面向低精度神经网络的数据流体系结构优化
2023-01-30范志华吴欣欣李文明曹华伟安学军叶笑春范东睿
范志华 吴欣欣 李文明 曹华伟 安学军 叶笑春 范东睿
1 (处理器芯片全国重点实验室(中国科学院计算技术研究所) 北京 100190)
2 (中国科学院大学计算机科学与技术学院 北京 100049) (fanzhihua@ict.ac.cn)
深度神经网络(deep neural network,DNN)模型规模变得越来越大,例如AlexNet[1]和VGG16[2]网络中分别包含6 000万和1.38亿个参数,大规模的数据以及复杂的计算过程对硬件计算、存储资源的需求也随之加大,神经网络压缩技术能有效缓解对计算和存储的压力.量化是一种广泛使用的压缩技术,利用神经网络中数据的冗余性,将高精度浮点数据映射到使用更少位的低精度整型数据(INT8,INT4或者更低),以此降低神经网络推理的硬件开销.
为充分体现低精度神经网络的性能和能效优势,许多面向低精度神经网络的加速器被提出.DRQ架构[3]提出了一种基于区域的动态量化方法,该方法可以根据激活值中的敏感区域动态改变DNN模型的精度,并针对所提出的敏感区域算法设计了一种混合精度卷积阵列加速器.AQSS[4]基于随机计算方法实现了固定精度的7 b加速器结构,该加速器通过移位器代替乘加器,提高了加速器的性能.算法与硬件架构的配合使得此类加速器在模型准确率与性能等方面可以取得良好表现,但是此类架构与软件方法之间紧耦合且仅支持单一精度,使得很难适用于其他的量化算法和神经网络模型.
由于量化算法和神经网络模型的不同,一些架构通过支持多种精度运算来增加灵活性.OLAccel[5]基于4 b的乘加单元对权重和激活值进行低精度计算,同时考虑了少量高精度的离群值的存在,增加了一个额外的高精度乘加单元,用于离群值的计算.BitFusion[6]设计了精度可变的乘加单元,能够支持精度为2的任意指数的乘加运算.由于可以支持多精度数据的运算,相比于前一类加速器,此类加速器能支持更多的量化方法和低精度网络.但是,此类加速器采用细粒度的配置方式,给编译造成比较大的困难,并且对于计算部件的重构会带来额外的开销.另外,此类架构的时钟频率都受限于计算部件的设计.
数据流架构的执行方式与神经网络算法具有高度匹配性,并且在灵活性、性能之间具有良好权衡.Eyeriss[7]是一款典型的数据流神经网络加速器,通过减少数据移动、实现本地数据复用等方式最小化模型中数据移动距离,从而降低神经网络加速器的能耗.DPU[8]面向神经网络的稀疏性对数据流架构进行了优化,通过去掉与0相关的无效操作提升了数据流芯片的性能与能效.然而,现有数据流加速器没有面向低精度神经网络展开研究,而且都关注计算部件的设计,忽略了数据在片上存储和片外存储之间的传输问题.此外,传统数据流架构通过双缓冲机制掩盖数据传输的延迟,但是当部署低精度(INT8,INT4)神经网络时,传输带宽的利用率显著降低.这导致计算执行时间无法掩盖数据传输延迟,使得计算阵列完成此次计算之后不能马上开始下一次计算,需要等待数据传输完成,从而降低了数据流架构的性能和能效.
基于以上问题,本文面向低精度神经网络,对数据流架构进行了优化,设计了软硬件协同的低精度神经网络加速器DPU_Q.本文的贡献有4个方面:
1)为充分挖掘低精度卷积计算过程中的数据并行性,本文设计了灵活可重构的计算单元,根据指令的精度标志位动态重构数据通路,能高效灵活得支持多种低精度数据运算,并实现计算部件的高利用率和高峰值性能;
2)为支持低精度神经网络中复杂的访存模式,本文设计了Scatter引擎,能对低精度数据进行拼接、预处理,以满足高层次/片上存储对数据排列的格式要求,能有效应对复杂的访存模式并解决低精度数据传输带宽利用率低的问题;
3)为充分发挥数据流架构的性能优势,本文提出了一种数据流图映射算法,兼顾负载均衡的同时减少了访存和数据流图节点之间的数据传输带来的开销;
4)通过实验评估,相比于同精度的 Titan Xp GPU,DPU_Q可以获得最高3.18倍的性能提升和4.49倍的能效提升.相比于同精度的Eyeriss加速器,DPU_Q可以最大获得6.05倍性能提升和1.6倍能效提升,相比于BitFusion加速器,可以最大获得1.52倍性能提升和1.13倍能效提升.
1 相关研究
量化是一种神经网络压缩技术,通过将神经网络模型中的数据映射到使用更少位的数据域,减小神经网络存储规模、简化计算过程从而加快神经网络训练和推理的速度.量化的对象常为神经网络中的权值[9]、激活值[10]和反向传播中的梯度[11].常见的低精度有 16 b,8 b,4 b.这些低精度神经网络经过量化、重训练过程之后,能够保证模型准确率损失在可接受的范围内,因此,面向低精度神经网络的量化算法和体系结构研究成为计算机领域的研究热点.表1展示了具有代表性的低精度神经网络加速器.
为充分体现低精度神网络的性能和能效优势,许多面向低精度神经网络的加速器被提出[3-7].DRQ[3]架构根据激活值矩阵中敏感区域的特征,动态改变神经网络网络的精度,并且从硬件架构层面动态适配模型精度,设计了支持多种混合精度的卷积计算阵列.AQSS[7]架构则是基于随机计算的计算模式,设计了7 b精度的加速器微架构,并且使用移位器实现乘加计算,显著提升了计算性能和效率.然而,基于随机计算的架构需要额外的资源开销,例如随机数据生成、预处理等.以上述DRQ和AQSS为代表的、与软件算法紧耦合的架构的缺点是灵活性较差,很难适用于其他的量化算法、不同的神经网络模型以及模型精度.
由于量化算法和神经网络模型的不同,单一精度使加速器的灵活性受限,因此,一些架构通过支持多种精度运算来增加灵活性.OLAccel[5]基于4 b的乘加单元对权重和激活值进行低精度计算,同时考虑了少量高精度的离群值的情况.增加了一个高精度乘加单元,用于计算离群值,避免高精度与低精度计算单元的更新带来的一致性问题.BitFusion[6]引入了动态比特级融合/分解思想,是一种可变精度的比特级加速器,它由一组可组合的比特级乘加单元组成,动态融合以匹配单个DNN层的精度.该加速器的缺点在于细粒度的可重构运算部件使编程和算法移植变得困难,而且此类架构的时钟频率都受限于计算部件的设计.通过此类加速器的设计思想我们得到启发,低精度神经网络加速器的设计是需要同时支持低精度运算与部分高精度运算,一方面能在性能与模型准确率的权衡中获得最大收益,另一方面还可以支持更多的量化方法和网络模型,增加架构的灵活性.
数据流架构的执行方式与神经网络算法具有高度匹配性,并且在灵活性、粗粒度可重构性、性能之间具有良好权衡.Eyeriss[7]在整个模型中使用16 b的量化数据进行推理,并且通过减少某些数据移动、实现本地数据复用等方式最小化神经网络模型中数据移动距离,从而降低神经网络加速器的能耗,但Eyeriss由于精度较大,使其加速效果并不显著.DPU[8]面向稀疏神经网络对数据流处理器进行了优化.然而,现有数据流加速器没有面向低精度神经网络展开研究,更重要的,现有数据流架构侧重关注数据流计算单元和数据流图映射方面的研究,并未关注数据在片上存储和片外存储之间的传输.
2 背 景
2.1 深度神经网络
DNN主要由多个卷积层组成,它们占据整个网络处理约85%的计算时间[12],这些卷积层执行高维的卷积计算.卷积层在输入特征图 (input feature map,Ifmap)上应用卷积核(kernel)以生成输出特征图(output feature map,Ofmap).卷积层的输入数据由 1 组2维输入特征图组成,每个特征图称为1个通道,多个通道的输入组成1个输入图像,每个通道的特征值都与1个不同的2维滤波器(filter)进行卷积运算,通道上的每个点的卷积结果相加得到1个通道的输出特征图.卷积层的计算为
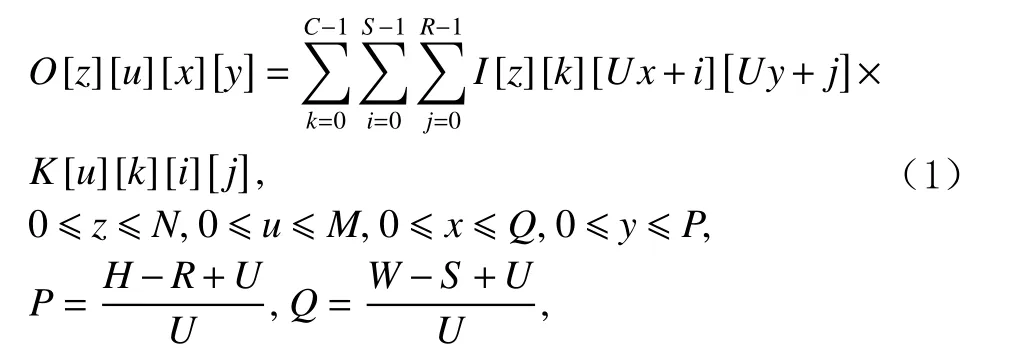
2.2 低精度神经网络
低精度神经网络是经过量化操作之后得到的神经网络模型,量化能够减少神经网络模型中数据的精度,缩小神经网络的规模,简化计算来加速神经网络的训练或推理过程.
量化的过程可以描述为将网络中的参数分成不同的簇,同一簇中的参数共享相同的量化值,量化之后对参数进行编码,将量化后的参数转换为二进制编码来存储.常见的量化算法有线性映射、k-means聚类;常见的编码方式有固定长度的二进制编码和变长的霍夫曼编码.
表2展示了具有代表性的低精度神经网络及其数据精度.Q_CNN[13]是将卷积神经网络中的权值量化,对于图像识别应用能显著提升神经网络的性能并减少存储开销.EIA[14]将权值和激活值都量化成8 b定点数据,DFP[15]和LSQ[16]将网络中的权重和激活值等数据量化成多个不同的数据精度,而QIL[17]将权值和激活值量化成4 b数据.

Table 2 Representative Low-Precision Neural Networks表2 代表性低精度神经网络
参考文献[18]中的方法,分别对AlexNet和 VGG16网络进行量化、微调,不同数据位宽与网络模型精度损失的关系如图1所示.对于VGG16网络,数据位宽少于8 b时,模型的准确率就会出现明显下降.而对于AlexNet网络,数据位宽至少为4 b时,可以保证模型的准确率.
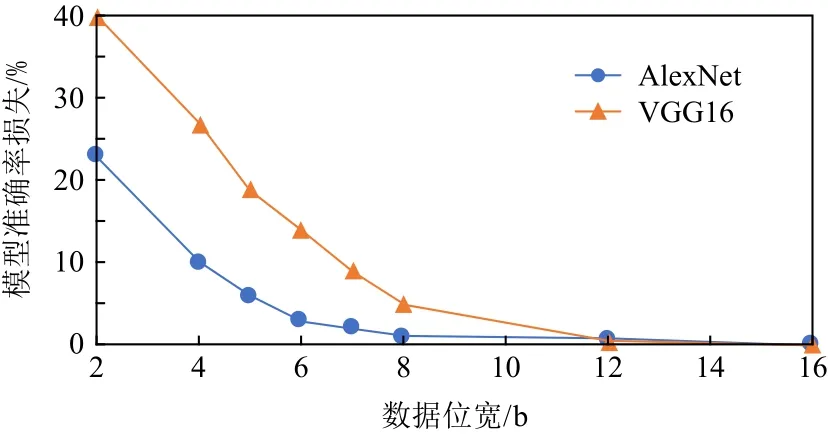
Fig.1 Relationship between the accuracy loss of the neural network model and the quantization of bit-width图1 神经网络模型准确率损失与数据位宽的关系
2.3 数据流架构
DPU[8]是一款典型的粗粒度数据流架构,采用数据流程序执行模型.计算机程序通过数据流图表示,数据流图由节点和连接节点的有向边构成.节点表示计算过程,节点之间的有向边表示数据依赖关系.计算节点是一个指令集合,各节点之间的调度与执行采用非抢占机制.借助于这种特殊的计算方式,DPU在功能灵活性方面与控制流驱动处理器相似,在能效上接近专用处理器芯片.
图2展示了DPU的整体架构,该架构由2维PE(process element)阵 列 、 微 控 制 器 和 DMA(direct memory access)组成.DPU作为协处理器,通过接口与主机端进行交互.由于DMA传输不占用计算资源且控制简单,所以,DPU使用DMA作为片上与片外存储之间数据传输的部件.
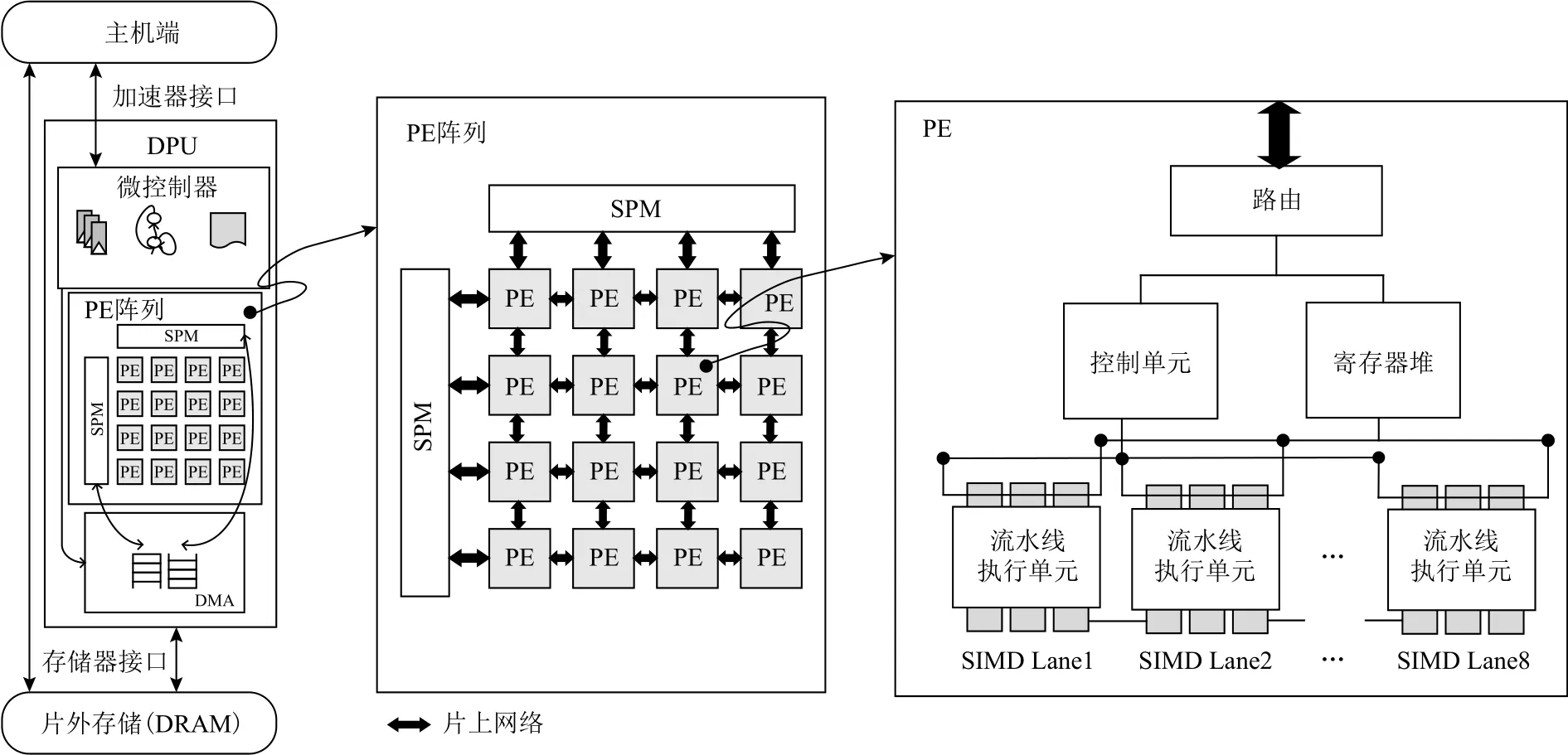
Fig.2 Overall architecture of DPU图2 DPU 架构
PE阵列由多个同构PE、片上网络和片上存储SPM(scratchpad memory)组成.片上存储 SPM 负责存储指令和数据,并由2块相同大小的SPM块组成,目的是通过双缓冲机制掩盖数据传输的延迟.片上网络将PE阵列组织为2维mesh拓扑结构,并负责在PE之间传输配置信息和数据.
在每个PE内部,由路由、控制单元、寄存器堆、流水线执行单元组成.为充分利用数据并行性,流水线执行单元使用单指令多数据(single instruction multiple data,SIMD)技术,进入流水线执行单元的矢量寄存器中都包含多个数据.为了提高PE计算部件的利用率,DPU采用解耦合的流水线设计,将访存、计算部件解耦合,访存部件采用传统5级流水,计算部件采用4级流水,减少了访存阶段.
微控制器负责控制PE阵列的执行,还负责与主机端进行通信.主机端向微控制器发送启动信号以及数据流图映射等配置信息,微控制器启动并配置DMA,DMA将片外存储中的数据加载至PE阵列的SPM中.微控制器配置并启动PE阵列,每个PE获得映射的数据流节点,根据节点中的指令,从SPM中加载数据,进入流水线单元执行.当PE阵列执行结束后,微控制器向主机端发送结束信息.DMA负责片上SPM中的结果传回片外存储.在此过程中,片上网络负责PE之间传递配置信息与数据.
3 研究动机
3.1 计算单元精度不匹配
在传统数据流架构中,计算单元的数据通路宽度为32 b,与低精度神经网络中的数据宽度不匹配,不能充分利用低精度数据的性能、能耗优势.图3展示了数据流架构DPU中卷积运算的数据通路,数据通路中的数据位宽、计算部件、单个寄存器规模都是32 b,当计算低精度数据时,比如 8 b数据,虽然能够完成计算,但在数据通路中传输、计算的数据的高24位全为0,造成计算资源的浪费.
3.2 访存模式复杂
SIMD是一种利用数据并行性提升性能的技术.SIMD指令中的操作数都是一个向量,指令可以对向量中的每个操作数执行相同的操作和控制.SIMD的维度以8为例,即每条计算和访存指令同时对8个数据进行计算和读取/写回,每条Load指令就可以将8个分量从片上存储SPM加载到PE中的矢量寄存器中.在神经网络推理过程中,8个SIMD可以并行计算不同图像或者不同通道中相同位置的数据,但是这些数据需要在SPM中顺序排列.然而,在片外存储中,图像数据按照图像顺序依次排列存储在每张图像内部,不同通道的数据依次排列存储.所以在SPM中顺序排列的SIMD数据在片外存储中是地址离散、分散排列的,并非按照其在SPM中的顺序排列.面对片外存储中非连续数据的访问,DPU对DMA进行了优化,不同通道之间或者不同图像之间(SIMD之间的数据偏移)的地址偏移可以通过输入图像规模得到,所以根据访存首地址以及该偏移值,即可得到8个SIMD数据在片外存储的地址,DMA并行需要从片外存储中读取8个数据并依次写回SPM即可.
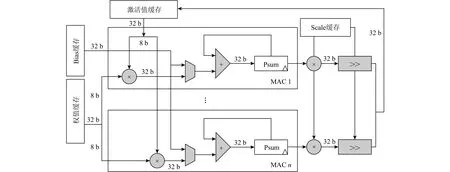
Fig.3 The data path of convolution图3 卷积运算的数据通路
在低精度神经网络推理过程中,存储的访问模式变得更加复杂.图4以8 b精度为例,展示了数据在片上和片外存储中的排列格式.为了充分利用存储资源和数据并行性,SPM中每个存储单元存储同一图像中4个不同通道相同位置的数据,每个SIMD分量对4个通道数据进行卷积计算,而SIMD维度可以并行处理8个图像的数据,这样能充分挖掘数据的并行性,从而提升芯片的性能.但是,在每个图像中,相同位置不同通道的数据在片外存储中也并非连续存储,意味着在SPM中每个地址的32 b数据在片外存储中是分散排列的,因此,不同通道和不同图像之间数据在片外存储的偏移计算变得复杂.同时,使用优化后的DMA进行数据传输,每次只能并行读取8个SIMD的数据,即8个图像中单个通道的数据,所以对于8 b精度,DMA需要启动4次,才能完成1次计算所需的4个通道数据的传输.
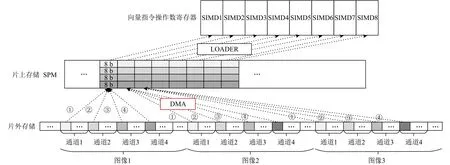
Fig.4 Memory access patterns in low precision data图4 低精度数据的存储访问模式
3.3 传输带宽利用率降低
在数据流架构DPU中,DMA负责片上SPM与片外存储之间的数据搬运.与传统数据流架构一致,DPU的片上存储采用双缓冲机制,目的是用计算时间掩盖DMA的配置和数据传输时间.图5(a)展示了AlexNet网络5个卷积层进行1次DMA传输与1次计算的时间对比,对于32 b高精度数据,每一次启动DPU的执行时间远大于传输时间,传输时间完全可以通过双缓冲机制掩盖.然而,在数据流架构部署低精度神经网络时,基于3.2节的分析,需要多次启动DMA传输,导致数据传输时间变长,计算时间无法掩盖传输延迟,使得双缓冲机制失效.图5展示了AlexNet网络进行INT4和INT8的传输时间和执行时间.当精度为INT8时,conv3到conv5的数据传输时间超过了该层的执行时间,传输的平均带宽利用率仅为20.05%;当精度为INT4时,AlexNet每一层都无法通过双缓冲机制掩盖传输延迟,传输带宽的利用进一步降低.如图5(b)所示的是双缓存机制失效,可以看出,当第i−1层卷积运算结束后,第i层卷积的数据还未完成从片外存储到片上SPM的传输,导致第i层的计算无法在上一层结束之后立马开始,PE阵列需要长时间处于等待数据传输状态,双缓冲机制因此失去效果,使得计算单元的利用率下降,这会降低芯片的性能.
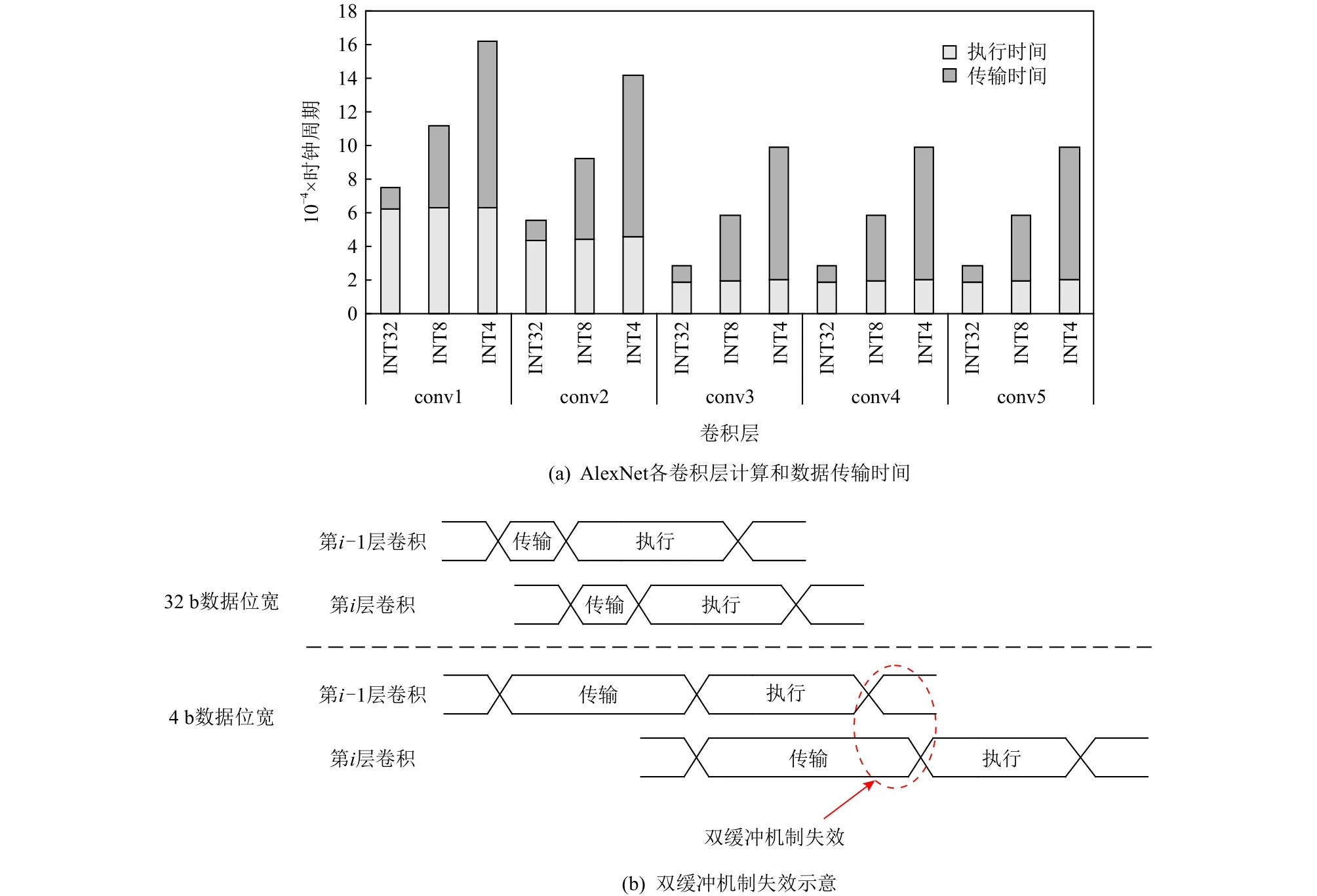
Fig.5 Calculation and transmission overhead of different precisions in AlexNet图5 AlexNet网络不同精度的计算和传输开销
4 DPU_Q架构
基于对低精度神经网络和数据流架构的分析,本文设计了面向低精度神经网络的数据流架构DPU_Q,总体架构如图6所示.DPU_Q核心部件包含微控制器、Scatter引擎、双缓冲SPM、PE计算阵列和片外存储.Scatter引擎负责片上SPM和片外存储之间的低精度数据访问和传输;PE阵列负责计算,其具有灵活可重构的低精度卷积计算部件RPU(reconfigurableprocess unit);双缓冲 SPM既负责数据存储,又掩盖数据传输的延迟;微控制器负责控制各部分的功能.
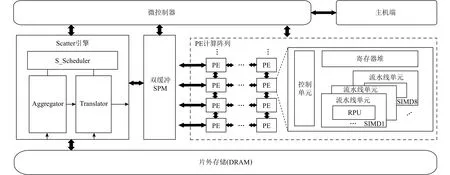
Fig.6 The overall architecture of DPU_Q图6 DPU_Q总体架构
与众多神经网络硬件加速器一样,DPU_Q是由PE 阵列组成的空间架构(spatial architecture).PE 之间通过片上网络进行互联,每个PE内包含本地存储和共享的片上存储,PE其内包含简单的计算单元.由于神经网络中的计算是相对简单且规则的操作,如张量的乘加运算,所以可以利用PE阵列的结构计算得到有效的处理.利用PE的本地和片上共享存储可以实现数据的时间复用,并且数据流程序执行模型提高了程序指令级并行性的同时,数据流图节点之间的数据传输实现数据的空间复用,从而减少存储访问.
DPU_Q架构的设计特点主要体现在3个方面:
1)在计算部件设计方面.以提升吞吐量和性能为目标,设计了灵活可重构的计算单元RPU,根据指令的精度标志位动态重构数据通路,能高效灵活地支持多种低精度数据运算,并且RPU内MAC簇可以进行通道维度并行,结合SIMD维度进行图像(batch)维度并行,以此充分挖掘低精度神经网络中的数据并行性.
2)在访存部件设计方面.以提升低精度数据传输带宽利用率为目标,设计了Scatter引擎,通过在数据传输过程中对数据进行重组、预处理,解决低精度数据访存模式复杂的问题.
3)在调度方面.以提高计算部件的利用率为目标,设计了兼顾负载均衡和数据重用的dR(data reuse)数据流图映射算法.
4.1 低精度卷积计算单元
图7展示了DPU_Q中低精度卷积计算单元的数据通路,该数据通路能够根据指令中的精度标志位动态选择可重构计算单元中的计算部件.该数据通路由4个流水线阶段组成.
第 1 阶段为取指(instruction fetch,IF).此阶段根据指令寄存器(program counter,PC)的值,从指令存储中获得指令.
第 2 阶段为译码(instruction decode,ID).指令译码器对指令进行译码,将指令码(opcode)、源/目的寄存器地址、精度标识位(precision flag)和加法树使能信号(adder tree enable)等信息分别发送到相应的状态寄存器和寄存器文件中.
第 3阶段为指令执行(execution, EX).RPU 根据精度标识位动态选择执行部件(MAC簇).然后,根据ID阶段解析的源寄存器地址获取源操作数,进行计算.加法树从流水线寄存器(EX stage)中获取使能信号,根据精度标识位将RPU计算的结果进行求和.另外,该阶段还包含了可选的量化部件,目的是为上层软件算法提供支持.
第 4 阶段为写回(write back, WB).在该阶段,计算结果被写回目的寄存器或者数据存储中.
在DPU_Q的实现中,精度标志位设计为2 b宽度,用于表示 INT4,INT8,INT16,INT32 这 4 种精度.对应地,RPU中包含了8个INT4的MAC簇、4个INT8的MAC簇、2个INT16的MAC簇以及1个INT32的MAC.RPU根据精度标志位选取MAC簇,并建立MAC簇与寄存器堆、加法树之间的线路链接.RPU和寄存器堆、加法树之间的线路连接宽度都为32 b,在RPU内部,不同精度的MAC簇的计算总的数据宽度也为32 b,目的是可以充分利用部件之间线路链接和寄存器文件.另一方面,结合卷积的算法特点,同一MAC簇的MAC可以并行计算同一图像不同通道的数据,充分利用低精度神经网络通道间的并行性.在DPU_Q中,向量SIMD不同维度用于不同图像之间的并行,单个SIMD内对相同图像的不同通道数据进行并行,以此进一步提高计算并行性和吞吐量.
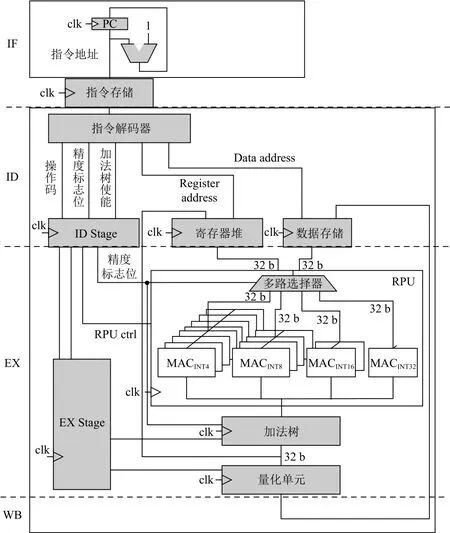
Fig.7 The data path of low-precision convolution in DPU_Q图7 DPU_Q中低精度卷积的数据通路
4.2 Scatter引擎
Scatter引擎主要包括调度单元、Aggregator和Translator这3部分,如图8所示.调度单元由地址计算单元和控制模块组成.调度单元一方面负责计算多个图像和通道数据在片外存储中的地址;另一方面负责控制Aggregator和Translator的执行.Aggregator完成低精度数据的拼接,由多个插槽和用于同步的计数器组成.Translator负责SIMD数据格式转换,由8个SIMD数据队列、分发单元和同步单元组成.
调度单元根据图像特征(map_feature)、访存地址(mem_addr)和精度(precision)可以得到参与计算的每张图像和每个通道的首地址.图像特征是个3元组(x_slice,y_slice,z_slice),分别表示图像的宽、高和通道规模.根据图像特征三元组和精度可得到每个图像在片外存储中的偏移,根据x_slice、y_slice和精度便可得到图像内每个通道的偏移,地址计算单元根据上述输入信息得到访存地址表,表中记录需要访问的片外存储地址.控制模块根据精度信息,首先生成Aggregator和Translator的控制信息.如果精度为32 b数据,Aggregator处于闲置状态,数据不会通过Aggregator,直接从片外存储进入Translator.如果是低精度数据,控制模块负责提供Aggregator同步所需的s_counter信号.最后,控制模块负责给Translator提供写地址信息spm_addr.
Aggregator负责同一张图像不同通道低精度数据的拼接,由多个插槽和同步计数器组成.Scatter引擎根据调度单元生成的访存地址表读取数据,每张图像中相同点不同通道的数据依次写进对应插槽中.每次在插槽中写入1个数据,对应的同步计数器值减1,插槽是一个32 b的存储单元,插槽的同步计数器归零意味着插槽中已经完成多个低精度通道数据的拼接,然后,Aggregator将该32 b数据单元传输至Translator.其中,同步计数器的初始值由调度单元生成s_counter信号提供.
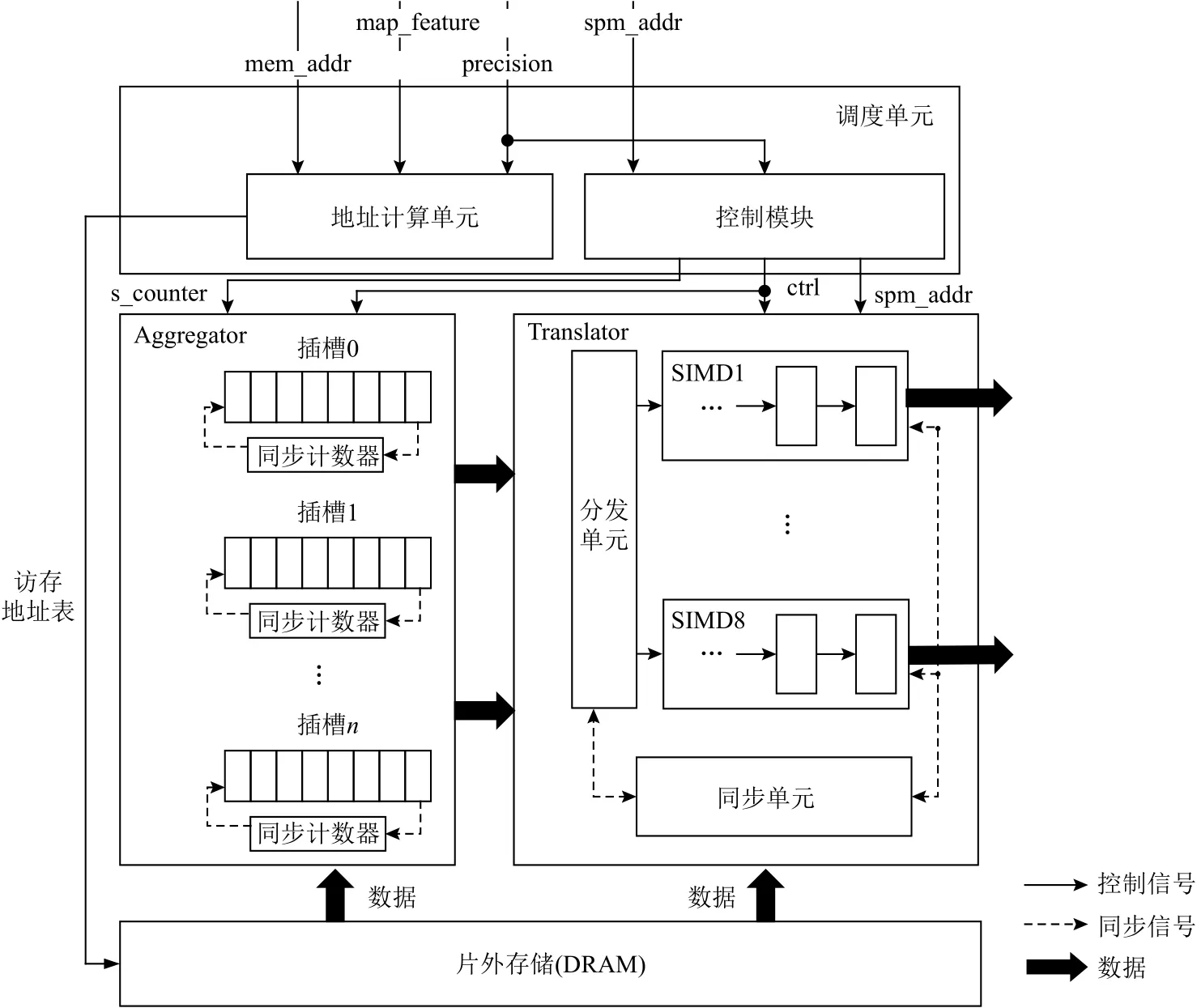
Fig.8 The structure of the Scatter engine图8 Scatter引擎结构图
Translator负责SIMD数据格式转换,由分发器、SIMD数据队列和同步单元组成.分发单元接受来自Aggregator或者片外存储的数据,将不同图像的数据送入不同的SIMD数据队列中,SIMD数据队列由先入先出(first in first out,FIFO)队列组成,同步单元使用bitmap进行同步操作,bitmap中纪录每个数据队列中队首数据是否就绪,一旦8个数据队列的队首数据就绪,则根据调度单元提供的spm_addr地址,将8个数据写入SPM对应地址中.
4.3 调 度
在数据流架构中,程序使用数据流图表示,数据流图(dataflow graph,DFG)记为GDFG,由一组节点(vertices)和连接节点的有向边(edge)组成,GDFG=(V,E).在粗粒度数据流架构中,数据流图每个节点由一段代码组成,代码段作为基本的调度和执行单元.
负载均衡有利于提升数据流架构的部件利用率从而保证数据流架构性能的发挥,而数据流图节点间的数据共享及复用能减少存储访问带来的开销,所以本文提出了兼顾负载均衡和数据复用的dR数据流图映射算法.具体的算法如算法1所示.
算法1.dR数据流图映射算法.
输入:特征矩阵规模IFmap、权值矩阵规模kernel、数据精度precision、计算阵列拓扑PEA、计算阵列规模PEvol、片上存储容量volume;
输出:数据流图GDFG=(V,E)、数据流图节点V与计算阵列拓扑PEA的映射关系map(V,PEA).
①d_volume←calculate(IFmap,kernel,precision);/*计算每层参与运算的数据量*/
②instance←calculate(d_volume,volume); /*由 于某些神经网络每层数据规模较大,需要多次计算*/
③vertices_work←calculate(d_volume,instance,PEvol);/*保证每个PE的负载均衡*/
④generate(vertices_work,V); /*根据每个节点的工作负载,编译生成数据流图节点集合V*/
⑤reduce_MA(V,GDFG);/*遍历节点集合V,消除相同地址的访问指令,将具有相同访存指令的节点定义为节点之间的数据流动关系,实现数据复用*/
⑥SD←BreadthFirstSort(GDFG);
⑦ for each nodeninSDdo
⑧ for each PEpinPEAdo
⑨curruentcost←Cost(n,p);/*代价函数 */
⑩ ifcurruentcost ⑪bestcost←curruentcost; ⑫map(n,p); ⑬ endif ⑭ endfor ⑮SD←SD−{n}; ⑯PEA←PEA−{p}; ⑰ endfor 算法1首先根据特征矩阵、权值矩阵规模和精度计算神经网络每层参与运算的数据规模;然后根据片上存储的容量计算迭代次数,受限于片上存储容量,某些神经网络层需要多次迭代才能完成计算.由于每次迭代计算的数据规模可以提前计算得到,所以可以根据数据规模以及PE阵列的计算规模,为每个计算单元分配均衡数据量,达到负载均衡的目的. 根据每个PE的工作负载,编译器生成每个数据流图节点的指令,包括取数指令、计算指令等,生成了数据流图的节点集合V.在reduce_MA操作中,遍历节点集合V,如果节点之间包含了对相同地址的取数指令,意味着这些访存指令是冗余的,只保留一个节点内的访存指令,该节点作为访存节点,去除其他节点的该条访存指令.访存节点作为上游节点,其他节点作为该访存节点的下游节点,通过节点之间的数据流动代替冗余的访存操作,实现数据的复用. 算法的下一步是程序的数据流图GDFG到计算阵列PEA的映射.首先对数据流图进行宽度优先遍历,然后根据代价函数Cost评估每个数据流图节点与不同PE映射方法的代价,选取最小代价的方案进行映射.由于数据流图节点之间的依赖关系表示数据的流动,所以上下游节点应该尽可能映射到相邻的PE,这样一方面可以减少下游节点的等待时间,另一方面还可以减少对片上网络的压力.所以在算法1中将每个数据流图节点映射到与其所有上游节点欧氏距离之和最小的PE上.其中,代价函数如式(2)所示,式(2)计算待映射数据流图节点为n且映射到序号为p的PE时,节点n与其所有上游节点(已映射)的欧氏距离之和. 为验证第4节中所提方法的有效性以及评估DPU_Q处理低精度神经网络的能力,本文使用中科院计算所研发的大规模并行模拟框架SimICT[19]实现了时钟精确的模拟器,模拟器配置信息如表3所示.同时,实验中使用Verilog语言实现了对DPU_Q的RTL 级仿真,并且利用 Synopsys Design Compiler工具进行综合,使用Synopsys ICC编译器进行布局布线,使用Synopsys VCS进行验证设计. Table 3 Configuration Information of DPU_Q表3 DPU_Q的配置信息 在本实验中,微控制器用于执行控制程序,采用ARM架构处理器.DPU_Q由8×8的PE阵列组成, PE中配置了8 KB的指令缓存和32 KB的数据缓存.PE中数据通路的关键路径为DECODE_REG→MUX→MAC_REG,时延为 0.8 ns,最高频率可以达到 1.25 GHz.实验中PE时钟频率设置为1 GHz.PE之间通过2维的mesh网络连接,完成数据、控制信息在PE阵列的传输.SPM的大小配置为6 MB,用于保存数据和指令. 在启动阶段,主机端将DPU_Q所需要的指令和数据通过Scatter引擎从内存拷贝到SPM中,然后配置处理器阵列控制部件来启动加速器的执行.计算任务完成之后,结果数据通过Scatter从加速器的SPM中拷回片外存储当中. DPU_Q主要对低精度卷积运算进行优化加速,为评估性能,实验选取AlexNet,VGG16网络模型中的卷积层作为实验的测试程序,各层规模如表4所示.实验中使用文献[18]提出的方法对AlexNet,VGG16卷积层的激活值和参数进行量化,计算过程中保留全精度的部分和.使用基于LLVM平台设计的编译器,编译器将每个卷积层编译为数据流图并映射到PE阵列. 为评估DPU_Q性能,实验中选择GPU(NVIDIA Titan Xp)、低精度神经网络加速器Eyeriss和BitFusion作为对比平台.需要说明的是,由于cuDNN暂无法支持INT4,所以GPU平台仅使用cuDNN实现INT8神经网络;参考文献[4]中的方法,实现了INT8的Eyeriss加速器.实验中使用部件利用率评估映射算法的有效性,部件利用率计算为 Table 4 Benchmark Information表4 测试程序信息 图9展示了DPU_Q在执行不同精度的AlexNet和VGG16网络时数据传输和执行的时间对比,其中传输时间指Scatter引擎进行数据传输的时间,执行时间指PE阵列计算时间.图9(a)中AlexNet和VGG16网络没有经过量化,对于每一层计算执行时间都超过该层数据在片上SPM和片外存储之间的传输延迟,DPU_Q可以通过双缓冲机制掩盖数据的传输延迟,对性能不会造成影响. 图9(b)(c)分别为 INT8 和 INT4精度下,DPU_Q部署AlexNet和VGG16网络时计算执行时间和传输时间的对比.得益于Scatter引擎,低精度数据的数据传输延迟不会超过计算部件的执行时间,双缓冲机制完全可以发挥作用.AlexNet和VGG16网络在不同精度下的传输带宽平均利用率为80.01%. Fig.9 Data transmission and execution time proportion of each layer of AlexNet and VGG16图9 AlexNet和VGG16各层的数据传输和执行时间占比 因此,实验证明了Scatter引擎可以有效解决低精度神经网络复杂的访存模式和带宽利用率降低的问题,解决了低精度神经网络执行过程中双缓冲机制面临失效的问题. 图10展示了不同精度下DPU_Q相对于DPU的性能提升.对于AlexNet和VGG16网络,INT4精度下,DPU_Q的性能达到了最佳,分别是DPU的7.9倍和7.7倍.当精度为INT8和INT16时,DPU_Q相对于DPU性能分别平均提升了3.80倍和1.89倍.DPU_Q的性能提升得益于RPU的设计,RPU可以根据精度动态重构数据通路,RPU内的MAC簇可以并行计算多个通道,这使得DPU_Q具有高吞吐量并以此获得性能的提升.当然,当精度缩小为1/n之后,性能并未达到理想的n倍加速,例如精度为8 b时的性能未到达32 b精度时的4倍,而是3.8倍.这是因为数据流架构的执行时间包括了配置初始化时间和计算时间,配置初始化的时间并未缩短. Fig.10 Speedup promotion of DPU_Q over DPU图10 DPU_Q相对于DPU的加速比提升 图11展示了以Eyeriss为基准,DPU_Q执行AlexNet和VGG16网络各层的加速比.DPU_Q执行各层的性能都优于Eyeriss.这是由于Eyeriss在进行神经网络部署时,仅考虑减少数据在片上的移动距离,减少数据搬运带来的功耗,并未挖掘神经网络计算中的并行性.对于AlexNet,加速比最高的是conv1,其加速比是2.85,这是因为第1层的权重矩阵规模较大、通道数较少,RPU中利用通道并行性以及SIMD间利用通道并行性的优势能显著减少数据的平均执行时间.另外得益于本文提出的映射算法能对数据进行充分复用,使得计算部件利用率提高,加速效果更明显.conv4和conv5的加速比较低,原因在于这2层的权重矩阵的规模很小,意味着可复用的数据占比减少,PE阵列的部件利用率下降,导致加速效果不明显.当执行VGG16时,conv2_1和conv2_2层的加速比较大,分别是8.155和8.157,这2层的通道数较少,DPU_Q加速效果明显的原因与第1层相似.执行AlexNet和VGG16网络时,DPU_Q计算平均部件利用率为76.02%. Fig.11 Speedup of DPU_Q over Eyeriss图11 DPU_Q相对于Eyeriss的加速比 图12展示了 DPU_Q,Eyeriss,BitFusion相对于GPU的性能对比,其中图12(a)是INT8精度的性能对比,图12(b)是INT4精度的性能对比.对于INT8精度,当部署AlexNet和VGG16网络时,DPU_Q相比于GPU可取得3.18和1.16的加速比,DPU_Q的性能是Eyeriss的1.52倍和6.05倍.当网络结构较为简单时,Eyeriss通过最小化数据传输距离作为优化目标以及细粒度的数据流执行方式能够取得较好的性能表现,但是当网络结构复杂时,较差的数据复用以及低并行性使得性能下降较为明显. 对于INT4精度,当部署AlexNet和VGG16时,DPU_Q相对于加速器BitFusion可以取得1.52和1.17倍的性能提升.与BitFusion相比,DPU_Q能取得较好的性能表现,主要原因是由于BitFusion比特级的计算部件重构会导致计算的数据通路较长,计算周期增加.另外,得益于DPU_Q同时利用不同图像和不同通道维度的数据并行,实现了高吞吐量和性能的提升. Fig.12 Performance comparison of DPU_Q,BitFusion,Eyeriss over GPU图12 DPU_Q,BitFusion,Eyeriss相对于GPU的性能对比 图13展示了4种方案的能效对比,DPU_Q的能效都优于其他3种不同的平台.当部署AlexNet和VGG16网络时,DPU_Q的能效是GPU的4.49倍和3.34倍,造成GPU能效较低的主要原因是GPU的能耗非常高(计算资源平均部件利用率为41.35%).DPU_Q的能效是 Eyeriss的1.6倍和1.38倍.虽然Eyeriss的性能表现不佳,但是由于其具有毫瓦级的功率,使得其在能效方面具有良好表现.DPU_Q的能效是BitFusion的1.13和1.05倍,DPU_Q在性能方面的提升得益于挖掘了多种并行性和映射算法,但是在计算单元以及传输Scatter引擎等特殊部件的设计也带来了额外能耗的开销. Fig.13 Energy efficiency comparison图13 能效对比 实验中使用Verilog语言实现了对DPU_Q的RTL 级仿真,并且利用 Synopsys Design Compiler工具以 TSMC 12 nm 工艺进行综合,使用 Synopsys ICC 编译器进行布局布线.DPU_Q的面积和功耗分布如图14所示,Scatter引擎所占面积比例为0.61%,功耗占比仅为0.80%.另外,DPU_Q的面积相对于DPU增加了17.6%,额定功耗增加33.59%,硬件增加的开销主要来源是PE内RPU多种不同精度的计算部件. Fig.14 Distribution of area and power consumption of DPU_Q图14 DPU_Q的面积和功耗分布 本文结合低精度神经网络的计算需求,设计了灵活可重构的计算单元和Scatter引擎,并提出了负载均衡和数据复用的数据流图映射算法,设计了数据流加速器 DPU_Q.相比于同精度的 Titan Xp GPU,DPU_Q可以获得最高3.18倍的性能提升和4.49倍的能效提升.相比于同精度的Eyeriss加速器,DPU_Q可以最大获得6.05倍性能提升和1.6倍能效提升,相比于BitFusion加速器,可以最大获得1.52倍性能提升和1.13倍能效提升,表现出良好的性能和能效优势.本文仅针对卷积层进行了优化设计,由于神经网络中还包括其他类型的计算,未来会面向神经网络中其他类型的计算,进一步优化数据流架构. 作者贡献声明:范志华负责论文思路的提出、架构设计、实验和论文的撰写;吴欣欣负责论文思路讨论和架构设计讨论;李文明负责论文架构讨论和整体质量把控;曹华伟负责论文修改及实验指导;安学军负责论文整体思路的指导;叶笑春负责论文整体架构设计及修改;范东睿负责论文整体架构设计.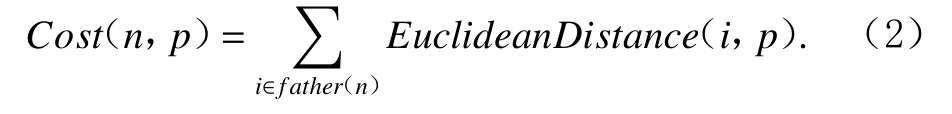
5 实验设置
5.1 实验平台

5.2 测试程序
5.3 对比平台


6 结果分析
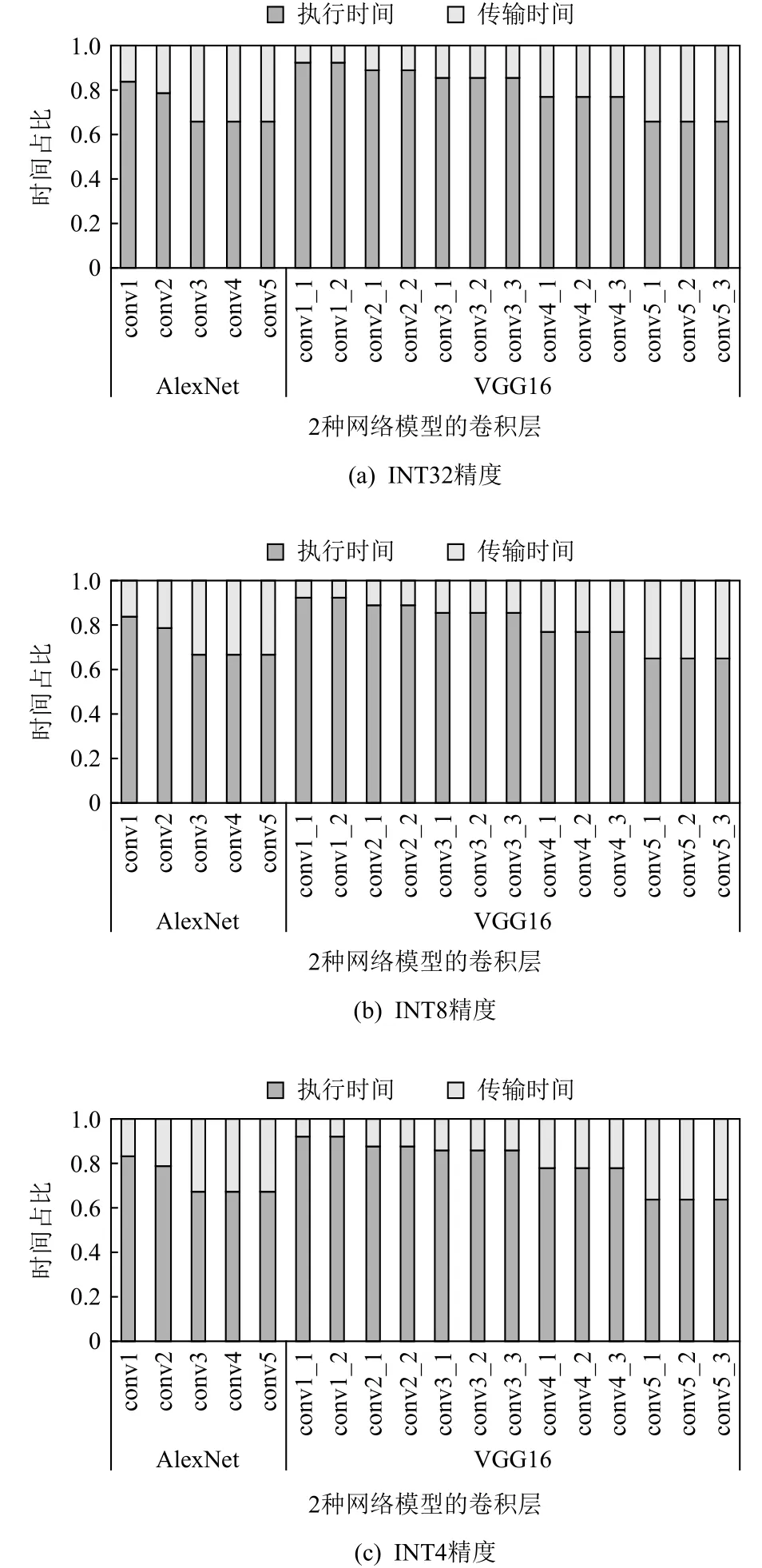
6.1 Scatter引擎收益
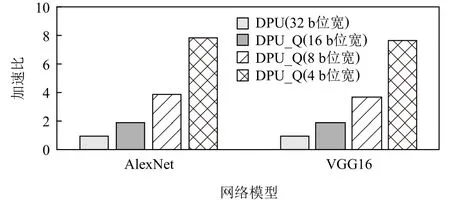
6.2 性能对比
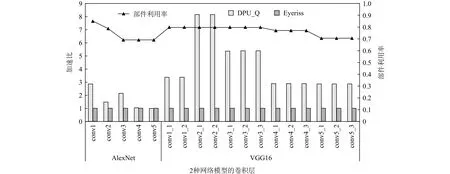
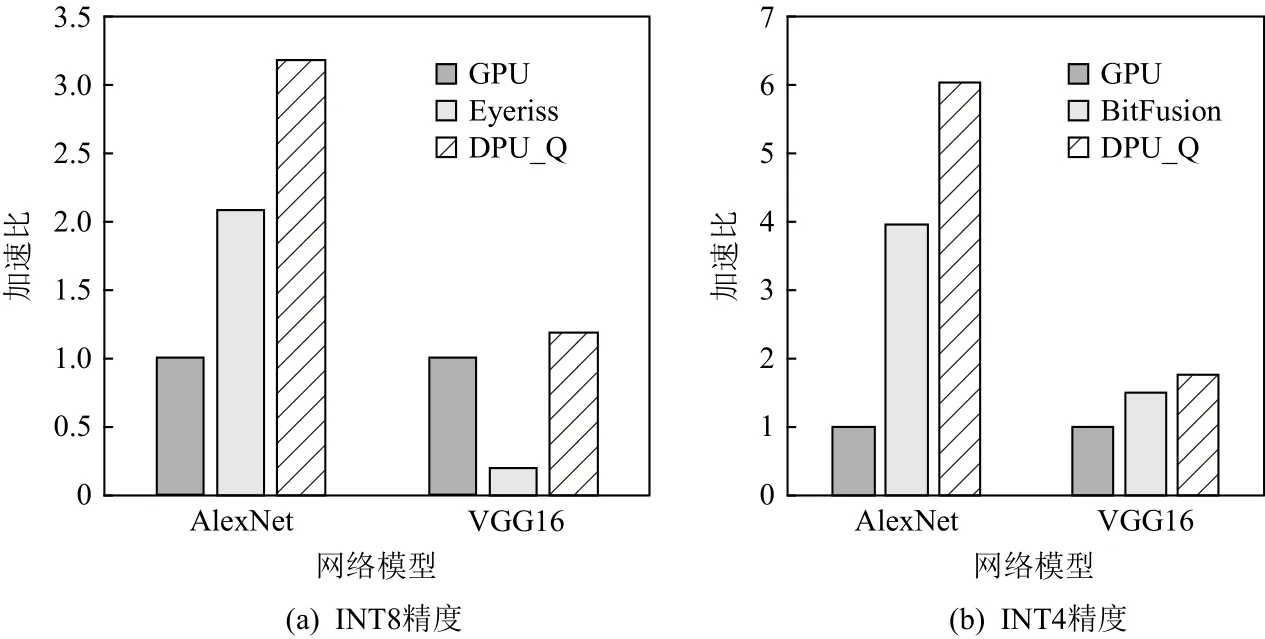
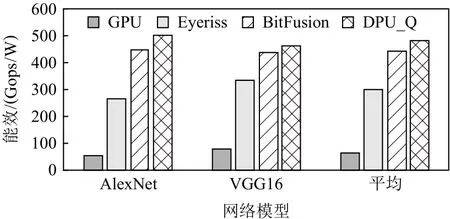
6.3 能效对比
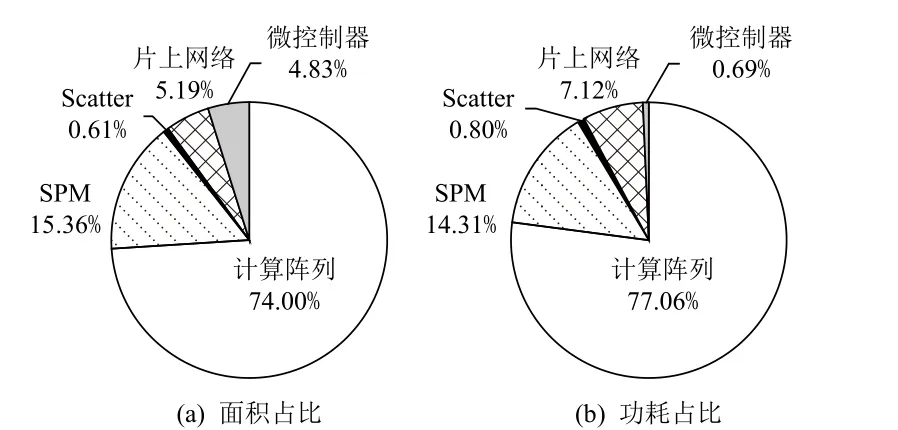
6.4 硬件开销
7 总 结
