Krotos Dehumaniser 2生物/怪物语音特效制作原理浅析
2023-01-16夏田
夏 田
北京电影学院声音学院,北京 100088
1 引言
生物/怪物语音特效制作一直以来都是影视、游戏声音制作中充满挑战的问题,通常要根据制作项目的具体需求,综合运用配音、编辑、声音合成、效果处理等多种手段完成制作。英国Krotos公司推出的语音特效制作插件Dehumaniser 2通过模块化方式让用户在该插件内部自行搭建效果处理链,提供10种专门面向生物/怪物语音特效制作的处理模块及200多种预置,为生物、怪物、外星人、机器人等特效声音设计构建了一种便捷的解决方案,并在《复仇者联盟2:奥创纪元》 《惊奇队长》 《星际迷航》《攻壳机动队》等影片中得到了运用。
本文将对Krotos Dehumaniser 2提供的粒子合成、延时音高平移、磁带摩擦卷积处理模块的工作原理进行分析,并统计原厂预置对各种模块的组合及使用频次,初步归纳生物、怪物等语音特效制作的常用声音处理手段,同时在Native Instruments公司推出的通用声音合成平台REAKTOR 上进行简单仿真验证。
2 KrotosDehumaniser2 简介
Dehumaniser是Krotos公司推出的第一款声音设计工具产品,源自该公司创始人奥菲斯·博蒂斯(Orfeas Boteas)在英国爱丁堡大学攻读硕士学位时进行的研究项目。博蒂斯在Max/MSP 环境下编写了程序,能够让声音制作者运用自己的语音实时进行怪物、机器人、生物声音特效制作。在传统声音制作方式中,制作这类声音特效需要综合运用多种效果处理方式以及大量的动物声音素材,既费时又费力。博蒂斯通过编写这个程序,简化了制作流程,同时实时表演的方式也能更好地激发声音制作人员的创造力。在爱丁堡大学的支持下,2013 年9 月,博蒂斯与他人联合创办了Krotos公司,并于同年11月发布了经过商业化改造和增强的独立软件Dehumaniser专业版。2016年5月,Krotos公司发布了升级后的Dehumaniser 2,对内部算法进行了改进优化,加入了新的处理模块和声音素材库,并引入了基于节点的模块化信号处理方式,为声音制作者提供了更大的创作空间。
3 Dehumaniser2 部分模块工作原理分析
Dehumaniser 2 并非一个简单的效果器插件,而是一个模块化的声音处理平台。它提供了10种效果/功能模块,允许用户在该插件内部自主选择使用哪个或哪些模块,并允许用户自由搭建各个模块之间的信号路由,从而能够产生出千奇百怪的声音特效。遗憾的是,Dehumaniser 2 的官方文档并未详尽介绍这些模块的工作原理和使用方法,本节将通过实验的方式,对其中部分模块进行工作原理分析。
3.1 Granular模块
粒子合成模块Granular通过把声音切割成若干粒子(片段)来产生一些新奇的效果,它可以改变音高以及声音的质感,产生低声细语或是粗粝声音的效果。此外,Granular模块还可以只重现输入声音的某些部分,并在这些部分之间插入静音,从而产生奇异的效果,非常适合制作异星语言。该模块包含6个参数:Grain Pitch、Grain Pitch Variation、Grain Size、Density、Density Variation 和 Max Voices。
3.1.1 Grain Pitch与Grain Pitch Variation
Grain Pitch参数控制声音粒子的变调程度,该参数的含义是频率比,即当Grain Pitch为2.0时,音高升高一个八度;为0.5时,音高降低一个八度。实验表明,Granular模块采用类似于重采样的方式进行变调,即粒子时长会跟随音高变化同步变化:音高升高导致时长缩短,音高降低导致时长伸长。通过实验发现两个需要注意的问题: (1) 当音高降低过多(即参数接近0时),音高会在两个音调之间来回摆动; (2) 参数最小值为0,但实际上,小于0.1的参数不会带来音高的进一步变化。Grain Pitch Variation 参数令每个声音粒子的音高以Grain Pitch设置的音高为中心随机变化,变动范围为±Grain Pitch Variation个半音。
3.1.2 Grain Size
该参数名义上设置的是每个声音粒子的长度,但以恒定幅度的单频正弦波作为输入信号进行测试后发现,该参数的实际效果是设置了声音粒子的最小长度。从图1中可以看出,若假设Grain Size设置为GS毫秒,则粒子长度大致在 [GS,GS+60]毫秒之间均匀分布。此时,Granular模块其他参数设置为Grain Pitch=1.00,Density=0,Variation=0,Max Voices=1。
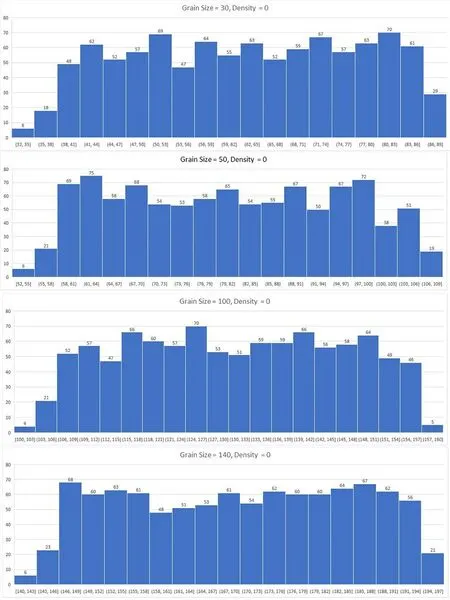
图1 Grain Size分别为30、50、100、140毫秒时,对Granular模块产生的1000个声音粒子的时长进行统计后绘制的直方图
图2 为Grain Size 分别设置为30、50、100、140毫秒时,Granular 模块对输入的单频正弦波(振荡频率为375 Hz)的输出波形。从图2中可以看出:每个声音粒子的长度是随机变化的,但粒子与粒子之间的时间间隔是恒定的 (即当前声音粒子的起始点与下一个声音粒子的起始点之间的时间间隔始终为200毫秒,由下文可知,这是因为Density设置为0);每个声音粒子的淡入和淡出包络呈对数线性变化。

图2 Grain Size分别为30、50、100、140毫秒时,7个相继的声音粒子的波形图
3.1.3 Density与Density Variation
Dehumaniser 2的操作手册中仅仅提到 “Density参数能影响相继声音粒子之间的时间间隔”。通过测试可知,该参数影响相邻两个声音粒子的起始点之间的时间间隔:Density=0 时,时间间隔为200毫秒;Density=10 时,时间间隔为180 毫秒;Density=20时,时间间隔为160毫秒。以此类推,即时间间隔大约为200-Density×2毫秒。
由于Granular模块的每个声音粒子长度实际是在[GS,GS+60]毫秒之间均匀分布的,因此,即使Grain Size设置为最小值GS=1,该模块实际产生的声音粒子的时长仍然有可能达到60 毫秒左右,所以,当Density≥(200-GS-60)/2时,相继声音粒子就有可能出现重叠。
Density Variation参数控制了添加到Density的随机量,数值越高,各个粒子之间时间间隔的变动越明显,这将产生更加分散的抖动输出。通过测试可知,若Density Variation参数的数值设置为DV,则相邻两个声音粒子的起始点之间的时间间隔在[d,d+DV]之间均匀分布,其中d=200-Density×2。所以,需要注意的是,DV 值越大,实际的声音粒子的密度越低。
3.1.4 Max Voices
该参数用于控制同时发声的声音粒子数。当声音粒子之间的时间间隔小于声音粒子本身的时长时,就会出现多个声音粒子同时发声的情况,如图3所示。

图3 Max Voices分别为0和2时的波形图(Grain Size=20,Density=80)
(1) 若Max Voices为0,则不会出现多个声音粒子同时发声的情况,此时,前一个声音粒子播放完毕之后,才会播放下一个粒子,并且中间不会有间隔。
(2) 若Max Voices为1,可能会与设置为0时相同,也可能能够同时播放两个声音粒子。这可能是因为Dehumaniser 2对旋钮的数值显示进行了四舍五入,导致显示数值与实际进行运算的数值不一致。
3.1.5 REAKTOR 仿真
通用声音合成平台REAKTOR 在Primary Level中提供了Grain Resynth、Grain Pitchformer、Grain Cloud、Grain Delay、Grain Cloud Delay等模块进行粒子合成。在这些模块中,Grain Resynth、Grain Pitchformer和Grain Cloud对事先导入的音频文件进行粒子重合成,无法处理实时输入的音频信号。Grain Delay和Grain Cloud Delay则是对延时缓冲区中缓存的音频输入进行粒子重合成,因此当延时时间设置得很小时,可将其近似看成对输入音频信号进行实时粒子重合成。这里选用了与Dehumaniser 2 中Granular模块功能最接近的Grain Cloud Delay模块进行仿真,实现了Granular模块的大部分功能,如图4 所示。Grain Pitch、Grain Pitch Variation (GPV)、Grain Size、Density、Density Variation都可以通过面板上的旋钮实现,Max Voices功能需要在Grain Cloud Delay模块的属性页中单独设置。
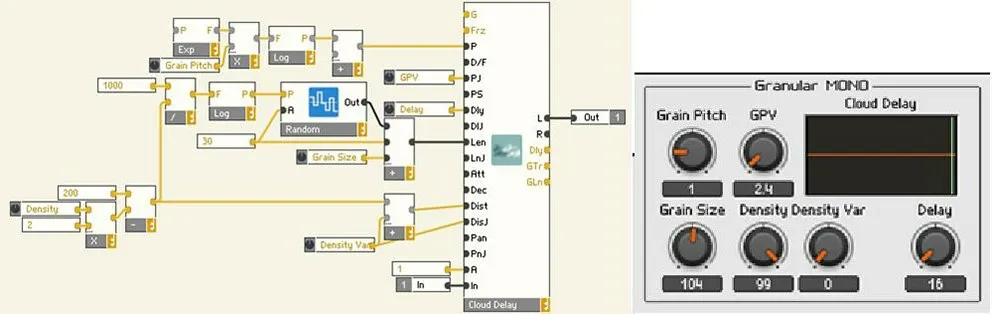
图4 在REAKTOR 中使用Grain Cloud Delay模块模仿Dehumaniser 2中Granular模块的大部分功能
3.2 Delay Pitch Shifting模块
Delay Pitch Shifting (延时音高平移)模块能够对输入信号进行延时,并同时进行音高平移。实验表明,对于单频正弦波,该模块的输出存在弧形幅度包络。通过观察输出信号频谱可以发现,即便在没有进行音高平移的情况下,该模块对于单频正弦波输入信号所产生的输出仍然含有多个频率分量,如图5所示。通过测量可知,这些多出来的频率分量之间的频率间隔几乎相等,并且随着音高平移量的增大,该频率间隔也逐渐增大。这些频率分量在输入频率成分两侧对称分布,类似于幅度调制或频率调制的频谱。从图6可以看出,这些频率分量使输出信号波形的包络产生了周期性波动。
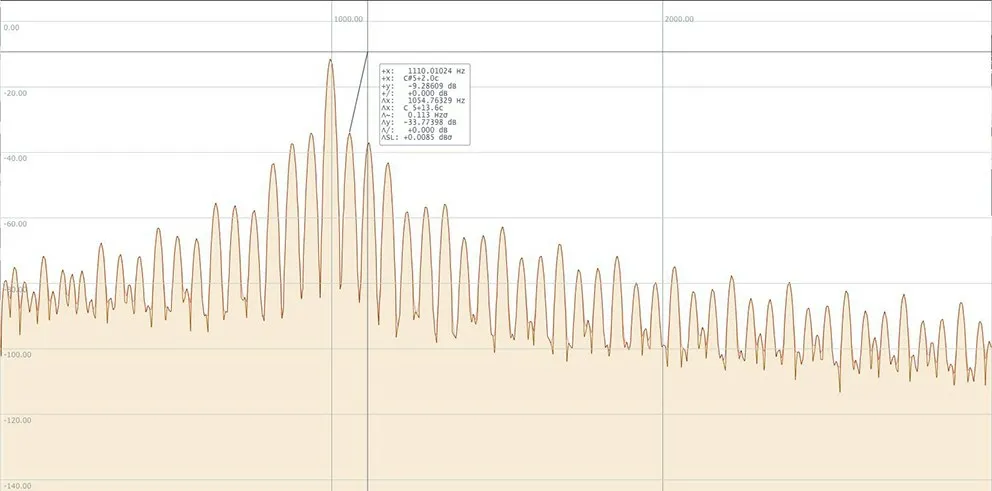
图5 Delay Pitch Shifting模块的音高偏移量为0时,输入997Hz、0dB的正弦波所产生输出信号的频谱

图6 Delay Pitch Shifting模块的音高偏移量为-1时,输入不同频率正弦波产生的输出波形
从图5中可以看出,在该模块的输出中,输入正弦波的幅度降低了12dB,同时出现了大量额外的频率成分。
Dehumaniser 2 的官方文档中没有说明Delay Pitch Shifting模块的工作原理。但我们知道,基于粒子重合成技术的延时器对延时缓冲区内的音频信号进行粒子化处理,即对音频信号进行切片并施加幅度包络,形成声音粒子,同时可以对这些声音粒子进行音高平移。为使处理后的声音听起来连贯平滑,切片(或声音粒子)的时间长度应该不大于人耳的时间分辨率,即时长在几毫秒到几十毫秒之间。此类延时器实现音高平移的最简单方法就是对各个声音粒子进行变采样率处理,这将令每个声音粒子的时长发生变化,从而需要对各声音粒子之间的间距进行相应的反向调整,以使输出声音总体时长保持不变。声音粒子间距的这种调整使得相邻声音粒子之间的交叠淡化难以实现完美的平滑过渡,从而在声音中产生了周期性的不平滑点,在频谱上就会表现为类似于图5的频谱。REAKTOR 中的Grain Cloud Delay及Grain Delay模块即采用此类工作方式产生音高被平移的延时信号,其频谱如图7 所示。据此推测,Dehumaniser 2的Delay Pitch Shift模块可能采用了类似于粒子重合成的技术对延时信号进行音高平移。
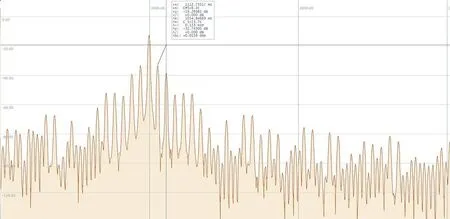
图7 在REAKTOR 中使用Grain Cloud Delay模块输入997Hz、0d B的正弦波所产生输出信号的频谱
在图7中,声音粒子长度为24.6毫秒,粒子间距为17.3毫秒,包络平滑系数为0.21。
3.3 Scrubbing Convolution模块
Scrub一词来自于模拟磁带,在这里意味着对音频文件进行 “摩擦”式的播放。Scrubbing Convolution (磁带摩擦卷积)模块通过使用粒子合成方式,产生类似于模拟磁带摩擦还音的播放效果。该模块根据输入信号A 的幅度以及用户在模块图示上绘制的映射曲线,对用户选择的音频样本B进行粒子重合成。
根据Dehumaniser 2 操作手册的描述,映射曲线的横轴方向表示输入信号A 的电平大小,纵轴方向表示被选中的音频样本B 的播放位置 (低位置表示样本的开头,高位置表示样本的结尾)。但通过实际测量发现,纵轴方向并非与播放位置呈直接的线性对应关系(参见3.3.2映射曲线一节)。
Mix可以在粒子合成引擎和卷积引擎之间进行混合。默认情况下,混合设置为50%卷积和50%粒子合成的混合。当Mix设为0时,只会听到输入音频信号与样本的卷积结果。当Mix为1时,将仅听到粒子合成引擎的输出,即根据输入音频信号的振幅,在选定文件中进行“磁带摩擦”播放。
3.3.1输入信号幅度与音频样本播放位置的映射关系
通过实验发现,在当前版本的Dehumaniser 2中,Scrubbing Convolution 模块 (以下简称SC 模块)对输入信号幅度的响应并非线性。为准确测量输入信号幅度与SC 模块音频样本播放位置的映射关系,专门构造了一个特殊的音频文件。该音频文件为一系列首尾相接、相位连续且振荡频率不断阶跃升高的单频正弦波(从1000 Hz开始),每个正弦波的振幅均为1,持续时间均为100毫秒,每个相邻正弦波的振荡频率相差100Hz。因此,0~100毫秒为1000 Hz的正弦波,100~200毫秒为1100 Hz的正弦波,200~300毫秒为1200 Hz的正弦波,以此类推,4900~5000毫秒为5900 Hz的正弦波。这样可以通过测量输出信号的频率来间接测量被播放的音频片段在原音频样本中的时间位置。
当输入信号为单频正弦波时 (振荡频率不能过低,否则容易因为振幅变化较为缓慢而导致被测量出来的输出电平发生波动),若SC 模块选取上述特制音频文件作为其音频样本,并将Mix设定为1、利用Reset Envelope按钮将映射曲线重置为对角线(图8),则能观察到:
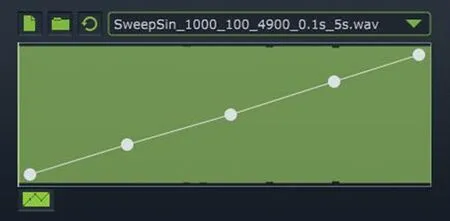
图8 利用Reset Envelope按钮将映射曲线重置为对角线
(1) 当输入信号峰值从-∞上升到-24 dB 附近时,SC模块开始输出幅度相近、频率为1000Hz和1100Hz的两个正弦波,根据专门构造的音频样本文件可知,这表明SC 模块当前正在读取的是位于音频样本最开始的200毫秒之内的部分。
(2) 当输入信号峰值上升到-16.8 dB 时,SC模块的输出信号为1100 Hz的正弦波 (同时伴有其它不太明显的频率成分,在波形上体现为振幅在不断变化)。
(3) 当输入信号峰值上升到-13.2 dB 时,SC模块的输出信号为1200 Hz的正弦波 (同时伴有其它不太明显的频率成分,在波形上体现为振幅在不断变化)。
(4) 以此类推,具体数据如图9所示。
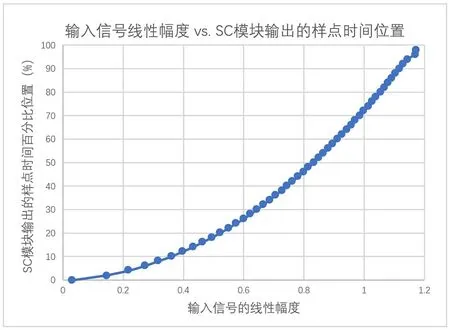
图9 输入信号幅度与SC模块 “磁带摩擦”输出的样点时间位置的对应关系
从图9 中可以看出,SC 模块在进行 “磁带摩擦”输出时,其输出的样点所在时间百分比位置①与输入信号的线性幅度存在单调变化关系,但并非在输入信号的全部幅度范围内均保持线性关系。通过后面的进一步测量可知,这个对应关系实际上是一条二次曲线。
当输入信号为幅度发生跳变的正弦波时,通过观察SC的输出波形可以看到,在输入信号发生幅度跳变时(跳变前幅度与跳变后幅度均在前述能够引起SC输出信号发生时间位置变化的范围之内),SC输出信号将会经过100毫秒左右的过渡时间,从输入信号跳变前幅度所对应的音频样本时间位置,渐变过渡到跳变后幅度所对应的音频样本时间位置,如图10所示。
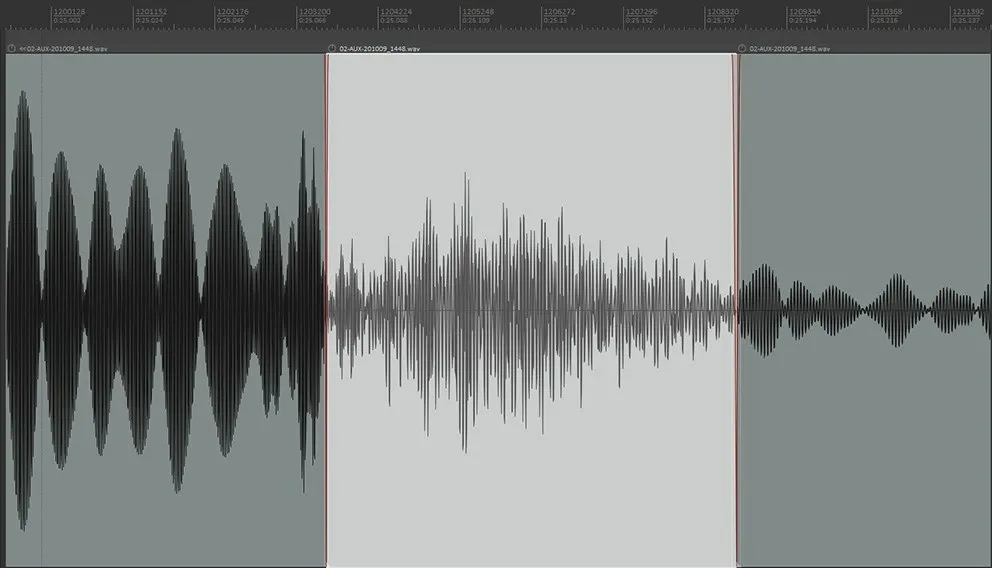
图10 SC模块 “磁带摩擦”输出信号在输入信号幅度发生跳变时,会出现100毫秒左右的过渡时间
图10中左侧部分是输入信号幅度为-4 d B 时SC模块的“磁带摩擦”输出,右侧部分是输入信号幅度为-16 dB时SC模块的“磁带摩擦”输出,中间被高亮选中的区域是过渡部分。被 “磁带摩擦”的音频样本为前述测试信号,即幅度恒定、频率从1000Hz开始、每100毫秒上升100Hz的单频正弦波。
3.3.2映射曲线
SC模块的映射曲线有5个控制点(两个端点和三个中间拐点),通过使用类似于图11所示映射曲线进行测量,可以得出这些控制点的默认横纵坐标位置如表1所示。
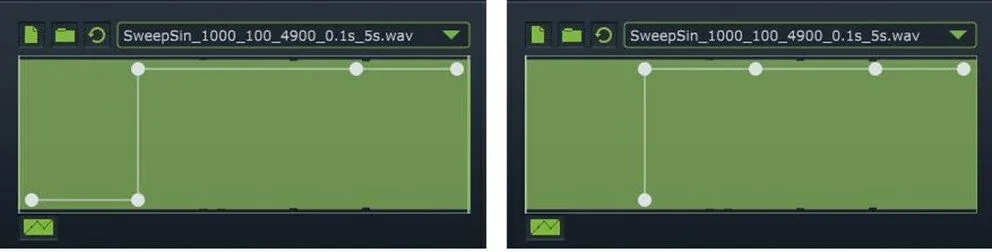
图11 测量第一个中间拐点横坐标及最低纵坐标 (时间百分比位置)和最高纵坐标 (时间百分比位置)所用的映射曲线
对于所有点纵坐标位置均相等的情况,即所有拐点的纵坐标分别全为0、0.25、0.5、0.75、1(图12),进行进一步测量,可以得到如图13所示结果。从图13 可以看出,映射曲线的纵坐标位置决定的是图中输入输出转移函数曲线的变化率,映射曲线纵坐标数值越大,转移函数曲线的变化率越大,且映射曲线纵坐标数值与转移函数曲线变化率基本呈线性对应关系,如图14 所示。由此推断,当映射曲线纵坐标为a 、输入信号线性幅度为xin时,SC模块输出的样点时间位置(%)≈ (ka+b)xin,其中k、b为常数(根据图14所示的初步拟合结果,k≈77,b≈7)。
图12 将映射曲线所有拐点设置为纵坐标均相等
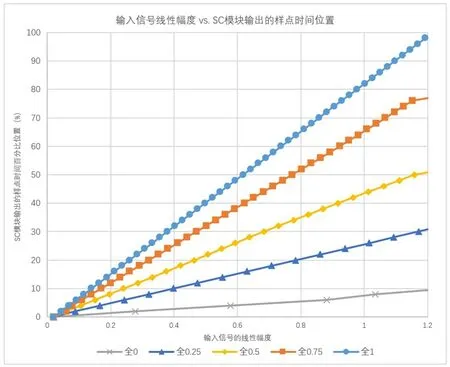
图13 在映射曲线所有拐点的纵坐标位置均相等时,输入信号线性幅度与SC 模块输出的样点时间位置之间的关系
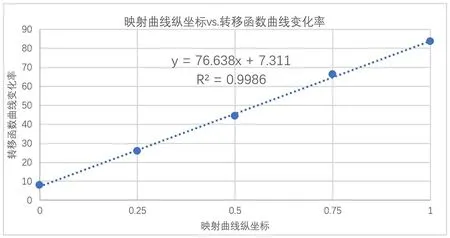
图14 映射曲线纵坐标数值与转移函数曲线变化率基本呈线性对应关系
因此,为了得到SC 输出模块的样点时间位置(%),需要先在映射曲线上找到横坐标为当前输入信号线性幅度xin的点,以该点的纵坐标作为转换曲线斜率a,再根据该斜率计算出当前输入信号线性幅度xin在该条转换曲线上对应的样点时间位置(%)。例如,当映射曲线被重置为自左下角至右上角的对角线时,其纵坐标a本身就与输入信号线性幅度xin呈线性关系(即a=kTxin,kT为常数),所以,此时SC模块输出样点的时间位置≈ (k·kTxin+b)xin=77kT+7xin,即图15中△标记的 “Reset”线所示的抛物线形态。
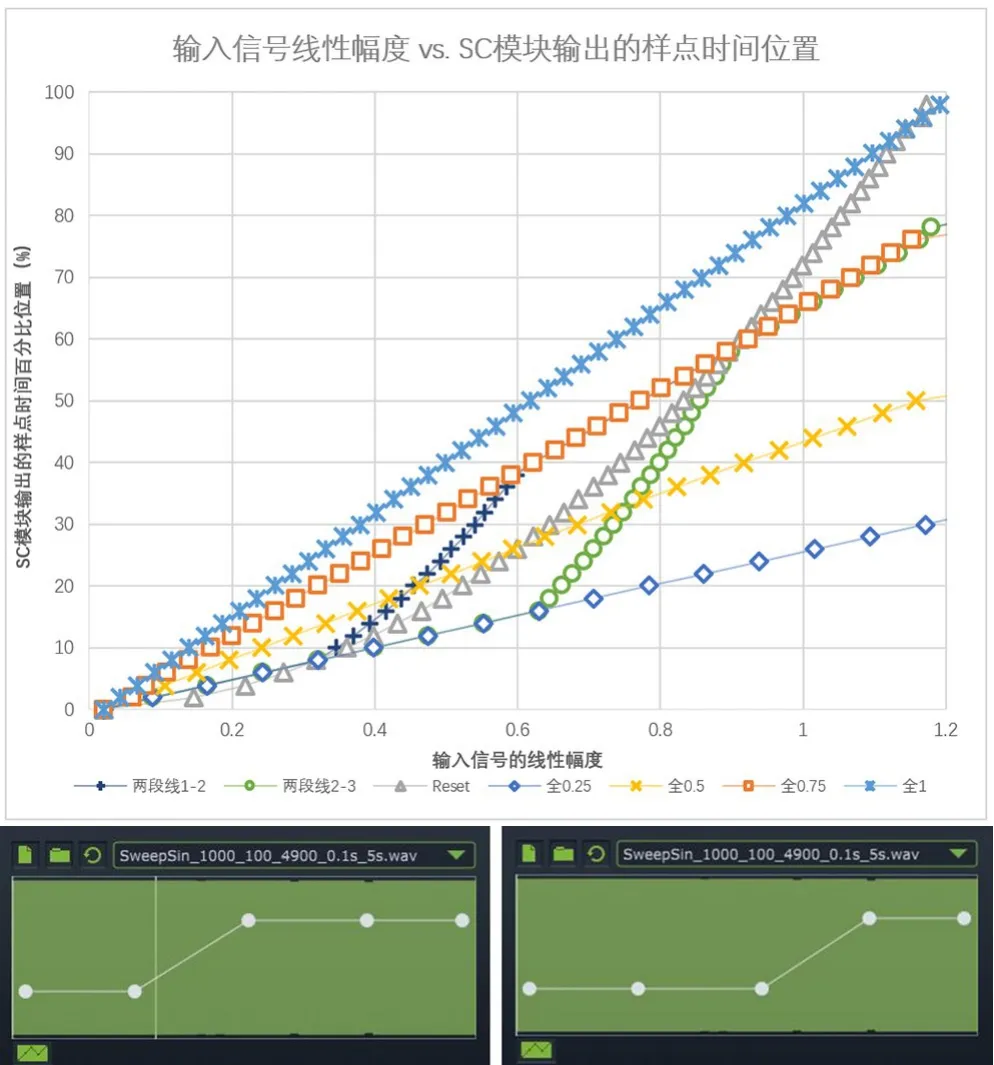
图15 在映射曲线如下两图所示 (两段线1-2、两段线2-3)及被初始化为对角线 (Reset)的情况下,输入信号线性幅度与SC模块输出的样点时间位置之间的关系
综上所述,在实际使用中需要合理设置SC 模块的映射曲线:映射曲线的纵坐标并非直接代表音频样本被输出的时间位置;输入信号的线性幅度与映射曲线在该幅度的高度共同决定了音频样本中能被输出的最远时间位置;音频样本的最后部分较难被输出,需要输入音频信号的线性幅度较高且映射曲线的右半段尽量高;默认的Reset映射曲线总体偏向输出音频样本的前半部分。
3.3.3 REAKTOR 仿真
REAKTOR 在Primary Level中提供的Sample Lookup和Grain Cloud模块,允许用户实时设置被导入音频文件的当前播放位置,从而实现自定义播放。Sample Lookup模块仅输出当前播放位置的样点幅度,而Grain Cloud模块则能在播放位置不变时,反复输出位于播放位置处的声音粒子。因此在这里选用了运行维护成本更低的Grain Cloud模块进行仿真,通过Peak Detect模块对输入音频信号的幅度进行包络跟踪,并以此作为Grain Cloud模块产生的声音粒子在导入音频文件中的位置,从而实现了Scrubbing Convolution的基本功能,如图16所示。
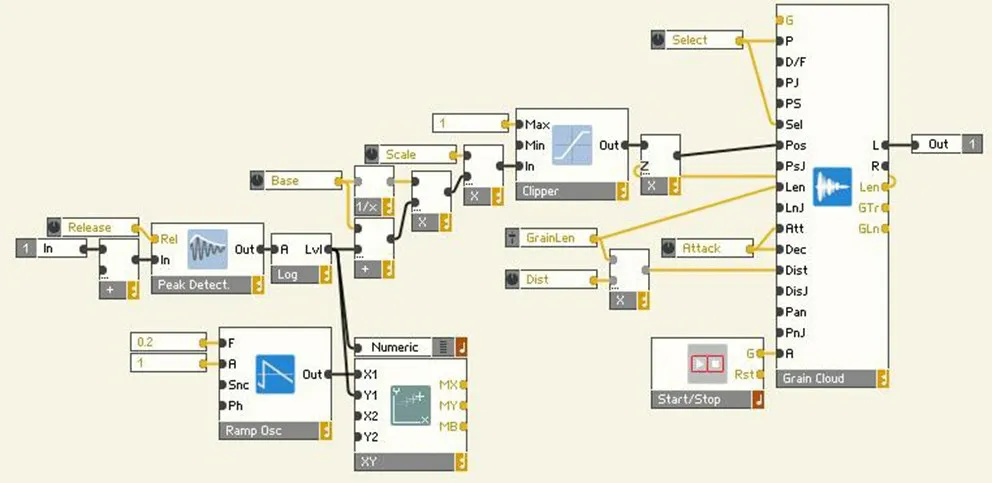
图16 在REAKTOR 中使用Grain Cloud模块模仿Dehumaniser 2中Scrubbing C onvolution的基本功能
4 Dehumaniser2 原厂预置中各模块使用频次统计
通过对Dehumaniser 2 当前版本 (ver 1.3.3)自带的208个原厂预置进行统计,可以得出各个模块在各类预置中的使用频次,如表2 所示。表中IP、DP、FC、GR、NG、PS、RM、ST、SC、SS、VC 分别为模块Input、Delay Pitch Shifting、Flanger/Chorus、 Granular、 Noise Generator、Pitch Shifting、Ring Modulation、Sample Trigger、Scrubbing Convolution、Spectral Shifting、Vocoder的缩写。在Dehumaniser 2当前版本中,每个模块最多可以使用两次 (IP、OP和NG 模块除外),因此表2中用DP1和DP2分别表示第一个和第二个Delay Pitch Shifting模块,其他模块以此类推。
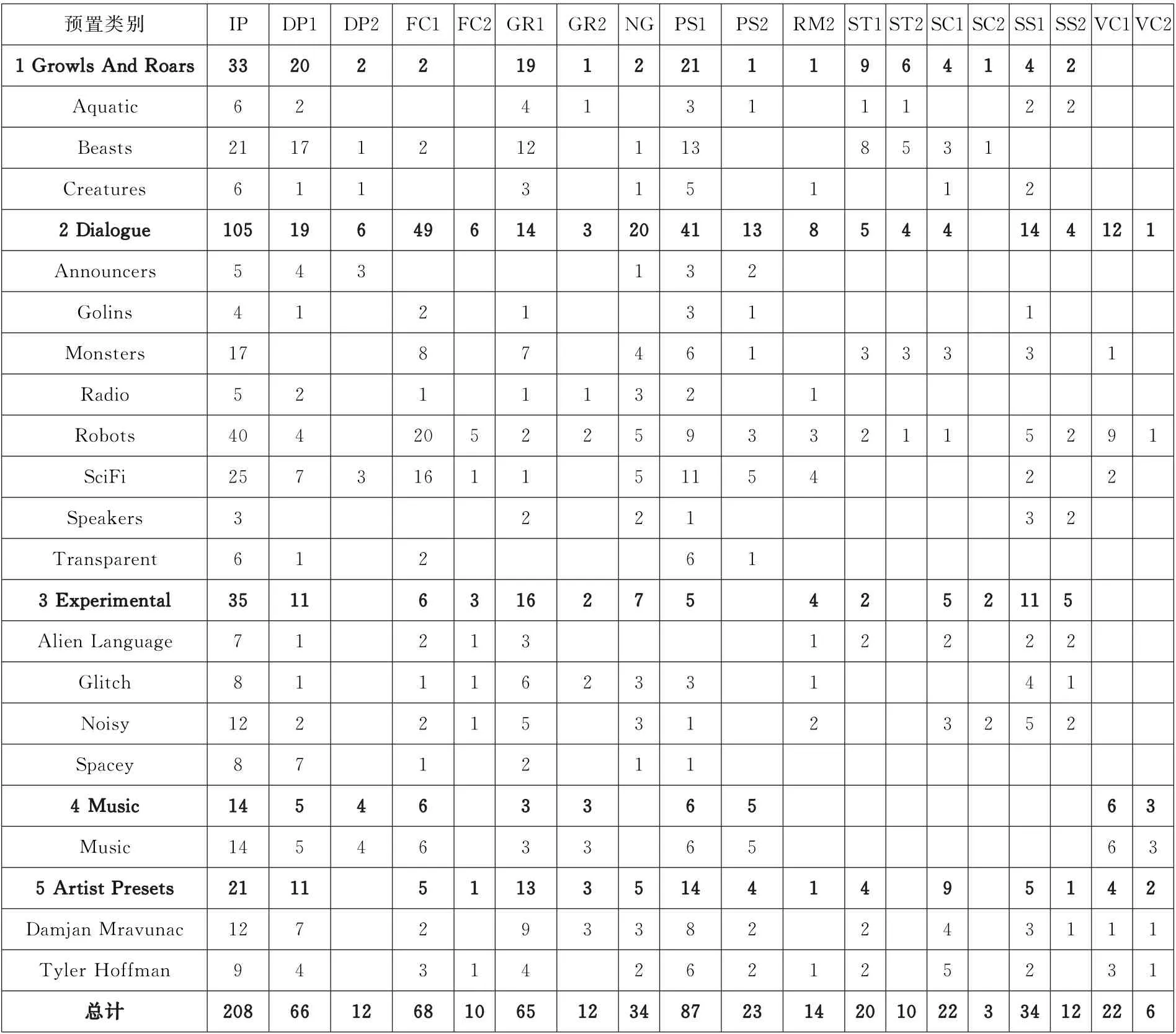
表2 Dehumaniser 2当前版本 (ver 1.3.3)原厂预置中各个模块的使用频次统计
从表2中可以看出,在与生物/怪物语音特效制作关系最密切的第一类 “咆哮与吼叫 (Growls And Roars)”预置和第二类 “对白 (Dialogue)”预置中,使用频次最高的模块是与音高平移相关的模块(DP和PS),使用比例超过了50%;其次是粒子合成模块 (GR),使用比例在第一类预置 “咆哮与吼叫”中超过了50%。此外,在科幻类语音制作中(“对白”大类下的 “机器人 (Robots)”和“科幻 (SciFi)”两个子类)中,镶边/合唱模块(FC)的使用比例也超过了50%。Dehumaniser 2的特色模块Scrubbing Convolution (SC)和Spectral Shifting (SS)在这两大类预置中都有一定程度的使用,但占比并不高。另外,进行样本播放的Sample Trigger模块在与生物/怪物语音特效制作关联紧密的 “野兽 (Beasts)” “怪物 (Monsters)”子类预置中的使用比例明显高于在其他子类中的使用比例。
5 总结
通过研究Krotos Dehumaniser 2 中各功能/效果模块的工作原理可以发现,Dehumaniser 2携带的处理模块各具特色,提供了生物/怪物语音特效制作中最常用、效果最明显的各种处理手法,对于研究总结生物/怪物语音特效以及其他相关声音特效的制作手法具有很好的参考意义。Dehumaniser 2 为语音特效制作提供了多样的声音效果,从小动物的声音到巨人、兽人的声音,再到机器人的声音,都可以通过Dehumaniser 2内置的各种模块的灵活组合而实现。与传统的语音特效制作手段相比,Dehumaniser 2最重要的特点是它在一个单一的插件中实时完成了整套特效处理,既简化了效果处理链路的设置,又能在录制素材时直接听到配音或拟音表演经过效果处理后的结果,从而能够更快捷、更有针对性地调整配音或拟音表演,录制出更贴合画面、更符合后期制作需要的声音素材。
近年来,针对某一特定类型声音特效而推出的专用制作软件日益增多,逐渐成为了声音效果处理软件的一个新发展方向。除了本文介绍的制作语音特效的Dehumaniser 2以外,还有制作运载工具音效的Boom Library Turbine、Boom Library Grip、Krotos Igniter,制作武器音效的Krotos Weaponiser,制作Whoosh 音效的UVI Whoosh FX 等。这些软件插件借鉴了特定类型声音特效的已有制作经验,在素材库选取、信号处理模块选取、信号处理流程设计、多参数协同调制等方面进行了大量有针对性的优化,为使用者提供了方便快捷的一体化制作工具,大大提升了制作效率。这类软件插件也并不局限于专门类型的声音特效制作,使用Dehumaniser 2可以把一些Whoosh声变形为全新的特殊效果或氛围声,可以让声音素材库中的很多普通素材变得更为新鲜有趣,还可以用在音乐中,为吉他、打击乐等声部增添黑暗元素或空灵气氛。
通过实验也发现,Dehumaniser 2在面板显示、操作手册说明、预置存取等方面还有诸多不明确、不完善,甚至错误的地方,需要在具体使用过程中注意甄别。此外,对此类一体化专用制作工具的使用也要适度,不宜完全依赖某一款软件制作所有同类型声音,否则制作出来的声音特效容易出现较为明显的同质化现象。为了达到更为精致的制作效果,更为可取的方法是把经过Dehumaniser 2处理的结果作为一个声音元素或层次,加入到整个生物/怪物声音效果中。❖
注释
①时间百分比位置=输出样点所在时间÷音频样本总时长×100%。
