基于无人机高光谱的荒漠草原地物精简学习分类模型
2023-01-05毕玉革
王 圆 毕玉革
(1.内蒙古农业大学机电工程学院,呼和浩特 010018;2.鄂尔多斯应用技术学院信息工程系,鄂尔多斯 017000)
0 引言
荒漠草原是我国北方重要的生态安全屏障,在保持生物多样性及维护生态平衡方面具有特殊地位[1]。荒漠草原地物呈现细碎分布,分类要求趋于精细化[2],无人机低空遥感平台克服了传统遥感空间分辨率不足[3-5]的缺点,在草原生态环境保护领域逐渐得到应用[6]。高光谱数据具有“图谱合一”的特点[7],在地物精细识别分类中,以无人机为高光谱成像仪搭载平台,可充分发挥纳米级光谱分辨率与厘米级空间分辨率相结合的优势[8-9]。
从目前研究现状来看,许多性能优异的卷积神经网络模型经过改进后被引入到遥感影像解译中[10-11],这些模型[12-13]通过加深网络获取RGB图像特征[14-15],然而采用经典模型缺少对遥感场景特殊性的考虑[16-18]。大量研究成果为获得较高分类精度而创建了多层网络模型[19-20],如汪传建等[21]建立7层二维卷积神经网络模型对多种农作物进行分类,PI等[22]创建5层三维卷积神经网络模型对荒漠草原裸土、植被进行分类,这些深度网络模型可能存在计算过度、耗费时间过长等问题。应用于高光谱遥感的3D-CNN可以同时提取高光谱遥感影像数据的光谱信息和空间信息,缺点是3D-CNN卷积操作本身计算复杂度高,易造成计算压力加大,训练成本增加等问题。
本文集成无人机高光谱遥感系统,选择典型荒漠草原为研究对象,在保证地物分类精度的基础上,提出3D-CNN精简学习分类模型,并通过超参数调优,以降低模型深度为目标,向轻量、高效模型方向探索,以期建立适用于荒漠草原细碎地物分类应用的精简学习分类模型。
1 研究区与数据采集
1.1 研究区概况
研究区位于内蒙古自治区四子王旗,地理坐标为北纬41°47′17″,东经111°53′46″,海拔1 450 m,地处温带草原向干旱荒漠过渡的典型荒漠草原。无人机航飞数据采集区域为4.61 hm2,气候类型属于中温带大陆性季风气候,春季干旱多风,夏季炎热,年降水量约200 mm,该地具有荒漠草原典型地域的特征[23],植被草层低矮稀疏,盖度低且呈碎片化分布[24-25]。研究区域位置及无人机航飞区域卫星图像如图1所示。
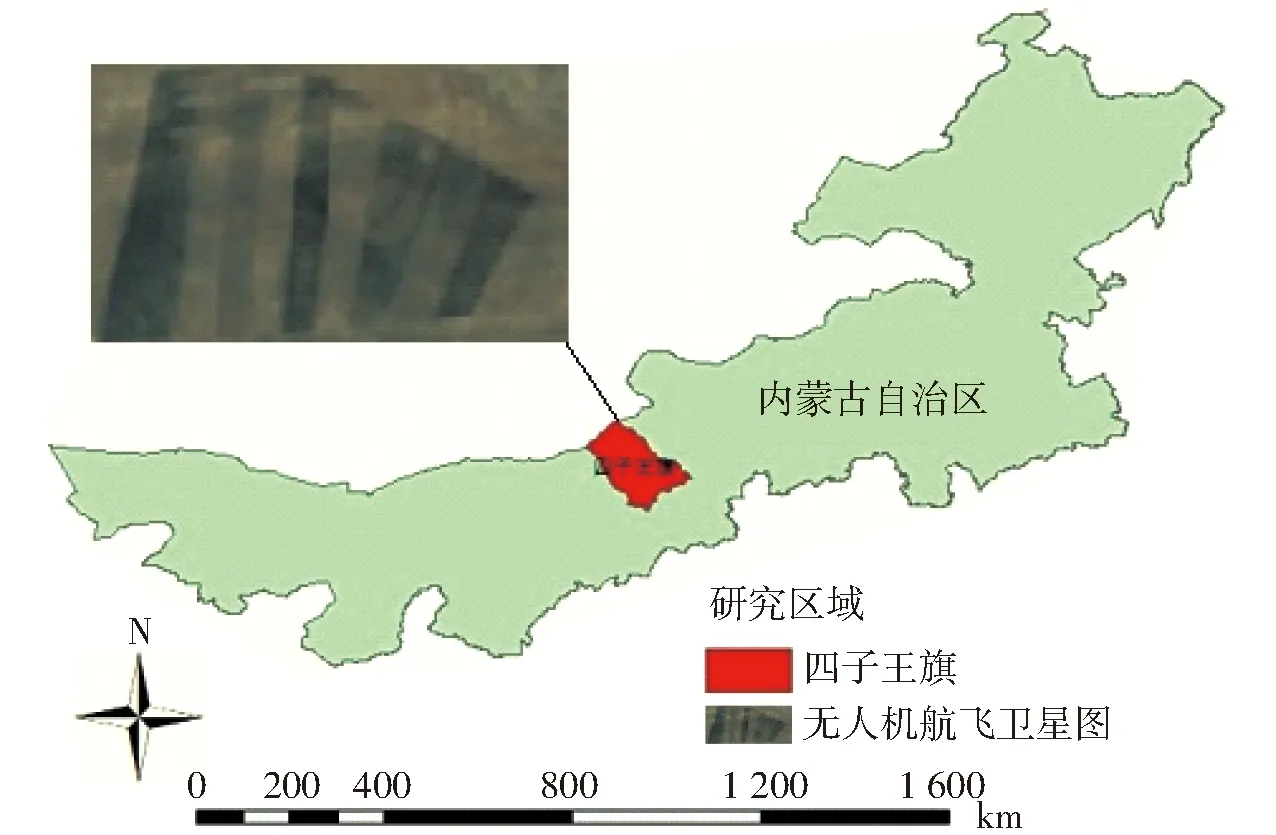
图1 研究区域位置及其卫星图像
1.2 无人机高光谱遥感采集系统
本研究集成的无人机高光谱遥感系统为六旋翼无人机搭载Gaia Sky-mini型高光谱仪,该高光谱仪具有256个波段,采用内置推扫成像工作方式,光谱分辨率为3.5 nm,光谱范围为400~1 000 nm,可将高空间分辨率与高光谱分辨率优势结合,并实现“空谱合一”,无人机高光谱遥感系统如图2所示。

图2 无人机高光谱遥感系统
2 研究方法
无人机高光谱影像数据采集后,在数据完成预处理的基础上,首先利用目视解译提取裸土、植被、标记物纯净像元光谱,进行光谱特征分析,计算反射率均值,选取特征波段;而后利用特征波段构建分类规则,进行阈值统计与分析,选取最佳可分性阈值,制作数据集;最后构建精简学习分类模型,并进行超参数优化,图3为研究方法的具体技术流程。
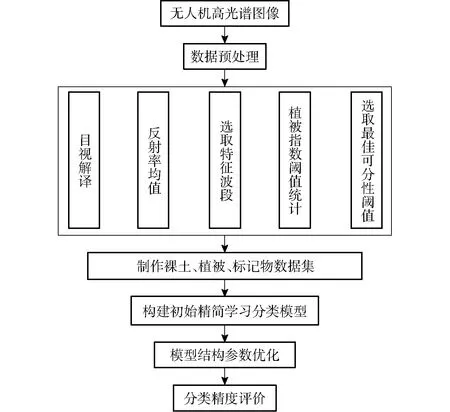
图3 技术路线流程图
2.1 高光谱影像获取和预处理
2.1.1无人机遥感系统数据采集及野外实测
根据2021年荒漠草原气候特征及其植被的生长周期特性,在植物长势茂盛的2021年7月上旬进行野外试验,通过人工踏访,在植被相对聚集区设置样方,共设置植被混合样方20个,为满足光学遥感所需的气象条件,选择无风晴朗少云的天气进行野外数据采集并及时校正标准参考白板。为了便于无人机空中采集数据辨认样方种类,由样方外西南角插下蓝色小旗、东北角放置蓝色地垫共同指示,标记物图像如图4中红色方框所示。

图4 标记物图像
无人机飞行高度30 m时,获得的高光谱遥感影像的空间分辨率为2.3 cm,满足荒漠草原裸土、植被群落和标志物的目视解译要求。为了进一步减小随机误差,对每个样方采集5次,图5为无人机数据采集流程图。

图5 无人机数据采集流程图
2.1.2数据预处理
本文数据预处理包括去除扭曲变形图像、辐射校正、滤波降噪等环节。先由人工目视法去除因阵风影响发生扭曲变形的图像,而后使用SpectView软件进行辐射校正,将遥感影像像元亮度值(Digital number,DN)转换为光谱反射率[26],得到地物真实的反射率数据,再使用ENVI 5.3软件进行反射率检查,进一步筛选出可用数据。由于野外采集光谱受到环境干扰、仪器噪声等多种因素影响,导致光谱曲线附带较多噪声,影响后续光谱分析。为使光谱曲线降低噪声干扰[27],更易发现波峰、波谷,因此需要对反射率校正后的光谱曲线进行光谱平滑去噪[28-29],本文采用Savitzky-Golay方法进行平滑降噪。
2.2 样本数据制作
高光谱图像由数百个高度相关的光谱波段组成,光谱信息丰富,具有遥感大数据的特征[30],因此高光谱遥感影像数据的处理方式不同于RGB 3波段图像数据处理,高光谱图像处理通常用到波段选择[31]、特征提取[32]等方法。
2.2.1存储格式转换
本研究采集数据默认的存储格式为波段按行交叉格式(Band interleaved by line format,BIL),由于按波段顺序排列存储格式(Band sequential format,BSQ)更适合空间分析应用,因此将无人机获得的高光谱数据由BIL格式转换为BSQ格式。
2.2.2包络线去除
基于荒漠草原地物之间光谱差异微弱的特点,直接使用原始反射率光谱构建植被指数难以实现地物分类,因此需要采用光谱变换的方法增强光谱差异。本文采用包络线去除法,将原始反射率光谱进行连续统去除变换,有效突出了地物的光谱特征。
2.2.3植被指数构建
利用经过连续统去除变换后的高光谱数据,选取第50波段(中心波长为508.6 nm)和第65波段(中心波长为543.5 nm)构建差值植被指数(Difference vegetation index,DVI),选取第125波段(中心波长为686.7 nm)和第145波段(中心波长为735.8 nm)构建归一化植被指数(Normalized difference vegetation index,NDVI)。以上2种植被指数利用近红外波段高反射率和红光波段低反射率进行波段合成[33]。通过构建的2种植被指数,获得植被图像增强的灰度图,提高了目视解译精度,便于进一步选取感兴趣区域[34-35]。
2.2.4自制数据集
数据采集时由于空间分辨率的影响导致存在大量混合像元,干扰地物边界提取,造成光谱数据不确定,导致地物像素分类难度加大。通过对感兴趣区域裸土、标记物、植被3种地物提取纯净端元,构建植被指数分别进行阈值统计。具体过程为:①通过选取每类地物各50个纯净像元确定特征波段。②利用特征波段建立植被指数,获得灰度图。③在灰度图上选出各地物像元,进行置信度为5%~95%的DN值统计。④分析得出各地物的最佳可分阈值,设定NDVI大于0.15且DVI大于0标记为植被,NDVI取[0,0.08]标记为裸土。裸土、植被、标记物对应的颜色编码和样本数量如表1所示。
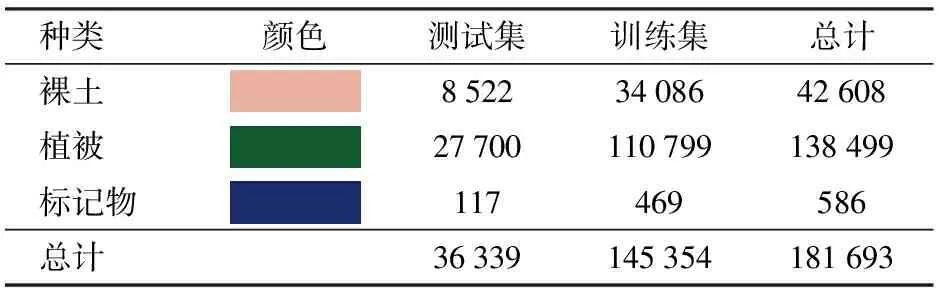
表1 数据集颜色编码和样本数量
在确定地物间最佳可分阈值基础上制作数据集,数据集共有181 693个数据样本,其中裸土有42 608个,标记物(地垫、旗子)有586个,植被有138 499个。在进行模型训练之前,随机选取数据集中80%的数据作为训练集,其余20%的数据作为测试集,训练集共有145 354个样本,测试集共有36 339个样本,数据集标签图如图6所示。

图6 数据集标签图
2.2.5数据降维
高光谱图像数据大量波段间的高度相关性带来了数据冗余,有必要进行数据降维[36],本研究获取的高光谱数据共有256个波段,采用主成分分析(PCA)法,设置8个新的主成分进行降维,将图像信息保留到98%以上。
2.2.6patch分割
高光谱遥感数据地物分类是类似于图像语义分割的技术,即把分类器的预测结果映射到遥感影像的每个像素,实现影像分割。3D-CNN是以影像像素的邻域块作为网络的输入,基于滑动窗口patch进行高光谱遥感影像语义分割,设置窗口尺寸为17,即表示采用一个尺寸17×17的滑动窗口,按照从左到右、从上到下遍历整个高光谱遥感影像,将每个窗口的内容放在卷积神经网络里面进行分类,分类结果就是每一个窗口的中心像素点的类别。
2.3 精简学习分类模型构建和精度评价
2.3.1精简学习分类模型构建
与传统的机器学习特征工程[37-38]相比,深度学习可以自动提取图像内在深层特征,有利于解决复杂的分类问题,因此现有研究中模型卷积层个数普遍大于1层,但随着层数的增加容易造成计算过度的问题。本研究旨在建立适用于荒漠草原地物分类的单层卷积学习分类模型,以构建精简模型的思路解决荒漠草原地物分类的问题,并在此基础上,进行网络超参数的优化,达到高精度识别各类地物的目的,精简学习分类模型结构示意图如图7所示。
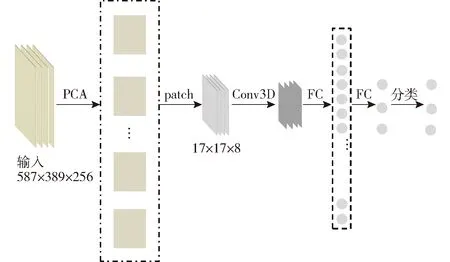
图7 精简学习分类模型结构示意图
初始网络模型中,卷积核数量为4,卷积核尺寸为7×7×7,窗口尺寸为17,学习率为0.001,批量规模为32,训练轮数为100。初始网络模型如表2所示。

表2 初始网络模型
2.3.2精度评价
为评价精简学习分类模型的分类精度,本文采用混淆矩阵、测试准确率、总体分类精度(Overall accuracy,OA)、平均分类精度(Average accuracy,AA)、Kappa系数等作为精度评价指标,对分类结果进行分析并评价模型性能。其中,混淆矩阵以表格形式对多分类结果进行可视化展示,总体分类精度以数值形式表示被正确分类的样本数占分类样本总数的比例。
3 结果与分析
3.1 初始模型可视化分类结果
对初始精简学习分类模型进行训练,得到初始模型分类结果:初始模型的裸土测试准确率为99.835%,植被测试准确率为99.913%,Kappa系数为0.988,总体分类精度(OA)为99.573%。
初始模型可视化分类结果如图8所示,从图8可以看出,初始模型未识别到任何标记物,即标记物识别率为0%,初始模型平均分类精度为66.583%,识别结果未达到预期效果,因此本模型需进行超参数优化,进一步改善模型分类性能。

图8 初始模型可视化分类结果
3.2 精简学习分类模型超参数优化
根据参数逻辑关系及单变量原理,依次调整初始精简学习分类模型中的超参数,逐步得到最优超参数组合并进行预测。具体超参数有训练轮数、卷积核尺寸、卷积核数量、学习率、批量规模等。
(1)训练轮数。通过反复多次进行模型训练,结果显示模型在训练轮数前50次期间,训练精度已趋于一个稳定值,所以在随后训练中,训练轮数均取50即可。
(2)卷积核数量。卷积核起到特征提取的作用,增加卷积核数量可以提高模型性能,训练时间也相应增加。因此在初始精简学习分类网络模型卷积核数量为4的基础上,逐渐增加卷积核数量至5、6、7、8、9、10,分别进行模型精度测试,得到总体分类精度分别为95.546%、99.912%、99.931%、99.568%、99.584%、99.917%。
当卷积核数量为5、6、7时,总体分类精度逐步升高,卷积核数量为7时达到最大值。当卷积核数量为8时,分类精度下降,卷积核数量为9和10时,分类精度有所上升,但未达到最大值。
(3)学习率及卷积核尺寸。保持初始模型的学习率为0.001,卷积核数量为4,将卷积核尺寸分别设置为1×1×1、3×3×3、5×5×5时,得到分类结果如表3所示,从表3可看出,这3种卷积核尺寸条件下的标记物均未被识别出。
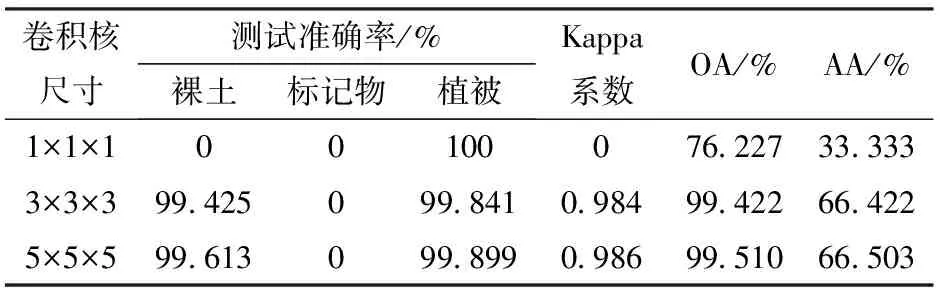
表3 初始模型的学习率为0.001时的分类结果
将学习率设置为0.000 1,对卷积核尺寸依次设置为1×1×1、3×3×3、5×5×5、7×7×7,得到分类结果如表4所示。

表4 初始模型的学习率为0.000 1时的分类结果
由表4可以看出,在学习率为0.000 1条件下,卷积核尺寸为3×3×3、5×5×5、7×7×7时均可以高精度识别标记物,模型在卷积核尺寸为7×7×7时达到最优。
(4)批量规模。在初始模型各项参数保持不变的基础上,取批量规模依次为16、32、64、128、256、512,对比模型在不同批量规模下的分类结果,如 图9所示。当学习率保持0.001时,改变批量规模,随着批量规模增加,各项指标均得到提升,当批量规模为512时,模型分类结果达到最优。
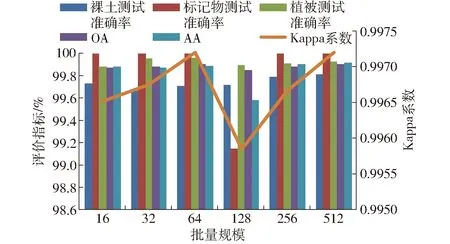
图9 不同批量规模的分类结果
(5)其他参数。将卷积层valid模式更改为same模式进行训练,分类效果基本不变,卷积运算模式对本模型分类结果影响不大;将池化参数由(1,1,2)更改为(2,2,2)后进行训练,结果显示此操作不能对标记物识别结果起到改善作用。
3.3 模型优化结果分析
研究表明学习率、卷积核尺寸、批量规模对精简学习分类模型性能影响较大,而卷积模式、池化参数对模型性能影响较小。综合以上研究结果,设定各超参数为:批量规模为512,学习率为0.000 1,卷积核尺寸为7×7×7,训练轮数为50,卷积核数量为4,连续训练5次,分类结果如表5所示。

表5 连续训练5次的分类结果
通过模型优化,本研究将初始精简学习分类模型在数据集上的总体分类精度从99.573%提高到99.746%(5组数据的计算平均值)。模型优化后可视化分类结果如图10所示。

图10 模型优化后的可视化分类结果
分析初始学习精简分类模型识别标记物小样本出现的问题,原因是学习率为0.001时,损失函数曲线波动较大,不利于标记物的识别。可将学习率降低,设置学习率为0.000 1,采用优化后的超参数组合,得到模型损失函数曲线如图11所示,由图11可知,曲线较为平滑,模型优化效果较好。
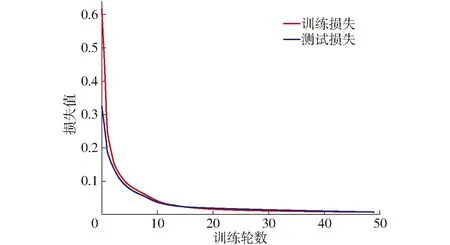
图11 优化后模型损失函数曲线
4 结论
(1)针对荒漠草原植被稀疏、裸土呈细碎化分布的特点,集成了无人机高光谱遥感系统,选择在典型荒漠草原进行地物光谱数据采集,首次提出基于3D-CNN的精简学习分类模型,对荒漠草原植被、裸土、标记物等地物进行分类,得到了较高精度。精简学习分类模型具有轻量、高效的特点,在荒漠草原地物的分类与识别应用中具有较大优势。
(2)采集的无人机高光谱数据具有256个波段,不能直接输入精简分类模型,需通过主成分分析法进行降维,为保留98%的信息量,获得8个主成分,若保留更少的信息量,主成分数量也可减少,分类模型可进一步简化。
(3)对初始模型调优的过程中发现3个主要规律:针对初始模型对标记物的识别效果不佳问题,通过对学习率、批量规模、卷积核尺寸、卷积核数量等超参数优化,可有效提高标记物识别率,而通过改变卷积模式、池化参数等方式,不能改善标记物识别效果;学习率对模型训练有较大影响,当学习率偏大时,损失函数曲线呈现出较大波动,不利于标记物识别,应降低学习率,使损失函数曲线趋于平滑后再进行标记物识别;在确定适当学习率基础上,选择尺寸较大的卷积核有利于标记物的分类与识别。精简学习分类模型的优化建立在多种超参数不断调整的基础上,需充分对比不同组合分类效果,来获得精度高、耗时短、性能稳定的最优模型。
