多层次融合与注意力机制的人群计数算法
2023-01-17孙艳歌郭华平
李 萌, 孙艳歌, 郭华平, 吴 飞
(信阳师范学院 计算机与信息技术学院, 河南 信阳 464000)
0 引 言
中国是世界上人口数量众多的国家, 其过高的人口密度对维护城市安全、 预防紧急公共事件都带来很大困难。2020年一场突如其来的疫情改变了人们正常的生产生活秩序, 人群的过度聚集引发了很多起集中性的感染案例。例如, 在工业园区入口、 高校餐厅、 商场等人员密集场所, 由于人员的过度聚集, 造成了大量的集中性感染, 给疫情防控带来了严峻的挑战。目前, 在疫情防控常态化、 规范化下, 严格控制各公共场所中的人员数量是一种有效切断疫情传播链的方法。而通过在人群易聚集的公共场所布置摄像设备, 应用人群计数的方法, 可高效快捷地统计出实时人群信息, 相关人员可及时地对人群密集的场所施行引流、 分流、 限制出入等措施, 可有效控制疫情集中性扩散的风险。因此, 如何从图像或视频中及时准确地估计人群数目与密度是非常值得研究的课题。
透视效应是人群计数问题中不可忽视的关键问题, 由于不同人群距离监控设备之间的远近不同, 在一张人群图像中会存在多个尺度的人群, 对人群计数的精度产生干扰。为解决透视效应引起的人群尺度变化问题, 人们利用多列卷积(MCNN: Multi-Column Convolutional Neural Network)或在不同卷积层上使用不同尺度的卷积核应对, 或采用扩张卷积替换不同的卷积核, 但上述方法仍存在许多不足, 不能完善地解决尺度变化问题。多列卷积会使网络变得更加复杂, 计算复杂度的急剧增加将导致模型难以收敛或梯度爆炸等问题。Li等[1]提出在MCNN中由不同列卷积得到的特征几乎相同, 其对解决尺度变化问题的贡献很小。基于上述讨论, 为更好地学习到不同尺度上的特征, 笔者采用一种编解码网络在不同层级的卷积上提取不同尺度的特征, 以应对透视效应带来的尺度变化问题。通过对编解码网络迁移预训练后的VGG16(Visual Geometry Group Network)[2]参数, 降低网络的复杂度。
由于人群场景的复杂性, 树木、 车辆等复杂背景会导致人群图像存在大量遮挡, 只应用人群密度图对抗背景的干扰并不完善, 难以达到对人群区域的特征增强效果。大多工作只考虑了高层卷积对高级语义信息的提取, 而低层卷积对遮挡边缘细节的提取常常被忽略。受多层次注意力模块[3]的启发, 在不同的卷积层次上融合提取到的尺度注意力, 以对抗复杂背景的干扰。
人群图像经过多次池化后, 其空间分辨率急剧下降, 丢失了大量的空间信息, 影响人群密度图的生成。因此, 笔者在网络的末端使用转置卷积的方法对空间信息进行补充, 并提高了图像分辨率。基于上述, 笔者提出了一种多层次融合与注意力机制的人群计数算法(MLFAM: Multi-Level Fusion and Attention Mechanism Based Crowd Counting Algorithm), 其贡献主要包括3个方面: 1) 引入编解码网络对人群图像的高层语义信息和低层边缘特征进行提取并生成尺度注意力, 由于不同层级的卷积包含不同的语义信息与尺度特征, 高低层特征的融合可有效解决由透视效应引发的尺度变化问题; 2) 提出多层次融合模块在多个卷积层次上融合尺度注意力以对抗人群图像中存在的严重遮挡与尺度变化问题; 3) 在解码层和网络的末端使用反池化与转置卷积恢复由编码层多层池化引起的分辨率下降、 空间信息与全局信息丢失等问题, 以生成更高质量的人群密度图。应用迁移学习的思想, 在编解码层中迁移了预训练后的VGG16参数, 有效地降低了计算复杂度与网络复杂度。
1 相关工作
影响人群计数的主要因素是人群尺度变化、 复杂背景干扰等。为解决上述问题带来的计数精度下降, 目前人们采用如下方法进行研究。
1.1 传统方法
传统方法分为基于回归和基于检测两大类。基于检测方法的主要思想是先检测到每个行人, 再对行人数量进行相加, 得到总人数。Dollar等[4]使用类似于滑动窗口的方式从图像中提取特征, 再通过分类器对行人进行识别, 最后将人数相加得到总人数。该方法在面对稀疏的人群场景时可以得到较好的结果, 但真实人群图往往十分拥挤, 且行人间存在着严重的互相遮挡, 无法提取到完整的行人特征。因此, Felzenszealb等[5]设计与训练了一个只利用人体部分特征判断的分类器, 但该分类器在面对高密度的人群场景时, 仍存在较为严重的误差。为解决上述方法在应对高密度人群场景时的缺陷, Chen等[6]提出了一种自适应的回归预测方法, 通过从人群场景中提取的特征学习图像特征到人群数量之间的映射关系。
综上, 传统方法主要依赖人工提取的特征对行人进行识别, 但该类方法不能很好反应人群图像的真实情况, 且容易受到多尺度、 背景复杂等问题的干扰, 对人群计数的精度产生影响, 在实际应用中的预测效果较差。
1.2 基于深度学习方法
近年来, 随着深度学习在计算机视觉任务[7-10]中的不断发展, 应用卷积神经网络对人群图像进行特征提取与人数预测是目前最为有效的方法。卷积神经网络通过提取的深度特征生成包含有人群空间与数量信息的人群密度图, 再对密度图逐像素求和得到总人数。针对人群图像中的尺度变化问题, Zhang等[11]提出的多列卷积神经网络(MCNN)使用多尺寸的卷积核提取不同感受野的特征。类似地, Sam等[12]提出了一种密度分类网络(Switch-CNN: Switching Convolutional Neural Network), 使用密度分类器自适应地输出密度等级。Amirgholipour等[13]提出了一种基于金字塔密度感知注意力的网络(PDANet: Pyramid Density-Aware Attention based Network), 通过金字塔规模特征和两个分支解码模块在提取不同尺度特征的同时抑制背景噪声。Sindagi等[14]提出了一种多层次的自下而上和自上而下的融合网络(MBTTBF: Multi-level Bottom-Top and Top-Bottom Feature Fusion), 通过一种双向的特征融合方式, 将低层特征融合到高层, 也将高层特征融合到低层, 从而提升了网络对尺度信息的表达能力。
针对复杂背景造成的人群遮挡问题, 主要的解决方案为利用视觉注意力机制, 使网络有意识地聚焦人群图像中更有用的信息, 以提高计数精度。Liu等[15]提出了一种可形变卷积神经网络(ADCrowdNet: An Attention-Injective Deformable Convolutional Network), 通过一阶段网络AMG(Attention Map Generator)为二阶段网络DME(Density Map Estimator)提供人群区域候选与拥挤度等先验信息的方式, 提升了网络对复杂背景的过滤能力以及在不同人群分布下的性能。Ilyas等[16]提出了一种基于CNN(Convolutional Neural Network)的密集特征提取网络, 利用密集特征提取模块(DFEMs: Dense Feature Extraction Modules)和通道注意模块(CAM: Channel Attention Module)将底层提取的特征通过密集连接传播到上层, 并加入通道注意力以获得全局信息, 提升了网络在密集场景下的计数精度。
2 多层次融合与注意力机制的人群计数算法
在应用卷积神经网络模型解决人群计数问题时, 多数方法都是直接将人群图映射为密度图, 从而忽略了人群图像背景产生的干扰。近年来提出的一些方法应用注意力机制解决背景干扰的问题, 但往往只考虑了由高层特征生成的注意力, 忽视了低层的细节特征, 其在面对如树叶、 建筑物、 车辆等复杂背景的干扰时并不能很好的对人群密度图进行预测。而传统方法在应对由透视效应引起的人群尺度变化问题时, 无法进行有效的识别与判断, 影响了人群密度图的精度。因此, 笔者提出了一种多层次融合与注意力机制的人群计数算法(MLFAM), 其网络结构如图1所示。

图1 MFAN网络结构图Fig.1 The diagram of MFAN network structure
该网络结构包含尺度注意力提取与多层次融合两个子网络, 用于在多层级卷积上融合不同尺度的注意力, 以实现对密度图更好地预测,
2.1 尺度注意力提取网络


表1 多尺度注意力提取网络参数配置
2.2 多层次融合网络
多层次融合网络由两个阶段构成, 分别为融合特征提取和人群密度图的生成。第1阶段采用预训练的VGG16网络中前13层卷积作为主干, 并在每个卷积块之前增加一个特征融合操作, 即

(1)
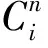
2.3 损失函数
笔者采用欧几里得距离衡量真实密度图与预测密度图之间的差值, 其定义如下
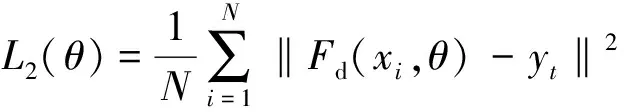
(2)
其中θ表示一组在网络训练时的参数,N表示训练的样本数量。Fd(xi,θ)表示在参数为θ的网络中输入xi图像后输出的预测密度图,yt表示与输入图像xi对应的真实密度图。
3 实 验
在2块RTX 2080Ti GPU上进行实验。网络整体基于Pytorch架构, 使用初始学习率为1×10-5的Adam优化器对网络参数优化, 并在除输出层外的每个卷积层应用批正则化和Relu, 以提高网络的训练速度并有效地避免梯度消失和爆炸等情况。
3.1 真值的生成
现有的数据集大都提供原始图像中人群的空间位置坐标与总人数。首先, 对原始图像的真值图进行裁剪, 得到4幅用于监督尺度注意力提取网络的真值图集。其次, 使用自适应的高斯核函数生成人群密度图的真值, 自适应高斯核函数定义如下
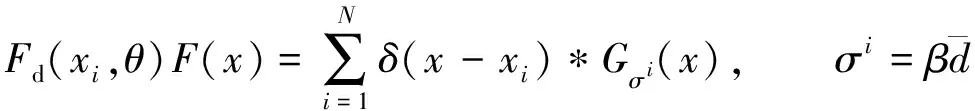
(3)
3.2 评价标准
使用两个在人群计数方法中常用的指标, 即平均绝对误差(MAE: Mean Absolute Error,EMAE)与均方误差(MSE: Mean Squared Error,EMSE)。其中MAE可以表示预测的准确性, MSE表示预测的鲁棒性。具体定义如下
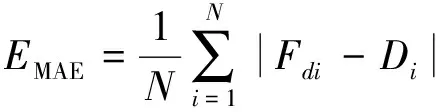
(4)

(5)
其中N表示测试图像的总数量,Fdi表示对第i个图像的预测人数,Di表示第i个图像的真实人数。
3.3 在ShangHaitech数据集上的实验
ShangHaitech数据集是一个多样且拥挤的数据集, 该数据集包括了Part A和Part B两个部分。其中Part A是从互联网上搜集的高密度人群照片, 共有482张图片, 每张图片的平均人数达到了501人, 人数最多的一张图片中有3 139人。Part B是通过在上海街头布置的摄像设备抓拍得到的, 相对于Part A, 其人群密度较为稀疏, 图片的平均人数为124人, 最多的一幅图片中有578人。在Part A和Part B中分别设置300张图片和400张图片进行训练, 182张图片和316张图片进行测试。
表2给出了使用MAE和MSE评价指标与最先进方法进行比较的结果。从表2可以看出, 在PartB数据集的测试中笔者方法明显优于其他方法, MAE提高了17%; MSE提高了25%, 有效证明了该方法的优越性。同时, 在Part A数据集上, MAE提高了1.6%, 可以说明本模型具有良好的准确性。但在MAE方面稍低于CAT-CNN(Crowd Attention Convolutional Neural Network)模型, 这表明笔者方法在预测的鲁棒性上存在一定的问题。

表2 在ShangHaitech数据集上使用不同方法的性能比较
图2给出了训练后的模型对人群密度图进行预测的结果, 并与其真值进行了对比, 第1列为原始图像, 第2列为MFAN得到预测人群密度图, 第3列为人群密度图的真值。可以看出, 本模型生成了人群分布较为准确的密度图, 有效地解决了复杂背景造成的遮挡问题。
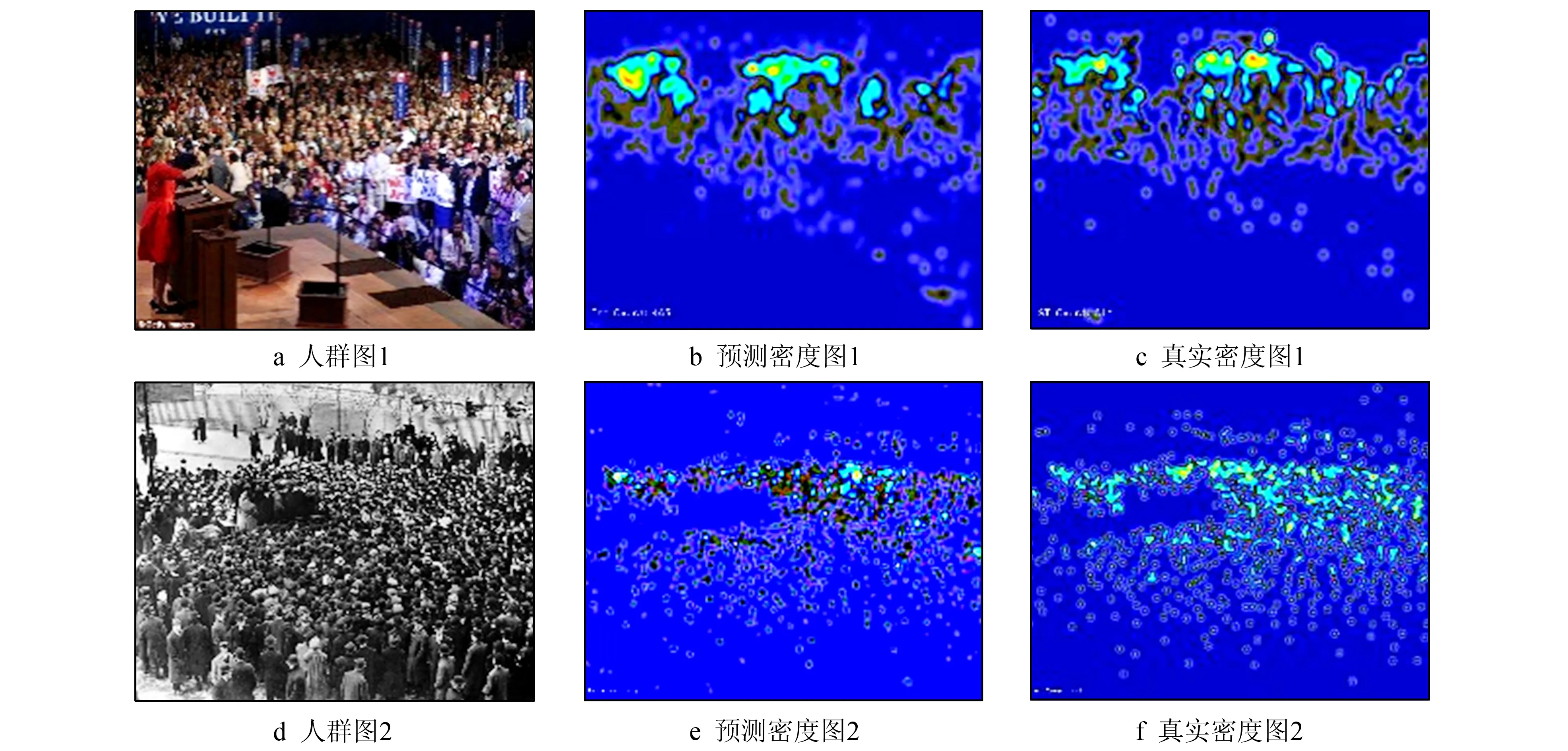
图2 在ShangHaitech数据集上的实验对比Fig.2 Experimental comparison on the ShangHaitech dataset
3.4 在UCF_CC_50数据集上的实验
UCF_CC_50数据集包含了50张具有不同视角和分辨率的图像, 每张图像的平均人数达到了1 280人, 最多的一幅图像中更是达到了4 543人, 整个数据集共标记了63 075人。由于该数据集中可供选择的图像太少, 不便于进行训练集和测试集的划分, 因此采用五折交叉验证的方法对数据集进行最大限度地利用。5次实验结果如表3所示。

表3 在UCF_CC_50数据集上使用不同方法的性能比较
将五折交叉验证得到结果与目前最先进的方法在MAE和MSE方面进行比较, 其结果如表3所示。可以看出, 相较于最先进的方法, 笔者方法的MAE提高了7%, 但在MSE方面稍差于PCC Net(Perspective Crowd Counting via Spatial Convolutional Network)。该结果有效地说明了本模型具有较高的准确性, 但在鲁棒性方面还存在一定的问题。
图3给出了训练后的模型对人群密度进行预测的结果, 并与其真值进行了比较。第1列为原始图像, 第2列为MFAN得到预测人群密度图, 第3列为人群密度图的真值。可以看出, 本模型可以较好的解决由透视效应引发的人群尺度变化问题, 可对拥挤的人群进行较好地预测并生成准确的人群密度图。


图3 在UCF_CC_50数据集上的实验对比Fig.3 Experimental comparison on the UCF_CC_50 dataset
3.5 消融实验
为证明MFAN结构的有效性, 在ShanghaiTech Part A数据集上进行了消融实验, 结果如表4所示。主网络即多层次融合网络去除掉注意力模块的其余部分, 其结果已优于大部分的经典人计数网络, 证明了骨干网络具有较为优秀的特征提取能力。在加入尺度注意力后, MFAN的计数精度得到显著提升, 验证了笔者所提方法的合理性。

表4 在ShangHaitech数据集上的消融实验
4 结 语
笔者提出了一种多层次融合与注意力机制的编解码人群计数网络, 采用编解码网络进行尺度注意力提取, 并在多层次融合网络中对提取到的尺度注意力进行融合, 在对抗复杂背景的同时, 有效地抑制了由透视效应带来的尺度变化问题, 进而生成高质量的人群密度图。经过实验分析, 证明了MFAN具有较好的鲁棒性与准确性。在未来的工作中, 将在其他人群计数数据集上进行实验, 以充分说明MFAN在不同环境下的性能, 并考虑利用图片与现实世界间空间关系的先验知识, 以进一步改善尺度注意力的提取。
