云环境下数据中台能耗感知的微服务任务调度算法
2023-01-31谢裕清王永利
谢裕清 王 渊 江 樱 李 浩 王永利*
1(国网浙江省电力有限公司信息通信分公司 浙江 杭州 310000) 2(南瑞集团有限公司(国网电力科学研究院有限公司) 江苏 南京 211100) 3(江苏瑞中数据股份有限公司 江苏 南京 211100) 4(南京理工大学计算机科学与工程学院 江苏 南京 210094)
0 引 言
数据中台的理念源自阿里巴巴“构建规范定义的、全域可连接萃取的、智慧的数据处理平台”,数据中台的建设目标是实现前台数据的高效分析和应用[1]。数据中台的机制是通过云计算等数据技术,对海量数据进行采集、计算、存储、加工,并将数据的标准和口径进行统一。数据中台将数据存储为经统一之后所形成的标准数据,构成大数据资产层,进而为客户提供高效服务。
随着数据中台建设与计算机网络云计算服务的发展,数据中台中越来越多的用户开始向云计算提交服务请求,利用数据中台提供的虚拟资源来完成任务,而云服务供应商需要根据云计算的特点、用户的偏好、实际的情况为用户动态地提供调度服务。在数据中台体系中,由于云平台任务调度面临的是一个非定常多项式(Non-deterministic Polynomial,NP)完全问题,引起了众多学者的关注,尤其是云平台下的多任务调度问题成为目前云计算领域研究的一个热点。
数据中台下的云数据中台用户越来越多,在扩大云平台规模的同时,为了提高调度的灵活性并且避免不必要的能耗浪费,云服务供应商提出了微服务架构[2]。微服务架构中的服务是指细粒度的、相互间松耦合的、可独立开发部署的组件。采用微服务架构设计的系统由一组通过轻量级接口实现的通信服务组成。
由于微服务架构将应用系统分为多个细粒度项目,原本单体式应用中的一系列操作可能需要多个服务协同完成,因此需要设计一个任务调度服务来处理关联多个服务的任务,比如在某一操作完成后执行另一类别的一个操作[3-4]。云计算数据中台具有异构性、动态性和地理分布性等特点,微服务工作流任务在云平台执行时,不但要保证任务执行时间满足截止期限制,云服务提供商还要最大限度优化数据中心能耗,否则可能违反SLA(Service Level Agreement)协议。因此,如何设计启发式调度算法并应用到调度系统中来优化任务调度问题中的目标约束成为众多学者研究的核心问题。
文献[5]提出一种基于二次分派问题QAP的调度算法,在任务-资源映射阶段和资源频率分配阶段中同步进行能量优化;文献[6]提出了一个多目标遗传进化算法用于云平台中的任务调度,认为优化问题中的多个目标函数都是相互冲突的,目的是找到这些多目标折中的非支配Pareto解集。文献[7]针对云环境下数据密集型任务的调度问题,设计了一个基于二叉树建模的调度方法,同时满足用户QoS(Quality of Service)需求[8]。
现有云计算环境下的工作流任务调度的研究大多针对独立任务或元任务的特殊形式,忽视了任务间的数据关联与优先约束关系,不能反映应用任务间的实际特征。同时缺少调度大规模复杂的微服务工作流的工作,无法充分利用微服务工作流提高应用的灵活性和敏捷性。
鉴于此,本文提出一种利用Docker容器融入能耗感知的微服务工作流任务调度算法,综合考虑了微服务任务间的数据依赖和优先级依赖,引入了能耗效益函数。在此基础上,设计两个子算法——任务映射算法和任务合并算法,用于协助云资源调度器调度管理提交到云数据中台的微服务工作流任务,最小化数据中台能耗的同时,满足工作流任务截止期限制,以实现用户QoS需求。仿真实验表明,在同等条件下,与经典的EES(Enhanced Energy-Efficient Scheduling)[9]和EHEFT(Enhancing Heterogeneous Earliest Finish Time)[10]等算法相比,在任务截止期长度变化以及子任务个数变化等环境下,本文算法具有较好的综合性能。
本文的贡献如下:
(1) 提出使用Docker容器调度云数据中台的微服务工作流,相比于直接使用IaaS虚拟机,可有效提高计算资源的利用率。
(2) 综合考虑微服务任务间的数据依赖和优先级依赖,体现微服务工作流执行的灵活性。
(3) 引入了能耗效益函数,满足不同的工作流截止期约束条件下,以最小化计算资源租赁成本为目标,有效提高云环境下数据中台调度大规模微服务工作流的经济效益。
1 问题描述及建模
数据中台上基于微服务的应用程序调度可以通过三个组件的属性来表征,即应用程序模型、系统模型和性能模型。应用程序模型定义基于业务工作流调度的应用程序结构;系统模型描述执行应用程序的VM和基础网络;性能模型负责调度优化等任务。这种由三部分组成的视图与定义经典调度问题的表示法一致。
应用模型中基于微服务的工作流模型采用有向无环图(Directed Acyclic Graph,DAG)W=(T,E),其中顶点T={t1,t2,…,tn}代表n个任务,一对相邻任务ti和tj之间的执行依赖性由它们之间的有向边表示,可以附加权重wi,j表示从ti传递到tj的数据大小。任务ti从其每个先前功能接收数据输入并执行预定义的业务逻辑。成功执行后,任务ti的输出数据将立即发送到其后续任务。如图1所示,ti从tj和tk接收输入数据执行其自身的功能,并在完成执行后将输出数据wi,p发送至tp。此处不考虑应用程序模型中功能的计算开销。系统模型IaaS支持运行基于微服务的应用程序的基础环境,其中在互连的物理计算机上保留、部署和执行虚拟机。本文将这样的云环境建模为完全连接的有向图G,顶点由VM集合组成,边由虚拟机之间的一组有向链接组成,VM虚拟机vi和vj之间的每个通信链路li,j与带宽(BW)bi,j和最小链路延迟(MLD)di,j相关联。应用程序的每个功能都由微服务实现,每个微服务都需要部署在一个容器中,该容器的计算能力定义为四元式pci=(c,f,r,d),其中:c表示CPU内核数;f表示每一CPU核的频率;r表示RAM总大小;d表示总磁盘空间。功能ti被映射到微服务msi并由微服务msi实现,然后微服务msi被封装在容器ci中,而计算能力pci部署在VMvy上。
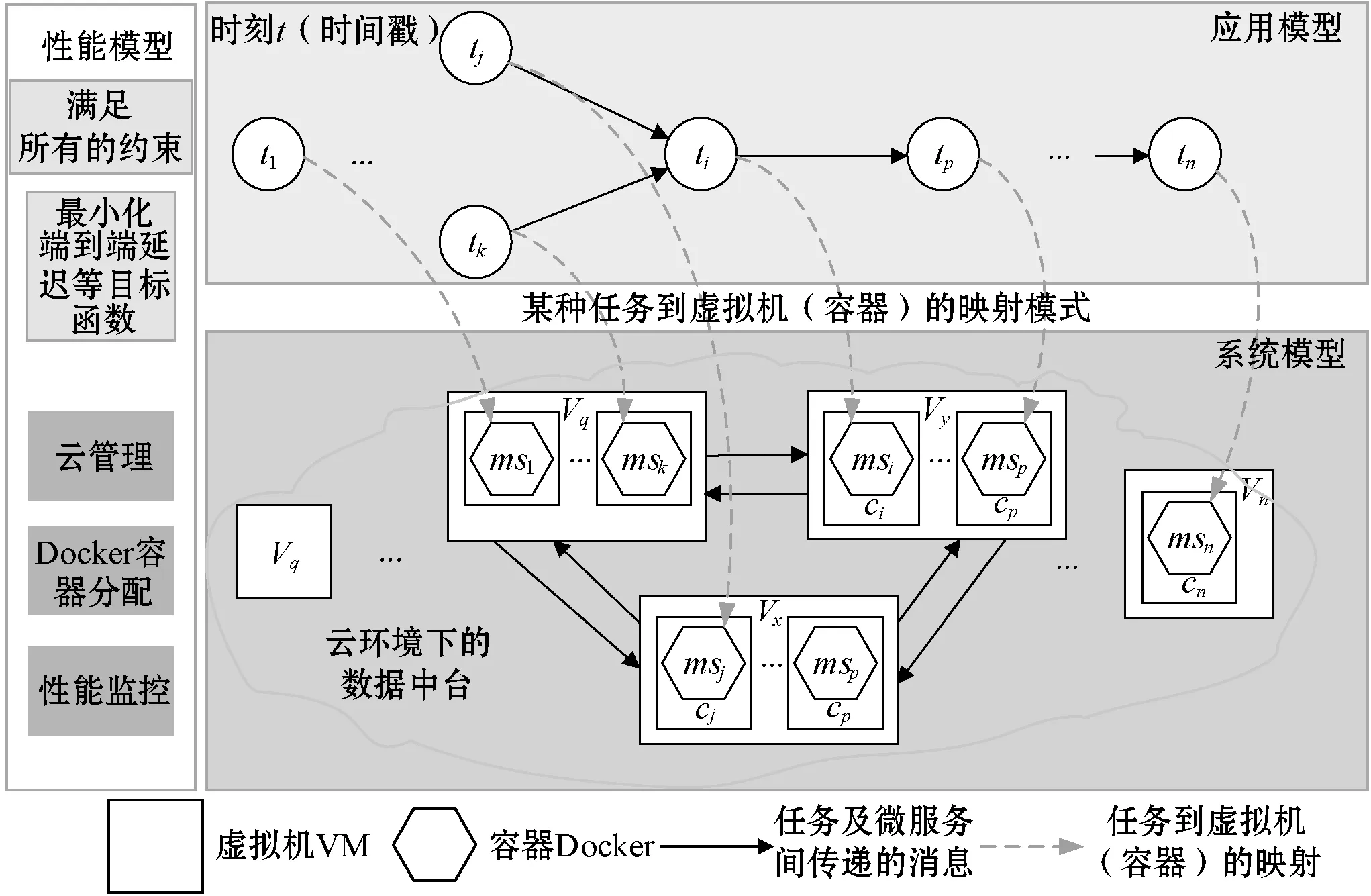
图1 云数据中台上基于微服务的应用程序调度模型
在IaaS中,云提供商以互连VM的形式租用计算资源。通常,提供具有不同计算能力的不同类型的VM,根据计算能力c、f、r、d满足不同的应用程序需求。不同的VM类型以不同的价格收费。以Amazon EC2.3为例,提供五种按需实例类型的配置和价格,Amazon采用分步计费模式,其中VM不足1小时使用时间会被四舍五入到1小时。本文的工作针对单一公共云中的计算环境,在该公共云中物理机通过高带宽Intranet互连,因此不专门考虑数据传输成本。更笼统地说,考虑一个具有l个VM类型的公共云环境vm1,vm2,…,vml,其中每种类型的vmk都与成本和性能相关的属性相关联,并定义为算力、最大功率、带宽三元组。图1给出了在示例系统模型中由vy表示的一个vmk类型的VM实例和由vq和vx表示的两个vmj类型的VM实例。每个通信链路(例如,从vx到vy)是有方向的,并与带宽(bx,y)和最小链路延迟(dx,y)相关联。
性能模型主要负责在公共数据中台云中执行基于微服务的应用程序调度,满足用户指定的预算约束、功耗约束下实现最小的端到端延迟(MED)目标。本文扩展了主要考虑能耗因素,将它们扩展到具有函数间依赖性的应用程序模型中,以识别和量化公共云的功耗成分。使用微服务和容器的一个关键优势是快速复制和迁移的便利性,因此将复制的微服务作为不同的实例运行,每个微服务都可以实现不同应用程序所需的相同功能。
与基于虚拟机的云服务相比,本文设计的基于容器的数据中台微服务模型的技术特征及优势为:
1) 微服务易于被开发人员理解、修改和维护。各个微服务可被独立部署,各个微服务之间是松耦合的,每个微服务都很小,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的,有助于聚焦指定的业务功能或业务需求。2) 基于容器的微服务运行占用的空间少启动速度快且便于迁移。与虚拟机相比,容器中的微服务可以共享操作系统内核,不需要在主机上构建多个虚拟机拥有完整的副本,占用的空间更少,启动速度也更快。每个微服务都可以实现不同应用程序所需的相同功能,可以将复制的微服务作为不同的实例运行,有利于快速复制和迁移。
为简便起见,假设每个虚拟机只对应一个容器。
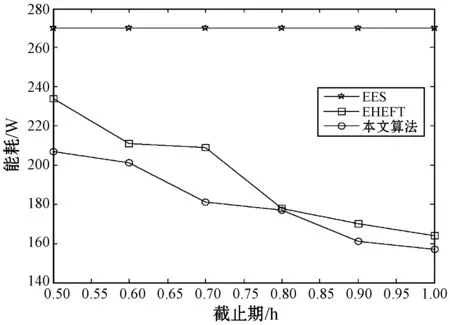
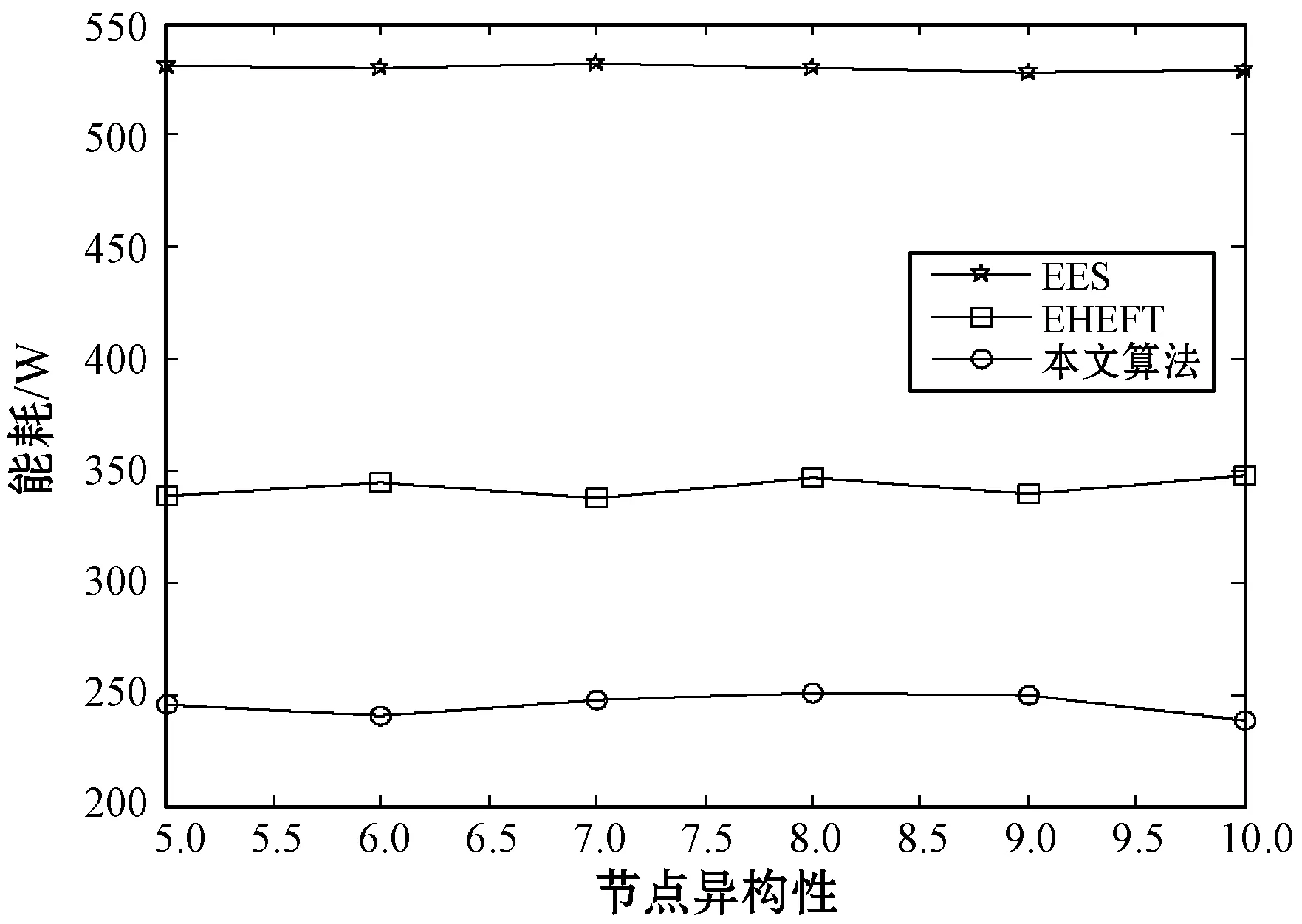
定义1微服务工作流模型。通常情况下,一个微服务工作流W=(T,E)可以用一个有向无环图(DAG)来表示,如图2所示。其中T={t1,t2,…,tn}为工作流中的任务集合,DAG中一个顶点代表一个任务,E是DAG中边的集合,代表任务之间的依赖关系。若任务ti和任务tj(ti,tj∈T,ti≠tj,且1≤i (ti)={tj|(tI,tj)∈E} (1) 图2 一个DAG工作流模型 定义2数据中台虚拟机模型。数据中台提供l种类型的虚拟机的类型集为VM={vm1,vm2,…,vmk…,vml},每种类型VM的虚拟机的特性都可以用(c,pmax,B)三元组表示,其中:c是虚拟机的计算能力,用每秒运算的浮点数(MFLOPS)衡量;pmax是虚拟机的最大功率;B为带宽。不同类型的虚拟机之间满足如下约束关系: (2) 式中:所有虚拟机实例的计算能力和最大功率均按升序排序。式(2)就意味着,虚拟机之间随着计算能力的增强,虚拟机的功耗将随之增加,且增加幅度超过虚拟机计算能力的增强幅度。 定义3基于容器的数据中台虚拟机微服务任务调度问题可描述为:在数据中台中,将微服务工作流的n个子任务分配给m个异构的虚拟资源节点执行(m (3) i∈{1,2,…,n},j∈{1,2,…,m} (4) (5) (6) 定义5虚拟机空闲能耗。当虚拟机处在空闲状态时,CPU芯片会使用动态电压频率调整(Dynamic Voltage Frequency Scaling,DVFS)技术把CPU的电压和运行频率调整到一个较低的水平。因此,虚拟机处在空闲状态时的能耗可由式(7)计算。 (7) 定义6数据中台的总能耗。由数据中台中所有虚拟机实例的总能耗组成(动态能耗和空闲能耗),因此,云数据中台的总功耗Etotal为: (8) 定义7基于以上定义,本文的调度问题可以描述为:找到一个微服务工作流调度方案,使得数据中台执行工作流任务时产生的总能耗最小,且满足工作流任务的截止期限制。可以由式(9)定义。 minEtotal (9) 任务的调度问题面临的是一个NP-难问题[12],本文的目标是设计启发式调度算法以最大限度优化数据中台产生的能耗。下面给出算法的实现以及伪代码。 定义8一个任务的完工时间由两部分组成:该任务真实的执行时间和该任务的依赖数据需要传输的时间。可由式(10)计算得出。 (10) 定义9能耗效益函数。能耗效益函数代表消耗单位的能耗下能完成的工作负载的大小。任务ti在类型为k的虚拟机上执行时的能耗效益函数可以通过式(11)计算。 (11) 式中:分子为任务ti的工作负载;分母为执行任务ti时产生的能耗。能耗效益函数值越大,表明该任务被映射到类型为k的虚拟机上执行时越节能。 微服务工作流任务与虚拟机分配映射算法伪代码: 算法1微服务工作流任务与虚拟机分配映射算法TaskMapping 输入:微服务工作流任务ti,i∈1,2,…,n,虚拟机能耗效益函数集合。 输出:任务ti与虚拟机映射关系map。 3) 初始化任务集R=∅,k=1; 4)whilek≤landR≠∅do 5) 针对任务ti,选取能耗效益函数集合中的第k个虚拟机类型作为目标虚拟机类型,如果ti能在其截止期限执行完成,则选取当前第k种虚拟机类型机为VMopt,把任务ti映射到该类型的虚拟机的容器上,即map:ti→VMopt; 6) 否则,把任务ti放入R中,针对R中的每一个任务,选取该任务的能耗效益函数集合的下一个虚拟机类型作为目标虚拟机类型; 7)enddo 虚拟机类型的能耗效益排序采用快速排序或者堆排序,最优时间复杂度为O(llogl),其中l为虚拟机类型数目,步骤5)到步骤7)算法复杂度为O(nl),n为微服务工作流任务个数。与已有任务虚拟机映射算法相比,本文提出的启发式微服务工作流任务与虚拟机分配映射算法具有复杂度低且满足综合能耗效益函数约束。 定义10两个存在依赖关系的串行任务之间数据传输时间可由式(12)获得。 (12) 式中:data(ti,tj)表示有依赖关系的任务ti和tj之间传输的数据量。 从式(12)可以看出,如果两个串行任务分配到一台虚拟机上执行,那么这两个任务间的依赖数据传输时间就会被节约。因此,下面给出串行任务合并算法的伪代码。 算法2串行任务合并算法TaskMerging 输入:微服务工作流任务ti,i∈1,2,…,n,虚拟机能耗效益函数集合。 输出:微服务工作流任务集。 1) 初始化空任务集合,记为T。 2) 对工作流中的任务进行拓扑排序,然后把所有拓扑排序后的任务放入T中,i=1; 3)while任务集合T不为空do 4)if(ti只有一个直接后继任务且该后继任务只有一个前驱任务,或者ti只有一个前驱任务且该前驱任务只有一个后继任务) then 5) 找到一个虚拟机类型k,满足在(deadline(ti)+deadline(ti+1))时间内能完成ti和ti+1; 7) 合并ti和ti+1为一个新任务t′, 8) 更新t′的前驱任务、后继任务、工作负载和截止期限; 9) 将ti从T中移除; 10)else 11) 不合并ti和ti+1,移除ti; 12)endif 13)endif 14)enddo 图3给出串行任务合并过程示意图,算法复杂度为O(nl),其中n为微服务工作流任务个数。 图3 串行任务合并过程示意图 与已有的串行任务合并算法相比,本文提出的串行任务合并算法考虑到虚拟机能耗效益因素,并且关注存在依赖关系的串行任务合并,显著地节约了数据传输时间。 本文提出的能耗感知的微服务工作流任务调度算法旨在优化云环境下数据中台执行微服务任务时产生的能耗,同时满足任务截止期限制。算法主要由以上提出的两个子算法构成。 算法3能耗感知的微服务工作流任务调度算法 输入:微服务工作流任务集合T={t1,t2,…,tn},虚拟资源节点集V={v1,v2,…,vm}。 输出:任务与资源分配关系矩阵X。 1)while未达到调度评价指标do 2) 调用任务映射算法TaskMapping; 3) 调用串行任务合并算法TaskMerging; 4)enddo 算法复杂度为O(nlm)。 为了验证本文算法在节约能耗方面的综合性能,在不同的仿真参数和性能指标下将其与同样为启发式任务调度算法的EES和EHEFT进行了综合对比分析。实验环境为Windows 7系统,Intel(R) Core 3.20 GHz CPU,1 TB硬盘,8 GB RAM。仿真平台为澳大利亚墨尔本大学的网络实验基于Java语言开发的Cloudsim云仿真平台[13]。在Cloudsim仿真平台中,DataCenter类代表数据中台,VirtualMachine类代表虚拟资源节点,Cloudlet类代表任务。 本实验旨在比较两个子算法随任务截止期变化时的节能性能。实验参数为:虚拟资源节点个数m=10,任务数n=30,虚拟资源节点类型数k=5。实验结果如图4所示。 图4 任务截止期变化对两个子算法能耗的影响 可以看出,随着任务截止期的变长,两者的能耗都在降低,且固定任务截止期时,任务合并算法的节能效果优于任务映射算法的节能效果,其原因在于,串行任务合并算法避免了数据依赖任务之间数据集的传输,而且任务合并后只需要租用更少的虚拟机实例。本文提出的能耗感知的任务调度算法在未达到调度评价指标情况下,综合两个子算法的节能优势,实现综合能耗最优化。 本实验的实验参数与实验1相同,主要考察随任务截止期变化时本文算法与EES和EHEFT之间的节能性能比较,实验结果如图5所示。 图5 任务截止期变化对能耗的影响 可以看出,本文算法的节能性能最优,这说明本文算法在调度任务执行时对数据中台的能耗最敏感,因为本文算法的能耗效益函数总是在满足任务截止期的前提下,借助工作流任务与虚拟机分配映射算法和串行任务合并算法,选择能耗最优的虚拟机执行任务。EHEFT次之,EES的能耗保持不变且维持在一个较高水平,这是因为EES总是选择数据中台中性能最强的虚拟机执行任务,不考虑能耗因素。 实验参数为:虚拟资源节点个数m=30,虚拟资源节点类型数k=5。性能指标比较结果如图6所示。可以看出,随着任务数的扩充,本文算法、EES和EHEFT的能耗都有所增加,但是固定任务数时,EES和EHEFT产生的能耗均高于本文算法,说明在同等条件下,本文算法的能耗效益函数机制在执行任务时节约能耗性能和可扩展性均明显优于EES和EHEFT。 图6 任务个数变化对能耗的影响 实验参数为:任务个数n=100,虚拟资源节点个数m=30。能耗比较变化趋势如图7所示。可以看出,随着虚拟资源节点异构性(虚拟机类型数)的变化,三个算法的能耗变化不明显,跟实验2类似,EES能耗最高,EHEFT次之,本文算法能耗最少。这说明本文算法对虚拟资源的异构性变化不敏感,但是节能性能最优。 图7 虚拟资源节点异构性变化对能耗的影响 综上,本文提出的能耗感知的微服务工作流任务调度算法与已有算法相比,在随任务截止期变化、随任务数变化、随虚拟资源节点异构性变化等几个方面均具有更好的性能。 能耗问题在基于微服务的数据中台云数据中心表现得越来越重要。本文针对云数据中台中依赖任务调度导致的能耗浪费问题,构建了能耗效益函数模型和云数据中台能耗模型,并提出一个包含了两个子算法的启发式微服务工作流任务调度算法对模型进行求解。仿真实验表明,本文算法在能耗管理方面具有较好的综合性能。下一步的工作将是考虑虚拟资源节点的综合成本问题,同时满足基于用户需求和云数据中台节能的多目标优化调度算法,以及采用相应的数学模型来刻画不同的用户需求。

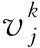
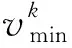
s.t.makespan≤deadline(w)2 算法设计与实现
2.1 任务映射算法

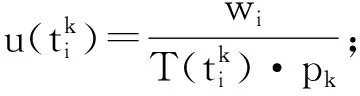
2.2 串行任务合并算法

2.3 能耗感知的任务调度算法
3 仿真实验及结果分析
3.1 两个子算法之间节能性能比较

3.2 随任务截止期变化的性能比较
3.3 随任务数变化的性能比较

3.4 随虚拟资源节点异构性变化的性能比较
4 结 语
