基于HMM-RF模型对新浪微博异常账号的识别与检测
2023-01-31徐建国刘梦凡刘泳慧
徐建国 刘梦凡 刘泳慧
(山东科技大学计算机科学与工程学院 山东 青岛 266590)
0 引 言
以去中心化、开放和共享为显著特征的Web 2.0时代,为社交网络的发展创造了优异的环境。以Twitter、新浪微博和知乎等为代表的社交平台方兴未艾。用户通过这些社交平台可以同他人互动,不受时间和地域限制地发表自己的观点,获取感兴趣的信息和知识等。社交网络为人们日常生活、工作和学习带来极大的便利。然而,有些不法分子则利用社交平台发布广告,甚至钓鱼、色情和暴力等方面的恶意信息,给社会和公众都造成了极大的损害。
新浪微博作为我国最具代表性的社交网络平台之一,截至2019年底,微博月活跃用户总数达5.16亿,与2019年同期相比增长19.36%。由于新浪微博的用户数量庞大且信息传播迅速,不法分子往往混迹其中,他们通常凭借创建大量虚假账号以及盗用用户原有账号等手段获得大量账号,再利用这些异常账号发布恶意信息或执行恶意行为。由此可见,对社交网络中异常账号进行检测、判定和处理,对人们在社交网络平台的正常交互活动具有重要意义。张玉清等[1]通过分析研究异常账号的不同表现形式,对社交网络中异常账号的发展阶段进行了详细的划分,包括创建阶段、发展阶段和应用阶段。其中,在应用阶段,攻击者会大量使用这些异常账号传播钓鱼、色情及反动等方面的恶意信息或进行恶意互粉、点赞和关注等行为获利,给社交网络用户和平台带来巨大的经济和信誉上的损失。考虑到异常账号在应用阶段对社交平台及其用户的影响和危害最大,且这一时期异常账号往往具有明显的行为特征和内容特征,故本文以新浪微博用户账号为研究对象,选取隐马尔可夫模型和随机森林算法进行建模分析,识别应用阶段的异常账号并对其进行详细的划分。
1 相关工作
目前,对社交网络异常账号的检测主要包括基于行为特征的检测方法、基于内容的检测方法、基于图的检测方法以及无监督学习的检测方法四种典型类别[2]。其中,基于行为特征和基于内容的检测方法都是通过特征选择,提取具有代表性的行为或内容特征进行训练,构造分类器,从而在大量账号识别出异常账号;基于图的检测方法关键在于识别异常账号与正常账号各自组成的图中的结构差异;无监督学习的检测方法不仅减少了使用有监督学习的方法在样本标记过程中耗费的时间和精力,还避免了标记的样本数量和质量对检测结果的影响,主要包括聚类和模型两类方案。
异常账号的检测方法并没有明确的分类界限,在实际应用中,通常会选择其中一种或采取多种检测技术相结合的方法,以求实现更高的准确率。
袁丽欣等[3]通过XGBoost算法进行特征选择,并构造分类器,对平衡数据集和非平衡和数据集均能达到较高的检测精度。刘琛[4]在分析用户行为特征的基础上,提取用户的粉丝数、关注数增量及微博中@的数量等特征进行建模并识别虚假粉丝、过度广告、过度转发以及发布恶意信息等异常账号的行为。Egele等[5]选取了time、message source、message text/language、message topic、links in messages、direct user interaction和proximity这7个基于消息内容的特征构建COMPA检测系统,对用户发布的新消息与历史消息特征进行对比,从而识别被劫持账户,也就是常说的被盗用账号。Amleshwaram等[6]则提取了15个消息内容特征用于检测Twitter中的垃圾邮件发送者,并对这些异常账号进行k-means聚类,进而得到在集中时间段传播相同或相似恶意信息以及执行各种恶意行为的具有群体行为特征的spam campaign账号[1]。周清清等[7]先用抽取的特征属性构造分类器进行受害者预测,再将预测结果运用到社交网络图模型中,最后结合随机游走算法将sybil账号[1]从大量正常账号中分离出来。
本文提出一种基于隐马尔可夫模型和随机森林算法相结合的异常账号识别与分类方法。该方法是在对异常账号的特征及表现进行详尽的分析的基础上,首先借助隐马尔可夫模型,完成账号一段时间内状态序列的追溯,从而判断其是否属于异常账号;然后使用随机森林算法对判定为异常账号的样本进行分类;最后给出细致全面的分析结论,从而有效提升了异常账号检测工作的准确率。
2 基于HMM-RF的异常账号识别与分类模型
现有异常账号识别工作多为通过提取特征属性构建分类器,利用分类器对样本数据进行分类,从而直接得到正常账号与各类异常账号。本文提出的方法是将异常账号的检测工作分为两个步骤:首先建立异常账号识别模型,将正常账号与异常账号分离开来;然后再对判定为异常的账号进行分类,得到具体的异常账号类别。
2.1 模型概述
本文提出的模型主要由以下两部分构成:异常账号识别模型和异常账号分类模型。数据集中数据经过清洗、集成和规约等步骤并完成特征提取得到特征属性后,选择合适的特征属性完成异常账号的识别,将识别模型得到的结果用于分类,从而得到最终检测结果,具体检测流程如图1所示。
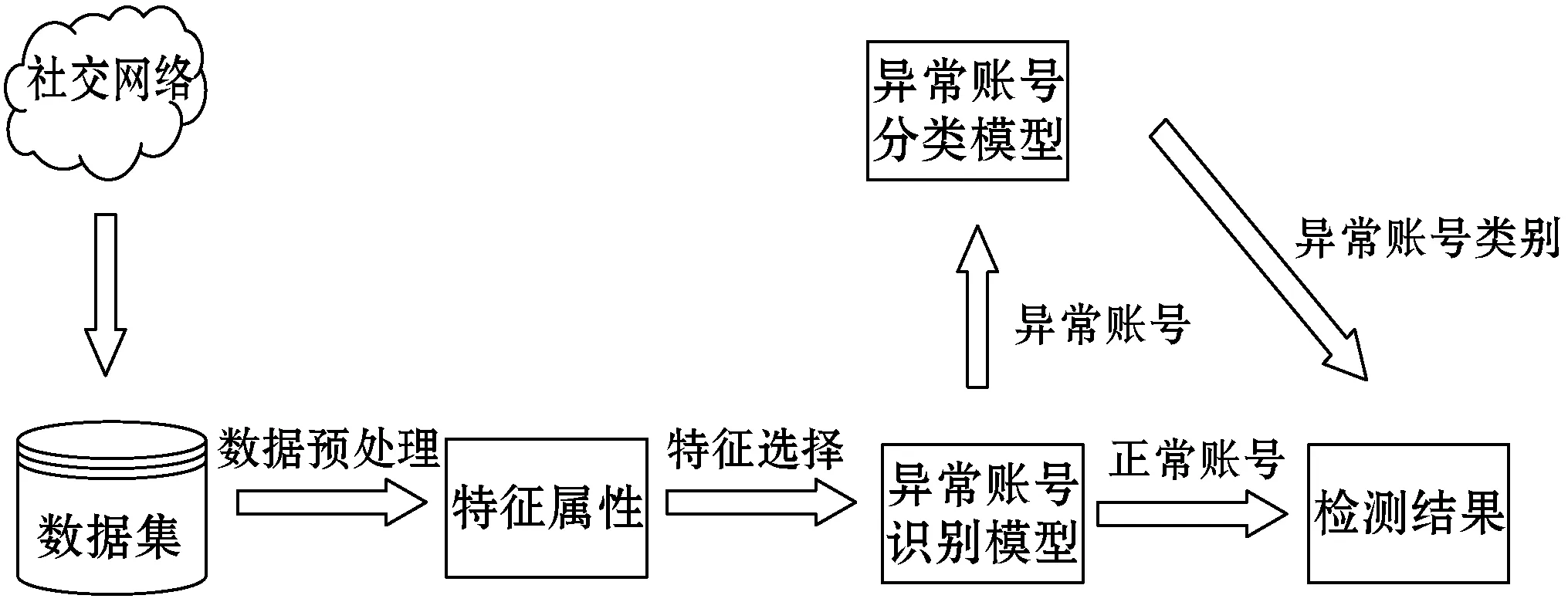
图1 异常账号识别与分类流程
异常账号识别模型采用了基于内容特征的异常账号分析方法并结合隐马尔可夫模型进行构建,从而实现对异常账号的识别,其主要功能在于对输入的样本数据进行判定,若输入样本被判定为异常账号,则由异常账号分类模型进行进一步的分析。异常账号分类模型则是考虑到随机森林算法能够较好地处理高维特征的样本,且与其他算法相比,具有极好的准确率等特点,故本文选取随机森林算法构建异常账号分类模型,从而判断异常账号的具体类别。
2.2 特征选择
微博账号中包含的信息多种多样,主要有用户个人信息、用户行为特征与用户发布微博特的内容特征三个方面。每种信息类型包括的可用于检测账号状态是否异常的特征属性有很多,比较有代表性的特征属性如表1所示。

表1 信息类型与特征属性的对应关系
本文旨在检测与鉴别发布广告、钓鱼、色情及暴力等垃圾信息的异常账号。由于这类账号通常发布上述垃圾信息,其发布的微博内容会同正常账号之间存在很大差异,并且不法分子多致力于广泛传播其发布的垃圾信息,却几乎不会像正常用户那样存在评论、转发和互动等社交行为。
由此可见,异常账号在行为特征与内容特征方面会与正常账号存在明显差异,故本文将在上述两类特征属性中进行特征选择。
本文采用基于网络爬虫的数据获取技术[4,8],可直接爬取微博用户的ID、粉丝数、发博数和点赞数等特征值,对爬取到的用户发布微博的内容采用提取特殊符号等文本处理技术获得用户微博内容中@的数量以及使用一对“#”标识的话题的数量等特征值[9]。将爬取的数据以每个账号一条记录的形式存储在MySQL数据库中,截图如图2所示。

图2 爬取的微博账号信息数据(部分)
本文通过多次试验,统计多个特征对异常账号判断的贡献值,从而得到每个特征在进行账号异常检测时的相对贡献大小。选取用户发微博频率、微博中含URL的比率以及消息相似度三个相对贡献最大的特征作为基本的特征属性进行识别模型的构建。其中,发博频率指的是最近两次发博时间间隔的倒数。为了便于计算,本文使用用户一天发微博条数代替发博频率。URL比率则由用户近期最新发布的100条微博中含URL链接微博与100(发博数量不足100则按实际发布微博总数)的比值计算得到[10]。消息相似度的计算离不开文本向量化方法,考虑到微博字数限制、用户发博习惯和垃圾信息文本本身特点等原因,本文采用TF-IDF[11]的统计方法,以词为单位对消息文本进行向量化。通过文本向量化,计算两个向量的余弦相似度,该值即为两篇微博的消息相似度。
2.3 用户隐私保护
由于识别、检测异常账号需要用到用户的历史行为信息,这就不可避免地带来隐私泄露的问题。现阶段常用的隐私保护手段是基于聚类的K-匿名算法。K-匿名算法是通过对数据进行更概括、抽象的描述和隐匿某些数据项的手段,使每条记录至少与数据表中其他k-1条记录具有完全相同的准标识符属性值,从而减少链接攻击导致的隐私泄露。
采用K-匿名算法实现用户隐私保护首先需要对用户数据类型进行分类:
(1) 显示标识符:用户ID。
(2) 准标识符:昵称、性别、年龄、生日和注册时间等。
(3) 敏感属性:真实姓名、联系电话、邮箱和住址等。
(4) 非敏感属性:粉丝数、点赞数、评论数、转发数和发布微博数量等。
为了保护敏感信息不被泄露,需要对标识序列进行脱敏处理。本文采用数据泛化的技术将可标识列数据替换为语义一致但更通用的数据。如当用户年龄为27岁时,可以用≥25表示。这样年龄作为准标识属性,相同的数值会关联到多条记录,同理,对其他准标识属性进行泛化处理,从而使攻击者无法确定与特定用户相关的记录,也就保护了用户的隐私信息。
2.4 异常账号识别模型建立
社交网络中一段时间内账号的不同状态可以看作一个马尔可夫链,基于这一特性,本文选取隐马尔可夫模型对选取的特征属性进行建模。构建隐状态集S={S1:正常账号,S2:异常账号}和观测变量集V={v1,v2,…,v8}。观测变量集V中的8个观测变量与特征属性值对应关系如表2所示。
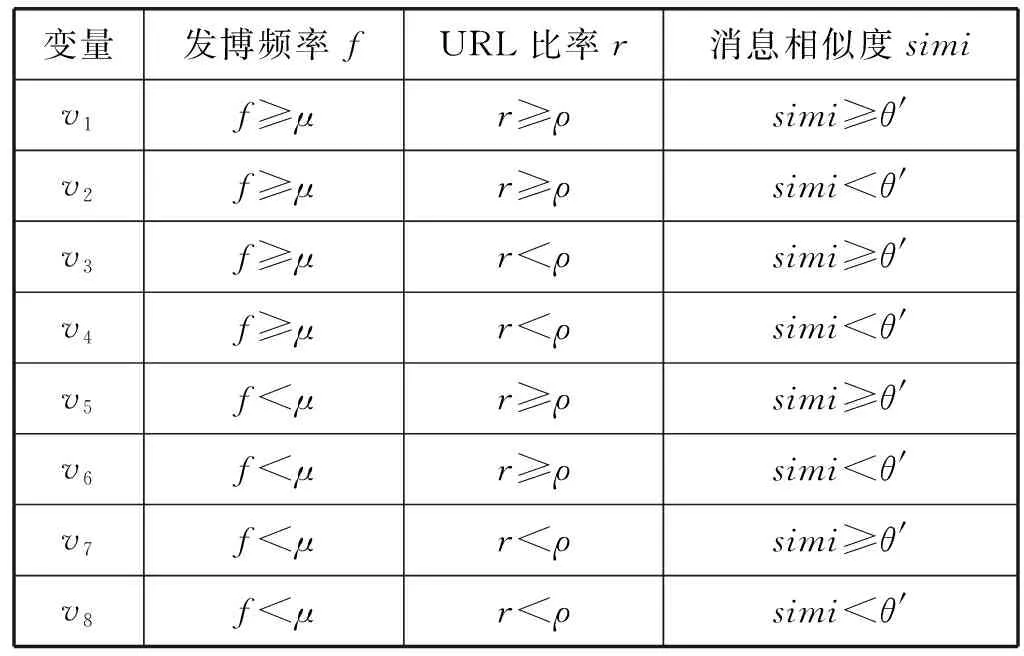
表2 观测变量与特征属性值的对应关系
其中,取μ=1,ρ=0.7,θ′=0.3。由此建立隐状态样本数M=2、观测样本数N=8的隐马尔可夫模型,记为λ={M,N,π,A,B},其中,π表示初始状态分布,A表示状态转移概率矩阵,B表示观测样本概率[12]。
事先随机选取300个新浪微博用户,借助爬虫技术爬取相关数据,经过预处理,选取这些用户20天的数据(即T=20)进行参数训练,最终得到HMM的参数如下:
π=(0.624 6,0.375 4)
(1)

(2)

(3)
利用维特比算法追溯账号的状态序列需定义维特比变量δt(i),表示t时刻之前的状态序列为q1,q2,…,qt-1,且在t时刻的状态为Si产生观测序列为o1,o2,…,ot的最大概率,即:
(4)
设记忆变量φt(i)记录的是概率最大路径上当前状态的前一个状态,显然,有递归关系:
(5)
(6)
最终可得到T时刻的状态为:
(7)
再沿T时刻逆向进行状态回溯,可得:
(8)
最终利用维特比算法求得的最优路径,也就是微博账号的状态序列即为:
(9)
综上,根据得到的微博账号状态序列,判断当前账号是否异常,若属异常,则进行分类,确定其所属异常账号类别。
2.5 异常账号分类模型建立
社交网络异常账号的检测实质上是一个分类任务,简单而言,就是将数据集中大量样本划分为正常账号和异常账号的二分类任务,其中异常账号再细分为多个类别,便于进一步处理。
2.5.1异常账号分类
目前,尚无明确与统一的异常账号分类类别与标准。本文根据异常账号在其应用阶段的表现与危害将其分为以下三类。
(1) 广告散布者:发布的微博内容多为一些与产品、收费服务的网站、App等有关的信息,吸引用户点击链接,购买产品或服务,或下载其推荐的App,并从中获利。这类异常账号的主要特征表现为:微博发布频率高,消息相似度较大且通常包含相关链接。
(2) 虚假粉丝:为实现某些博主在短时间内迅速获得大量关注度的目的,该类账号会根据用户需求对其关注成为其粉丝,但通常仅限于作为粉丝而很少甚至不会与其进行交互。主要特征为:很少或几乎不发布微博,几乎不会与他人互动,关注数量增长异常迅速等。
(3) 垃圾营销:发布包含暴力、色情、钓鱼或反动等信息,以牟取不法利益。主要特征表现为:微博发布频率较高,使用设备次数频繁,更换登录设备及地址频繁,微博中多包含URL。
2.5.2异常账号分类模型的构建
考虑到社交网络账号特征属性多且复杂的特点,同时为了减少筛选特征属性的工作量以及剔除属性造成的信息流失等问题,本文采用处理高维度数据性能比较优异的随机森林算法[13]对异常账号进行分类。随机森林是通过建立多个决策树,并由个别输出树结果的众数决定最终分类结果的分类器[14],该算法工作原理如图3所示。

图3 随机森林算法原理示意图
假设通过识别模型共检测出的异常账号共N个,特征属性共有M个。在构建随机森林时,借助Bagging策略生成不同的数据集,就可以构建多棵决策树,继而形成“森林”。Bagging策略[15]是指通过从样本集中有放回的随机抽取N次的方法生成一个新样本;在M个特征属性中随机抽取m(m< Cp=arg max(count(ci)) (10) 被盗用类异常账号通常是指用户正常使用的账号被黑客入侵并占用,同时利用这些账号牟利。诸如利用这部分账号发布广告或其他垃圾信息;利用该类账号向原本用户好友行骗;窃取他人私密信息从而盗用他人银行卡、手机支付软件等的账号密码。及时、准确地识别被盗用类异常账号,并对用户发出警示,以便用户尽早采取账号申诉、冻结等相应措施避免个人敏感信息以及经济方面的不可挽回损失,对用户个人及新浪微博等社交平台均具有重要意义。 通过对被盗用类异常账号的描述可知,该类账号通常初始状态是正常的,后来突然在某个时间节点变为异常状态。在2.4节中构建的基于HMM的异常账号识别模型可以利用维特比算法追溯账号在一段时间内的状态变化序列。根据该序列,可以对被盗用的账号进行初步判断,即满足上述条件的状态序列对应的账号将被标记为可疑账号。 为了进一步对可疑账号进行分析,本文采用COMPA检测系统[5]确定可疑账号中的被盗用账号,该系统通过该用户在线时长、消息来源、语言、主题、消息中的链接、直接用户交互以及邻近性七个方面分别构建相应的行为模型,其中任一特征发生变化,均会导致异常分数变化,当全局异常分数变化达到或超过设定的阈值时,可以认为该账号被盗用。 通过HMM追溯账号状态变化路径,在识别异常账号的同时,将满足被盗用账号特征的异常账号标记为可疑账号,实现初步判断,再由COMPA检测系统对这部分可疑账号做进一步分析,得到被盗用账号。这样可以大大减少COMPA系统的工作量,从而提升检测效率。 考虑到攻击者盗用用户正常账号最终目的是利用这部分账号牟利,因此这部分账号最终极大可能被用来发布恶意信息或执行恶意行为。根据其在应用阶段的最终表现与危害仍然可以将其归为2.5.1节中划分的三类异常账号中的一种。故本文不将被盗用类异常账号作为重点进行分析,下文的实验仅针对使用HMM-RF模型对正常账号与上述三类异常账号的分类效果进行分析与评价。 为验证本文构建HMM-RF模型的有效性,从新浪微博上收集数据对模型进行检测与评估。并采用随机森林算法(RF)和贝叶斯神经网络(BNN)进行对比分析,以求全面、客观地对本组合模型在异常账号识别与分类能力作出分析和评价。 本次实验用到的数据集是于2019年3月至6月利用网络爬虫技术在新浪微博爬取到的5 000条用户的账号及其相关信息。并在2019年12月对这些账号进行了访问,以验证账号是否仍在正常使用,其中部分账号已被用户自行注销或半年以上未有使用痕迹。剔除这部分账号后,得到有效数据4 437条。 本文实验均在Python 3.7环境下进行。采用本文模型、随机森林算法及贝叶斯神经网络三者在实验环境、操作步骤完全相同的条件下,分别对数据集进行异常账号检测处理,并选取准确率、召回率和F1值[16-18]作为评价标准,为了避免偶然性带来的实验误差,以下实验结果均为重复相同实验五次后取均值得到。 (11) (12) (13) 显然,相比于将正常账号判定为异常账号的代价,将异常账号误判为正常账号对平台和公众来说损失更大,因此,在模型评价指标中,三类异常账号分类结果的召回率应该占据重要的地位[3]。最终三种模型各自得到分类结果如表3所示。 表3 HMM-RF、RF与BNN分类结果对比(%) 续表3 由表3的结果分析可知: (1) HMM-RF模型对正常账号划分的准确率为96.61%,对异常账号中的广告散布者分类准确率高达92.83%,对虚假粉丝的分类准确率到达了81.31%,对垃圾营销类账号而言,准确率为72.05%,均显著优于使用RF和BNN的分类准确率。 (2) HMM-RF模型对正常账号以及本文划分的三类异常账号的分类结果均优于使用RF或BNN模型时的准确率,说明HMM-RF模型具有较强的分类性能。 (3) 对广告散布者这类异常账号而言,使用本文模型召回率为79.92%,而RF和BNN召回率分别达到75.89%和70.38%;虚假粉丝类异常账号使用三种模型得到召回率分别为71.67%、68.66%和73.22%;最后一种垃圾营销类异常账号使用HMM-RF模型和BNN召回率分别能达到67.53%和68.75%,而使用RF的召回率仅有58.75%。 考虑到模型对异常账号的识别能力远比对正常账号的识别能力更有意义,本文HMM-RF模型对三类异常账号的召回率比RF模型分别高出约4百分点、3百分点和10百分点;相比于BNN、HMM-RF对广告散布者和垃圾营销两类异常账号的召回率更高,虚假粉丝中,虽然BNN召回率的值大于HMM-RF,但不足2百分点的优势对应的是17百分点的准确率差异,证明HMM-RF模型具有更好的分类性能和更强的泛化能力[19],在今后应用中也更具使用价值。 现有异常账号检测工作的实质多为将其看作多分类任务,使用分类器将数据集中的数据划分为正常账号和各类异常账号。本文选取隐马尔可夫模型与随机森林算法相结合,构建HMM-RF模型实现了先识别、后分类的异常账号检测。与随机森林算法和贝叶斯神经网络模型相比,本文模型能够显著提高分类精度,在微博异常账号识别与检测的应用方面更具应用价值和潜力。2.6 被盗用类异常账号的识别
3 实验与结果分析


4 结 语
