及类型
2.3 数据预处理
(1) 标准化。对数据进行标准化处理可以排除不同变量值域量纲差异过大的影响,有利于算法模型的收敛。通过式(3)进行转换,假设原始变量集合为X={X1,X2,…,Xn},标准化处理后的变量集合为Z={Z1,Z2,…,Zn},使用sklearn.preprocessing中StandardScaler模块可以快速进行数据标准化处理。本文对检查科室总数、采血科队列人数、一般检查科队列人数、眼耳口鼻科队列人数、内科队列人数、外科队列人数和彩超科队列人数进行标准化处理。
(3)
式中:μ是该变量的均值;s为该变量的标准差。
(2) 独热编码。独热编码即一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。如对0和1进行编码,首先只有两个状态就是需要两个状态寄存器,将其编码为00和01。独热编码使得特征间的距离度量合理,不过会增加特征维度。本文使用Python的第三方库pandas中get_dummies()方法对进入队列时刻、采血科是否检查、一般检查科是否检查、眼耳口鼻科是否检查、内科是否检查、外科是否检查和彩超科是否检查共7个离散特征进行独热编码。
2.4 数据集切分
为评估模型的泛化性能,将实验源数据集,共计8 110条实验源数据,随机选取80%的数据(6 488个样本)作为训练集,20%的数据(1 622个样本)作为测试集。

表3 数据集大小
2.5 模型评价指标
使用两个指标MAE和MAPE度量Lasso、Ridge、GBDT、XGBoost、LightGBM模型的预测精度。
(1) 平均绝对误差(MAE)。平均绝对误差可以直接衡量预测值与真实值的差值大小,具体MAE计算方式见式(4)。
(4)
式中:n为样本个数;yobs,i为第i个实验数据的真实值;ymodel,i为第i个实验数据的预测值。MAE值越小说明算法预测精度越高。
(2) 平均绝对百分比误差(MAPE)。平均绝对百分比误差不仅仅考虑预测值与真实值的误差,还考虑了误差与真实值间的比例。MAPE计算方式见式(5),MAPE值越小说明算法预测精度越高,由式(5)可知当实际值为0时公式将不适用,因此在计算MAPE时将实际值为0的样本删除。
(5)
式中:n为样本个数;yobs,i为第i个观测样本的实际值;ymodel,i为第i个样本的预测值。
2.6 计算结果分析
模型验证实验电脑配置为64位Window 10操作系统,8 GB运行内存,Intel Core i5- 8250U处理器。使用Python3.5编程语言进行分析建模,建模过程主要使用到的包和机器学习库有pandas、numpy、matplotlib、seaborn、sklearn。
使用机器学习算法构建预测模型时,参数对模型的预测结果影响较大。对于Lasso模型,选取alpha和max_iter进行寻优;对于Ridge模型,选取alpha进行寻优;对于GBDT模型,选取learning_rate、n_estimators、max_depth和subsample这4个主要参数进行调优;对于XGBoost模型,选取learning_rate、n_estimators和max_depth这3个参数进行寻优;对于LightGBM模型,选取learning_rate、n_estimators、max_depth、num_leaves、min_data_in_leaf、feature_fraction和bagging_fraction共7个主要参数进行调优。使用随机搜索自动选取参数。具体步骤如下:(1) 确定参数的寻优区间;(2) 为每个超参数定义成均匀分布;(3) 根据给定的分布进行随机采样,然后根据得到的采样结果进行遍历。使用sklearn中RandomizedSearchCV模块可快速进行随机搜索。使用5折交叉验证选择参数,超参数寻优时采用MAE为评分函数。确定参数后分别评估各模型在测试集上的预测性能,并整理实验结果如表4所示。
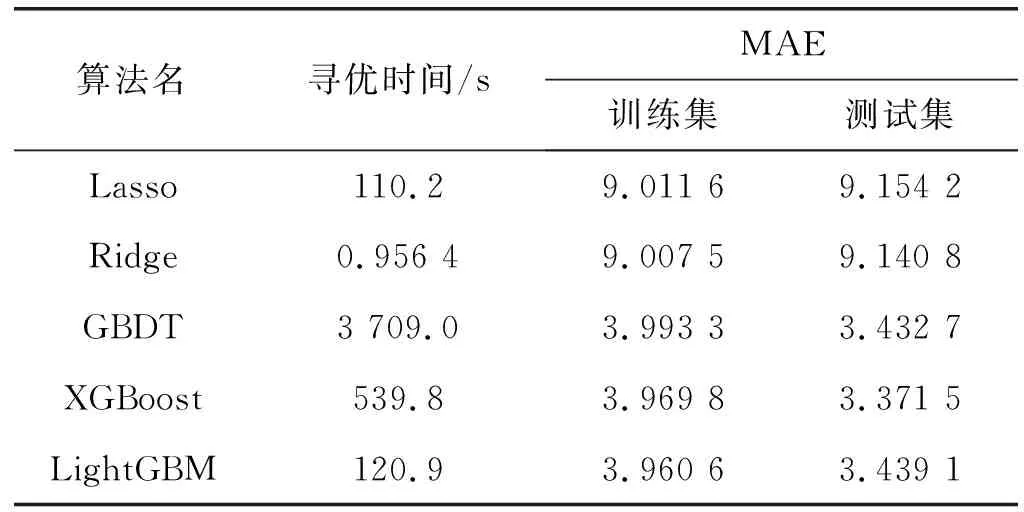
表4 不同模型寻优耗时与MAE值对比
可以发现Ridge寻优时间最短,预测性能较差,在测试集上MAE仅为9.140 8。GBDT、XGBoost、LightGBM都可以取得较好的预测精度,MAE约为3分钟左右,但是LightGBM模型可大幅降低寻优时间,其寻优时长仅为GBDT模型的3.3%,XGBoost模型的22.4%。因此,综合寻优时间和预测精度来看,确定LightGBM为最佳模型。
使用MAPE评估各模型的预测精度在测试集上预测精度,通常我们认为模型MAPE小于10%说明预测模型精度较高。如表5为各个模型的MAPE值。可以发现GBDT、XGBoost、LightGBM算法远高于Lasso和Ridge模型预测精度,预测精度分别为8.62%和8.23%和8.52%,满足实际应用需求。

表5 各算法MAPE值对比(%)
2.7 特征重要度
LightGBM建模可使用模型内置函数plot_importance提取特征对于模型的重要度,表6为各特征对模型重要度所占百分比,可以看出各科室队列人数和检查科室总数占比最高,计算可得这些特征占比总计达84.77%。这些特征是影响患者等待时间的关键。

表6 LightGBM模型特征重要度(%)
2.8 预测应用讨论
结合医疗工作,根据预测分析结果给出如下应用讨论:
(1) 体检流程作为典型的多阶段服务流程,患者往往处在焦急的等待之中,在我们的实际应用中,可在预测出的等待时间的基础上加上一段时间,使得患者实际感知的等待时间减少,提高病人满意度。
(2) 对于多阶段服务等待时间预测来说,获取各科室信息是预测的基础,因此建立统一的医疗信息系统尤为关键,结合文献调研分析和本文的研究,采集患者的挂号科室数、各科室的队列人数等信息对预测等待时间尤为关键。
(3) 多阶段服务等待时间预测有助于优化序列预约,减少不必要的过号浪费现象发生,因为目前的情况是每个环节都需要排队取号,存在大量过号,无法了解排队情况,有了患者服务等待时间,可用于最优化序列预约。
3 结 语
本文基于Lasso、Ridge、GBDT、XGBoost、LightGBM建立多阶段服务等待时间预测模型,预测结果显示LightGBM取得预测性能最好,平均绝对误差分别为3.439 1,平均百分比误差为8.52%。本文的不足之处在于LightGBM虽然可以提高预测精度,但与Ridge算法相比,其算法运行时间较长,特别是在医疗大数据的背景下如何在获得较高预测精度的同时降低算法寻优时长是以后研究主要内容之一。
