基于深度学习的遥感影像地类信息获取技术现状研究*
2023-01-16王本礼
王本礼,王 也
(1.湖南省第二测绘院湖南长沙 410119;2.自然资源湖南省卫星应用技术中心,湖南长沙 410009;3.湖南仁晟设计有限公司,湖南长沙 410018)
土地利用动态监测是指对不同时相的土地利用数据进行对比分析,并从空间分布及数量上进行变换特征提取及分析,并为土地利用规划决策提供数据支撑。遥感影像数据具有综合、宏观以及动态等多种优势,地类自动识别则是使用遥感影像数据进行土地利用动态监测的关键技术,同时也是遥感应用和研究的重要领域。随着深度学习等人工智能技术的提出与发展,目前地类自动识别逐渐从传统的基于图像特征的方法过渡为基于深度学习的方法,并取得较为显著的成果[1]。
深度学习技术在图像处理领域已经有广泛的应用基础,如人脸识别、图像匹配等。当前,基于深度学习的遥感影像地类自动识别技术主要分为遥感影像分割、遥感影像分类以及遥感影像目标监测三种方式。
1 基本概念
1.1 深度学习
深度学习是机器学习的子集,主要基于多层人工神经网络进行特征学习。因人工神经网络具有多个输入、输出以及隐藏层,且学习过程具有深度性,从而得名。机器学习则是人工智能的子集,主要采用可以让机器根据历史信息及经验在任务中做出改善的技术。人工智能则是让机器模拟人类智能的技术。三者的关系示意图如图1所示。
深度学习引起强大的信息处理能力,逐步成为机器学习领域最接近人工智能的方法。随着深度学习发展,各种具有特殊处理单元和网络结构的神经网络不断涌现,但其基本结构都是由激活函数(非线性)连接多个线性结构构成,主要分为输入层、隐藏层及输出层。其中输入层和输出层主要和任务相关,而隐藏层则决定该网络结构的具体功能。根据网络结构不同可以分为卷积神经网络、自动编码机等[2]。根据训练数据是否存在标签以及标签来源可以分为监督学习、半监督学习以及无监督学习[3]。

图1关系示意图Fig.1 Schematic diagram of the relationship
1.2 遥感影像分割
图像分割是计算机视觉的一项基本任务,也是许多视觉理解系统的重要组成部分[4]。图像分割主要通过将图像(或视频帧)划分为多个对象,以获取边界及目标物的面(体)积特征等,图像的输入和输出通常都是图像[5]。这项工作的重点是语义图像分割[6],在地类监测中,通常对遥感影像进行地块分割,以获取地块边界及地块面积信息,具体示例如图2所示。
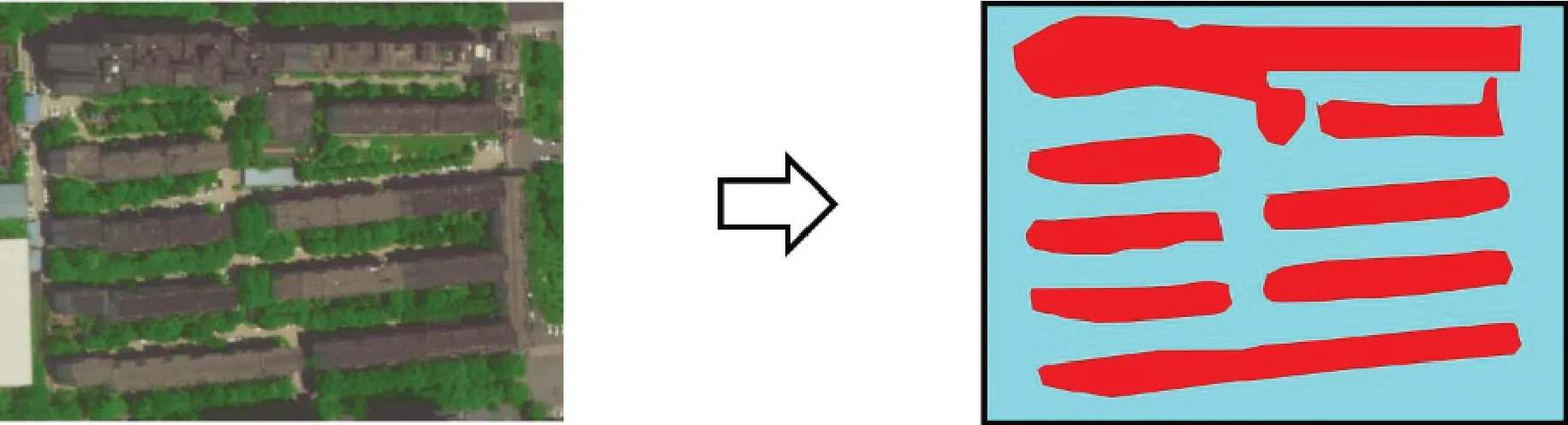
图2 分割示例Fig.2 A toy example of image segmentation
1.3 遥感影像目标检测
目标检测是模拟人类视觉浏览观测物体的方法,即通过算法从图像或视频中识别研究目标的位置及方向,从而实现对客观世界的感知、识别与理解。早期目标检测主要采取传统手工特征提取的方法,采取滑动窗口的方式遍历整张图像,并从中选取一定数量的候选框进行特征提取,如颜色、纹理、形状等。而后通过支持向量机(SVM)等分类算法进行候选框分类,最终确定目标内容[7]。但手工特征难以设计,且手工特征不具有鲁棒性,效率低,且滑动窗口提取策略非常繁琐。随着深度学习算法的发展,使用深度学习算法进行图像特征提取逐步成为主流,而模型的输入与输出示例如图3所示。

图3目标检测示例Fig.3 A toy example of object detection
1.4 遥感影像分类
图像分类是根据图像信息中反映的视觉特征如色彩等,把不同类别的图像区分开的数据处理方法,模型的输入通常是图像,输出往往是类别集,如图4所示。

图4 影像分类示例Fig.4 A toy example of image classification
遥感影像分类通常是指对已经切分好的地块进行分类,属于图像分类的子课题[8]。遥感影像分类算法根据训练样本中包含标签的情况可以分为监督学习、半监督学习和无监督学习。监督学习是指利用已知类别的样本进行模型训练,如深度卷积神经网络等。而半监督学习和无监督学习通常是指用缺失一部分或者全部图像标签的数据进行模型预测,通常是利用聚类或相似度等算法进行图像类别预测。此外,近几年来,无监督学习领域衍生出一种新型训练方式——自监督学习[9],该方法主要通过大量无标签数据训练出一个特征提取器,再利用该特征提取器对下游任务的神经网络模型进行训练,获取下游任务相应的。
2 相关技术
本文主要介绍图像领域经典的卷积神经网络模型结构以及近期的主流模型——Transformer模型基础。
2.1 卷积神经网络模型基础
卷积神经网络模型是图像领域深度学习技术的基础架构。卷积神经网络属于深度前馈神经网络,主要包含输入层、隐藏层和输出层[10],如图5所示。

图5 卷积神经网络结构示例Fig.5 Overview of convolutional neural network structure
其中隐藏层通常包括卷积层和池化层以及全连接层。输入层进行数据接受,隐藏层进行图像特征提取,输出层进行结果输出。其中卷积操作是指通过一个感受野即图中的蓝色方块根据一定步长对图像进行遍历扫描,从而获取图像的特征。因此,卷积操作本质上可以视为通过感受野进行的一种特征筛选。而池化层相当于对卷积层输出做下采样,卷积操作之后图像的维度会急剧增长,难以直接应用,因此需要通过池化操作选取局部最突出的输出,再进行分类操作。根据不同的池化方式可以分为最大池化、平均池化以及最小池化等,即取每个过滤器中最大值、平均值或最小值等。全连接层的主要作用是进行分类,通过综合前面通过卷积和池化获得的特征,最后进行最后输出[11]。
2.2 Transformer基础
Transformer 架构最早是应用于自然语言处理领域,其架构如图6所示。
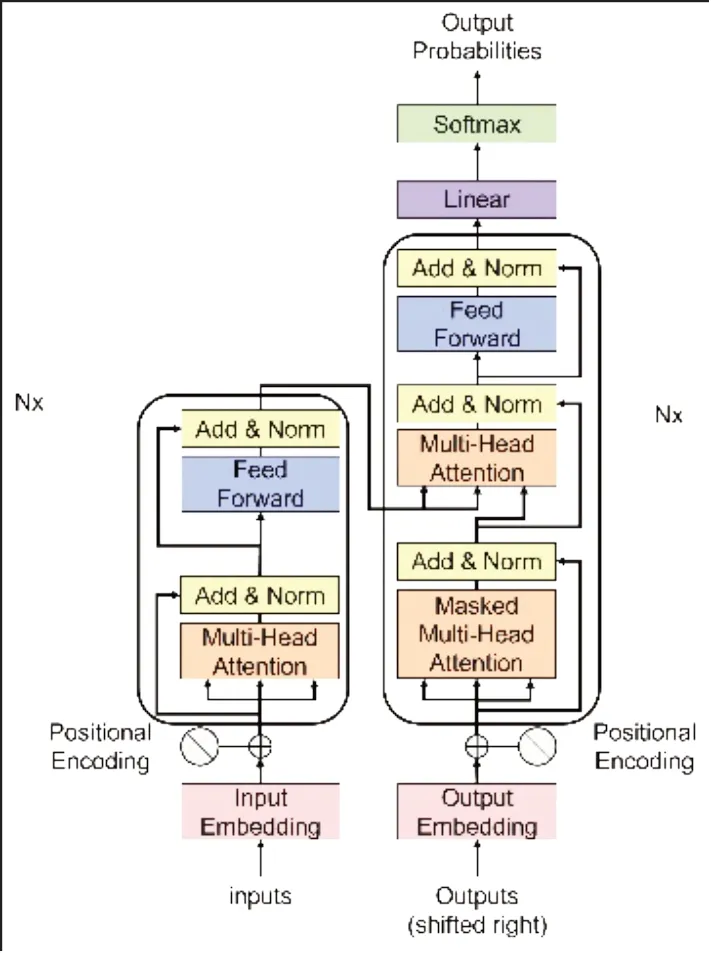
图6 Transformer模型架构Fig.6 Overview of transformer structure
该模型整体为一个端到端(encode-todecode)的架构,完全抛弃了CNN 和RNN 结构,而是使用注意力机制(自注意力机制和多头注意力机制)。如图7所示。
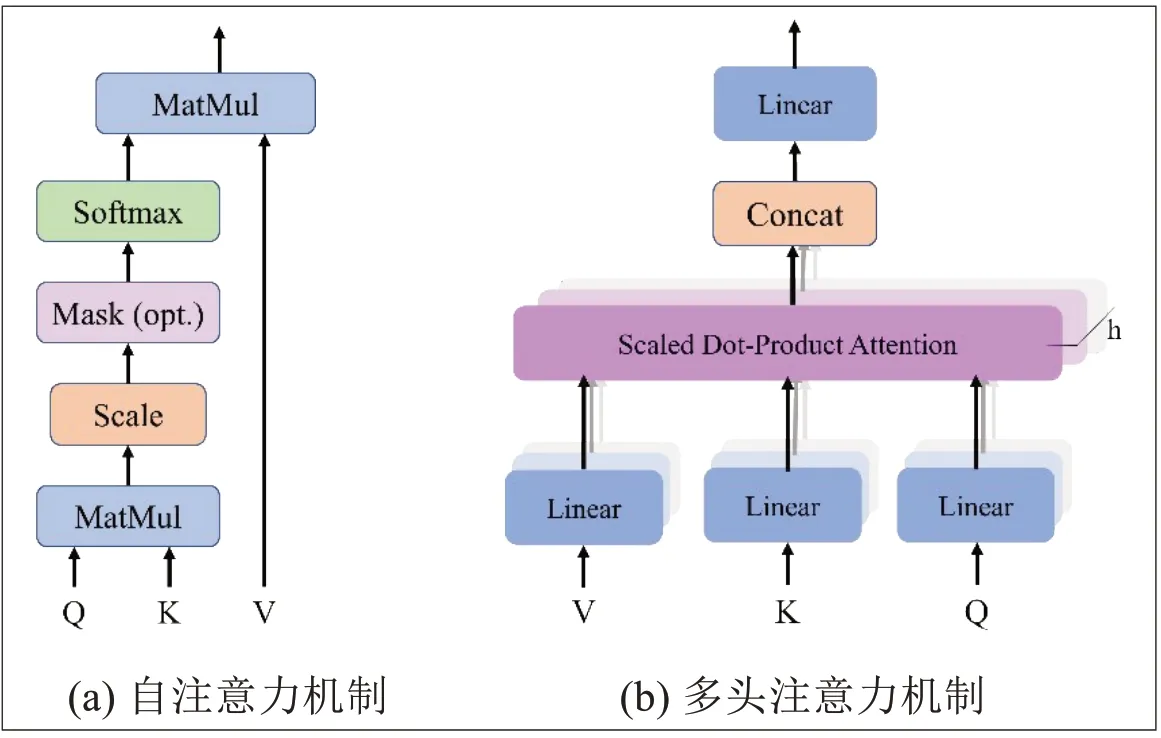
图7 Transformer中的注意力机制Fig.7 Structure of attention mechanism
在自注意层(Self-Attention Layers)中,输入向量首先被三个投影矩阵转换成三个不同的向量,即查询向量Q,键向量K 与值向量V。不同输入向量间的注意函数则可以通过以下步骤获得:
第一步:计算不同输入向量间的得分(score),

第二步:为了稳定梯度对得分归一化,

第三步:使用softmax函数将得分变为概率,

第四步:获得加权数值矩阵,

综上所述,自注意力机制的计算公式为,

而多头注意力机制则是用于提高自注意力机制的性能。具体来说,给定一个输入向量与头的数量h,输入的向量首先变换成三组不同的向量,即查询组、键组、值组。每组分别有h个维度,即dq'=dk'=dy'=dmodel/h=64。然后,将来自不同输入的向量合并在一起生成三组不同的矩阵以及。再将三组矩阵分别拼接为Q',K'以及V'。则多头注意力机制的计算公式可以表示为:

其中headi=Attention(Qi,Ki,Vi),Wo=∈Rdmodel×dmodel为一个线性投影矩阵。当前,Transformer在图像领域的经典模型主要包括iGPT 模型和ViT 即Vision transformer模型[12]。
3 相关数据集与对应SOTA模型分析
本章分别对图像分割、目标检测以及图像分类三个领域的经典遥感影像数据集进行详细分析。
3.1 图像(语义)分割
BigEarthNet 主要使用Sentinel-2 卫星数据,由590326 个图斑块组成,区域涵盖了奥地利、比利时等十个欧洲国家。每个图斑块都由CORINE 土地覆盖数据库(CLC 2018)提供标注。目前,该数据集的SOTA 模型为MoCo-v2 模型,该模型为MoCo 模型的改进版本。MoCo 是动量对比的缩写,属于无监督学习中的自监督学习[8],通过对无标签数据集进行预训练,获取图像表征。但这种方式需要强大的算力,即Google TPU的加持。而MoCo-v2则对此进行改进,该模型仅需8 个GPU 即可进行模型训练。最终该模型在BigEarthNet 的准确率高达89.3%。但该模型相较于其他模型需要额外的训练数据,且对Big-EarthNet算力的要求相对较高。
此外,不同地类获取子任务也具有特有的数据集,如城市景观相关的GTA5,ADE20K 以及Foggy Cityscapes 等,以及城市建筑物相关的INRIA aerial image数据集等。
3.2 目标监测
本文主要介绍DOTA 系列数据集。该数据集共包含三个版本。
3.2.1 DOTA-v1.0
最早的DOTA 数据集是用于航空图像物体检测的大型数据集,其来源包括多个传感器和平台,每个图像的大小范围从800×800 到20000×20000,包含多种比例、方向以及形状的对象。该数据集共包含15 个常见类别,2806 张图像,188282 个实例,当前该数据集的SOTA 模型为DAFNe 模型,获得了76.95 的性能。该模型为一个用于定向目标检测的一阶段Anchor-Free 深度学习模型。Anchor-Free 模型这个概念很早就被提出了,如大名鼎鼎的YOLO-v1 就属于Anchor-Free 模型。这类模型的主要缺陷包括正负样本失衡、超参难以调试以及训练匹配耗时严重等。以下为不同模型在DOTA-v1.0 上的性能表现变化如图8所示。

图8 DOTA-v1.0数据集上不同模SOTA型变化图Fig.8 Performance of different SOTA models of DOTA-v1.0
3.2.2 DOTA-v1.5
DOTA-v1.5 是数据集在v1.0 的基础上增加了集装箱起重机对象类别,并对小于10像素的极小实例冶金学了标注。该版本共计包含403,318个实例。该数据集主要用于航空图像中的物体检测。该数据集的SOTA 模型也是DAFNe模型,获得了71.99的成绩。
3.2.3 DOTA-v2.0
DOTA-v2.0 则增加了更多谷歌地球、GF-2 卫星和航拍影像,该数据集共18个常见类别,11268张图片,1793658 个实例。当前DOTA 数据集在航空图像目标检测的SOTA 模型为ViTAE-B +RVSA-ORCN,该模型是视觉Transformers模型与遥感影像结合的产物,提出将遥感影像目标获取作为一个大型数据集任务,并提出一种旋转可变大小窗口的注意力机制代替原始Transformers 中的全注意力机制。最终,该模型在DOTA 数据集上取得了81.16%的性能。值得注意的是,该成果中提出的另一模型ViT-B+RVSA-ORCN 排名第二,取得了81.01% 的性能。不同模型在DOTA-v2.0上的性能表现变化如图9所示。

图9 DOTA-v2.0数据集上不同模SOTA型变化图Fig.9 Performance of different SOTA models of DOTA-v2.0
3.3 遥感影像分类
3.3.1 UC Merced Land-Use
UC Merced Land-Use 数据集是由UC Merced 计算机视觉实验室公布的遥感图像场景分类公开数据集,数据集共分为耕地(agricultural)、机场(airplane)、棒球场(baseball diamond)以及沙滩(beach)等21 个类别。每个类别各包含100 张遥感影像,整个数据集共计2100 张256×256 的遥感影像。这个数据集数据量级较小,无法训练大型数据集,因而常被用作示例讲解。该数据集最新的SOTA 模型为MSMatch,该模型属于半监督模型,该模型的损失函数等于监督学习损失函数和无监督学习损失函数之和。监督学习部分损失函数即模型预测标签与真实标签之间的差异,而无监督学习部分则是预测标签与伪标签之间的差异[13],最终该模型在UC Merced Land-Use 数据集上的预测准确率高达98.33%。尽管该模型在部分数据集上达到了媲美监督学习的性能,但因伪标签获取需要,将该模型应用于大型数据集时的代价仍有待商榷。此外,与该数据集量级相近的 还 有WHU-RS19,RSC11,SIRI-WHU 以 及RSSCN7等。
3.3.2 EuroSAT
EuroSAT 是由欧洲卫星组织(EuroSAT)发布的,基于Sentinel-2 卫星的土地利用和土地覆盖分类数据集,涵盖13 个光谱波段,由10 个类组成,共计27000 条数据。上文提及的MSMatch 模型曾以该数据集作为基准模型,并达到SOTA 效果。当前该数据集的SOTA 模型为MoCo-v2 模型。
整体而言,遥感影像(语义)分割领域因其算法复杂度较高,因此,目前研究的重点主要集中于降低对高性能设备的依赖。目标检测则主要集中于对Anchor-Based 与Anchor-Free 算法以及两者融合算法的研究,试图避免或者减弱两者缺陷带来的影响,并提升性能。而遥感影像分类领域目前的研究主流为半监督和无监督(尤其是自监督)学习研究,以减少对人工标签的依赖。
4 目前不足与展望
4.1 深度学习方法的选择
理论上遥感影像地类信息获取可以采用影像分割、目标识别以及分类等任何方式,可以采用任意深度学习方法。但在实际应用中,采用不同的问题定义方法或者模型将直接决定最终数据获取的精度及时效,不同的模型应用于同一个问题表现出的学习能力、运行速度和自适应性都各有不同,且各模型各具优势与不同。因此,在后续的应用中需要更加深入地分析问题特征,选择合适的定义方式与模型。
4.2 地物识别精度
地类识别精度受到多种挑战,如遥感数据集缺乏人工标注、数据类型的多样性愈发丰富以及大研究区域的复杂性等[14]。针对第一个问题,尽管当前无监督学习包括自监督学习等得到一定的进步与发展,但并没有取得通用且令人满意的成就[15]。因此,在后续的研究中可以进一步加强对无标签数据的特征提取。针对第二个问题,随着遥感技术的发展及高光谱遥感的进步,遥感影像的质量及清晰度取得了较大进步。但不同地物的识别或应用场景和获取往往需要训练不同的模型,造成计算成本的增加。在后续的研究中可以促进对通用模型或研究范式的研究。针对第三个问题,目前研究大多局限于某个小区域的研究,对大研究区域的精细化研究并没有取得明显突破。但在政府等机构的应用和监测中,往往需要对某一行政区域进行统一监测,尤其是进行土地利用规划时,往往需要对全域地类地物信息进行综合了解、评估及判定。
4.3 地物识别代价
在深度学习的研究中,地物识别精度的提升往往意味着神经网络模型的深度、参数量以及模型复杂度等的提升,这也意味着模型训练及响应成本的增加。因此在后续的研究中,可以考虑在不牺牲识别准确度的前提下,进行优化,降低计算及时间成本,如通过模型优化降低计算成本,通过并行分布式计算提升模型训练及响应速度。
5 结语
随着遥感技术的发展,使用遥感影像数据进行土地利用动态监测逐步成为进行自然资源管控的重要技术手段,该类技术能够为土地利用监测、国土空间规划以及国家安全等提供实时准确的数据信息和参考依据。传统基于手工特征或传统机器学习的方法逐步无法满足当前社会对遥感影像地物识别精度及获取速度的需求。深度学习模型凭借其强大的特征提取能力,逐步成为利用遥感影像进行地类自动识别的主流方法,基于深度学习的模型具有更高的识别精度、更低的人工识别成本以及自适应性。但深度学习模型在实际应用中,仍需要注意问题定义及模型选择,仍需加强对识别精度及相应代价的进一步提升。随着遥感技术的进一步提升,后续相应信息提取模型的要求也将进一步提升,因此,融合深度学习等新兴人工智能方法与遥感影像传感器等,是未来自然资源智能监测技术发展的必然趋势。
