基于注意力机制的模糊数字识别研究
2023-01-31符哲夫
符 哲 夫
(复旦大学 上海 200433)
0 引 言
模糊数字识别是深度学习与模式识别下一个重要的分支。这项技术能够运用在财务报表、车牌识别、快递分拣、犯罪证据判断、试卷成绩统计、银行识别单据、统计金融数据等生活中方方面面,有着十分广阔的应用前景[1]。在全球数据化和人工智能快速发展的背景下,对于模糊数字识别研究的需要变得十分迫切,研究出准确率高并且运行时间短的识别算法有重要的意义和价值。Ghosh等[1]经过实验,发现结合注意力处理能提高大规模分类任务中CNN的性能。Fu等[2]提出了残差注意力网络可以提高特征提取性能。Sonbhadra等[3]共同提出了一种基于内容的模糊数字识别算法,这种算法可以很好地应对图像边界不清的问题。Zoran等[4]提出一种YOLO模型的检测图片内容算法,最后的结果可以放到神经网络的模型中,完成图像的识别。这种模型的检测速度十分快速,同时还有非常可观的准确率,但是其模糊数字的边界处理有一定的不足之处。Wang等[5]合作研究,开发出一种文本的数图像检测模型,使用检测到的数字特征,再定位到数字字符的区域,最后把结果利用二值化的技术后传送到一个全连接卷积神经网络中进行检测。Ma等[6]研究出了数字边缘检测模型,这种模型利用了滑动窗口,可以采用共享权重的方式提取特征,并利用卷积神经网络加以检测,能取得一定效果,但是准确率和时间复杂度仍有提高的空间。
本文主要提出基于注意力机制的SCDM模块,用来应对数字图像识别中可能出现模糊不清难以提取特征的情况[7]。SCDM模块具体可分为通道域(Channel)模块和空间域(Space)模块。使用该模块能够有效地利用图像中的通道注意力信息和空间注意力信息[8],对模糊数字图像的特征加以提取。本文介绍模SCDM模块的基本结构与各模块特征的计算方法,并经过实验验证,在ResNet网络上使用该模块,相较于之前的模糊数字识别方法准确率能进一步提高。
1 模块设计
1.1 通道域模块基本结构
通道域的中心思想是,使用特征中通道之间的联系,生成新的通道注意力图I′,并对通过卷积得到的特征图各通道层分配以不同的权重。这显示了该层所表示特征与目标信息的关联性。相应地,权重越大,这个层所表示的信息越重要,关联性的程度越高。权重越小,这个层所表示的信息就越不重要。获得k维卷积层后,通过压缩函数、Sigmoid函数和比例函数等获得各维的权重w1,w2,…,wk。这些权重将与各通道特征相乘,以获得新的特征[9]。通道注意力模块如图1所示。

图1 通道注意力模块
如果将I∈RC×H×W的特征指定为输入,SCDM将按先后顺序得到一维通道注意力图Mc∈RC×1×1以及二维空间注意力图Ms∈R1×H×W。整个特征提取的过程可以概括为两个阶段:
I′=Mc(I)⊗I
(1)
I″=Mc(I′)⊗I′
(2)
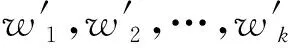
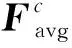
(3)
(4)
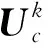
通道域模块注意力特征图的计算方法为:
MC(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))
(5)
通道模块的操作过程可以概括为以下:
(1) 对于一个中间特征图作为输入,利用两种池化方式将每一个二维通道图映射为一个特征量α,α一定程度上具有全局的感受野。最终获得向量的维度k和中间特征图的通道数是一致的。
(2) 利用共享的多层感知器MLP进行调整,可以更好地拟合特征通道间的联系,同时也可以实现轻量级运算,降低时间复杂度。再输出经过调整的特征F。
(3) 将每个向量各个元素进行逐项相加,映射成一个一维向量F′,再输入到Sigmoid函数,这样可以得到位于[0,1]区间内的向量。
(4) 把每一个通道与输入的中间特征图进行加权运算,实现初始特征在通道的每一个维度上重新标定。
1.2 空间域模块基本结构
空间域的设计思路是通过注意力机制,关注空间中的位置特性,将原来图像中的空间特征映射到其他空间中,并保存重要的信息[13]。空间注意力模块如图2所示。

图2 空间注意力模块
对于某个确定的通道域的特征I″,计算空间注意力的主要的思路与通道注意力的思想方法类似。要想获得空间注意力图,需要计算一个二维向量β,该向量对全部区域所有像素点进行通道赋值操作,然后将这个二维向量β输入到一个卷积层当中并获得输出β′。最终将注意力图通过Sigmoid函数进行归一化[14]。
因为卷积操作是把不同的通道和空间信息融合在一起来获得图像特征,因此模糊数字识别中采用这个混合模块来突出沿这两个重要维度(空间域和通道域)的有价值特征[15]。为此,将空间域模块和通道域模块串联使用,从而每个卷积模块都可以单独训练在通道域和空间域上的不同参数。该模块能够利用学习强化或削减某些信息,对于网络内的特征信息的提取具有重要的意义。
空间注意力向量Ct的定义为:
Ct=f(v,ht-1)
(6)
式中:f表示的是注意力映射函数;v表示卷积层获得的输入图像的特征;ht-1表示在t-1时隐藏层获得的状态。
之后用一个神经网络层把图像特征和隐藏层状态一起输入,最后添加Softmax函数用来获得图片的空间注意力分布。
at=ktatanh(kvv+(khht-1))
(7)
γt=softmax(at)
(8)
式中:kta、kv、kh这几个参数都需要通过神经网络学习获得的。
2 实验和分析
2.1 实验环境和数据集说明
实验环境:本文中实验均采用的是如下硬件环境:CPU为Intel(R) Core i7- 920,主频2.66 GHz,16 GB物理主存,GPU为NVIDIA GTX 1080,运行的操作系统为ubuntu18.04,并通过Python3.6环境下编译。
使用数据集:为了验证本文提出模块的有效性,利用了多个数据集进行实验。
(1) SVHN[16],这是源自于Google街景拍摄的数字数据集,数据丰富,包含约30 000幅模糊数字图像。经过优化后,对于图片的预先处理要求比较低。数据集含有两个变量X代表图像,训练集X的张量需要(samples,width,height,channels)等参数,所以需要进行转换。由于直接调用cifar 10的网络模型,数据需要先做个归一化,将所有像素除以255,另外原始数据0的标签是10,这里要转化成0,并提供one_hot编码。
(2) MNIST[17],这是NIST共享集中的一个子数据集,已在特征方面优化过,并添加高斯模糊处理。数据集包含了0~9共10类手写数字图片,每幅图片都做了尺寸归一化,都是28×28大小的灰度图。每幅图片中像素值大小在0~255之间,其中:0是黑色背景;255是白色前景。
2.2 评价指标
模糊数字识别的任务里最通用的评价参数是识别准确率,本文也以图像识别准确率进行识别方法性能评估[18],如式(9)所示。
(9)
式中:K表示测试集中模糊数字图像的总数;Ka表示测试集数字图片预测正确的图片数目,识别准确率可以比较好地反映识别的性能。
平均识别时间可由式(10)得到。
(10)
式中:n表示测试集中模糊数字图像预测正确的总数;Ti表示第i幅测试集数字图片预测的消耗时间。平均识别时间也能反映识别的性能。
2.3 实验过程与结果分析
可以通过实验说明该利用模块的有效性。对于此部分研究,使用SVHN、MNIST等数据集的图片当作训练集并采用ResNet作为基础架构[12]。SVHN分类数据集包含用于训练的8 000幅图像和用于验证的多种类别的12 000幅图像。MNIST数据集则包括了5 000幅数字图像用于训练,14 000幅图像用于测试。采用以上数据集进行训练,224×224规格的数字图像在测试中被用作输入。学习率从0.1开始,训练批次为100,最大迭代次数20 000。
首先,使用ResNet模型在SVHN数据集上进行添加SCDM模块的模糊数字识别实验。先训练采用最大池化的ResNet模型,再将ResNet模型中初始池化层的最大池化替换成了平均池化进行训练[19]。在第一个实验里,单独利用通道注意力模块,并且将压缩比设置为16。实验采用跨通道域的平均池化方法和最大池化方法以及利用标准1×1卷积将通道维数减小为1的通道池[20]。另外,内核大小分别为3和7。在第二个实验中,将之前讨论的通道域模块设置在空间域模块的前面,这是为了将两个模块串联使用。
利用MNIST数据集和SVHN数据集,复现文献[6]的Inception模型的对比实验,发现相比之前的文献[6]的Inception模型,准确性提高了近2.56百分点,如图3和图4所示。另外还作了单独添加空间注意力模块的实验结果对比。可以观察到加了空间注意力模块能得到更高的准确率,这表明两个子模块一起用能得到更精确的提取特征。可以看出添加单通道模块和完整的SCDM模块都能起到一定的效果。同时也能看出,如果只利用单通道模块,而没有利用完整的SCDM模块,结果就会差一些,准确率比后者要低4.35百分点。这说明加入SCDM模块是一种可以提升精度的方法,可以在不增加其他可学习参数的情况下将识别准确率从传统方法的基础上进一步提升。在通道注意力模型里同时利用了平均池化方法和最大池化方法,且压缩比设置为8。

图3 MNIST数据集上的识别准确率曲线图

图4 SVHN数据集在上的识别准确率曲线图
以上的实验结果表明,SCDM模块在ResNet网络中能够提高识别的准确率,但是实验过程仅仅只考虑到了ResNet的网络架构。为了进一步证明该模块的泛化性,另外使用了AlexNet网络模型,添加该模块后进行对照实验。学习率从0.1开始,训练批次为100,最大迭代次数20 000。首先单独利用通道注意力模块,并且将压缩比设置为16。再将通道域模块与空间域模块串联使用。实验结果如图5所示。从实验结果可以看出,在AlexNet网络下使用SCDM模块,准确率比之前的Inception模型提高2.15百分点。这也能看出,SCDM模块在不同网络下准确率均能取得一定的提升,但是在ResNet网络使用该模块提升的准确率较多。
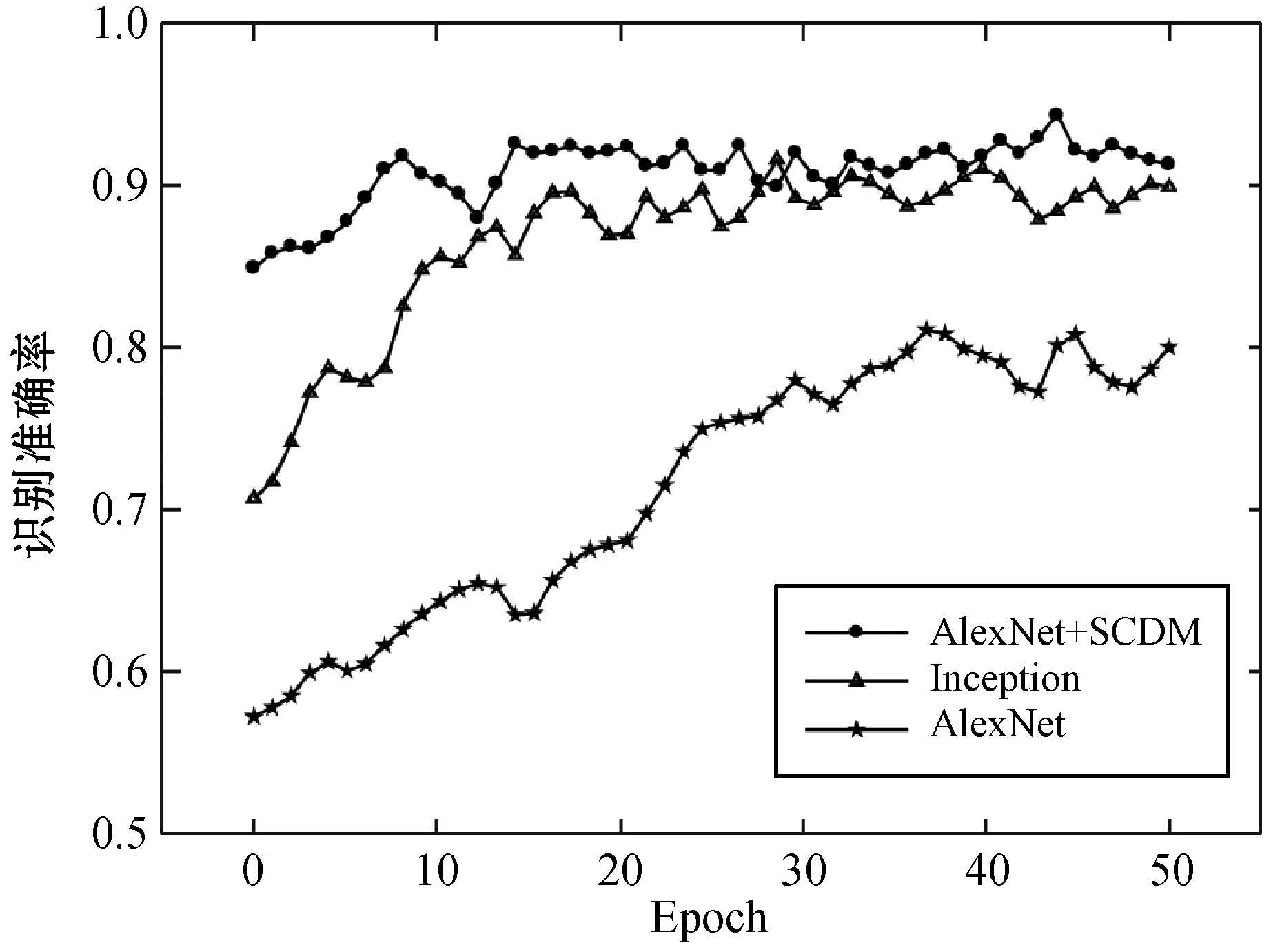
图5 SVHN数据集在AlexNet网络上的识别准确率曲线图
实验结果数据表明在传统的卷积神经网络中通过引入该附加的模块,能有效地利用注意力机制,能从传统的基本网络中获得更高的准确率[21]。这说明用SCDM加强的网络比基础传统网络更有针对性地关注目标特征,同时也说明该模块具有泛化性,在不同的网络中都能使用。特征的提取性能提高主要是因为有效信息的关注和无效信息的弱化[6]。并且通过实验也能发现,在SVHN和MNIST数据集上目标提取识别的性能均有比较好的改进,这也说明了SCDM模块能适用于多种场合的数据集,具有一定的普适性。在对比不同卷积核大小产生的影响时,发现在两种情况下利用更大的卷积核将会产生更高的精度。这说明有必要用一个更大的感受野来确定空间上需要重点关注的区域[22]。因此在计算空间注意力时,可以利用通道数较多和内核较大的卷积层来计算。使用空间注意力模块时,设置卷积核大小为7。此外,也对比了使用该方法和文献[6]方法的识别时间,如图6所示。结果表明相差不大,均在1.01 s左右。这是由于这个模块的运算量相比卷积网络来说不太大,因此引入参数和提高计算时间的花费可以相对忽略[23]。
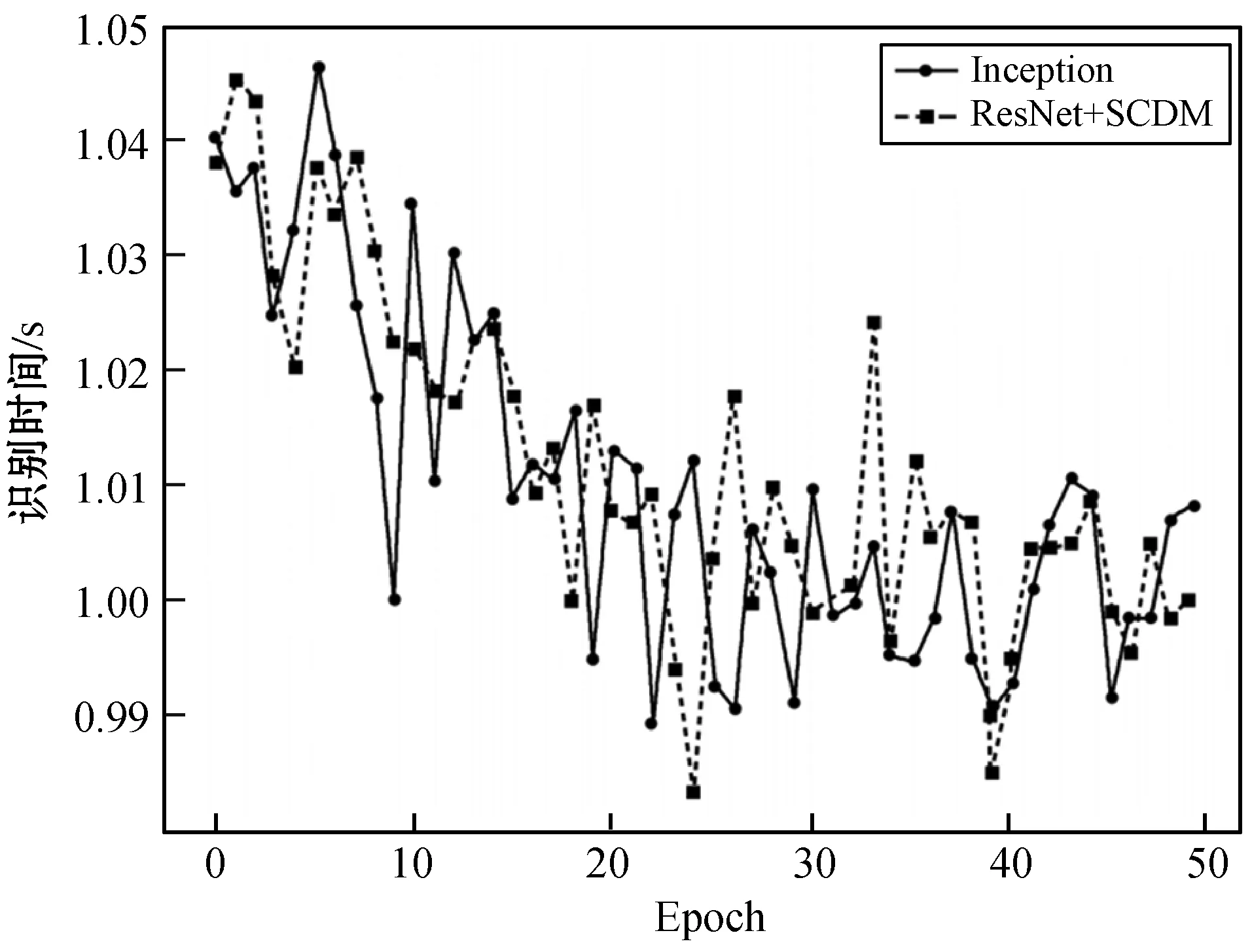
图6 MNIST数据集上的识别时间曲线图

表1 多种方法识别准确率对比
本节进行的实验中,添加SCDM模块的最终分类精确度最高为96.82%。比较现有的方法,采用文献[6]的Inception模型的方法是分类精确度较高的一种方法。与文献[6]的方法相比较,本文方法分类准确度提升了2.56百分点。结果证实利用SCDM模块能有效地提高模糊数字识别的准确率和有效性。
3 结 语
本文对于不同场景下的模糊数字,提出一种基于注意力机制的SCDM模块。在进行训练时应用该模块,使中间的特征图沿着空间与通道两个不同的维度生成注意力特征图,这样能够强化有效信息,削弱无效信息。在传统的卷积神经网络中通过引入该附加的模块,能有效地突出空间和通道上的特征,从传统网络中获得更高的准确率。并通过MNIST和SVHN数据集的实验,验证了运用该模块获得的识别准确率要高于已经存在的方法,说明该模块具有一定的泛化性与普适性,同时也证明了注意力机制的有效性。
