局部特征映射与融合网络的人脸识别优化算法
2023-01-11陈盈君汤弘毅杨昊东秦浩然
徐 武,陈盈君,汤弘毅,杨昊东,秦浩然
(1.云南民族大学 电气信息工程学院,云南 昆明 650000;2.中国石油运输公司,新疆 乌鲁木齐 830014)
0 引言
人工智能技术的发展引领着生物特征识别技术的不断创新。目前,影响生物特征识别技术发展的主要因素是人脸、指纹等特征的提取精度及稳定性[1]。人脸识别也就是对眼睛、鼻子、嘴、下巴等主要部位进行特征提取,并根据局部特征及其结构关系进行识别的过程。
文献[2]提出一种基于目标检测的人脸识别算法YOLOv1(you only look once v1),用于获取具有高区分度的人脸识别特征,可以极大地提高检测精度,但在提取多角度人脸特征时,会丢失很多高频细节信息。文献[3]根据时间卷积与空间卷积提出一种时空协同卷积模型(spatio temporal cooperative convolution,STC-Conv)来降低模型复杂度、提高计算效率,但是不能精确识别分割边缘。
1 DeepLab v2改进网络
1.1 DeepLab v2网络及不足
DeepLab v1将传统卷积神经网络(convolutional networks,CNN)和概率图模型(probabilistic graphical model,PGM)相结合,提高了网络性能且优化了分割结果。DeepLab v2在此基础上增加了多视野区域,并引入空间金字塔(atrous spatial pyramid pooling,ASPP)结构,融合不同级别的语义信息。传统DeepLab v2网络处理人脸图像的流程如图1所示[5]。

图1 DeepLab v2网络处理人脸图像的流程图
DeepLab v2网络主要分为3个部分:
第1部分是卷积结构,卷积层输入的图像与卷积核(卷积核大小为3×3,卷积核通道数为3)共同卷积计算,设置卷积层的步长stride值减小图像的尺寸,经过多层卷积得到图像的深层特征和浅层特征,公式如下:
jout=(jin*stride)+fsize,
(1)
其中:jin为输入特征;jout为输出特征;stride为上一层的步长;fsize为filter的尺寸。
第2部分是金字塔池化结构,将导出的特征图转化为4个相同尺寸的特征模块,特征信息输入金字塔池化结构,减少图像的参数,降低特征信息的维度,减少过拟合问题,公式如下:
(1)氯霉素半琥珀酸酯制备。将CAP、HS、丙酮、吡啶按适当比例混合、搅拌溶解,58~60℃回流2 h,浓缩、蒸去丙酮,加乙酸乙酯和稀盐酸振荡去酸层,用10%NaHCO 3转溶,加浓盐酸调pH值到3,析出糖浆状物,再用酸乙酯萃取,取有机相旋转蒸发器浓缩,得氯霉素半琥珀酸酯(CAP-HS),备用。
(2)
hout=2*ph+hin,
(3)
其中:floor(·)为向下取整运算;hin、hout分别为输入、输出的特征高度;kh为核的高度;ph为填充数量;n为池化数量。
第3部分是softmax分类器,这里计算输出特征的损失函数,将目标与现实输出之间的偏差通过概率的形式映射在[0,1],可保留特征精度较高的特征信息,softmax损失函数公式如下:
(4)
其中:Li为softmax交叉熵损失函数,表示输入特征分到每个标签的概率分布;fyi为目标特征分布;fi为真实特征分布。
在使用DeepLab v2网络提取人脸图像时,存在以下2个主要问题:
(Ⅰ)不同角度、不同表情会降低局部特征的提取精度,影响面部器官的识别和分割的精度,无法保留完整的人脸特征;
(Ⅱ)在采集人脸图像时,无法保证光照的强度、角度等因素一致,这导致了面部图像的原始数据空间混入无关噪声,原始噪声逐步传递给输出特征图像,使得提取的面部器官特征图像质量下降,影响目标识别和提取的精度[6]。
1.2 DeepLab v2网络的改进
针对第1个问题,在DeepLab v2网络的卷积层后加入SE模块,起到保留图像细节、提升细节特征分辨率的作用。使用SE模块重新标定每个特征通道的权重,增强提取图像中的目标区域特征,抑制提取无关的特征信息,有利于细化目标区域的纹理信息,提升细节特征精度[7]。
SE模块的主要部分是压缩(squeeze)和激励(excitation)。将人脸图像输入卷积层,输出具有多个通道的特征,加入SE模块可以重新标定每个特征通道的权重。SE模块分为3个步骤,分别是压缩、激励和重定权重(reweight),SE模块原理图如图2所示。压缩操作使用全局平均池化(global average pooling, GAP)将每个特征通道都压缩成1个实数,将感受也扩展到全局范围[8]。实数求取公式为:
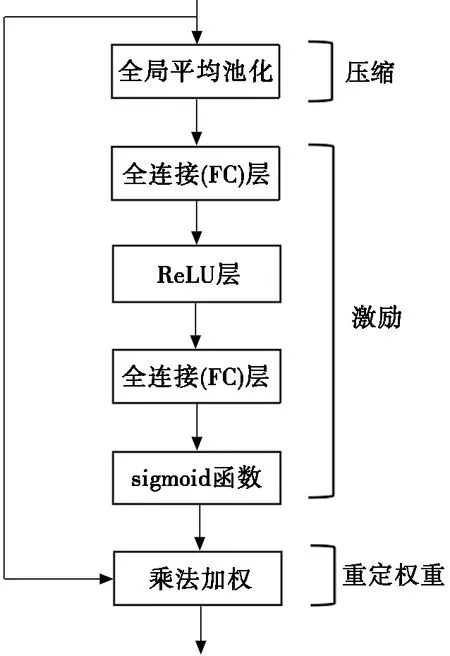
图2 SE模块原理图
(5)
其中:jout为卷积层输出的特征;C为全部特征的通道数;W、H为不同特征的维度。激励操作捕获压缩后的实数列信息,使用2个全连接(fully connected,FC)层增加模块的非线性。先经过第1个全连接层降维,再通过ReLU激活,然后经过第2个全连接层升维,最后经过sigmoid激活函数,公式如下:
s=σ[W2δ(W1z)],
(6)
其中:δ为非线性激活函数ReLU;W1和W2分别为第1FC层和第2FC层的参数;σ为sigmoid函数。最后重定权重,用原特征逐通道乘以激励操作获得的通道系数,得到重新标定的特征作为池化层的输入量:
hin=sk·jout,k=1,2,…,C。
(7)
2 LBP特征映射模块
基于非均匀光照的人脸图像,由于光照变化产生降低提取效果的无关噪声,在对目标人脸区域定位时,会把一些少量的无关噪声保留下来,对特征提取的结果有很大影响,鲁棒性差[9]。针对这个问题,采用局部二值模式(local binary patterns,LBP)对面部特征进行补充特征提取,通过计算目标像素与相邻区间的灰度值,提取出面部器官的轮廓纹理,对面部器官进行局部定位[10]。在光照变化的场景中,目标区域像素的灰度会同步增大或者减小,因此使用LBP对非均匀光照的人脸图像识别将极大降低光照的干扰。但LBP在处理人脸图像时会存在失真的现象,本文将轮廓纹理映射在DeepLab v2网络中,细化特征输出的边缘纹理,得到去噪的面部特征。
在处理人脸图像时,由于无法确定原始中心像素点与相邻区域的灰度值,LBP码值呈无序排列[11],本文通过利用多维标度(multi-dimensional scaling,MDS)法将无序的LBP码值转换为度量空间中的点,将原数据与导出数据的距离(或相似性)拟合到一个低维空间,在低维空间对目标区域进行定位分析,对于不同研究对象xi,xj,距离公式[12]为:
δi,j≈‖xi-xj‖=(xi-xj)T(xi-xj)=xiTxi-2xiTxj+xjTxj。
(8)
要保证δi,j的值尽可能小,这使得原空间2个数据的距离(或相似性)与低维空间基本一致,导致数据因降维所引起的任何形变最小。通过对变换后的点进行卷积运算求得平均值,导出数据间的距离近似于原数据间的距离,进而映射出原始图像的局部特征结构及空间位置[13]。由于直接将LBP加入特征提取网络中会产生严重的失真现象,本文通过LBP模块使数据在低维空间拟合,以达到对原始图像进行特征映射的目的[14],LBP映射效果如图3所示。
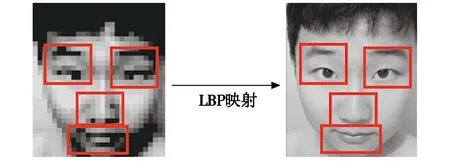
(a) LBP输出特征 (b) 原图像的特征映射
将LBP映射特征图像送入DeepLab v2网络中,但LBP特征映射时经过LBP编码,形成的非均匀模式的LBP会丢失一些有用的信息[15]。为了得到更充分的特征信息,对映射特征进行批量归一化处理(batch normalization, BN),以解决在训练过程中,中间层数据分布发生改变的问题,最后将LBP特征映射与DeepLab v2输出特征进行了特征融合。
3 融合网络结构
为了得到识别精度高、鲁棒性强的人脸识别图像,本文提出了基于DeepLab v2和LBP融合网络的人脸识别优化算法,如图4所示。该算法由3部分组成:DeepLab v2特征提取模块;LBP特征映射模块;softmax分类模块。首先,DeepLab v2特征提取模块对人脸的面部信息进行特征提取,加入SE模块提升识别的精确度;然后,LBP特征映射模块对图像进行补充特征提取,极大地消除光照噪声对识别精度的影响;最后,softmax分类模块对融合特征识别并分类处理。
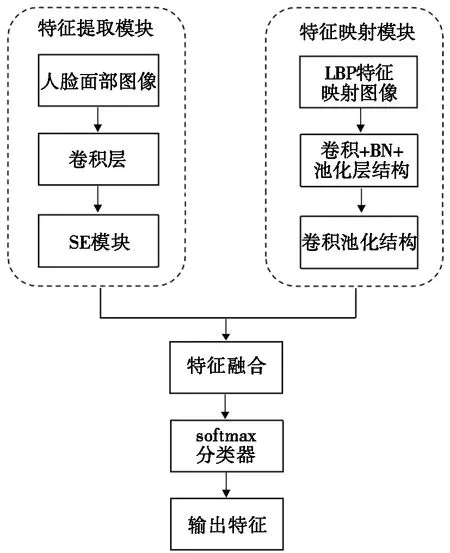
图4 融合网络
4 实验结果与分析
4.1 不同网络的识别精确度
本节针对多角度的问题对人脸进行实验,由于光照噪声极大降低了人脸识别的识别精度,为了降低光照的影响,这里选取了封闭环境下采集到的正脸和30°侧脸图像作为原始图像。YOLOv1可以高精度地提取图像中的特征信息,常用在处理多角度的人脸图像,现阶段多用于人脸识别的对比实验。本文针对YOLOv1、DeepLab v2和融合网络进行识别效果进行对比。
正脸的不同识别算法实验结果和30°侧脸的不同识别算法实验结果如图5、图6所示。对比图5中不同识别算法的识别结果,图5a为正脸原始图像,图5b和图5c中均有大量的识别重叠区域,因此识别结果中包含较多的无关特征;图5d没有识别重叠区域,且识别结果更加准确。对比图6中不同识别算法的识别结果,图6a为30°侧脸原始图像;图6b存在识别重叠区域;图6c虽没有识别重叠区域,但包含较多的无关特征;图6d识别效果最好。因此,YOLOv1网络识别的特征包含过多的无关信息,存在交叉信息的现象,对局部特征的识别能力较差;DeepLab v2网络可以识别出目标信息,但对非正脸图像识别精度略差;融合网络相对传统DeepLab v2可精确地识别出多角度的人脸局部特征。

(a) 原始图像

(a) 原始图像
本实验采用的评价指标为识别精确度(accuracy,ACC),公式如下。
(9)
其中:TP为正确分类的正样本数;TN为正确分类的负样本数;FN为错识分类的负样本数;FP为错识分类的正样本数;TP+FN+FP+TN为样本总数。基于YOLOv1、DeepLab v2、DeepLab v2+SE和融合网络进行识别精确度的对比,如表1所示。
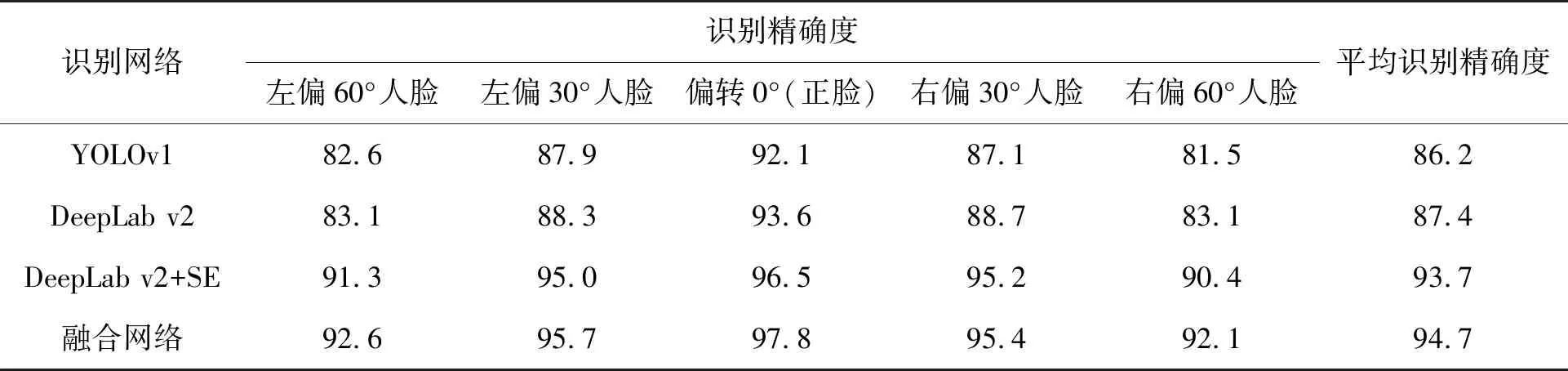
表1 不同网络的识别精确度 %
在对人脸图像进行识别时,由于ACC可以反映识别算法精度,算法精度随着ACC的增大而增大。由表1可知:DeepLab v2+SE网络和融合网络的平均识别精度分别为93.7%和94.7%,比DeepLab v2网络分别提高了6.3%和7.3%,比YOLOv1网络分别提高了7.5%和8.5%,且融合网络在识别30°人脸、60°人脸的平均识别精确度高于其他网络。由实验结果可以得到,在DeepLab v2网络中加入SE模块,识别精确度远远高于其他网络,针对多角度人脸图像也有较高的识别精确度,验证了融合网络具有高识别率的特性。
4.2 不同光照强度的识别精确度
本节针对光照强度的问题对人脸进行实验。本实验采用的评价指标为平均交并比(mean Intersection over union,mIoU),IoU是真实值与预测值的交集与并集之比,mIoU是交集与并集之比的平均值,其结果可以反映为算法处理的效果,计算公式如下:
(10)
其中:k为类别个数;pij表示被预测为j类中,类别为i的像素的个数;pii表示类别为i的同时被预测为i类的像素之和。
在光照强度为强光、正常光、弱光的密闭条件下分别对人脸进行采样,为了防止其他无关干扰因素对实验结果产生影响,均选用正脸图像进行实验,结果如表2所示。

表2 基于可见光的网络性能比较 %
由表2可知:在正常光的条件下,融合网络的mIoU值为95.3%,比DeepLab v2网络和YOLOv1网络分别提高了3.1%和5.9%。由于正面人脸特征较完全,融合网络对人脸图像有较高的识别能力。在强光条件下,融合网络的mIoU值为78.7%,分别比DeepLab v2网络和YOLOv1网络提高了9.5%和13.6%,改进效果较好。但由于强光的影响,对人脸图像识别依然较差,抗强光照干扰能力较弱。本文在DeepLab v2网络的基础上进行改进,识别效果远远高于其他算法,验证了融合网络提高了识别的精确度与鲁棒性。
4.3 案例分析
为了验证算法在基于可见光的多角度人脸图像中的识别效果,本文采用GENKI-4K人脸图像数据集,包含4 000张图像。数据集采集于1 820个人脸图像,图像中的环境、光照、面部位置、面部细节(种族、眼镜、表情、发型遮挡等)存在差异。数据集标签的种类和属性如表3所示。
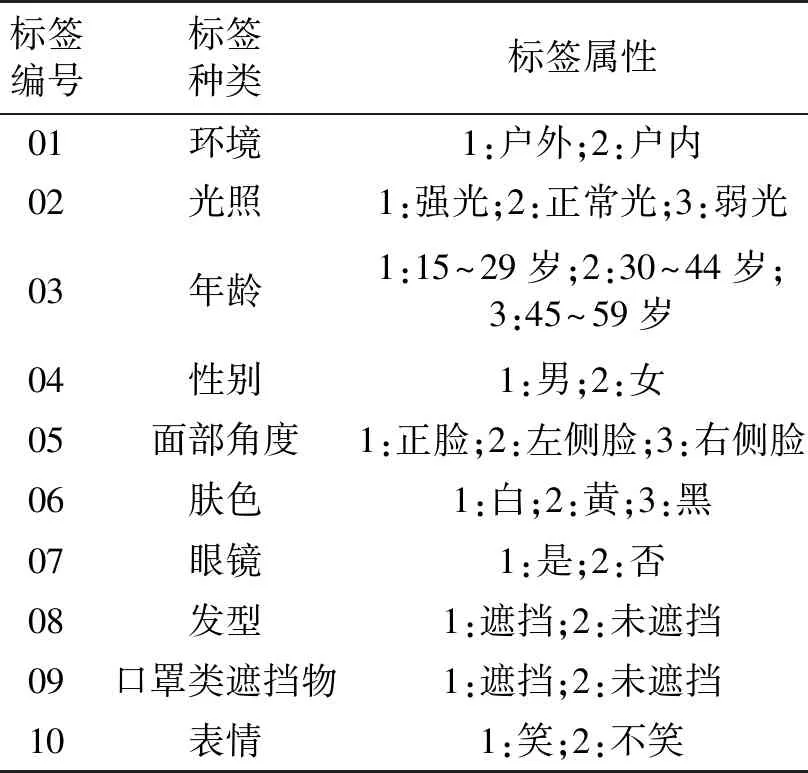
表3 数据集标签的种类和属性
本文通过求解各网络的ACC验证网络的识别精度,抽取数据集中1 328张图像训练网络模型,362张图像测试识别结果,设置网络的初始学习率Ir=0.01,实验迭代次数为2 000次训练融合网络,观察识别测试图像中面部器官的情况,评判模型的指标为ACC。将YOLOv1网络、DeepLab v2网络、融合网络的识别结果进行对比分析,如图7所示。
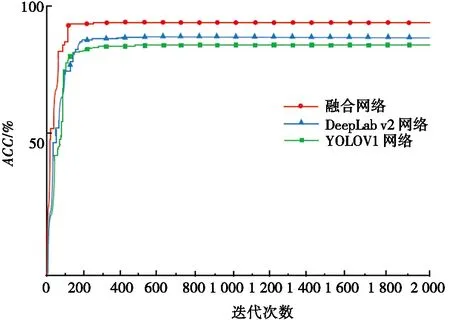
图7 3种网络的识别结果
图7是融合网络、DeepLab v2网络、YOLOv1网络随迭代次数的增加,提取图像的精确度的变化曲线。由图7可以得出:当迭代次数足够多时,融合网络的精确度最高,YOLOv1网络的精确度最低,且融合网络在迭代次数为100次时,精确度已经趋于最大值,迭代速度更快,传统的DeepLab v2网络和YOLOv1网络均是在迭代次数约200次时达到最大ACC。综上所述,融合网络的识别精确度和迭代速度均优于传统的DeepLab v2网络和YOLOv1网络,这表明了融合网络在人脸识别的可行性和适用性。
5 结束语
针对多角度的人脸图像以及存在光照噪声对人脸识别结果产生影响的问题,在传统人脸识别的基础上进行改进,在DeepLab v2网络的基础上加入SE模块,使用LBP模块对图像进行补充特征提取,softmax分类模块对融合特征识别并分类处理,极大消除光照噪声的影响,使在光照变化的环境下具有一定的抗干扰能力。将本文融合网络应用在人脸图像数据集中,与经典人脸识别网络YOLOv1、DeepLab v2作对比,展现了改进的融合网络在减小噪声干扰方面有更好的效果。未来工作将考虑减小其他噪声的干扰。
