一种3D眼镜虚拟试戴系统的实现
2023-01-03王晓锋付东翔
王晓锋,付东翔
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着互联网购物的普及,增强用户的购物体验已经成为计算机应用的一个热门课题。虚拟试戴眼镜的应用允许用户在网上选择眼镜进行试戴,不需要去线下实体店,提高了用户的购物体验。
目前,虚拟佩戴技术根据输入眼镜和人脸形式主要分为4类。第1类技术基于二维图像,例如文献[1]将眼镜图像佩戴到人脸图像上。这种方法相对简单,佩戴效果可接受,但只能处理正视角的人脸图像,不能真实反映用户真实的动态佩戴效果。第2类技术是将三维眼镜模型佩戴到人脸图像上,例如文献[2]使用三维眼镜模型代替眼镜图像,可以帮助系统处理多个视角的人脸图像,但需要解决镜腿的遮挡问题。第3类是将三维眼镜模型佩戴到重建的三维人脸模型,例如文献[3~5]解决了镜腿的遮挡问题,但重建三维人脸[6]是一个挑战,而且重建的三维人脸模型缺乏现实感。第4类是基于视频流的现实增强技术,例如文献[7~8],但试戴者必须配备摄像头,灵活性和便捷性欠佳。
本文结合人脸关键点检测和凸包算法提出了一种新的镜腿遮挡方法,能解决三维眼镜模型试戴到人脸图像上镜腿的遮挡问题。基于早期研究人员的研究成果,本文提出了一种基于特征点检测和姿态估计的虚拟佩戴技术,实现了真实的虚拟佩戴。本文所提系统的总体流程图如图1所示。

图1 虚拟试戴系统流程图Figure 1. Flow chart of virtual trial system
1 人脸形状三维模型的构建
构建人脸形状的三维模型是基于人脸关键点检测来实现的。通过对人脸关键点进行凸包运算,得到人脸的凸多边形,再通过平移扫描得到人脸形状的三维模型。
1.1 人脸关键点检测
本文中,人脸关键点检测采用级联的回归树[9]来实现人脸对齐。这种方法属于回归级联方法,将图像稀疏的像素强度子集作为特征,用回归树集合从中直接估计出人脸特征点的位置,进而对输入的图像进行人脸检测[10];然后标记出人脸的外轮廓、眼睛、鼻子、嘴巴、眉毛区域的关键点。如图2所示,用圆点标注的点即为检测出的关键点。

图2 人脸关键点Figure 2. Key points of the face
该关键点检测算法使用级联回归来建立数学模型,其迭计算式为
S′(t+1)=S′(t)+rt(I,S′(t))
(1)
式中,S是形状向量,存储着脸部所有关键点的位置信息;S′(t)表示对形状向量的估计;rt是一个回归器;t是级联序号。
在rt内部的回归过程中,采用梯度树提升法[11]得到一系列的回归树来完成回归。
在回归训练中,数据集合是(I1,S1),…,(In,Sn),其迭代为
S′i(t+1)=S′i(t)+rt(Iπi,S′i(t))
(2)
ΔS′i(t+1)=Sπi-S′i(t+1)
(3)

1.2 构建人脸形状的三维模型
本文将包含一个平面散点集的最小凸多边形(区域内任意两点的连线总在区域内)称为点集的凸包。本文采用Graham扫描法[12]对人脸关键点集合求运算,该算法运行速度快,得到的人脸的凸多边形效果较好。根据章节1.1中求得的人脸检测的关键点,本文选择人脸外轮廓的关键点作为输入。Graham扫描法的运算步骤如下,其中n是输入的人脸关键点数,Q为关键点点集,St为堆栈,存储凸包上的关键点:
步骤1在平面关键点点集中找出纵坐标最小的点,记为q0,已知该点是凸包上的一个点;
步骤2将点集Q中除q0以外的点以q0为坐标原点,转化剩余点的坐标;
步骤3以q0作为原点,计算剩余点对于q0点的幅角;
步骤4按照幅角大小的升序,重新排序点集Q后,记为Q′={q0,q1,…,qn-1};
步骤5初始化堆栈St,其中令St(0)=qn-1,St(1)=q0;初始化栈顶指针Stp指向第2个元素q0,点集Q’中元素的下标记为m,令m=0;
步骤6若m≥n,算法结束;
步骤7假设当扫描到Q′中下标为k的点Q′[k]时,此时St[j]是栈顶的元素,St[i]是其上一个的元素,判断St[i]、St[j]、Q′[k]这3个关键点形成的路径是左旋还是右旋。若为左旋,说明Q′[k]是凸包上的点,把这个点压入栈中,继续扫描点集Q′的下一个点,令Stp = Stp+1,St[Stp]=Q′[k],m=m+1,然后跳转到步骤6。若为右旋,说明St[j]不是凸包上的点,把St[j]弹出堆栈,此时扫描点仍为Q′[k],令Stp = Stp-1,跳转到步骤6。
经过以上的Graham算法步骤,得到人脸形状的凸多边形,将凸多边形轮廓内的区域作为填充区域,进行图元填充后得到凸多边形平面。本文采用扫描表示法[13]来构造人脸形状的三维模型。扫描表示法是一种通过平移、旋转及其他对称变换来构造三维模型的方法。通过指定一个二维图像,在空间区域内移动该图像的扫描可以表示一个三维模型。例如,把一个圆形图像作为输入,输出的是一个圆柱体的三维模型。根据以上得到的人脸形状的平面,把其作为输入,执行一次平移扫描,即沿垂直平面的直线路径移动一定距离。在沿这条路径的区间上,复制平面的形状,并在扫描的方向上画出连线,得到了人脸形状的三维模型。如下图3所示为人脸形状三维模型生成的结果,其中图3(a)是输入的人脸图像,图3(b)是人脸形状凸多边形,图3(c)是人脸形状三维模型。

图3 人脸形状三维模型的结果(a)图像 (b)凸包 (c)模型Figure 3. Result of 3D model of face shape(a)Image (b)Convex hull (c)Model
2 基于姿态估计的眼镜佩戴
2.1 头部姿态估计
头部姿态估计是以人脸图像作为输入,对头部姿态参数进行估计的方法。姿态角的形式是一个三维矢量,其值代表绕3个轴(x、y、z)的旋转角度,称为滚动、俯仰、偏航。
姿态估计的算法大致可以分为两类:第1类是基于外观的算法;第2类是基于模型的算法[14]。基于外观的方法是将新的头部姿势图像与模板联系起来,利用深度图像[15]确定实时的头部姿态估计。但该方法需要像kinect的深度相机[16]来获取深度图像,深度相机价格昂贵,适用的范围小,不适合虚拟眼镜试戴的应用。基于模型的算法需要三维标准的人脸模型,其原理是旋转三维标准人脸模型,使模型上的三维体征点投影尽可能与输入图像的特征点重合。本文采用是基于模型的姿态估计算法,在章节1.1中,已经求得人脸上的关键点,选取其中如图4所示的关键点(外眼角、鼻尖、嘴巴的两侧、下巴的最下端),采用非线性最小二乘法进行建模,计算式为

图4 人脸姿态估计关键点Figure 4. Key points of face pose estimation
(4)
式中,α、β、γ分别代表面部姿态角的3个分量;n代表特征点数;qi是待测人脸的特征点;pi是人脸特征点在三维人脸模型上对应的特征点;R是旋转矩阵;t是平移向量;C是收缩因子。
2.2 生成3D眼镜模型
为了增强虚拟试戴的真实感和现实感,本文采用的3D眼镜模型是fbx格式的。fbx模型由3ds Max软件生成,通过3ds Max软件的绘制,可以得到各式各样的3D眼镜模型。本文的工作是3D眼镜模型的虚拟试戴,从3ds Max中构建的三维眼镜模型如图5所示。

图5 3ds Max中的眼镜模型(a)模型1 (b)模型2 (c)模型3 (d)模型4Figure 5. Models of glasses in 3ds Max(a)Mode l (b)Mode 2 (c)Model 3 (d)Model 4
将fbx格式的眼镜模型导入到虚拟试戴系统时,需要对眼镜模型进行解析和重构,将模型中的顶点、线、面、纹理坐标、材质信息等数据传输到系统中,可以准确地绘制出3D眼镜模型。
2.3 眼镜佩戴
眼镜模型若要准确地佩戴到人脸图像上,则需要对齐到空间中的一个位置和做相应的变换,其中变换包括旋转变换和缩放变换。由于人脸图像是一个二维图像,不包含深度信息,因此将眼镜模型与人脸图像的佩戴问题转化为眼镜模型和人脸形状的三维模型之间的关系。基于人脸关键点检测的结果,本文选择人脸图像上鼻子根部的一个关键点的垂直方向向上两个单位的点Fn(如图6(a))作为佩戴点,同时选择眼镜模型中的Gn(如图6(b))作为支撑点,如图6所示。

图6 眼镜试戴定位点(a)人脸关键点 (b)眼镜关键点Figure 6. Registration point for fitting glasses(a)Key point of face (b)Key point of glasses
在三维空间中对物体的旋转变换有多种表达方式,例如欧拉角、旋转矩阵、四元数、旋转向量等。其中,欧拉角是最直观的表达方式,其含义是绕眼镜模型自身的3个轴(x、z、y)分别旋转某个角度。基于人脸姿态估计的结果,得到人脸图像在6个自由度上的偏转欧拉角(滚动、俯仰、偏航)。根据欧拉角,旋转眼镜模型,设定滚动角是α,俯仰角是β,偏航角是γ,旋转变换如式(5)所示。在虚拟试戴过程中,根据人脸大小来缩放三维眼镜模型,缩放计算式如式(6)所示。
R(α,β,γ)=Rx(α)Ry(β)Rz(γ)
(5)
其中
(6)
式中,Sx、Sy、Sz分别是x、y、z轴的缩放参数;P′是变换后的三维模型矩阵;P是原来三维模型矩阵。
2.4 遮挡处理
在真实的三维空间中,眼睛看到的画面是沿着视线投影的结果,物体间存在着互相遮挡的关系,例如从侧面观察佩戴眼镜者,佩戴者另一侧的眼镜镜腿是被遮挡的,是看不见的。但是,在虚拟试戴的系统中,由于人脸图像不包含深度信息,当试戴三维眼镜模型的时,被头部遮挡的眼镜模型不会被消隐,自然的投影不能实现遮挡眼镜的作用。
目前较好地解决镜腿遮挡问题的方法是根据人脸图像实时渲染出一个三维的人脸模型,利用深度缓冲检测[12]消隐镜腿,但是构造三维人脸模型计算复杂且对设备的要求较高。本文中构造的人脸形状三维模型代替了人脸模型,实现了镜腿遮挡的佩戴效果。
首先,创建一个三维的空间场景,依次导入人脸图像、人脸形状的三维模型、三维眼镜模型,将人脸形状的三维模型贴合到人脸图像上,根据人脸关键点定位和三维眼镜模型的变换进行佩戴工作,并利用深度缓冲检测消隐眼镜被遮挡的部分;然后设置人脸形状的三维模型透明度为0,通过摄像机的投影输出虚拟试戴效果图。实验结果证明,上述遮挡处理方法可靠,佩戴效果逼真。遮挡处理的实验如图7所示,图7(a)是未进行镜腿遮挡处理的实验结果图,图7(b)是进行镜腿遮挡处理的实验结果图。

图7 镜腿遮挡前后对比图(a)遮挡问题 (b)解决遮挡Figure 7. Comparison of mirror leg before and after occlusion(a)Occlusion problem (b)Occlusion is handled
3 实验分析和结果
3.1 实验分析
实验中的人脸图像是相机从多个角度拍摄而来的,包含人脸的多个视角,其偏航角度范围控制在-58°~65°,俯仰角度范围在-74°~76°,翻滚角度范围在-38°~45°。角度过大易导致人脸关键点检测失败,无法进行虚拟试戴的工作。因此,本文在求人脸凸多边形时,舍去了人脸轮廓内的关键点,仅计算人脸外轮廓的关键点的凸包。实验表明,人脸图像在水平方向上的角度范围在-26°~26°时,通过外轮廓关键点求得的凸包形状和人脸全部关键点求得的凸包形状一致。当人脸水平角度不在这个范围时,眼睛和眉毛部位的关键点和外轮廓的关键点较近,导致凸包形状和人脸全部关键点求得的凸包形状有小范围的偏差,但是不影响最后的佩戴结果。以下是不同大小的人脸图像虚拟试戴实验数据,其中凸包运算时间、人脸形状的三维模型构建的平均消耗时间如下表1所示。

表1 系统运行平均消耗时间表Table 1. Average cost schedule for system operation
为了测试镜腿遮挡效果的效果,实验中将输入人脸图像分为3组:第1组偏航角度在-5°~5°,作为人脸正脸图组;第2组偏航角在-58°~-5°,作为右脸图组;第3组偏航角在5°~65°,作为左脸图组。实验中定义遮挡误差率为输出图像中被遮挡镜腿的水平偏差像素与实际应露出镜腿的水平像素之比。实验数据如下表2所示。
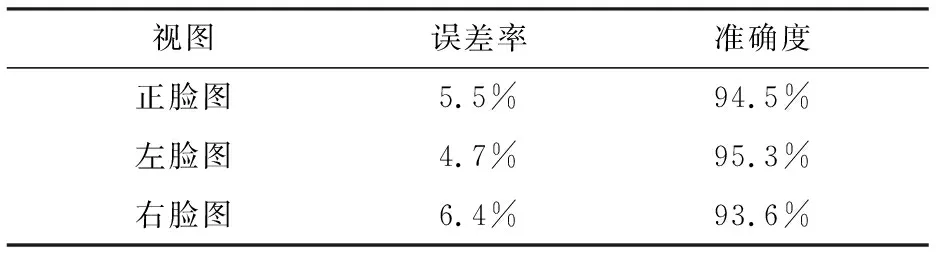
表2 镜腿遮挡准确度Table 2. Mirror leg occlusion accuracy
由表1可知,在舍去人脸内轮廓的关键点之后,获得的人脸凸包和人脸形状的三维模型运行速度都有所提高。
由表2可知,本实验方法的遮挡误差小,遮挡精度高,符合虚拟试戴的要求。
实验中,将本文的姿态估计方法与其他方法例如PRNet[6]进行运算速度比较。如表3所示,本文姿态估计算法具有明显的速度优势。

表3 不同方法的头部姿态估计运行速度Table 3. Running speed of different head pose estimation methods
3.2 实验结果
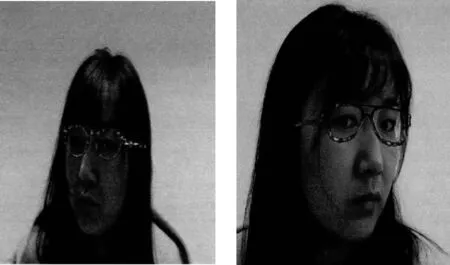
为了验证本文方法的效果,将本文所提出方法的虚拟试戴结果和其他虚拟试戴方法的结果进行比较。文献[3~5]涉及到人脸三维重建的技术,计算量大而且不容易实现,重建出来的三维人脸缺少真实的纹理信息,使得佩戴效果不具有真实感。文献[1]是根据二维图像的操作,不能实现多角度的人脸图像的佩戴功能,而且镜腿的遮挡问题没有得到有效解决。本文不需要进行复杂的三维人脸重建,而且针对多角度的人脸图像解决了镜腿的遮挡问题,实现了眼镜的真实佩戴效果。图8和表4是本文实验结果和其他方法的结果对比。其中图8(a)是文献[2]的实验结果图,图8(b)是文献[8]的实验结果图,图8(c)是文本实验结果图。

表4 不同方法的虚拟试戴对比Table 4. Virtual try - on comparison of different methods
图8 (a)虽然没有出现镜腿遮挡人脸的情况,但人脸图像的另一侧不能看到露出的部分镜腿(图8(a)左侧图片中没有露出左边的部分镜腿,右侧图片中没有露出右边的部分镜腿),并没有解决镜腿的遮挡问题。图8(b)中,眼镜大小不够精准,出现了镜框遮挡鼻子的问题,而且人脸另一侧的镜腿完全消失,没有解决镜腿遮挡问题。本文的实验结果表明,在虚拟试戴眼镜过程中解决了镜腿遮挡的问题,人脸另一侧的镜腿露出适当长度,增加了虚拟试戴的真实感。

(a)
(b)

(c)图8 实验对比 (a)文献[2]方法 (b)文献[8]方法 (c)本文方法Figure 8. Comparison of experiments(a)Method from reference[2] (b)Method from reference [8] (c)The proposed method
实验中采用不同眼镜模型对虚拟试戴系统进行测试,测试结果如图9所示。

图9 试戴不同眼镜的效果图(a)效果1 (b)效果2 (c)效果3Figure 9. Result of trying on different glasses(a)Result 1 (b)Result 2 (c)Result 3
4 结束语
本文基于人脸图像的关键点检测,提出了一种新的镜腿遮挡方法,根据人脸关键点生成人脸形状的凸多边形,通过平移扫描得到人脸形状的三维模型,在空间中对眼镜模型做相应变换,并将其佩戴到人脸上,利用深度缓冲检测实现镜腿消隐的作用。实验结果表明,虚拟试戴中镜腿的遮挡精度高,虚拟试戴效果逼真,并且对多视角的人脸图像完成佩戴工作有较好的动态展示效果。实验中利用图形学方法生成的人脸凸包和人脸三维模型速度较快,能较好地满足虚拟试戴的要求,使线上用户有较好的购物体验,因此本文研究具有一定的应用价值。本文方法也适用于其他虚拟试戴场景,例如虚拟试戴帽子、头戴式耳机、头巾等物品,试戴过程中能对物品起到遮挡的效果,使得佩戴效果更具有真实感和现实感。当前虚拟试戴领域研究较少,下一步的研究工作将集中在以下3个方面:(1)提高人脸图像的关键点检测精度,进而提高佩戴眼镜的精准度;(2)提高人脸检测视角的范围,使得人脸在大角度偏转的情况下,仍然实现虚拟试戴工作;(3)将本文方法推广到更广泛的应用场景,发挥更大的应用价值。
