基于时间和关系感知的图协同过滤跨域序列推荐
2023-01-30刘柏嵩孙金杨钱江波
任 豪 刘柏嵩 孙金杨 董 倩 钱江波
(宁波大学信息科学与工程学院 浙江宁波 315211)(janeyren@126.com)
序列推荐(sequential recommendation, SR)[1-2]算法旨在利用马尔可夫链[3]、循环神经网络(recurrent neural network, RNN)、 卷 积 神 经 网 络 (convolutional neural network, CNN)[4-5]以 及 图 神 经 网 络 (graph neural network, GNN)[6-9]等技术从一系列具有时间先后关系的行为序列中挖掘用户动态行为模式,预测用户可能感兴趣的或点击的下一个项目.传统推荐算法从用户长期静态历史行为中挖掘其偏好,忽略该用户在当前状态下的兴趣偏好的挖掘和利用;序列推荐算法则综合考虑用户的长期历史偏好和当前兴趣偏好,注重用户动态行为偏好的挖掘和捕捉,在新闻推荐、朋友推荐、音乐推荐、点击率预测等实际场景下发挥重要作用.当前,以GNN为基础模型建模用户兴趣偏好的序列推荐模式被证明在同等条件下其推荐最为有效[6].但此类算法的有效性严重依赖于丰富的历史行为数据,对于新用户或非活跃用户来说,其已知的历史行为数据相对稀疏,此时,用户意图预测的准确性较低,推荐效果受数据稀疏性影响明显.利用迁移学习从其他相关领域迁移合适的领域知识辅以解决当前领域的问题是缓解数据稀疏性影响的一种有效方法[10].在现实情况下,用户往往同时与多个领域的项目进行交互.自然地,当用户在域A中的交互历史较少时,可以考虑从包含更多行为数据的相关域B中获取相关数据,迁移相关领域B中用户的共同偏好以提高域A的推荐效果.近年来,部分工作[11-17]开始考虑利用迁移学习增强序列推荐算法的性能,跨域序 列 推 荐(cross-domain sequential recommendation,CDSR)算法被提出来,用以降低数据稀疏性问题对建模用户偏好准确性的影响.但是现有跨域序列推荐算法仍存在2个方面问题:
1)大多数推荐算法仅考虑用户在域间的共同偏好特征的提取与迁移,忽略不同领域中域间独有特征的利用,导致经过跨域知识迁移之后的用户偏好表示近乎完全相同,进而降低某个领域中项目与用户偏好的匹配度.
2)用户行为序列中蕴含的可用信息的挖掘与利用尚不充分.大多数情况下只利用项目间的相对时序关系初步建模序列中项目间的转换关系,忽略序列项目间的复杂转换关系的挖掘,导致用户的意图预测不准确.
受协同过滤思想启发,针对上述问题,提出基于时间和关系感知的图协同过滤跨域序列推荐(time and relation-aware graph collaborative filtering for crossdomain sequential recommendation,TRaGCF)算法.该算法主要包括3个模块:1)为获得用户行为序列中项目间高阶复杂的时序依赖关系,提出时间感知图注意力(time-aware graph attention,Ta-GAT),从已知的用户历史行为序列中获取项目的域间序列级嵌入表示;2)从域内用户−项目交互二部图中挖掘用户的行为偏好,提出关系感知图注意力(relation-aware graph attention,Ra-GAT)学习项目协同表示以及用户协同偏好表示,为用户偏好的跨域迁移提供基础;3)为同时提高2个领域中的推荐效果,提出用户偏好特征双 向 迁 移 模块 (user preference feature bi-directional transfer module,PBT)模块,迁移域间用户共有偏好,同时保留用户的域间特有偏好.
本文的主要贡献包括4个方面:
1)针对CDSR问题,提出了TRaGCF算法,将图协同过滤引入到序列推荐算法中,建立用户偏好跨域迁移的桥梁,从而缓解数据稀疏对推荐结果的影响.
2) 为从用户偏好特征学习过程中区分不同关系发挥的作用,提出关系感知图注意力提取项目协同表示和用户协同偏好嵌入表示,为用户偏好的跨域迁移提供基础.
3)提出用户偏好特征双向迁移模块,实现不同域之间的用户共有偏好迁移,并保留用户的域间特有偏好.
4)在2个公开的数据集上验证算法的正确性和有效性.实验结果表明,跨域迁移用户偏好过程中保留域内用户特有偏好对全面用户画像十分必要.
1 相关工作
1.1 基于GNN的序列推荐算法
GNN[18-19]在非欧氏空间中能有效建模项目间复杂的高阶关系,使得GNN成为大多数序列推荐算法的基础模型之一,通过将序列化问题转换为图问题以求解相应的推荐问题,取得可喜的成果[6,20-21].Wu等人[6]提出基于图神经网络的序列推荐算法(sessionbased recommendation with graph neural networks, SRGNN),将一个会话中用户交互序列构建为一个有向图,再利用门控图神经网络(gated graph neural network,GGNN)提取用户的偏好表示,取得较好推荐效果.此后,包括基于图上下文自我注意力网络的会话推荐模 型(graph contextualized self-attention network for session-based recommendation,GC-SAN)[22]在内的多种变体相继被提出,Qiu等人[9]提出构造一种带有自环的会话图,借助多头注意力来学习项目间的转换模式,重新考虑会话中的项目序列模式以得到相应的推荐.基于注意力机制的个性化图神经网络(personalized graph neural networks with attention mechanism, APGNN)[23]算法模型则利用自注意力挖掘用户历史会话和当前会话中的项目间细粒度转换关系建模其动态偏好,以用户身份信息作为指导做相应的个性化推荐;基于全局上下文增强图神经网络的会话推荐(global context enhanced graph neural networks for session-based recommendation,GCE-GNN)[24]模型首先构建会话图和全局会话图,再利用注意力机制学习项目的会话级和全局级嵌入表示;基于记忆增强图神经网络的序列推荐(memory augmented graph neural networks for sequential recommendation, MA-GNN)[25]
模型则利用共享记忆网络编码项目间的长期依赖关系,建模用户的长短期兴趣.虽这些算法的推荐性能已有明显改善,但它们都只考虑2个连续项目之间的简单的成对转换关系,忽略了非连续项目间的高阶复杂的转换关系,从而导致部分可用信息丢失.尽管上述研究表明,基于GNN的序列推荐算法性能优于其他序列推荐算法,但仍存在3点不足: 1)对项目间高阶转换关系的挖掘尚不充分;2)项目间的时间信息对建模项目间转换关系的贡献研究不够;3)极少有工作同时考虑用户的当前兴趣和全局兴趣偏好.
1.2 跨域序列推荐算法
数据稀疏和冷启动问题是推荐系统中常见的问题,在序列推荐场景中这些问题的影响尤为明显.Ma等人[11]提出一种全新的跨域序列推荐算法,解决在具有共享账户条件下的跨域推荐问题.该算法首先利用2个并行的RNN组成一个并行信息共享网络(parallel information-sharing network,π-Net),以 2 个域间共享账户作为知识迁移桥梁,通过共享账户过滤单元(shared account filter unit,SFU)提取特定用户的表示来识别不同的用户行为;再利用门控机制过滤掉可能对另一个域有用的信息,跨域信息迁移单元(cross-domain transfer unit,CTU)自适应地聚合每个时间戳中SFU的输出特征并将其迁移到另一个域中,实现2个域同时推荐.随后,郭磊等人[12]用自注意力网络替代RNN对π-Net进一步提出基于自注意力的跨域推荐模型(self-attention-based cross-domain recommendation model,SCRM),解决 RNN 无法建模项目间长期依赖问题.π-Net和SCRM算法都是特定的多用户共享账号的跨域推荐问题,而对于更一般情况下的跨域推荐场景来说,这2个算法都能不完全适用.于是,Ma 等人[13]进一步提出混合信息流网络(a mixed information flow network,MIFN),通过行为迁移单元从行为信息流中提取出与用户偏好相关的有用信息,并将其迁移到目标域中;以知识图谱作为基础知识迁移单元,建立不同领域中项目间关联关系.除此之外,Ma等人[13]还提出一种跨域图卷积机制来区分知识图谱中的项目,达到“在合适时机迁移合适的知识”的目的.基于并行循环网络的跨域推荐算法模型(cross-domain hierarchical recurrent model, CDHRM)[15]则通过2个并行的RNN挖掘用户跨域行为中项目的关联性,实现跨域序列推荐.该算法同时考虑用户的当前兴趣偏好和用户全局兴趣偏好,解决用户跨域行为交互过程存在的异步迁移问题.
1.3 图协同过滤
协同过滤(collaborative filtering,CF)[26]是现代推荐系统中的最常见的技术之一,通过将用户−项目交互关系映射到2个空间中分别得到用户的嵌入表示和项目的嵌入表示,二者执行内积运算得到预测评分.近年来,GNN在非欧氏空间中对非线性高阶关系特征学习的高效性使其自然地被引入到CF中来,从用户−项目交互二部图中学习用户和项目的表示以预测用户的偏好.图卷积矩阵补全模型(graph convolutional matrix completion,GCMC)[27]在编码用户−项目交互特征时,利用图卷积网络(graph convolutional network,GCN)来探索用户与项目间的关联.Wang等人[28]提出的神经图协同过滤(neural graph collaborative filtering,NGCF)将GCN集成到嵌入表示学习过程,通过堆叠多个嵌入传播层,捕获协作信号,建立用户与项目之间的高级连接,但其设计较复杂.LRGCCF[29]证明了NGCF中非线性变换函数对协同过滤效果没有提升,甚至限制了其应用于更大的数据集的可能性.此外,LR-GCCF利用残差学习解释了所有图层的输出间存在关联的原因.随后,轻量图卷积网 络(light graph convolutional network, LightGCN)[30]删除包括激活函数、非线性转换函数等对CF无明显促进作用的2个操作来简化NGCF,进一步降低模型复杂度.此外,考虑到用户间和项目间存在异构信息,多图卷积协同过滤(multi-graph convolution collaborative filtering ,Multi-GCCF)模型[31]分别构造了 2 个独立的用户−用户图和项目−项目图,利用一个多图编码层来整合用户−用户图、用户−项目图和项目−项目图所提供的信息,编码用户表示以及项目表示.利用上述模型建模用户偏好表示时需要有足够的用户−项目交互数据,算法性能受到数据稀疏影响明显,无法直接用于跨域场景中.
2 问题描述与定义
跨域序列推荐旨在从给定的某用户在一段时间内的交互行为序列中挖掘其兴趣偏好,以预测该用户在多个域中最可能同时与之交互的下一个项目,缓解序列推荐中的数据稀疏的影响,这里以用户重叠的2个域为例进行说明.
设VA={vA1,v2A,…,vmA} 是域A中m个非重复项目集合,VB={v1B,v2B,…,vnB} 是域B中n个非重复项目集合,U={u1,u2,…,uM} 表示域A和域B中所有的共有M个非重复用户集合.为建模项目间时序依赖关系,本算法中同时给定用户在A和B两个域中的交互行为序列.以用户u1为例,设其在域A中的交互序列为sA={v1A,v2A,…,viA}, 其 在 域B中 的 行 为 序 列 为sB={v1B,v2B,…,vBj},其中vdi表示用户u1在领域d∈{A,B}中与项目vi交互过,则跨域序列推荐的目标是根据已知的sA和sB的情况下预测某个用户下一项交互的项目,即分别预测域A和域B中的候选项目被推荐出来的概率
3 TRaGCF算法设计
3.1 概 述
TRaGCF算法处理过程为:1)在初始化阶段,通过嵌入层得到用户和项目的初始化嵌入表示.2)在项目的域内序列级表示学习阶段,将域A( 或B)中给定的用户行为序列构造为一个加权有向图GA(或GB),提出一种改进的时间感知图注意力获得域内项目的序列级表示.3)在跨域项目和用户协同表示学习阶段,为给定用户项目交互行为构造跨域交互类二部图,提出Ra-GAT分别学习项目和用户的协同表示.4)在特征聚合与特征迁移阶段,将项目的协同表示和序列级嵌入表示聚合成为最终的项目表示;用户特征表示则分为特征聚合和特征迁移2部分,用户偏好特征聚合方式类似于项目表示的聚合方法,用户特征迁移通过本文提出的PBT双向迁移用户域间共享偏好与域内特有偏好以聚合得到域内用户的终极表示.5)在预测与推荐阶段,通过每个域内用户和项目终极表示的点积计算出候选项目被推荐的概率,做出相应的下一项推荐.TRaGCF模型如图1所示.
3.2 用户和项目初始化模块
利用一层嵌入层对给定用户u和项目v进行初始化为huj和hvj,其中j∈{A,B}.对于域A

其中P和Q分别表示用户和项目的可学习参数矩阵,xu和xv分别表示用户u∈U和项目v∈V的独热编码,和分别表示域A和域B中相同用户的嵌入表示向量.类似地,得到在域B的用户初始化嵌入表示
3.3 项目的域内序列级表示学习模块
项目的域内序列级表示可从用户某个领域中给定的历史行为序列中挖掘更多项目间的高阶复杂的转换关系,从而建模项目间更长的时序依赖关系.给定某个用户的历史行为序列,项目间交互时间信息可反映项目间关联关系,且项目间关联关系的紧密程度与交互时间差的多少成反比.基于此,提出机制Ta-GAT学习项目的序列级表示.由于域A和域B中计算方法完全相同,仅以域A为例,域B则可自然得到.
在TRaGCF中,首先用类似于SR-GNN[6]中的会话图的构建方法在域A和域B中分别构建有向序列图GA={VA,EA,WA} 和GB={VB,EB,WB},序列图构造的示意图如图2所示.其中,V={v1,v2,…,vm}是有向图中的节点集合,vm表示用户在某个领域中交互过的项目;E表示有向图中的有向边的集合,考虑到节点间边的方向和类型可能反映出节点间的不同关系,且当2个节点间存在双向连边时,该节点项目间的关联程度则相对于仅存在一条连边的项目间的关联性更大,为此设定4种类型的边,即rij={rout,rin,rin-out,rself},rout表示只有1条从vi到vj的有向边,rin则表示仅有1条从vj到vi的有向边,rin-out表 示 节 点vi和vj间 存 在双向连边,rself表示节点的自连边,用于自身关系的更新与传递;权值矩阵WA(或WB)是通过序列中项目间的交互时间计算出的时间感知权重矩阵,则项目间的时间权重 ωi,j计算为其 中ti,j表 示 项 目vi和vj的 交 互 时 间 差 ,tmax和tmin分 别表示给定序列中相邻2个项目的交互时间差的最大值和最小值,其中 ωi,j的取值与项目vi和vj关系的紧密程度成正比,且该值越大,将对应的项目推荐给用户的可能性越大.
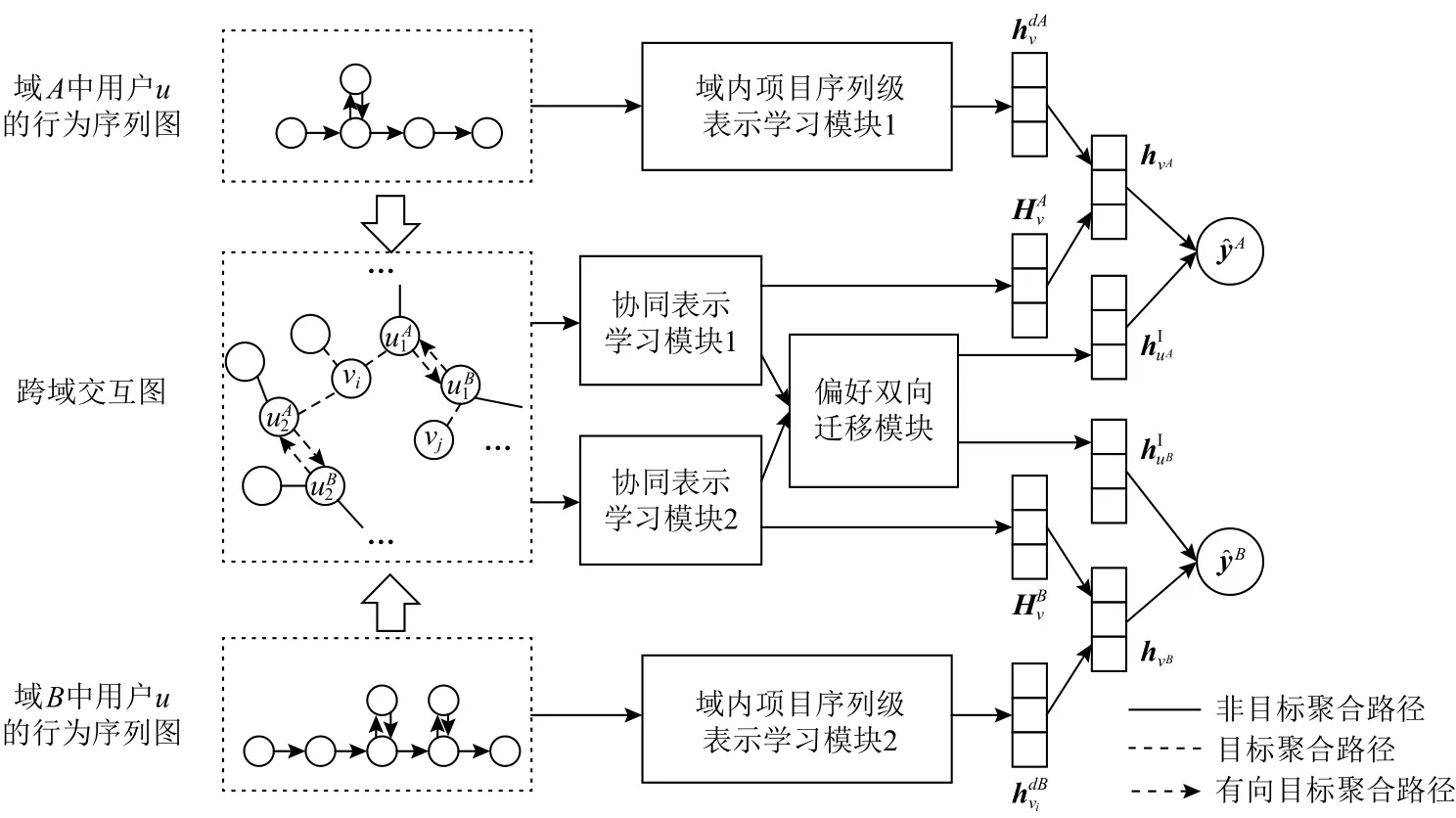
Fig.1 The frame of TRaGCF图1 TRaGCF 模型框架
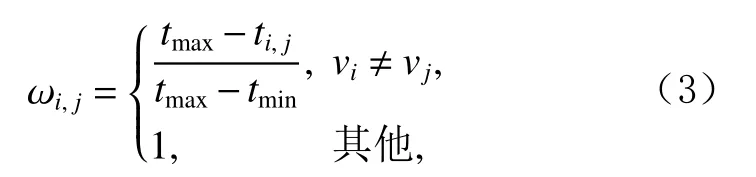
其次,根据图2构造的时间感知序列图学习序列中项目的表示,即节点间消息聚合与节点表示更新.不同邻居项目节点的重要程度不同,2个节点连边的类型和对应的时间间隔长短可反映出2个项目的关联程度.为此,考虑2个项目时间感知权重以及利用边类型感知注意力建模项目之间不同的关联程度,提出一种改进的边类型感知注意力,计算为
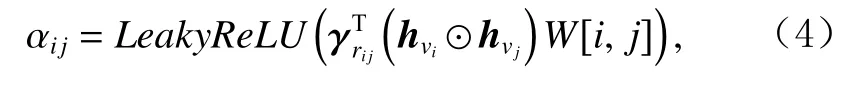
其 中 αij表 示2个 项 目 节 点vi和vj的 关 联 程 度 ,rij表示这2个节点间边的类型, γ∗和W[i,j] 分别表示边类型感知注意力权重和时间感知权重.进一步,为增加节点间的可比性,将上述注意力权重执行归一化处理:
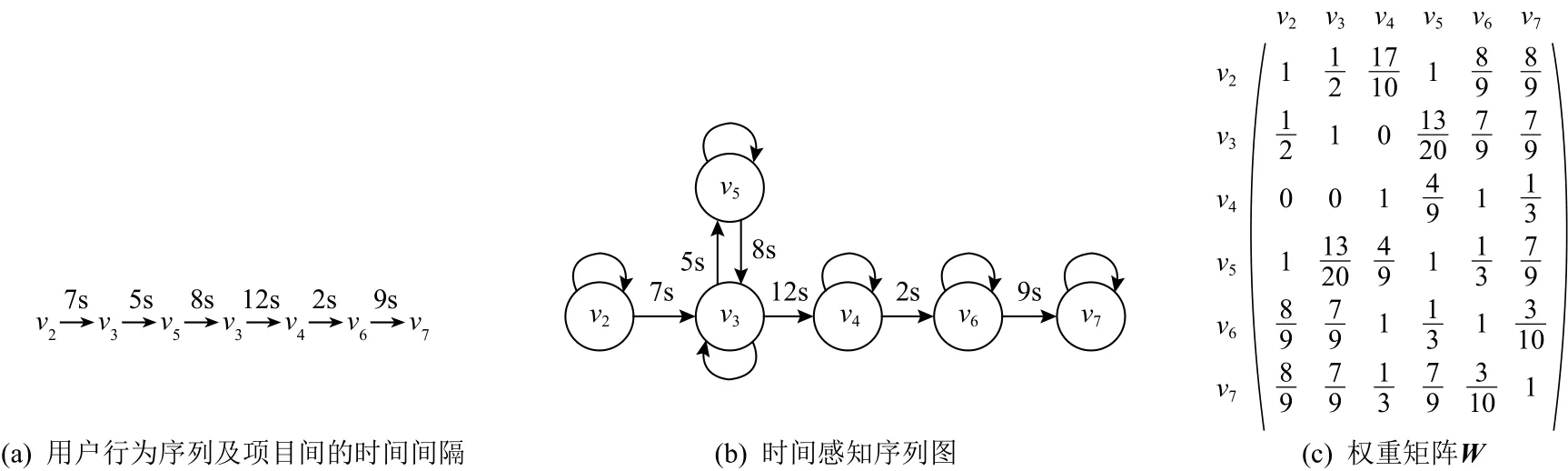
Fig.2 Time-aware sequential graph图2 时间感知序列图
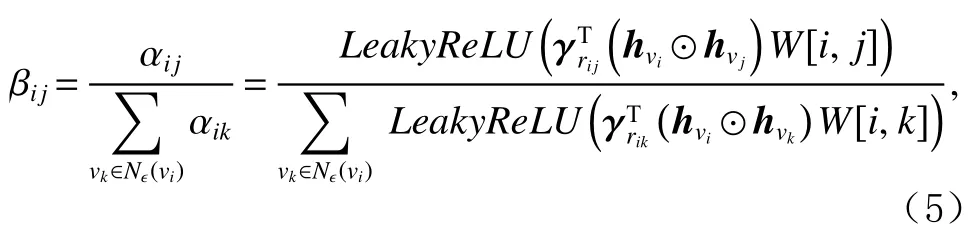
βij表示不同的邻居卫星节点对目标项目节点的贡献,其值是不等的,用来衡量其传递到当前节点的信息量.考虑到节点前一阶段的表示对当前项目的表示有一定的影响,显式聚合该节点上一次的序列级表示,即
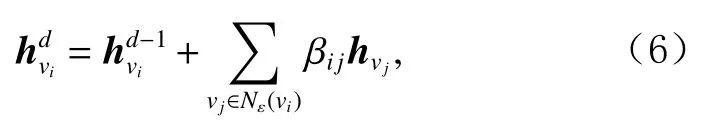
考虑到单层Ta-GAT可聚合来自目标节点的一跳邻居节点的信息,为了建模项目间的高阶复杂关系,聚合更多可用的辅助信息,进一步堆叠多层Ta-GAT得到项目的k阶表示:
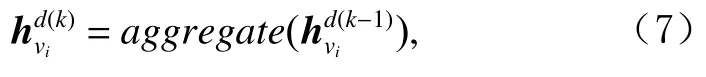
其中,aggregate()表示聚合函数.
3.4 项目与用户协同表示学习模块
该模块旨在从给定的用户和项目的交互行为中挖掘更多的信息用于后续推荐.首先建立如图3所示的用户−项目交互二部图H={U,V,E},其中U表示用户集,V表示项目集,e=(u,v)∈E表示用户u和项目v之间有交互行为.
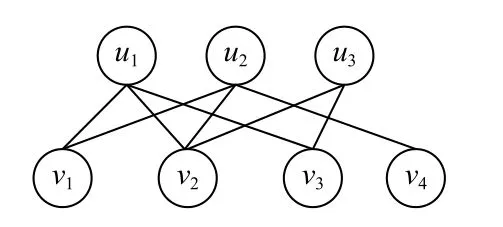
Fig.3 A user-item interaction bipartite graph图3 用户−项目交互二部图
从图3中可以看出,对于任意用户节点u,其直接相连的一定是项目节点v,反之亦然.对于特定用户,其偏好可能受其交互过的项目的影响,也可能受和其品味相同的用户的行为左右,受R-GCN(relational graph convolutional network)[32]的启发,本文中将“u→v”和“v→u”看成是2种不同类型的边,分别代表 “喜欢”和“被喜欢”2种含义,并在最终的推荐中发挥不同作用.为此,提出Ra-GAT用于学习用户和项目协同表示学习,以域A为例,项目和用户协同表示学习过程为
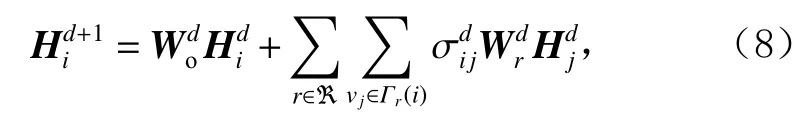
其中Hi∈{hu,hv}, ℜ 表示节点间的2种边的类型,Γr(i)表示节点i∈{u,v}的邻居节点集,和是2个可学习的参数矩阵,表示节点i和节点j间的关系注意力.计算为
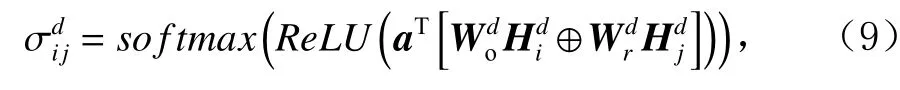
其中a是 一个转换矩阵,⊕表示拼接.由于不同层的可学习参数矩阵和不同, σdij是层独立,可有效地建模交互图中节点间的更为复杂的转换关系,丰富用户和项目的协同嵌入表示.类似地可得,域B中的用户和项目的协同表示.
3.5 用户偏好跨域双向迁移模块
为学习用户和项目的跨域协同表示,构造如图4所示的跨域交互图.以图4中的路径为例,对于项目vi,可从与其直接相连的邻居节点中聚合部分信息更新其表示,同时,节点也同样聚合了部分来自其一跳邻居节点vj的 信息,则项目vi和vj便可建立跨域关联路径为:
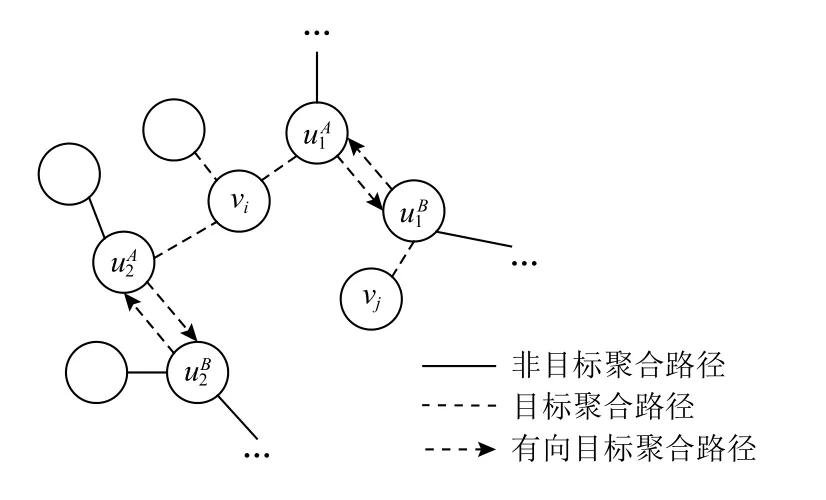
Fig.4 Cross-domain interaction graph图4 跨域交互图
由于项目的属性特征是稳定的,这里仅考虑将用户的偏好表示跨域迁移.不同于大多数传统跨域推荐算法中仅考虑用户的跨域共享偏好,本文中同时考虑用户的域间特有偏好,则定义域A和 域B中 用户u的特征双向迁移过程为
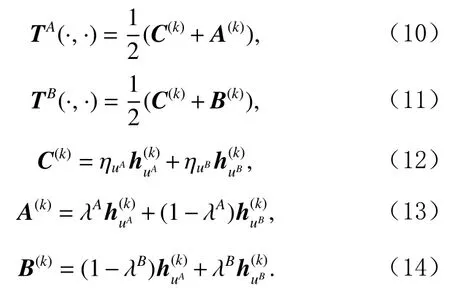
TA()和TB()分别定义为域A和 域B的特征迁移函数,C(k)为用户u在域A和 域B中 的k阶共有特征偏好,A(k)和B(k)则分别表示用户u在域A和 域B中 的k阶域间特有特征偏好(或)是由式(7)计算得到; ηuA和 ηuB分别表示在域A和 域B中的用户表示相关的权重因子,计算如式(15)(16); λA和 λB是2个范围在[0,1]之间的超参数,用于控制用户特征在对应域内的保留比例.
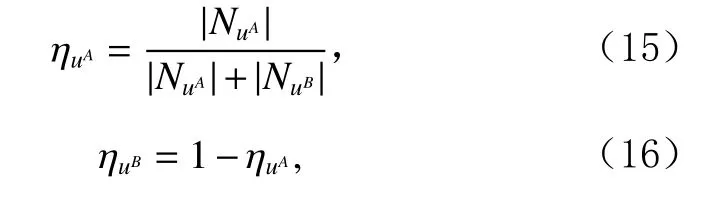
其中,和分别表示在域A和 域B中 用户节点u的一跳邻居节点的数量,即表示用户u在域A和 域B中的交互过的项目数量;若用户在特定领域中拥有更多的交互记录,则其在该域中的偏好特征就越明显,推荐过程中该领域中的偏好占比就越大,从其他领域中迁移过来的偏好特征的作用相对减弱.如此,用户u经过特征迁移后在域A中的表示:
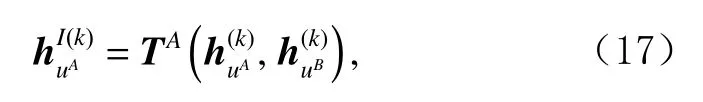
类似可得到其在域B中的最终的嵌入表示.
3.6 相关推荐与优化模块
经过项目的序列级表示学习模块和用户项目的协同表示学习模块以及用户特征的双向迁移模块后,分别得到项目的序列级表示和项目的协同表示以及用户在2个域中的偏好表示和.将项目的序列级表示和协同表示拼接后作为该域中项目的最后嵌入表示,与该域中的用户行为偏好表示执行点积运算得到相应的项目被推荐的概率.以域A为例,项目v被推荐给用户u的概率为
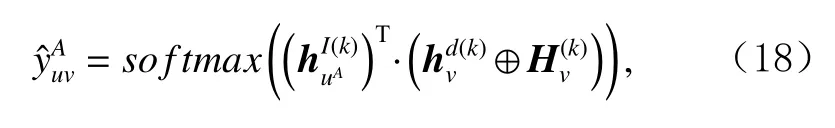
采用二元交叉熵函数作为模型训练和优化时目标函数:
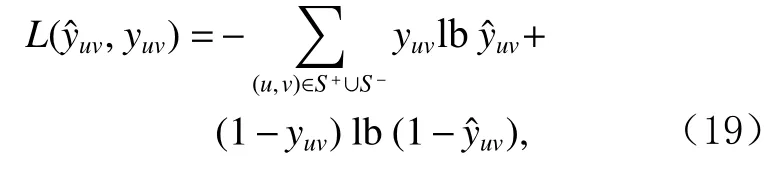
其中S+和S−分别表示给定的交互历史记录集和通过随机采样的方式构造的用户交互历史记录集.由于2个域的推荐模型完全相同,式(19)的目标函数在2个域的推荐中均适用,不做特别区分.
4 实验设计与性能分析
验证问题1.验证TRaGCF在跨域场景下的有效性和正确性,分析产生这样推荐效果的原因.
验证问题2.TRaGCF中不同的功能模块对推荐效果有怎样的贡献并分析原因.
验 证 问题3.验 证 超 参数 λA和 λB对 于算 法 性 能的影响并分析原因.
4.1 数据处理与实验设计
本节将从实验数据集选取及处理、评价指标、对比方法以及参数设置4个方面介绍实验设置.
1)数据集的选取及预处理
为验证所提算法TRaGCF的有效性,选择更加适合跨域序列推荐算法的Amazon数据集作为验证数据集,其中包含来自多个域中的用户项目交互数据(如用户ID、项目ID、评分以及交互时间戳等);此外,Amazon数据集包含了多个领域中重复用户的交互信息,满足跨域序列推荐的场景.具体地,选取Movie-Book以及Food-Kitchen构建执行行为迁移的2组数据集.Movie域和Book域中分别包含用户的观影记录以及阅读记录;Food域和Kitchen域中分别包含用户的食物购买记录以及器具采购记录.
按照Ma等人[11]的数据预处理方法对所选择数据预处理.为满足跨领域推荐的基本要求,选择在2个领域都有交互的用户作为目标用户,去掉没有交互记录的用户或者项目,仅保留交互项目超过10个的用户和出现频次大于10的项目.为满足序列推荐的要求,首先将用户的交互记录按照时间排序,把完整的交互序列分割成几个小的序列,每个小序列包含一定时间内的连续交互行为,且要求每个小序列中至少包含3个交互项目,实际上分割后的一个小序列可以看成是1次会话.经过预处理之后的数据集如表1所示:
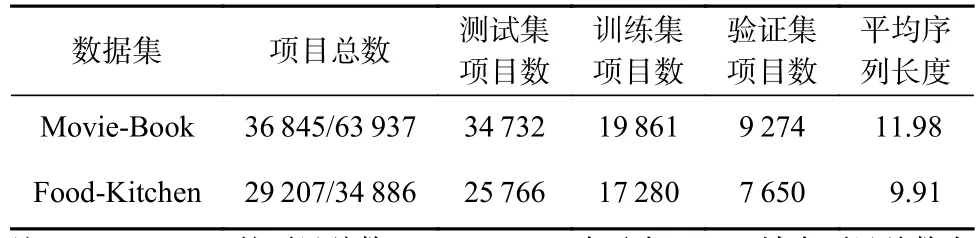
Table 1 The Statistics of the Datasets After Preprocessing表1 预处理之后的数据集统计分析
2)评价指标
实验选取召回率(Recall)和平均倒数排名(mean reciprocal rank,MRR)作为模型性能的评价指标.其中MRR表示样本中正确推荐的项目在推荐列表中的排名.被正确推荐出来的项目在推荐列表中的排名越靠前,其MRR的值越大;被正确推荐的项目排名越靠后,则其MRR的值越小;若当前的推荐列表中没有正确推荐的项目,则其MRR为0.Recall是指推荐列表中的top-k个项目中推荐出来的项目占样本中所有相关项目的总数,是衡量推荐全面性的常用指标,k∈{5,10,20}.
3)基线模型算法的选择
为全面检验本文算法的有效性,选取单域推荐算法(POP,Item-KNN)、单域序列推荐算法(GRU4REC,NARM,STAMP,SR-GNN)、跨域推荐算法(CoNet)以及跨域序列推荐算法(CDIE-C,CDHRM,π-Net,MIFN)作为对比算法,其中:
PoP根据训练数据中项目的受欢迎程度将排名最高的项目推荐出来.
Item-KNN[33]根据会话中项目向量的余弦相似度做出相应的推荐.该算法中引入正则化以解决推荐长尾问题.
GRU4REC[34]利用基于排序损失的门控循环单元(gated recurrent unit,GRU)建模用户行为序列用于序列推荐,是经典的基于RNN的序列推荐模型之一.
NARM[35]将注意力与RNN结合,建模用户的主要意图和顺序行为,是对GRU4REC的一种改进.
STAMP[36]利用注意力层来代替以往工作中所有的RNN编码项目表示,完全依靠当前会话中最后一项的自注意力来捕捉用户的短期兴趣.
SR-GNN[6]利用GGNN来获取项目表示,通过计算与最后一个项目的自注意力来获取会话嵌入表示,是本文模型的重点参考之一.
CoNet[37]利用基础协同过滤模型从每个域中分别提取用户和项目的特征表示,再利用十字交叉网络实现域间用户偏好的双向迁移.
CDIE-C[38]基于共聚类的异构跨域项目表示学习方法.通过共聚类提取跨域项目的聚类级项目表示,联合单领域会话和跨域会话学习项目的跨域综合表示,可用于解决用户不重叠时的跨域推荐问题.
CDHRM[15]利用2个并行的RNN挖掘用户跨域行为中项目的关联性,实现跨域序列推荐.该算法同时考虑了用户的当前兴趣偏好和用户全局兴趣偏好,解决部分用户重叠情况下存在用户跨域行为交互过程的异步迁移问题.
π-Net[11]通过并行的GRU单元分别循环提取并跨域共享来自不同领域中的有用信息,解决共享账户的跨域序列推荐问题.
MIFN[13]将知识图谱作为跨域序列推荐中的域间信息迁移的桥梁,是本文重点参考的模型之一.
4.2 模型性能对比实验结果与分析
表2和表3分别为TRaGCF同所选择对比模型在Movie-Book和Food-kitchen数据集上的实验结果.在单域推荐场景和跨域推荐场景下,序列推荐算法的整体性能好于非序列推荐,说明序列推荐在建模用户行为模式方面的有效性;在序列推荐场景下,跨域推荐的效果明显好于单域推荐的效果,说明跨域推荐用户模式的迁移有助于提升推荐性能,且对于数据稀疏性问题的解决有一定的效果.从总体结果上来看,k的取值与算法的性能成线性关系,这是由于序列推荐本质上是top-k推荐,即尽量使被正确推荐出来的k个项目在待推荐列表中排在尽量靠前的位置,当推荐的项目数越多,被正确推荐出来的项目的可能性越大.
在单域推荐场景下,基于传统的推荐算法效果相较于序列推荐效果更差,说明建模用户项目偏好时考虑时序模式有助于准确把握用户兴趣;同时,以Movie-Book数据集为例,SR-GNN的性能明显好于GRU4REC,表明利用GNN建模项目间的关联关系比RNN更有效,也说明挖掘项目间的高阶复杂转换关系有助于建模用户意图;STAMP和NARM的推荐效果好于GRU4REC,表明借助注意力机制有助于区分不同项目对用户偏好的贡献,有助于用户偏好的获取.在Food-Kitchen数据集中可以得到类似的结论.
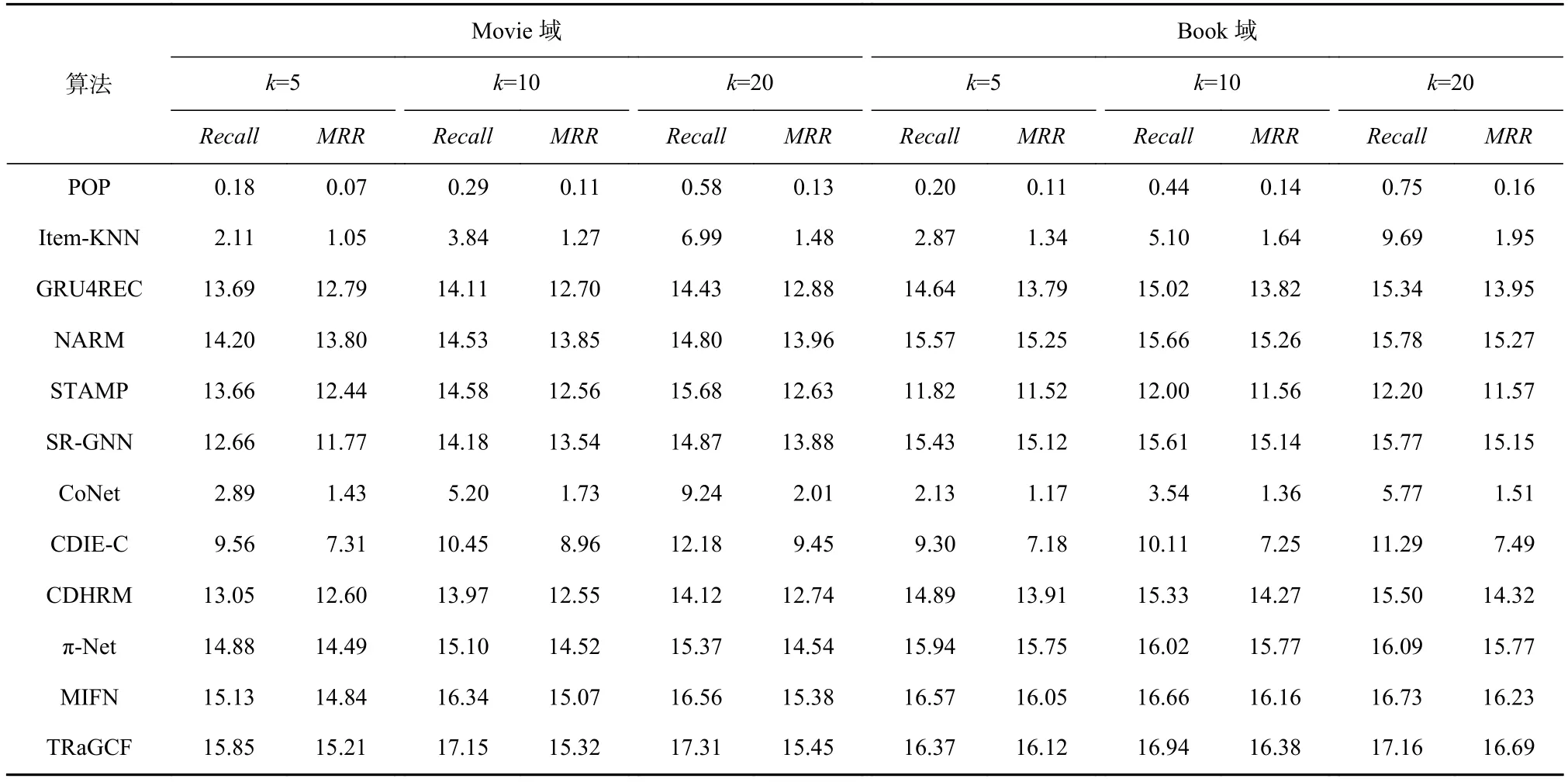
Table 2 Experimental Results on Amazon Movie-Book表2 在Amazon Movie-Book上的实验结果 %
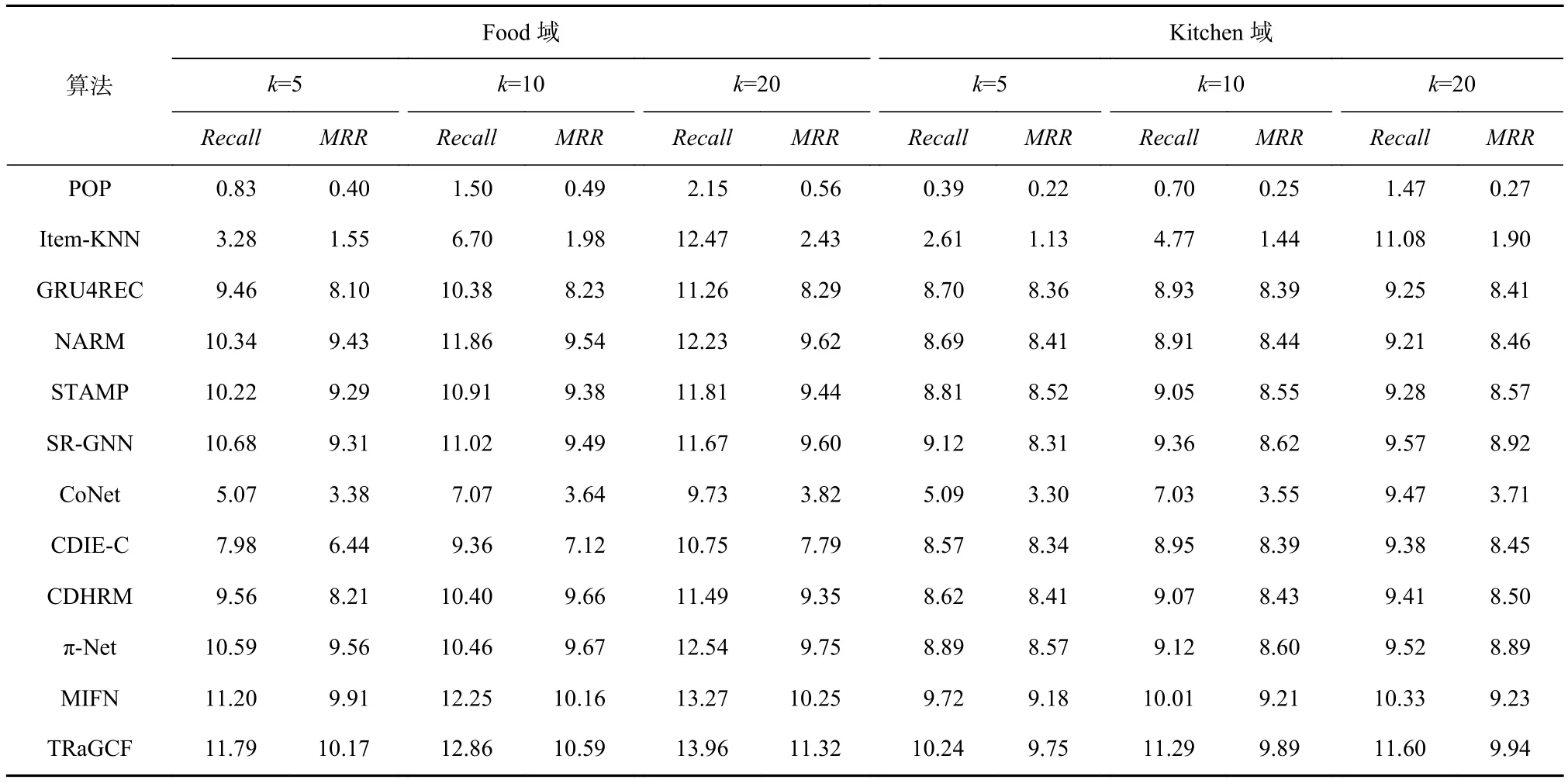
Table 3 Experimental Results on Amazon Food-Kitchen表3 在Amazon Food-Kitchen上的实验结果 %
在跨域推荐场景下,考虑利用用户行为序列建模用户兴趣偏好的算法性能明显好于简单的跨域推荐算法CoNet性能,说明用户行为序列中蕴含更多的用户偏好信息,也说明时序信息在促进用户兴趣挖掘方面的重要作用.而π-Net的推荐性能明显好于CDHRM,说明在跨域推荐中考虑用户的行为序列中的序列模型有助于其偏好的挖掘,但以域间重叠用户的兴趣偏好作为跨域迁移的桥梁,更有助于用户意图的把握.而MIFN的推荐效果在CDHRM和π-Net的基础上又有一定的提升,这表明考虑从不同领域中的用户行为序列中挖掘用户偏好同时适当地利用其他辅助信息(项目间的内在关联)可增加域间的关联,提升推荐效果.特别地,在Movie-Book数据集的提升效果更为明显,这是因为相较于Food-Kitchen数据集,电影和图书之间的内在关联更多,对推荐的指导性意义明显.
此外,TRaGCF在Movie-Book和Food-Kitchen数据集的性能相较于跨域序列推荐CDHRM,π-Net,MIFN都有提升.一方面说明GNN建模项目间的转换关系比RNN有效,这对建模用户的行为偏好有益,单域场景下有类似的作用;另一方面,除了从用户本身的历史行为挖掘其偏好,适当考虑其相同品味的用户的行为偏好对指导目标用户的推荐也有一定的促进作用,这是协同过滤思想的重要体现.在Movie-Book数据集上推荐性能的提高没有Food-Kitchen数据集明显,说明在该领域中有相似的用户与相同项目交互的可能性更大,因为该领域中项目间的分类明显,相同的项目关联性强,不同的项目间差异性大.然而,TRaGCF的性能相比MIFN提升不明显.由于TRaGCF中所有有用信息的提取均来源于用户−项目交互数据以及项目本身固有属性,而MIFN则是以引入外部知识图谱的形式建立起域间项目的关联,相较于TRaGCF引入更加丰富的外部数据.尽管如此,MIFN算法存在用户行为数据挖掘和利用不充分的问题,我们则充分考虑上述问题,通过引入图协同过滤以及2种图注意力机制来充分挖掘和利用有限的可用数据,解决因外部数据支撑不足而产生推荐效果不佳的问题.
4.3 TRaGCF中各模块性能的消融实验与分析
为进一步验证模型不同模块的功能,设计消融实验:在Food-Kitchen数据集实验中,以Recall@20和MRR@20作为评价指标,实验结果如表4所示:
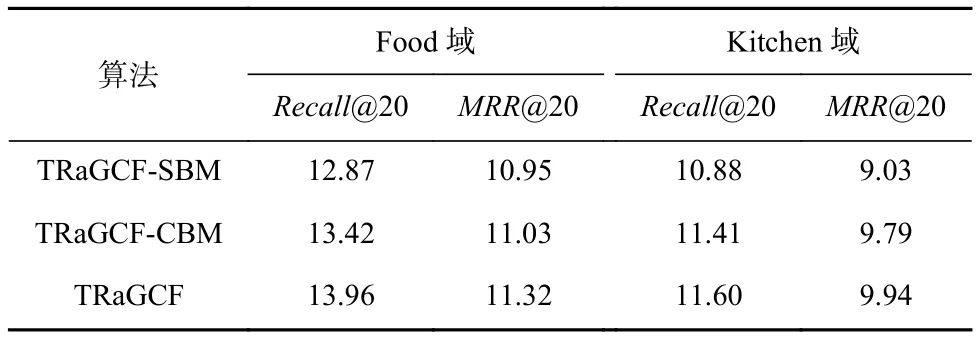
Table 4 Comparison Results of the Contributions of Different Modules of TRaGCF表4 TRaGCF各功能模块贡献对比结果 %
1)TRaGCF-SBM.去掉原模型中项目的序列级嵌入表示学习模块,最后的推荐预测模块直接将用户的协同偏好表示和项目的协同表示执行点积运算.
2)TRaGCF-CBM.去掉原模型的项目和用户协同表示的关系感知注意力机制后得到.
从表4中可看出,TRaGCF-SBM在2个域的推荐数据集上的性能都是最差的,这说明无论是Food域还是Kitchen域的推荐,从用户历史行为序列中挖掘项目间的序列依赖模式对提升跨域推荐效果的贡献更大,也侧面证明了提出跨域序列推荐算法的必要性;同时,Food域推荐的性能变化量相对于Kitchen域的性能变化量更大,这是由于Food域中食品间的关联关系更为密切,充分挖掘各项目间复杂的关联关系对提升推荐效果是有益的;而Kitchen域中不同的项目间的关联关系对推荐的结果影响相对较弱,因为用户通常会按需购买家用电器,并不会受到相同用户行为的影响.TRaGCF-CBM的性能变化不是十分明显,但确实对推荐效果有一定的影响,且在Food域的推荐效果的变化相对于Kitchen域来说稍显明显,可能是在Food域用户和项目间的特征关系相对复杂一些,此时区分用户和项目间的不同关联关系的效果明显一些,由此说明了在关联关系较为复杂的场景下,区分不同关系对推荐结果的影响十分必要.
4.4 TRaGCF算法超参数敏感性实验与分析
在用户特征偏好双向迁移模块,通过调整 λA和λB的取值情况控制不同域中、域间特有信息的保留比例.为简化实验流程,每次只考虑单个超参数的影响,即λ=λA=λB,设定其取值范围为[0.5,1],每次增加的步长为0.1.图5为实验结果,图5(a)(b)是在Movie-Book数据集上的实验结果,图5(c)(d)是在Food-Kitchen数据集上的实验结果.可以看出,在Movie-Book数据集上 λ=0.6, λ=0.7时取得最好的结果,在Food-Kitchen数据集上 λ=0.8时效果最优.实验结果说明,在用户偏好迁移过程中保留域内特有偏好的必要性,且在不同的场景下用户域内特有偏好的保留比例是不同的.
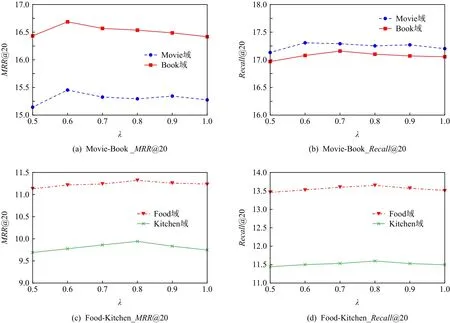
Fig.5 The impact ofλon the performance of the model图5 λ对模型性能的影响
5 总 结
本文研究基于图协同过滤跨域序列推荐问题,提出了一种新的基于时间和关系感知的图协同过滤跨域序列推荐算法TRaGCF,通过挖掘用户的高阶行为模式来解决推荐过程数据稀疏性问题.具体来说,将图协同过滤引入到序列推荐中,建立用户偏好在跨域双向迁移过程中的桥梁,从而缓解数据稀疏对推荐结果的影响;分别提出时间感知图注意力和关系感知图注意力建模用户历史行为序列中项目间深层高阶复杂的关联关系,挖掘用户的高阶行为模式,预测用户当前的意图并为其推荐合适的项目.在2个跨域序列数据集上验证模型的有效性,同时验证跨域迁移过程中保留用于域间特有偏好的必要性.TRaGCF算法虽然取得了较好的结果,但仍具有一定的局限性.如本文算法中仅建模成对项目间的关联关系,现实情况下用户的意图可能受到之前几个连续交互项目的共同影响,此时,项目间的更为复杂的关系没有被充分挖掘.此外,本文算法中假设2个领域的用户完全重叠,下一步将考虑将算法模型推广至用户只有部分重叠的场景中.
作者贡献声明:任豪提出了算法思路和实验方案,并完成了相关实验、实验结果分析及论文撰写;刘柏嵩对算法框架以及实验方案提出指导意见并参与论文修改;孙金杨协助任豪对本文实验方案提出改进意见,并对算法进行针对性优化提升;董倩负责对实验结果分类整理,并协助任豪完善实验结果分析;钱江波提出部分指导意见并修改论文.
