基于最大熵强化学习的电网自主拓扑切换控制技术
2023-01-09马世乾黄家凯崇志强韩枭赟穆朝絮
马世乾,黄家凯,崇志强,韩枭赟,徐 娜,穆朝絮
(1.国网天津市电力公司电力科学研究院,天津 300384;2.天津大学电气自动化与信息工程学院,天津 300072)
目前,随着高比例可再生能源广泛接入电网,我国电网运行特征朝着电力电子化方向快速发展,其运行过程中的随机性、动态性、波动性和复杂性显著增强[1]。一般情况下,大型电网的建设和运行过程中遵循包括功率、电压、线路潮流等在内的多项安全指标[2-3],以保障正常及故障工况下的安全稳定运行。但在某些突发重大故障时,例如可再生能源的快速波动所导致的局部功率不平衡,如果没有及时、有效的电网调控手段,局部扰动可能会扩散,进而导致连锁故障,甚至大停电。例如2019年7月美国纽约曼哈顿大停电、2020年8月美国加州大停电[4]和2021年2月美国得克萨斯州大规模停电等事故。这些问题也是传统电网自动控制方法难以解决的问题。因此,实时监测电网异常并制定快速、准确的在线调控决策,对于确保电网安全稳定运行至关重要。
随着新一代人工智能技术的快速发展,深度强化学习DRL(deep reinforcement learning)技术在多个领域(例如AlphaGo[5]、无人驾驶[6]、工业自动化[7]等)成功应用,为电网实现智能自主运行提供了借鉴和参考。已有部分学者将DRL算法用于电力领域,多侧重于负荷预测、可再生能源预测、安全性预测等方向。文献[8]针对可再生能源的不确定性提出了一种基于连续作用域的DRL无模型负载频率控制方法。文献[9]提出了一种新的联络线功率调整方法,该方法采用自适应映射策略和马尔可夫决策过程公式,然后采用一种无模型DRL算法来求解所提出的马尔可夫决策过程MDP(Markov decision process)并学习最优调整策略。文献[10]提出了一种基于DRL算法的数据驱动多智能体电网控制方案,以有效解决自主电压控制问题。文献[11]在考虑负荷需求和电价的不确定性的基础上,将基于深度Q网络DQN(deep Q network)方法应用于微电网的实时能量优化调度。文献[12]提出了考虑不确定性的深度期望Q-learning算法来求解微电网的实时优化问题。然而,在电网安全稳定运行领域,DRL技术的研究与应用鲜见报道。
本文在上述研究成果的基础上,针对电力系统在运行过程中出现计划检修(已知传输线故障)和随机故障(未知传输线故障)等影响电力系统稳定运行的情况,提出了一种基于最大熵强化学习SAC(soft actor-critic)算法的电网自主拓扑切换控制算法,设计了基于模仿学习IL(imitation learning)的神经网络预训练方案,进一步改进SAC算法中重要的超参数α,使得α在训练过程中能够自主调节,进一步提高算法控制效果。最后,将所提出的模仿学习-最大熵IL-SAC(imitation learning soft actor-critic)算法应用于Grid2Op环境中的IEEE 45节点算例,并与现有的其他DRL算法进行对比,例如SAC、PPO(proximal policy optimization)、双深度 Q网络DDQN(double deep Q network)。结果表明,该算法训练好的IL-SAC智能体可与电网实时运行环境进行交互,在亚秒级内给出控制决策,保证了电力系统连续安全稳定运行。
1 DRL与SAC算法
1.1 DRL基本原理
人工智能是研究如何使用计算机来模拟人的某些思维过程和智能行为从而完成特定任务的学科。机器学习作为人工智能的核心,主要可以分为监督学习、无监督学习和强化学习RL(reinforcement learning)3大类。3类学习方法均可以通过学习和训练复杂随机动态系统的大量观测数据,迭代更新网络模型,最终实现根据当前时刻观测值给出实时可靠的动作策略。RL又作为机器学习的核心,可以更加智能化地解决复杂动态物理系统的实时控制和决策问题。图1为RL智能体与电力系统环境的交互过程。首先,智能体给出动作(action)到电网环境中,电网环境在执行该动作之后会返回相应的新系统状态(state)和奖励值(reward);然后,智能体再根据返回的状态和奖励值,以能够获得最大化奖励期望值为目标,更新网络参数,改进动作输出策略;最后在与电网环境的不断交互中使输出策略最优化。

图1 RL智能体与电力系统环境交互过程示意Fig.1 Schematic of interaction process between RLagent and power system environment
深度学习DL(deep learning)是机器学习的一个新研究方向,其通过表征学习平台、学习样本数据的内在规律和表示层次,一般使用深度神经网络描述复杂物理系统的输入、输出关系。DL的优点在于可以自主智能地提取大量观测数据样本中有效的样本特征,并用于训练智能体以提升其性能。
DL具有强大的感知能力,但是决策能力有欠缺;RL具有强大的决策能力,但是缺乏相应的感知能力。DRL技术是将两者结合起来,优势互补,其主要是在与环境交互迭代的过程中自主学习,并逐步提高推理、决策等智能化能力,为复杂物理系统的决策问题提供了新的解题思路。
1.2 SAC算法
由于当前新型电力系统的随机性、复杂性,而SAC算法在收敛性和鲁棒性方面相比于其他DRL算法更为优越[13],因此本文基于SAC算法提出了一种电网自主拓扑控制算法。
SAC算法与其他DRL算法最大的区别是在同样使用了值函数和Q函数的情况下,SAC算法的目标是追求最大化预期奖励值积累的同时追求最大化的信息熵值,即在满足控制性能要求的前提下采取尽可能随机的控制策略[14],而其他DRL算法的目标一般只追求最大化预期奖励值的积累。SAC算法的核心部分是更新最优策略的公式,可表示为

式中:J()为SAC算法的目标函数;π和π*分别为控制策略和最优的控制策略;st和at分别为t时刻下的状态和动作;r(st,at)为状态是st时进行动作at得到的奖励值;H(π(·|st))为状态是st时控制策略π的熵值;E(st,at)~ρπ为当状态动作对(st,at)概率分布为ρπ时的期望奖励值;α为鼓励新策略探索的程度,在文献[14]被称作温度系数(temperature parameter)。
针对电网自主拓扑切换实现安全控制这一决策问题,SAC算法在随机策略下拥有更加强大的可行域探索能力[15]。SAC算法训练网络的过程与其他策略梯度算法相似,采用带有随机梯度的人工神经网络来进行控制策略的评估与提升。在构造其值函数Vψ(st)和Q函数Qθ(st,at)时,分别使用神经网络参数ψ和θ来表示。SAC算法的值函数被称为“柔性”值函数,作用是逐步更新策略,使得算法的稳定性、可靠性得到保障。根据文献[14],基于最小化的误差平方值可以更新“柔性”值函数神经网络的权重,即

式中:D为先前采样状态的分布空间;Est~D为对误差平方的期望值;Eat~πΦ为控制策略πΦ下控制动作at的期望;π(at|st)为状态是st时动作选取为at的概率。
然后求取式(3)的概率梯度,其计算公式为

同理,可通过最小化“柔性”贝尔曼残差(soft Bellman residual)的方式来更新“柔性”Q函数的神经网络权重,其计算公式为

式中:γ为折扣因子;E(st,at)~D为预估Q值与目标Q值误差的期望值;Est+1~ρ为满足概率分布ρ的状态st+1的期望值;为目标状态价值函数值,目标状态价值网络参数定期更新;Vψ(st+1)为预估状态价值函数值;()为目标Q值。
与式(3)同理,式(5)的优化求解可由概率梯度进行计算,即

与其他的确定性梯度算法不同,SAC算法的控制策略输出值是由平均值和协方差组成的随机高斯分布表示的,可以通过最小化预期Kullback-Leibler(KL)偏差来更新其控制策略的神经网络参数,以Φ作为参数的控制策略π的目标函数可将式(2)具体化写为

式(8)的优化求解过程可由概率梯度计算得出,即

在此基础上,根据文献[13]可知,温度系数α自主调节的核心更新过程可以表示为

2 基于DRL的自主拓扑切换控制算法
2.1 Grid2Op环境介绍
Grid2Op是L2RPN WCCI 2020挑战赛中使用的电网运行开源仿真平台。Grid2Op是在实际电力系统运行中发现的,并用于测试先进控制算法的现实概念建模,该仿真环境遵循实际电力系统的运行约束和分布[16]。Grid2Op中每个变电站均为双母线系统,这意味着连接到变电站的元件(即负载、发电机和线路)可以分配到两条母线中的任意一条,因此可以将每个变电站视为2个节点。
Grid2Op中双母线变电站示意如图2所示,圆圈表示2号变电站,该变电站延伸出4条线路。以1号线路为例,进行细节放大可以看出,1号电力传输线路可选择该变电站的母线a或母线b,这便是Grid2Op双母线系统的特性。

图2 Grid2Op中双母线变电站示意Fig.2 Schematic of double-bus substation in Grid2Op
Grid2Op中电网状态由各种特征组成,例如拓扑结构、每个发电机提供的负荷、每个负载所需的负荷、在每条线路中传输的功率等。Grid2Op提供了相应的接口,用来观测及调用这些特征的实时变化值。此外,每条线路都有自己的输电能力,当传输功率量溢出时,可以自动断开。Grid2Op中输电能力用rho表示,当1≤rho≤2时,Grid2Op允许线路过载2个时间步;当rho>2时,该线路立即断开。Grid2Op规定所有断开线路在断开12个时间步之后才能选择是否重连。
智能体通过算法提供的策略在变电站和输电线路上做出具体动作来管理电网。变电站上的操作称为母线分配,将与变电站相连的元件分配给母线。线路上的动作称为线路开闭,用于断开线路或重新连接断开的线路。Grid2Op允许智能体每个时间步执行1个母线分配或线路开闭动作。Grid2Op中出现以下两种情况会使电网运行立即终止:①负载所需的负荷量无法提供,即电网功率不平衡,在有较多断开的线路时可能发生电网运行立即终止;②由于智能体执行的动作使得负载、发电机或者变电站形成孤立的节点,在智能体拓扑控制策略不合理时有可能发生电网运行立即终止。
2.2 电力系统的约束型MDP建模
电网中的诸多控制决策问题都可以描述成MDP,用于解决随机动态环境下的离散时序控制问题[17-18]。针对于Grid2Op电网中的双母线系统拓扑切换控制,相应的约束型MDP可用5维元组(S,A,P,R,C)描述。其中,S为该电网的状态集;A为该电网的动作集;P为状态转移概率,P:S×A×S→[0,1];R为奖励机制,R:S×A→R;C为奖励机制所对应的约束条件。
1)状态集S
状态变量的选取对RL的效率及泛化性有一定影响,在t时刻Grid2Op系统状态st∈S,可表示为

式中:N、J、K分别为该电网中线路总数、发电机节点总数、负载节点总数;fi为第i条电力传输线上的开断状态,fi是1个布尔值变量,当fi=1时表示传输线为断开状态,当fi=0时表示传输线为连接状态;rhoi为第i条线路上的负载率;PGj、QGj、VGj分别为第j个发电机节点上的有功出力、无功出力及电压;PLk、QLk、VLk分别为第k个负载节点上的有功需求、无功需求及电压;为第k个负载节点上t+1时刻的有功需求预测值。以上变量都可以通过Grid2Op电力系统仿真模型直接观测或调用的系统观测状态量。
2)动作集A
动作变量即系统可调整变量,t时刻Grid2Op系统的动作变量at∈A,可表示为

式中:M为该电网变电站总数;BDm为第m个变电站节点上的母线分配变量,BDm是1个布尔值变量,当BDm=1时表示选择变电站中的母线a,当BDm=0时表示选择变电站中的母线b;LSn为第n个变电站节点上的线路开闭变量,LSn是1个布尔值变量,当LSn=1时表示断开传输线,当LSn=0时表示连接传输线。
3)状态转移概率p
状态转移概率表示给定当前状态st∈S及动作at∈A下状态从st变换到st+1的概率,即

由于该系统受到确定性故障及不确定性故障的影响,状态转移概率难以用精确的概率分布模型来描述。本文采用的DRL算法从历史数据中采样,从而隐式学习得到该概率分布。
4)奖励机制R及相应约束条件C
本文设置的奖励可分为符合电力系统常规知识经验得到的奖励和符合约束条件得到的奖励两类。
(1)常规知识经验奖励。
电力系统运行过程中机组存在运行费用,在t时刻可用负奖励表示,即

在新型电力系统运行过程中,由于新能源接入给电网负荷带来不确定性,输电线路过载概率也将提升。故线路负载率rho成为奖励设计过程中一个非常重要的参数,直接影响整个电力系统运行的安全稳定。本文根据一般经验设计关于rho的奖励为

(2)约束条件奖励。
根据状态空间观测值,本文设计的奖励约束条件主要有机组的有功出力约束C1、机组的无功出力约束C2、机组和负载节点的电压约束C3、电力系统整体功率平衡的约束C4,C1、C2、C3、C4∈C。当 Δa=at+1-at≠0 时,约束条件C1、C2、C3、C4可分别表示为



式(21)~(23)和式(26)设计的奖励函数侧重于实现系统功率平衡,以及防止机组有功功率越限,这是基于工程实际的考虑[19]。
综上所述,t时刻奖励函数rt可表示为

2.3 基于DRL的自主拓扑切换控制算法总体架构
基于DRL的电网自主拓扑切换控制算法训练智能体的总体架构流程设计如图3所示,主要步骤如下。
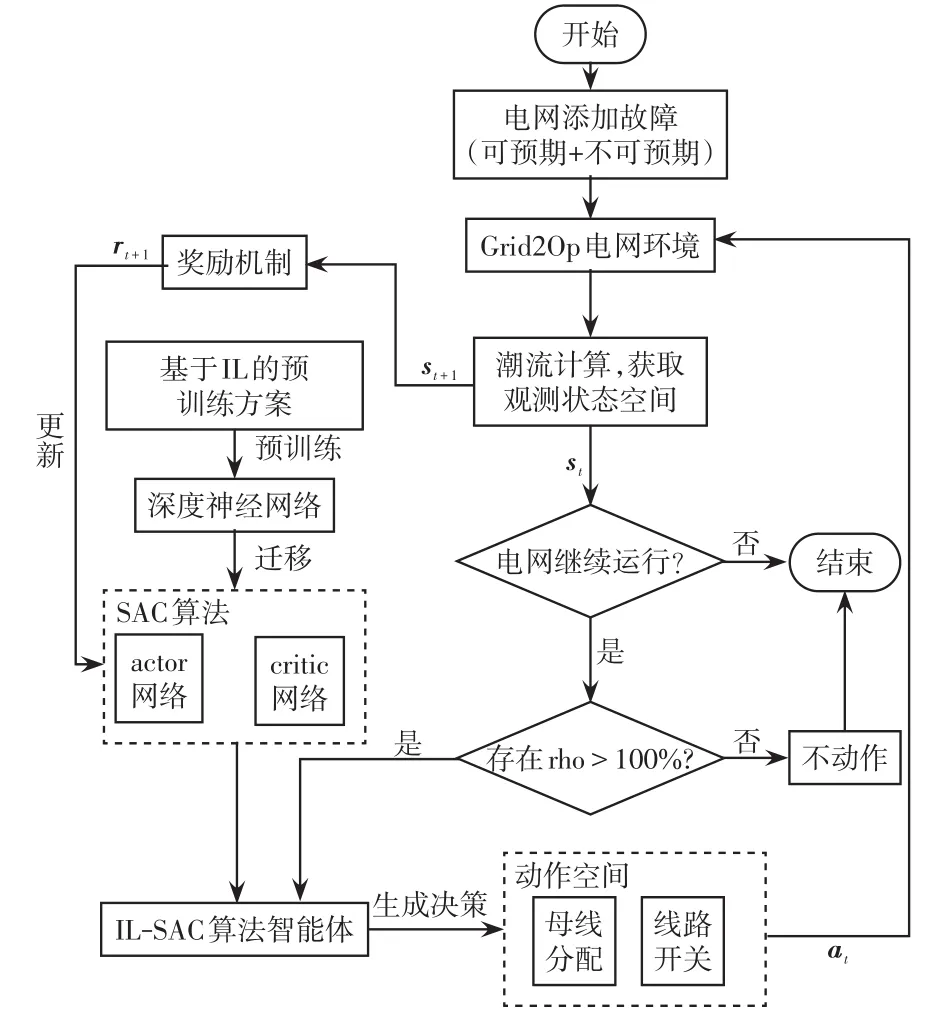
图3 基于DRL的自主拓扑切换控制算法总体架构流程Fig.3 Flow chart of overall architecture for DRL-based autonomous topology switching control algorithm
步骤1根据当前电网工况,在Grid2Op电网仿真环境中添加随机和已知的输电线路故障,以模拟实际运行情况。在该仿真环境进行潮流计算,然后通过调用程序接口获取相应的观测状态空间。
步骤2基于IL的预训练方案采样已存储的电网历史状态向量,预训练深度学习网络,并迁移至SAC算法中actor网络和critic网络中使用,该模块在第2.4节中详细描述。
步骤3实时观测到的状态空间首先用于判断当前Grid2Op中的电网是否达到终止条件。若达到终止条件,则电网不会继续运行,直接结束流程;反之,则继续判断当前电网中是否有输电线路的rho>100%,这是影响电网安全稳定运行的重要因素。若不存在输电线路的rho>100%,则不进行任何动作;若存在1条或多条该线路的rho>100%,则需要调用IL-SAC智能体生成决策,并进行动作,返回Gird2Op电网仿真环境
步骤4在IL-SAC智能体生成动作并返回环境后,仍可根据实时观测状态空间及奖励机制,更新SAC算法中的神经网络参数,继而更新IL-SAC智能体。反复实施以上4个步骤,从而达到训练ILSAC智能体的目的。
2.4 基于模仿学习的预训练方案
由Grid2Op电网环境及当前电网环境的约束型MDP模型可知,针对该电网环境进行DRL将会存在如下2个比较突出的问题。
(1)Grid2Op电网在运行过程中存在终止条件,在RL初始探索优化动作阶段,容易触发该终止条件(例如潮流不收敛、功率不平衡等),使得智能体在初始阶段无法有效地学习经验,算法网络参数更新过程将十分缓慢,即学习效率低、神经网络参数收敛慢。
(2)根据式(11),在RL过程中原始的动作空间相当大,总共有2M+N种动作可选。在本文采用的IEEE 45节点算例中,可选动作达到约1016种。动作空间巨大会导致算法参数更新计算量大、速度慢等问题,甚至会使该算法最终无法收敛。故本文设计如图4所示的基于IL的预训练方案。该预训练方案主要步骤如下。
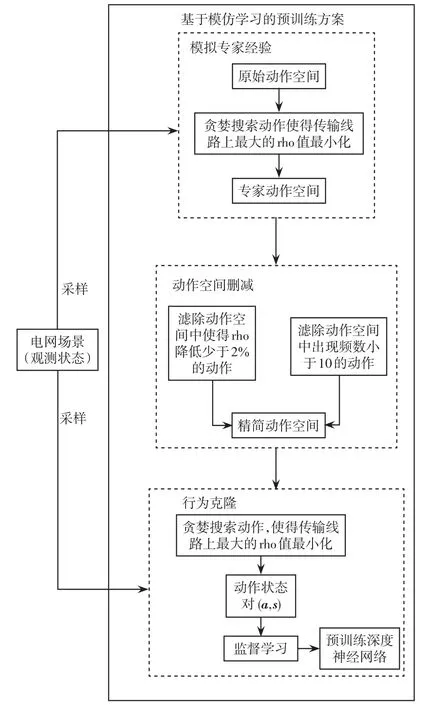
图4 基于模仿学习的预训练方案流程Fig.4 Flow chart of pre-training scheme based on IL
步骤1模拟专家经验过程,从电网仿真环境中采样大量场景,将大量的观测状态空间作为输入量,本文以100 000个场景作为输入量。然后在原始动作空间中基于贪婪算法贪婪搜索最优的动作,最优指标是使这些场景中线路上rhomax最小化。之后,可得到模拟的专家动作空间,对于原始动作空间已有所缩减,但可选动作仍达到1 000余种。
步骤2继续删减动作空间。为此提出两条删减动作空间的准则:①滤除专家动作空间中使rho降低少于2%的动作;②滤除专家动作空间中出现频次少于10次的动作。根据以上两个准则可将专家动作空间删减到100余种可选动作的精简动作空间。
步骤3模仿学习中的行为克隆[20]。仍使用100 000个电网场景作为输入量,基于步骤1的贪婪优化准则,在精简动作空间中贪婪搜索最优的动作,并将对应的电网状态与动作组合形成动作状态对(a,s)。最后,应用(a,s)对设计好的深度神经网络进行监督学习预训练,动作状态对中动作a即为该状态的标签。
3 算例分析及讨论
3.1 仿真算例介绍
为了验证所提出的IL-SAC算法智能体对电网自主拓扑控制的有效性,本文以Grid2Op提供的IEEE 45节点算例为实验对象,其本身为IEEE 118节点系统的局部电网,包含了22个发电机组、36座变电站、37个负载和59条线路,其中安全线路为rho≤60%的线路,危险线路为60%<rho<100%的线路。Grid2Op为该系统提供了100 000组真实场景的数据,调用每组场景时设置的最高存活步数为1 440,即每组场景数据代入时该电网最多稳定运行1 440个时间步,每个时间步为5 min,1 440个时间步对应5 d。
在仿真过程中以此电网算例为基础,添加计划检修和不可预期故障,设计规则如下。
(1)针对计划检修的设计规则为每隔12个时间步断开1条已知线路,即在t时刻可以预测到t+1时刻的断开线路编号。t时刻的状态st改为,即

式中,xt+1为t+1时刻将会断开的线路编号,xt+1=1,2,…,N。
(2)针对不可预期故障的设计规则为每个时间步中设计1%的线路停运概率,即t时刻59条线路出现故障的概率均为1%。
3.2 训练、测试结果以及对比分析
DRL方法应用于Grid2Op仿真环境中的电网拓扑控制较少,因此本文选取两组算法进行对比,以验证所提算法的有效性。
第1组算法对比是SAC算法的纵向性能比较,对比α自更新的IL-SAC算法(后文简称IL-SAC算法)智能体与SAC算法智能体、α固定的IL-SAC算法(后文简称IL-SACF算法)智能体在该电网仿真环境中的性能。本文使用的SAC算法相关参数如表1所示。

表1 SAC算法相关参数Tab.1 Parameters related to SAC algorithm
第2组算法对比是RL算法的横向性能比较,对比IL-SAC算法智能体与PPO算法[21]智能体、DDQN算法[22]智能体在该电网仿真环境中的性能。
值得注意的是,在当前设置故障的情况下,若使用随机动作智能体对该电网仿真环境进行控制,则该电网稳定运行的步数不会超过2个时间步,一般只能运行1步或直接因故障导致的连锁反应而终止运行。
3.2.1 纵向对比训练、测试结果及分析
随机选取Grid2Op提供的8 000组真实电网运行场景数据,其中5 000组用于智能体的训练,其余3 000组用于测试。训练过程中控制的性能指标包括行动网络的loss函数、评价网络的loss函数、奖励值、存活步数。其中,行动网络的loss函数表示对期望奖励值的相反数求最小值,其值越小表示该网络性能越好;评价网络的loss函数表示当前Q值与目标Q值的均方误差,其值越接近于0表示该网络性能越好;奖励值表示智能体在该场景下获得奖励大小,其值越大表示该智能体表现越好;存活步数表示该电网仿真环境在该智能体的调度下持续安全稳定运行的时间步大小,其值越大表示该智能体表现越好。从图5可以明显看出,IL-SAC算法具有更快的收敛速度,收敛后具有更稳定的奖励值和存活步数;而SAC算法的收敛速度最慢,IL-SACF算法收敛后的奖励值和存活步数最低且最不稳定。对比可知,IL-SAC算法在训练过程中具有更好的鲁棒性和可靠性。


图5 IL-SAC算法与SAC算法、IL-SACF算法在训练中控制效果对比Fig.5 Comparison of control effects in training among IL-SAC,SAC and IL-SACF algorithms
在智能体测试过程中,本文设计了分组的测试模式,充分体现测试的随机性特点。实验共分为5组测试,每组测试过程中从3 000组场景数据随机挑选200个输入各个智能体,然后计算各个智能体在这200个场景下的平均奖励值和平均存活步数作为控制性能的指标值。图6为IL-SAC算法智能体与SAC算法智能体、IL-SACF算法智能体在测试过程中对电网控制的效果对比。可以看出,相比于其他两种算法,IL-SAC算法智能体在随机选择场景进行测试时能获得更高的奖励值与更多的存活步数,即可使电网安全稳定运行更长的时间,且该算法的奖励值和存活步数变化也比较小,具有更稳定、更优越的控制效果。

图6 IL-SAC算法与SAC算法、IL-SACF算法在测试中控制效果对比Fig.6 Comparison of control effects in test among ILSAC,SAC and IL-SACF algorithms
3.2.2 横向对比训练、测试结果及分析
与第3.2.1节相同,随机选取Grid2Op提供的8 000组真实电网运行场景数据,其中5 000组用于智能体的训练,其余3 000组用于测试。图7为ILSAC算法智能体与PPO算法智能体、DDQN算法智能体在训练过程中对电网控制的效果对比。训练过程中控制的性能指标包括奖励值和存活步数。从图7可以明显看出,训练过程中IL-SAC算法的收敛速度及收敛之后的奖励值、存活步数、稳定性都是远强于PPO算法和DDQN算法。可见相较于PPO算法、DDQN算法,IL-SAC算法在有效性、稳定性、鲁棒性、可靠性上都具有更大优势。

图7 IL-SAC算法与PPO算法、DDQN算法在训练中控制效果对比Fig.7 Comparison of control effects in training among IL-SAC,PPO and DDQN algorithms
智能体测试模式及测试性能指标与第3.2.1节相同。图8为IL-SAC算法智能体与PPO算法智能体、DDQN算法智能体在测试过程中对电网控制的效果对比。可以看出,IL-SAC算法智能体在测试过程的平均奖励值和平均存活步数同样远高于PPO算法智能体和DDQN算法智能体,相比于DDQN算法,IL-SAC算法控制下电网安全平稳运行的时间步多出1倍以上,相比于PPO算法平均多400时间步以上。可见,IL-SAC算法控制效果的优越性十分突出。

图8 IL-SAC算法与PPO算法、DDQN算法在测试中控制效果对比Fig.8 Comparison of control effects in test among IL-SAC,PPO and DDQN algorithms
4 结语
本文提出了一种基于DRL的电网自主拓扑切换控制方法,该方法充分考虑了由于负载需求变化、可再生能源波动等引起的可预期故障和随机故障情况下新型电网系统的安全稳定运行问题。本文方法的核心是在SAC算法基础上添加了本文设计的IL预训练方案所提出的IL-SAC算法智能体,其能够在亚秒内做出控制决策,重新配置电网的拓扑结构,改变电力流的线路,从而使电能从生产者高效地传输到消费者,保障电网安全运行。最后,利用Grid2Op提供的IEEE 45节点电网模型及真实电网系统场景数据进行仿真,结果表明,本文方法的控制性能优于现有的其他DRL算法,具有较强的高效性与鲁棒性。。
