基于NGSIM数据库的驾驶风格聚类研究
2023-01-06宋函锟
宋函锟
基于NGSIM数据库的驾驶风格聚类研究
宋函锟
(长安大学 汽车学院,陕西 西安 710064)
驾驶风格用于表征驾驶人的行为特性,对发展自动驾驶技术、制定个性化的驾驶策略具有重要价值。文章基于美国NGSIM数据库中的车辆行驶状态数据,选取横向速度绝对值均值、横向速度绝对值标准差、纵向速度绝对值的标准差等九个统计量作为特征变量,利用主成分分析降维算法及K-means聚类算法对行驶数据进行驾驶风格分类研究。将驾驶风格分为保守型、一般型及激进型三个类别,数据分析表明,保守型驾驶人的横向速度均值、纵向加速度均值、横纵向冲击度均值等统计量均为三种类型中的最小值,而激进型驾驶人的对应统计量为三者中的最大值,一般型驾驶人居中,验证了本次聚类结果的合理性。
数据处理;特征选择;驾驶风格聚类;NGSIM数据库
驾驶风格用来表征驾驶人在车辆运行过程中对车辆的操作行为特征。不同驾驶风格的驾驶人在相同的道路环境下具有不同的行为特性,通过对驾驶人驾驶风格的分析,有助于分析驾驶人的行为,进一步开发自动驾驶技术。目前国内外针对驾驶员风格分析的方法主要有[1]基于问卷调查的驾驶员风格分析方法和基于驾驶行为特征的驾驶员风格分析方法。基于问卷调查的方法具有一定的主观性,可能对驾驶风格的识别分析产生较大影响;基于驾驶行为特征的方法通常采用数据分析技术和机器学习算法,且数据采集来源于真实交通场景,对驾驶风格的识别研究具有较高的可靠性。
本文提出了一种基于车辆状态数据的驾驶风格分类及识别方法,通过对NGSIM(Next Genera- tion Simulation)数据集中车辆行驶数据的分析,实现了不同驾驶人驾驶风格的分类与识别,对自动驾驶技术的研究具有一定的参考价值。
1 数据介绍
本文选用的驾驶数据来源为美国联邦公路管理局发布的NGSIM交通流数据集,其中包括US101,I-80,Lankershim Boulevard和Peachtree Street四条路段的车辆行驶数据,本文选取I-80路段部分车辆数据进行驾驶风格的分类研究。
相机以0.1 s的时间间隔记录行驶的车辆信息,主要数据信息如表1所示。

表1 NGSIM主要数据信息
2 构建特征变量及主成分分析
驾驶风格的聚类研究首先要对数据进行处理,并选择特征变量,特征变量的选择通常是与车辆状态信息及驾驶人操作信息相关的统计量参数[2],并且为降低变量间的相关性,需要对特征变量进行降维处理,最后得到用于聚类的特征矩阵。
2.1 数据选择及处理
车辆的运动控制通常包括横向与纵向控制,且二者均能在一定程度上体现驾驶人的驾驶特性,因此本文选择在行驶过程中进行过换道行为的车辆作为研究对象,将其数据作为聚类的初始数据。
在原始数据采集过程中会不可避免地出现数据噪声、数据缺失及异常等现象,影响数据的真实性。因此,需要对数据进行预处理,减少异常数据的干扰。本文首先采用Savitzky-Golay平滑方法对数据进行降噪处理,平滑窗口为21,平滑前后某车辆的横向轨迹对比如图1所示。
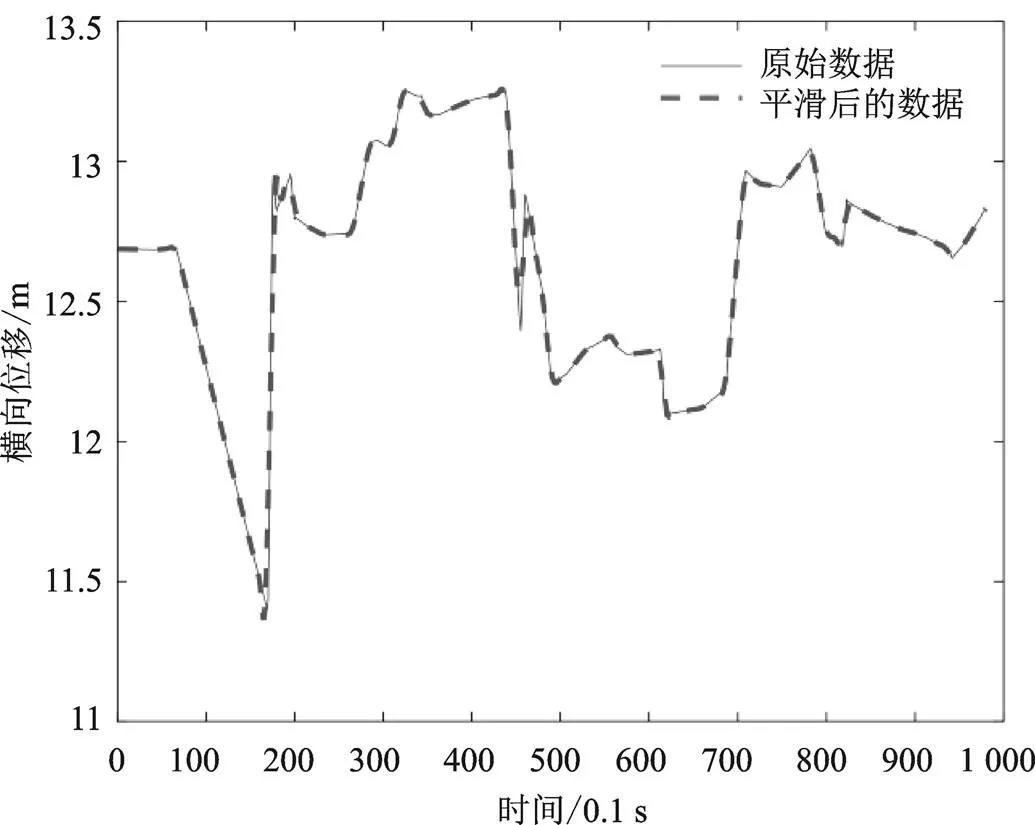
图1 原始数据与平滑后数据对比
由于对原始轨迹数据处理后,车辆的轨迹数据与当前速度、加速度数据不一致,为保证数据精度,对处理后的轨迹进行重新求导,如式(1)、式(2)所示。
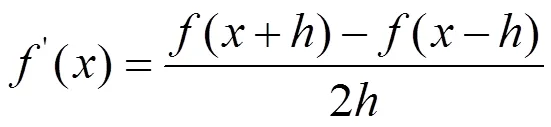
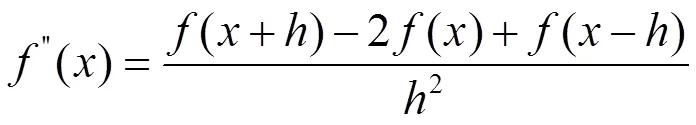
式中,为时间步长,单位为0.1 s,()为车辆的轨迹数据。求导法得到新的横向、纵向速度及加速度如图2—图5所示。
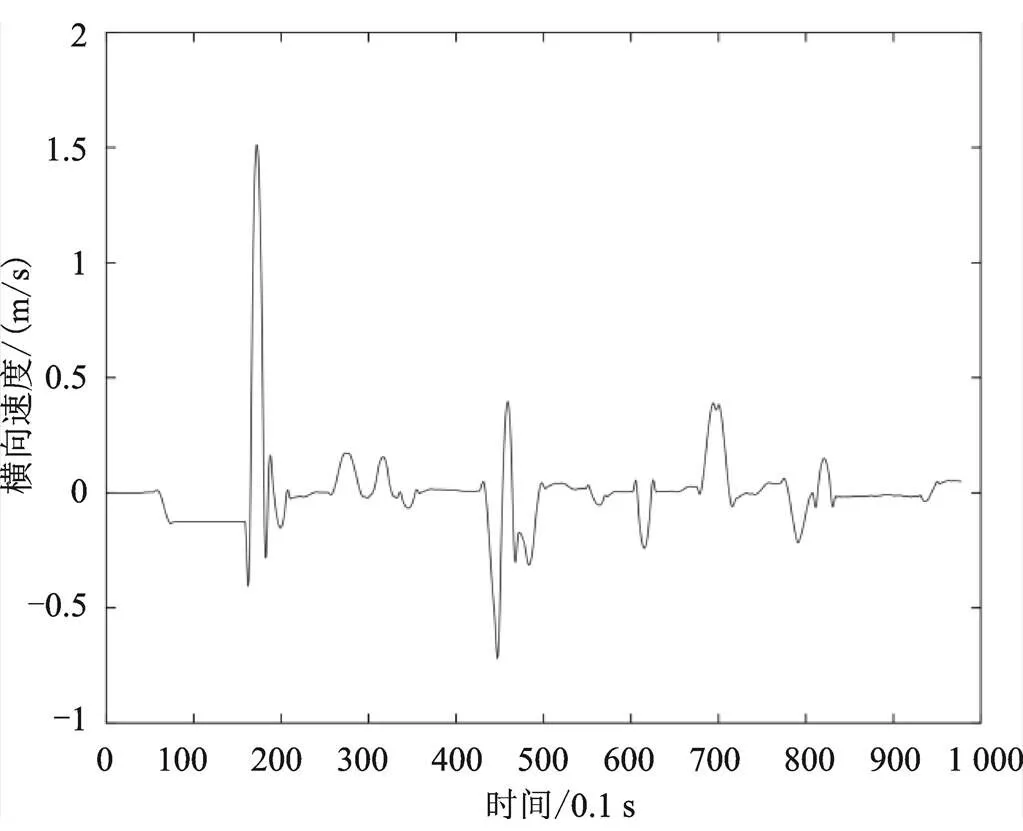
图2 求导计算后的车辆横向速度
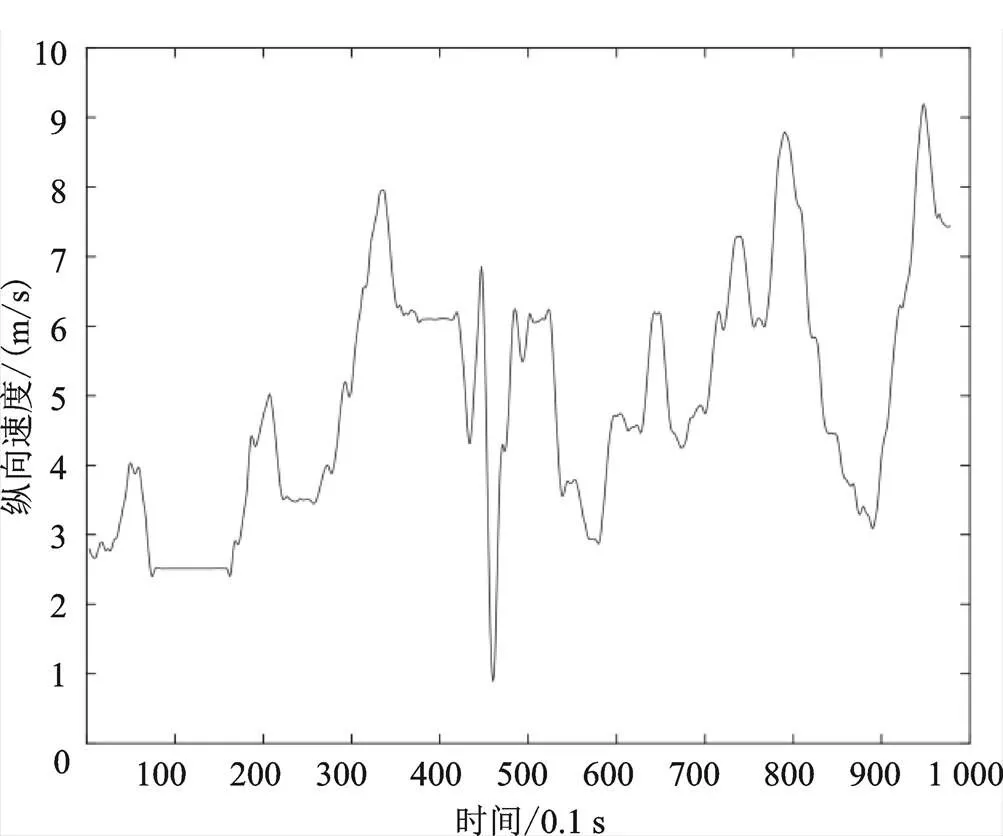
图3 求导计算后的车辆纵向速度
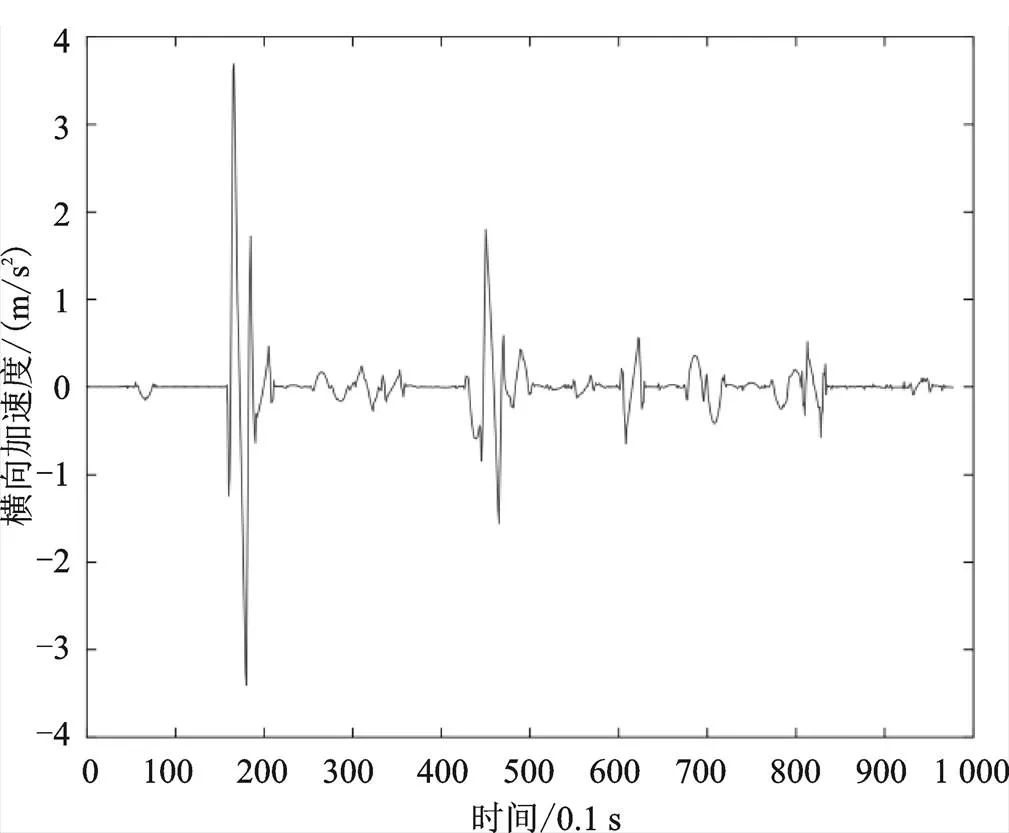
图4 求导计算后的车辆横向加速度
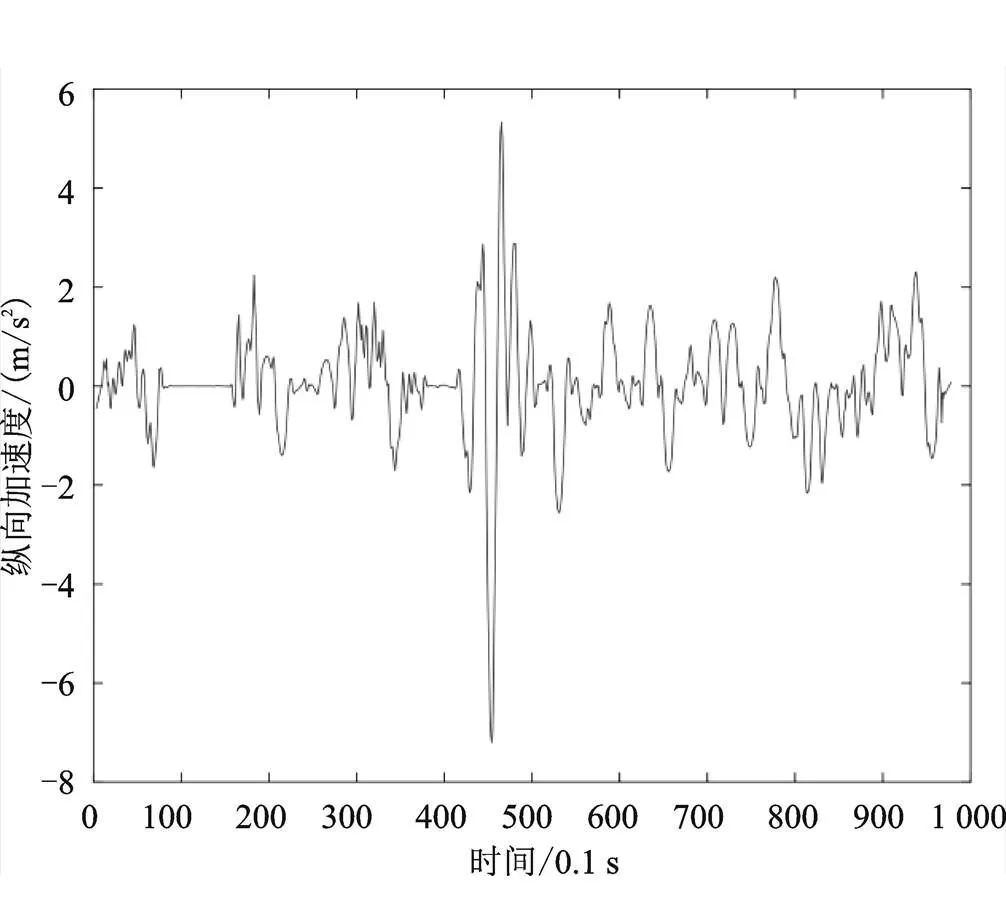
图5 求导计算后的车辆纵向加速度
从图中可以看出,对速度加速度重新求导后,其曲线变得较为平滑,但仍存在较多异常值,因此,还需进一步检测异常值并进行修正。本文参考相关文献[3],将纵向加速度范围限定在[−8 m/s, 8 m/s],将横向加速度范围限定在[−2 m/s2, 2 m/s2],即超出以上范围的数据点均视为异常点,删除后在原位置采用三次样条插值对其进行修正处理,得到新的速度数据后,求导得到横、纵向加速度数据。进行异常值处理后的横、纵向速度及加速度与处理前的数据对比如图6—图9所示。
从图中可以看出,处理后的数据异常点明显减少,并且变得更加平滑,可用于最终特征矩阵的构建。
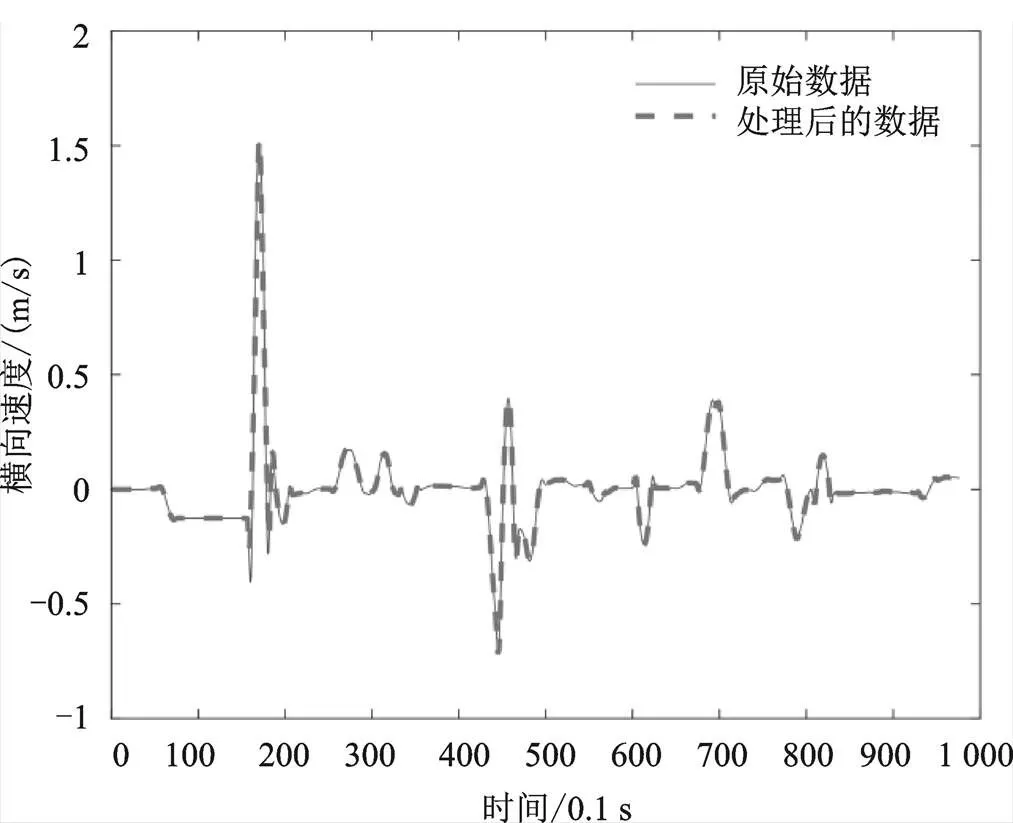
图6 处理前后的横向速度对比
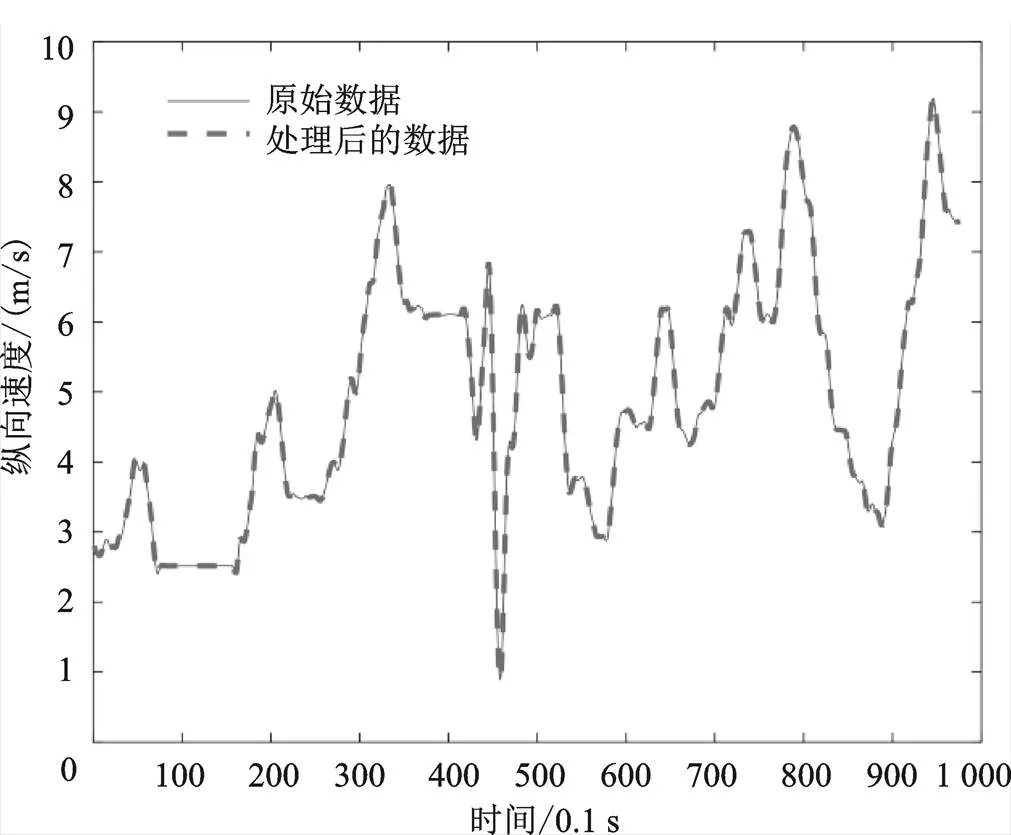
图7 处理前后的纵向速度对比
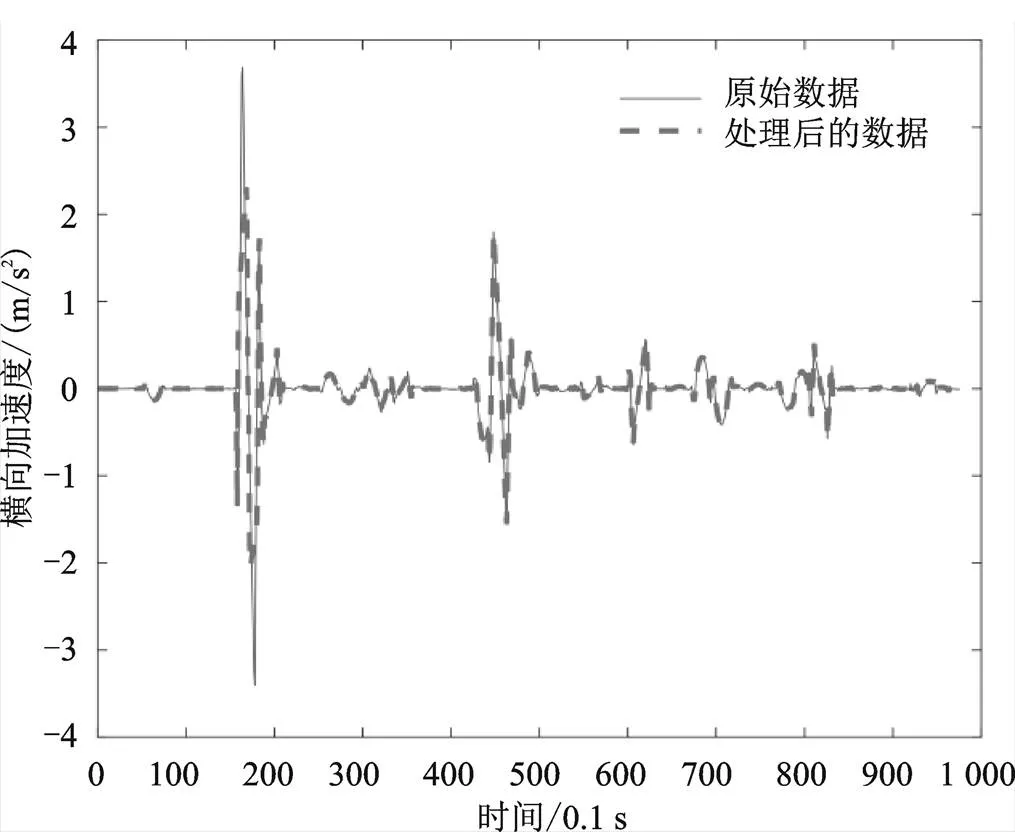
图8 处理前后的横向加速度对比

图9 处理前后的纵向加速度对比
2.2 选择特征变量
在进行驾驶风格识别前,需要选择驾驶风格特征变量,用于描述不同的驾驶风格。由于在车辆行驶过程中,速度、加速度、冲击度、跟车距离等状态参数通常是反映驾驶人操作激进程度的重要变量,可以通过这些状态参数的相关统计量表征不同驾驶人的驾驶风格,得到特征矩阵,特征变量的选择如表2所示。
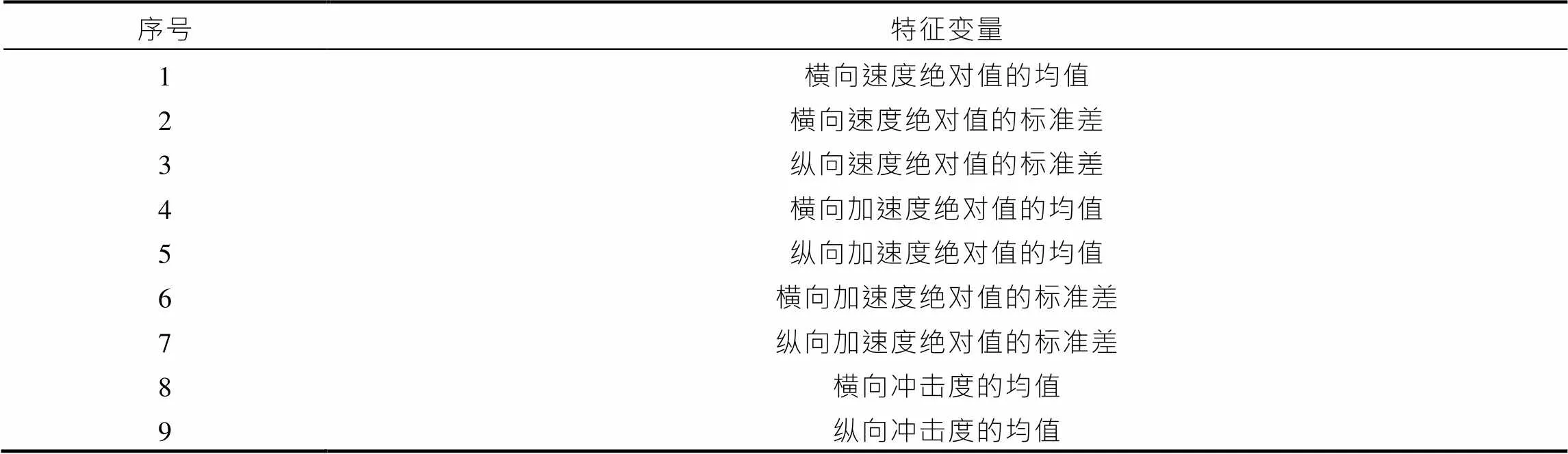
表2 聚类特征变量
其中冲击度为加速度的导数[4],冲击度的计算如式(3)所示。
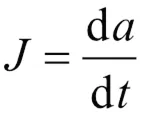
式中,为车辆的冲击度,为车辆的加速度。
2.3 主成分分析
由于选取的特征变量数目较多且彼此间存在一定的相关性,为降低数据的冗余,提高聚类效果,需要使用主成分分析方法对其进行降维处理[5]。主成分分析法是一种统计分析、简化数据的方法,它利用正交变换来对一系列可能相关的变量值进行线性变换,从而投影为一系列线性不相关变量的值,这些不相关变量称为主成分。主成分分析的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的信息量最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。由于其计算简单,并且是一种以方差衡量信息的无监督学习方法,其使用不受样本标签的限制,因此,被广泛应用。
在进行主成分分析前,考虑到各变量的量纲和数值范围不同,直接用于聚类对结果的影响较大,因此,需要进行数据归一化处理,归一化公式为
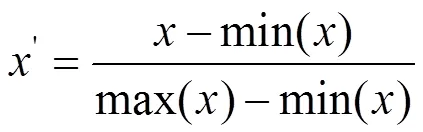
式中,为数据样本,min()为样本中的最小值,max()为样本中的最大值。
归一化完成后,对特征变量进行主成分分析并计算各主成分的贡献度,选择累积贡献度之和超过85%的前三个主成分,如表3所示,与原特征矩阵相乘后得到最终用于聚类的矩阵。

表3 主成分分析结果
3 驾驶风格聚类
得到最终用于聚类的矩阵后,可通过聚类算法进行聚类分析。聚类算法属于无监督算法,其特点在于原始数据没有标签,需要经过聚类分析为数据贴上标签,常用的聚类算法有K-means、层次聚类、谱聚类以及高斯混合模型等,其中K-means算法较为经典且应用广泛[6],本文采用K-means算法进行驾驶风格的聚类分析。
3.1 K-means算法
K-means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇,让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大,每个簇内所有样本的均值即为聚类中心,也称为“质心”,该算法通过计算各样本点与“质心”间的距离进行归类,具有聚类效果较优、可解释度较强、收敛速度快等优点,其原理如图10所示。
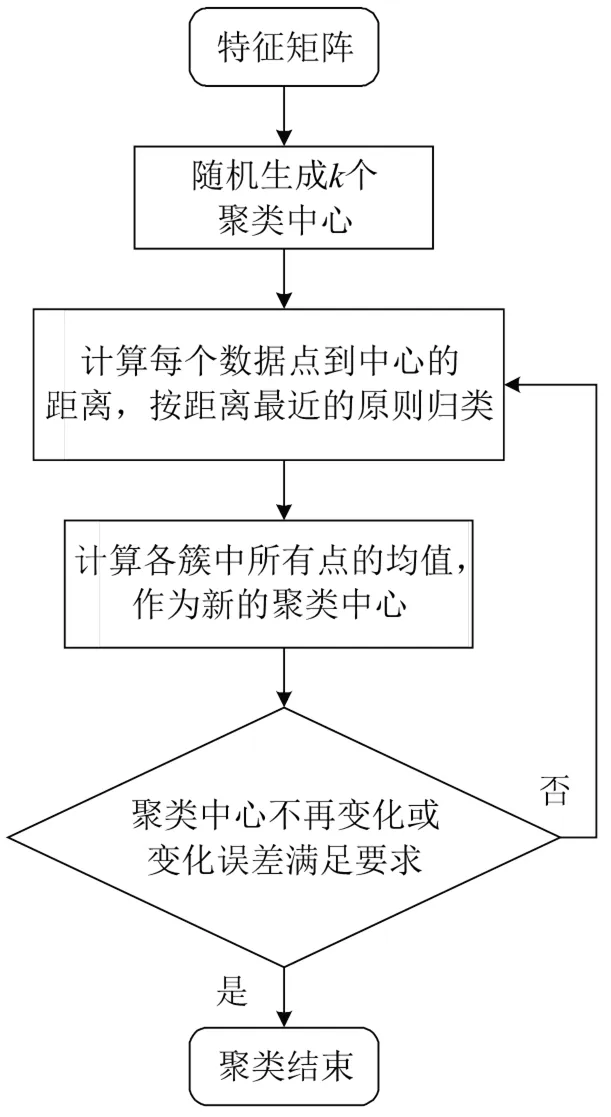
图10 K-means算法原理
3.2 驾驶风格聚类
通过主成分分析降维处理后,选择前三个主成分系数,与原矩阵相乘得到用于聚类的特征矩阵。采用K-means聚类时,首先定义本次聚类中心个数为3,随机生成三个聚类中心后,按照样本与中心间的距离划分类别,并更新聚类中心,反复迭代后当聚类中心不再变化或误差平方和最小时,聚类完成。本次驾驶风格聚类结果如图11所示。
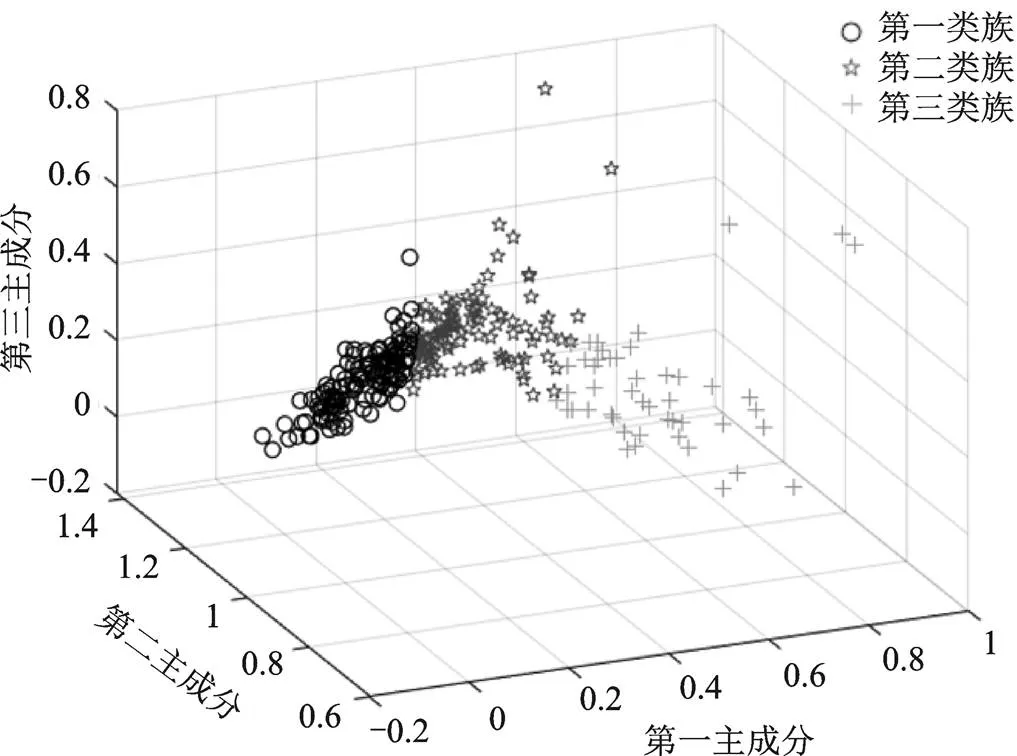
图11 驾驶风格聚类结果
3.3 聚类结果分析
以上分析中将驾驶风格聚类结果分为了3类,但还没有将其定义为不同驾驶人具有的特定风格。查阅相关文献[7],对驾驶风格的研究通常按照驾驶员驾驶车辆激进程度从弱到强将驾驶风格类型分为保守型、一般型和激进型3种,不同驾驶风格类型车辆对应的特征参数如表4所示。
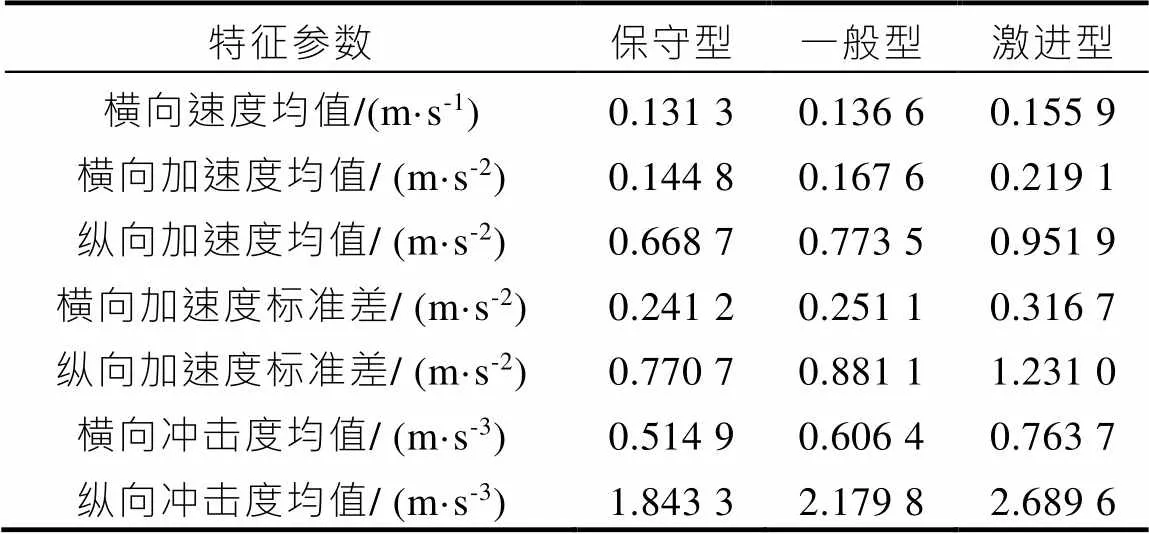
表4 不同驾驶风格类型对应的特征参数
由表4可知,保守型驾驶人的横向速度均值、纵向加速度均值、横纵向冲击度均值等统计量均为三种类型中的最小值,而激进型驾驶人的对应统计量为三者中的最大值,一般型驾驶人居中,表明本次聚类结果较为合理,符合实际情况。
4 结论
本文通过对NGSIM数据库中的数据提取与处理,选择了包括横向速度绝对值均值、横向速度绝对值标准差等特征变量,利用主成分分析及K-means聚类算法将驾驶风格分为保守型、一般型及激进型,并验证了聚类结果的合理性,实现了对不同驾驶人驾驶风格的分析与研究,对制定个性化的驾驶策略具有一定的指导作用,有利于自动驾驶技术的进一步发展。
[1] 王科银,杨亚会,王思山,等.驾驶风格聚类与识别研究[J].湖北汽车工业学院学报,2021,35(3):1-6,10.
[2] 金辉,李昊天.基于驾驶风格的前撞预警系统报警策 略[J].汽车工程,2021,43(3):405-413.
[3] 李晓阳,刘树伟.驾驶风格研究综述[J].时代汽车, 2020(15):189-190.
[4] 张一恒.基于驾驶风格辨识和运动预测的换道风险评估及决策方法[D].西安:西安理工大学,2020.
[5] 王庆昕.考虑驾驶员特性的车辆行驶风险度评估方法[D].长春:吉林大学,2020.
[6] 李经纬,赵治国,沈沛鸿,等.驾驶风格K-means聚类与识别方法研究[J].汽车技术,2018(12):8-12.
[7] 詹森.基于工况与驾驶风格识别的混合动力汽车能量管理策略研究[D].重庆:重庆大学,2016.
Research on Driving Style Clustering Based on NGSIM Database
SONG Hankun
( School of Automobile, Chang’an University, Xi’an 710064, China )
Driving style is used to represent the behavior characteristics of drivers. It is of great value to develop automatic driving technology and formulate personalized driving strategies. Based on the vehicle driving state data in the American NGSIM database, this paper selects nine statistics such as the mean of the absolute value of transverse speed, the standard deviation of the absolute value of transverse speed and the standard deviation of the absolute value of longitudinal speed as the characteristic variables, and uses the dimension reduction algorithm of principal component analysis and K-means clustering algorithm to classify the driving style of the driving data, and divides the driving styles into conservative, general, radical three types.The data analysis shows that the statistics of the mean transverse speed, the mean longitudinal acceleration and the mean transverse and longitudinal impact of the conservative driver are the minimum of the three types, while the corresponding statistics of the radical driver is the maximum of the three, and the general driver is in the middle, which verifies the rationality of this clustering result.
Data processing;Feature selection;Driving style clustering;NGSIM database
U495
A
1671-7988(2022)24-40-06
U495
A
1671-7988(2022)24-40-06
10.16638/j.cnki.1671-7988.2022.024.007
宋函锟(1997—),男,硕士研究生,研究方向为车辆动力学控制,E-mail:shk19971231@163.com。
