改进YOLOv5s算法在非机动车头盔佩戴检测中的应用
2023-01-21张瑞芳程小辉
张瑞芳,董 凤,程小辉
(桂林理工大学 a.机械与控制工程学院;b.信息科学与工程学院,广西 桂林 541000)
0 引言
随着我国城市汽车保有量不断攀升,城市交通道路环境日益严峻,特别是在欠发达地区,相较于通行受限的机动车,小巧轻便的电动车、摩托车等小型非机动车更受人们的青睐,尤其现阶段随着汽车燃油价格的上调,电动车已成为人们减负出行的重要代步工具。但此类车辆因体型较小,活动相对灵活,加之车体外部缺乏类似安全气囊之类的防护工具,在交通事故中致死率极高,属于交通道路环境中的弱势群体,导致骑乘人员死亡的直接原因大多是头部零防护式的撞击造成不可逆转的颅脑损伤。而正确佩戴头盔可以将头部损伤率减到69%[1],为骑乘人员生命安全提供了重要保障,但由于受到传统观念的影响、法律层面的约束缺乏、骑行舒适度降低等原因,骑行头盔佩戴率并不高。为了提高人们安全出行防患意识,减少交通事故的死亡率,公安部于2020年6月1日起推行“一盔一带”安全守护行动[2],对非机动车骑乘者佩戴安全头盔、机动车驾驶者佩戴安全带进行倡导。由此可见,为了推动智慧城市中交通监控的智能化,骑乘者佩戴骑行头盔的法治强制性是大势所趋。但由于欠发达地区城市基础设施不完善,经济技术落后等原因,多地交管部门仍采用人工巡查的方式对头盔佩戴情况进行督察,但面对复杂多变的交通道路环境,传统方式显然耗时耗力,无法有效推广。因此设计一种低成本、高性能的面向非机动车骑乘者的头盔佩戴检测模型是非常有现实意义的。
市面上骑行头盔形状各异、种类繁多,且尺寸变化大,头盔佩戴检测任务是一项不小的挑战。文献[3]针对乘客重叠、人头尺寸偏小等因素导致的两轮车漏检问题,通过修改候选框尺寸和特征融合方式加强了模型对小目标的灵敏度,并用柔软的非极大值抑制(soft-non maximum suppression,Soft-NMS)替换非极大值抑制(nonmaximum suppression,NMS)等策略对更快的基于区域的卷积神经网络(faster region based convolution neural network,Faster R-CNN)进行改进,缓解了二轮车乘客漏检问题。文献[4]在YOLOv3(you only look once version3)基础上,引入通道和空间注意力模块,用密集连接网络模块(denseblock)构建空间金字塔,显著提升了电动自行车头盔佩戴的检测精度; 文献[5]选用YOLOv5s模型为基础框架,为减少参数量,以GhostBottleneck模块取代卷积模块,并对特征提取网络进行优化,有效改善了密集场景下小目标的泛化能力;文献[6]在单一的多锚框检测器(single shot multi-box detector,SSD)算法的基础上引入多个注意力模块,采用Mosaic数据增强方式,并用余弦衰减学习率优化网络,显著提升了网络对摩托车驾驶人员头盔佩戴的检出率;文献[7]为了提高头盔检测器的准确率,设计了两个检测网络,首先使用YOLOv5检测车体,然后将其输出结果作为第二个头盔检测网络的输入,头盔检测网络加入了注意力,有效改善了头盔检测的性能。
以上基于深度学习的头盔检测模型虽在一定程度上提高了检测效果,但仍存有下列不足:
(Ⅰ)现有头盔检测模型大多只关注骑乘人员的头部区域,忽略了非机动车车体和骑乘人员的整体性,模型仅能学习到头部的局部特征信息,只对人头进行检测,会把区域内的非骑乘者划为待检目标,造成资源浪费,且有悖于头盔检测模型的设计初衷。
(Ⅱ)模型的泛化性和鲁棒性较弱。由于头盔检测的任务环境与检测目标均处于高速移动的运动状态,捕获到的头盔图像会存在一定的模糊感,同时由于目标对象距离拍摄点的远近不同,图像尺度存在显著变换的问题,会造成物体特征难以区分。在拥挤的交通场景中,目标重叠严重,而远距离的小目标在整个图像中占比面积小,存在感较弱,现有模型在上述场景中很难发挥作用,导致漏检。
(Ⅲ)模型特征融合性不足。随着网络层数的加深,头盔图像的底层纹理信息丢失严重,无法捕获关键位置信息会导致模型对头盔图像的相关特征学习不彻底,从而无法区分与安全头盔外形极其相似的其他帽子(类如草帽、鸭舌帽、遮阳帽等),造成误检。
(Ⅳ)公开数据集的缺乏也给非机动车头盔检测研究带来了一定限制。
为了解决以上问题,本文自建一套骑行头盔佩戴图像数据集Datasets-Helmets,提出一种基于YOLOv5s的非机动车安全头盔佩戴检测算法YOLOv5s-BC,重点研究如何提升网络的特征提取能力,加强网络对图像的特征信息的提取,以提升网络模型的检测精度,降低漏检率和误检率。
1 相关介绍
YOLOv5算法在YOLOv4[8]的基础上进行改进,YOLOv5系列共有4个不同的网络,分别是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。考虑到交通监控现场投放的大多是算力偏低的嵌入式设备和低分辨率摄像头,从项目落地的经济实用性出发,本文最终选用YOLOv5系列中模型最小的YOLOv5s网络作为非机动车安全头盔佩戴检测算法的基准网络。图1为YOLOv5s模型的结构图,主要由3部分组成:特征提取网络(即骨干网络)、特征融合网络(即颈部网络)和预测端。
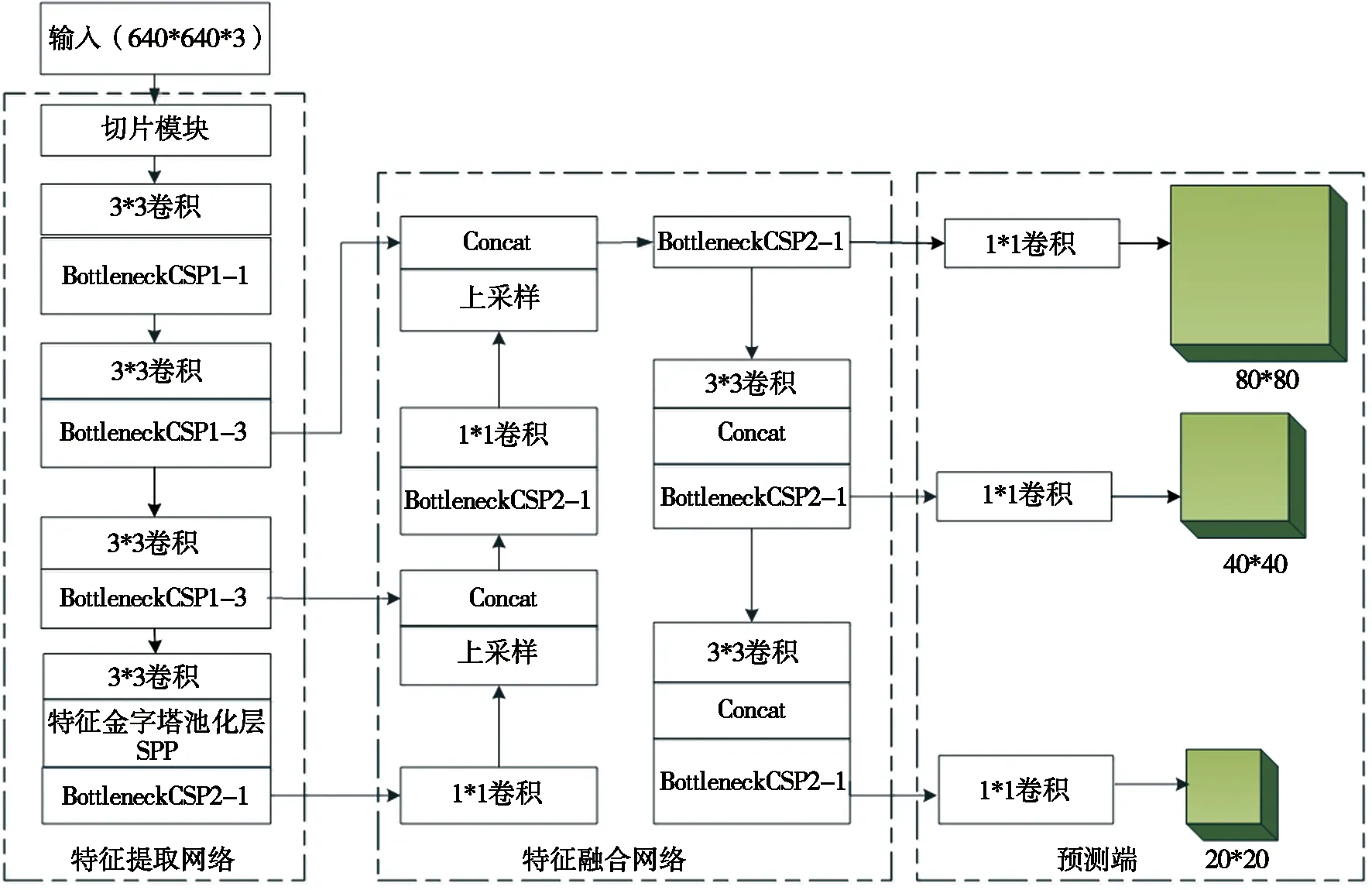
图1 YOLOv5s算法结构图
对于一个640 pixel*640pixel大小的输入特征图,在骨干网络依次经过切片模块(focus)、BottleneckCSP结构(cross stage partial)和空间金字塔池化结构(spatial pyramid pooling,SPP)[9]完成的8倍、16倍的32倍下采样操作,生成3个尺度为80 pixel*80 pixel、40 pixel*40 pixel、20 pixel*20 pixel的特征映射层;在进入到颈部网络后,经过一个自顶向下的特征金字塔网络结构(feature pyramid network,FPN)[10]网络和一个自底向上的路径聚合特征金字塔结构(path aggregation network,PAN)[11]将高层语义信息和底层位置信息进行聚合,得到3个融合后的有效特征输出层,并传入预测层;预测端3个检测层分别是80 pixel*80 pixel、40 pixel*40 pixel和20 pixel*20 pixel的特征图,分别对应小、中、大三种物体,检测层的每个网格会生成3个预测框,对应预测目标的置信度、类别和位置信息,最后由NMS将得分最高的预测目标框、预测类别、预测置信度输出,从而在头盔检测任务中完成整个检测流程。
由于头盔在整个图像中占比面积小,随着网络的逐渐加深,头盔图像关键信息有丢失的风险,所以加强头盔检测网络模型的特征提取能力和特征融合能力至关重要。本文重点围绕这一方面展开对基于YOLOv5s头盔佩戴检测算法的研究,并提出了非机动车头盔佩戴检测算法YOLOv5s-BC。针对头盔图像特征相似性高,最大池化会损失小尺度的头盔图像特征信息的问题,提出用SoftPool替代最大池化,保留更多的头盔图像细粒度特征信息,以缓解密集场景中小目标的漏检情况。针对原YOLOv5s在密集场景下,由于人和车遮挡严重而出现的漏检问题以及对与头盔相似度高的其他帽子的误检问题,提出一种嵌入坐标注意力机制的加权双向特征融合网络模块,跨阶段连接加强不同层级之间的联系,并提升底层网络的利用率,有效缓解密集场景下的漏检情况,并且将融合后的特征信息又嵌入了坐标位置信息,提高模型对头盔图像的方向感知灵敏度,帮助模型学习到头盔图像的关键特征信息,以正确区分安全头盔和其他帽子的不同,降低误检率。针对原YOLOv5s模型中使用的GIoU回归定位不准确的问题,提出用更高效的EIoU损失函数作为模型的定位损失,对非机动车车体、骑乘人员以及头盔精准定位。
2 改进的YOLOv5s-BC算法
2.1 SoftPool
在常见的深度学习算法改进方法中,鲜有改进池化层,但池化又是卷积神经网络中非常关键的组成部分:通过减少特征图尺寸以减少内存开销,从而支持模型创建更深层次的结构;不增加网络参数,可以缓解网络过拟合风险。而目前卷积神经网络大多依赖最大池化、平均池化或两种池化组合的形式,如原YOLOv5s算法模型中的SPP结构使用的是4个内核不同的最大池化过滤器,这种池化方式仅将内核中的局部最大值参与到后续的卷积映射中,以凸显图像中最显著的特征信息,而这极有可能丢失图像中重要的细节信息。相比之下,平均池化虽考虑了区域的所有特征,能保留更多背景信息,但取平均值后又弱化了明显的特征,降低了区域的目标特征强度[12]。而文献[13]提出软池化SoftPool方法,其核心思想是对感受野中的所有像素以加权求和的方式映射到下一层,保证较高激活比较低激活占据高主导位,是一种更加平衡的池化方法。
图2是SoftPool实现方式的示意图,以2 pixel*2 pixel大小的池化核为例,权重表达式如式(1)所示:
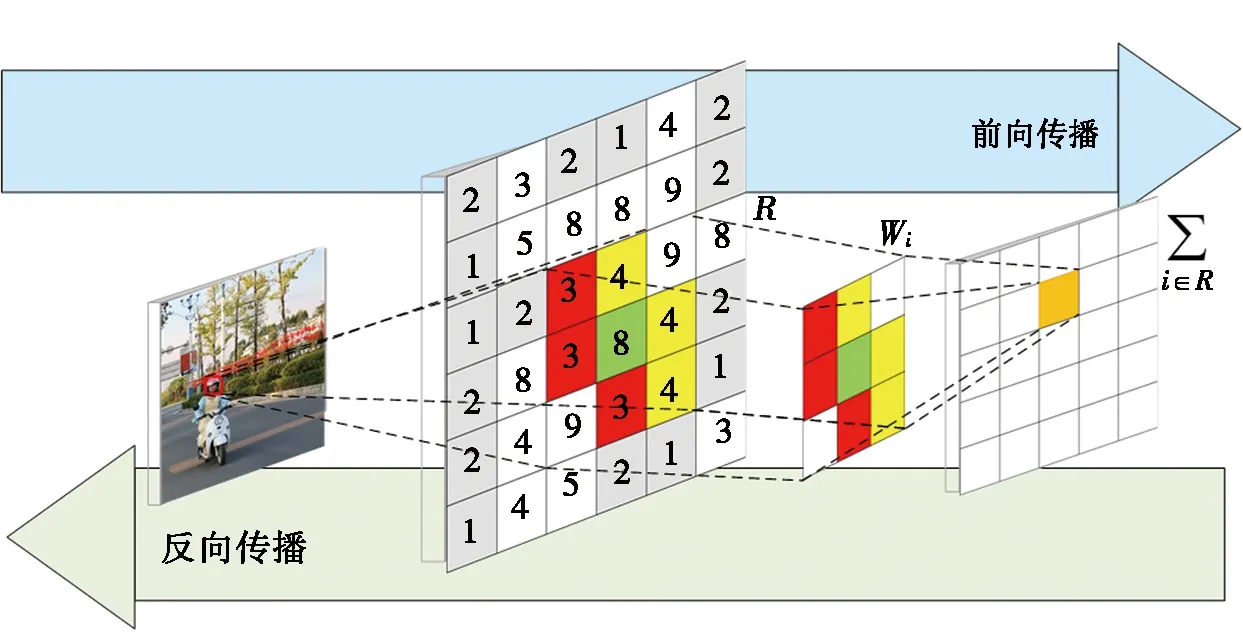
图2 SoftPool实现方式示意图
(1)
其中:R为区域内所有像素的集合;wi为感受野内每个像素的权重,以自然指数为基础,采用Softmax加权算子权衡激活效果,做非线性变换,经过Softmax函数得到的归一化结果和区域激活值成正比,即当前像素点的值越大,分配的权重越高,对结果的影响越大。将得到的权重wi和区域R内所有的激活加权求和,形成最终的池化输出,如式(2)所示:
(2)
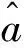
由式(2)可以看出,SoftPool是可微的,即在反向传播过程中可以不断更新梯度值,得以保证每个激活都至少会分配一个最小梯度,从而加快模型收敛速度,提高训练效果[14]。所以本文将原YOLOv5s算法中SPP结构中的4个最大池化均替换成SoftPool,改进后的Soft-SPP模块结构图如图3所示。由于SoftPool能有效平衡最大池化和平均池化的影响,并利用两者的有利属性,保留更多特征细粒度信息,增大邻域特征的区分度,改进后的Soft-SPP模块能最大程度的保留图像中的特征信息,在一定程度上可以提高模型的检测精度。
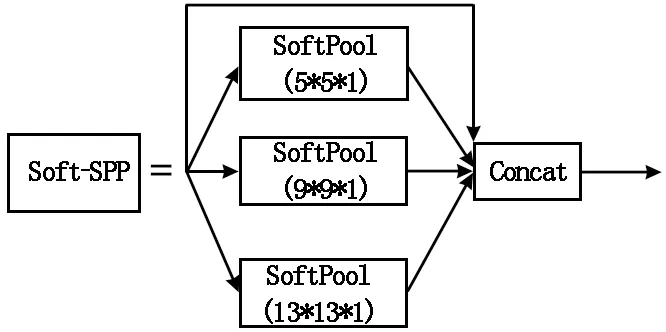
图3 改进后的Soft-SPP结构
2.2 融合注意力机制的加权双向特征聚合网络BiFPN-CA
2.2.1 双向加权特征金字塔结构BiFPN
在目标检测算法中,通常采用构建特征金字塔结构的形式来融合不同层级的语义信息,以缓解因网络层数不断加深产生的图像特征丢失问题。在YOLOv5s模型中使用的是一个自底向上的PAN网络结构,把来自不同路径且宽高尺寸相同的特征图在通道维度上进行简单相加,这种聚合网络结构默认所有输入特征对输出特征的贡献是一致,但谷歌团队认为不同分辨率的输入特征图对输出特征图的影响是不同的,为此提出一种双向加权特征金字塔网络结构(bidirectional feature pyramid network,BiFPN)[15],即在不同层级的网络进行堆叠融合时引入可学习权值,使网络不断调整权重以学习不同输入特征的重要性。图4a为BiFPN结构图。图4中,P3~P7是原网络模型的5个输入节点。
本文受文献[16]启发,将加权双向融合的思想运用到YOLOv5s模型中,并结合PAN网络结构做进一步的优化:减少BiFPN的输入节点个数以适应原模型的3个输入有效特征层;删除只有一个方向的输入节点,因其对网络的贡献较小;在同一尺度的输入节点到输出节点之间加一个跳跃连接,以实现最大程度的特征融合。由此提出简化版双向跨尺度特征融合金字塔网络结构,记作BiFPN-Short,图4b为BiFPN-Short的结构图。
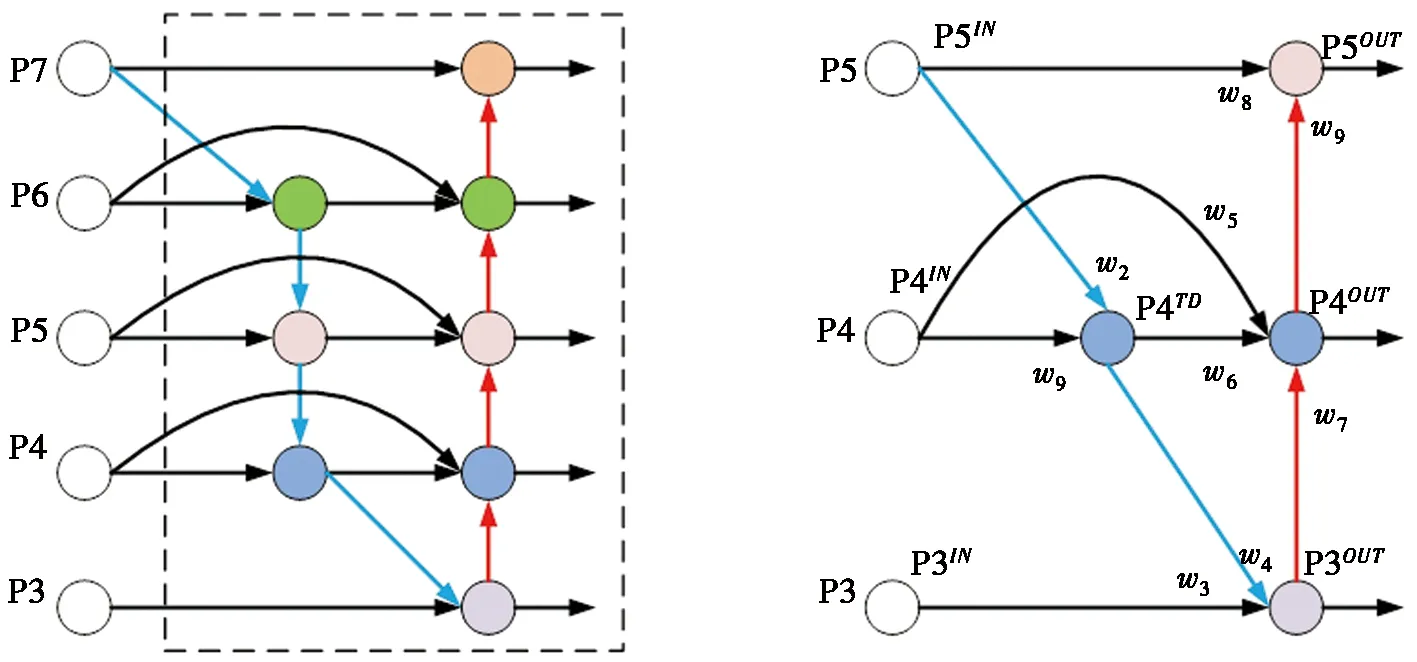
(a) BiFPN (b) BiFPN-Short
在BiFPN-Short结构中,P3~P5是3个输入节点,每个输出节点的数学表达式如式(3)~(6)所示:
(3)
(4)
(5)
(6)
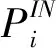
2.2.2 引入坐标注意力机制的BiFPN-Short
虽然BiFPN-Short特征融合网络以双向加权的形式聚合了不同层的语义信息,加强了深浅层网络的联系,但在头盔检测任务中,由于车体处于不断行驶的状态,目标离拍摄设备的距离不同,设备捕捉到的图像尺寸也大小不一;且当处于车流密度较大的交通道路场景中,目标之间相互遮挡,对于仅露出部分的头部或头盔,模型很难细致全面地学习到高质量的特征信息,从而导致漏检和误检。如何使模型在复杂背景下提高对目标方向感知和位置感知的敏感度,成为需要研究和解决的关键问题。
故考虑对BiFPN-Short网络结构做进一步的优化:即在原始特征融合网络的基础上,为3个加强输出特征层分别插入3个坐标注意力机制(coordinate attention,CA)[17],以实现对不同通道特征信息重要性的筛选。图5是坐标注意力机制结构图。坐标注意力机制是一种将坐标信息嵌入通道注意力的新型轻量级模块,基本思想是将通道注意力分解为两个并行的一维特征编码,分别沿着高度和宽度两个不同的空间方向聚合特征,可以更加关注目标,以增强复杂背景下网络的特征表达能力。
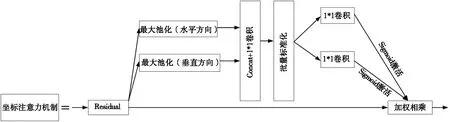
图5 坐标注意力机制结构图
CA模块将位置信息嵌入通道注意力中,主要分为2个步骤:坐标信息嵌入和坐标注意力生成。
第一步,将通道注意力分解为两个一维全局池化,分别沿着水平方向(宽度)和垂直方向(高度)对每个通道进行编码,表达式如式(7)所示:
(7)
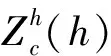
第二步,将2个方向上的特征图进行级联,之后经过1 pixel*1 pixel共享卷积模块和批量归一化操作得到变换特征图F1,以得到空间信息在水平(宽度W)和垂直方向(高度H)聚合之后的中间特征图f,其公式如下:
f=δ(F1([zh,zw])),
(8)
其中:f∈Rc/r×(H+W),r为下采样倍数;δ为非线性激活函数;F1为变换特征图;[,]为空间维度上的级联。
接着,将f分别沿着高度和宽度方向分割成2个独立张量fh∈Rc/r×H和fw∈Rc/r×W,再利用两个1 pixel*1 pixel卷积模块(Fh,Fw)将特征图fh和fw变换到和输入特征X相同的通道数,从而得到两个方向上的注意力权重gh和gw,如式(9)所示:
gh=σ(Fh(fh));gw=σ(Fw(fw)),
(9)
其中,σ为Sigmoid激活函数。
最后和原输入特征图进行乘法加权计算,得到在宽度和高度上分别融合了坐标信息的注意力权重的输出,其表达式如式(10)所示:
(10)
在BiFPN-Short的3个输出节点上分别加入CA模块,这样BiFPN-Short融合了包含位置坐标间的关联信息,模型会对方向特征和位置特征更加关注,将该模块命名为BiFPN-CA。图6为BiFPN-CA网络模块结构示意图,C1~C3是骨干网络输出的3个有效特征图,此时作为特征聚合网络的3个有效输入层,P1~P3是经过BiFPN-Short模块的3个输出特征图。
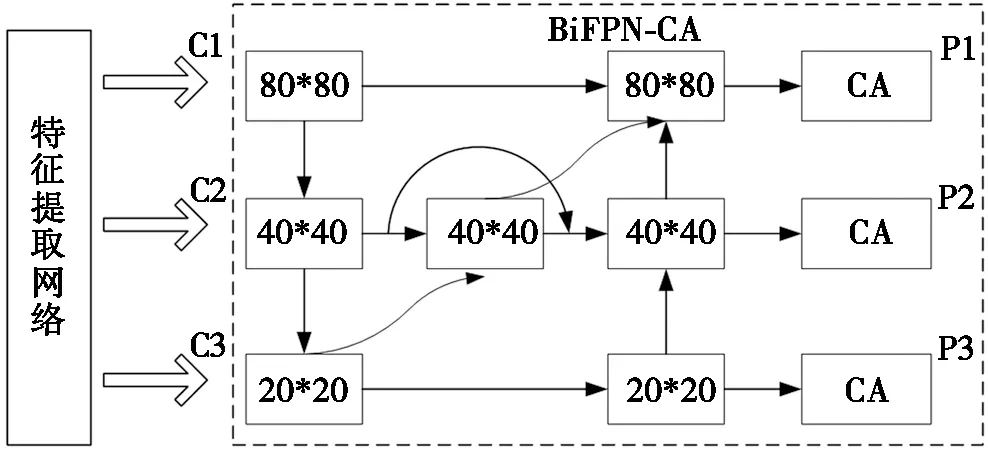
图6 BiFPN-CA的结构示意图
相较于原PAN特征聚合网络模块,BiFPN-CA在PAN基础上为每条路径均引入了可学习参数,改善原网络中不同输入特征平等贡献的问题;加入跳跃连接,聚合不同分辨率的特征,以丰富特征语义表达,实现多尺度特征融合;嵌入的坐标注意力机制在不增加计算开销的同时,可以更加关注目标,增强复杂背景下的特征表达能力。最后将改进后的BiFPN-CA特征融合模块用于YOLOv5s头盔检测模型进行多尺度特征融合,成为连接主干网络和预测端强有力的纽带。
2.3 损失函数改进
一个优秀的回归损失函数应当考虑3个关键的几何因素:两框重叠面积、两框中心点距离、两框长宽比。原YOLOv5s算法使用的损失函数是GIoU-Loss[18],公式如式(11)所示:
(11)
其中:N为目标框与预测框的最小外接矩形;(A∪B)为两框的并集。GIoU强调两框重叠区域和非重叠区域,所以它缓解了IoU存在的无法优化两框不相交以及无法反映两框如何相交[19]的问题。
但GIoU并没有考虑两框的相对位置和长宽比,当预测框位于目标框的内部,即(A∪B)相同,两框最小外接矩形N也相同,此时GIoU退化成IoU。针对GIoU损失函数回归不准确问题,本文引入LEIoU(efficient intersection over union-loss,EIoU-Loss)[20],如公式(12)所示:
LEIoU=LIoU+Ldis+Lasp=
(12)
其中:LIoU为重叠面积损失;Ldis为中心距离损失;Lasp为宽高损失;ρ2(b,bgt)为两框中心点欧氏距离;c为最小外接矩形对角线长度;ρ2(w,wgt)和ρ2(h,hgt)分别为两框在宽度和高度上的欧氏距离;Cw和Ch分别为最小外接矩形真实宽度和高度。EIoU-Loss损失将两框纵横比拆成两框在宽度和高度上分别与最小外接矩形宽高的比值,从而使回归定位更精准。
3 实验平台与结果分析
3.1 数据集采集和标注
由于目前尚没有公开的非机动车头盔数据集,本文在桂林市凯风路非机动车车道实地拍摄了3 284张包含多种交通情景的头盔图像,部分数据集样本如图7所示。图7a~图7f分别表示不同拥堵情景、不同天气条件、不同光线条件、不同拍摄角度,佩戴不同帽子、不同车型等6种不同交通情景的非机动车头盔佩戴图像。

(a)不同拥挤情景 (b)不同天气条件 (c)不同光线条件 (d)不同拍摄角度 (e)佩戴其他帽子 (f)不同车型
将搜集到的头盔图像分类整理后,利用LambelImg软件对其进行人工标注,以生成包含目标类别和目标框坐标信息的XML格式的数据文件。根据非机动车头盔检测的任务设定,设置4种标签类别:“Motor”(非机动车车体)、“Helmet(戴有头盔)”、“Head(未戴头盔)”、“Non-helmet(佩戴其他帽子)”。为了使算法在车体和骑乘人员头部佩戴头盔的状态之间建立联系,在标注时,将2者视作1个整体,一同标记为“Motor”。最后将标记后的数据照片按8∶1∶1比例随机划分为训练集(2 627张)、验证集(328张)、测试集(328张)。在训练集中Motor、Helmet、Head、Non-helmet分别被标记8 598、6 255、6 107、5 772次。
3.2 实验环境
本实验以NVIDIA GeForce RTX 3060处理器为平台,CPU为Gen Intel(R)Core(TM)i7-11800H,操作系统为Windows10,内存32 GB,显存11 GB。Pytorch深度学习框架,CUNA 11.1版本,Pytorch 1.8.0版本,IDE环境为Pycharm 2021,编程语言为Python3.8.6,Anaconda 3作为包管理器。并使用随机梯度下降优化器(stochastic gradient descent,SGD)对网络参数进行更新优化。训练超参数设置如表1所示。
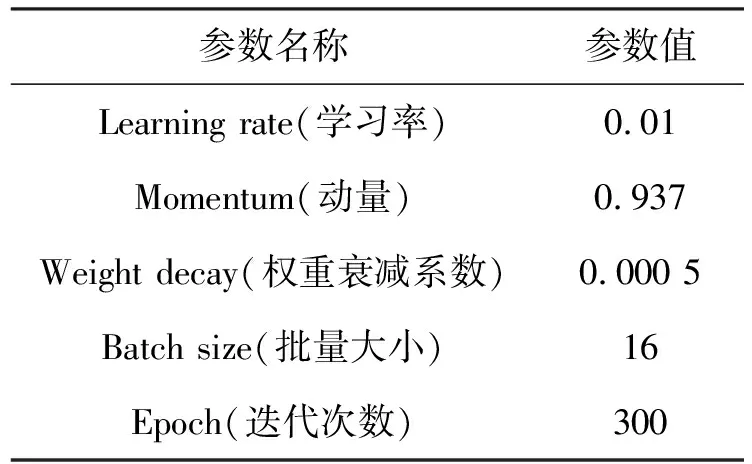
表1 训练超参数设置
3.3 评价指标
采用目标检测领域主流的评测指标定量评估算法性能:平均精度均值(mean average precision,mAP),计算如公式(13)所示;考虑在头盔佩戴检测的实际应用场景中,实时性不可忽视,故将每秒检测帧数(frames per second,FPS)也作为本实验的评价指标之一,通常30帧/s就可满足实时检测要求。
(13)
其中:classes为检测的类别数,在头盔检测任务中,类别数为4;P和R分别为准确率(precision)和召回率(recall),公式如(14)和(15)所示:
(14)
(15)
其中:TP为正确预测为正样本的数量;FP为错误预测为正样本的数量;FN为错误预测为负样本的数量[21]。
3.4 实验过程
3.4.1 消融实验
为了验证YOLOv5s-BC算法的有效性,设置消融对比实验以验证每个改进策略对模型性能的影响,实验考虑了Soft-SPP模块、BiFPN-CA模块、EIoU-Loss损失函数3个因素,依次将3个改进策略添加到原YOLOv5s算法模型中,在同一实验条件下,训练300轮次,训练结果如表2所示。表2中,√表示在当前实验中使用该改进策略。
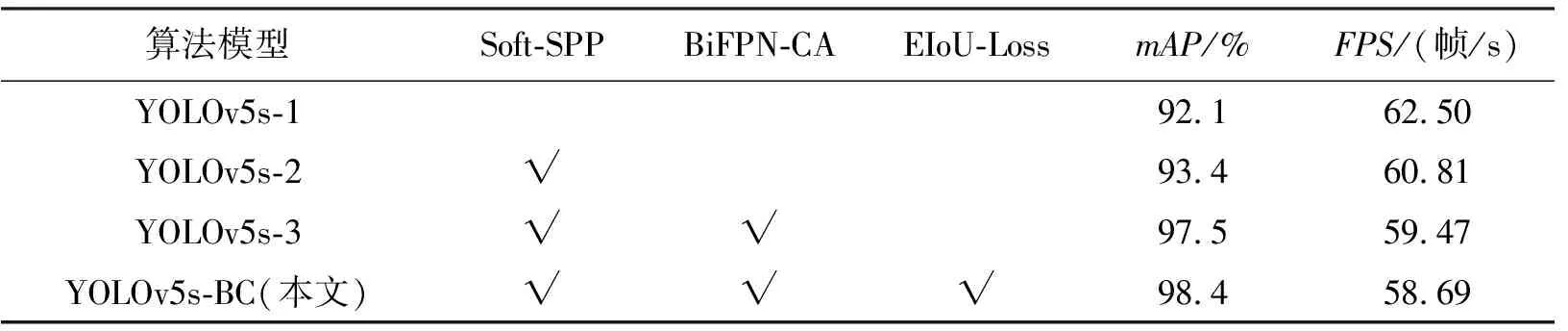
表2 不同改进方法的实验结果性能对比
由表2可知:YOLOv5s-1实验代表原YOLOv5s算法,其mAP达到92.1%;YOLOv5s-2实验增添Soft-SPP模块,相较于YOLOv5s-1,mAP提升1.3%;YOLOv5s-3实验在YOLOv5s-2的基础上添加了BiFPN-CA模块,mAP提升4.1%,可见本文提出的嵌入坐标注意力机制的双向跨阶段特征融合结构取得了可观的效果。YOLOv5s-BC也即本文方法在YOLOv5s-3的基础上优化了EIoU损失函数,mAP提升了0.9%,比YOLOv5s-1上涨了6.3%。由于添加的3个模块引入了部分参数,检测速度相较于原YOLOv5s模型出现了小幅下降,但也达到了58.69帧/s,可以满足实时检测的水平。由此可见,本文改进的头盔佩戴检测算法YOLOv5s-BC在检测精度方面较原算法得到了较大提升,同时推理速度也没有大幅降低的趋势,具有一定的可行性。
3.4.2 对比分析实验
为了进一步验证YOLOv5s-BC算法的优越性,设置第二组对比实验,即将本文改进的算法YOLOv5s-BC同二阶段目标检测算法的代表Faster R-CNN,一阶段目标检测算法的代表SSD、YOLOv3、YOLOv4以及YOLOv5等目标检测领域主流的算法在同一实验环境下,使用同一套数据集,采用同样训练策略训练300轮次,实验统计结果如表3所示。图8为各模型算法的训练损失对比图。
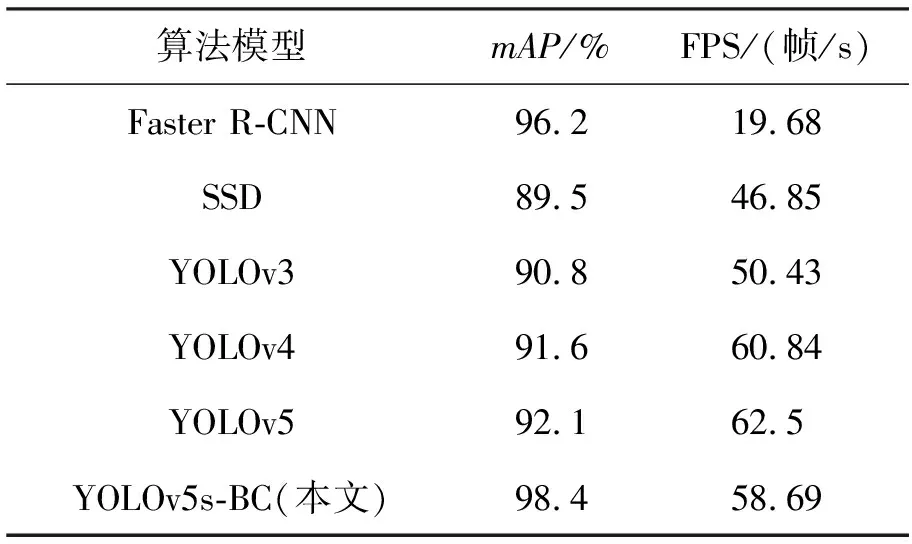
表3 主流算法模型的实验结果对比
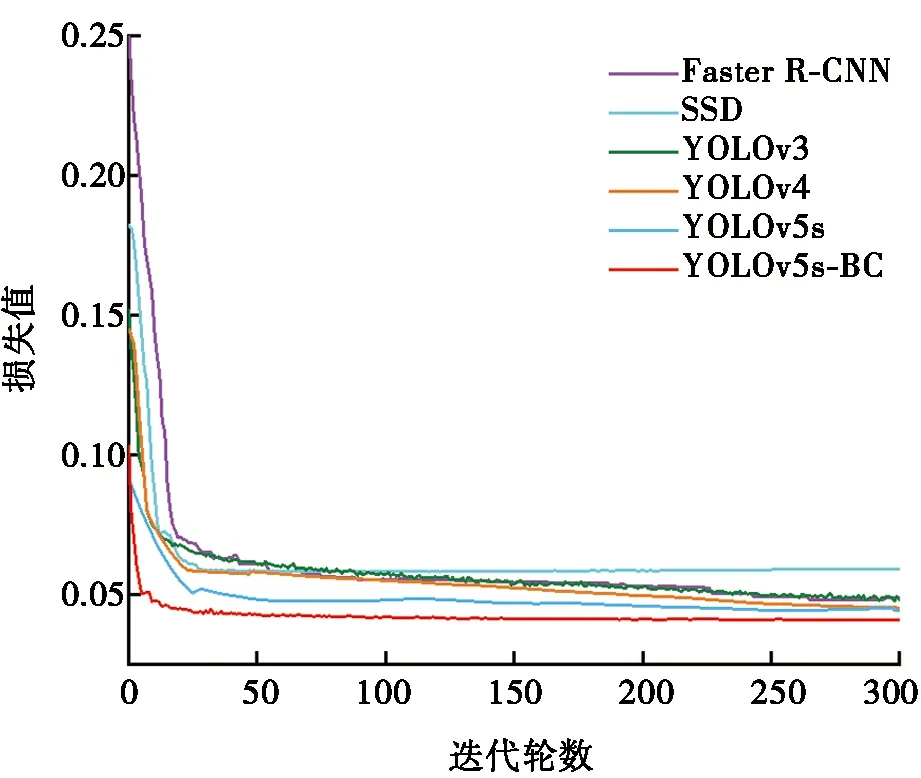
图8 各模型的训练损失对比图
由表3和图8可知:改进后的YOLOv5s-BC算法在检测精度上高达98.4%,模型训练损失最小,相较于其他算法,YOLOv5s-BC模型收敛最快,大约在150轮达到稳定状态,且没有出现过拟合和欠拟合的趋势,整体性能明显优于其他主流算法,Faster R-CNN的检测精度虽然达到了96.2%,但其检测速度太慢,难以实现头盔的实时检测。在检测速度方面,改进后的YOLOv5s-BC算法达到了58.69帧/s,比Faster R-CNN高出39帧/s,快了将近3倍,比SSD高出11.85帧/s,快了1.25倍,相较于同一系列的YOLOv3和YOLOv4均有所增加。由于新增模块增添了部分参数,导致推理速率比原YOLOv5s模型有所下降,但也完全可以满足检测任务的实时性。总体而言,相比于其他主流算法,YOLOv5s-BC算法在头盔检测数据集上取得了最优性能。
3.5 检测结果
在同一实验条件下,用328张头盔图像的测试集对各个训练模型进行测试,检测结果可视化如图9所示,第1列到第6列依次为Faster R-CNN、SSD、YOLOv3、YOLOv4、YOLOv5s以及YOLOv5s-BC模型分别在雨天场景、夜晚场景以及密集场景下的检测效果。从一行的雨天场景的对比结果图中可以看出,面对和安全头盔外形极其相似的雨衣帽时,只有YOLOv5s-BC模型正确将其识别为“Non-Helmet(非安全头盔)”,其他算法模型均误检为“Helmet(头盔)”;在第2行中的夜晚场景中,所有模型的检测性能均欠佳,YOLOv5s-BC模型虽正确定位到了车体和人员的头部区域,但检测精度并不高,这是因为夜晚光线较暗,且存在车灯的强光干扰,骑乘人员的头部区域人眼也不易识辨,模型很难对其进行准确定位;在第3行的密集场景中,由于车体和骑乘人员相互遮挡严重,相比于YOLOv5s-BC模型,其他模型均有一定的漏检。由此可见,本文改进的非机动车安全头盔佩戴检测算法YOLOv5s-BC模型相比于其他主流模型具有较强的泛化性和鲁棒性,取得了更好的检测性能。

图9 不同交通场景下各检测模型效果对比图
4 结束语
针对现有头盔检测算法在密集场景中的漏检以及对其他和头盔高度相似的帽子的误检问题,本文通过实地取景拍摄自建一套涵盖多种交通场景的非机动车骑乘者佩戴头盔的图像数据集,具有一定的真实性,并提出一种非机动车安全头盔佩戴检测方法YOLOv5s-BC。首先,针对原SPP 结构中使用的最大池化在进行下采样时会丢失大量信息,提出用3个SoftPool取代原有的3个最大池化层,以最大程度保留非机动车车体、头盔、人头的特征信息和细粒度特征,mAP可提升1.3%;然后,针对原YOLOv5模型中的特征融合网络融合性欠佳,提出将BiFPN结构应用到模型中,加入一条跳跃连接实现跨阶段连接,加强了深浅层网络的联系,并将坐标注意力机制嵌入到BiFPN结构中,构建一个加强版特征融合模块,以增强有效特征信息的表达,mAP提升了6.4%;最后,选用EIoU损失函数优化边框损失,以对目标进行精准定位。
实验结果表明,本文提出的头盔检测算法模型,精度高达98.4%,推理速度可达58.69帧/s,检测性能明显优于其他算法。测试结果表明,本文提出的头盔佩戴检测算法在诸多道路环境中都取得了较好的成绩,具有一定的稳定性。特别是在车流密集场景中和光线较弱且有车灯干扰的夜晚场景中,YOLOv5s-BC头盔检测算法明显改善了漏检问题;同时,模型在识别其他和头盔高度相似的帽子时,能正确区分出差异特征,不会误检。下一步将重点探讨如何将改进后的网络模型嵌入到移动设备端,以实现非机动车头盔佩戴检测项目的实际应用。
