基于Bi-LSTM+CRF模型的航母情报实体识别方法应用
2023-01-30许山山史涯晴
许山山,史涯晴
(陆军工程大学指挥控制工程学院,江苏 南京 210007)
0 引言
互联网快速发展,信息量剧增,开源情报分析面临巨大挑战和困难。自然语言处理的基础任务之一是命名实体识别NER(Named Entity Recognition),从航母编队信息中识别实体是基础环节,也是较难的环节。首先,航母情报信息的结构化数据不多,来自百科和新闻网站的半结构化、非结构化数据不能直接利用;其次,航母编队可利用的已标注的数据集几乎没有。另外,航母编队信息中包含军事领域的专业名词和表述,如舰艇领导者信息、舰艇指挥机构信息、航母战斗群的任务记录、航母舰载机信息等,直接将通用领域实体识别方法应用到舰船情报分析领域效果不佳。为了解决上述问题,本文构建了航母编队实体识别语料库,采用基于Bi-LSTM+CRF 实体识别算法,实现航母编队情报信息的实体识别,辅助情报分析人员进一步挖掘和分析相关情报信息奠定基础。
1 航母信息实体识别
命名实体的研究主要分为三大类。①基于词典和规则的方法[1]。如果获取的样本数据较少,利用这种方法能够提高精度和执行效率,但是该方法过度依赖词典规模及词典覆盖率,同时需要耗费巨大时间和精力生成规则[2]。②基于机器学习算法的方法[3-4]。常用的算法模型有条件随机场CRF(Conditional Random Field)和支持向量机SVM(Support Vector Machine)等。③基于深度学习策略的方法[5-6]。通过大量数据支持,利用神经网络训练,生成基于向量嵌入的特征表示,进而实现特定领域的实体识别。
1.1 模型框架
Bi-LSTM+CRF 模型方法综合应用特征模板和神经网络,其中,Bi-LSTM 是常见的的循环神经网络,能够解决中文“词”在中文句子中的远距离依赖问题;CRF(Conditional Random Field)是指条件随机场模型,是一种鉴别式机率模型,可以利用之前标注过的标签。该模型由三部分组成:输入层、编码层和预测层[7],如图1所示。输入层作用是对中文字符或词语进行编码,将文本向量化表示。编码层作用是提取文本序列的抽象特征,尤其是字符或词语的上下文联系。双向LSTM 包括前向LSTM 和反向LSTM,比单向LSTM 挖掘文本序列的整体隐含特征更加全面。预测层作用是处理编码层的输出,结合上下文向量的特征,输出最终识别结果。
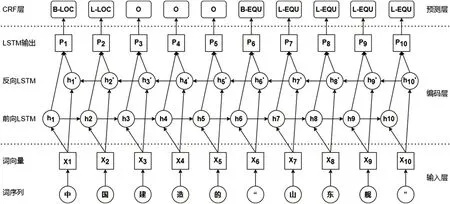
图1 Bi-LSTM+CRF模型
1.2 Bi-LSTM结构
LSTM 是一种基于RNN 的被广泛使用模型,可以有效地解决顺序标记问题[8]。LSTM 网络引入门的策略解决反向传播过程中的梯度消失等问题。图2 是Bi-LSTM 的细胞单元结构示意图[7]。在时刻t,xt是输入向量,它是一个输入字符的嵌入,ht-1是前一时刻的隐藏状态,神经元权重W和偏差b是可训练参数,Γf、Γu、Γo分别表示t时刻的遗忘门、记忆门、输出门。表示t时刻的单元状态、其中σ(x)=、tanh=。LSTM 细胞单元计算存储单元Ct和ht的过程如下:遗忘门决定应该丢弃多少先前的信息,0 表示全部丢弃,1 表示全部保留;记忆门决定应该向单元存储器中添加多少信息,使用tanh函数可以更新临时单元的状态信息;t时刻的每个隐藏状态Ct和ht都由输出门决定。图2中每个门结构的作用及数学表达式如表1所示。
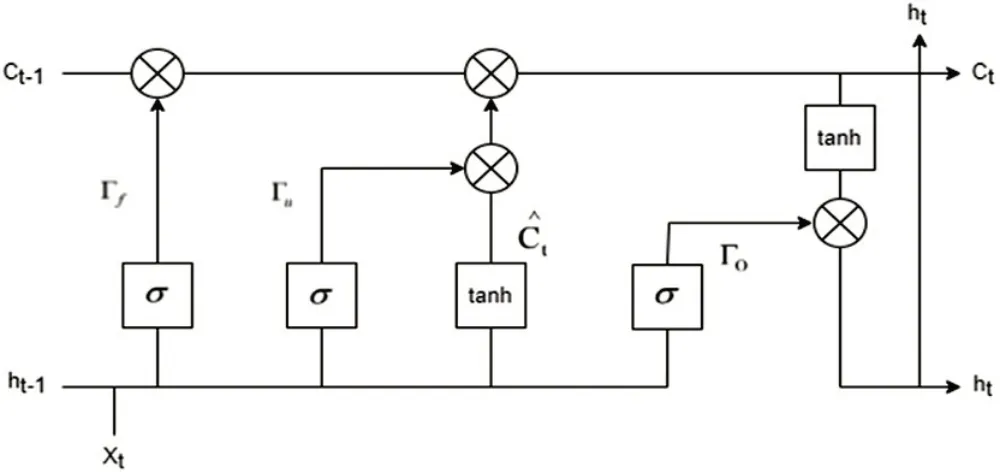
图2 Bi-LSTM细胞单元结构

表1 Bi-LSTM细胞单元结构数学表达式及门结构功能
1.3 CRF结构
由于不同文本属于各个标签结果的概率值计算相互独立,CRF 解决局部标签和上下文信息不会被归一化函数计算的问题,通过融合相关标签数据,将附近标签的相关性纳入计算范围,实现较为准确的标注。
CRF 可以看作是一个线性链,给定一个词序列,如下:

CRF 标记在w中的每个符号,并输出相应的标记序列,如下:

定义一组K 个特征函数f(ti-1,ti,w,i),K 是特征函数的个数,如下:

i 是一个符号在句子w中的位置,yi是当前符号的标签,yi-1是前一个符号的标签,如果满足特征函数的条件,则输出为1,否则为0。利用特征函数对候选序列进行评分,最终得分是所有特征函数给出的得分之和:
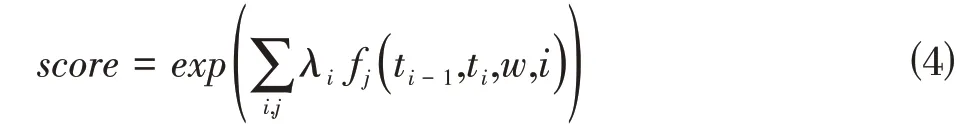
根据得分,选择最可能的序列作为输出序列,即最大概率序列。借助于归一化因子Z,获得每个候选序列的概率。因此,条件概率P(t|w)计算如下:

通过学习,获得最佳的权重λ,得到最佳的CRF,而CRF作为模型的输出层,生成文本的序列标注结果。
2 实验数据
2.1 数据集
针对航母实体识别分析研究,本文使用的航母编队的专项领域BIO 标注集的原始数据来自百度百科[9],军事特定领域文本标注数据集中命名实体的类型共有四种:人名PER(Person)、地名LOC(Location)、机构名ORG(Organization)和装备EQU(Equipment),非命名实体组成部分记为O。利用BIO 三元集的标注方法进行标注,B-PER:人名(开头),I-PER:人名(非开头),B-LOC:地点(开头),I-LOC地点(非开头),BORG:组织机构(开头),I-ORG:组织机构(非开头),B-EQU:装备(开头),I-EQU:装备(非开头)。本文通过改造通用领域BIO 标注集,构建的航母编队专项领域BIO 标注集的数据规模,通用领域Train_data 数据集2220533 字符,Test_data 数据集177231 字符,航母编队专项领域数据集Train_data 和Test_data 数据集108969字符。
2.2 实验评价标注与参数设置
对于航母实体识别模型的识别效果,本文采用命名实体识别的通用测试指标正确率、召回率和F1值,定义如下:

Bi-LSTM+CRF训练模型的重要参数,如表2所示。

表2 训练模型重要参数表
3 实验
3.1 实验设计
为了验证Bi-LSTM-CRF 方法对航母信息实体的识别能力,本文进行两类实验:实验类型Ⅰ:Bi-LSTM+CRF 识别效果检测;实验类型Ⅱ:通用数据集和专用数据集实体识别对比。
3.2 实验结果分析
3.2.1 实验一:Bi-LSTM-CRF识别效果检测
图3所示为模型训练的总体情况,图4至图7分别所示EQU、LOC、ORG 及PER 四个类别的实体识别正确率(precision)、召回率(recall)和F1 值随迭代次数(epoch)变化的曲线。根据曲线图可以看出,在经过32 轮(epoch)迭代之后,正确率(precision)、召回率(recall)和F1 值都相对稳定在90%左右。对武器装备类(EQU)实体的识别效果最好,达到95%以上;对人名(PER)实体的识别效果最差,仅85%左右。
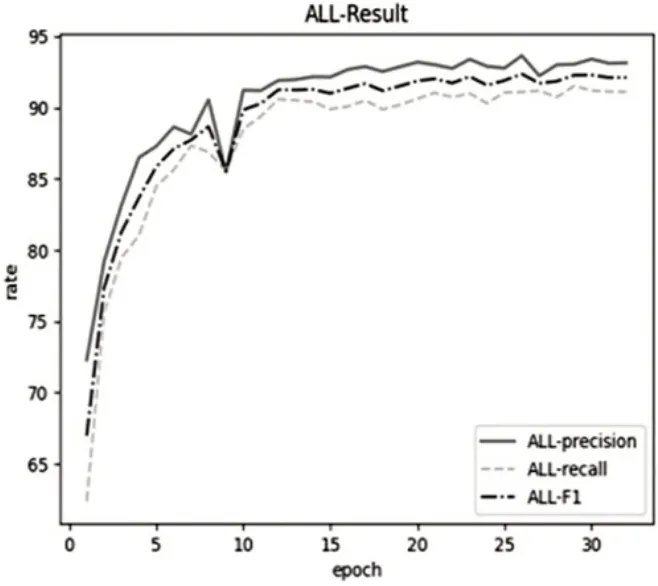
图3 ALL结果图
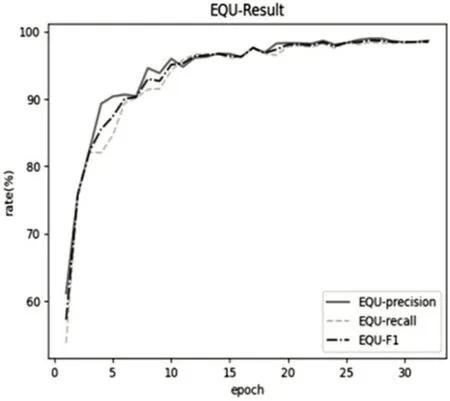
图4 EQU结果

图5 LOC结果
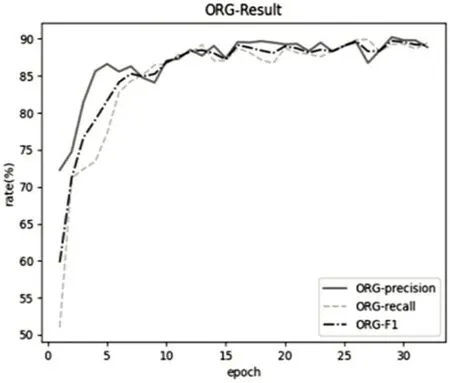
图6 ORG结果
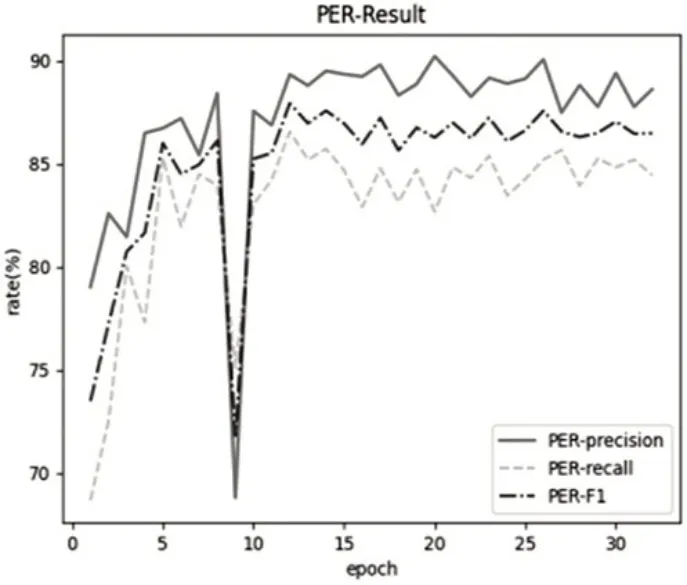
图7 PER结果
3.2.2 实验二:通用数据集和专用数据集实体识别对比
为了验证Bi-LSTM+CRF 模型对航母情报的实体识别效果,本文训练了两个Bi-LSTM+CRF 模型。模型Ⅰ的训练数据为通用领域的BIO 标注集,在此基础上通过改造,形成模型Ⅱ的通用领域的BIO 标注集+航母编队的专项领域BIO标注集。这两个模型识别出的实体数和识别正确的实体数,模型Ⅰ标注实体总数9977,返回实体总数9879,识别正确总数6665,模型Ⅱ标注实体总数9977,返回实体总数9760,识别正确总数9090。这两个模型对于总体和分类别的实体识别正确率(precision)、召回率(recall)、F1 值和返回的实体数(found)的结果如表3所示。

表3 不同模型针对不同类别实体识别结果
通过表3 中数据对比,可得出以下结论:①在模型Ⅱ中,非实体被识别为实体和实体名称识别不全的数量比模型Ⅰ有所减少;②在模型Ⅱ中,将实体类别识别错误的数量比模型Ⅰ少;③在模型Ⅱ中,没有识别出B 标签的情况比模型Ⅰ少;④在模型Ⅱ中,正确识别的实体数目明显多于模型Ⅰ识别出的数目,特别是与航母密切相关的武器装备类(EQU)实体。综合以上实验分析和结论,Bi-LSTM+CRF 航母实体识别模型的性能达到了预期目标。
4 结束语
基于改造的BIO 标注集,构建了航母情报信息中文实体识别语料库,通过BI-LSTM+CRF 模型算法训练出航母实体识别模型,实现了对航母情报信息的有效实体识别。实验证明,Bi-LSTM+CRF 航母实体识别模型的性能可以达到预期目标,本研究有效提高了航母编队情报信息领域命名实体识别的效率和正确率。在未来的研究中,将考虑实体间的关系抽取,为进一步实现提高航母情报分析能力和效率奠定坚实基础。
