基于加权直觉模糊兰氏距离的密度峰值聚类算法
2023-01-13徐鑫,曹原
徐 鑫,曹 原
(山东理工大学 数学与统计学院,山东 淄博 255000)
聚类分析的目的是将对象按照某种规则划分成不同的簇,使得簇内相似性较大、簇间相似性较小。目前,聚类分析在文本挖掘[1-2]、生物医学[3]、金融管理[4]、工业发展[5]等领域得到了广泛应用。从机器学习角度看,聚类分析属于无监督学习方法,根据学习算法自动确定无标签数据的标记。大数据时代的数据规模越来越庞大,数据类型也更加丰富,很难使用人工去定性分析庞大的数据集群,因此适用于大数据环境的聚类算法便应运而生。
传统的聚类方法主要包括k均值算法(k-means)、k中心点算法(k-medoids)、基于密度的噪声应用空间聚类算法(density-based spatial clustering of applications with noise,DBSCAN)和凝聚型层次聚类算法等。这些算法各有优点,原理简单且易于实现,因此广泛应用于各个领域。但上述算法同样存在一定的不足,如k-means算法的类别个数难以确定、迭代过程中易受噪声点干扰;DBSCAN算法受参数影响较大,因此Dong等[6]将两种算法结合,克服了两种算法的缺点,提高了聚类精度。除了集成聚类算法外,还和其他优化算法相结合,如Kapil等[7]基于遗传算法改进k-means算法,优化了算法参数的选择。此外,Rodriguez等[8]提出了一种新的快速搜索和发现聚类中心的算法,利用局部密度和相对距离2个变量来刻画聚类中心,可以大大减少算法的运行时间。近年来,随着深度学习的迅猛发展,越来越多的聚类算法与其相结合,体现出了强大的算力,Xu等[9]提出了一种基于SDAE和Gath-Geva(GG)聚类算法的无数据标签滚动轴承故障诊断方法,大大提高了检测的准确性。
上述方法通常适用于确定性数据集下的聚类问题。然而在现实生活中,很多问题不能用确定性数据进行表示,如在决策过程中,决策者对一个元素属于某集合和不属于某集合的程度,即隶属度和非隶属度是不确定的。对此,Zadeh在1965年首次提出模糊集的概念[10],更加细腻地表达决策过程中的不确定问题。近几年,模糊集被广泛应用于水利抗洪、信息安全、创新收入关系分析等领域。许多学者对模糊集进行拓展延伸,提出更加符合实际问题的直觉模糊集、犹豫模糊集、毕达哥拉斯模糊集等。1986年Atanassov[11]提出的直觉模糊集(IFS),可以表示决策者对一个元素属于某个集合的支持、反对和犹豫的程度,通过这3个变量的刻画,更加全面地反映决策者对实际问题的评判结果。在直觉模糊集的基础上,Shu等[12]定义了三角形直觉模糊数,并将其与故障树分析技术相结合,灵活地估计故障区间。在直觉模糊集聚类方面,Li等[13]提出新的直觉模糊相似度与熵,利用传递闭包法进行聚类分析,提高了直觉模糊聚类的准确性。但是,上述聚类算法仅适用于小规模样本的直觉模糊集。随着大数据时代的到来和机器学习算法的广泛流行,有学者将机器学习算法应用到样本量较大的直觉模糊集中进行聚类分析,Xu[14]提出了凝聚型直觉模糊层次聚类算法,优化了直觉模糊集的聚类效果,但是其复杂度较高,不适用于解决大规模直觉模糊集聚类的问题。
针对大规模直觉模糊集的聚类问题,本文在文献[14]的基础上提出了新的直觉模糊聚类算法。首先,给出了改进兰氏距离在直觉模糊集上的计算公式,并利用直觉模糊熵计算属性权重;其次,对于聚类过程中算法复杂度较大的情况,本文利用密度峰值算法进行聚类,使聚类算法能够适应大规模样本环境,具有一定的实用性。同时,将UCI机器学习数据库中的数据进行直觉模糊化并进行实验分析,实验结果验证了本文算法的有效性。
1 相关定义
1.1 直觉模糊集的相关定义
现实生活中有很多概念不能简单地用“是”或“否”来描述,模糊集合指具有某个模糊概念所描述的属性对象的全体。由于概念本身不是清晰的、界限分明的,因而对象对集合的隶属关系也不是明确的、非此即彼的。Zadeh提出了模糊集的概念用于描述模糊性现象。
定义1[10]设X是一个给定的非空对象集合,则定义模糊集A是由X集合通过函数f映射所得的一个新对象集合,fA(x)∈[0,1]的值表示集合A中元素x∈X的隶属程度,简称隶属度。
直觉模糊集(IFS)是一种模糊集的拓展与改进理论,它最大的特点就是同时考虑了支持、反对和弃权的程度。
定义2[14]设X是一个固定集合,在X上的直觉模糊集合A定义为
A={〈x,μA(x),vA(x)〉|x∈X},
式中函数μA(x)和vA(x)分别表示在X中的元素x对集合A的隶属度和非隶属度,并满足条件
0≤μA(x)≤1,0≤vA(x)≤1,
0≤μA(x)+vA(x)≤1,
其中πA(x)=1-μA(x)-vA(x)表示x对集合A的犹豫度。当X中只有一个元素x时,IFS表示为A={〈x,μA(x),vA(x)〉},称为直觉模糊元。
定义3[15]给定两个直觉模糊集A={〈x,μA(x),vA(x)〉|x∈X}和B={〈x,μB(x),vB(x)〉|x∈X},其运算法则如下:
1)A⊆B当且仅当∀x∈X,有μA(x)≤μB(x)且vA(x)≥vB(x);
2)A=B当且仅当∀x∈X,有μA(x)=μB(x)且vA(x)=vB(x);
3)Ac={〈x,vA(x),μA(x)〉|x∈X};
4)An={〈x,[μA(x)]n,[1-vA(x)]n〉|x∈X}。
为刻画直觉模糊集的距离,文献[15]给出直觉模糊集的距离度量的一般定义。
定义4[15]称映射D:SIF(X)×SIF(X)→[0,1]为论域X上的直觉模糊集的距离度量,若对任意直觉模糊集A、B、C∈SIFs(X),D满足:
1)D(A,B)≥0,D(A,B)=0当且仅当A=B;
2)D(A,B)=D(B,A);
3)D(A,C)≤D(A,B)+D(B,C);
4)如果A⊆B⊆C,即相应的隶属度和非隶属度分别满足μA(xi)≤μB(xi)≤μC(xi)且vA(xi)≥vB(xi)≥vC(xi);
那么D(A,C)≥D(A,B),D(A,C)≥D(B,C)。
文献[16]给出了两个直觉模糊集之间的Hammning距离dH(A,B)、标准化Hamming距离dHn(A,B)、欧氏距离dE(A,B)和标准化欧氏距离dEn(A,B),表示如下:
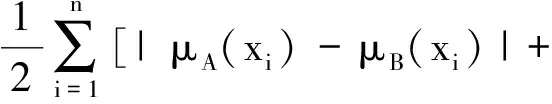
|vA(xi)-vB(xi)|+
|πA(xi)-πB(xi)|];
(1)
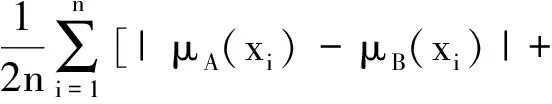
|vA(xi)-vB(xi)|+
|πA(xi)-πB(xi)|];
(2)
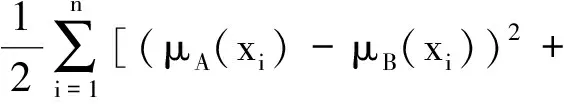
(vA(xi)-vB(xi))2+
(πA(xi)-πB(xi))2];
(3)

(vA(xi)-vB(xi))2+
(πA(xi)-πB(xi))2]。
(4)
其中:n表示集合A中直觉模糊元的个数,即属性值个数;μA(xi)、vA(xi)和πA(xi)分别表示第i个属性对集合A的隶属度、非隶属度和犹豫度。由于这些算子中都包含犹豫度的计算部分,因此不满足定义4中的4)。
直觉模糊集通常由直觉模糊补构造[17]。建立直觉模糊补的常用方法有Yager生成函数和 Sugeno生成函数。基于这两种生成函数可以将模糊集拓展成直觉模糊集。根据Yager生成函数[18],得到的直觉模糊集为
B={〈x,μB(x),(1-μB)β)1/β〉|x∈X}。
(5)
其中,β∈(0,∞)是非隶属度和犹豫度的控制参数,则犹豫度由下式计算:
πB(x)=1-μB(x)-vB(x)=
1-μB(x)-(1-μB(x)β)1/β。
(6)
根据Sugeno生成函数[19],得到的直觉模糊集为
C={〈x,μC(x),(1-μC(x))/(1+λμC(x))〉|
x∈X}。
(7)
其中,λ∈(0,∞)是犹豫度的控制参数,则犹豫度由下式计算:
πC(x)=1-μC(x)-vC(x)=1-μC(x)-
(1-μC(x))/(1+λμC(x))。
(8)
1.2 IFSHC算法
层次聚类分析法是聚类分析中较为常用的算法,它的思想简单,易于实现。文献[14]利用自底向上的层次聚类算法对直觉模糊集进行聚类,扩展了直觉模糊集的聚类方法。
定义5[16]设任意两个直觉模糊集A={〈x,μA(x),vA(x)〉|x∈X}和B={〈x,μB(x),vB(x)〉|x∈X},为方便起见,Xu[20]将直觉模糊元(IFNs)记为A=〈μ,v〉,具有以下运算法则:
3)A⊕B={〈μA+μB-μAμB,vAvB〉};
4)A⊗B=〈μAμB,vA+vB-vAvB〉。
基于加性算子和乘性算子,文献[20]提出了直觉模糊加权平均算子(IFWA)和直觉模糊加权几何算子(IFWG)。
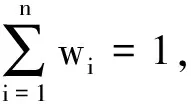
(9)
(10)
当权向量取值相同时,即wi=1/n,此时IFWA就退化成了标准直觉模糊平均算子(NIFWA):
(11)

算法1 IFSHC算法输入:数据集S输出:数据对象的聚类结果步骤1:根据(4)式计算直觉模糊集中数据对象的距离dij;步骤2:选择其中距离较小的两个簇进行连接;步骤3:根据(10)式计算连接后的簇中心数据对象;步骤4:重复步骤1^3,直到数据对象合并成一个簇。
在IFSHC算法中,步骤1通常利用(4)式计算直觉模糊集中数据对象的距离,若数据对象中出现偏移较大的属性值,则聚类结果也会受到较大影响。步骤2体现了层次聚类的不可逆性,由于对象在合并后,下一次聚类将在前一次聚类的基础上进行,若在一次聚类中出错,则会产生较差的聚类效果。在合并两个类之后,算法在步骤3需要利用(9)式或(10)式重新计算合并后的簇中心,这使得算法的复杂度较高,不适用于解决大规模样本的聚类问题。针对上述问题,本文提出了一种基于加权直觉模糊兰氏距离的密度峰值聚类(WIFDPL)算法,以降低直觉模糊集聚类对异常值的敏感性,提高算法的效率。
2 WIFDPL算法
2.1 基于兰氏距离的直觉模糊集距离度量
在利用欧氏距离直觉模糊算子计算样本点之间的距离时,计算结果会受到异常值的影响,导致聚类结果不稳定。因此,距离度量的选择对整个聚类算法有着至关重要的作用。兰氏距离[21]由Lance和Williams最早提出,是聚类分析中用于确定样本间距离的一种方法,其克服了闵可夫斯基距离与各指标量纲有关的缺点,且兰氏距离对大的奇异值不敏感,这使其特别适合高度偏移的数据。兰氏距离的计算方法如下:
(i,j=1,2,…,n)。
(12)
由定义式(12)可知,兰氏距离的应用范围要求xij>0。但是,在直觉模糊数据集中经常有隶属度、非隶属度或犹豫度为0的情况,因此本文在定义式的分母中加入属性个数的倒数,即避免分母为0的情况出现,又利用数据属性信息减少数据的偏移程度。本文提出了改进标准化的直觉模糊兰氏距离dL(A,B)和改进加权直觉模糊兰氏距离dLw(A,B),表达式如下:
(13)
(14)
其中,wi表示第i个属性的权重,一般根据属性的重要程度对其进行人工设置。当对属性权重没有特殊要求时,取wi=1/n,这时加权直觉模糊兰氏距离退化为标准化的直觉模糊兰氏距离。下证改进的直觉模糊兰氏距离满足定义4。
证明1)和2)显然成立,此证略。
由于
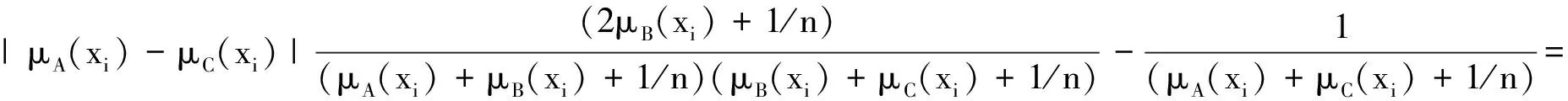

则
同理
则dL(A,B)+dL(B,C)≥dL(A,C)。
4)设A⊆B⊆C,即μA≤μB≤μC,vA≥vB≥vC,则
同理得
即dL(A,C)-dL(A,B)≥0,则dL(A,C)≥dL(A,B)。同理可证dL(A,C)≥dL(B,C)。证毕。
考虑3个具有明确态度的直觉模糊集A={[0.5,0.4],[0.3,0.5],[0.4,0.6]},B={[0.9,0.1],[0.8,0.1],[0.7,0.2]},C={[0.1,0.9],[0.2,0.8],[0.2,0.7]},可以直观看出,A偏向中立态度,B偏向支持态度,C偏向反对态度。利用(2)、(4)和(13)式计算得到3个直觉模糊集的距离如表 1所示。后3列为具有异常属性值的偏移直觉模糊集,A′={[0.5,0.4],[0.3,0.5],[0.4,0.6],[0,1]},C′={[0.9,0.1],[0.8,0.1],[0.7,0.2],[0,1]},

表1 不同算子的距离
B′={[0.1,0.9],[0.2,0.8],[0.2,0.7],[1,0]}。
通过计算得到3个算子的偏移量,如表2所示(加粗代表偏移量最小)。分析得到利用改进的兰氏距离算子计算的距离,其偏移量明显小于其他算子。因此,相比于其他算子,本文提出的兰氏距离计算公式不仅满足直觉模糊集的距离度量的定义,还在有异常值的情况下减少了数据的偏移程度,在进行聚类分析时能够降低异常值对聚类效果的影响。
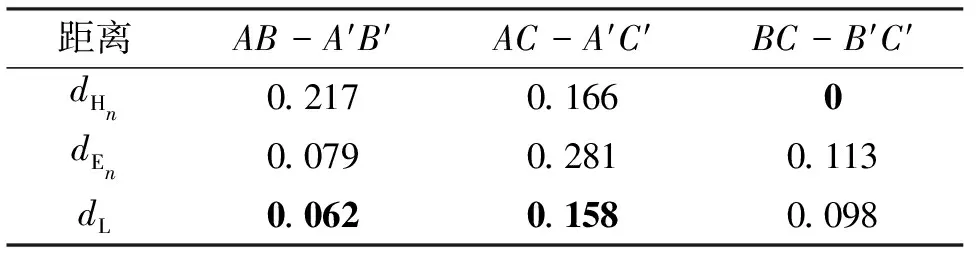
表2 不同算子的偏移量
2.2 WIFDPL算法
针对IFSHC算法的缺陷,提出基于密度峰值思想和改进兰氏距离的加权直觉模糊聚类算法(weighted intuitionistic fuzzy algorithm based on density peaks and Lance distance, WIFDPL)。
针对需要人为设定属性权重的问题,文献[14]在没有特殊说明的情况下采取了属性权重一致的做法,没有充分利用数据集本身的性质。汪凌[22]给出了一种利用直觉模糊熵确定属性权重的方法。首先计算直觉模糊集A中各属性的直觉模糊熵
(15)
E(A)越大,直觉模糊数的不确定性越高,说明决策者对此属性的意见分歧就越大,因此要相应减小此属性的权重。记第j个属性的总体直觉模糊熵为
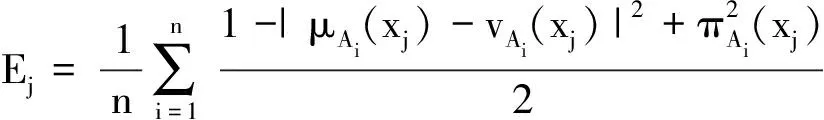
(16)
决策者关于第j个属性的权重可以表示为
(17)
在IFSHC算法中,每次计算都只能依据距离大小合并2个簇,计算繁琐,很容易受到较大的异常值影响,而且不能自动确定聚类的簇数。本文采取密度峰值聚类算法确定簇心,既避免了繁琐的数据计算过程,又优化了聚类个数的选择。密度峰值聚类算法(DPC)要求聚类中心满足两个特点:本身密度比较大,即聚类中心被密度均不超过它的数据点包围;聚类中心与其他密度较大的数据点之间的距离相对更大。因此,需要利用局部密度ρi和高局部密度点之间的距离δi两个数据指标来刻画聚类中心。
定义7[8]设Xi为数据集S的一个数据对象,它的局部密度可以用S中与Xi之间距离小于dc的点的个数来表示,具体公式如下:
(18)
(19)
上式是离散和的形式,适用于数据量大的情况。在数据量小的情况下,为了降低局部密度数值一致的概率,需要采用连续值高斯核的形式:
(20)
其中:dc表示截断距离,通常取样本量的1%~2%作为dc的取值;dij表示直觉模糊集第i个数据对象到第j个数据对象的距离,通过(14)式计算得到。存在数据1,2,…,N的一个全排列q1,q2,…,qN,有ρq1≥ρq2≥…≥ρqN,距离δqi为
(21)
上式说明,当xi是局部密度最大的点时,相应的距离δi也会较大;否则,δi表示在局部密度比xi大的所有点中,与xi距离最小的点的距离。确定了ρ和δ之后,就可以根据这两个数据指标来选择聚类中心点,从ρ-δ决策图中可以选取两者都较大的数据点作为聚类中心。若在决策图中难以选取聚类中心,文献[8]提出一种定量选择聚类中心的方法,即通过计算γi=ρi×δi,将γi从大到小排序,选取有明显断层的前k个ri对应的数据点作为聚类中心。确定聚类中心以后,剩余的点将分配到距离自身最近的聚类中心所在的类中,从而完成直觉模糊集的聚类。
本文基于上述思想,总结新的直觉模糊集聚类算法基本步骤。

算法2 WIFDPL算法输入:数据集S,参数dc输出:数据对象的聚类结果步骤1:根据(16)和(17)式计算属性权重wj;步骤2:根据(14)式计算数据对象之间的距离;步骤3:根据(18)或(20)式计算数据对象的局部密度ρi,根据(21)式计算数据对象的距离δi;步骤4:通过ρ-δ决策图或者γ值确定聚类中心;步骤5:分配除簇心外的其他数据对象到距离自身近且局部密度比自身大的数据对象所在的簇中。
在WIFDPL算法中,步骤1利用直觉模糊熵计算属性权重,反映决策者对各个属性的重视程度。步骤2利用改进的加权直觉模糊兰氏距离计算数据对象之间的距离,降低了由偏移数据引起的计算结果不准确的影响。步骤3~5是密度峰值聚类,仅通过距离矩阵就可以完成整个聚类过程,算法复杂度较低。
2.3 WIFDPL算法的复杂度分析
算法的复杂度[23]分为时间复杂度和空间复杂度。在时间复杂度上,计算权重的复杂度为O(nd),计算距离的复杂度为O(n2),计算局部密度和相对距离的复杂度分别为O(n(n-1))和O(n(n-1)/2),寻找聚类中心时计算γ值并排序的复杂度为O(n+nlog2n),因此时间复杂度为O(n2);在空间复杂度上,存储权重的复杂度为O(d),存储距离的复杂度为O(n2),因此空间复杂度为O(n2)。
在IFSHC算法中,时间复杂度上,计算距离的复杂度为O(n2),合并两个较小的类时需要比较大小的次数为(n3-n)/6次,则复杂度为O(n3),计算类中心的复杂度为O(n),因此时间复杂度为O(n3);空间复杂度主要为存储距离矩阵的O(n2)。
由两个算法复杂度的比较结果可知,IFSHC算法时间复杂度较高,随着数据量规模的扩大,算法所需计算时间较多,不适于解决数据量较大的实际问题。本文提出的WIFDPL算法的时间复杂度比IFSHC算法降低了一个指数级,更适于解决现实生活中大规模直觉模糊数据聚类的问题。
3 仿真实验分析
3.1 实验1
利用文献[14]中的例子对算法做出说明。如表3所示,实例由5个直觉模糊集组成,每个直觉模糊集有8个维度。
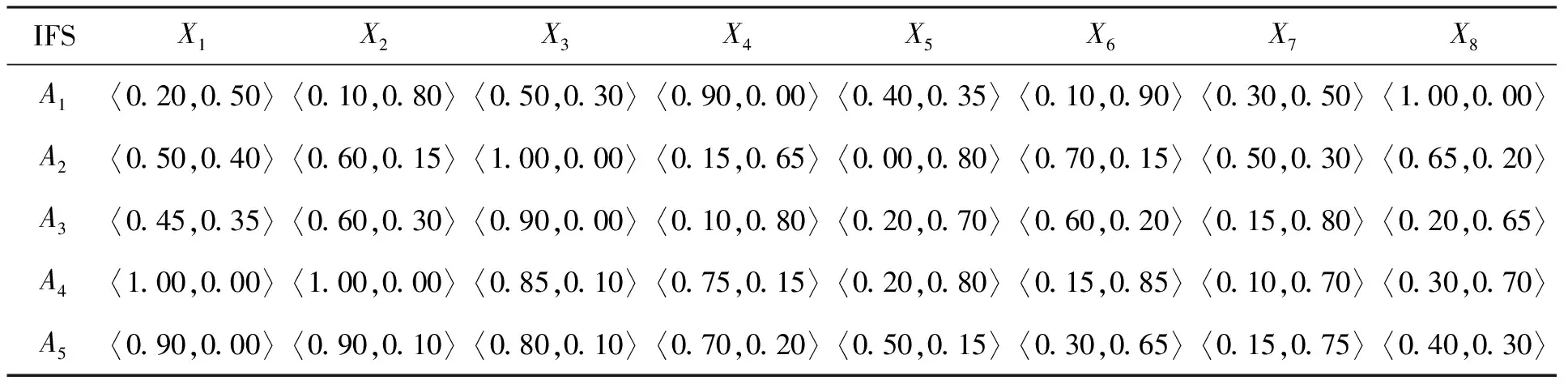
表3 直觉模糊集
首先确定属性权重,将每个属性所对应的直觉模糊元带入(16)式计算总体直觉模糊熵,得到结果E1=0.317,E2=0.266,E3=0.200,E4=0.292,E5=0.366,E6=0.335,E7=0.391,E8=0.338;再将其带入(17)式计算出属性权重,最终结果为w1=0.12,w2=0.11,w3=0.08,w4=0.13,w5=0.15,w6=0.13,w7=0.15,w8=0.14。
根据加权直觉模糊兰氏距离计算每个数据对象之间的距离。由于距离矩阵是对称矩阵,因此根据(14)式计算得到上三角距离矩阵,结果如表 4所示。

表4 直觉模糊集之间的距离
得到直觉模糊对象之间的距离后,就可以计算得到ρi和δi值。根据这2个值发现,A2、A5、A1的γ值分别为0.138 5、0.091 3、0.063 6,明显高于γ3=0.014和γ4=0.004,因此可以判断该数据集可以分为3簇,簇中心为A2、A5和A1。最后分配簇以外的数据对象,最终得到聚类结果为{A1}、{A2,A3}、{A4,A5}。
文献[14]中IFSHC算法的聚类结果如表5所示。

表5 IFSHC算法聚类结果
从表5的第3行可知,当聚类类别数为3时,聚类结果为{A1}、{A2,A3}、{A4,A5},与本文算法一致。IFSHC算法将聚类结果分为了4种情况,不能选择出合适的聚类类别数。基于密度峰值聚类算法可以根据决策图或值的变化选择适合的聚类中心和聚类簇数,能够更好地解决现实生活中的聚类问题。
3.2 实验2
为了验证本文算法适用于较大规模直觉模糊数据的聚类,本文在Python仿真环境中进行验证,选取经典UCI机器学习库中常用的Seeds、Iris和Spiral数据集以及文献[8]中的Aggregation数据集和R15数据集,以此说明本文提出算法的有效性。表 6为各个数据集的描述,图1为利用t-SNE降维后数据集的直观展示。

图1 人工可视化数据集

表6 数据集描述
为了使数据集适用于直觉模糊环境,需要对数据集进行直觉模糊化处理。首先将数据规范化,公式为uij=(uij-min(uj))/(max(uj)-min(uj))。其中:uij表示第i个数据点的第j个属性;max(uj)和min(uj)表示第j个属性中的最大值和最小值。规范化后的数据uij作为第i个数据对象对第j个属性的隶属度。非隶属度和犹豫度由(5)~(8)式进行设置。在进行非隶属度和犹豫度的设置时,需要设置适当的非隶属度和犹豫度的控制参数。本文在区间[0,500]内寻找聚类效果最好的参数[17],每一组参数设置见表7和表8的第2列。实验中截断距离均取包含2%的样本量。聚类性能的评价采用3种常用指标。
1)标准化互信息[24]
标准化互信息(normalized mutual information,NMI,本文用NMI表示)可以用来衡量两种聚类结果的相似度,是聚类中最常用的评价指标之一。NMI越接近1意味着两种聚类结果越相似,
(22)
其中:I(X,Y)是X和Y的互信息,
(23)
H(X)是X的信息熵,
(24)
2)兰德系数[25]
兰德系数(Rand index,RI,本文用RI表示)用来衡量预测结果与真实结果成对的匹配程度。m表示预测结果与真实结果相同的对数,n表示样本点的个数。RI越大,聚类效果越好,
(25)
(3)F1得分[26]
F1得分(F1-score,F1,本文用F1表示)计算了准确率评分和召回率评分的调和平均值。F1越大,聚类效果越好,
(26)
表7和表8分别是通过Yager生成函数和Sugeno生成函数将实数集转换成直觉模糊集后的聚类结果。直觉模糊集之间的距离分别采用(7)式的改进直觉模糊兰氏距离和(4)式的直觉模糊欧氏距离进行计算,加粗显示的数据表示在当前数据集中相对最优的指标数据。由两个距离度量计算得到的对比结果可知,利用改进兰氏距离得到的聚类结果比利用欧氏距离得到的聚类结果更好。这是由于兰氏距离是一个无量纲量,克服了欧氏距离与各指标量纲有关的缺点,且兰氏距离对异常值不敏感,对高度偏移数据的聚类效果较好。
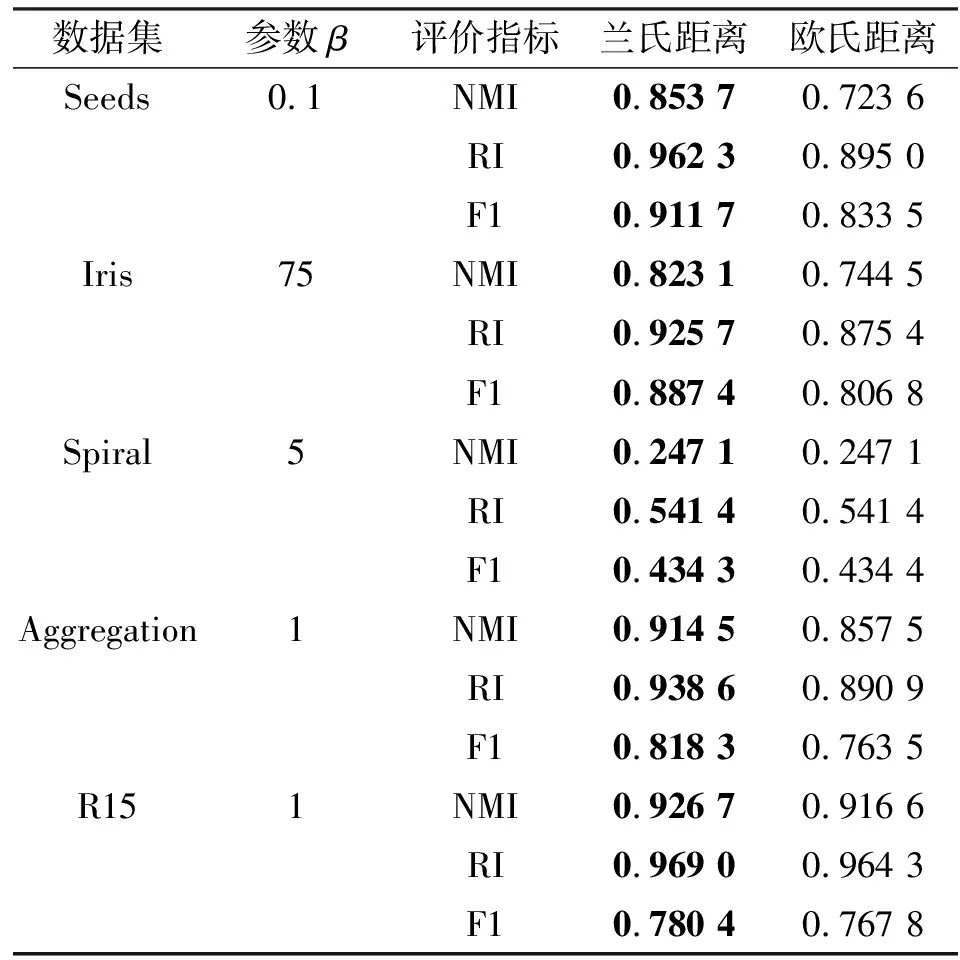
表7 利用Yager生成函数设置的直觉模糊集聚类结果
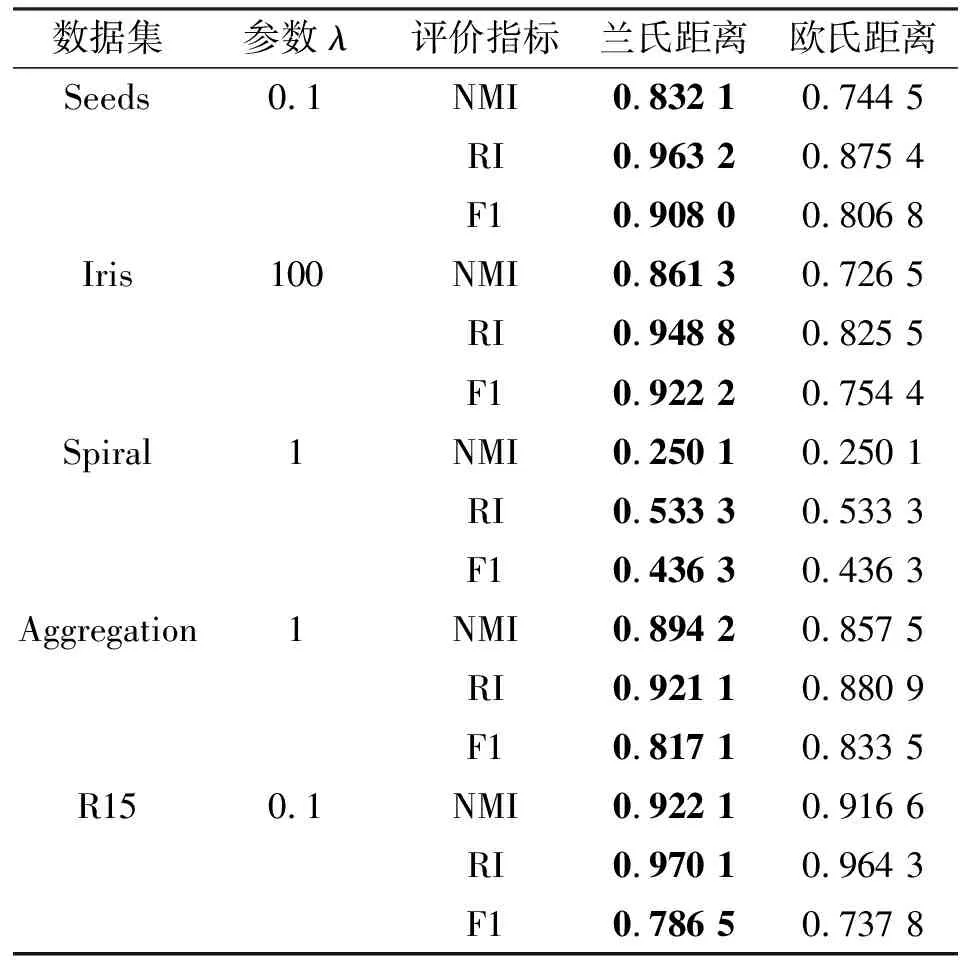
表8 利用Sugeno生成函数设置的直觉模糊集聚类结果
从实验结果可以看出,对于真实数据集Seeds和Iris,利用兰氏距离计算得到的聚类效果比利用欧氏距离得到的聚类结果更好,在3个评价指标上提高了5%~13%。这是因为在利用本文算法时加入了调节属性权重的系数,在进行距离计算时更偏重数据本身混乱程度较小的属性,充分考虑了决策者的直觉模糊信息,从而提高了群决策的合理性和有效性。对于合成数据集Aggregation和R15,利用本文提出的距离算子进行聚类得到的结果在3个指标上提高了1%~5%。这2个数据集样本量相对较大,聚类效果较好,因此本文提出的算法更适用于大规模的直觉模糊集聚类。
此外,从形状数据集Spiral的聚类结果可以看到,算法对于非凸数据的聚类效果并不理想。这是由于不同类数据点之间的距离都较近,而且在直觉模糊的情况下,数据对象在某一维度不断靠近另一个簇的数据对象,导致二者距离过近,从而容易形成球形簇。下一步工作是改进直觉模糊相似度的计算方式,提高算法对于不同形状样本的识别能力。
为验证本文算法的高效性,使用改进直觉模糊兰氏距离的密度峰值聚类算法和凝聚型层次聚类算法,利用5组数据对象在同样的运行环境中进行对比实验,实验结果见表 9。

表9 运行时间对比
由仿真实验的运行时间可知,本文提出的直觉模糊聚类算法在较小数据集上效率提升不明显;但是在较大规模的数据集上,显著降低了算法的运行时间,提高了聚类效率。
4 结语
本文针对现有直觉模糊距离算子不满足距离度量定义的问题,提出了改进加权直觉模糊兰氏距离算子,减小异常值对计算结果的影响。同时,将新提出的算子和密度峰值聚类算法应用到直觉模糊集的聚类中,降低了直觉模糊集聚类算法的复杂度。仿真实验结果表明,新算法提高了直觉模糊集的聚类精度,在数据量较大的直觉模糊集中显著提高了算法的运行效率,具有广阔的应用前景。
