采用语义一致性编码网络的跨模态语音关键词检索
2023-01-06刘则芬
齐 梅,刘则芬,樊 浩,李 升
(安徽开放大学信息与建筑工程学院,安徽合肥 230022)
随着互联网和通信技术的飞速发展,产生了海量的多媒体数据,如何快速便捷地检索获取有效信息是信息检索领域的一个重要研究方向[1-2].而语音是人类最自然的交流方式,不仅是人与人之间沟通交流的桥梁,也是音频、视频信息传输的重要载体之一.作为实现和改善智能友好人机交互的重要技术,语音检索技术在过去的几十年里一直都是研究热点[3].
语音关键词检索是实现基于内容的语音信息检索的一个重要手段,具有广泛的应用场景[4-5]:
(1)人机交互应用,基于语音的信息检索,可以直接利用便捷的移动设备输入检索词从而解放双手,无需使用键盘、触屏、按钮等.例如车载导航通过语音指令实现目的地查询,家居家电智能语音控制都会给人们的生活带来极大便利.
(2)多媒体信息检索,无论是传统的广播电视,还是从事教育、直播、短视频制作,通过语音关键词检索出用户感兴趣的内容是重要需求.例如在远程教育的课程资源中,可以快速检索出感兴趣的课题知识点.
在海量的多媒体数据中,语音和文本是信息检索中最重要的两个载体.大多数信息检索系统都以基于文本的信息检索为基础,文本信息检索技术已经应用发展得相对成熟,随着大量无键盘应用的出现,基于语音的信息检索也受到越来越多的关注.
目前,构建公共子空间已经成为跨模态语音-文本检索的主流方法,其核心思想是对不同模态的数据进行建模,建立一个有效的映射机制将不同模态的数据映射到一个公共空间.映射机制不仅需要缩小多模态相关数据之间的语义距离,还要扩大语义不相关数据之间的距离,使得在该空间可以直接使用一组语义向量对不同模态的样本特征进行比较.相关的检索方法主要集中在多媒体数据特征学习、跨模态模型检索设计等方面:
(1)数据特征学习方面,代表性的有跨模态因子分析(cross-modal factor analysis,CFA)[6]通过最小化不同模态成对样本之间的弗罗贝尼乌斯范数学习线性映射,将不同模态数据映射到公共空间;典型相关分析(canonical correlation analysis,CCA)[7]通过最大化不同模态样本之间的相关性来学习映射矩阵;多视角判别分析(muti-view discriminant analysis,Mv-DA)[8],联合表示学习算法(jointrepresentation learning,JRL)[9]等.
(2)模型检索方面,典型方法有文本图像协同注意力机制网络模型(Collaborative attention network,CoAN)[10],通过选择性关注内容相似的关键信息部分,使用递归神经网络和关注机制联合哈希方法提高了检索速度;如跨模态混合迁移网络(cross-modal hybrid transfer network,CHTN)[11]将从单模态数据中学习到的知识在跨模态数据之间共享,以提升跨模态检索的精度;全模态自编码器和生成对抗机制的跨模态检索方法[12],引入2个并行自编码器并设计3个判别器提升了跨模态识别平均精度.
随着深度学习方法在机器学习领域的广泛应用,研究人员提出来一系列的基于深度神经网络的信息检索方法.例如Roy[13]提出了一个基于动态形状编码网络的单词发现框架,该方法适用于检索自然场景中图像和视频帧中文本,并不能直接应用到基于语音关键词的检索中;Zhang[14]提出了一种采用交互式学习卷积的跨模态语音-文本检索方法,但不能较好满足实时性需求;Pal[15]利用神经网络学习散列函数,获得端到端深度语义保持序数散列框架,但该方法并未获取跨模态语义的在公共空间上的映射表达;孪生卷积神网络模型[16]与三分支孪生网络[17]等通过构建模型将关键信息进向量表示并分类得到结果.
基于深度神经网络的相关技术已经取得很大进展,但现有的方法有些是针对单模态检索任务的,有些适用于特定的图文检索等场景,有些并不能满足语音检索任务的实时性需求.
针对现有方法的缺点,以及满足现实语音检索任务中的精度和实时性需求,同时受模式识别任务启发,本文将语音关键词检索任务视为模式识别中的分类问题.在训练阶段,本文构建了语义一致性编码网络,提取语音特征和文本特征在公共空间上生成统一的语义特征表达,在测试阶段,通过语义一致性编码网络训编码模型获得检索项统一语义向量,通过余弦距离直接度量向量相似度.经实验验证,该方法与多个基线方法对比,在检索精确上更优,且时效性也能够得到保证.
1 语义一致性编码网络模型
利用深度神经网络提取语音和文本的特征,将两者映射到一个公共的表示空间,以此来建立语音和文本之间统一的语义表达,从而完成语音关键词检索任务.
1.1 模型概览
语音关键词检索模型整体框架如图1所示.受模式识别领域中的分类任务启发,将跨模态的语音关键词检索任务,分为线下训练和线上预测(检索)两个阶段.训练阶段,检索模型设计了一个双重损失函数(一致性损失和分类损失)来训练网络参数,进而优化调整语义一致性网络模型.利用分类损失训练好的语义一致性编码网络会将检索库中的数据集q1,q2,…qn,转化为语义特征向量{s1,s2,…sn},预测阶段有新的检索项q0同样通过编码得到s0,通过语义特征向量之间的距离度量获得最佳检索结果.

图1 采用语义一致性编码网络的语音关键词检索模型Fig.1 Speech keyword retrieval model using semantic consistency coding network
1.2 语义一致性编码网络
在编码网络设计上采用深度全卷积神经网络联合双重损失函数方法,通过堆叠多个卷积层对表示语音和文本信号进行建模,更好地提取语义一致性特征,编码网络模型如图2所示.借鉴图像识别任务中效果较好的网络配置,每个卷积层使用3×3的卷积核,在多个卷积层之后加上池化层,大大增强网络模型的表达能力,首先需要提取输入样本的不同模态语音和文本信息特征.
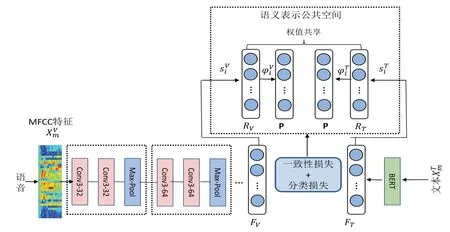
图2 编码网络模型图Fig.2 Coding network model diagram
(1)语音特征提取
语音属于连续的一维信号,为了对连续语音进行量化,需要对语音信号进行前段处理,包括预加重、分帧和加窗操作.
预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱.同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰.预加重处理就是将语音信号通过一个高通滤波器:

式(1)中预加重系数u的取值范围在0.9~1.0之间,根据实际需要,本文取0.945.
语音信号在产生的过程中受到发声器官状态变化的影响,而状态变化速度较声音振动的速度要慢得多,因此可以认为是短时平稳的,进行分帧后对每一帧信号进行处理就相当于对特征固定的持续信号进行处理,可以减少非稳态时变的影响.为捕获连续完整语音信号,相邻帧之间会有重叠,相邻帧之间的重叠部分被称为帧移,一般帧移长度为帧长度的一半左右,每帧长度在15 ms~20 ms之间.
分帧后每一帧的起始段和末尾段会出现不连续的地方,从而导致与原始信号的误差越来越大.而加窗则可以使分帧后的信号变得相对连续,本文选择使用汉明窗.
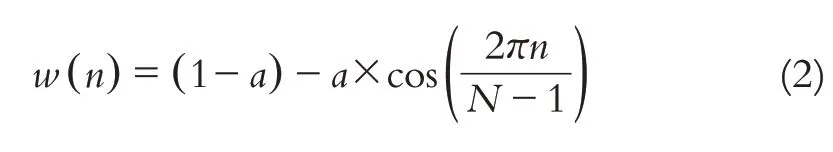
其中N表示帧的大小,n=0,1,…N-1,按照一般设置a取0.46.
本文使用梅尔频率倒谱系数提取语音特征,梅尔频率与线性频率之间的函数关系是非线性的,其函数关系如下:

提取梅尔倒频谱系数的主要步骤如下:输入的语音信号通过傅里叶变换转化为傅里叶变换的频域信号;进行滤波操作,根据梅尔音阶从低到高设置带通滤波器;根据不同的频率,从低到高设置梅尔刻度;对带通滤波器处理过的信号作进一步处理,如对数运算;进行离散余弦变换,这些经过处理的信号特征可以被视为语音信号的最终特征参数.基于MFCC提取的语音特征[18],在应用于语音检索系统时,将获得良好的识别检索效果.
(2)文本特征提取
针对文本信息,本文采用维基百科中文数据集上预先训练的(bidirectional encoder representation from transformers,BERT)[19],将模型输出中[CLS]标志位对应的一个768维向量作为文本的特征表示.
(3)网络架构
所提网络模型具体结构如图2所示.在网络参数设置上,采用了10层卷积核5层池化,卷积核参照图像识别领域常用的3×3的小卷积.
不同层的卷积核个数分别设置为为32、64、128、128、128,在两次卷积之后采用最大池化操作,前三层池化的池化核为2,后两层池化的池化核为1.
假设数据集包含N对语音-文本对,用D={(XVm,XTm,ym)}Nm=1表示,其中XVm表示第m类语音关键词,XTm第m类本文信息,ym是第m个样本的类别标签.语义编码的目标是学习两个映射函数FV和FT提取高层次语音语义特征{sVi}Ni=1和文本语义特征{sTi}Ni=1.此后,在公共空间学习两个映射函数RV和RT以获得语义一致的语音表示{φVi}Ni=1和文本表示{φTi}Ni=1,获得的一致性向量表达,最后参数矩阵为P的现行分类器分别连接至两个子网络末端,可以直接用于跨模态的语音关键词检索.
如网络模型图2所示,在语音和文本两个子网络后分别得到语音语义编码:
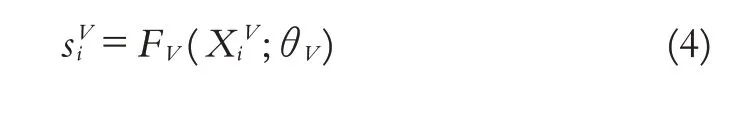
其中,i=1,2,…N,sVi∈Rd1代表提取的第i个高层级语音语义特征,d1表示语音向量维数,θV表示可训练的参数.
文本语义编码:

其中,i=1,2,…N,sTi∈Rd2代表提取的第i个高层级本文语义特征,d2表示文本向量维数,θT表示可训练的参数.
为获得语义一致性表达,需要将sVi和sTi映射到公共子空间,形成公共空间的特征向量.第i个语音特征向量表示为:

其中,φVi∈Rd,表示第i个语音样本在公共空间特征向量,RV表示语音语义特征在公共空间的映射函数.第i个文本语义特征在公共空间表示为:

其中,φTi∈Rd,RT表示文本语义特征在公共空间的映射函数,d表示公共空间特征向量的维数,ΘV和ΘT分别表示可训练的参数.
1.3 损失函数
本文提出的跨模语音关键词检索为来自不同模态的特征在公共空间映射得到统一的向量表达,使得语义类别相同的样本特征向量相似,语义类别不同特征向量不相似.为此,本文设计了一种联合双重损失函数Lcc:由语义一致性损失Lconsis和分类损失Lclass组成.
在公共空间获得语义一致性向量表达,可以直接度量向量之间的相似性,余弦距离常用于跨模态检索,余弦距离为:

其中,x,y分别表示具有相同维度的向量,在此基础上定义成对的语音文本样本一致性损失为:

单模态一致性用来度量同一模态内的两个不同向量之间的关系,因此定义单模态一致性损失为:

其中,h(x)=max(0,x),ξ是预定义的阈值,将检索任务视为分类任务,lij为分类标签预测,假如φVi,φVj或φTi,φTj表示相同的语义,lij=+1;否则lij=-1,且i≠j.模态内一致性定义,将会使同模态内的相同语义聚集,不同语义向量远离.
对于跨模态语音检索任务,定义跨模态语义向量之间一致性损失计算方法为:

式中ζ是预定义的阈值,假如φVi,φTj或φTi,φVj表示相同的语义,lij=+1;否则lij=-1,且i≠j.
以上定义的成对一致性损失、单模态一致性损失和跨模态一致性损失,联合这三类一致性损失构成本文的语义一致性损失函数:

其中η1是控制单模态和跨模态损失的权重系数.
本文方法将检索任务视为分类任务,在训练过程中分别在语音和文本子网络后增加一个分类过程,分别设置了softmax层:

其中,pVi是属于第i个语音样本的概率,pTi是属于第i个文本样本的概率,WI、WT和bI、bT是softmax层训练参数.将分类损失Lclass表示为:

其中,yit表示第i个样本,t表示第t个类别,pVit表示第i个语音的预测概率,pTit表示第i个文本的预测概率,ε表正则化常数,防止出现NaN值.通过最小化分类损失函数,在公共空间中统一表示的特征向量的语义辨别能力可以得到极大地提高.
综合以上公式,得到本文设计的双重损失函数Lcc:
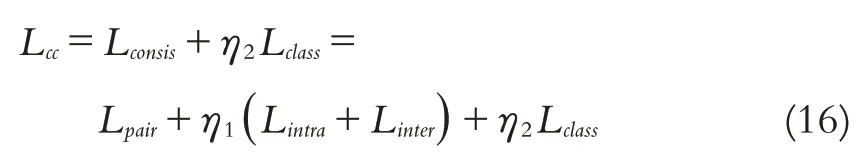
其中η2是分类损失权重系数.
语义一致性编码网络训练流程如算法1所示:


2 实验验证
2.1 实验数据集评价指标
语音关键词检测本文采用Kaldi工具包,Kaldi是当前最流行的开源的语音识别工具包,它的开发团队在github上进行维护.与其他开源语音识别工具相比,Kaldi支持任何长度的声学建模语言.
本文实验数据集采用清华大学的THCHS-30和北京希尔贝壳科技有限公司开源的AISHELL语音数据集,建立语音-文本对,每个样本对共用一个类别标签,相对文本检索的成熟应用背景,本文主要关注语音->文本场景的跨模态检索.THCHS-30是一个开源中文语音数据库,总时长超过30个小时,训练、测试及验证集比例为7∶2∶1;AISHELL语音数据集由来自不同口音不同地区的400人参加录音,共178小时,训练、测试及验证集比例为32∶2∶1.
本文通过计算语音特征和文本特征的余弦向量来度量两者之间的相似性,采用语音关键词检索系统广泛使用的评估标准:召回率(Recall@N)和平均精度均值(mean Average Precision,mAP)对检索算法进行评价.Recall@N表示输入语音关键词得到的跨模态检索结果中,前N个文本中出现与语音信息类别相同的概率,mAP综合考虑所有的检索结果,对每个测试样本的平均精度进行了再平均,反映了检索模型的整体性能.上述两种评估标准的值越大,说明模型的检索性能越强.
2.2 训练与参数设置
实验在Windows 7(8 GB内存,64位,Intel CPU 3.60 GHz)系统上运行,主要采用Python编程语言,版本为Python 3.8.6.在语音特征提取阶段,采用帧长16 ms、帧移5 ms及加窗(汉明窗),SCCN模型输入特征为600×39维的二阶差分MFCC特征参数;在提取阶段采用BERT模型中的[CLS]标志位对应的d2=768位向量作为文本特征;在构建语义一致性编码网络时使用Tensorflow框架,选取适应性动量估计算法(Adaptive moment estimation,Adam)作为训练优化器,该算法不仅能够对不同参数计算适应性学习率,而且能够加速网络收敛速度,学习率为1×10-4,epoch=300,batch_size=100.
损失函数超参η1和η2分别设置为1和0.1.
2.3 实验结果与分析
(1)损失函数超参分析
超参数η1控制了单模态和跨模态之间一致性的贡献,η2控制了对语义分类建模的贡献,为了研究它们对编码网络性能的影响,在THCHS-30数据集上对这两个参数进行了参数实验.实验参数调节参考了网格搜索方法[20],η1的范围设置为{0,0.2,0.4,0.8,1.0,1.2,1.4,1.6,1.8,2.0},η2的 范 围 设 置 为{0,0.0001,0.001,0.01,0.1,1,10}.
η1调参方法为:根据经验将η2的值固定为1,η1从0到2,每步递增0.2.关于参数η1的对应的mAP结果如图3所示,可以看出η1=0时,所提出的方法的检索性能会明显降低,因为忽略了单模态和跨模态之间的一致性损失,导致两个模态间的同一语义不能被正确匹配,η1=1时,mAP结果最佳.

图3 η1参数调整结果Fig.3η1 parameter adjustment results
η2调参方法为:将η1的值固定为1,η2从0到10,每步递增10倍.关于参数η2的对应的mAP结果如图4所示,可以看出η2=0时,检索性能不佳,这表明分类损失有助于提高语义鉴别能力,当η2=0.1时,获得了最佳的性能.
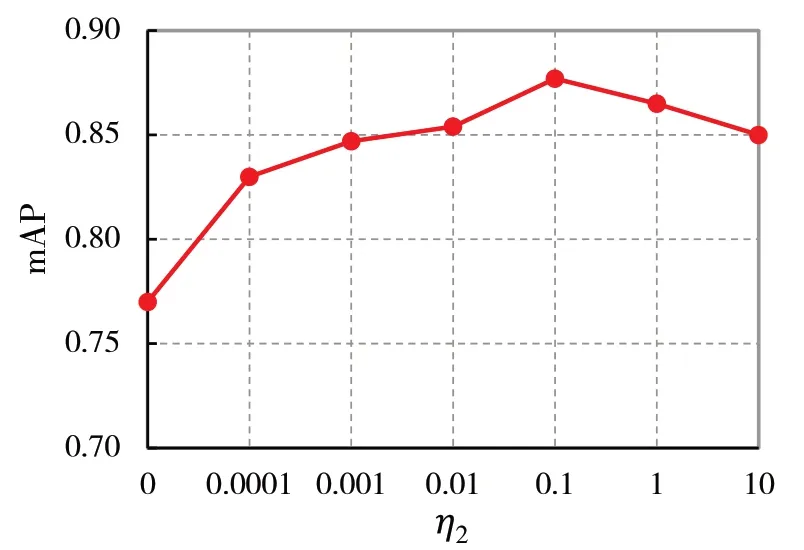
图4 η2参数调整结果Fig.4η2 parameter adjustment results
(2)与基线方法进行精度对比实验
本文选取经典的的检索算法BM25、向量空间模型(Vector Space Model,VSM)以及CNN-LSTM模型进行对比.比较的CNN-LSTM模型输600×39维MFCC特征参数,模型结构由三层卷积、三层池化、一层全连接层组成,卷积核为3×3,池化层选择1×3,只对频率维度进行池化.第一层隐藏层节点256个,第二层512个,全连接层节点2 667个,batch_size=100,学习率设置为1×10-4.
在AISHELL数据集上不同方法的实验结果如表1所示,表中第5-9行展示了本文语义编码网络基于不同类型损失函数的实验结果,SCCN-Lcc即为本文所提联合语义一致性损失和分类损失的双重损失函数方法.
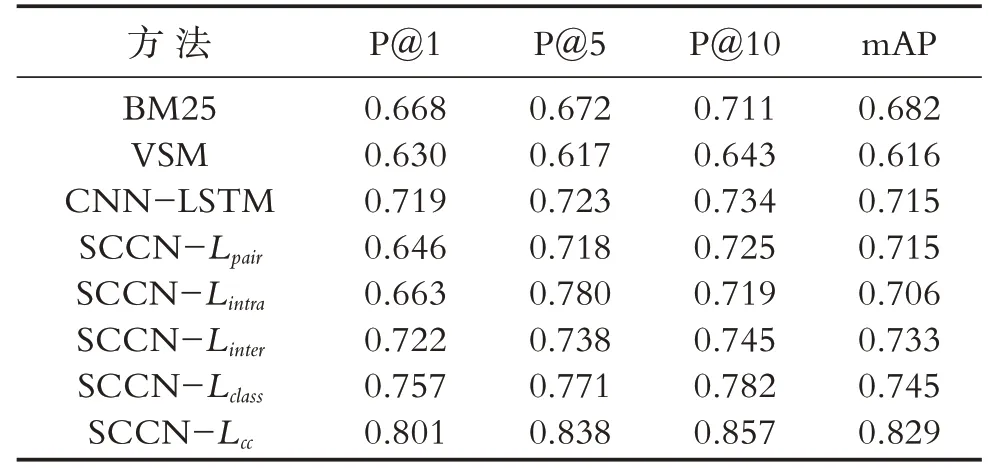
表1 AISHELL数据集实验结果Table 1 Experimental results of AISHELL dataset
从实验结果看出相对经典的基线方法,文本方法(SCNN-Lcc)在mAP和P@i指标上系性能都优于比较方法,相对于次优方法在P@1、P@5、P@10、mAP上性能分别提升4.4%、6.7%、7.5%和7.4%,证明本文方法在检索性能上优于其他方法.同时对比传统的检索方法,可以看出基于深度学习的方法要优于传统基于特征统计的方法.本文所提的SCNNLcc方法基于深度全卷积网络,能够提取语音和文本高层次语义特征,同时利用深度学习方法学习到的公共子空间语义特征表达具有更好的鉴别能力,可以为跨模态数据建立更强的语义关联,实现更好的检索性能.验证阶段分别联合五种不同损失函数的SCCN方法实验:SCCN-Lpair仅计算成对样本语音-文本损失,SCCN-Lintra仅计算单模态内损失,SCCN-Linter计算跨模态数据间的损失,SCNN-Lclass仅计算跨模态检索损失,SCNN-Lcc(本文提出的基于双重损失函数)联合了语义一致性损失和检索损失.表1的第5-9行分别展示了不同类别损失函数的性能表现,使用SCCN-Lclass方法的mAP要高于其他的仅依赖单一损失的方法,这说明分类损失较好均衡了语音与文本之间跨模态检索的语义差异,提高了模型检索性能.但是通过比较单一损失函数与本文的SCNN-Lcc方法可以看出,单独一种损失函数在数据集上的表现都低于共同训练结果,证明只有同时考虑联合多种损失函数的方法才能具有更好的跨模态检索性能.
在THCHS-30数据集上不同方法的实验结果如表2所示.从对比实验看出本文方法同样取得最优结果,证明了本文方法的有效性,对比表1和表2看出本文方法在THCHS-30数据集上的效果要优于AISHELL数据集,这是因为THCHS-30都是由标准普通话发音组成,而AISHELL数据集包含了不同口音的说话者.
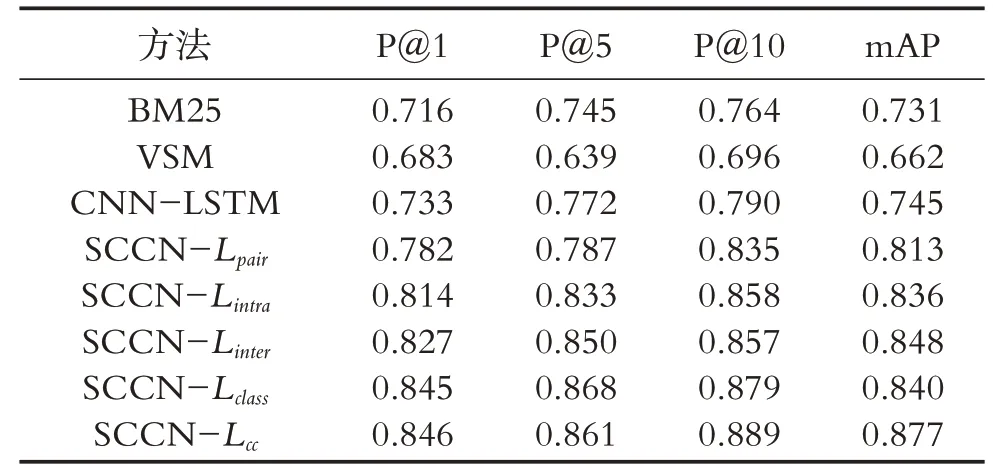
表2 THCHS-30数据集实验结果Table 2 Experimental results of THCHS-30 dataset
(3)与不同模型进行复杂度比较
本节对比SCCN方法的复杂度,检索结果基于余弦距离是线性计算,主要计算在预测阶段的语义特征学习,因此时效性分析基于模型复杂度分析.如表3所示,对于注意力机制、RNN、还有信息检索领域前沿的BiMPM[21]模型进行对比.

表3 模型复杂度分析Table 3 Model complexity analysis
从模型复杂度对比可以看出,本文方法在测试使用前,可以使用训练好的语义编码网络对数据进行预处理,将大量数据转换成公共空间的语义向量存储.在测试时,SCCN方法只要利用语义编码模型对检索语音关键词进行语义向量转化,再将其与事先存储的语义向量进行常数项时间复杂度的向量距离计算与排序就能得到结果.整个过程时效性大大优于基于二元检索项匹配的深度神经网络方法,既利用了深度学习方法学习了一致性语义编码特征,在检索阶段只要进行线性匹配即可得到结果,又能满足时效性需求.
3 结论
本文提出采用语义一致性编码网络(SCCN)的语音关键词检索方法,利用深度神经网络学习跨模态的语音和文本信息表示为公共空间的向量表达,将检索问题转换为分类任务,通过联合双重损失函数训练语义一致性网络模型,在检索(测试)阶段只使用训练好的语义编码网络对语音关键词进行语义空间上的距离衡量即可得到检索结果.实验证明,本文方法既利用了深层语义信息,又兼顾了实际检索应用中的时效问题,具有更好的精确和更高的时效性.
未来将结合相关前沿深度学习网络模型,针对语义编码网络模型进一步研究分析,并且探究更优的损失函数,进而提升方法性能.
