基于FastText和多尺度深层金字塔卷积神经网络的中文文本情感分类模型
2023-01-29何颖刚夏丽丽郑新旺
何颖刚,王 宇,夏丽丽,郭 静,郑新旺
(集美大学 诚毅学院,福建 厦门 361021)
情感分析是自然语言处理领域的热点研究方向之一,具有广泛的应用价值.例如电商在线购物平台从商品评论信息中分析和挖掘用户的喜好和情感信息,对商业决策和营销策略具有重要参考价值.在舆情信息分析方面,通过对微博热点事件的观点进行情感倾向分析,有助于政府了解民意,及早发现舆情.情感分类是情感分析技术的核心,其任务是判断文本的情感取向,根据文本所表达的含义和情感信息将文本划分成积极、消极两种或多种类别[1].传统的文本情感分类模型常依赖于人工进行文本特征选择和模型参数调优,分类效果不佳.此外,为了提高分类效果,需要耗费大量人力预先采集和构建情感词典,并对情感词极性进行判断和量化.近年来,随着机器学习和深度学习在图像识别、语音识别、机器翻译等领域的巨大成功,卷积神经网络(CNN)、循环神经网络(RNN)和记忆神经网络等深度学习模型成为文本分析热点研究方向.层次更深的神经网络模型能带来较好的实验效果,但也存在模型过大、参数量多和训练速度慢等问题.
为提高文本情感分类的准确性,本文提出一种结合FastText 和多尺度深层金字塔卷积神经网络(deep pyramid convolutional neural networks,DPCNN)模型的中文短文本情感分析模型.模型通过Fast⁃Text 训练词向量从文本中学习语义信息,避免人工构建情感词词典的问题.同时,利用多尺寸过滤器对文本向量矩阵进行卷积运算,获得含有上下文关系的特征图,融合多个特征图后输入DPCNN模型,充分提取文本关键信息,取得类较好的分类效果.
1 相关工作
情感分析方法按照技术路线可以分为基于情感词典的情感分析方法、基于传统机器学习的情感分析方法和基于深度学习的情感分析方法[2].基于情感词典的情感分析方法需要通过人工构建情感词典,并根据情感极性进行线性加权的方式衡量和确定句子的情感倾向.周哲等[3]通过人工标注的方式构建情感词典,使用朴素贝叶斯分类器进行有监督学习电影评论情感分类;卢玲等[4]将情感词典与否定副词相结合,提取情感短语作为文本特征,通过卡方统计筛选特征后使用朴素贝叶斯分类器进行分类;孙向琨等[5]提出一种将歌曲的音乐内容和歌词特征结合进行歌曲情感分类的方法,通过歌词的词频-逆文档率(term frequency-inverse document frequency,TF-IDF)[6]进行情感计算,输入K近邻(K-nearest neighbor,KNN)算法进行分类,从而避免了耗费大量人工用于构建情感词典.
基于传统机器学习的情感分析方法常常需要通过大量有标注或无标注的语料使用统计学习方法,从语料中抽取文本特征进行情感分类.常见的机器学习方法有支持向量机(supported vector machine,SVM)、朴素贝叶斯(naive Bayesian)、K 均值聚类(K-means clustering,K-means)、K 近邻算法等.传统机器学习算法在抽取文本特征前,需要将文中的每个词根据词典转换为One-hot向量,缺点是词语编码维度是整个词典的大小,导致向量维度巨大和数据稀疏的问题,使得算法计算量增大.对此,许多学者尝试使用不同的文本特征表示方法进行情感分析.肖正等[7]提出一种结合潜在语义分析(latent sematic analy⁃sis,LSA)和SVM 的文本情感分类方法,利用SVM 构建基于TF-IDF 的文本向量空间,然后通过LSA 奇异值分解将文本向量空间映射到低维度的潜在语义空间中,解决数据稀疏问题,并提高了分类效率和准确率;邢玉娟等[8]提出基于信息增益(information gain)特征选择和SVM 的文本情感分类方法,通过计算文档词语TF-IDF 值,计算词语信息增益,选择出具有较高分类能力的文档特项后输入SVM 进行分类;李晓东等[9]运用TF-IDF 提取文本特证词,根据特征词属性依赖关系添加隐藏节点,输入朴素贝叶斯模型进行情感分类.
基于深度学习的典型方法有:卷积神经网络、递归神经网络、长短期记忆(long short-term memory,LSTM)神经网络等.冯多等[10]使用Word2Vec训练词向量,将微博文本转化为词向量后,输入卷积神经网络进行情感分类,通过引入词向量解决了传统分类方法无法利用词语语义、语序的问题,提高了分类准确率.LSTM 是一种可以在文本序列中学习到长距离依赖信息的特殊RNN,在语音识别、手写识别等方面取得了较好的效果.Chen等[11]探索了一种组合双向LSTM 和CNN 的网络模型,该模型对含有隐含语义的英文文本评论情感识别取得了不错的效果;郭庆等[12]利用LSTM 单元构建树状网络模型Tree-LSTM,结合自定义情感词典后进行情感分析,相比未使用情感词典的LSTM 模型,分类准确率有了进一步提高;Jiang 等[13]在LSTM 和CNN 模型基础上添加注意力机制,进一步提高了文本情感分类的效果.虽然LSTM 和CNN 两种模型均能提取语义信息,但LSTM 结构比较复杂,模型参数多,计算复杂度较高,训练时间长,对文本局部语义学习不足,而CNN对长文本序列不够敏感.
本文提出一种结合FastText 词向量和多尺度DPCNN 的中文短文本情感分类模型.通过FastText 将文本转换为词向量表示,避免了人工构建情感词典.同时通过多尺度DPCNN 更有效地从文本中学习远距离上下文信息和局部信息.
2 基于FastText和多尺度DPCNN模型
基于FastText和DPCNN 模型的整体结构如图1,由输入层、卷积层、DPCNN层和全连接输出层组成.
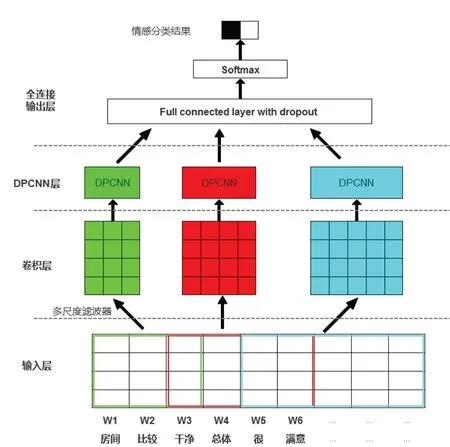
图1 基于FastText和DPCNN模型
2.1 输入层
将文本转换为高质量的向量表示是自然语言处理工作的首要步骤.模型输入层采用FastText 构建文本特征矩阵,FastText[14]是2016 年由FaceBook AI Research 提出的一个词向量训练与文本分类算法.词向量(word em⁃bedding)又称为词嵌入,2003 年由Bengio[15]等提出,是通过利用神经概率语言模型训练词的分布式表示,将词映射到一个低维、稠密的实数向量空间中的技术.通过计算词向量之间的距离,可表示词与词之间的语义相似度.
本文首先将文本进行数据清洗,利用Jieba 分词工具对文本进行分词和去除停用词处理.利用FastText 预训练词向量库,使用查字典方式,将文本单词转换为词向量表示,从而构建文本向量矩阵为

式中:X1:n为文本向量矩阵;xi表示文本中第i个词所对应的词向量,xi∈Rk,k为词向量维度;⊕表示向量拼接操作;n为文本统一长度,由于文本中的单词数量不同,通过补0 或截取的方式,将文本扩充成统一的长度n.
2.2 多尺度卷积层
为更好获得文本上下文关系,通过多个过滤器对文本向量矩阵X1:n进行卷积操作.定义过滤器W∈Rhk,h为卷积核宽度,即参与生成特征的单词数量,h可通过实验确定最优值.在图1中使用了宽度h分别为3、4、5 的三个过滤器用于从文本矩阵中提取特征c.当过滤器通过宽度为h的窗口与文本向量矩阵进行卷积运算后,获得文本特征ci为

式中:i=1,2,3,…,(n-h+1);“⋅”表示点积运算;Xi:(i+h-1)对应文本矩阵中的第i行到第(i+h-1)行的滑动窗口;b为偏置.将过滤器对整个文本矩阵进行逐窗口计算,获得文本特征图Ch为

2.3 DPCNN层
深层金字塔卷积神经网络[16]是2017 年由Johnson 和Zhang 提出的文本分类模型,模型结构如图2.模型底层Region embedding 使用词嵌入技术对文本区域(包含一个或多个词的片段)进行卷积操作后生成Embedding.使用多个堆叠卷积块提取文本特征,每个堆叠卷积块由两层卷积层、一个残差连接和下采样层构成,这种结构增大了模型感知长文本特征的能力,同时有效解决了深层神经网络梯度弥散的问题.同时,通过增加1∕2 池化,将文本序列的长度压缩成原来的一半,随着卷积块数量的增加,文本序列长度呈指数级减少.相较于其他深度神经网络模型,DPCNN 模型结构在不增加计算成本的基础上,加深了网络层级,有利于提高预测效果.
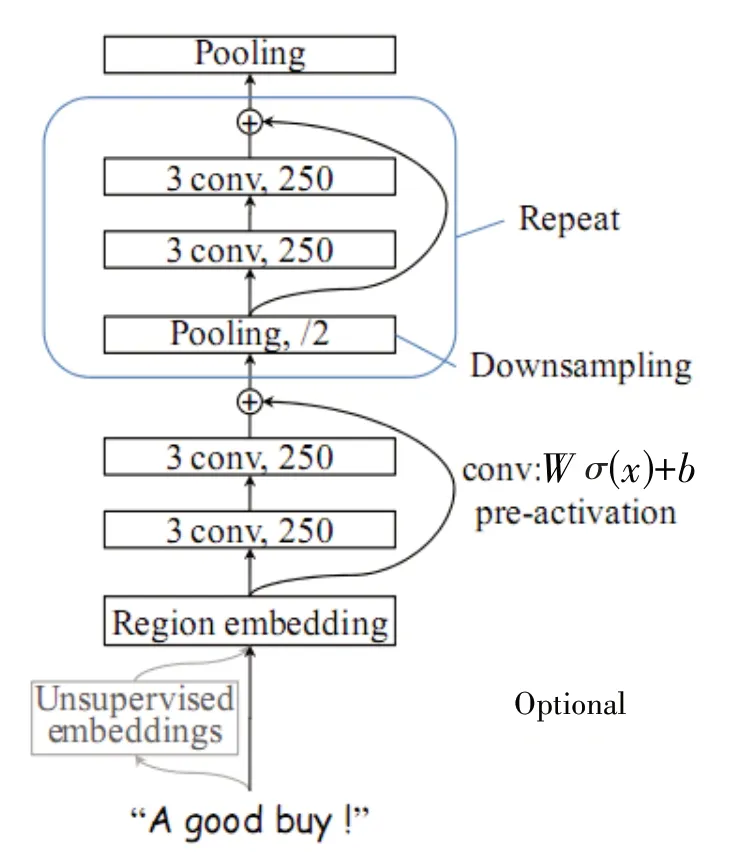
图2 DPCNN模型
本文采用DPCNN 模型从文本特征图中学习关键信息.将三个过滤器获得的文本特征图Ch,分别输入DPCNN模型,生成新的文本特征图Mh,即有
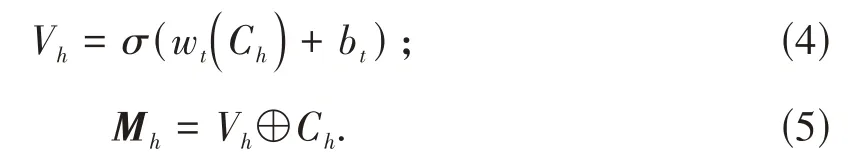
式中:Vh为DPCNN 中多个堆叠卷积块输出;σ为非线性激活函数;wt和bt为模型训练参数;⊕表示向量拼接操作;Mh为DPCNN模型输出.
2.4 全连接层文本分类
将三个DPCNN 模型结构得到的特征向量Mh进行拼接,并输入全连接层,通过非线性函数σ变换后送入soft max分类器,计算过程为
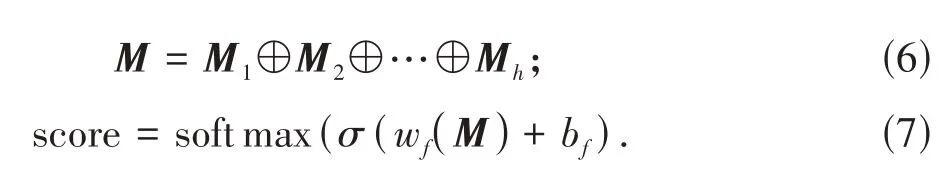
式中:σ表示sigmoid函数;wf,bf为随机初始化的参数;soft max分类器输出各个分类的概率score,通过判断概率大小获得文本对应的情感分类标签.
2.5 正则化
在模型训练过程中,为避免出现过拟合现象,使用Dropout 方法.Dropout 方法是目前能有效预防神经网络过拟合的方法之一,其原理是在训练迭代过程中,以设定的概率p随机删除神经元,用余下的神经元组成网络训练数据,从而提高模型的泛化能力.
3 实验结果与分析
3.1 实验平台和开发环境
实验环境为Windows10 操作系统,处理器为Intel Xen 4216,内存64 GB RAM,显卡Nvidia GeForce 3060.编程语言为Python 3.7,算法使用基于Tensorflow机器学习框架的Keras深度学习库开发实现.
3.2 数据集与预处理
实验语料来自于中文情感挖掘语料库(ChnSentiCorp),数据概况见表1.包含了酒店(hotel)评论、图书(Book)评论和笔记本电脑(NoteBook)评论三大类,合计18 000条评论数据,其中酒店评论来自于中科院谭松波老师收集整理的数据集ChnSentiCorp_htl_all.

表1 ChnSentiCorp语料数据概况
实验语料经过Jieba 工具分词、去除停用词处理、随机乱序后,以6∶2∶2 的比例划分为训练集、测试集和验证集,用于模型的训练和测试.
3.3 模型参数设置
FastText和多尺度DPCNN模型的参数设置见表2.

表2 模型参数设置
3.4 评价标准
实验采用准确率(accuracy)、精确率(precision)、召回率(recall)和F1值(F1-score)衡量句子相似度计算方法的性能.准确率用于表示正确分类为指定类别的文档数量与分类到了指定类别的全部文档数量的比值;召回率是指某个类集内同属于某类别文档的数量与文档集中属于该类别文档数量的比值;F1值是用来衡量分类模型精确度的一种指标,是准确率和召回率的调和均值.各指标定义:

式中:TP 为正确分类到正类的样本数;TN 为正确分类到负类的样本数;FP 为误分为正类的负样本数;FN为误分类到负类的正样本数.
3.5 实验对比与分析
为验证本文方法的有效性,选择3 种基于TF-IDF 构建文本特征的传统机器学习算法:KNN、SVM 和朴素贝叶斯.同时选择4种采用词向量构建文本特征的深度学习算法:CNN、CNN+BiLSTM、DPCNN 和单尺度DPCNN进行对比.
1)TF-IDF+KNN.将文本分词后,计算单词TF-IDF,转换文本为TF-IDF 表示的特征向量后,输入KNN分类器.
2)TF-IDF+SVM.将文本分词后,计算单词TF-IDF,转换文本为TF-IDF 表示的特征向量后,输入SVM分类器.
3)TF-IDF+NB.将文本分词后,计算单词TF-IDF,转换文本为TF-IDF 表示的特征向量后,输入朴素贝叶斯分类器.
4)FastText+CNN.参考文献[10]卷积神经模型结构进行设计,并将文献中Wrod2Vec 词向量替换为FastText预训练词向量,使用soft max函数对输出结果进行分类.
5)FastText+CNN+BiLSTM.参考文献[11]中的CNN+BiLSTM模型结构进行设计,替换文献中Word2Vec词向量为FastText预训练词向量,然后进行情感分析.
6)DPCNN.将文本分词后,不使用预训练词向量,而是使用动态随机初始化参数构建文本特征矩阵,然后输入DPCNN模型分类,模型在训练过程中自动学习词向量表示.
7)FastText+单尺度DPCNN.将文本分词后,使用FastText预训练词向量构建文本特征矩阵,然后利用宽度为3的卷积过滤器获取文本序列特征后,输入DPCNN模型.
8)FastText+多尺度DPCNN.本文所提方法,将文本分词后,使用FastText预训练词向量构建文本特征矩阵;然后,利用宽度为3、4、5的卷积过滤器分别获取文本序列特征,最后输入DPCNN模型学习和分类.
8组模型实验结果见表3.
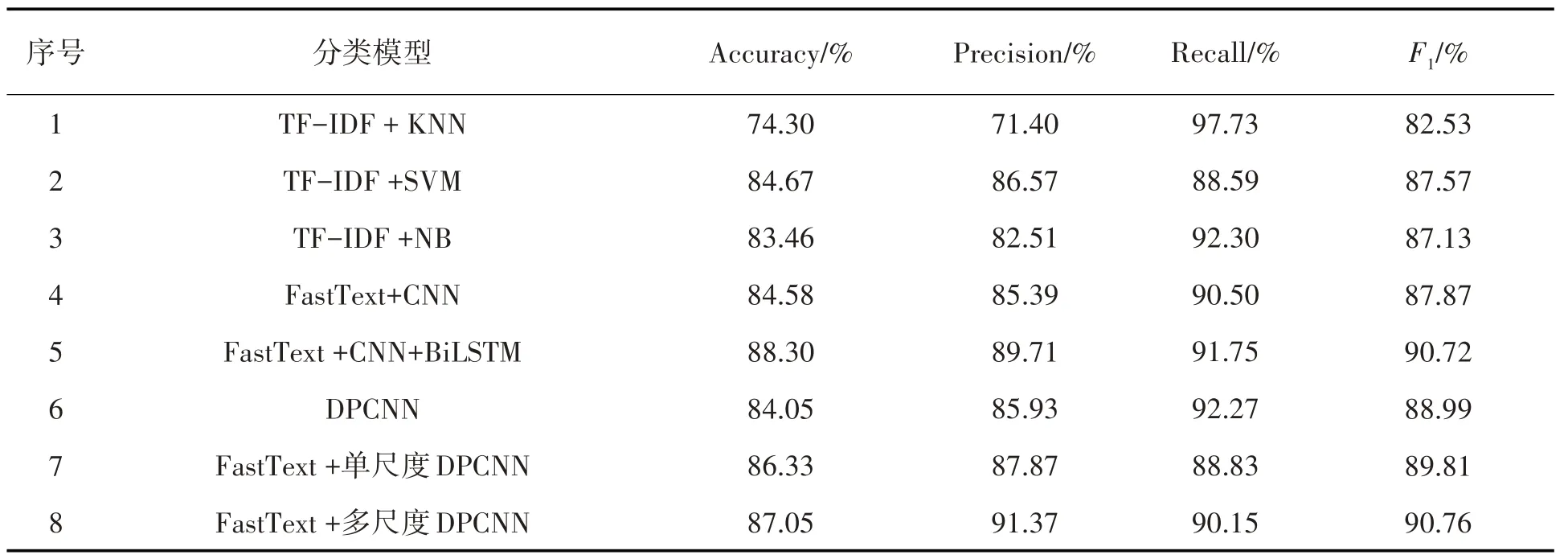
表3 文本情感分类结果
通过对比表3 实验结果可以看出,在情感分类任务中,本文所提出的FastText+多尺度DPCNN 的模型,获得了比传统方法KNN、SVM 和朴素贝叶斯更好的分类效果.从模型6 和模型7 的数据对比可以看出,使用了预训练词向量的DPCNN 模型,比没有使用词向量的DPCNN 模型,准确率提升了2.28%,精度提升了1.94%,说明在情感分析任务中,通过预训练词向量融合额外的语义特征信息,能够提升文本情感分类的准确度;比较模型4、模型5、模型7 和模型8 的实验结果可以看出,使用FastText+多尺度DPCNN 模型有较好的实验结果,证明了该模型处理中文文本情感分类问题具有可行性;对比模型7 和模型8 实验结果可以发现,在使用DPCNN 进行情感分析之前,使用多尺度过滤器能够从文本中学习到更多的高层次特征,帮助提升分类效果.
4 结语
情感分析是自然语言处理领域中的重要任务之一.本文针对中文评论文本,提出基于FastText词向量与多尺度DPCNN模型处理情感分类问题.该模型对比传统模型,在分类准确率、精确率以及算法的性能上有明显的提高,仿真实验结果验证了本文方法的有效性和可行性.未来工作中,将研究字向量与词向量相结合,采用注意力机制的方法在模型中应用,以期提高分类准确率.
