兴趣点推荐研究综述
2023-01-31谢林基赵铁柱
谢林基 赵铁柱 柳 毅
1(广东工业大学计算机学院 广东 广州 510006) 2(东莞理工学院计算机科学与技术学院 广东 东莞 523000)
0 引 言
随着移动设备的普及和社交网络的发展,用户普遍地在互联网上分享自己的位置信息,以及对签到位置进行评论。基于这些用户数据,基于位置社交网络(Location-based social network,LBSN)的服务应运而生。利用这些用户数据,服务商可以分析用户的行为,挖掘用户感兴趣的兴趣点(Point-of-interest,POI),典型的服务如点评网站Yelp、Foursquare和大众点评等。将用户可能感兴趣的兴趣点推荐给用户,既为用户带来了便利,也能够为商家带来可观的利益。
基于兴趣点推荐服务的商业价值,兴趣点推荐成为了推荐系统的热门研究领域之一。兴趣点推荐面临的首要问题是标签数据稀疏问题,该问题在兴趣点推荐中比起其他推荐系统严重。对此,已有研究者针对兴趣点推荐的稀疏性问题提出了解决方案。解贵龙等[1]利用矩阵分解附加商业地理信息,在数字标牌广告投放的推荐地点问题上,解决了兴趣点推荐中位置访问数据稀疏的问题。任星怡等[2]通过融合兴趣点的地理、文本、社会关系、分类与流行度信息,提出一种上下文感知的概率矩阵分解的兴趣点推荐算法。为了解决用户远离常驻地而面对的数据稀疏问题,卢露等[3]在推荐过程中同时融合用户的偏好和兴趣点的主题分布,提出了一种基于主题模型的兴趣点推荐算法。李鑫等[4]利用社会关系作为规则化项来优化矩阵分解模型,提出一种在社交网络中基于兴趣圈的社会关系挖掘推荐算法来解决冷启动带来的签到数据稀疏性问题。李心茹等[5]利用狄利克雷分配主题模型挖掘用户的兴趣话题,然后融合标签数据来计算相似度来解决用户-签到矩阵稀疏问题。
兴趣点推荐面临的第二个问题是特征提取,该问题具体表现在于对用户行为的挖掘和从兴趣点的图文描述中提取出关于兴趣点的特征。在该问题上,也有不少研究者做出了研究。余永红等[6]在用户对兴趣点访问的频率数据的意义问题上,利用泊松分布模型建模用户的兴趣点签到行为,然后用贝叶斯个性化排序算法(Bayesian personalized ranking,BPR)拟合用户对兴趣点的偏爱,最后通过低于影响力的正则化因子约束泊松矩阵的分解,提出一个基于Ranking的泊松矩阵分解兴趣点推荐算法改善传统推荐算法将访问频率数据与评分数据同一对待的问题。吴海峰等[7]提出一种融合的算法模型,模型融合通过隐语义分析算法挖掘的用户历史行为和通过基于领域的方法结合社会关系和地理位置等因素挖掘出来的用户行为,以实现对用户行为更好的预测。为了改善兴趣点推荐工作中信息挖掘不充分的情况,胡德敏等[8]利用分层狄利克雷过程主题模型学习用户和兴趣点相关的兴趣话题,然后利用核密度估计法,融合个性化地理信息对用户签到行为的影响、用户对兴趣点访问序列的影响和社会关系的影响,基于联合概率生成模型,提出了改进的多类型信息融合的联合概率生成的兴趣点推荐模型。邵长城等[9]利用VGG16深度卷积神经网络模型识别兴趣点图像来改善兴趣点特征缺失问题。
另外,关于兴趣点推荐的研究中,还面对着推荐结果多样性等其他的问题。文献[10]通过兴趣点的地理关系和社会关系计算兴趣点的相关度,然后在此基础上通过谱聚类获得兴趣点的多样性分类,最后通过基于概率因子模型的兴趣点选取和个性化排序方法获得满足用户的个性化推荐列表,解决了以往兴趣点推荐中多样性不足的问题。由于兴趣点推荐算法需要使用用户的历史行为记录,为了避免推荐过程中用户的隐私信息被泄露,文献[11]通过差分隐私保护机制对用户信息进行了保护。
1 兴趣点推荐算法概述
1.1 传统的推荐算法
在推荐系统领域,大多数的算法都是基于内容的推荐算法或者基于协同过滤的推荐算法。
1.1.1基于内容的推荐算法
基于内容推荐算法就是从用户的历史喜好项目中,提取项目的特征,以这些特征表示用户的喜好,然后利用这些特征计算项目间的相似性,将邻近相似项目推荐给用户的一种算法。王光等[12]通过余弦相似度来匹配用户的偏好和项目的特征,其计算式表示为:
(1)
式中:Ik表示第k个项目;wij表示第i个特征在第j个项目中的权重;Ij=(w1j,w2j,...,wnj)表示对于项目j,用户对该项目每个特征的偏好所组成的向量。
基于内容推荐最大的优点是可以忽略用户对项目的实际评分,减缓用户对项目评分稀疏带来的可靠性影响。但是,现有技术对项目特征提取的准确程度造成了该算法发展的制约。
1.1.2基于协同过滤的推荐算法
协同过滤的概念最早由Goldberg等[13]提出。算法的核心概念是在相似用户中,将相似用户感兴趣但目标用户还没感兴趣的项目推荐给目标用户。文献[14]对协同过滤给出了如下描述。
m×n阶矩阵W表示用户-项目的连接矩阵,其中wik表示用户i对项目k的执行行为,wik=1表示用户i执行过项目k,wik=0表示用户i没有执行过项目k。
用户i和用户j的相似度计算式表示为:
(2)
选择与用户i相似度最高的K个用户构成近邻用户集U′,则用户i对未执行项目a的偏好程度表示为:
(3)
由于协同过滤的计算方法是找出相似用户,所以其具有项目内容无关的特点。而它推荐的项目不会涉及项目内容与用户描述的相关性,所以,对于被推荐用户来说,推荐皆具有新异性的特点。同时得益于其算法程序的简单,使得程序具有较好的扩展性和易于实现。
在获得良好推荐效果的同时,协同过滤同时也面临着一些问题制约,如稀疏性、多内容和可扩展性[15]。
(1) 稀疏性。由于庞大的用户数与项目数,导致每一个用户仅对一小部分的项目有评分,这导致计算用户或项目的相似性时难以得到邻近的用户或项目,从而导致低效的推荐结果。
(2) 多内容。大部分协同过滤算法专注于相似用户的计算,而忽略了如何最大限度对项目进行区分,从而导致推荐结果的多样性欠佳。
(3) 可扩展性。由于庞大的数据量,导致计算的时间增加,最终影响到了系统推荐的实时性。
1.2 兴趣点推荐
兴趣点推荐与商品推荐、视频推荐等推荐既有相似之处,也有差异。一般的兴趣点推荐算法主要基于协同过滤算法实现,但兴趣点推荐算法会更多地考虑时空和社交因素。文献[16]归纳了现在用于兴趣点推荐的因素有地理位置因素、分类流行因素、情感倾向因素和社交关系因素,并给出了几个兴趣点推荐中的定量模型,各模型的具体定义如下:
(1) 基于地理位置因素的偏好计算模型。集合L表示所有兴趣点的集合,集合Li={l1,l2,…,ln}表示第i个用户的签到记录,Li∈L。则第i个用户访问第j个兴趣点的评分计算式表示为:
(4)
式中:dist(lj,li)表示第j个兴趣点lj与兴趣点li间的地理距离。然后将式(4)的评分进行0-1规范化作为最终预测评分,计算式表示为:
(5)

(2) 基于情感倾向因素的偏好计算模型。用户对兴趣点的喜好可以从其评论中获知,自然语言处理技术能够对用户的评论进行情感倾向分析,通过将评论中表达的感情进行量化来体现用户对兴趣点的偏好程度,以此协助提高推荐效果。该模型的计算基于一个词与极性词汇表中的词语的相关性强度,若与积极的词语呈正相关,则该词为积极性词汇,反之亦然。Turney等[18]提出了一种基于点互信息的方法来计算目标词与词汇表中的感情词汇之间的PMI,以此来确定目标词的情感极性。两个词wi和wj之间的PMI值定义为:
(6)
式中:p(wi)和p(wj)分别表示词汇wi和wj在语料库中出现的概率,p(wi,wj)表示wi和wj一起出现的概率。
那么目标词wk的情感极性SO可通过式(7)计算所得:
SO(wk)=PMI(wk,″excellent″)-PMI(wk,″poor″)
(7)
最终,可以通过计算评论中所有情感词汇的SO值的平均值来对用户的评论进行量化。所以,对于某个用户uk对兴趣点li的评论rki,该评论代表用户对兴趣点的偏好量化计算式表示为:
(8)
式中:m表示评论中情感词汇的数量。
(3) 用户间的社交关系强度计算模型。朋友会影响用户对兴趣点的选择,越亲近的朋友对用户的选择的影响就越重。因此,可以通过共同朋友的数量来对朋友间的亲近程度进行量化,而朋友间兴趣的相似程度的量化以朋友间共有的兴趣点访问数量来表示。所以,用户和某个朋友间的社交关系强度计算式表示为:
(9)
式中:Fi和Fj分别代表用户i和用户j的朋友集合,Li和Lj分别表示用户i和用户j的签到兴趣点集合。
兴趣点推荐作为推荐系统中的一个特殊领域,它有着自己特殊的发展难点。本文将这些问题概括如下。
(1) 用户标签数据稀疏。在兴趣点推荐中,由于兴趣点需要用户实际到达该地理位置进行签到,而人的精力始终有限,因而在兴趣点推荐比起其他的如商品推荐、视频推荐、音乐推荐等推荐所用数据集面临的稀疏性问题更为严重。商品等这些东西,可以在单位时间内由大量的用户进行体验,并且提供反馈。但是,一个兴趣点在单位时间内,其用户容纳是有限的,而且用户进行体验的成本往往会较电影、音乐等因素高,这同时造成了比起其他项目的推荐,对兴趣点推荐的稀疏性问题的解决会更为困难。
(2) 特征提取。兴趣点推荐中,用户偏好建模是一个重要环节,而对于用户的偏好除了用户预选的标签,更多的是需要从用户的历史行为记录中提取出可以表示用户偏好的特征,常见的是从用户评论中提取用户的喜好。同时,为了匹配用户的喜好特征与兴趣点特征,需要从兴趣点的描述中提取出兴趣点的特征,而兴趣点往往是图文结合描述的,因而会对兴趣点的特征提取造成了一定的阻碍。
2 兴趣点推荐的关键技术研究
基于LBSN的特点,兴趣点推荐存在着其独有的关键推挤技术,如针对兴趣点推荐的标签稀疏性问题解决方案,跨模态的兴趣点推荐技术和基于LBSN的兴趣点推荐框架。本文将这些研究归纳如下:
2.1 标签稀疏性问题
标签稀疏性问题除了来源于一个人不可能在有限时间内到达大量物理位置外,还来源于用户是否愿意共享位置信息等。借鉴了其他推荐系统对数据稀疏问题的解决方案,当前研究人员针对兴趣点推荐也有了大量的解决方案,本文将这些解决方案分为3类:矩阵分解、建模预测和其他解决方法。
2.1.1矩阵分解
矩阵分解就是将用户的签到矩阵分解为几个维度较小的子矩阵,其过程实质上是对用户和兴趣点进行聚类的一个过程,因而最终减弱了模型所需的用户-兴趣点签到数据的稀疏性。
对于兴趣点推荐,矩阵分解在该领域的应用中往往融合了诸如地理位置、社交关系和签到上下文等额外信息。解贵龙等[1]融合矩阵分解算法和地理信息数据来解决数据稀疏性问题。龚卫华等[19]通过建立基于非负矩阵分解的联合聚类目标函数,函数同时融入用户社交关系、用户和位置的签到关系以及兴趣点特征等多维度的影响因素,通过利用这些因素分别对用户和兴趣点进行聚类来缓解数据稀疏问题。李全等[20]提出了基于LBSN动态异构网络的时间感知兴趣点推荐算法,该算法在LBSN异构网络模式中增加会话节点类型,设置用户-兴趣点之间的动态元路径集,计算动态路径的偏好度,通过矩阵分解模型对动态偏好矩阵进行矩阵分解来解决签到数据稀疏性问题。张进等[21]提出了一种融合社交信任的矩阵分解算法,该算法利用BPR模型来优化矩阵分解的过程,同时在相似度结合中融入信任度因子来解决用户签到矩阵稀疏问题。廖国琼等[22]利用高阶奇异值分解算法对用户-主题-时间三阶张量进行分解,计算用户在不同时间段对不同主题的偏好评分来解决数据稀疏性问题。任星怡等[2]提出一种上下文感知的概率矩阵分解兴趣点推荐算法TGSC-PMF,该算法通过将地理、文本、社会、分类与流行度信息融合来解决数据稀疏性问题。高榕等[23]在基于矩阵分解的推荐模型上,融合关于兴趣点的评论信息、用户社交关系和地理信息来解决数据稀疏性问题。
2.1.2建模预测
在兴趣点推荐中,面对数据稀疏,不少研究者采取的策略是融合各种与用户选取兴趣点相关的信息,构建用户对兴趣点的偏好模型,从而预测空白的评分。
(1) 基于单源信息的建模。许朝等[24]通过将2-度好友引入协同过滤算法中构建社交影响模型,计算历史记录与好友相似度获得2-度好友对用户的社交影响来解决签到数据稀疏问题。苏畅等[25]利用用户签到的相似性,结合兴趣点的类别信息和用户信任度建模来解决数据稀疏性问题。
(2) 多源信息融合建模。随着融合信息进行预测方法的深入研究,越来越多的研究者并不局限于某一个因素,而是一次性融合多个因素进行建模预测。在文献[26]中,提出了一种基于社区发现的兴趣点推荐算法CBR(Community-Based Recommendation)。该算法先将兴趣点的按主题聚类,并计算目标用户与主题的相似度,然后将地理位置聚类,计算用户在地理位置簇上的隶属度,最后融合用户的社交关系来预测用户对各个兴趣点的偏好评分。彭宏伟等[27]除了用户的签到数据,还利用兴趣点的地理位置、社交网络数据、兴趣点类别信息辅助对用户签到行为进行建模来解决用户签到数据的稀疏性。Zhou等[28]将用户对POI的预测评分建模为用户偏好、朋友重要性和POI间的签到相关性量化分数的权重和。首先基于协同过滤算法,计算用户访问某个POI的分数作为用户的偏好量化。然后将用户访问POI的余弦相似度和以0/1表示的用户社会关系的权重和作为朋友重要性的量化,在将朋友重要性与该朋友对应的POI访问频数之积作为用户对POI访问的分数。接着利用幂律分布,基于用户的历史记录计算用户访问某个POI的概率作为POI间签到相关性在POI推荐中的分数量化。最后将3个量的线性相加作为对用户访问某个POI的预测分数来消除数据稀疏问题。Zhang等[29]将用户对POI的评分建模为图像影响力和地理影响力的权重和。该融合框架将图像特征用于建模POI-POI和POI-群体间的关系,再基于这些关系进行权重矩阵分解得到用户和POI的隐向量,将这些隐向量用于图像影响力的计算。同时利用幂律分布对用户的地理偏好进行建模得到地理影响力的量化。Lyu等[30]设计了名为iMCRec的框架融合用户对POI的地理偏好、类别偏好和属性偏好进行推荐。融合框架先基于用户的历史记录,利用文献[31]的二维KDE模型对地理偏好进行建模;利用TF-IDF模型对类别偏好进行建模;利用TF-IDF和信息熵对属性偏好进行建模。之后利用其他用户的历史记录,基于协同过滤算法对之前用户的3种偏好添加权重。最后基于MCDM算法利用3种偏好的评分对POI进行预测评分。
(3) 其他建模预测方法。李心茹等[5]利用最近邻的兴趣点预测签到缺失的兴趣点的访问概率,以此解决数据稀疏性问题。鲜学丰等[32]将用户周期性的行为作为上下文情景信息,融合用户本身签到的上下文情景信息来扩大有效数据缓解数据稀疏性问题。任星怡等[33]设计了名为GTSCP的联合概率模型来模拟用户的签到行为决策过程,以此预测用户签到来解决数据稀疏性问题。曹玖新等[34]提出了一种基于元路径的兴趣点推荐算法,该算法将LBSN构建成一个带权的异构网络,该网络的路径用元路径来表示。对于实例路径中,首尾节点之间的关联程度,算法通过利用随机游走算法计算出的元路径特征值来衡量。而对于各特征的权值,则通过监督学习取得。最终利用这些参数预测用户在各兴趣点的签到概率来缓解数据稀疏性问题。
2.1.3其他解决方法
除了进行矩阵分解和建模预测用户偏好的方法外,还有诸如改善推荐模型等一些方法。
李丹霞等[35]提出了一种融合时空信息的连续兴趣点推荐算法,该算法将用户的签到行为建模为用户、当前兴趣点、下一个兴趣点、时间段的四阶张量,通过LBSN中的地理信息计算用户对兴趣点的地理距离的偏好,最后利用贝叶斯个性化排序算法BPR(Bayesian personalized ranking)优化目标函数来解决数据稀疏性问题。单硕堂等[36]利用用户专家的评分数据进行训练来缓解数据稀疏性问题。卢露等[3]为了解决用户远离常驻地时造成签到数据稀疏,基于隐含主题模型融合了用户的偏好分布和兴趣点主题分布来解决该问题。
2.1.4稀疏性问题解决技术小结
矩阵分解方法降低了用户-签到矩阵的维度,降低了计算资源的需求,加快了推荐速度,提高推荐系统的实时性,这对于兴趣点推荐是一个良好的解决方案。对于用户来说,对兴趣点的推荐需求往往是随时间变化而变化的。所以,一个高效运转的兴趣点推荐系统在时间性能方面可以很好地满足用户。但是这种方法的本质是聚类的一种方法,因而其最终结果会缺乏个性化。
建模预测方法可以有效填补用户-签到矩阵或者用户-评分矩阵的空白,对数据稀疏性的改善比较直接。但是该值始终并非用户的真实意愿,所以其预测偏差最终会影响推荐结果的准确性。同时由于在兴趣点推荐中一般会结合多种因素进行预测,这些因素除了可见的文本和图像等,研究者更多考虑的是事物间的联系这种抽象的信息,所以,对于其他信息的定量与融合是一个难点。
2.2 跨模态推荐技术
在LBSN中,图片与文本是常见的两种数据。文本主要承担着用户偏好和POI描述两种角色。图片主要承担了用户签到和POI描述两种角色。而从单独的某种数据类型来看,它们的特征也同样呈现着多模态。而不同模态间的互补可以更好地对信息进行表达,因此,对多模态进行融合的跨模态推荐方法是当前POI推荐的研究课题之一。
2.2.1跨模态推荐
兴趣点推荐有着不同模态的数据进行推荐计算,而单独某种类型的数据,从其特征来说,也会呈现不同的模态,对于如何利用不同的模态进行信息互补,提高推荐结果的准确性是当前研究者热衷研究的课题之一。
Li等[37]利用DCA模型取得从图片中提取的HSV、LBP、SIFT、VGG16和RGB特征间的跨模态联系,然后通过贝叶斯个性化排序算法获得用户对POI的预测评分。并且结合基于问卷调查和分层采样模型得到的POI预测评分对用户进行POI推荐。推荐结果比起基准算法更加高效稳定。Chen等[38]先利用LDA(Laten Dirichlet Allocation)模型对评论进行软聚类,然后将评论的TF-IDF特征和情感特征作为模态,并利用这两种模态构造超级图得到基于主题的跨模态超级图。最后利用验证集中的评论与超级图中顶点的相似性预测项目的评分进行推荐。推荐结果对比基于朴素贝叶斯、最大信息熵、支持向量机和基于字典等方法对评论的情感分类作出推荐的准确率更高。为了更为准确地匹配图像与文字,Otto等[39]先提取图像和文字的语义与实体特征,然后在CMI(Cross-modal Information)准则、SC(Semantic Correlation)准则和描述图像与文本间关于相对重要性的层次关系的状态准则下,基于这两种特征利用深度学习对图像和文本的联系进行分类。从而提高了推荐的准确率。郭斌等[40]利用卷积神经网络CNN和循环-卷积神经网络CNN-RNN跨模态分析图像与文本的联合分类,最后基于分类用关联规则进行旅游路线的推荐。
跨模态技术的研究对推荐系统的准确性起到了积极的推进效果,而在跨模态推荐中常用到的是图片与文本及它们的特征。因而图片与文本特征的提取是跨模态推荐的基础。
2.2.2图片特征提取
当前图片特征的提取中,常见的提取方法有CNN、EMK(Efficient Match Kernels)[41]、KDES(Kernel Descriptors)[42]、SC(Sparse Coding)[43]和RBM(Restricted Boltzman Machines)[44]等。其中以神经网络方法最为常用。
侯媛媛等[45]利用卷积神经网络多层特征融合提取出图像特征。生龙等[46]利用卷积神经网络CNN特征提取的方法结合全卷积神经网络像素位置预测功能,将卷积神经网络卷积层提取出的特征图与同类标签特征图交换,加强图像的特征提取效果。Qing等[47]利用PCNN(Pulse Coupled Neural Networks)提取图像的时间序列特征和熵序列特征。在众多的研究基础上,闫河等[48]通过从网络架构和内部结构两方面对深度神经网络AlexNet进行改进和优化,进一步提升了特征的表达能力。郭文慧等[49]提出了名为提出3D多尺度特征融合残差网络的方法,该方法先对图像的3D-HSI数据进行自适应降维,并将降维后的图像作为网络的输入。然后,利用多尺度特征融合残差块依次提取光谱-空间特征,并且融合不同尺度的特征,最后通过特征共享增强信息流以此来获得更丰富的特征。梁华刚等[50]通过将图像中背景信息丢弃来减少干扰,然后建立一个由特征提取网络、注意力区域定位网络和特征融合网格组成的特征提取模型,利用模型的级联结构完成将特征由全局到局部的转移,以此完成目标在图像中较细粒度的识别。Kim等[51]通过将图像转换的颜色转换到YUV颜色空间,然后利用YUV得到的像素的正信息和逆信息的权重和提出一个基于tone mapping的模型从低动态图片中提取更多的SIFT(Scale-invariant Feature Transform)特征。
除此之外,还有一些别的方法,如林克正等[52]为了取得较好的图像HOG特征提取效果,提出了一种信息熵加权的HOG(Histogram of Oriented Gradients)特征提取方法,该方法先将图像分成若干块,然后分别对各子图像进行HOG特征提取,并且将每块子图像所含的信息熵作为权重系数加到这些HOG特征上,最后利用PCA算法对新的特征进行降维得到信息熵加权的HOG特征。王晓华等[53]先通过Hessian矩阵行列式确定图像中的特征点,然后用梯度方向对快速鲁棒特征算法(SURF)中的主方向提取方法进行改进,以提高特征点方向的准确性,同时用二进制特征描述子对特征点进行描述。在此基础上,再利用汉明距离对获得的特征点进行粗匹配,最后通过网格运动统计剔除误匹配点来获取较为精准的图像特征。
2.2.3文本特征提取
文本特征提取是将原文表达转换到低维度的特征空间的简洁表达。当前常见的文本特征提取方法有深度神经网络DNN(Deep Neural Network)、LDA和PCA(Principal Components Analysis)等。
韩建胜等[54]利用单向多层空洞因果卷积结构分别对文本进行前向和后向特征提取,然后将两个方向的序列特征融合进行情感分类。马慧芳等[55]根据词语的共现构建文本图,该图以词汇为顶点,以词语间的相似度作为边的权重。词语间的相似度别基于语义耦合和基于结构特征进行计算,从而获得两个文本图实例。最终利用随机游走方法融合两个文本图,迭代计算出各节点的重要性以此获取文本的重要特征。陈文实等[56]先通过LDA对文本的全局特征进行建模,然后利用LSTM对文本的局部特征建模,最终结合有监督学习和无监督学习,对文本进行不同层次的特征提取。李平等[57]在基于CHI特征提取方法的基础上,通过融入特征词出现的频率、特征词的影响力和特征词与文本类别的相关性来提高特征词提取的准确性。韩慧等[58]基于深度森林算法BFDF(Boosting Feature of Deep Forest)建立了一个模型,该模型以文本的评价对象-评价词极性特征对的二元特征和情感语义概率特征融合作为文本的特征。并用AdaBoost方法来获得不同特征的重要性,以此计算评论文本的情感倾向。王伟等[59]先利用双向门控循环(BiGRU)神经网络层对文本深层次的信息进行特征提取。然后,利用注意力机制(attention)层对提取的文本深层次信息分配相应的权重。最终对不同权重的文本特征利用softmax函数对文本进行情感极性计算。Lei等[60]在神经网络的输入层设计噪声减弱机制,然后利用基于SVAE(Stacked Variational Autoencoder)模型的隐藏层进行文本的特征提取,在Fudan和Reuters数据集上得到的提取结果的准确性比PCA的更高。
2.2.4跨模态推荐技术小结
跨模态推荐技术能够利用信息的不同模态进行互补来更加完善地描述信息的主体对象,从而提高推荐结果的准确性。而特征提取是跨模态推荐技术的基础。在兴趣点推荐中,图像和文本是两种主要模态。图像特征提取和文本特征提取技术当前主要使用的是神经网络算法,因此面临着无法解释提取结果的问题。同时利用神经网络算法需要大量的数据进行训练,但是当前的文本数据集主要是常见的英文和中文等广泛使用的语言,因此对于小语种的数据需求是一个挑战。而在LBSN上的图像很多都经过用户的修饰,因此对图像特征提取算法的鲁棒性也是图像特征提取所面临的一个挑战。
2.3 基于LBSN的兴趣点推荐框架
兴趣点推荐基于LBSN而生,所以它有着丰富的背景信息用于推荐。这些信息不仅解决了推荐系统面临的数据稀疏性问题和冷启动问题,而且还提高了POI推荐的准确性和使得推荐结果更具个性化。设计用于融合这些信息的兴趣点推荐框架是当前不少研究者热衷的工作之一。
Yin等[61]基于LDA模型提出了一个ST-LDA的推荐框架。框架在数据处理部分为基于时间的主题发现、地理区域建模、基于区域的用户兴趣建模、个人空间模式建模和基于角色的群体偏好建模5部分。它们利用狄利克雷模型分别对与主题相关的词语和时间、兴趣点在区域中的分布、用户在区域内的分布和用户在各区域中访问主题的分布进行统计建模。在兴趣点推荐计算部分,首先利用数据处理得到的统计信息,基于多项分布和用户的历史记录,计算用户访问时选择的区域、主题、兴趣点、地理坐标、主题相关词和访问时间的概率。然后给定用户当前的时间、地点和角色,将之前得到用户在各种信息下的概率分布作为条件概率的条件,计算每个兴趣点的条件概率,然后将top-k个兴趣点推荐给用户。Wang等[62]提出了一个融合序列性信息和个人兴趣的框架SPORE(Sequential Personalized Spatial Item Recommendation Framework)。序列性信息是指时间、地理的邻近程度和人类的偏好与POI类型的内在联系(如为了健康着想,人们通常先运动再吃饭)等信息。在数据处理部分,首先利用文献[63]中的方法对用户的个人兴趣进行量化,同时用文献[64]的SAGE模型量化之前访问过的项目的影响力,以及用背景模型量化大众偏好。然后基于这3个参数,用多项分布计算主题区域指标z,以及z对应的内容词汇和POI的分布。在推荐计算部分,对基于每个用户的历史记录,对没访问过的项目,分别计算z及其对应的描述词语和POI的出现概率,将这3个概率的乘积作为用户没访问过的POI的访问概率。Qiao等[65]提出了一个名为UP2VEC的表示学习框架对地理影响力、社会关系和时间信息进行融合。在数据处理部分,在基于访问关系连接的用户-POI图的基础上,对于有社交关系的用户也相互连接、同一天内访问过的POI间相连接,组成一个成分混杂的LBSN图。然后将地理距离纳入各顶点间的跃迁概率的计算中。最后通过文献[66]中的模型Node2Vec学习用户和POI的表示。在推荐阶段,通过学到的用户表示和POI表示的内积产生推荐列表。Ankita等[67]提出了一个将社交网络内的地理特征、语义信息和时间信息融合用户的社交关系进行推荐,名为LoCaTe的框架。框架在数据处理部分首先用核心密度估计模型基于用户的签到记录计算用户对各POI的偏好PL。然后基于签到记录用隐藏狄利克雷分配模型计算用户对POI主题的偏好PC。最后基于签到记录用指数分布计算时间相关系数T。推荐部分通过PL和PC的权重和乘以T作为用户访问POI的概率。Baral等[68]提出了名为HiRecS的系统框架。系统在数据处理部分,先用主题、距上个签到点的距离和签到频率构建每个POI的特征档案,并且基于Haversine公式进行地理位置的聚类。然后利用用户的签到频数计算用户对不同特征的偏好,以建立个人档案。接着根据用户的签到偏好,在每个地理区域对用户进行聚类。系统在推荐部分,给定目标用户和特定区域,在该区域找到与用户相似的群体,以群体偏好表示用户偏好,基于CMI(Conditional Mutual Information)标准和各群体的偏好特征对POI进行分层。最后用PMD(Partition Membership Divergence)将各群体的POI分层树融合成一棵树。利用用户的偏好特征,在每一层找到最匹配用户偏好特征的节点直到达叶子节点并将该POI推荐给对应用户。
基于LBSN的兴趣点推荐的技术框架的总体抽象如图1所示。
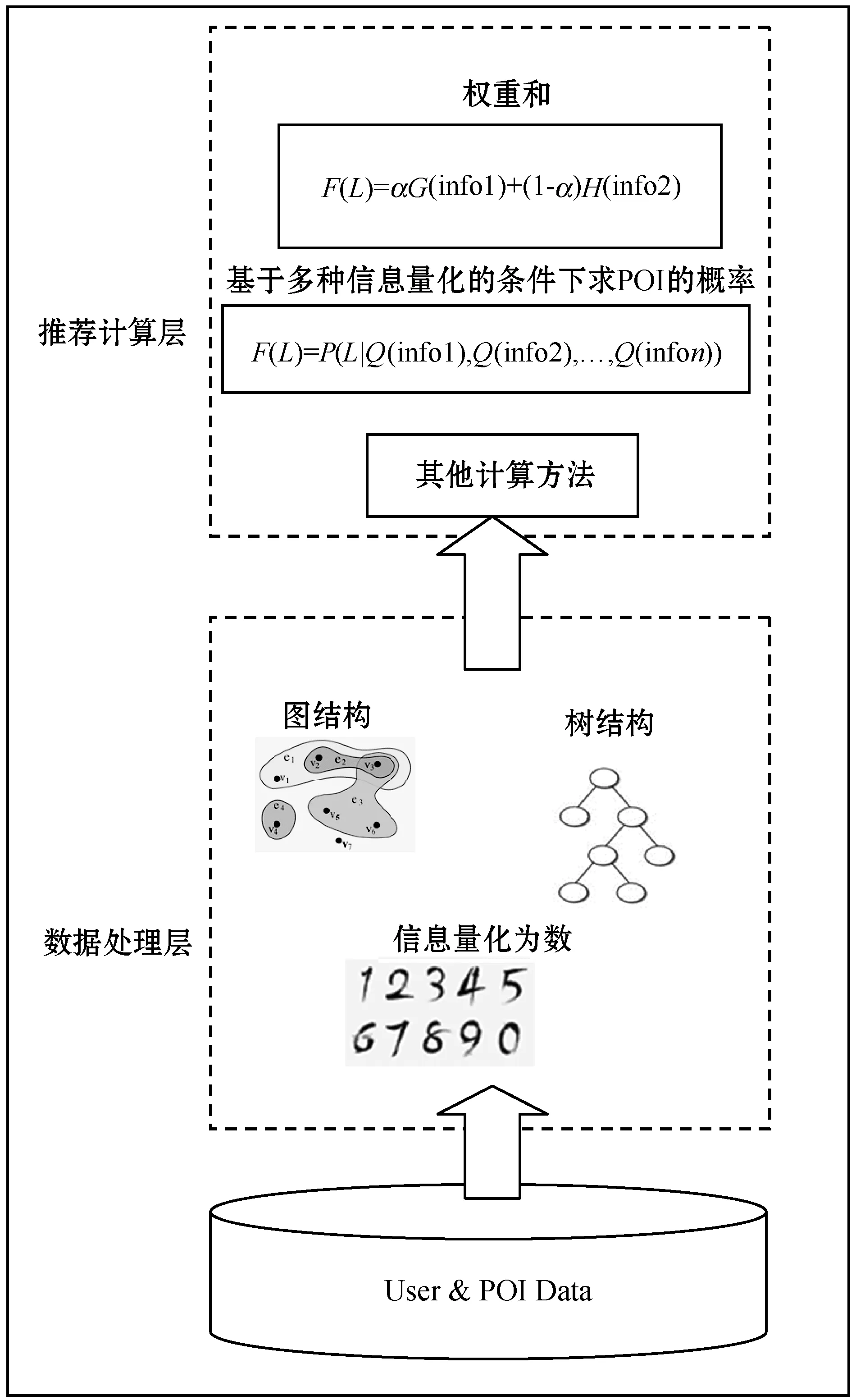
图1 基于LBSN的兴趣点推荐框架
框架主要分为用户和POI信息处理的数据处理层和推荐计算层两层。在数据处理层,当前使用比较普遍的信息有POI的地理位置、POI的主题、用户的偏好、用户的历史记录和用户的社交关系。常用的处理方法是将各种信息量化或者基于这些信息构造新的图或树。量化的常见方法是利用狄利克雷分布和多项分布进行建模,得出各种信息条件下访问POI的概率。在推荐计算层,常见的推荐计算是对POI进行评分或利用条件概率求在多种信息的条件下POI被访问的概率。而评分的计算方法常见的是基于权重和的计算公式。所以,在基于LBSN的兴趣点推荐框架中,数据处理层是推荐计算层的基础。契合的数据表示将会带来高效的推荐过程和优秀的推荐结果。
3 兴趣点推荐常用数据集
兴趣点推荐作为一个特殊的推荐领域,其要求的数据集中较其他数据集多了时间和地理位置数据,而且算法对数据集的地理、时间和社交关系等影响一个人出行的数据尤为敏感。当前常见可用于兴趣点推荐的数据集有Foursquare数据集、Yelp数据集、Gowalla数据集、GPS数据集、MIT数据集和DoubanEvent数据集等[69]。下面介绍几种常用的数据集。
1) Foursquare数据集。Foursquare数据集来源于一个基于位置的社交网站Foursquare。Foursquare本身没有提供API来访问用户的签到数据,但其与Twitter的关联导致可以从Twitter中寻找用户利用Foursquare的签到。Bao等[70]将收集到Foursquare数据划分为用户基本信息、兴趣点基本信息、用户历史记录和用户社交关系4类。其中,用户基本信息包括了用户的ID、姓名和住址等。兴趣点的基本信息包括了地点的ID、名称、地址、坐标和分类标签等。用户的历史记录包含了用户的评论标签,每个评论标签与兴趣点的ID、详细评论和时间戳相关联。用户的社交信息由用户的ID组成。
Foursquare数据集的不足之处在于其本身非公开的性质,其出现来源于研究人员的自行收集,这造成了无法收集到没有捆绑Twitter的用户数据,而且收集到数据会有一定的片面性。
2) Gowalla数据集。Gowalla数据集来源于基于位置的社交签到应用Gowalla。相应的签到数据由Stanford的Jure Leskovec收集,从2009年2月至2010年10月,该数据集包含了6 442 890条签到信息。数据中每条记录由用户的ID、签到时间、兴趣点的坐标和兴趣点的ID组成。
Gowalla数据集虽然来源于社交应用Gowalla,但是由于其并非由Gowalla直接公开,所以该数据集没有明确的社交关系。同时,该数据集已不再更新,而用户对兴趣点的选择是具有时效性的,所以,从该数据集学得的模型可能会与用户的实际选择偏差较大。
3) Yelp数据集。Yelp数据集来源于美国最大点评网站Yelp,它由Yelp自行公开。数据集由JSON格式记录。该数据集截至2020年3月26日包含了4个国家共11个大城市的兴趣点信息,含520 000 000条用户点评,174 000条兴趣点信息。数据集由兴趣点信息、签到信息、评论信息、用户评论标签、用户信息和图片信息组成。兴趣点信息由兴趣点ID、名称、地址、坐标、评分、分类、营业时间和其他属性信息组成。签到信息由兴趣点ID和该兴趣点被签到的时间戳集合组成。评论信息由评论ID、评论用户的ID、兴趣点ID、评论内容和评论时间等组成。评论标签信息由标签文本、兴趣点ID和用户ID等组成。用户信息由用户ID、姓名、评论数、社交关系等组成。图片信息由图片ID、对应兴趣点的ID、描述文本和图片分类标签组成。
Yelp数据集的完善数据记录可以使它完全满足于现有的兴趣点推荐算法,其信息之详细可以有效地提高兴趣点推荐结果的个性化、准确性和多样性。但是其仅面对着11个大城市,这就造成了这些城市以外的兴趣点均无法被推荐。而且,从该数据集中学得的用户行为,也仅适合于这11个地区,对于这些地区以外的应用,与用户的实际偏差会较这11个地区的大。
4) DoubanEvent数据集。DoubanEvent数据集来源于中国的一个基于项目的社交网站DoubanEvent。用户在该网站指定何时何地举行某一个活动,然后其他用户通过在线签到表达对该活动的偏好。它主要囊括了北京、上海、广州和深圳4个城市的签到记录。其主要由用户信息、活动信息、用户反馈信息和用户社交关系信息组成。用户信息包括了用户ID、名称和用户所在城市。活动信息包括了活动ID、名称、发生地的坐标、活动总结和活动分类。用户反馈信息包含了用户ID和活动ID。用户社交关系的每条记录由用户ID及其相互关注的其他用户ID组成。
DoubanEvent数据集是中国较大的一个公开数据集,它可以较好地适应中国国内的兴趣点推荐服务。但是其主要集中于北京、上海、广州和深圳这4大城市造成了它的局限性。同时,由于其来源豆瓣相对微博、微信等社交平台来说,并非一个广泛流行的社交应用,所以依据该数据集学得的模型会存在一定的片面性。
4 兴趣点推荐的效用评价
对于推荐系统的效用评价,可以分为评价方法和评价指标两方面。评价方法有在线评价、离线评价和混合评价3类。
4.1 评价方法
4.1.1在线评价
在线评价指的是通过直接询问用户得到用户对推荐系统的反馈,从而改善推荐方法的一种方式。其常见做法是进行问卷调查。
在线评价的优点在于其对用户需求的实时响应,频繁的用户交互可以最大限度地满足用户的需求。但该方法需要较大的成本投入。Bao等[70]在其设计的移动推荐系统中使用了在线评测,实验结果表明该方法可以带来极高的用户满意度。
4.1.2离线评价
离线评价是指利用测试数据集,计算评价指标来衡量推荐系统的质量。常见的计算方法是k-折交叉验证法。而常见的衡量指标有召回率、精确度、平均平方误差等。
离线评价的优点在于其可以独立在线下完成,所需的资源投入较少。但是其缺乏了与用户的直接互动,无法准确地判断是否满足用户的需求。
4.1.3混合评价
鉴于在线评价和离线评价的特点,有研究者提出将两种评价联合使用,这就是所谓的混合评价。混合评价能同时兼具在线评价和离线评价的优点。在文献[71]中便使用了在线评价和离线评价作为推荐系统的效果评价方法,在得到较好的用户满意度的同时又不至于投入太大的成本。
4.2 评价指标
除了评价方法,评价时还需要评价指标,常见的评价指标有召回率Recall、准确率Precision和平均平方误差MSE等。以TP表示正类数,FP表示负类被预测为正类的数目,FN表示正类被预测为负类的数目,则几个常见的评价指标计算如下。
召回率的计算公式如下:
(10)
准确率Precision的计算公式如下:
(11)
平均平方误差MSE的计算公式如下:
(12)
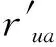
4.3 效用评价小结
推荐效果一般有着一系列的评价指标,但同一个算法在同一个数据集在不同的指标上所得出的结果往往是不同的。所以推荐效果,其实是算法、数据集和评分模型三者共同作用的结果。文献[69]给出常见数据集的基准模型和基准评价指标,如表1所示。

表1 常见数据集的基准推荐模型和评价指标
5 兴趣点推荐未来的发展
尽管现今对兴趣点推荐的数据稀疏性问题和特征提取问题取得了一些成果,但是对兴趣点推荐的研究还需不断完善,今后的进一步研究工作可从如下方面展开。
5.1 隐私保护
兴趣点推荐是对地理位置的推荐,推荐过程中会涉及用户的活动踪迹、用户的行为偏好等信息。而为了实时推荐,甚至会实时地获取用户的定位信息。而所有的这些信息都属于用户的个人隐私,尤其是这些隐私的泄露容易导致用户遭受攻击,从而出现意外。所以如何有效地保护用户数据的隐私是兴趣点推荐的必须要解决的问题。
5.2 机器学习
当前兴趣点推荐中,图像特征提取、文本特征提取和文本情感分析成为了一个重要的环节。而当前这些提取技术更多的是依靠神经网络和机器学习。神经网络是机器学习的进一步优化。可以说,机器学习的发展严重影响了推荐效果的准确性。同时当前文本的处理只是停留在词汇的处理上,对于文本语义的理解还有待发展。
另外,对于兴趣点的推荐模型,其本质同样是从已有的数据中学习用户的行为,应用的是机器学习的方法。一个好的推荐模型可以带来优秀的推荐效果。因此,机器学习是兴趣点推荐的一个重要研究方向。
5.3 数据集标准化
虽然当前有不少的公开数据集可供使用,但是,数据集中的数据大多数呈地域性集中,即现有的数据主要是某几部分地区的用户活动信息。而且数据集之间存在着互补关系,但不同数据集记录的格式,字段均不一样,这不仅为联合使用带来了不便,同时对推荐系统的建模与程序编写也带来不便,因此,标准化的数据集格式是必需的。
6 结 语
随着LBSN的普及与发展,兴趣点推荐无论为商户还是用户都带来了利益。面对兴趣点推荐系统,过去对于其他项目的推荐系统的解决方案已不再适用。本文总结归纳了面对数据稀疏性问题时,兴趣点推荐领域独有的解决方法、兴趣点推荐面对特征提取问题时的解决方案、适用于兴趣点推荐的数据集以及如何对兴趣点推荐的推荐效用进行评价。通过整理分析得到的几点结论如下。
(1) 兴趣点推荐已有自己一套面对数据稀疏性问题的解决方案,但是还有待改进。当前较为常见的方法是通过多源信息的融合来缓解数据稀疏问题。通过融合其他诸如地理位置、社交关系等与用户选取兴趣点及其相关的因素进行矩阵分解,或者将这些因素进行量化来对用户的行为进行建模预测都可以有效缓解兴趣点推荐上的稀疏性问题。但是这无法更改矩阵分解的聚类本质,所以,在采用矩阵分解算法的同时,应该采用其他方法来弥补推荐结果多样性的缺失。对于建模预测用户行为的方法尽管与实际结果会存在偏差,但是可以较好地缓解数据稀疏性问题。但是,该方法在兴趣点推荐中往往较其他推荐融合的信息多。对于多源信息在兴趣点推荐中的量化与融合模型是该方法所面对的一个难点。
(2) 多模态数据是兴趣点推荐的一个特色背景。跨模态融合推荐可以提高推荐结果的准确性。而特征提取是跨模态推荐的基础技术。所以,其准确性会直接影响到最终推荐结果的准确性。当前该技术所用的方法主要是基于神经网络的机器学习方法。而神经网络的方法会面临结果的可解释性问题。同时,机器学习方法除了解决特征提取问题外,机器学习中的模型也是推荐模型建模的主流方法,因此,机器学习的研究是兴趣点推荐的一个重要研究方向。
(3) 已经有着不少可用于兴趣点推荐的数据集,这些数据集大多都记录着用户的签到行为、对兴趣点的评论、用户的社交关系以及兴趣点的信息等。它们可以在一定程度上满足科研的要求。当前兴趣点推荐所面临的数据集问题主要集中有2点。其一是用户的隐私问题。用户的隐私涉及到用户的安全问题,因而,很多应用都选择不公开其应用所收集的用户数据。这造成了用于兴趣点推荐的数据集缺乏广泛性。其二是当前数据集面对着来源单一、格式不统一、地域性集中等问题。该问题造成了研究人员跨数据集使用数据的困难。
一个标准的数据加密处理方法和标准的数据记录格式可以很好地解决其中大部分的问题。标准的加密处理可以在一定程度上协助研究人员找出不同应用中的同一个用户,既减少了数据的重复,同时又可以扩展用户的历史记录,减缓数据稀疏问题。而标准的数据字段可以让研究人员同时使用多个数据集,降低了建模与编程的难度,增加推荐结果的准确性。
因此,针对兴趣点推荐的数据标准化处理不仅是科研所需,同时也是商业的要求。
(4) 任何一个推荐系统的评价,它都是由其算法、评价方案和使用的数据集所决定。尽管孟祥武等[69]给出了一套基于各数据集的标准模型和评价指标,但是,这些基准所基于的数据集和推荐模型都是有着一定缺陷的。所以,纵使在某个基准数据集上,依据评价指标优于某基准推荐模型,但实际的应用效果也不一定能够由于基准推荐模型。为此,推荐系统的评价这方面,一套标准的评价体系还有待制定。
综上所述,对于兴趣点推荐的研究还有待深入。本文介绍了一个相对完整的兴趣点推荐技术的知识框架。希望本综述对于兴趣点推荐的研究脉络的理清和兴趣点推荐技术后续的研究能够提供参考和帮助。
