基于ArcGIS ModelBuilder 的多时相栅格数据处理方法
2023-01-24黄选威
◎ 黄选威
广西地图院,广西 南宁 530023
目前,多时相栅格数据已广泛应用于生态环境和气候变化领域。时间分辨率为小时或天的栅格数据往往需要处理成月均或年均栅格数据,才能实现进一步分析。对于跨度数十年的单时或日均数据,单项数据处理的工作量大、耗时多、效率低。此次研究笔者针对IMERG全球2001 年—2020 年约7 300 幅降水量单日NetCDF 文件展开数据研究,利用ArcGIS ModelBuilder 可视化编程开发语言进行集成开发处理,获取广西2001 年—2020 年月均降水量和年均降水量栅格数据集,从而实现快速获取降水量基础研究数据。
1 方法原理
NetCDF(Network Common Data Form)网络通用数据格式是一种面向数组型并适于网络共享数据的描述和编码标准[1]。在ArcGIS 中,可以通过NetCDF 文件创建TIF栅格数据集,用一个维度来显示所有栅格数据的单元值。对于具有相同属性的多个栅格数据,要合成一个更大时间分辨率的栅格数据集,通常采用镶嵌至新栅格的方法,求取单个栅格像元上的平均值来实现,公式可以表示为:

式(1)中,Vmean为更大时间分辨率栅格数据集的像元值;Vij表示第i行第j列的像元位置的数值;n表示镶嵌原始栅格的数量。
ArcGIS ModelBuilder 是一种可视化的编程语言,用于构建地理处理工作流。ArcGIS ModelBuilder 能够将一系列ArcToolbox 现有工具和ArcPy 语言通过输入输出的方式串联起来进行数据处理[2]。这种处理方式节省人机交互的中间过程,并且能够迭代具有相同属性样式的数据,实现数据的自动化或半自动化批量处理。赵强等人通过MATLAB 等程序语言进行NetCDF 数据的批量读写操作,但该读写方式设计需要在特定环境下进行,且MATLAB 可视化表达效果较为单一[3]。温树栋、昝建春等人基于ArcGIS ModelBuilder 单一计算和解析路径的方式来实现地理数据库按区域自动批量的裁剪输出,但输入输出位置是固定的,不具有迁移重复使用的灵活性[4-5]。
常用的ModelBuilder 由变量、工具和连接符组成(见图1)。
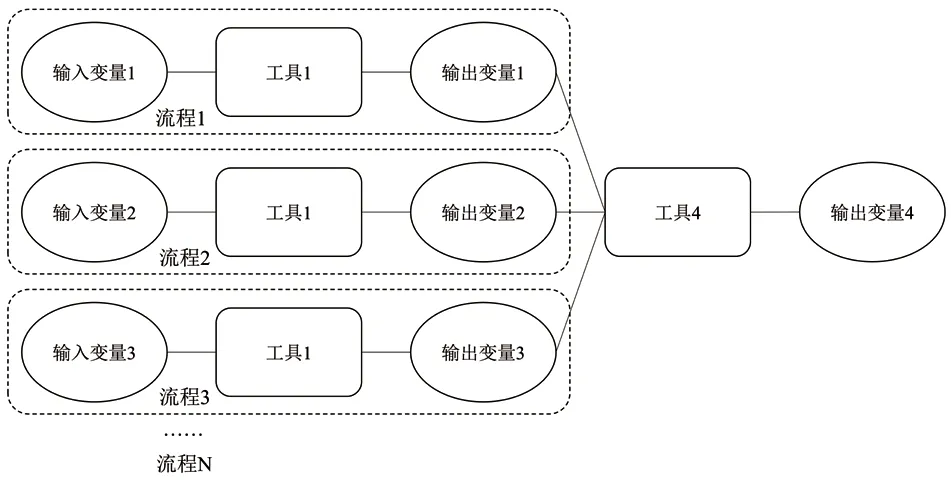
图1 ArcGIS ModelBuilder 工作流程示意图
常用的ArcGIS ModelBuilder 结构单元主要组成部分如表1 所示。

表1 ArcGIS ModelBuilder 结构单元主要组成部分表
2 实验数据与处理方法
2.1 数据来源
此次研究的数据源自2001 年1 月1 日至2020 年12 月31 日约7 300 幅全球降水量GPM IMERG 数据。通过访问美国NASA 地球科学数据和信息服务中心(Goddard Earth Sciences Data and InformationServices Center,GES DISC)的网站(https://disc.gsfc.nasa.gov)可以下载到数据格式为NetCDF 的全球日均降水量数据。该数据的空间分辨率为0.1°,单个NetCDF 数据大小约30 M。
2.2 处理方法
笔者针对数据量巨大的NetCDF 日均降水量数据,此次研究首先使用ArcGIS ModelBuilder中的栅格数据迭代器进行循环读取,获得的文件名通过ArcPy 中的截取函数截取特定字段,用于创建特定文件夹,使用工具将NetCDF 数据转换为TIF 数据,生成的TIF 文件放入特定文件夹中。然后,将单个文件夹内的数据以收集多值的方式作为单一数据整体输入,在迭代循环文件夹的基础上,迭代文件夹内部的TIF数据。最后,通过镶嵌至新栅格的方式生成某一时间段月均降水量或年均降水量栅格数据。数据处理过程如图2 所示。

图2 数据处理过程示意图
2.3 技术难点
(1)字段获取与匹配。获取的原始日均降水量数据的文件名称较长,如3B—DAY.MS.MRG.3IMERG.20200101—S000000—E235959.V06.nc4。此次研究通过ArcPy 中的ArcPy.Split()函数进行日期字符的获取,再利用获取的特定字段创建文件夹和TIF 数据文件名,通过“\%文件名%\%栅格数据%.tif”地址组合的方式进行数据特定文件夹下的自动保存。其中,“%文件名%”和“%栅格数据%”为自定义变量,通过连接的方式组合地址路径,便于灵活选择输出地址。
(2)循环迭代和嵌套。将NetCDF 文件转化为按月保存的TIF 文件,要先迭代文件夹内的日均栅格数据作为收集值整体输入,再迭代该文件夹进行多年数据处理,这里需要对文件夹和文件夹内的数据都进行迭代读取。由于ModelBuilder 同一模型下不能出现2 个或2 个以上的迭代器,因此需要把其中一个迭代模型作为新工具嵌入到另一个模型中进行2 次以上的迭代计算。这种模型嵌套的方式能够有效解决多个迭代器在同一个模型进程中共同计算的问题。
(3)多值合一输入输出。由于迭代器每次只能读取1 个数据,但计算数据平均值要读取多个数据,因此需要通过迭代的方式读取所有栅格数据,直到读完文件夹内所有数据为止,之后将其作为一个数据整体进行输入。这种方式可以避免迭代一个数据就进行镶嵌,或者迭代未完成就计算的问题。
(4)迁移重复使用。模型中的输入输出变量可分为带固定参数变量和不带参数变量2种。带参数的变量通过输入固定的路径、数据直接进行计算,每次计算都要重新设置新的参数,不利于迁移多次使用。对于不带参数的变量,将其设为空值,并作为开源变量,可以由使用者自行输入,进行参数调整。此次研究笔者将必要参数作为不带参数的变量,均做开放处理,便于计算模型重复使用和调整。图3 中的所有变量右上角带p 标志的均为不带参数的变量。
2.4 模型构建
以日均数据生成月均数据为例,模型设计主要包括按月创建文件夹、NetCDF 数据转换为TIF、按月镶嵌平均计算3 部分(见图3)。
(1)按月创建文件夹。考虑到原始数据的文件名读取、存储不方便,需要生成月份的文件夹来存储对应月份的单日数据。在图3(a)中,“原始数据文件夹”用于输入原始日均数据位置,“文件夹位置”用于输出生成月份文件夹的位置。此次研究笔者使用计算值工具,利用截取函数ArcPy.Split()按照关键字符位置进行读取月份如“202001”6 位,其他字符舍去,即可生成名称为“202001”的文件夹。
(2)NetCDF 数据转换为TIF。由于NetCDF数据格式不是GIS 常用数据类型,因此需要先进行数据转换。此次研究笔者通过ArcGIS 工具箱中的创建NetCDF 栅格图层、复制栅格、按掩膜裁剪的工具进行处理。将对应转换后的日均TIF 栅格数据存入到相应月份文件夹中。在图3(b)中,“文件夹”为原始数据位置;“通配符”和“文件扩展名”分别对应文件名的关键字和文件类型;NetCDF 数据的变量参数HQprecipitation、Lon、Lat 可以自行输入,也可以作为默认变量填入参数;“裁剪矢量数据”为进行掩膜裁剪的研究区范围;“输出文件位置”为月份文件夹所在的上一层文件夹。
(3)迭代按月镶嵌计算。将图3(b)过程生成的TIF 栅格数据作为一个整体输入,再进行镶嵌计算。需要注意的是,不能只把收集值作为一个简单的变量放入模型中,需要将其设置为带p 标志的参数变量,否则就会以下面这种方式进行计算:

式(2)显然与式(1)的计算结果不同,这不是此次研究需要的结果。
(4)迭代文件夹进行月均计算。将图3(c)的模型作为一个整体嵌套到图3(d)中,图3(c)是迭代循环月份文件夹中的日均TIF 栅格数据,图3(d)是迭代循环不同的文件夹,嵌套的方式可以进行多次循环。图3(d)中,“中间数据文件夹”为月份文件夹所在的上一层文件夹位置,“输出位置”为生成月均数据的存放位置。

图3 月均降水量数据批量处理模型图
3 分析讨论
批量处理模型设计完成之后,选取2020 年12 个月366 份的全年NetCDF 日均数据,分别通过常规人工方法和批量处理模型工具法进行处理,比较数据处理花费的时间(见图4)。

图4 常规人工方法和批量处理模型工具法耗时对比图
实验结果表明,将日均降水量数据处理成月均降水量栅格数据,批量处理模型工具法用时约为5 min/月,常规人工方法用时约为48 min/月,批量处理模型工具法在数据处理时间上较常规人工方法缩短8 了倍以上。由此可见,批量处理模型工具法能大幅提高多时相栅格数据处理的效率,能有效克服常规人工方法效率低、用时长、容易出错等问题,并且可以使用ArcGIS 中的地理处理结果,将其作为计算包整体运算,减少设置参数的时间。
与MATLAB 方法相比,此次研究不需要进行复杂的编程计算,使用模块化的封装工具即可实现搭积木式计算处理,并且ArcGIS 支持二次开发,可不依靠环境进行运行计算,对于零基础的使用者来说较为友好。通常情况下,在数据输入输出路径上,很多模型工具往往都是固定的,即输入数据的路径也是输出路径,不能自行设置,不具有灵活性。此次研究笔者将输入输出位置作为不带路径参数的变量开放出来,提供给使用者自行输入,大大增强了批量处理模型工具的迁徙性和提高了重复使用水平。同时,批量处理模型工具法不局限于单一的裁剪计算,而是把名称修改、数据转换、裁剪提取、加权计算、数据生成等栅格数据处理的常见流程进行综合设计,对于其他具有不同需求的栅格数据处理来说,具有很强的借鉴和指导意义。
4 结 语
此次研究中,笔者基于ArcGIS Model-Builder 可视化编程开发环境,集成ArcToolbox 现有工具和ArcPy 语言处理,开发实现多时相栅格数据批量处理模型工具。研究中,对于输入输出变量,采用空参数的形式,能满足和实现批量处理模型工具的可迁移性和重复使用。同时,使用ArcGIS 临时数据库ScratchGDB,避免了大量中间数据的出现,节省了内存。下一步,应对不常使用的输入输出变量直接填充相应参数,减少批量处理模型工具使用过程中变量交互的次数;扩展模型工具的数量和模块选项,使用者在做修改调整后,即可对其他相似类型的栅格数据进行批量处理。
