基于WPD-AHA-ELM 模型的水质时间序列多步预测
2023-01-05崔东文袁树堂
崔东文 袁树堂
(1.云南省文山州水务局,云南 文山 663000;2.云南省水文水资源局昆明分局,昆明 650000)
水质时间序列预测是依据已有的历史监测数据,通过科学的方法推测将来的水质变化趋势,以期达到掌握水质现状及发展趋势的目的.提高水质时间序列预测精度,对于水环境治理、水资源保护和水生态修复具有重要意义.由于水质时间序列影响因素众多,并最终体现在随时间变化的水质监测数据中,因此可采用时间预测模型挖掘水质时序数据的潜在规律,进一步预测其发展趋势.当前,基于“分解-预测-重构”思想的多种方法组合预测模型被尝试用于水质时间序列预报,取得较好的预报效果.孙铭等[1]基于db5小波分解方法和长短期记忆网络(LSTM)建立组合水质预测模型,将其应用于安徽阜南王家坝流域pH值、DO、CODmn、NH3-N 预测;金昌盛等[2]基于奇异谱分析(SSA)、遗传算法(GA)和BP神经网络建立组合水质预测模型,将该模型应用于湘江新港断面水质预测;顾乾晖等[3]基于变分模态分解(VMD)、粒子群优化(PSO)算法和长短时记忆神经网络(LSTM)构建VMD-PSO-LSTM 河流水质预测方法,并将其应用于河南南阳当地高锰酸盐含量预测;李建文等[4]融合集合经验模态分解(EEMD)方法、支持向量回归机(SVR)模型,提出EEMD-SVR 组合预测模型对天津某渔业养殖池塘内溶解氧和pH 值进行预测.然而,在实际应用中,水质单步预测往往无法满足实际需求,需要根据历史数据实现更多尺度的超前多步预测,实现未来更为长远的水质时间点预测,多步预测的重要性和实用性往往超过单步预测.
极限学习机(extreme learning machine,ELM)是一种新型神经网络模型,与传统神经网络相比,ELM 可以避免训练陷入局部极值,学习精度和速度表现优秀,已在各行业领域中得到应用.但由于ELM初始输入权值和阈值具有随机性,很大程度上制约了其训练精度和泛化能力的提升.目前,粒子群优化算法[5]、果蝇优化算法[6]、灰狼优化算法[7]、鲸鱼优化算法[8]、黑猩猩优化算法[9]、樽海鞘群算法[10]、鸟群算法[11]等多种智能优化算法被用于ELM 优化,并取得较好的优化效果.
为提高水质时间序列多步预测精度,进一步拓展智能优化算法在ELM 优化中的应用,本文基于“分解-预测-重构”思想,研究提出小波包分解(wavelet packet decomposition,WPD)-人工蜂鸟算法(artificial hummingbird algorithm,AHA)-ELM 水质组合多步预测方法.模型主要按照以下3 个方面进行构建:①以云南省昆明西苑隧道断面pH 值、CODmn、DO、NH3-N 超前1步~超前5步预测为例,采用2层WPD 将pH 值、CODmn、DO 水质时序数据分解为4个子序列分量,采用3层WPD 将NH3-N 水质时序数据分解为8个子序列分量,达到降低时间序列数据复杂性的目的,并在延迟时间为1条件下,采用Cao方法确定各子序列分量的输入、输出;②介绍一种新型元启发式优化算法——人工蜂鸟算法(AHA),通过6个典型测试函数在不同维度条件下对AHA 寻优能力进行仿真验证,并与旗鱼优化(SFO)算法、灰狼优化(GWO)算法、粒子群优化(PSO)算法的仿真结果进行比较,旨在验证AHA 的寻优能力;③采用各分解分量训练样本构建ELM 适应度函数,利用AHA 优化适应度函数获得最佳ELM 输入层权值和隐含层偏值,建立WPD-AHAELM 水质时间序列多步预测模型对各子序列分量进行预测,将预测结果叠加重构后即得到pH 值、CODmn、DO、NH3-N 最终多步预测结果.
1 研究方法
1.1 人工蜂鸟算法(AHA)
1.1.1 AHA 简述
人工蜂鸟算法(AHA)是ZHAO 等[12]于2021年提出的一种新型元启发式优化算法.该算法模拟了自然界中蜂鸟轴向飞行、对角飞行、全方位飞行3种特殊飞行技能和引导觅食、区域觅食、迁移觅食3种智能觅食策略,并通过引入访问表来实现蜂鸟寻找和选择食物来源的记忆功能,最终达到求解最优化问题的目的.目前AHA 已在函数优化及工程设计中得到应用.AHA 数学描述简述如下[12]:
1)初始化.
AHA 将n只蜂鸟放置在n种食物源上,随机初始化食物源位置:

式中:xi表示第i个食物源位置;n表示种群规模;Su、SL分别表示搜索空间上、下限值;r表示[0,1]之间均匀分布的随机数.
食物来源访问表初始化如下:

式中:i=j表示蜂鸟在特定的食物来源处觅食;i≠j表示当前迭代中第j个食物源被第i只蜂鸟访问过.
2)引导觅食.
AHA 中,蜂鸟为了获得更多的花蜜,会在相同访问级别的食物源中访问花蜜补充率最高的食物源.在觅食过程中,通过引入方向切换向量描述全向飞行、对角飞行和轴向飞行3种技能,用于控制d维空间中的一个或多个方向是否可行.轴向飞行、对角飞行、全向飞行技能分别描述如下:

式中:D(i)表示飞行技能;i=rand([1,d])表示生成从1到d的随机整数;rand(k)表示创建从1到k的随机整数排列;r1表示[0,1]之间均匀分布的随机数;d表示问题维度.其中i=1,2,…,d.
凭借这些飞行技能,蜂鸟可以访问目标食物源,从而获得候选食物源.候选食物源位置更新数学描述如下:

式中:vi(t+1)表示第t+1次迭代第i个候选食物源位置;xi(t)表示第t次迭代第i个食物源位置;xi,tar(t)表示第i只蜂鸟将访问的目标食物源位置;a表示服从正态分布(均值=0,标准偏差=1)的引导因子.
依据式(6),引导觅食第i个食物源的位置更新如下:

式中:xi(t+1)表示第(t+1)次迭代第i个食物源位置;f(·)表示函数适应度值;其他参数意义同上.
3)区域觅食.
蜂鸟在访问了目标食物源后,很可能会移动到自己领地外的邻近区域寻找新的食物源,而不是访问其他现有的食物源.邻近区域候选食物源位置更新数学描述如下:

式中:b表示服从正态分布(均值=0,标准偏差=1)的区域因子;其他参数意义同上.
4)迁徙觅食.
当蜂鸟经常造访的区域缺乏食物时,蜂鸟通常会迁移到较远的食物来源区进行觅食.花蜜补充率最差食物源位置更新数学描述如下:

式中:xwor表示种群中花蜜补充率最差的食物源位置;其他参数意义同上.
1.1.2 AHA 仿真验证
选取Sphere等6个典型测试函数在不同维度条件下对AHA 进行仿真验证[13-15],并与GWO、SFO、PSO 算法的仿真结果进行比较,20次寻优平均值见表1.4种算法设置种群规模n=50,最大迭代次数T=100.其他参数设置采用各算法默认值.
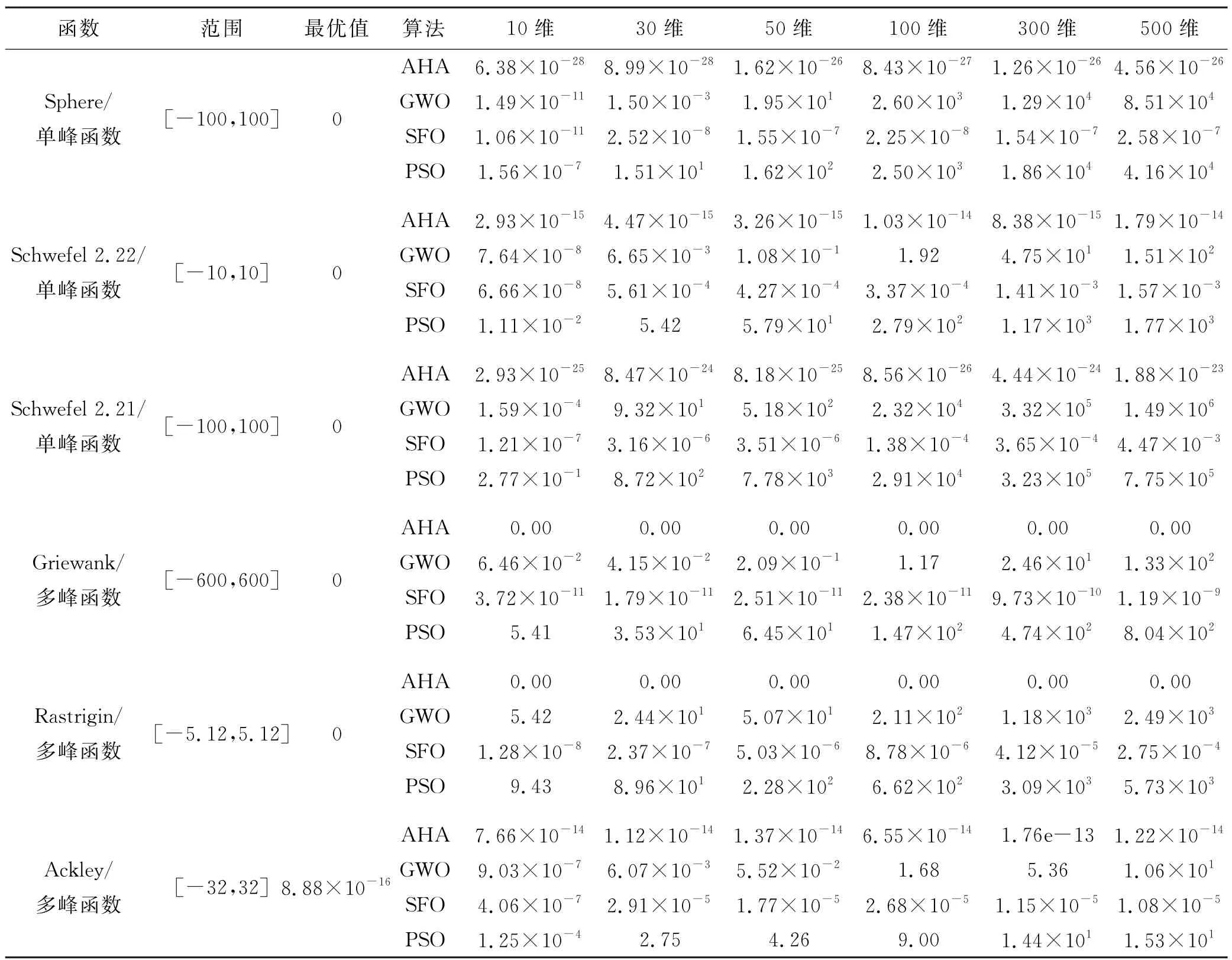
表1 AHA标准测试函数寻优结果
对于单峰函数Sphere、Schwefel 2.22、Schwefel 2.21,AHA 在不同维度条件下寻优精度较GWO、SFO、PSO 算法提高7个数量级以上;对于多峰函数Griewank、Rastrigin,AHA 在不同维度条件下寻优均获得理论最优值0,寻优精度优于GWO、SFO、PSO 算法;对于Ackley函数,AHA 在不同维度条件下寻优精度较GWO、SFO、PSO 算法提高6个数量级以上.可见,AHA 具有较好的寻优精度和全局搜索能力,寻优精度基本不受维度变化的影响.
1.2 小波包分解(WPD)
小波包分解(WPD)衍生于小波分解(WD),与之不同的是,WD 只对低频信号再次分解,不分解高频信号,而WPD 同时将低频、高频信号再次分解,并能根据信号特性和分析要求自适应地选择相应频带与信号频谱相匹配.对于波动信号,采用WPD 能够凸出信号的细节特征.小波包分解算法公式[16-18]为:

重构算法为:
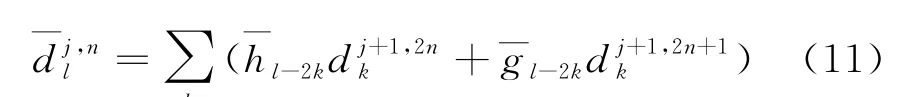
1.3 极限学习机(ELM)
极限学习机(ELM)是一种广义的单隐层前馈神经网络,具有较快的学习速度和良好的泛化能力.给定M个样本Xk={xk,yk},k=1,2,…,M,其中xk为输入数据,yk为真实值,f(·)为激活函数,隐层节点为m个,ELM 输出可表示为[9,19]

式中:oj为输出值;Wi={ωi1,ωi2,…,ωim}为输入层节点与第i个隐含层节点的连接权值;bi为第i个输入节点和隐含层节点的偏值;λi为第i个隐含层节点与输出节点的连接权值.
1.4 建模流程
WPD-AHA-ELM 模型预测步骤如下:
步骤1:小波包分解层数的确定是小波包分解的关键,分解层数过低,原始序列中的内部特征信息并未完全挖掘出来;分解层数过高不但易导致模型复杂度增加,而且过度分解会破坏原始序列的完整性和时变特征,反而起不到提升模型精度的作用[20].为兼顾分解效果和预测模型复杂度,本文基于dmey小波包基,采用2层WPD 分别将实例pH 值、CODmn、DO时序数据分解为4个子序列分量[2,1]~[2,4],采用3层WPD 将实例NH3-N 时序数据分解为8个子序列分量[3,1]~[3,8],如图1~4所示.

图1 pH值时序WPD分解3D效果图

图2 CODmn时序WPD/EMD分解3D效果图

图3 DO值时序WPD分解3D效果图

图4 NH3-N时序WPD分解3D效果图
从图1~4可以看出,[2,1]/[3,1]主要为低频部分,聚集了原始水质时间序列的大部分能量,描述了水质序列的趋势;[2,4]/[3,8]为所有分解分量中的最高频成分,也是幅值最低的分量,描述了水质序列的波动情况.
步骤2:为便于各分量预测结果重构,在延迟时间为1的条件下,采用Cao方法确定各子序列分量及原序列的嵌入维度l,即选取预报对象前l周历史数据来预报当周(超前1步)、第2周(超前2步)…第5周(超前5步)的水质.并选取1~468组样本为训练样本,468~624组样本为预测样本.
步骤3:利用训练样本均方误差(MSE)作为AHA 优化ELM 输入层权值和隐含层偏值的适应度函数minf(x,y).
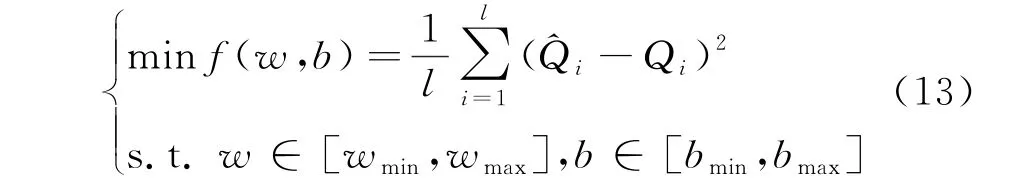
式中:^Qi表示第i个水质样本实测值;Qi表示第i个水质样本预测值;l表示训练样本数;w表示ELM 输入层权值;b表示隐含层偏值.
ELM 输入层权值、隐含层偏值优化维度表示为:
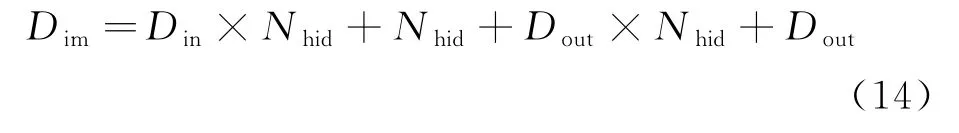
式中:Dim为优化维度;Din为ELM 输入维数;Nhid为隐含层神经元数;Dout为ELM 输出维数.
步骤4:设置蜂鸟种群规模n、最大迭代次数T.利用式(1)随机初始化食物源位置xi,i=1,2,…,n.令当前迭代次数t=1.
步骤5:基于式(13)计算食物源适应度值;保存当前最佳食物源位置xbest.
步骤6:执行引导觅食策略.利用式(6)更新候选食物源位置,利用式(7)更新食物源位置.
步骤7:执行区域觅食策略.利用式(8)更新邻近区域候选食物源位置.
步骤8:执行迁徙觅食策略.利用式(9)更新花蜜补充率最差食物源位置.
步骤9:利用更新后的食物源位置计算适应度值.比较并保存当前最佳食物源位置xbest.
步骤10:令t=t+1.判断是否满足终止条件,若是,输出xbest,算法结束;否则转至步骤7.
步骤11:输出minf(x,y)和最佳食物源位置xbest,xbest即为ELM 输入层权值和隐含层偏值矩阵.利用最优ELM 输入层权值和隐含层偏值矩阵建立WPD-AHA-ELM 模型对各分量进行超前1 步至超前5步预测,将预测结果叠加重构后即得到实例pH值、CODmn、DO、NH3-N 最终多步预测结果.
步骤12:模型评估.利用平均绝对百分比误差(EMAP)、平均绝对误差(EMA)、均方根误差(ERMS)和纳什系数(ENS)对预测模型进行评估,见式(15)~(18).

2 实例应用
本文实例昆明西苑隧道断面水质数据来源于中国环境监测总站2004—2015年实时监测值,按周统计,共 得624 组pH 值、CODmn、DO、NH3-N 数 据值,对于个别缺失数据采用线性法进行插补,如图5所示.

图5 昆明西苑隧道断面水质时序序列3D 图
从图5可以看出,pH 值、CODmn、DO 和NH3-N 时序数据呈现出典型的多尺度、非线性特征,尤其是NH3-N 时序数据,其最大与最小实测值之比高达703,起伏变化十分激烈.
2.1 模型参数设置
AHA 参数设置同上述“AHA 仿真验证”;ELM网络激活函数选择sigmoid,隐层数为2*input-1(input为输入维数),输入层权值和隐含层偏值搜索空间设置为[-1,1],数据采用[-1,1]进行归一化处理.
2.2 预测结果及分析
利用所构建的WPD-AHA-ELM 模型对pH 值、CODmn、DO、NH3-N 进行训练及多步预测,结果见表2.并利用上述平均绝对百分比误差(EMAP)、平均绝对误差(EMA)、均方根误差(ERMS)和纳什系数(ENS)对模型性能进行评估.预测相对误差效果图如图6~9所示.

表2 WPD-AHA-ELM 模型多步预测结果对比(pH 值无量纲)
依据表2及图6~9可以得出以下结论:
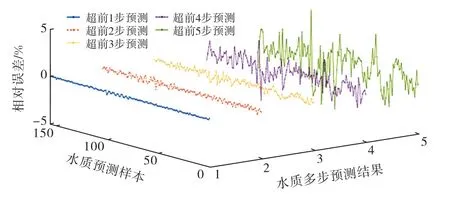
图6 pH 值时间序列预测相对误差3D

图7 CODmn时间序列预测相对误差3D

图8 DO 时间序列预测相对误差3D
1)WPD-AHA-ELM 模型对实例pH 值超前1步至超前5步预测的EMAP、EMA、ERMS分别在0.05%~1.23%、0.004~0.099、0.005~0.126之间,对超前1步至超前4 步预测的EMAP均在1%以内;对实例CODmn超前1 步至超前5 步预测的EMAP、EMA、ERMS分别在0.10%~3.15%、0.010~0.311mg/L、0.014~0.405mg/L之间,对超前1步至超前3步预测的EMAP均在1%以内,ENS均在0.9991以上;对实例DO 超前1步至超前5步预测的EMAP、EMA、ERMS分别在0.103%~3.67%、0.008~0.225mg/L、0.010~0.295mg/L之间,对超前1步至超前3步预测的EMAP均在1%以内,ENS均在0.9993以上;对实例NH3-N 超前1步至超前5步预测的EMAP、EMA、ERMS分别在0.65%~106%、0.002~0.028mg/L、0.002~0.035mg/L之间,对超前1步至超前4步预测的ENS均在0.9990以上.上述结果表明WPD-AHAELM 模型具有较高的预测精度和较小的预测误差,尤其是对pH 值、CODmn、DO、NH3-N 超前1 步 至超前3 步具有理想的预测效果.可见,WPD-AHAELM 模型用于水质时间序列多步预测是可行的.模型的预测精度随着超前预测步数的增大而降低.
2)从图9可以看出,NH3-N 实测值起伏变化十分激烈,最大与最小实测值之比高达703,采用2层WPD 难以将原始NH3-N 序列分解为多个平稳、集中的子序列;为兼顾预测精度和计算规模,采用3层WPD 将原始NH3-N 序列分解为8个更具规律的子序列分量,进而采用AHA-ELM 模型预测得到较好的预测结果.

图9 NH3-N 时间序列预测相对误差3D
3)从图6~9可以看出,总体上WPD-AHA-ELM模型对实例pH 值、CODmn、DO、NH3-N 时间序列超前1步至超前3步预测误差更小、效果更好.
3 结论
为提高水质时间序列多步预测精度,基于多种方法研究提出WPD-AHA-ELM 水质时间序列多步预测模型,通过云南省昆明西苑隧道断面pH 值、CODmn、DO、NH3-N 多步预测实例对模型进行验证,得到如下结论:
1)在不同维度条件下,AHA 对Sphere等6个标准函数的寻优效果优于GWO、SFO、PSO 算法,具有较好的寻优效果.将AHA 用于ELM 输入层权值和隐含层偏值优化是可靠的.
2)针对pH 值、CODmn、DO、NH3-N 时间序列多尺度、非平稳性特征,有区别性地采用2层和3层WPD 将原始水质序列分解为不同的子序列后再进行预测,可减小不同特征值序列数据之间的相互影响,将复杂的水质序列分解为多个平稳、集中的子序列,使得AHA-ELM 能够更好地预测每一个子序列,进而得到更好的预测结果.
3)WPD-AHA-ELM 模型对实例pH 值、CODmn、DO、NH3-N 时间序列超前1步至超前5步均具有较好的预测效果,尤其是对超前1步至超前3步的预测误差更小、效果更好.WPD-AHA-ELM 模型用于水质时间序列多步预测是可行的.WPD-RAHA-ELM模型的预测误差随着预测步数的增加而增大,超前预测步数越多,预测精度受到的影响越大,预测结果越会偏离实际值,预测效果越不理想.
