基于深度强化学习的智能决策方法*
2023-01-18熊蓉玲段春怡冉华明冯旸赫
熊蓉玲,段春怡,冉华明,杨 萌,冯旸赫
(1.中国西南电子技术研究所,成都 610036;2.西南交通大学 数学学院,成都 611756;3.国防科技大学 系统工程学院,长沙 410003)
0 引 言
强化学习通过智能体和环境不断试错交互的方式学习到能够使奖励最大化的最优策略[1]。深度强化学习结合神经网络强大的表征能力来拟合智能体的策略模型和价值模型,求解复杂问题的能力大幅提升,近年来在各类智能决策问题上取得了巨大的进步,成为人工智能领域发展迅猛的一个分支[2]。实时策略类游戏作为典型的时序决策问题,成为国内外学者研究深度强化学习的试金石。Mnih 等[3]提出深度Q网络(Deep Q Network,DQN)算法解决Atari2600游戏,在6个游戏中的表现优于以前的方法,在3个游戏中的表现优于人类专家。但Atari2600游戏的任务场景较为简单,决策时序较短,决策空间较小,问题复杂性不高。Vinyals等[4]针对星际争霸游戏问题,采用了强化学习和模仿学习相结合的方式,解决了非完全信息下的即时策略游戏问题。Jaderberg等[5]针对雷神之锤游戏问题,利用双层流程来优化智能体的内部奖励机制,再通过这些奖励来优化强化学习模型,通过并行训练多个不同的智能体集群相互配合,实现了完全无监督的自学机制。与Atari2600游戏相比,星际争霸和雷神之锤的任务场景复杂,决策难度大幅提升,文中设计的算法架构复杂,计算资源需求大,训练时间长,难以应用到其他任务场景中。
针对传统深度强化学习方法难以快速解决长时序复杂任务的问题,本文提出一种引入历史信息和人类知识的深度强化学习方法。
1 背景介绍
1.1 深度强化学习
强化学习主要关注智能体如何在环境中采取不同的行动,以最大限度地提高累积奖励。强化学习主要由智能体、环境、状态、动作、奖励组成[6]。其中,状态空间用状态集合S表示,动作空间用动作集合A表示,则智能体与环境的交互过程为:当给定环境的某个状态s∈S,智能体将根据当前的策略π(a|s)执行某个动作a∈A,环境迁移到新的状态s′∈S,同时智能体从环境获得奖励r(s,a)。智能体根据环境反馈的奖励,对自身的策略模型进行更新,以学会最佳决策序列。
为了表示累积奖励,通常使用折扣累积奖励来代替:
(1)
式中:γ为折扣系数。
当执行到某一步时,需要评估当前智能体在该时间步状态的好坏程度,主要由值函数来完成,包括状态值函数Vπ(s)和动作-状态值函数Qπ(s,a)两类,分别如公式(2)和(3)所示:
Vπ(s)=E[Rt|st=s],
(2)
Qπ(s,a)=E[Rt|st=s,at=a]。
(3)
强化学习的核心思想是使用值函数找到最优的策略,通常采用求解贝尔曼方程的方法,即


(4)
或者


(5)
式中:p(s′,r|s,a)为状态转移概率。
深度学习通过神经网络的逐层组合,最终提取能够代表数据最本质的高维抽象特征,具有极强的表征能力。深度强化学习使用强化学习定义问题和优化目标,使用深度学习求解策略函数或者价值函数,充分利用了强化学习的决策优势和深度学习的感知优势,近年来在很多任务上取得了巨大的成功。
1.2 近端策略优化
深度强化学习算法大体上可分为三类,即值函数方法、策略搜索方法和混合型的行动者-执行者(Actor-Critic,AC)算法。典型的深度强化学习算法包括DQN[7]、优势行动者-执行者(Advantage Actor-Critic,A2C)[8]、确定性策略梯度(Deterministic Policy Gradient,DPG)[9]、置信区域策略优化(Trust Region Policy Optimization,TRPO)[10]、近端策略优化(Proximal Policy Optimization,PPO)[11]等。经过实验对比发现,PPO算法的整体表现更优,常作为深度强化学习应用中的首选算法。
PPO算法是在TRPO算法的基础上,使用截断的方式构建目标函数,以保证新策略和旧策略的差异控制在一定范围内,提高算法模型训练的稳定性。

1+ε)A(st,at))。
(6)
式中:ε为截断系数;rt(θ)为新策略和旧策略的比率,
(7)
变量A(st,at)为优势函数,有助于在保持无偏差的情况下,尽可能地降低方差值,表达式为
A(st,at)=Q(st,at)-V(st)。
(8)

(9)

2 深度强化学习决策模型
2.1 问题建模
本文考虑经典飞行射击类游戏的任务场景,对抗双方的智能体在模拟环境中各操控一架飞机从基地起飞,在飞行过程中智能体根据飞机传感器探测到的对手信息和自身平台的信息进行控制决策,以对飞机进行全方位的操控,包括飞行控制、雷达控制、电子战控制、武器控制,最终达到击落对方飞机的目的。
针对上述飞行射击类游戏场景,本文采用深度强化学习方法对其进行问题建模,明确深度强化学习算法模型的状态空间、动作空间和奖励。首先,在强化学习决策模型中,引入历史状态和动作信息作为状态输入,让智能体进行游戏决策时可以显式地获取历史信息。其次,将游戏过程中对最终胜负有贡献的关键事件作为中间奖励,以显式引导智能体如何获胜。这样设计可以带来以下三方面的好处:
一是可以让智能体更准确地掌握对手的状态信息。在游戏过程中,对方飞机如果进入我方传感器的探测范围内,我方智能体只能获得对手飞机的位置信息,无法获得其航向和速度信息。通过引入上一时刻对手飞机的位置,智能体可以隐式获得其航向和速度信息,可以帮助智能体更准确地进行飞行航向和速度控制决策。
二是可以帮助智能体保持控制决策的一致性。飞行射击类游戏属于典型的长时序连续决策问题,引入历史动作信息可以让智能体显式获得过往动作,有利于其保持决策的一致性,在游戏过程中避免无意义的动作频繁变更,比如无意义的大幅机动、连续发弹、雷达频繁开关机等。
三是可以帮助智能体更快地掌握获胜方法。现有的强化学习方法通常只根据游戏的胜负设置奖励,但飞行射击类游戏单局游戏的时长通常为20 min左右,只根据最终的胜负进行奖励反馈属于典型的稀疏回报问题,智能体很难学习到有效策略。将游戏过程中对最终胜负有贡献的关键事件作为中间奖励,比如发现目标、武器发射等,可以引导智能体更快地学习到获胜策略。
本文采用PPO算法构建飞行射击类游戏智能决策模型,状态空间来源于飞机传感器探测到的对手信息和自身平台的信息,包括飞机位置、传感器状态、武器状态等共20项,动作空间包括飞机飞行控制、雷达控制、电子战控制、武器控制共8项控制项,状态空间、动作空间和奖励的详细信息分别如表1、表2和表3所示。
智能体在每个时间步根据最新的环境状态以及历史环境状态和动作进行动作决策,考虑到过多引入历史信息会加大状态空间,从而影响训练效率,本文在最新环境状态的基础上只引入上一步的历史状态和动作信息作为状态输入进行动作决策,游戏环境接收到决策动作进行环境状态更新并反馈奖励。重复上述过程直到游戏结束。

表1 状态空间详细信息

表2 动作空间详细信息

表3 奖励详细信息
为了缓解智能体与游戏环境频繁通信交互导致的训练时间过长的问题,以及智能体频繁决策动作变更导致的前后决策不一致的问题,智能体的1个时间步对应游戏环境中的10个推进周期,即1次动作指令在10个游戏推进周期内执行。
2.2 无效动作掩膜
在强化学习中,智能体在探索阶段可以在整个动作空间内进行试错探索。但是,针对特定的环境状态,可能存在无效或者不合理的动作。智能体一旦探索到这些无效或者不合理的动作,会导致模型训练收敛的时间变长。通常,任务场景的动作空间越大,其中无效或不合理的动作越多。
针对飞行射击类游戏而言,其中存在的无效或者不合理的动作包括尚未发现对方飞机却大幅机动转弯;雷达尚未探测到对方飞机却发射武器;对方雷达尚未探测到我方飞机(对方雷达状态为关机或扫描)却电子战开机干扰。因此,本文采用无效动作掩膜[12]的方式避免智能体进行无效或不合理的探索,以提高模型的训练收敛速度。
在PPO算法中,策略网络输出为未归一化的概率(logits),然后经过softmax操作转变为归一化的概率值,根据不同动作的概率分布来进行动作选择。
(10)
当某个动作是无效或不合理时,只需要将对应策略网络输出(logits)替换为无穷小的值(如-1×108),则经过softmax操作后该动作被选择的概率趋近于0,以此来实现该动作的禁用。
同时,当某个时间步智能体采用了无效动作掩膜禁用某个动作时,对应的策略梯度为0,从而保证了替换操作不会给策略网络参数带来负面影响。证明如下。

(11)
式中:N为样本数据总量;Rk是第k条样本的累积奖励。
针对式(11)中的梯度计算部分进行公式推导:
(12)
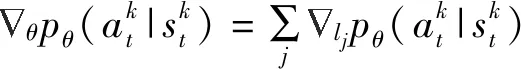
(13)

(14)
假设在某个时间步,智能体采用无效动作掩膜禁用了动作a0,并按照动作概率分布选择执行动作a1,则在式(14)中,i=1,无效动作a0对应的梯度为
(15)
因此,证明得到无效动作掩膜对应的策略梯度为0,策略网络参数的更新不受动作掩膜的影响,从而保证了替换操作不会给策略网络参数带来负面影响。
为了验证上述计算过程的正确性,在接收到最新的环境状态时,人为将对方飞机的信息屏蔽来模拟尚未发现对方飞机的情况,在此情况下,智能体输出的机动决策均为保持直飞,证明无效动作掩膜确实屏蔽了无效的大幅机动。同时,对比了该情况下策略网络模型更新前后的网络参数值,发现网络参数值未发生改变,证明无效动作掩膜对应的策略梯度确实为0,不会给策略网络参数带来负面影响。
3 仿真结果及分析
3.1 仿真场景设置
本文所提的PPO智能决策算法模型是在Stable Baselines[13]中PPO2算法源代码的基础上增加无效动作掩膜实现的,并调用该算法库中的矢量化环境模块(Subproc Vec)实现多进程并行采样。矢量化环境是一种将多重独立环境堆叠成单一环境的方法,可以实现同时在多个环境上进行并行交互采样,以提高智能体的探索效率。
游戏环境则是基于OpenAI Gym框架[14]对飞行射击类游戏进行封装。智能体与游戏平台之间采用用户数据包协议(User Datagram Protocol,UDP)通信,通过最基本的套接字的方式进行信息交互,以减少网络堵塞,缩短通信时间。
本文中设定的任务区域如图1所示,分为待战区和自由交战区,待战区的大小为15 km×25 km,自由交战区的大小为150 km×25 km。对抗双方的初始经纬度可在各自待战区内任意选择,双方飞机初始航向为东西方向对飞,初始高度均为8 000 m,初始速度均为1Ma。

图1 游戏任务区域场景示意图
决策智能体的训练集为3个固定场景,采用相对态势的思路,敌方飞机的初始经纬度保持在其待战区的中心位置,我方飞机的初始经纬度分别在其待战区的上方(-12.5 km)、中间(0 km)、下方(12.5 km)。测试集为100个随机场景,对抗双方飞机的初始经纬度在各自待战区内随机生成。
3.2 训练结果
在深度强化学习算法模型的训练中,超参数的设置对模型训练的影响较大,尤其是学习率的合理设置尤为重要。本文通过对比不同学习率情况下的损失函数收敛曲线和随机测试场景对抗胜率收敛曲线来进行学习率的选择。其中,随机测试场景对抗胜率用于验证决策智能体对不同任务场景的适应性,采用100个随机场景,每训练10个回合测试一次,从而展现训练过程中决策智能体对抗胜率的变化。
图2为学习率分别设置为10-5、10-4、10-3时决策智能体损失函数的收敛曲线。从图中可以看出,随着学习率的不断增大,损失函数收敛得更快,损失值更小。当学习率设置为10-3时,损失函数收敛到0.000 5附近。
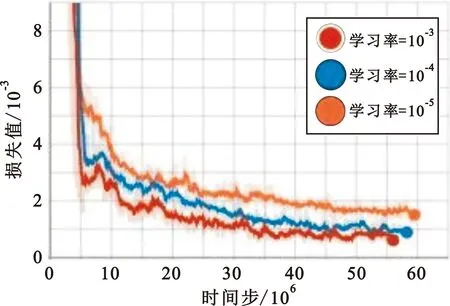
图2 损失函数收敛曲线
图3为学习率分别设置为10-5、10-4、10-3时决策智能体随机测试场景对抗胜率的收敛曲线。从图中可以看出,当学习率为10-5时,智能体几乎不能找到有效的策略,平均胜率在15%左右;当学习率为10-4时,智能体在训练150个回合后平均胜率在50%左右;当学习率为10-3时,决策智能体在训练150个回合后可以稳定达到80%左右的对抗胜率。

图3 决策智能体测试胜率收敛曲线
本文中算法模型的训练超参数设置如表4所示。
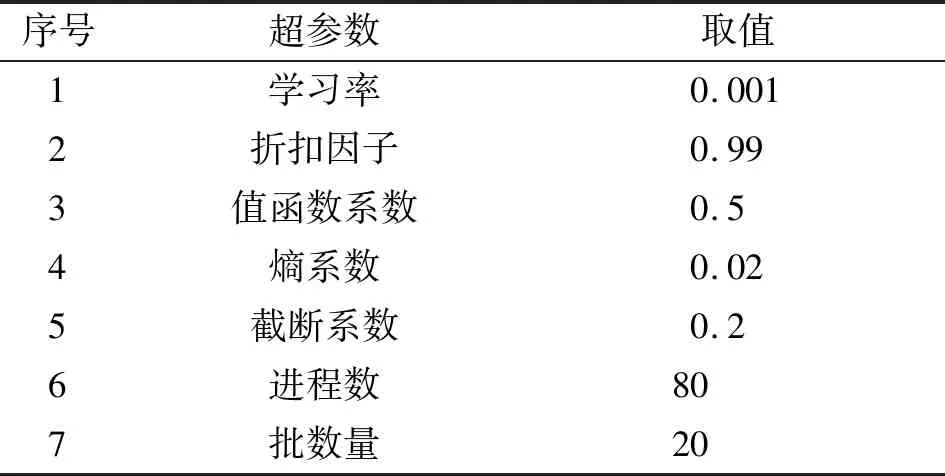
表4 超参数设置
为了验证引入历史状态和动作信息以及无效动作掩膜对模型训练的影响,对比了只引入历史状态和动作信息、只引入无效动作掩膜情况下的回报收敛曲线,如图4所示。可以看出,去除历史状态和动作信息或者去除无效动作掩膜均无法获得高回报,智能体无法学习到有效的策略。以上结果表明,通过在PPO算法模型的基础上引入历史状态和动作信息以及无效动作掩膜可以引导智能体更容易学习到获胜策略,可以显著提高模型收敛效果。
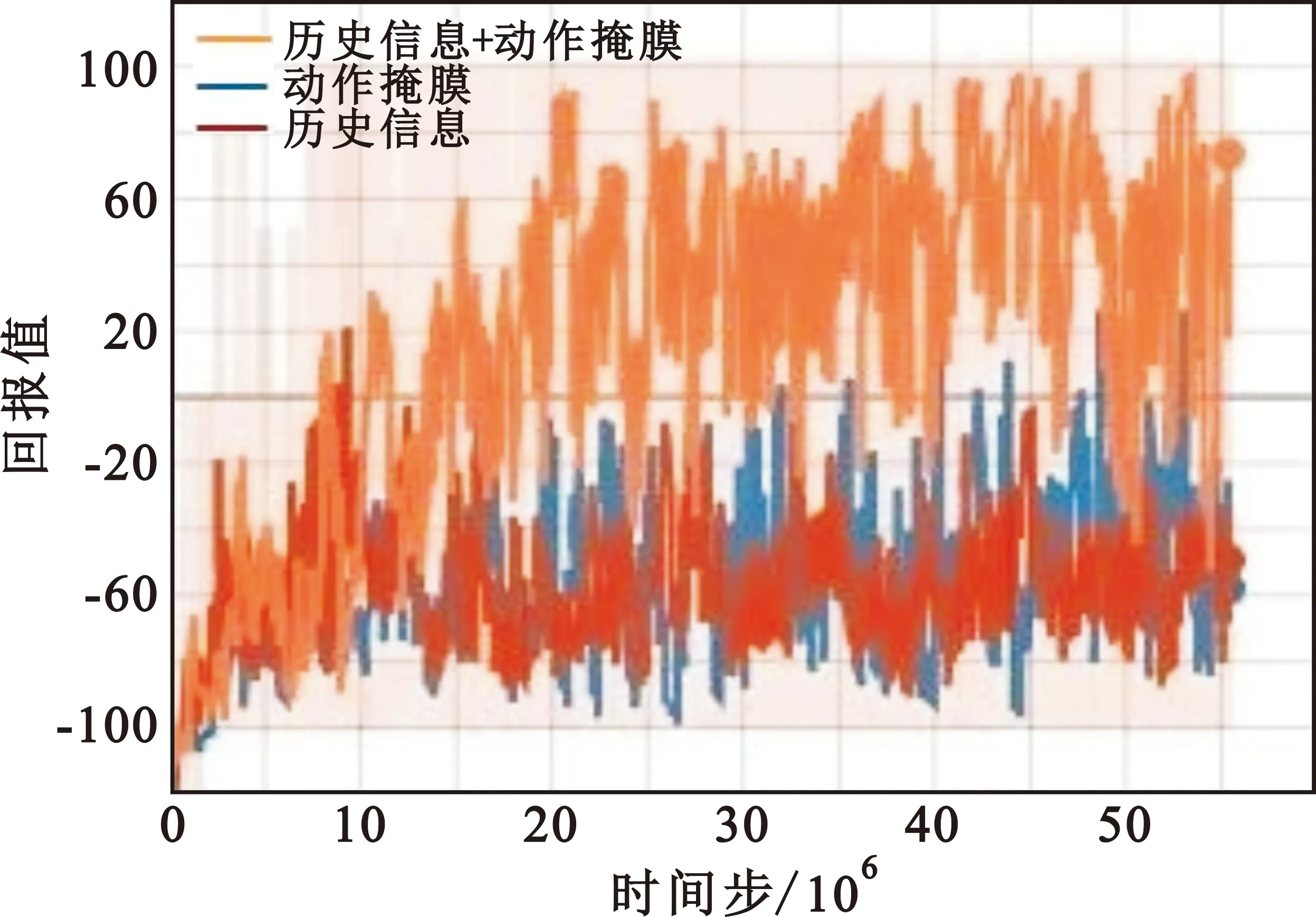
图4 游戏回报变化曲线对比
4 结束语
针对传统深度强化学习算法难以快速解决长时序复杂任务的问题,本文在经典PPO算法的基础上提出了一种引入历史信息和人类知识的深度强化学习方法。首先,在输入状态中引入历史状态和动作信息,让智能体可以显式获取历史信息,以帮助智能体更准确掌握对手状态和保持自身决策的一致性。其次,在策略模型中引入无效动作掩膜,避免智能体进行无效或不合理的探索,以提升探索效率。本文通过仿真试验验证了所提方法的有效性,对比试验结果表明所提方法可显著提升智能体的探索效率,可引导智能体学习到有效策略。
与其他深度强化学习模型一样,由于神经网络的高度拟合性导致智能体的行为决策机理难以解释,后续将对智能体行为的可解释性进行研究。
