基于共享GPU的深度学习训练性能实证研究
2023-01-31徐涣霖顾嘉臻周扬帆
徐涣霖 顾嘉臻 康 昱 周扬帆
1(复旦大学计算机科学技术学院 上海 200433) 2(上海市智能信息处理重点实验室 上海 200433) 3(微软亚洲研究院 北京 100080)
0 引 言
深度学习技术已经在自然语言处理[1]、图像分类[2]和推荐系统[3]等众多领域中被证明是卓有成效的,甚至在特定领域中超越了人类的表现[4]。这使得深度学习模型被广泛地训练和部署。通常情况下,一个深度学习模型会包含数以千万计的参数。为了能尽可能提高深度学习应用的开发效率,通用计算能力更强的图形处理单元(GPU)被大量应用于模型训练中。
因此近年来随着深度学习应用的普及,GPU越来越被认为是一种重要的计算资源。云端提供GPU计算设备的服务正变得流行。诸如Google Cloud、Amazon Web Service和Microsoft Azure等云平台,已经向开发者提供了GPU云计算服务。出于商业考虑,云服务供应商通常会利用虚拟化技术使得多个应用程序之间共享一个GPU设备[5],以最大化经济效益。因此当用户使用云服务来训练其深度学习模型时,其使用的GPU设备可能同时为其他用户执行训练进程[6]。在运行适当的深度学习模型组合时,GPU云平台的资源利用率有望得到提高,但也可能导致整体训练效率的大幅度下降。如何在这种情境下优化GPU资源分配成为一个值得研究的问题。
我们希望通过研究说明,各种类型的深度学习模型在一个GPU设备上同时训练时,训练进程的具体性能表现和原因。此研究结果可以为提高GPU云平台资源利用率和优化深度学习模型训练进程的调度提供参考,使用户和服务提供商受益。为了达到这个目标,我们精心设计了四个研究问题,并通过相关实验研究来回答这些问题。研究结果提供了训练不同的深度学习模型组合时的性能表现,并且展示了训练进程性能表现与模型属性之间的关系。
1 研究问题
我们在本节提出了四个研究问题。通过回答这些问题,旨在更好地了解在一个GPU设备上同时训练多个深度学习模型的性能表现。首先定义共享训练的概念。
定义1如果训练深度学习模型A和B的进程同时在同一个GPU设备上运行,则称之为深度学习模型A和B的共享训练。
GPU设备的内存资源对模型训练非常重要,因为GPU内存大小决定训练进程是否可以正常运行至结束。在这种情况下,现有的深度学习开发框架的默认设置倾向占用尽可能多的GPU内存。因此,第一个研究问题如下。
问题1当一个深度学习模型单独占用GPU设备训练时,分配不同的GPU内存大小是否会影响它的训练进程运行时间?
这种独占资源的调度使得一个GPU设备每次只能训练一个深度学习模型。如果用于训练的应用程序实际上只需要很少的GPU内存,就将导致资源的浪费。这在GPU云平台中尤其不可取。一种提高资源利用率的朴素方案是让一个GPU设备同时运行多个深度学习模型的训练进程。然而在一个GPU设备上共享训练多个深度学习模型时,训练进程的整体效率尚不明确。我们对几个具有代表性的深度学习模型组合进行了实验,旨在讨论共享训练将使训练性能受到多大程度的影响,不同深度学习模型组合的具体性能表现如何。第二个研究问题如下。
问题2当共享训练深度学习模型A和B时,是否会影响深度学习模型A的训练进程运行时间?如果是,那么模型组合类型是否与训练运行时间变化有联系?是否存在共享训练效率更高的情况?
在回答以上问题后,我们进而研究为什么两个深度学习模型共享训练会对互相的训练进程性能进行产生影响。为了后续研究,分析了不同深度学习模型的底层运算属性。第三个研究问题如下。
问题3不同深度学习模型的运算属性是否存在显著差异?
深度学习模型训练进程所需系统资源主要分为GPU核心的计算资源和数据交换的I/O资源。不同类型的模型对计算资源和I/O资源的需求不同。一个深度学习模型可能是I/O密集型或(/和)计算密集型的。在共享训练中,不同进程可能会相互争夺计算和I/O资源。这种资源竞争可能导致整体性能下降。所以第四个研究问题如下。
问题4共享训练时是否存在系统资源竞争的情况?如果是,是否是导致每个训练进程性能下降的因素?
2 研究方法
2.1 共享训练的性能分析
首先测试共享训练时的进程性能表现。由于在模型的训练过程中每次迭代的时间是相对稳定的,可以使用每次迭代的时间来近似表示模型的总训练时间。首先独立训练每个模型并记录它们的训练时间,再将这些深度学习模型两两组合进行共享训练,以获得各模型组合的整体训练性能表现。定义性能退化系数的概念如下。
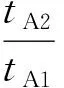
性能退化系数rAB可以表明模型A和B在共享训练中,模型A的性能退化情况,系数越大性能退化越严重。如果两个模型的共享训练比分别独立训练更快,那么共享训练是有益的。共享训练下总训练时间更短的条件的推导过程如下。
首先,假设模型A和B独占GPU时的训练时间分别为tA和tB,共享训练时的性能退化系数分别为rAB和rBA。则模型A和B共享训练时的总训练时间t可以表示为:
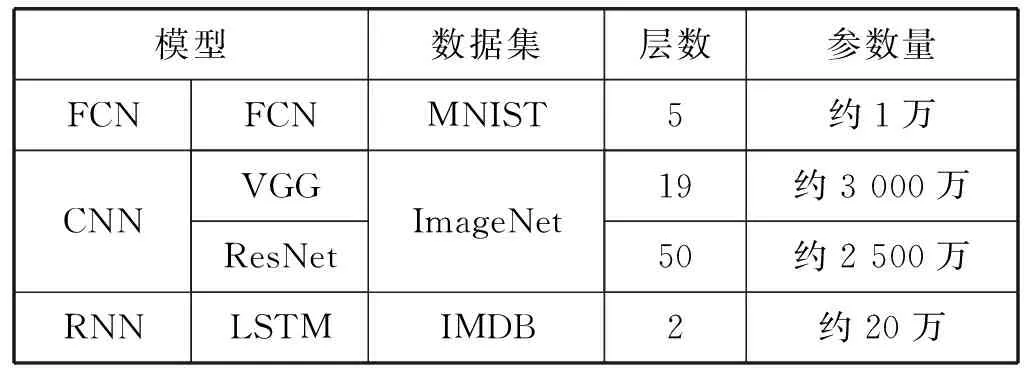
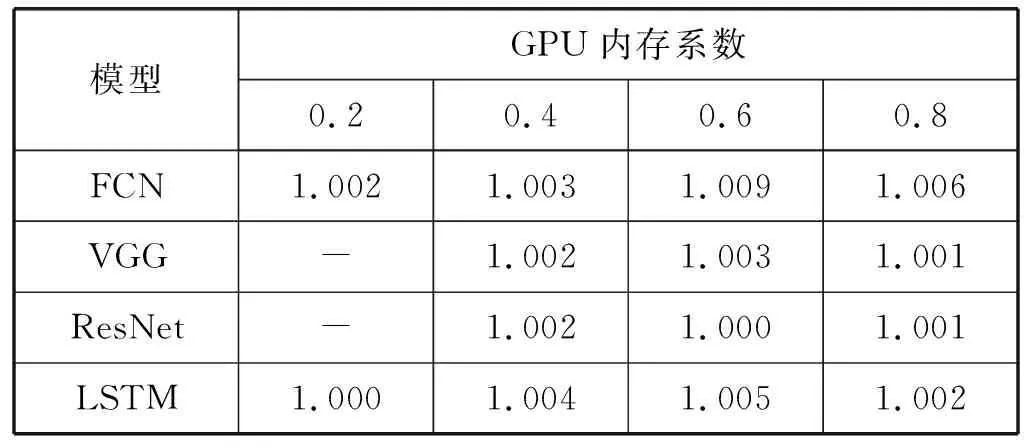
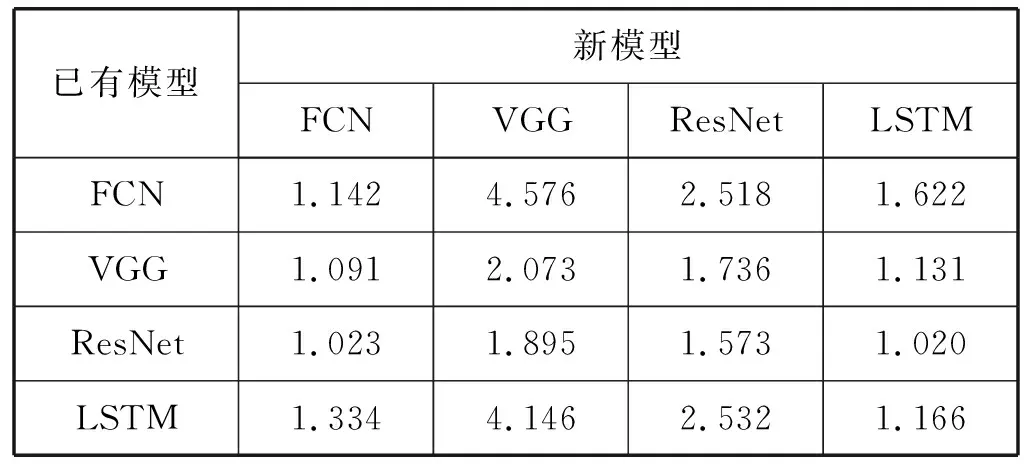
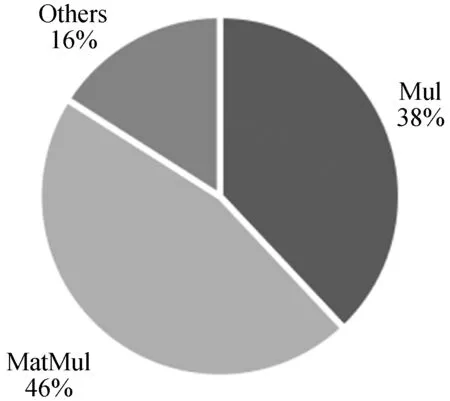
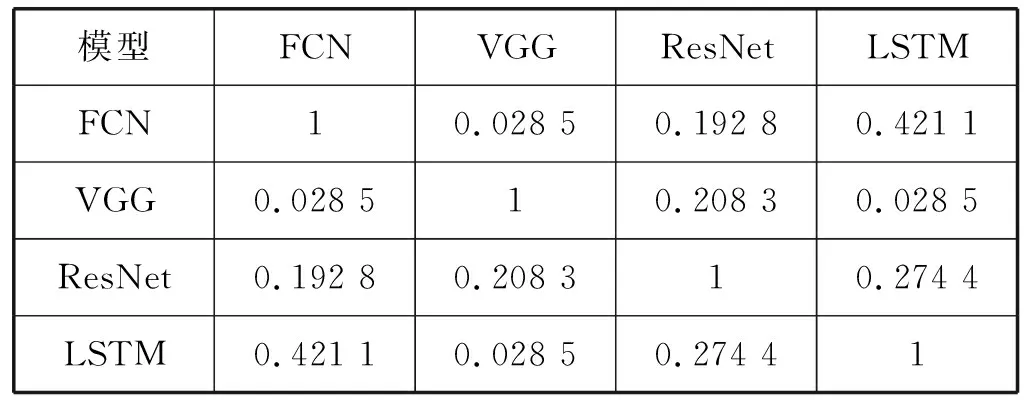
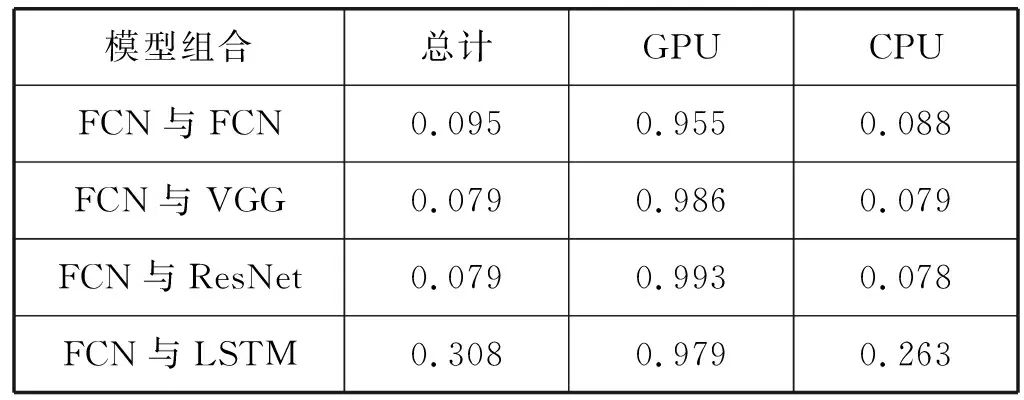
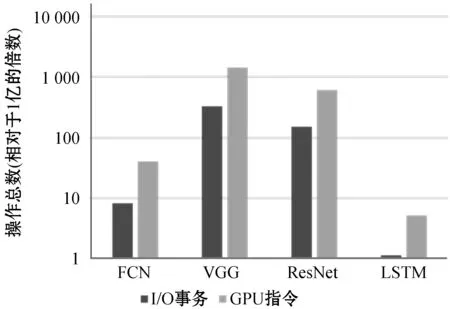
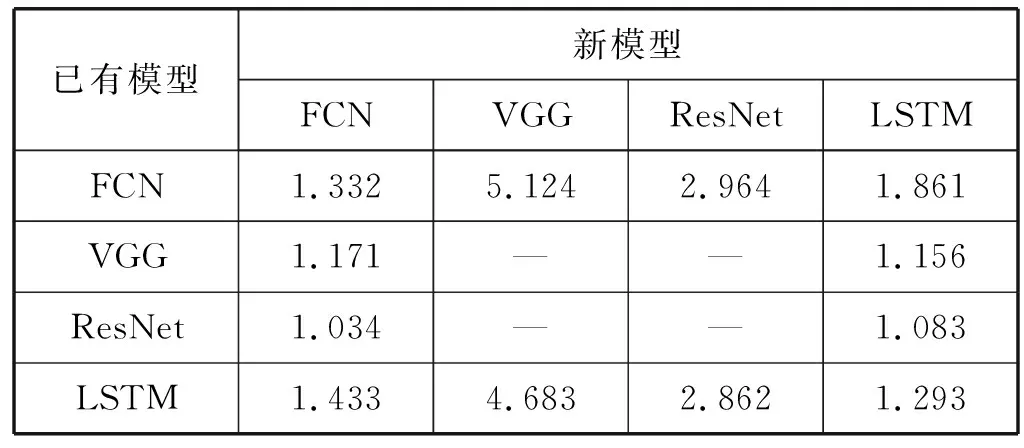
如果有t 综上所述,对于模型A和B,如果我们得到rAB和rBA,可以知道:1) 模型A和B的共享训练相对于每个模型独立训练的性能差别;2) 模型A和B在共享训练和分别独立训练两种情况下,哪种的总训练时间更短。 进一步研究共享训练时进程性能下降的原因。通常,GPU计算和I/O操作的工作负载是影响深度学习模型训练性能的两个主要因素。与GPU计算相关的属性包括进程内的计算操作执行率等。与I/O相关的属性包括进程所需的内存大小、总体数据读取请求速率和总体数据写入请求速率等。以上这些属性描述了深度学习模型训练进程的总体执行特性。我们检验了不同深度学习模型的属性是否存在显著差异。进而比较了在共享训练的过程中,GPU核心利用率和I/O吞吐量与独立训练相比有什么区别,目标是探究共享训练中是否存在系统资源竞争以及对进程性能的影响。为了验证假设结果的相关性,进行KS检验和卡方检验来进一步保证结果的有效性。 以上的研究旨在展示深度学习模型在共享训练过程中的表现以及造成这种现象的潜在原因。为了证明以上实验结果的普遍性,我们在不同的GPU设备上重复了相同的实验,并对实验结果进行了比较。 我们重点关注三类有代表性的深度学习模型,分别是全连接神经网络[7](FCNs)、卷积神经网络[8](CNNs)和递归神经网络[9](RNNs)。这些模型的建模能力是互补的[10],并在众多领域得到了广泛应用。由于深层FCNs的应用受到限制,使用5层全连接网络作为FCNs的代表[10]。为了研究不同结构的CNN,我们实现并测试了两个具有代表性的CNN模型,即VGG-19[11]和ResNet-50[2]。LSTM[1]用于建模序列结构,我们将其作为RNNs的代表。实验中涉及到的模型配置和相应的数据集的细节如表1所示。 表1 实验模型和数据集的相关细节 实验中涉及的所有深度学习模型全部利用TensorFlow 1.13实现,Python版本号为3.6,实验GPU为NVIDIA GTX 1080Ti,测试服务器系统为Ubuntu 16.04,配置了CUDA Toolkit 9.0和cuDNN 7.0。 为了回答问题1,首先通过配置GPU内存系数,来调整训练深度学习模型的应用程序可用的GPU内存大小,接着以独占GPU的模式训练四个目标深度学习模型。对每个模型进行1 000次迭代的训练,并记录训练进程执行的总时间作为训练性能表现的指标。为了保证统计学上的意义,对每种配置分别进行3次训练,计算时间的平均值作为结果。该实验结果如表2所示。表2中的小数表示在该GPU内存系数配置下与使用全部内存(系数为1.0)的训练时间的比值。 表2 不同GPU内存大小下的性能变化情况 从结果可以发现,当分配的GPU内存足够使训练进程正常运行后,训练进程的运行时间变化与GPU内存系数增加没有显著关系。 结论1当深度学习模型独占GPU训练时,如果分配的GPU内存大小已经足够训练进程正常运行,那么额外分配的GPU内存对训练时间没有显著影响。 将之前实验的四种模型进行两两组合,对这些组合进行共享训练,分别记录总训练时间。为了模拟实际应用中的情况,首先在系统后台运行训练模型A的进程,然后启动训练模型B的进程,来研究共享训练模式对模型A的训练进程的性能影响。给每个进程分配所需的最少GPU内存,在共享训练的模式下进行1 000次迭代,并将得到的执行时间与相同配置在独占GPU模式下训练的进程执行时间相除,得到比值作为性能退化系数记录下来。结果如表3所示。 表3 不同模型组合的共享训练性能退化比率 可以看出,在共享训练时每个模型相比于独立训练都会出现不同程度的性能退化。不同的模型组合的性能变化差别非常显著。同时根据之前的讨论,当rAB×rBA 结论2共享训练会使单个模型的训练进程运行时间延长。模型组合类型与训练运行时间变化情况存在联系,且一些模型组合的共享训练效率比分别独立训练更高。 为了研究模型属性与共享训练的关系,需要分析不同的深度学习模型的底层运算属性是否存在区别。我们利用TensorFlow框架内建的分析功能,收集训练进程运行时所有涉及到的运算符种类和其执行时间百分比形成一个运行时运算符集合。 图1以FCN模型为例,展示了运行时运算符集合的分布情况。该模型的运行时运算符集合内包含Mul运算符,并且其数值标记为38%。即表示在该模型中Mul运算符消耗38%的训练时间。 图1 FCN模型的运算符运行时间百分比 在收集到所有模型的运算符集合分布情况后,计算它们的标准化Jaccard相似度。度量结果见表4。可以看出,不同深度学习模型的训练进程执行的底层操作差距确实非常显著。 表4 不同模型运算符集合间的Jaccard相似度 结论3不同深度学习模型的底层运算属性存在显著差异。 在明确了不同模型的运算属性存在差异后,我们进一步研究了不同情况下训练时模型各运算符的CPU和GPU执行时间。表5展示了FCN模型的相关结果。可以看出,共享训练与独占训练比较,模型各运算符GPU执行时间的分布情况几乎相同,而CPU执行时间分布情况表现出显著差异。 表5 不同FCN模型组合共享训练与独占训练的总计、CPU和GPU执行时间的Jaccard相似性 以上的实验结果,尤其是共享训练与独占训练差异很大的CPU执行时间,表明应该深入研究深度学习模型训练时的I/O操作和GPU运算操作情况。我们利用NVIDIA的nvprof工具记录训练进程的两个度量指标,进程的资源加载和存储事务共计为I/O事务,展示了系统I/O请求情况;GPU指令数表明GPU设备上的计算请求情况。结果如图2所示。 图2 模型每秒的操作情况(对数刻度) 可以看出,每个模型的操作量与表1中的模型参数规模呈正相关。同时联系表3中的数据,训练进程的操作量越大,使得共享训练中其他模型性能退化得越多。所以可以得到如下结论。 结论4如果参与共享训练的深度学习模型的参数规模有显著差异,则较小模型的共享训练性能退化比较大的更加严重。 最后,将探究共享训练过程中是否存在资源竞争情况及其影响,在该实验中关注GPU计算和I/O操作的指标。我们将一种模型独占训练和将该模型与其他模型组合共享训练,收集GPU实际占用率作为训练进程的GPU计算情况指标;收集系统内存到GPU内存的拷贝吞吐量作为训练进程的I/O操作特性。应用KS检验和卡方假设检验,验证独占训练和共享训练下的两种指标是否属于同一分布。 图3和图4展示了独占GPU训练与共享训练下的拷贝吞吐量直方图。假设检验得到的p值接近于0,这说明吞吐量分布有显著区别,表明共享训练会影响系统I/O操作。人工比较了不同模式下的吞吐量,发现共享训练时的吞吐量出现了显著下降。 图3 FCN模型独占训练时的系统内存吞吐率 图4 FCN与FCN模型共享训练时的系统内存吞吐率 图5和图6展示了独占GPU训练与共享训练下的GPU占用率直方图。假设检验的结果表明它们属于同一分布。人工比较了不同模式下的GPU实际占用率,发现它们几乎相同。这说明在共享训练过程中,每个模型的GPU计算过程没有受到其他模型的显著影响。 图5 FCN模型独占训练时的GPU实际占用率 图6 FCN与FCN模型共享训练时的GPU实际占用率 我们联系GPU的执行运算的机制分析。由于GPU设备上的不同宿主进程会创建独立的进程上下文,且不同上下文中的操作在执行时都会被底层驱动程序序列化而顺序执行,导致无论模型是独占GPU训练还是共享训练,都会得到几乎相同的实际占有率。即使调度两个训练进程共享训练,GPU在某一时刻也只能进行一个模型的底层运算。这使得共享训练时不同的训练进程轮流占用GPU,导致额外的系统I/O开销,进而使得进程不能很好地利用内存的空间局部性。 结论5共享训练时存在I/O操作竞争的情况,并导致了训练进程性能下降。 为了验证以上实验中的共享训练性能变化情况是否具有普遍性,在性能较弱的GPU设备GTX 1080上重复了所有前面的实验。我们得到的绝大多数结果与之前在GTX 1080Ti上的结果相似。为了避免冗余,表6展示了最主要的共享训练性能退化系数情况。可以看到,GTX 1080上的共享训练性能变化情况与GTX 1080Ti几乎相同。 表6 GTX 1080上模型组合的共享训练性能退化比率 结论6共享训练时的性能变化是普遍存在的,且在相同架构的GPU中性能下降的趋势是相似的。 根据以上实验结论,我们提出了优化GPU云平台进程调度的若干参考原则。 在分配GPU资源时,开发者一般需要考虑GPU内存的分配。根据结论1,可以知道当分配给训练进程的GPU内存足以完成训练任务时,继续分配额外的GPU内存对训练效率几乎没有影响,这将会产生资源的浪费。由此可以得到: 原则1GPU资源调度程序只需确保每个深度学习模型训练进程已经被分配正常运行所需的最小GPU内存。 当一个深度学习模型训练进程所需的资源已经满足时,就可以将剩余的GPU内存分配给其他进程。结论2表明,是否应该同时执行两个或多个模型训练进程,取决于具体情况。总结如下: 原则2当模型组合满足rAB×rBA 结论4显示在共享训练时,较小模型的训练进程性能更容易受到影响。根据结论5,I/O竞争使得每个训练进程的性能都会不同程度的下降。而结论3表明不同模型的运算属性差异明显,这将增加系统的I/O操作量,使得I/O竞争更加严重。为了尽量避免这种影响,可以得到: 原则3虽然某些情况下共享训练可以提高整体训练效率,但其中某些模型的训练进程效率可能会严重退化。在实践中为了保证每个用户的使用体验,应该尽量让参数规模和运算属性相近的模型共享训练。 根据结论6,我们所提出的以上参考原则适用于所有利用CUDA Toolkit执行通用计算任务的NVIDIA GPU。 为了满足现代云计算系统中对通用计算,尤其是深度学习相关的应用程序的高性能需求,开发者引入了GPU虚拟化技术[12-13]。Giunta等[14]实现了提高云平台GPU虚拟化性能的gVirtuS组件。Shi等[15]提供vCUDA以重定向虚拟机中的CUDA API从而启用GPU加速。还有一系列的研究集中在GPU云平台的资源管理上[16-17]。Phull等[18]提出了一个驱动的管理框架,以提高GPU集群的资源利用率。Qi等[19]提出了VGRIS框架,用来虚拟化和高效调度云游戏中的GPU资源。Li等[20]分析和评估GPU云计算中多媒体处理服务的定价策略。 深度学习模型的精度在不断提升的同时,模型的结构和参数规模也变得越来越大,这使得训练和部署变得困难。因此,一些工作的重点是在保持深度学习模型精度的同时减小模型的规模,使模型更适合在云平台上训练和部署[21]。Iandola等[22]提出了一个与AlexNet精度相同的较小的图像分类模型。Luo等[23]通过从神经元中提取信息来压缩人脸识别模型。一部分开发者利用分布式训练的方法提升效率。Storm[24]通过扩展分布式随机梯度下降来加速训练神经网络。Chen等[25]利用数据并行性,通过增量训练加速深度学习机的训练。Iandola等[26]设计了FireCaffe,它专注于跨集群扩展深度学习模型训练,并减少集群间的通信开销。 本文对深度学习模型在GPU设备上的共享训练性能进行了研究。我们重点关注在共享GPU设备资源的情况下,深度学习训练进程的性能表现将如何变化以及产生这种变化的原因。通过实验研究,我们发现在共享训练的情况下,每个深度学习模型的训练进程的执行时间都会延长,部分模型组合的总训练时间会缩短。造成训练进程性能退化的主要原因是额外的系统I/O操作使得进程的等待时间变得更长。这也导致规模相差悬殊的模型共享训练时,小模型的训练进程性能退化的情况更加严重。最后我们证明了以上实验结论具有普遍性,所总结的原则有助于提高GPU云平台上的资源利用率。2.2 深度学习模型属性对共享训练性能的影响
2.3 其他GPU设备上的结果
3 研究结果
3.1 实验设置说明
3.2 GPU内存大小对训练性能的影响
3.3 共享训练对整体性能的影响
3.4 模型底层运算属性的情况
3.5 I/O操作和GPU计算特性与共享训练性能的关系




3.6 其他GPU设备上共享训练的性能表现
4 实践建议
5 相关工作
5.1 GPU云平台资源调度优化
5.2 深度学习模型训练效率优化
6 结 语
