基于ADASYN-LOF-RF模型的核心专利识别研究
2023-01-11吴增源
李 颖,吴增源,陈 亮
(1.中国计量大学 经济与管理学院,浙江 杭州 310018;2.中国计量大学 光学与电子科技学院,浙江 杭州 310018)
核心技术,是在某一技术领域中处于关键地位,对技术发展具有突出贡献、对其他专利或者技术具有重大影响且具有较强创新性的技术[1]。专利是技术进步与产业发展的重要载体[2],包含着技术发展等关键信息。通过对专利数据进行分析、挖掘,可了解本领域的核心技术前沿和动态,对企业明确研发方向、实现技术突破进而形成核心竞争力至关重要。近十年,全球专利申请量、授权量激增,2021年,全球专利申请量持续突破300万,国际专利数量同比增长3.5%,但对某领域的发展起到关键决定性作用的核心专利数量[3]却只占极少数。因此,如何从海量专利数据中及时、准确地识别出核心专利,成为理论界和实践界关注的热点问题。
Zhong等[4]使用社交网络分析法和文本聚类识别光伏领域的技术演化路径与前沿核心技术。Kwon等[5]利用技术积累、技术生命周期、技术保护范围等专利指标,识别单一技术领域内的核心技术。陈祥[6]以技术发展规律为基础,并基于专利技术知识扩散视角构建核心专利识别模型。但现有研究依然存在以下两方面的不足:1)核心专利指标体系构建不够完善,识别准确率低;2)对于核心专利与非核心专利数据分布上的不平衡,现有模型处理效果欠佳、稳定性较差。
指标选取和识别方法是核心专利识别的两个关键。指标选取直接影响专利识别效果。罗立国[7]利用多元回归模型验证引用专利数量、IPC分类号数量、同族专利数量、同族专利被引用数指标与核心专利呈显著正相关关系;王曰芬[8]通过行为效果和动机目的两大维度构建指标体系,证实引用专利数、科学关联度以及权利要求数对人工智能领域核心专利识别结果影响较大;马瑞敏[9]证实四年被引频次、同族专利数、专利宽度、权利要求数和科学关联度五个指标构建核心专利预测模型的合理性。现有核心专利识别研究中,大部分学者只考虑专利本身的因素,很少有学者将专利发明人自身实力构建到核心专利识别体系中。但最新研究表明专利所处的地位和影响力很大程度上取决于专利发明人。乔永忠[10]通过专利引证分析证明不同的主体人对专利质量水平有显著影响;筱雪[11]通过波音公司和空客集团的专利分析证实专利发明人的技术实力越强,越有可能创造出核心专利。
核心专利识别方法方面,主要包括专利指标频次统计法[12]、改进的专家打分法[13]、专利共类分析法[14]等。专利指标频次统计法简单易行,但可靠性较差。选择不同的专利指标直接影响核心专利识别结果,其中专利被引频次从技术影响力上反映出专利技术的重要性,被引次数高的专利往往影响力大,因此部分学者使用该指标识别核心专利[15]。改进的专家打分法不需要考虑较多制约因素的影响,在专家熟悉的领域内识别准确率较高,但是该方法的指标体系构建过程繁琐,并且每项指标的赋权过程受主观因素影响大。专利共类分析法通过构建专利IPC分类号的共现网络,并计算节点中心度,认为中心度高的节点对应的是核心IPC,核心IPC所对应的技术领域的专利是核心专利。随着人工智能技术的发展,机器学习开始运用到核心专利识别研究中,该方法充分考虑核心专利评价指标的多元性,并且可以轻松处理大量专利数据,适用性较强。但大部分学者直接使用机器学习进行核心专利识别,然而准确率较低,所以在实际的应用中,需要进一步对指标的选取和算法进行改进。从本质上看,核心专利识别是一个数据不平衡的二分类问题,即非核心专利与核心专利数量差异较大,直接使用机器学习算法进行识别,难以克服数据不平衡导致的分类性能较差问题。现有对于不平衡数据的处理方法主要有两类:数据级处理和算法级处理。数据级处理方法主要是重采样技术,分为欠采样和过采样。欠采样通过随机地移除多数类样本,使样本分布均匀,但可能会丢失重要的信息,常见的欠采样算法有剔除最近邻法(edited nearest neighbor,ENN)[16]、Tomek links[17]等。过采样技术通过随机地复制少数类样本使数据达到平衡,该技术的缺点是会使信息变得冗余,模型训练复杂度增大,容易造成过拟合问题,典型的随机过采样方法是合成少数类过采样(synthetic minority oversampling,SMOTE)[18]。这两种采样方法比较容易操作、具有较好的适应性,但是对数据的删减与扩充并未遵循原始数据的分布规律,可能导致有价值的信息丢失或模型过拟合问题。算法级处理是直接对算法进行改进。单一的分类算法在处理数据量大、较为复杂的问题时,效果不理想。为了提升分类性能,学者对分类算法进行改进,主要包括代价敏感学习[19]和集成学习[20]等。常用的集成学习算法[21]是将多个分类器组合起来形成一个强分类器,以提高分类性能。但是单独使用集成算法容易导致过拟合问题,并且鲁棒性不强,算法训练时间长。因此,部分学者提出使用组合模型来提升分类性能,张阳等[22]将SMOTE过采样算法分别与多种集成算法进行组合,比较分析模型有效性;周杰英[23]将随机森林和梯度提升树进行融合,解决网络入侵数据不平衡的多分类问题;王文博[24]使用SMOTE-XGBoost组合模型对变压器缺陷进行预测。这些组合方法大多在数据级层面仅使用单一的采样算法,可能导致数据存在噪声样本,训练效果不佳。
基于上述分析,科学合理地构建核心专利指标体系,设计适用的优化算法对核心专利识别至关重要。首先,针对核心专利识别准确率低的问题,本文在初选指标体系的基础上加上专利发明人的两个指标:发明人技术实力和发明人技术影响力。其次,对于不平衡数据的处理,现有的算法在模型的稳定性和准确性上效果不佳,而本文使用自适应综合采样算法(adaptive synthetic sampling, ADASYN)对原始数据进行过采样,平衡数据集;并对生成的新样本使用局部离群因子(local outlier factor, LOF)算法进行降噪处理,可克服简单的数据过采样带来的信息冗余和模型过拟合等问题;使用随机森林(random forest, RF)集成算法进行分类,构建组合模型ADASYN-LOF-RF,并与其它模型进行比较,验证其有效性。
1 ADASYN-LOF-RF模型构建
1.1 ADASYN-LOF算法
ADASYN是He等[25]在2008年提出的一种过采样算法。该算法使用密度分布参数作为分布标准,根据不同的少数类样本学习的难易程度,对其进行加权分布,使较难学习的少数类样本比较容易学习的少数类样本生成更多的合成样本。ADASYN算法从两方面改善学习:1)减少数据不平衡带来的偏差;2)自适应地将分类决策边界向困难的样本实例转移。LOF是针对离群点的检测方法。大部分离群点检测都是借助密度、夹角和距离等来划分超平面找出异常点,这些方法都是从数据点相似度出发。不同于上述算法,LOF算法是从样本点周围的数据密度基础出发的检测算法,它给每个样本点分配一个局部可达密度,通过可达密度的离群因子分析该样本的离群程度,判断其是否为离群点。LOF算法简单直观,同时考虑数据集局部和全局的属性。ADASYN-LOF算法先对原始数据进行采样,采样后的数据必然存在噪声样本,再通过LOF进行降噪处理,最终得到的平衡数据集更有助于进行分类处理,具体训练过程如表1。

表1 ADASYN-LOF算法训练步骤
1.2 ADASYN-LOF-RF模型
随机森林是Breiman[26]在2001年提出的分类算法,它以决策树为基分类器进行集成。从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集训练决策树,再按以上步骤生成m棵决策树组成随机森林,数据分类结果按照分类树投票分数而定。随机森林算法简单易实现,在实际解决问题的时候展现出强大的性能,其基分类器的多样性不仅来自样本扰动,也来自属性扰动,能够提升集成分类器的泛化性能。随机森林算法每次随机选取样本和特征,提高模型抗干扰能力,泛化能力也较强,适用性较广。随机森林的主要算法步骤如表2。

表2 RF算法训练步骤
但是,单独的随机森林算法难以有效处理数据不平衡问题,会导致分类性能差。基于此,本文在数据级方面使用ADASYN-LOF算法使数据达到平衡,进一步提升分类性能,并且与随机森林构成ADASYN-LOF-RF组合模型,可以提高预测结果的精确性能。该模型先通过ADASYN采样算法增加少数类样本的数量,使数据达到平衡。针对数据集中存在的噪声样本,使用LOF算法对新增加的合成样本去噪,提升平衡数据集的质量,提高其分类性能。最后使用随机森林算法对最终数据集进行分类预测。该模型的主要流程如图1。
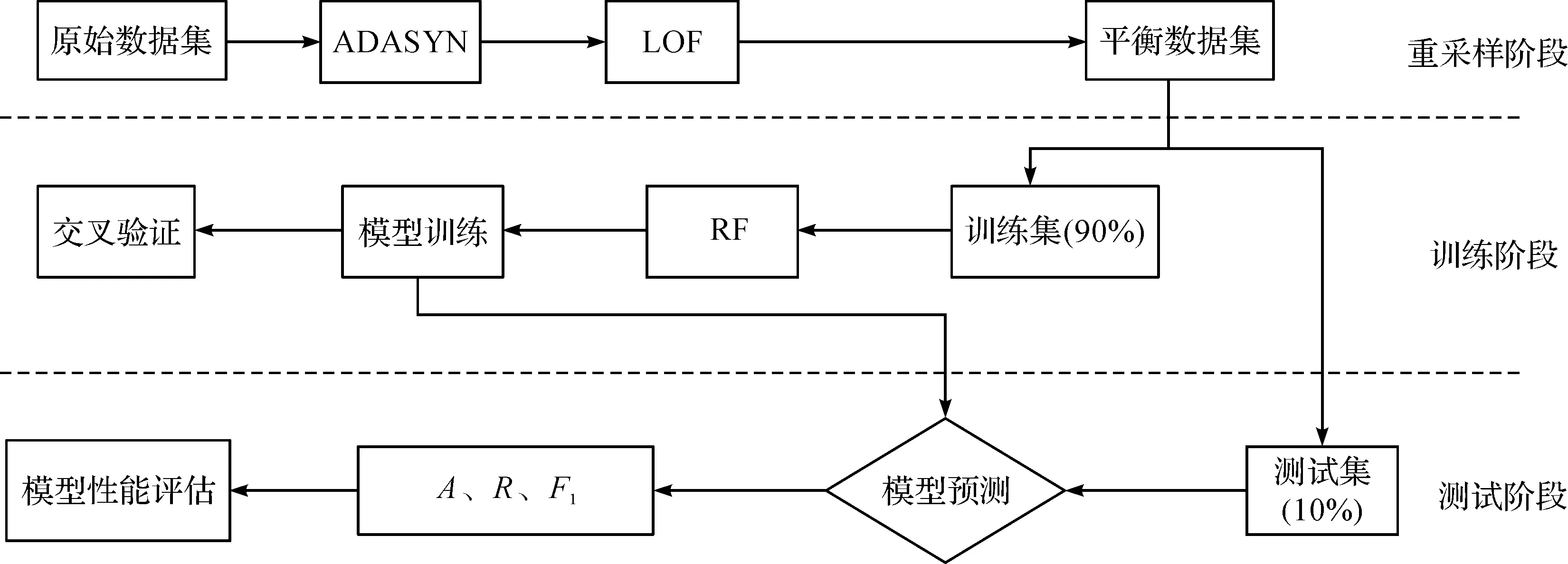
图1 ADASYN-LOF-RF算法流程图
2 实证研究
2.1 专利指标体系构建
基于现有研究,本文构建核心专利指标体系,包含9个指标,如表3。具体指标含义以及指标与核心专利之间的关系解释如下。
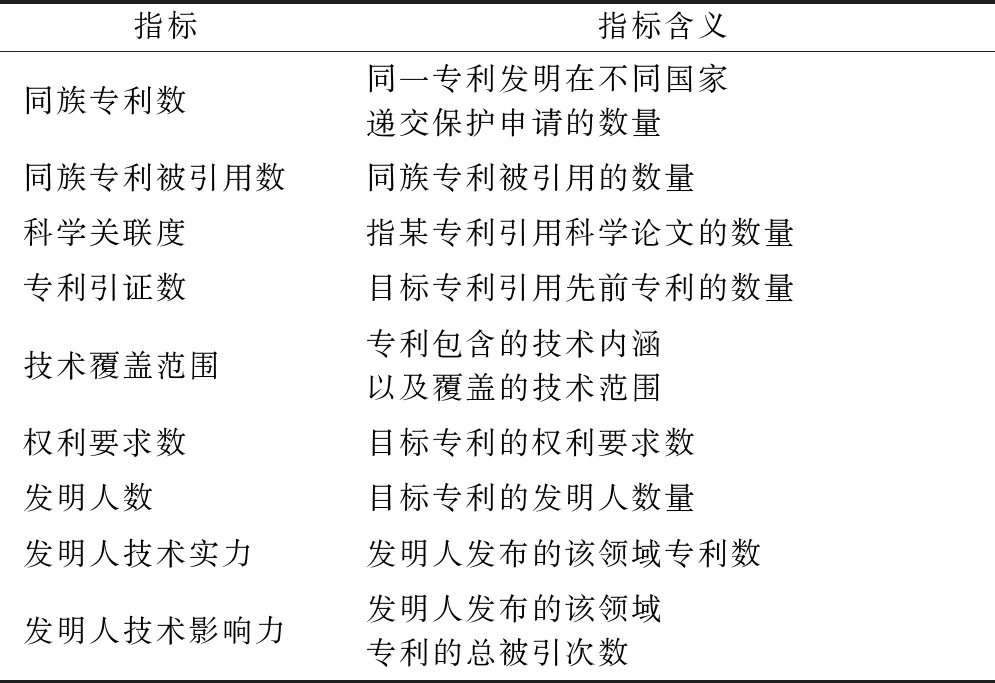
表3 专利指标体系
同族专利数指同一专利在不同国家或地区,以及地区间专利组织多次申请、多次公布或批准的内容相同或基本相同的一组专利文献的数量。已有研究表明同族专利数与核心专利显著正相关[9]。同族专利被引用数是指目标专利和其同族专利总的被引用数量,该项指标体现目标专利在领域内的核心程度,同时也体现该专利的技术影响力。同族专利被引用数越高,对其它专利技术的参考价值越大,越有可能是核心专利[7]。科学关联度指目标专利引用非专利文献的数量,马瑞敏[9]发现科学关联度指标数值越大,专利的技术水平也越高,两者呈现显著正相关。专利引证数是目标专利引用其它专利的数量,反映其技术关联程度。专利引证数越高,就越有可能是核心专利[8]。技术覆盖范围一般用专利IPC分类号数量来衡量。Lerner[27]认为IPC分类号数量越多,专利技术越为复杂,也就越有可能成为核心专利。权利要求数指一项专利要求的权利保护数量。专利要求数越多,专利的技术特征越多,技术创新能力越强,专利也就越重要[28]。发明人数指目标专利发明人数量的总和,它反映企业对该项专利技术的重视程度。一般而言,发明人数量越多,则技术研发成本投入越大,越有可能突破技术壁垒,成为核心技术[29]。发明人技术实力[30]使用专利发明人在该领域内发布的专利数总和进行衡量,该指标反映专利发明人对该领域知识的了解程度。通常,专利发明人在该领域内发布的专利数越多,该发明人的实力就越强,其发布的专利也就越有可能成为核心专利。发明人技术影响力[30]一般用专利发明人在某一领域内所发布专利的总被引次数来衡量。被引次数越多,技术影响力越大,越有可能成为核心专利。
2.2 数据描述
本文使用的光伏专利数据来源于智慧芽专利检索平台,根据光伏领域相关的专利信息并综合使用专利检索方法,确定专利检索策略为:TAC:(photovoltaic* OR PV System* OR solar cell* OR Solar Batter* OR Solar module*),筛选出已授权的发明专利,并将搜索时间定为2012—2016年,共检索到22 077条该领域相关的专利数据。
2.3 数据预处理
数据预处理主要是对各项专利指标数据的处理。整理发现发明人数量和IPC分类号数量均存在缺失值,将缺失值删除后得到21 802条数据。根据核心专利的定义并参考以往的实践研究,将总被引次数排在前百分之十的专利标记为核心专利[10],数据不平衡比1∶9。使用Python软件,选择imbalanced-learn中的ADASYN进行数据采样处理,扩充后的数据集达到39 246条,再使用LOF对数据集进行降噪处理,最终得到32 896条数据。
2.4 分类结果比较
本研究所采用的数据划分方法是十折交叉验证法,即将所有的数据划分成十份数量相等、大小相似的互斥子集,再将所得到的数据中九份作为训练集,一份作为测试集,依次迭代,进行十次训练和测试。从模型准确性和模型稳定性两个方面,将组合模型与SVM、RF、ADASYN-RF三种分类算法来进行比较。
2.4.1 评价指标介绍
实验所预测的是一个二分类问题,因此采用准确率(accuracy,A)、R召回率(Recall,R)和F1值三个评价指标对模型效果进行评价。对于二分类问题,可以将数据集中的真实类别和分类器预测的类别进行组合,划分成四类,用混淆矩阵来表示(如表4)。

表4 混淆矩阵
1)准确率A
ACC表示的是分类正确的样本数占样本总数的比例,在本研究中即为分类正确的核心专利占总专利的比例。在数据不平衡的分类任务中,它是比较常用的性能度量指标。由表中的二分类混淆矩阵可以将ACC表示为
(1)
2)召回率R
Recall召回率也叫查全率,表示原样本集中有多少是被预测正确的。在本研究中表示被正确识别出来的核心专利占原样本核心专利的比例。
(2)
3)F1值
F1值是精确率和召回率的调和平均数,可以用混淆矩阵将F1得分表示为
(3)
2.4.2 模型准确性分析
本研究使用的是十折交叉验证法,通过A均值、R均值和F1均值对ADASYN-LOF-RF进行分类性能验证,并将该模型与SVM、RF、ADASYN-RF对比,进行有效性验证。通过表5,可以看出每种算法的分类效果。
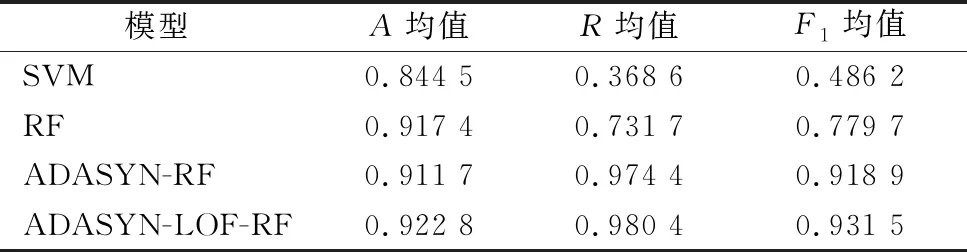
表5 模型准确性均值
ADASYN-LOF-RF和SVM、RF、ADASYN-RF等算法分类性能的对比结果如表5。结果表明,RF的各项指标明显高于SVM,说明集成算法优于单一算法。通过ADASYN-RF和RF的对比,可以看到虽然ADASYN-RF的ACC均值略低于RF,但总体性能明显优于RF,说明对数据采样处理是有效的。在采样基础上进行LOF降噪处理的ADASYN-LOF-RF模型要比直接使用采样的ADASYN-RF更有效果,各项指标得到明显提升。
通过表5中A均值对比,可以看到ADASYN-LOF-RF的A均值为0.922 8,其它模型的ACC均值较低,说明该模型的区分能力较强,能够准确识别出核心专利。对于R这一指标,SVM的R值仅为0.368 6,RF的R值为0.731 7,经过采样后的ADASYN-RF算法达到0.974 4,而ADASYN-LOF-RF的Recall为0.980 4,说明该模型能够识别出更多的核心专利。SVM的F1均值为0.486 2,RF的F1均值为0.779 7,ADASYN-RF的F1均值为0.918 9,经过降噪后的ADASYN-LOF-RF模型的F1均值达到0.931 5,表明该模型整体性能优于其它模型。
综上所述,ADASYN-LOF-RF模型的A均值、R均值和F1均值均优于其它几个模型,这说明该模型在核心专利识别时具有更高的准确性。
2.4.3 模型稳定性分析
模型预测结果的波动程度也是评价模型性能的重要指标。本研究使用十折交叉验证法,直接通过十次测试结果计算标准差,标准差越小,说明模型越稳定。通过表6可以看到ADASYN-LOF-RF的标准差值最小,说明该模型识别性能最稳定。同时我们也可以看出标准差值中SVM>RF>ADASYN-RF>ADASYN-LOF-RF,说明单一算法稳定性最差;对数据进行采样处理后的ADASYN-RF模型稳定性要优于单独使用集成算法;在采样基础上对数据进行降噪处理的ADASYN-LOF-RF模型要比ADASYN-RF更稳定。

表6 模型稳定性
综合以上分析,本文提出的模型不仅在A、R、F1值上都优于其它分类模型,具有较高的准确性,并且在模型稳定性上,波动程度小,稳定性更强。因此,ADASYN-LOF-RF在核心专利的识别中更具有优势。
2.5 模型可解释性
通过随机森林算法,我们可以直接导出所选取的指标相对于核心专利的重要性程度,如图2,常见的技术覆盖范围、发明人数量、权利要求数量等指标与核心专利的关联程度不强,而本研究中新加入的发明人技术实力和发明人技术影响力这两个指标排序比较靠前,这也进一步验证新加入指标的合理性和有效性。

图2 指标重要性排序
3 结论与展望
如何从海量专利中识别出核心专利,是企业开展技术研发、提升创新能力的关键环节。针对现有研究在指标选取和不平衡数据处理方面的不足,本文通过增加专利发明人指标重构指标体系,同时结合采样技术和集成算法,提出组合模型ADASYN-LOF-RF。通过与SVM、RF、ADASYN-RF进行对比,证实ADASYN-LOF-RF在模型准确性和模型稳定性上都具有较好的分类性能;并通过指标重要性排序证实新加入的两个专利发明人指标的合理性。
基于本文的模型对比实验结果以及实证分析,可以得出以下两点结论:第一,使用采样技术和集成算法的组合模型能够提高核心专利识别的准确率,并且稳定性较好;第二,在梳理现有相关文献的基础上,本研究构建的核心专利识别指标体系是有效的。
本研究也具有一定的局限性:第一,每种算法都有优缺点,为提高核心专利识别的准确率,未来可尝试对集成算法进行改进,如加入代价敏感学习等。第二,在未来的研究中,有必要考虑引入专利网络中心度的概念,将其作为机器学习模型的输出指标,对核心专利进行标记。第三,核心专利的早期识别对企业实施专利布局具有更高的价值,未来研究需关注核心专利的早期识别问题。
