基于改进YOLOv5的工业钢材瑕疵检测算法
2023-01-16廖义奎
周 繁,廖义奎
(广西民族大学电子信息学院,南宁 530006)
0 引言
钢材作为国民经济的基础产业,在工业建设和社会发展中都发挥重要的作用。随着钢材产量的增大,钢材质量检测成为其中重要的一环。尽管在钢材的瑕疵检测方面、生产设备方面的技术得到一定程度的发展,但对于钢材表面多类瑕疵的检测问题还是无法得到彻底的解决[1]。因此,提升工业钢材瑕疵检测的效率和准确率对提高工业钢材质量有重要的意义。
目前,一些传统的检测技术已得到应用。例如,朱柳忠[2]结合超声波检测技术,进行了钢材检测领域的应用研究,并解释了其技术原理及已有的应用实例。苏伯泰等[3]设计了基于涡流成像的钢材表面裂纹检测平台,利用平台验证分析了对涡流热成像检测钢材裂痕效果的多种内部影响因素,从而更加高效地检测钢材裂痕。董宁琛等[4]在对钢材表面裂痕检测时,利用了脉冲激光光源热成像原理,将热量在裂缝缺陷处传递并形成表面温度差,使用热成像仪实现裂痕的可视化。
为解决传统的瑕疵检测技术存在的效率低、检测精确度不高等问题,目前在瑕疵检测领域,深度学习技术得到应用。因其工作量小、学习能力强等特点已成为热门的研究方法。例如,刘洋[5]通过改进Tiny-YOLOv3(You Only Look Once)算法,来实现对钢材瑕疵检测速度的提升。Zhao 等[6]通过重构Faster R-CNN 的网络结构,加强对目标特征的提取,有效提高了检测精度。Ferguson 等[7]提出基于CNN(Convolutional Neural Network)的检测方法,主要对图像进行分割,并进行迁移学习来提升网络模型精度。Zhang 等[8]对YOLOv3 算法进行改动,在原始的基础上增加小目标识别层,从而增强网络检测能力。上述研究表明,深度学习技术已在钢材瑕疵检测领域得到应用,且现阶段主要将检测速度以及精度的提升作为主要目标。
1 YOLOv5算法
YOLOv5算法相比同系列其他算法具有较好的性能。YOLOv5 算法有四个主要的组成结构:输入端,Backbone 骨干网络,路径聚合网络(Path Aggregation Networks,PANet)和输出检测层。其中,第一部分输入端主要增强图像数据,同时丰富背景也减少对图片批量处理需求[9],显著提升训练速度。
第二部分Backbone骨干网络,该网络由Focus模块、CBL(Conv Bn LeakRelu)、CSP(Cross Stage Paritial)和SPP(Spatial Pyramid Pooling)结构组成,主要作用是从图像中提取丰富的信息特征。其中Focus 模块对图片进行切片处理,在减少模型的计算量的同时,还不会发生信息丢失。CBL 结构在YOLOv5 中使用Conv 结构替代,新的结构主要替换原始的激活函数为SiLU[10]。CSP结构由C3结构替代,C3主要由Conv结构和BottleNeck 结构组成,即去掉了原始的Bottle-Neck 结构后的卷积层操作。SPP 结构的主要作用是进行多尺度融合,并分离出上下文的重要特征。第三部分为路径聚合网络,其主要特征就是将图像的不同特征层的相应尺度的特征图进行相互融合。第四部分输出检测层,该部分有三种不同的检测头,分别实现对大中小目标的检测识别。
2 算法改进
2.1 协同注意力机制
为了提升网络对瑕疵特征的学习能力,本文应用协同注意力机制[11](Coordinate Attention,CA)。在对图像中目标特征的提取过程中,往往会忽视重要的位置信息,CA 注意力机制在通道注意力中嵌入位置信息,使网络能够更准确定位特征信息以及参与较大的区域的空间选择。主要结构如图1所示。
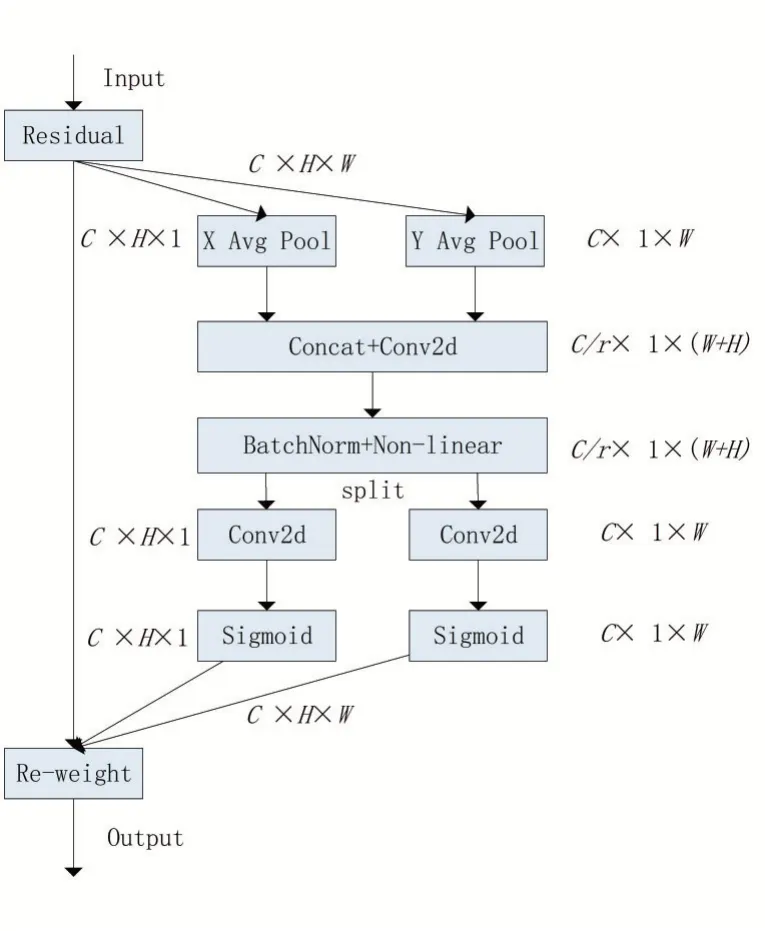
图1 CA注意力机制结构
CA 注意力机制的主要步骤为坐标信息嵌入和坐标信息特征图的生成。首先坐标信息的嵌入,即具体在两个独立的空间方向上分别采用一维全局池化操作,将输入信息聚合成该方向的感知特征。然后将这两个特征映射分别编码成两个注意映射,协调注意编码横向和纵向空间方向上的远程依赖关系和位置信息,然后进行特征聚合。其次坐标信息特征图生成,即先对上述两个变换在空间维度上进行拼接,再通过卷积变换函数F1进行信息变换。变换公式如式(1)所示:
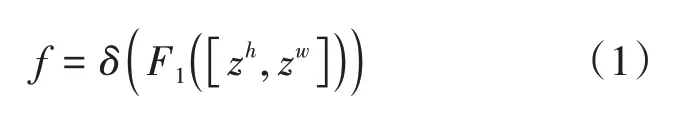
其中δ为非线性激活函数。再将f分解成两个独立的张量fh和fw,之后利用卷积Fh和Fw变换得到与输入相同的通道数,其变换操作如式(2)、式(3)所示:

其中σ为Sigmoid 函数。然后扩展上述结果,作为注意力权重,得到输出y。如式(4)所示,其中xc(i,j)表示输入特征图,ghc(i)和gwc(i)表示两个空间方向的注意力权重。

2.2 边框回归损失函数
原始算法边框回归损失为GIoU,其解决了传统IoU存在的当预测框和目标框没有重叠部分时,所出现的梯度消失的问题,但其同时也存在收敛慢及回归不准确的问题。其中GIoU 计算公式如式(5)所示:

其中A和B分别为目标框和预测框的面积,C为能够包围住A和B的最小的框的面积。本文将采用CIoU Loss[12]作为边框回归损失函数,CIoU 引入中心点距离,解决了当两框出现包含时,两框的距离变化但其损失不变的问题。同时考虑了长宽比的差异问题,解决了当两框中心点发生重合,但两框的长宽比不同时其损失不变的问题。CIoU Loos 能够很好地解决GIoU Loss的不足,从而提升边框回归预测能力,其公式如式(6)所示:
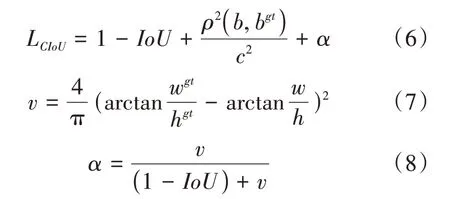
其中两框的中心点分别为b,bgt。式(7)中w,wgt分别代表了两框的宽度,h,hgt分别代表两框的高度。式(8)中α表示权重参数,v表示预测框与目标框的长宽比差异。
2.3 Ghost模块
2.3.1 Ghost卷积
Ghost 模块是华为诺亚方舟实验室在Ghost-Net[13]网络中提出的。其卷积操作主要由一般卷积层和线性变化层组成,Ghost 卷积操作如图2所示。

图2 Ghost卷积结构
如图2所示,Ghost 卷积先经过普通卷积,然后分别经过一次恒等映射和m次线性变换。其中Φ1、Φ2、Φ3表示对应的线性操作,最后将恒等映射和线性变换后的特征图拼接后输出。
假设原始的输入特征为X∈ℝW×H×C,经过普通卷积的输出为Y∈ℝW'×H'×M。其中W'×H'为普通卷积输出尺寸,M为通道数,同时令卷积核大小为k×k,则普通卷积运算后的计算量F1可表示如式(9)所示:
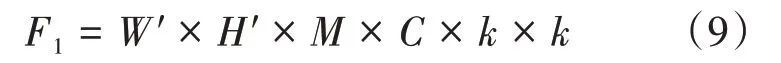
与普通卷积不同,Ghost 卷积对于同样的输入特征图,首先经过一个普通卷积运算转化为输出Y'∈ℝH'×W'×m。再对Y'进行m 次线性操作,每个线性操作输出通道数为s,则共生成M=m×s个特征图[14]。同时令每个线性操作的卷积核大小为d×d,则一般卷积计算量F1和Ghost卷积的计算量F2比值如式(10)所示:
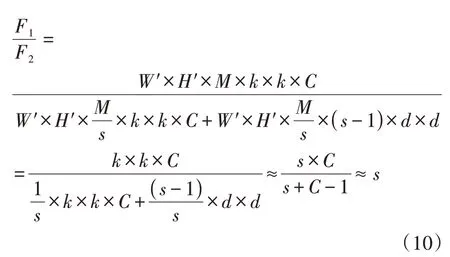
由式(10)可知,Ghost 卷积计算量大概是普通卷积的1s。
2.3.2 C3Ghost模块
C3Ghost 模块是通过对C3 模块中的Bottleneck进行修改得到的,结合Ghost模块的特点得到新的Ghost-BottleNeck结构,其结构如图3所示。
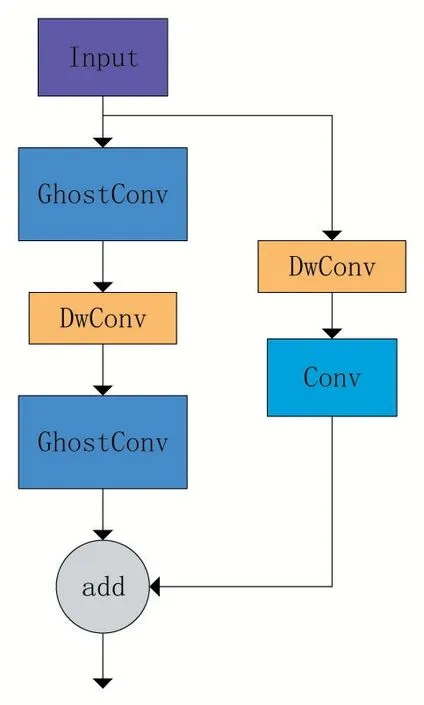
图3 Ghost-BottleNeck结构
Ghost-BottleNeck 结构由两个分支组成,首先是左分支经过一个Ghost模块进行卷积运算减少特征通道数,然后通过深度卷积(Depthwise Convolution,DWConv)执行下采样操作,改变特征尺度,再通过Ghost 模块增加特征的通道数。右边经过一个深度卷积减少特征尺度,再通过一个Conv 结构的卷积层增加通道数,此时左右分支得到相同的通道数再相加[15]。结合了Ghost 模块在卷积过程中的特点得到新的C3Ghost结构,其结构如图4所示。
如图4所示,C3Ghost 为了提高特征的重用性,首先复制输入特征图,然后分别送入上下两条支路进行操作。其中下面的支路主要是实现通道数缩减,上面的支路首先经过Conv 结构减少通道数,然后进入Ghost-BottleNeck 进行多次操作。随后将两支路输出进行拼接,再进行一次Conv卷积层的操作,以调整输出通道数。

图4 C3Ghost结构
结合以上三点的改进,最终的改进算法的结构如图5所示。

图5 改进后算法结构
3 实验结果与分析
3.1 实验环境及数据集
本文实验环境配置:显卡为GeForce RTX 2080 Ti,11 G 显存,CPU 为Intel(R)Xeon(R)Platinum 8255C,操作系统为ubuntu20.04。实验框架为Pytorch1.9.1,开发环境Python3.8,CUDA11.1版本,训练迭代次数为300次。
数据集采用东北大学(NEU)的钢材表面缺陷数据集。整个数据集总共包含了钢材表面常见瑕疵的6 个类别,每个类别300 个样本。分别为轧制氧化皮(Rolled-in Scale,RS)、银纹(Crazing,Cr)、斑块(Patches,Pa)、杂质(Inclusion,In)、划痕(Scratches,Sc)、点蚀表面(Pitted_Surface,PS),训练之前随机按照80%训练集、10%验证集和10%测试集划分。
3.2 评价指标
为了验证改进后算法的性能,需要选择合适的评价指标进行系统模型的评价。本文选取的评价指标包括:准确率(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP),网络参数量大小(Parameters)等。
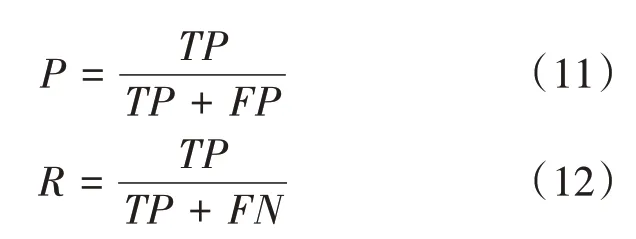
由式(11)和式(12)可知,对应本文数据集的检测识别种类,以银纹(Crazing)样本为例,TP为模型检测银纹类别正确识别的数量,FP表示识别错误或者没有识别的数量,FN表示将银纹识别成其他类别的数量。AP为PR曲线下方面积,mAP为所有AP求和取平均后的值。
3.3 实验结果分析
3.3.1 对比实验分析
为了体现CA 注意力机制对模型性能的提升,以及对比其他的注意力机制的优势。现与CBAM[16]、SE[17]以及ECA[18]注意力机制进行对比实验,分别添加至主干网络的相同位置。结果记录如表1所示。
由表1结果可知,CA 注意力机制对网络的提升性能比其他注意力机制更好,其检测的准确率、召回率以及mAP值都是最高的。CA 注意力机制与SE 注意力机制相比,在基础上考虑了空间位置信息,能够更好地定位瑕疵的位置。检测准确率提高1.7 个百分点,mAP值高0.7 个百分点。与其他注意力机制检测效果单独对比,CA 注意力机制对大部分瑕疵类别的检测准确率要高。其中mAP最高为73.3%,较CBAM和ECA 注意力机制分别高1.2 和0.7 个百分点,较YOLOv5提升了1.4个百分点。
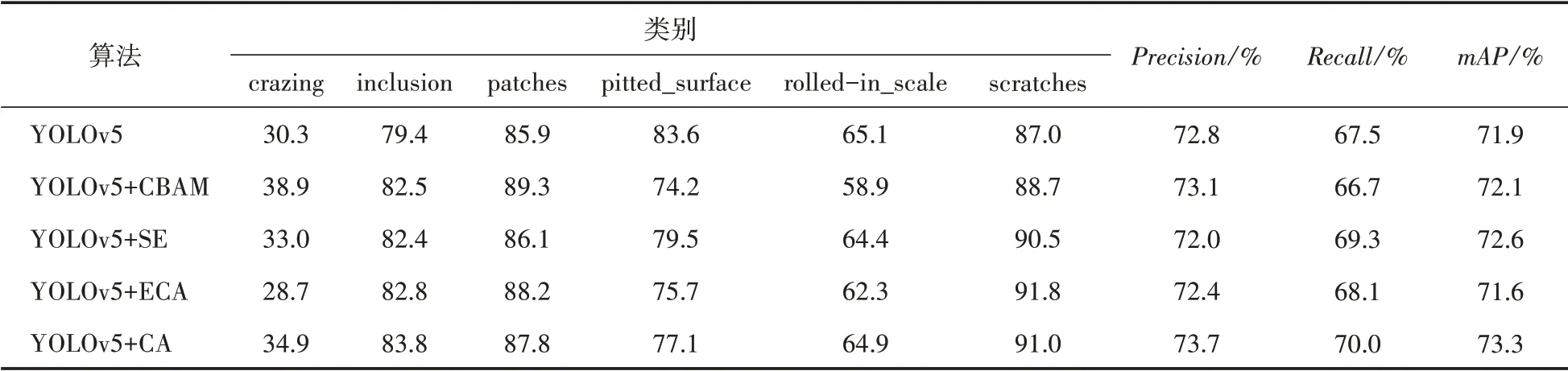
表1 不同注意力机制对比
为了验证使用CIOU Loss 做为损失函数时检测性能的提升,进行了几种主流的边框回归损失DIoU[19],EIoU[20]的对比实验,验证其对模型性能提升优势。结果如表2所示。
由表2可知,原始的边框回归损失函数,其检测对模型的性能提升有限。相对于使用其他损失函数,大部分瑕疵类别的检测能力有限。使用CIoU Loss 作为边框回归损失函数,其对检测性能有较好的提升。其引入中心点之间的距离、考虑长宽比,能够做到更好地回归。其中mAP值较GIoU、DIoU 以及EIoU 分别提升了2.2、0.3和1个百分点。

表2 不同边框回归损失函数对比
为了验证各改进点对本文算法的提升,在原始YOLOv5 网络的基础上分别使用各改进点,记录各瑕疵类别的平均检测精度,并将其作为评价指标,结果如表3所示。同时消融实验结果如表4所示。
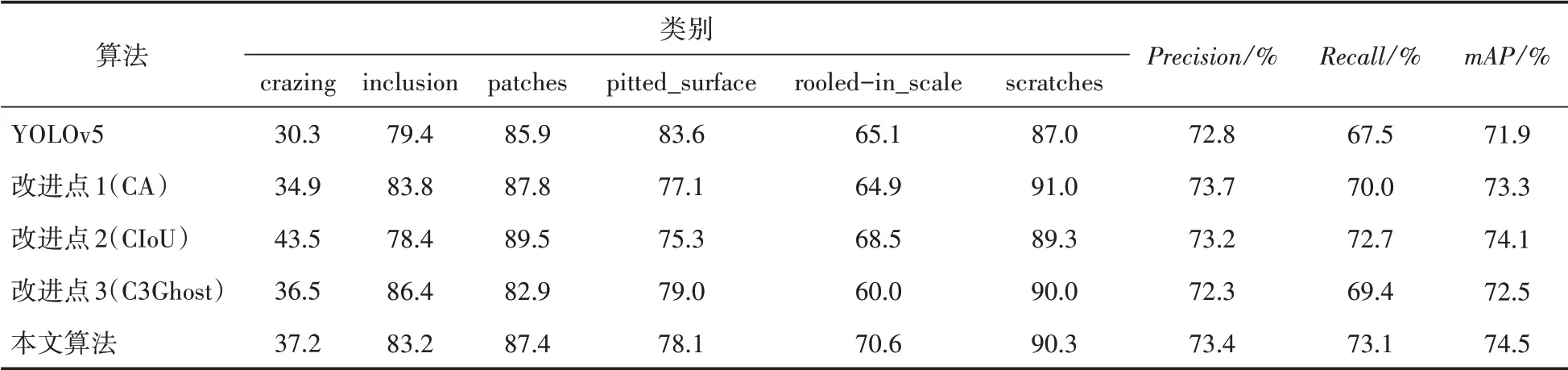
表3 各改进点对比实验

表4 消融实验
由上表3可知,改进点1 能够有效地提升系统的性能,加强主干网络的提取能力,对比各瑕疵的检测平均精度,除点蚀表面(pitted_surface)、轧制氧化皮(rooled-in_scale)两个类别的检测能力没有提升,其他类别的检测精度都有显著的提升。其中mAP值提升了1.4 个百分点。改进点2提升预测框的回归定位能力,有效地提升了系统的性能,检测精度提升较大,有0.9 个百分点,召回率提高2.5个百分点以及mAP值提升1.4 个百分点。改进点3 使用轻量级的网络结构,能够有效地减少网络模型的模型参数量。
由表4可知,原始的YOLOv5 网络检测精度以及召回率各参数值都较低,参数量较高。添加CA 注意力机制后,提高检测精度但同时也增加了算法的参数量,参数量增加0.01 M。提升主干特征提取能力的同时改变边框回归损失方式,有效地提升检测精度,相比单独使用CA 注意力机制提升了1.5 个百分点,mAP值提升1.9个百分点,参数量并未增加。最后引入C3Ghost模块,检测精度有少许的降低,参数量在前者基础上减少,一定程度上抵消了注意力机制带来的网络参数量的提升。相较于原始的YOLOv5算法,本文改进算法在各评价指标上都有一定的提升,同时网络模型参数量更少。
为了体现本文算法相比与其他检测算法的性能优势,进行了对比实验,结果如表5所示。得到各目标检测算法的平均检测精度及mAP值,另外引入在测试集检测后的模型的平均推理时间(Inference time)作为模型的速度对比。
由表5可知,使用Faster-RCNN 算法检测,其推理时间最长为170.36 ms。本文算法推理时间最短为4.8 ms,极大地提升了检测速度。相对于同为单阶段目标检测算法的SSD 以及YOLOv3算法,本文算法的参数量较少,仅为6.1 M,为较轻量的网络。同时本文算法的mAP值最高达74.5%。
3.3.2 检测结果显示
为了直观地体现改进后的YOLOv5算法对工业钢材瑕疵检测的效果,经过对测试集的数据测试后得到测试结果,选取各瑕疵类别的测试结果进行对比显示。检测结果如图6所示。
对比图6(a)和图6(b)可知,改进后的算法的检测能力及检测准确率有显著的提升,如瑕疵类别:杂质(inclusion),点蚀表面(Pitted_Surface)等,在原始算法中检测精度较低,而且存在检测不全及检测范围不全的问题。改进后的算法参与了更大的空间检测,对瑕疵的定位更加准确,且解决了存在的漏检的问题,对存在的瑕疵检测更全面。检测结果很好地展示了改进后的算法能实现对工业钢材检测更好的检测效果和识别率。

图6 对比结果图
4 结语
本文提出的基于YOLOv5的改进算法,解决在工业钢材缺陷检测过程中的检测效率低,检测精度不高等问题。通过使用CA 注意力机制,弱化对无用信息的关注,加强对目标的定位能力。再改变边界框回归损失函数为CIoU Loss,加强预测框的回归预测能力,以及使用C3Ghost结构简化模型大小,并进行对比实验和融合实验验证。结果表明,改进后的算法性能得到提升,参数量更少,算法推理时间较短。其中mAP值提升了2.6%,参数量减少了13.3%,在工业钢材缺陷检测中有较大的检测精度和速度。但同时由于本文是对已有数据集的训练和测试,实际工业生产过程中可能会考虑较多的外部因素。所以还需不断地完善数据库,并且开发出配套的硬件设施为实际的工业钢材生产及质量检测提供更好的辅助。
