用孪生网络进行人脸识别与效果分析
2023-01-11火善栋
火善栋
(重庆三峡学院计算机科学与工程学院,重庆 404000)
0 引言
到目前为止,人脸识别已经是一项比较成熟的技术,而且成功应用于各种商业领域,但是,这些人脸识别技术不是算法过于复杂,就是技术不够透明。为了克服这些技术壁垒,构建属于自己的人脸识别系统,本文在已有的技术之上,通过构建孪生网络来探索该网络模型在人脸识别上的有效性。
人脸识别属于图像分类问题,神经网络模型的传统做法是:先使用大量带标签的图片训练模型,然后让训练好的模型对不在训练集中的图片进行分类,去预测输入的图片属于哪一类。如果采用传统的方法进行人脸识别,就需要把每一个不同的人脸图片做为一个类别,然后采集大量的相同,或不同的人脸在不同状态下的图片进行分类训练,这样造成的问题就是,一方面分类数量庞大,另一方面对个人人脸图片采集的难度也比较大;再者,即使完成了训练,也只能对已经训练过的人脸进行识别,对于陌生的人脸则无法识别。这样,一旦要识别的人群发生变化,整个模型则需要重新进行训练,因此,采用传统的方法进行人脸识别,其网络模型的可扩展性也比较差,不具备实用价值。
孪生神经网络是基于两个人工神经网络建立的耦合网络,孪生网络可以利用相同样本对和不同样本对之间的区别,训练出一个网络模型,使同类样本生成的特征向量相近,不同样本的特征向量远离,从而让网络能够识别两张不同人脸的差别,进而达到进行人脸识别的目的。训练孪生网络的主要目的就是提高网络模型的辨别力,对于任意输入的两张人脸图片,网络模型能够识别是同一个人还是两个不同的人,由于网络模型自身的特点,训练好的网络模型可以对已经训练过的人脸图片或者其它任意陌生的人脸图片进行有效的识别,因此,孪生网络的通用性比较好。
采用孪生网络进行人脸识别,为了提高识别速度,通常会对要进行识别的人脸图片进行采集并预先计算出特征向量并保存在数据库中,在进行人脸识别的时候只需计算待检测人脸的特征向量,然后与数据库中的特征向量做比较,并通过设置合理的阀值从而达到人脸识别的目的。
1 人脸识别的具体步骤
1.1 构建残差网络[1]
采用pytorch[2]构建残差网络,图1为18层残差网络的基本结构,整个网络总体由输入层、残差层和输出层三部分组成。输入层由一个卷积层和一个池化层组成;输出层由一个池化层和一个全连接层组成;残差层由四个残差模块组成,每个残差模块包含有两个残差块,每一个残差块由两个卷积层组成,除第一个残差模块输入和输出向量长宽不变以外,其它残差模块输出向量长宽减少一半,通道数增加一倍,由于本实验采用18层残差网络结构实验效果不是太理想,故采用了34层残差网络结构,34层与18层残差网络结构输入层与输出层是一样的,不同的是每个残差模块中残差块的个数不同,18层网路结构每个残差模块残差块的个数都为2,32层每个残差模块的残差块个数分别为3、4、6、3。
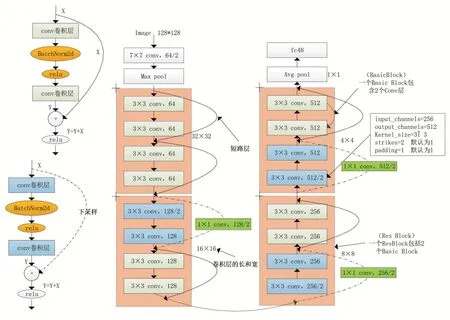
图1 18层残差网络结构图
1.2 构建孪生网络[3]
以34层残差网络为基本网络结构,构建孪生网络,两个34层残差网络其参数是一样的,其网络结构如图2所示。
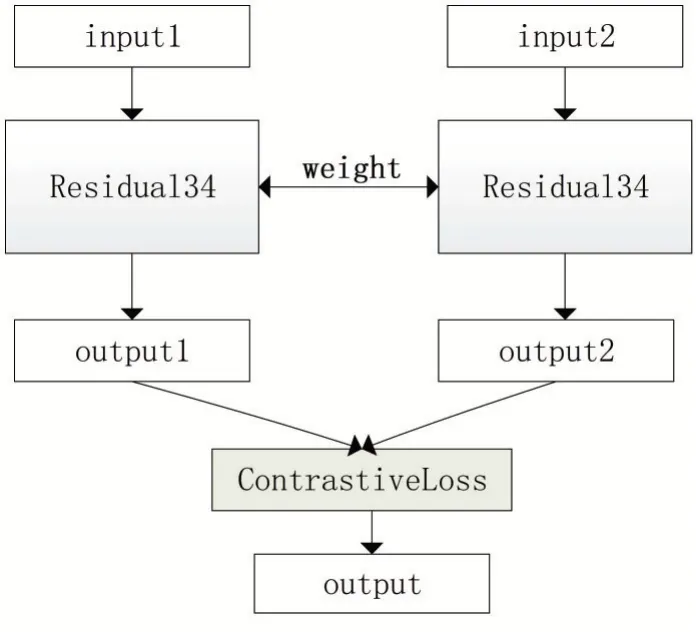
图2 孪生网络结构图
图中Contrastive Loss[1]为损失函数[4]:
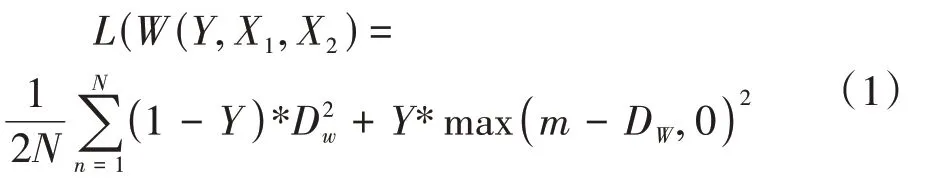
其中:Dw代表两个样本输出特征向量的欧氏距离(本实验特征向量的长度设置为10)。
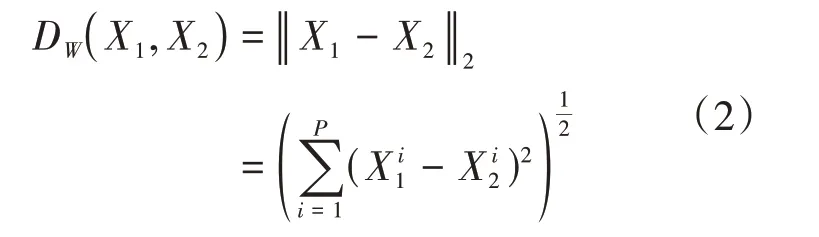
式(1)中Y为两个样本是否匹配的标签,Y=0代表两个样本相似或者匹配(同一个人脸照片);Y=1则代表不匹配(不同的人脸照片);m为设定的阈值(本实验定为2.5),表示当人脸不相同时,只考虑不相似特征欧式距离在0~m之间的特征差值,当特征距离超过m时,则将其loss看做为0。
ContrastiveLoss损失函数所要达到的目的是:同一个人脸不同照片特征向量的距离越小越好,不同人脸照片特征向量的距离越大越好。
1.3 数据预处理
从网上下载数据集(外国人脸数据集,一共有500个不同人的照片,每个人有5张不同状态的照片,累计总共有2500张照片,为了缩短训练时间,本实验只采用了其中的200个人、1000张照片进行训练);为了去掉图片噪音对人脸识别的影响,采用openCV对这1000张照片进行人脸检测。由于进行人脸检测时,有的图片人脸的检测效果不是太好,为了保证训练人脸图片的质量,最后通过人工的方式对无法检测到人脸的照片或者人脸检测错误的照片进行裁剪,得到正确的人脸图片,其效果如图3所示。
图3 人脸检测效果示意图
1.4 网络训练
随机从训练集中提取样本数据,以32个样本(正样本和负样本各占50%)作为一个训练批次(注:一次迭代总的训练批次为1000/32=32次),网络总的迭代次数设置为500(网络累计训练次数大约为32×500=16000次),其训练效果如图4所示,从训练结果来看,随着迭代次数的增多,总的趋势是差值越来越小,但在迭代过程中,误差损失一直不稳定,呈现出细微的波动。
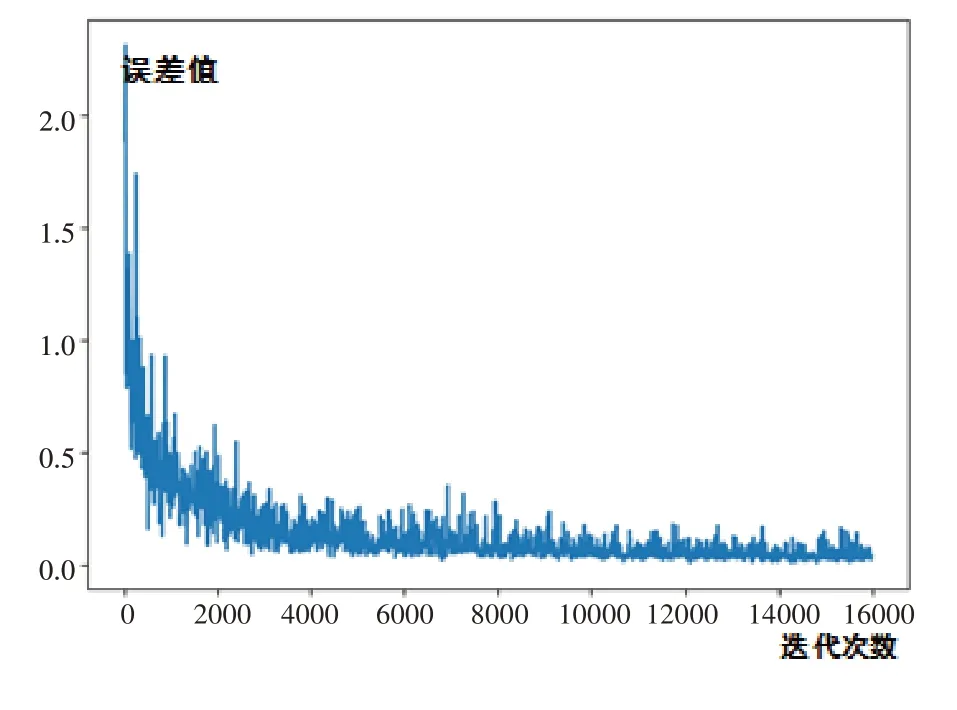
图4 训练迭代次数与损失函数差值结果图
1.5 网络测试
从数据集中未参与训练的照片中随机抽取16组照片(8组人脸相同,8组人脸不相同)进行对比测试,其结果如图5、图6所示。
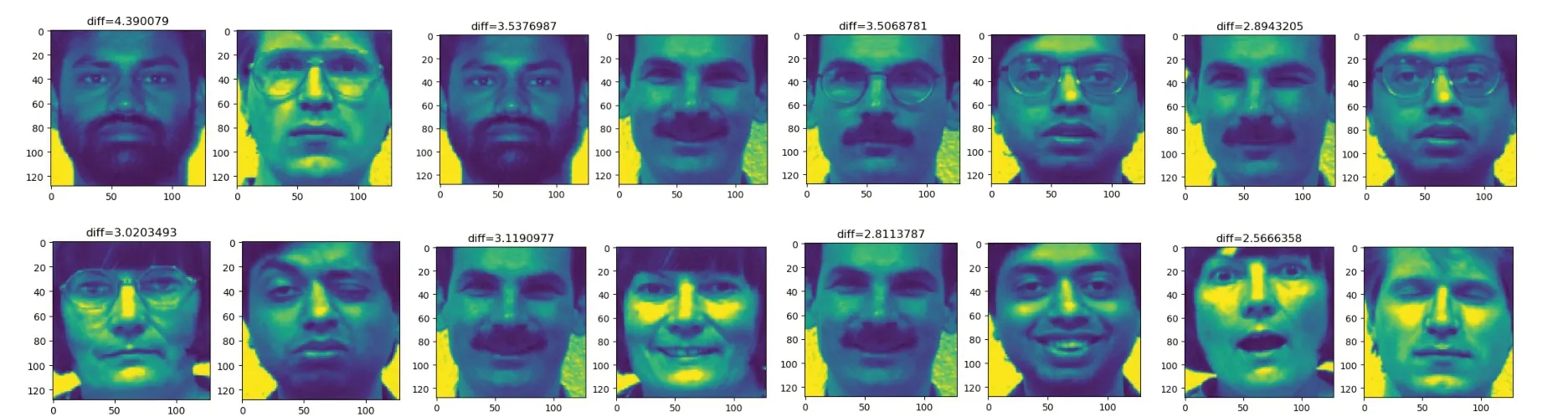
图5 不同人脸识别截图

图6 相同人脸识别截图
从上面几组照片测试结果来看,孪生网络在人脸识别方面可以达到一定的效果,不相同人脸特征差基本在2.5以上;相同人脸特征差总体上虽然偏小(最小可以达到0.5102),但是,有一组特征差值达到了2.4175,这样必然会导致人脸识别出错。当然,以上只是在训练样本比较少而且有些样本图片比较模糊的情况下得到的结果,如果在算力允许的情况下,改善网络结构,优化训练算法,提高训练样本图片的质量,加大训练样本的规模和迭代次数,还是有可能达到一个比较理想的效果。

表1 不相同人脸特征差值表

表2 相同人脸特征差值表
2 结语
为了比较不同网络结构对人脸识别的效果,本文也通过比较流行的VGG19、ResNet50、Inception[5]等网络构建孪生网络,并进行了训练和测试,其效果各有千秋。总之,由于用孪生网络进行人脸识别最本质的特点就是:通过学习样本,训练网络模型对相同和不同人脸的分辨力,相同的人脸特征值差越小越好,不相同的人脸特征值越大越好,这样必然会导致相同的人脸在状态差别比较大或者不相同人脸在特征相貌非常相似的情况下很难达到正确识别的目的;但是,由于孪生网络其原理和构建都比较简单,而且通过小样本训练就可以在一定程度上达到正确识别的目的,所以,在一些人脸识别不太严格的场合,例如,住宅小区人脸识别、人脸考勤等方面通过改善训练样本图片的质量,提高人脸检测的准确度以及对人脸不同状态进行多次识别的情况下仍然具有一定的实际意义。
