基于检索重排序模型的文本差异化研究
2023-01-18门业堃钱梦迪于钊滕景竹陈少坤颜旭
门业堃,钱梦迪,于钊,滕景竹,陈少坤,颜旭
(1. 国网北京市电力公司电力科学研究院,北京 100075; 2.北京恒华龙信数据科技有限公司,北京 100088)
0 引 言
电力行业在设备质量评估中会大量使用种类、版本众多的行业标准规范文件,业务人员在实际使用中需要根据文件内容判断采购设备时应遵循的具体标准,以人工方式浏览查询大量标准规范文件,效率低,准确性有待提升。然而,目前国内外对标准差异化梳理技术的研究还处于专家总结经验的形式。面对种类、版本众多的行业标准规范文件,仅靠专家经验的形式已不能满足目前的标准差异化梳理的要求,建立自动化、信息化、智能化的标准差异化梳理技术是现阶段电力企业迫切需要的技术。
标准差异化梳理技术的本质是通过自然语言处理技术,完成对行业标准规范文件的语义相似度计算。文本相似度计算主要可分为基于词共现向量的文档模型方法[1]、基于语料库的方法[2-5]、混合方法和基于描述性特征的方法[6-8]。文本挖掘作为数据挖掘[9-11]的一个分支,能够充分挖掘信息的潜在价值。国内学者在文本相似度方面取得了一定的进展,其中文献[12]在知网语义相似度的基础上,将基于语义理解的文本相似度计算推广到段落、篇章范围。文献[13]通过将文本的特征词相似度为基础,来计算文本间的相似度。在国外方面,文献[14]通过将基于相似性度量和字向量的文档模型方法用于信息检索系统。潜在语义分析(LSA)[15]通过高维的线性关联模型,生成文本相似性。
然而,目前在国内外,对技术文档差异性内容检索的研究依然是空白。事实上,与普通内容检索和相似度计算相比,差异性内容检索难度更大,主要原因在于具有差异的内容往往句式不同,而句式不同的语句所表达内容有可能相同。建立文本差异化模型,解决方法有两种:(1)字面相似度模型:编辑距离等从字面意义上判断句子的相似度,方法简单,容易出现无法识别文本描述内容相同但说法不同的情况;(2)判别式算法:通过判别式机器学习算法,直接对两个句子是否描述同一实体的概率进行建模分析识别。因为判别式机器学习算法能够利用上下文(包括标题、子标题、上下文句子)等特征,综合考虑句子的相似度,因此文中使用判别式算法来建立差异性检索召回模型。
文中主要围绕标准差异化梳理技术,以判别式算法为基础,通过基于检索重排序模型的信息检索模型,建立完善的自动化、信息化、智能化的标准差异化梳理技术系统,能够快速识别同一领域不同标准文件的检索比对,以及不同部门发布的同类标准文件中存在差异的内容,并针对不同部门发布的标准文件中对相同设备技术要求却不同的、需要技术人员着重注意的差异内容进行检索,便于标准使用人员选择合适的标准规范,提升业务效率,起到降低工作量,提高准确性,有利于对技术要求的管控的作用。模型具有较强的实用性,还可以广泛应用于电力设备质量评估,供应商评价标准检索等领域。
1 理论基础
1.1 TF-IDF
TF-IDF[16](Term Frequency-Inverse Document Frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF-IDF通过词频和逆文档频率来评估一字词对一个文件集合或语料库中的某文档的权重。
词频(TF)表示词条(关键字)在文本中出现的频率。即:
(1)
逆文档词频(IDF):某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到:
(2)
TF-IDF=TF×IDF。词汇的TF-IDF重要性随着词汇在单个文件中出现的次数的增多而增多,同时也会随着它在总体语料库中出现的次数增多而减小。一般来说,在某一篇文章中出现频率大,但在其他文章中出现次数少的词语,更有可能是这篇文章的关键词。因此,TF-IDF利用这一规律通过词频和逆文档频率来对每一个词打分。
TF-IDF是一种用于信息检索与数据挖掘的常用加权技术。如果某个词比较少见,但是它在这篇文章中出现多次,那么它很可能就反映了这篇文章的特征,正是我们需要的关键词。
1.2 word2vec词嵌入
word2vec(word to vector)是一种基于文本上下文,将词语映射到低维实数空间的文本向量化算法。word2vec通过双层神经网络,拟合用来表示词对词之间的关系的向量。这种通过算法将非实数空间的实体映射到实数空间算法,又叫做嵌入技术。嵌入技术产生的向量被称为嵌入,因此文中的word2vec产生的向量称为word2vec词嵌入。
1.3 LambdaMART排序学习模型[17]
传统的搜索引擎排序问题,通常会涉及到很多的排序策略。这些策略根据不同的特征,在不同的适用范围中起作用。因此,一个传统的排序算法,至少涉及到两方面的内容:策略的制定,以及不同策略的组合。策略的组合需要考虑策略分析适用的特征,以及相应策略的适用情况。根据这些内容,通过人工或者半机器半人工的方式组合起来,才能组成一个实用的排序算法。
LambdaMART算法主要基于MART算法。MART是梯度提升决策树算法,是一种集成学习算法(将几种机器学习技术组合成一个预测模型的算法,以达到减小方差、偏差,以及改进预测的效果),MART的原理通过拟合上一轮分类器产生的残差,更新下一轮学习的样本权重。
LambdaMART基于梯度提升决策树,通过优化λ梯度来得到最优排序函数。对于一个列表中任意的一对文章i和j,有:
(3)
式中C为损失函数;σ为控制损失函数形状的参数,一般设为1。|Δzij|表示交换i和j的位置产生的评价指标差值,si和sj分别代表文章i和j的模型打分,z可以是NDCG(正规化累计收益折扣)或者ERR(期望倒数排名)等。累加其他所有排序项,可得:
(4)
式中λi为累加排序项后的值,因此其损失函数梯度为:
(5)
其中:
(6)
然后可以得到:
(7)
所以我们可以用下面的公式计算第n棵树的第k个叶子节点上的值:
(8)
如表1所示,LambdaMART算法流程如下:k表示算法当前执行到的树的个数,i表示第i篇文章。算法第3行计算出了λ梯度,在第4行计算出了λ二阶梯度。算法在第6行通过拟合λ梯度,得到一棵叶子数为L的树,并在第7行中计算出牛顿法叶子权重,第8行将当前的树与上一棵树整合。算法不断循环N次,最后将每次得到的树相加,即得到最终的模型。

表1 LambdaMART算法流程
1.4 编辑距离
编辑距离[18]是一种常见的字符串距离衡量公式。编辑距离由俄罗斯科学家Vladimir Levenshtein在1955年提出,因此也得名叫Levenshtein距离。在自然语言处理中,编辑距离是用来度量两个变量相似度的指标。通俗来讲,编辑距离指的是在两个单词(ω1,ω2)之间,由其中的一个词ω1转化为另一个词ω2所需要的最少的单字符编辑操作的次数。其中,编辑操作有三种:插入、 删除、 替换。一般来说,两个字符的编辑距离越小,则他们越相似。
2 研究方法
主要针对同一领域的电力标准文件做检索比对,即针对不同部门发布的描述主体相同、技术要求却不同的标准进行检索并预警提示。差异性检索与信息检索技术之间存在方法上的通用性,但差异性检索对检索内容的要求更高:与检索出最相关内容的目标不同,差异性检索的目的是检索出内容最相关但描述方式存在差异的文本信息。由于二者之间存在一定的相似性及通用技术,因此,文中在普通的信息检索模型基础上,引入排序学习算法对初步检索出的内容进行重排序,并选择top-k置信度内容(即检索最理想的前k个内容)作为最终检索结果,实现了精度的进一步提高,以满足差异化查询的要求。其中k为两篇文章预期差异内容数,可根据实际需要进行调整。提出的模型主要分为三大部分:数据处理、差异性检索召回和top-k检索重排序。
数据处理,即通过基础的自然语言处理技术,对待检索文本进行处理,将其转化为计算机能够识别的数值形式,主要技术如TF-IDF、word2vec词嵌入等。
在使用word2vec词嵌入同时,为了避免一些与预测无关的词对预测结果带来影响,文中利用TF-IDF指标选取出电力行业技术标准数据的关键词,利用TF-IDF对词嵌入进行加权,得到句子的关键词嵌入。
编辑距离可以度量两个变量的相似度指标,将两个字符串a和b的编辑距离表示为lev{a,b}(|a|,|b|),其中|a|和|b|分别对应a和b的长度,用i和j分别代表a的前i个字符和b的前j个字符,那么,两个字符串a,b的编辑距离即lev{a,b}(|a|,|b|)可以用如下的数学语言描述:
(9)
应用判别式算法构建差异性检索召回模型的主要步骤有两点:(1)为了保证检索结果是最具有差异性的内容,引入top-k检索重排序;(2)在普通的信息检索模型的基础之上,通过使用排序学习算法对top-k置信度的检索内容进行重排序,使其精度能够进一步提高,以满足差异化查询的要求。文中使用LambdaMART算法来进行重排序处理,技术路线图见图1。
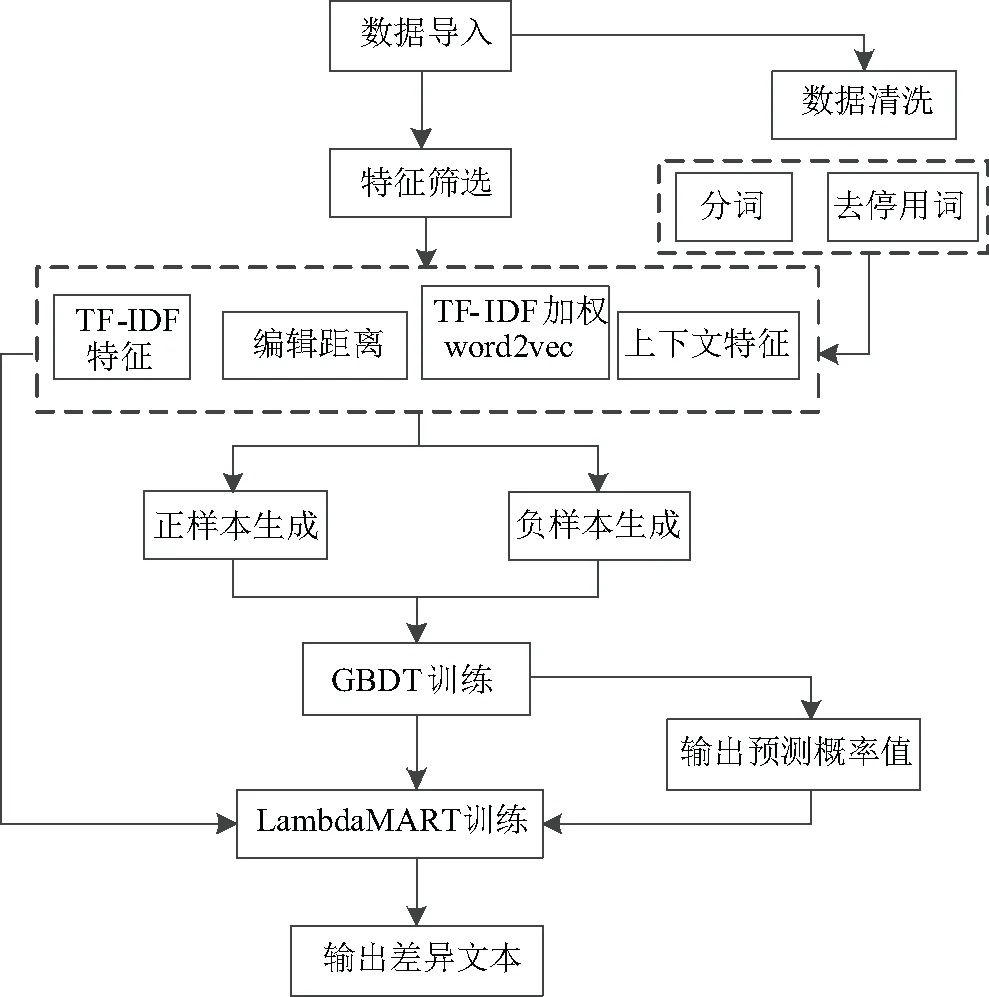
图1 技术路线
差异性检索召回模型一共包括三层:(1)第一层为数据处理层,计算出对检索有巨大帮助的文本特征;(2)第二层为差异性检索召回层,通过将数据处理层的特征,输入到具体分类模型中计算,得到分类结果;(3)第三层为检索重排序层,通过将差异性检索召回层传入的前k项(top-k)的候选句子对,根据它们所处的上下文信息等特征,统一进行排序操作。
文中引入的检索重排序层提高了文章差异性检索的效果与准确度,主要原因在于:(1)差异性检索召回层仅仅考虑了句子之间的匹配程度,没有考虑到从标准文件整体角度进行匹配;(2)检索结果往往无法明确地区分语义“完全一致”和“存在部分差异”之间的区别。因此,通过引入检索重排序层,能够既保留差异性检索召回层召回候选能力强的特点,也能够引入检索重排序层精确性高的优点。
3 模型分析
3.1 实验设置
为了得到模型所需的效果,额外搜集了多篇电力行业不同领域的技术标准文档,对模型进行训练,用20余篇进行验证,均得到较好的效果。文中以三篇变压器相关的技术标准文档进行说明,分别是2012年由国家能源局发布的DL/T 770-2012《变压器保护装置通用技术条件》[19]、2002年由中华人民共和国国家经济贸易委员发布的DL/T 770-2002《微机变压器保护装置通用技术条件》[20]和2016年由中华人名共和国国家质量监督检验检疫总局和中国国家标准化管理委员会共同发布的《1000 kV变压器保护装置技术要求》[21]。其中DLT 770-2012《变压器保护装置通用技术条件》为待查询差异的文章。
3.2 实验结果
3.2.1 数据处理层
(1)预处理。
对文本的预处理是自然语言处理的基础,也是能否达到符合预期目标效果的基础和核心。预处理包括去除无关内容、分词、去除停用词等。去除无关内容,就是将数据中与差异化检索无关的内容(如HTML标签、Word格式和因字符集编码解析错误导致的乱码)去除。分词,就是将中文的句子、文章从句子切分为词语。分词是中文自然语言处理的必要一步。一般来说,分词在机器学习中可以归结到序列标注问题,属于有监督学习。分词的实现方法有很多,文中采用的是最大概率法与隐马尔科夫模型的结合,对研究目标进行分词处理。去除停用词,就是将与文章内容无关的停用词(例如“的”、“了”、数字等)去除,以避免该类词对后续处理和训练所造成的影响。文中通过使用电力停用词词典对研究文本数据进行了去停用词预处理。
(2)特征生成。
使用的特征主要包括编辑距离、TF-IDF和word2vec。文中采用编辑距离和TF-IDF作为文本特征。表2为节选的DLT 770-2012《变压器保护装置通用技术条件》与DLT 770-2002《变压器保护装置通用技术条件》中的句子计算出两文本数据的编辑距离。

表2 编辑距离计算示例
在得到了分词后的结果后,一方面通过TF-IDF计算每一个句子的TF-IDF向量,另一方面可以通过使用Word2vec,生成每一个词的词嵌入。电力行业技术数据中存在一些在词嵌入中不存在的生僻词,需要对这一部分词进行单独处理。常见的处理方法有丢弃、占位符、均值填充等。丢弃即直接将生僻词丢弃,这种方法容易损失信息;占位符则是将生僻词转化为特殊的词嵌入,如全零或其他向量表示,这种方法在数据量大时有一定效果;均值填充即将生僻字利用上下文中的其他词的均值替代,这种方法效果较好,文中主要通过均值填充法对生僻词进行计算。
文中利用TF-IDF指标选出电力行业技术标准数据的关键词,利用TF-IDF对词嵌入进行加权,得到句子的关键词词嵌入。具体方法为先计算出每一个词在所在所在句子中的词频,再统计每一个词在文章中出现的次数,然后利用TF-IDF公式计算得到词的逆文档频率。
3.2.2 差异性检索召回
针对模型训练中差异性检索召回部分,将两篇文章中的任意句子两两配对,形成句对,分析每个句子对是否为待检索内容,并进行0-1标记,即二分类打分,然后将结果传入到检索重排序层。差异性检索召回层所用到的模型为二分类机器学习模型。在此用正类表示两个输入句子为相似且存在差异的句子,即文中需要检索的句对,负类表示两个输入句子为不相似句子。
为了使二分类模型能够精确有效判断出输入句子是否为正类、负类,需要先为模型提供一批人工审核的相似、不相似样本,分别作为模型的正样本和负样本。
差异性检索召回正样本为模型提供相似句对的样例,提供模型遇到类似的句对时能够自动判断是否相似。文中将待查询差异的文章与其他文章相似的句子两两配对,形成正样本。例如 <待查询差异文章句子1,其他文章句子1>为相似句子,则该句子构成一个正样本。
与差异性检索召回正样本相反,差异性检索召回负样本为模型提供不相似句对的样例,文中随机挑选不相关句子,作为负样本。例如 <待查询差异文章句子1,其他文章句子1>为不相似句子,则该句子构成一个负样本。负样本中还包括两种类型的样本:(1)语义相同但表述方式不同的句对,即逻辑完全相同句对;(2)语义不同的句对,即逻辑完全不同句对。两种类型的样本需要区别对待,其原因是逻辑完全相同的样本与正样本之间往往更难分割,因此需要分类器着重分析。文中将逻辑完全相同的样本进行过采样,在采样过程中对此类句对多次重复有放回抽取,对逻辑完全不同的样本进行欠采样,在采样过程中对此类句对随机丢弃。
上文得到的正样本、负样本均为人工审核的小数据量的准确样本,为了能对现存的海量待查询文章进行差异化检索召回,必须通过一种具有泛化能力的模型进行处理。GBDT模型是一种目前业界常用、性能优异的分类模型。文中利用GBDT模型,自动分析差异化检索召回的正负样本,来拟合二分类概率,以达到泛化的能力,这一过程又称为学习或训练。
差异性检索召回层通过查找数据处理层中句子的特征,对句对特征进行拼接,形成完整的差异性检索召回层的特征,然后送入到GBDT模型中进行训练。
经过了差异性检索召回层处理后,输出的候选句对已经能够达到基本的查询目标。在两篇待查询文章上进行实验后发现,DL/T 770-2012《变压器保护装置通用技术条件》与《1000 kV变压器保护装置技术要求》之间的差异性检索正确率(AUC指标)能达到0.874。DL/T 770-2012《变压器保护装置通用技术条件》与DL/T 770-2002《变压器保护装置通用技术条件》之间的差异性检索正确率(AUC指标)达到0.937。差异性检索对检索出的结果不仅要求整体正确率高,还需要保证top-k的准确率(即最先展现给用户的前k个差异检索)。例如,仅仅通过差异性检索召回,在k=300时,DL/T 770-2012《变压器保护装置通用技术条件》与《1000 kV变压器保护装置技术要求》之间的差异性检索正确率(即AUC指标)仅有0.476,DL/T 770-2012《变压器保护装置通用技术条件》与DL/T 770-2002《变压器保护装置通用技术条件》之间的差异性检索正确率(即AUC指标)也仅仅只有0.512。检索重排序层的引入,正是为了提高top-k的检索正确率,为用户直接提供最优质的差异检索。
3.2.3 检索重排序层
检索重排序层的输入是差异性检索召回层输出的二分类概率top-k的句对,输出为排序后的结果。检索重排序层通过使用LambdaMART算法,得到全局最优的排名和打分结果。
文中主要针对于提高top-k的精度,因此检索重排序层通过对top-k的样本进行训练,将top-k中的正样本和负样本的特征输入到LambdaMART模型中进行训练。虽然差异性检索召回层的预测概率结果并不一定正确,但其仍然能够为检索重排序层提供较为正确、丰富的预测帮助,因此检索重排序模型的特征与差异性检索召回层的特征相比,增加了一项由差异性检索召回层提供的二分类概率。另外,从集成学习的角度可以认为这实际上是一种更强大的层叠(stacking)学习。因此文中将其预测结果同样作为检索重排序层的特征,进一步提高模型的整体效果。验证结果如图2所示。
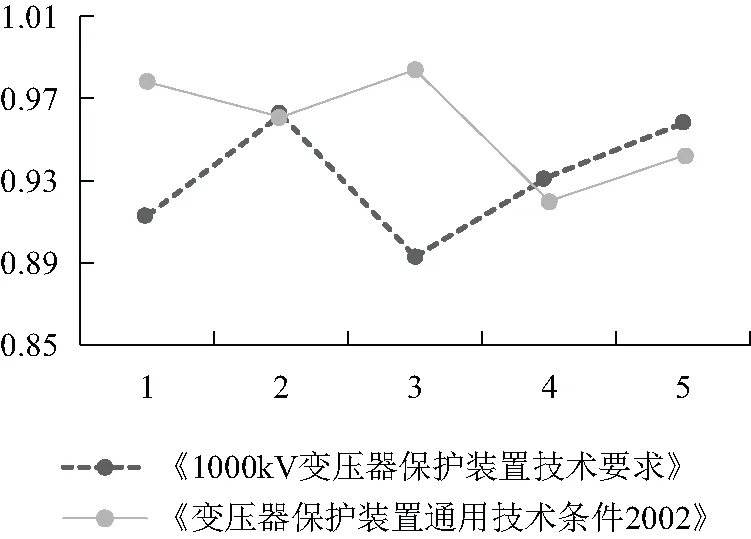
图2 五轮交叉验证的实验效果
在经过检索重排序的学习后,top-k(k=300)检索正确率(AUC)在DL/T 770-2012《变压器保护装置通用技术条件》与《1000 kV变压器保护装置技术要求》之间的差异性检索正确率(AUC指标)能达到0.928,DL/T 770-2012《变压器保护装置通用技术条件》与DL/T 770-2002《变压器保护装置通用技术条件》之间的差异性检索正确率(AUC指标)能达到0.954。可以看出,检索重排序层的引入,对提高top-k的检索正确率、提高用户使用便捷程度有非常巨大的帮助。
为了更鲁邦的验证模型的效果,文中在数据集上进行了交叉验证,图2为在五轮交叉验证的实验效果。可以看出,使用了检索重排序后,检索正确率已经能够均匀达到0.95以上。
对检索重排序模型与其他目前主流方法:TF-IDF、编辑距离、word2vec与检索重排序模型的AUC指标进行了对比,实验发现检索重排序模型效果较其他方法具有巨大的提升(如图3):TF-IDF、编辑距离这类不考虑语义相似度的方法效果最差,AUC指标最高仅为0.47。word2vec方法考虑了词汇的语义特征,但其并不能准确判断文章是否具有差异性,AUC指标也仅有0.61。文中提出的检索重排序模型,既能够利用word2vec提供的语义特征,又能够通过检索重排序有效判断是否具有差异性,效果最好,AUC指标达到0.95。
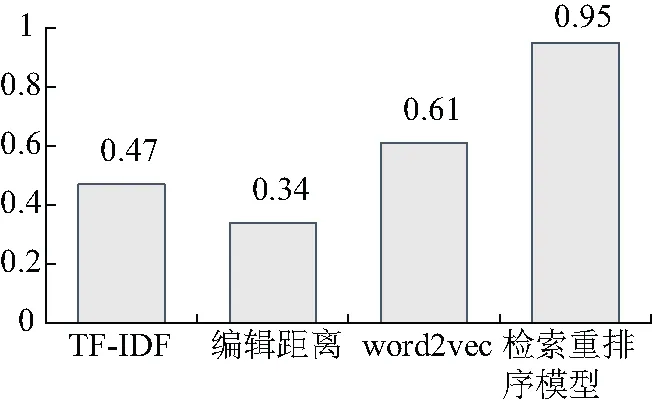
图3 检索重排序模型与主流方法效果对比
4 结束语
标准差异化研究是自然语言处理的重要组成部分,广泛应用于各个领域,相比常见的文本差异查询,文中主要针对电力行业中同一领域的不同标准文件做检索比对,检索出不同部门发布的文件中对同一技术不同要求的差异性内容并预警提示。模型在研究上主要针对差异性检索,提出了在普通的信息检索模型的基础之上,使用排序学习算法对top-k置信度的检索内容进行重排序,使其精度能够进一步提高的模型,以满足差异化查询的要求。
文中提出的电力行业技术标准差异化研究模型主要分为三大部分:数据处理、差异性检索召回和top-k检索重排序,并在真实的电力行业技术标准文档上进行了系统鲁邦的交叉验证,验证了模型效果的优异,结果表明模型具有非常高的差异性检索正确率(AUC指标),说明检索模型是有效的,检索输出结果是准确的,经过综合分析得出所采用的模型是可行的。
基于文本特征的检索重排序模型可应用于电网设备供应商绩效评价体系中的供应商名称匹配领域,能够提高供应商名称匹配效果,提高数据治理质量。此外还可以广泛应用于电力设备质量评估,电力行业标准检索、评价标准检索等领域。
