基于力导引算法的复杂网络多细节层级可视化
2022-12-30安沈昊于荣欢
安沈昊,于荣欢+,薛 琼
(1.航天工程大学 复杂电子系统仿真重点实验室,北京 101416;2.中国航天系统科学与工程研究院 信息工程研究所,北京 100032)
0 引 言
网络拓扑可视化技术能够以图形图像的方式清晰展现复杂网络中节点的连接情况,帮助人们有效认识和理解网络内部特征和结构[1]。力导引算法作为目前最常用的网络拓扑可视化技术,实现简单、易于理解,适用于大多数复杂网络结构数据的可视化。但随着复杂网络的结构逐渐向多层化、复杂化发展,如何在狭小的屏幕范围内合理地展现复杂网络的宏观整体结构与局部细节结构为基于力导引算法的网络拓扑可视化带来了巨大的挑战。因此,为兼顾复杂网络拓扑结构在宏观整体与局部细节方面的可视化分析,本文将力导引算法与层次聚类算法结合,提出了一种能够在不同细节层级下展示复杂网络结构特征的可视化方法。首先简要介绍了几种经典力导引算法,分析了当前复杂网络在可视化研究方面的不足。之后在FR(Fruchterman Reingold)算法[2]的基础上进行改进,提出了一种可变力导引算法(variable force-directed algorithm,VFDA),通过改变同一层级结构下节点之间的引力来有效展示社团结构与层次结构。最后描述了聚类规则,通过层次聚类算法对节点进行聚类并建立网络多细节层级模型,实现不同层次下的网络拓扑结构可视化。通过对复杂网络实例数据进行实验与对比分析,验证了本文可视化方法的有效性与适用性。
1 经典力导引算法
力导引算法又称弹簧模型,其原理是将网络中的节点和边模拟为钢环和弹簧,二者共同组成为一个物理系统[3]。确定初始状态之后,弹簧的相互作用会使钢环位移,当系统总能量消耗至最小值时钢环保持静止。弹簧模型为了减小距离过于远的两个节点之间的作用力,并没有遵循胡克定律,且每次迭代都需要计算节点的受力情况,对大规模网络进行布局时算法运行度较高、布局效果较差。因此,不少学者在原算法的基础之上进行了改进,例如KK(kamada kawai)算法[4]、DH(davidson harel)算法[5]、FR算法、LinLog算法[6]等。
KK算法在弹簧模型的基础上引入了胡克定律,建立了能量模型,将节点位置的求解转换为系统能量最小值的求解。在胡克定律中,单个弹簧的能量为
E=kx2/2
其中,k为弹簧的弹力系数,x为弹簧的被拉伸量。因此,KK算法的能量公式为
其中,kij节点vi与节点vj之间引力的强度,pi与pj分别表示节点vi与节点vj的位置, |pi-pj| 则表示两个节点之间的笛卡尔距离,lij表示两个节点之间的理想距离。KK算法的优点是进一步优化了节点布局,并且加快了算法的收敛。
DH算法受到其它优化方法的启发而采用了模拟退火思想,即将网络布局的优化过程模拟为某些物质系统的冷却过程,当系统温度衰减至阈值时,系统总能量达到最小值,所有节点不再移动。DH算法的能量模型公式为
f(G)=∑λifi(G)
上式包含了5方面要素,分别是点与点的距离、点与边的距离、点与边框的距离、边的长度、边的交叉程度,λi为每部分权重,并可以根据所要遵守的美学标准来设置。DH算法的优点在于布局结果能够达到全局最优值,其缺点是所需时间较长。
FR算法在弹簧模型的基础上引入了粒子物理理论和模拟退火思想,将节点模拟为粒子,将边模拟为粒子间存在的引力,所有粒子间均存在斥力,引力与斥力的相互作用使粒子获得速度与加速度,从而不停运动,多次迭代之后系统温度不断下降从而达到动态平衡状态。在这种设定之下,两个相互连接的节点会趋于靠近,而所有节点因斥力作用又不会距离过近,节点分布整体上较为均匀。首先对初始化所有节点的位置,之后计算每个节点的受力情况并根据受力情况更新节点位置,根据当前系统温度选择是否迭代或停止布局。与上述力导引算法相比,FR算法的聚类效果更加突出,其布局结果的美观程度也更高,因此本文选择在FR算法的基础上进行改进。
LinLog算法通过引入Barnes-Hut算法[7]来减少节点的位置与受力计算量,提高了算法的效率,并且提出了表示聚类分离效果的函数,能够更好地展示网络内部结构。其能量公式如下所示,等式右边第一部分和第二部分分别表示相互连接的两个节点之间的引力与任意两个节点之间的斥力。采用Barnes-Hut算法对能量最小值得求解进行优化,当ULinLog(p) 达到最小值时,代表布局结果已为最优值
ULinLog(p)=∑(vi,vj)∈E|pi-pj|-∑(vi,vj)∈V2ln|pi-pj|
2 基于力导引算法的复杂网络可视化
2.1 问题分析
随着复杂网络理论研究的不断深入,其越来越多的结构特征也逐渐被人们发现与关注。社会与科技的发展使某些领域的复杂网络规模愈加庞大、结构也更加复杂,例如天地一体化网络[8],其网络结构具有明显的分层特性,若干个一级节点相互连接组成骨干网,每个一级节点连接着若干二级节点,每个二级节点连接着众多三级节点,之后依次向下叠加。除此之外,大部分复杂网络的拓扑结构还兼具社团特性,即父节点与其下众多子节点组成了一个子网络,或部分子节点组成了一个子网络,子网络内部节点联系紧密从而构成了一个社团,社团外的子节点单独与父节点相连。而且,子网络之间还存在联系稀疏的节点,即相互连接的两个节点存在于同一层级中的不同社团中。
目前大多数复杂网络的结构都具有分层特性,其可视化方法一般基于单层网络可视化方法和技术来解决新问题,即将多个不同层级的网络聚合到同一层面,形成一个单层网络,之后通过单层网络布局算法进行网络布局,这种方法虽然易于实现,但忽略了节点的异质性与边的多元性,不能完全展示网络的层次信息[9]。因此大部分学者将其与聚类算法结合,通过将不同层级的节点依次聚类,根据显示层级展示网络多层结构。比如汤颖等[10]结合FR算法与LinLog算法的优点,提出了一种层级视觉抽象方法,基于结合算法的初始布局结果进行多层级视觉抽象,既能清楚地观察网络整体结构,也能有效避免大规模数据带来的视觉杂乱。刘凤剑等[11]针对样本的分集处理问题,提出了一种基于力导引模型的聚类算法,通过控制样本间距与样本局部密度,提高了聚类的准确率。于少波等[12]结合空间信息网络的层次性等特征,总结了多层网络可视化技术的发展现状与特点,并分析了目前遇到的问题与挑战,为多层网络可视化方法的研究提供了参考与技术支持。
但是,多层特征只是复杂网络结构特征之一,其另外一个重要的结构特征是社团特征。而上述可视化方法的研究几乎都仅聚焦于体现复杂网络的层次结构特征,忽略了其社团结构特征的展示。对于兼具多层化特征与社团化特征的复杂网络来说,父节点与父节点、父节点与子节点、子节点与子节点之间的连接关系都需要被呈现出来,只展示网络的层次结构而忽略其社团特征并不能完全展现其结构特性。另外,将力导引算法应用于复杂层次数据的研究目前还较少,因此接下来将基于力导引算法和聚类算法对复杂网络拓扑结构可视化进行研究。
2.2 总体思路
FR算法可以达到一定程度的聚类效果,但由于为不同节点之间定义了一个理想距离k,遵循节点均匀分布和边长统一的原则[13],这使得该算法社团结构的展示不明显,主要表现为边长相对一致、子节点过于分散、不同社团的子节点交叉遮挡现象严重,难以从布局结果发现明显的层次结构或社团结构特征。为此,提出了可变力导引算法(VFDA)以改善布局效果。首先在FR算法的基础上增加同一父节点下子节点之间的引力,使同一子树、同一社团的节点相互聚拢,通过改变同层次节点之间的边长展示社团结构与层次结构。为优化斥力的计算,在实现布局的过程中引入Barnes-Hut算法。为进一步优化布局结果,为所有节点增加了一个中心力,使最终布局结果处于场景中心,不会发生偏离。此时,节点将受到多个力,包括来自其它所有节点的斥力、与自身相连接节点的引力、位于布局中心位置的引力。最后,在VFDA算法的布局结果上,基于层次聚类算法对同一层次的节点进行聚类,建立网络多细节层级模型,根据显示层级展现复杂网络社团结构与层级结构。
2.3 基于多力导引算法的网络拓扑结构布局
2.3.1 算法描述
定义一个无向网络可由二元组G(V,E) 表示,其中V表示节点集,即V={v1,v2,v3,…}, |V|=N1表示节点数量为N1。E表示边集,连接节点vi与节点vj的边可用元素eij∈E来表示, |E|=N2表示边数量为N2。网络G可以被划分为多个社团,所有社团的集合可表示为C={c1,c2,c3,…}。
FR算法布局速度快、易于实现,且布局结果能在一定程度上体现出聚类效果,因此本文选择在FR算法的基础上进行改进,其相关定义如下
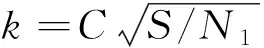
其中,k表示节点之间的理想距离,C为常数,S为网络布局结果所处边框的面积,N1为节点总个数,当系统趋近于稳定状态时,节点之间的距离将趋近于理想距离k。d表示两个不同节点之间的笛卡尔距离,fa与fr分别表示两个相互连接的节点之间的引力与两个节点之间存在的斥力。
由于斥力则存在于所有节点之间,而引力只存在于两个相互连接的节点之间,因此下一步改进措施:一是在计算节点斥力方面引入Barnes-Hut算法,加快算法收敛速度;二是在计算节点引力方面改变相关联节点之间的引力,从而凸显网络的社团结构;三是增加中心力,进一步提高布局美观程度。
Barnes-Hut算法是一种解决N体问题的优化算法,即在经典力学规则下,已知多个物体的质量、位置和速度,在此基础上求解这些物体的后续运动情况。而复杂网络的布局问题即可模拟为一个N体问题,所有节点的初始状态位置随机并保持静止,在布局过程中节点受到其它节点的作用力而不断运动,最终保持静止。引入Barnes-Hut算法的目的是减少节点间斥力的计算量,其基本思想是将相互接近的m个节点模拟为一个节点,这个节点的位置就是这组节点的质心位置,其质量为该m个节点的质量和。这样,这组节点斥力的计算次数就由m次缩减到了1次,大大减少了每次迭代的计算量[14]。
通过Barnes-Hut算法计算节点斥力分为以下3个步骤:
(1)建立节点四叉树
四叉树是一种每一个父节点最多可以有4个子节点的树形结构。在2D平面上,将布局所在的平面不断递归地分为4个同样的子区域,每个子区域就代表父节点下的一个子节点。如果某个子区域内没有节点,该子区域为一个叶子结点,不再对其进行划分。当某个子区域内存在多个节点时,该子区域为一个非叶子节点,之后继续对其进行划分,直至之后的子区域内最多只存在一个节点,完成后的节点四叉树如图1所示。
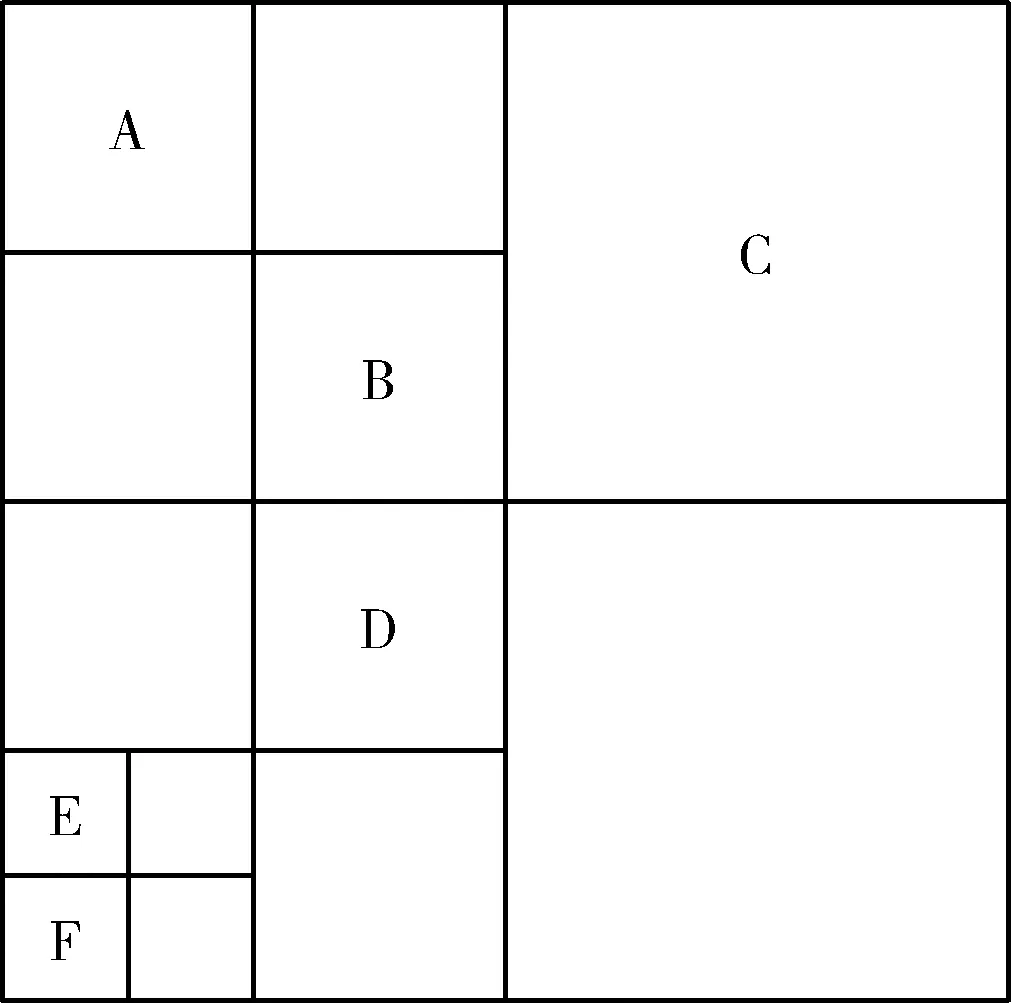
图1 节点四叉树
(2)计算质心
按照面积由小至大(从四叉树底部由下至上)依次计算每个包含节点的子区域的质心位置,只包含一个节点的子区域的质心位置则直接为该节点的坐标。
(3)计算节点斥力
计算节点vi所受斥力时,需要从四叉树的根节点开始由上至下遍历树中所有节点。令w表示非叶子节点所代表的子区域的宽度,dvi表示节点vi到该非叶子节点质心的距离,设定判定距离大小的阈值θ。如果w/dvi<θ, 那么这个非叶子节点距离该节点足够远,则将其内部所有节点模拟为一个节点,其位置就是该非叶子节点的质心;如果w/dvi>θ, 则在其子节点递归地进行上述操作,最终计算出节点vi所受斥力的合力。
由于计算特定节点所受的斥力可能来自单个节点,也可能来自一组节点,因此对斥力计算公式作出改进
frij=-k2MvjA1/d
其中,k与d的定义不变。定义Mvj为该组节点的质量和或单个节点vj的质量,考虑到本文算法的适用对象以及运算量,统一将每个节点的质量设定为一个固定值,因此Mvj的值仅由该组节点的个数决定。定义A1为斥力系数,可通过调整该值控制斥力大小。节点vi所受斥力的合力为
当应用对象与布局范围确定之后,理想距离k即可作为一个固定值。此时,从原始引力公式可看出最终引力值fa将只受关联节点间的笛卡尔距离d影响。而引力值fa与笛卡尔距离d成明显的正比关系,距离的增大会带来引力的增大,增加的引力会拉近两个相互连接的节点,此时距离又将减小,从而使引力减小,其它情况亦是如此,最终在多次迭代后节点间的边长趋近一致,布局结果难以体现明显的社团结构。因此,需要从发现社团结构的角度出发,针对两个相互连接的节点是否处于同一个子树内对原始引力公式进行改进
strength(vi,vj)=1/(min(degree(vi),degree(vj)))faij=(d-k)*strength(vi,vj)+A2*δ(cvi,cvj)
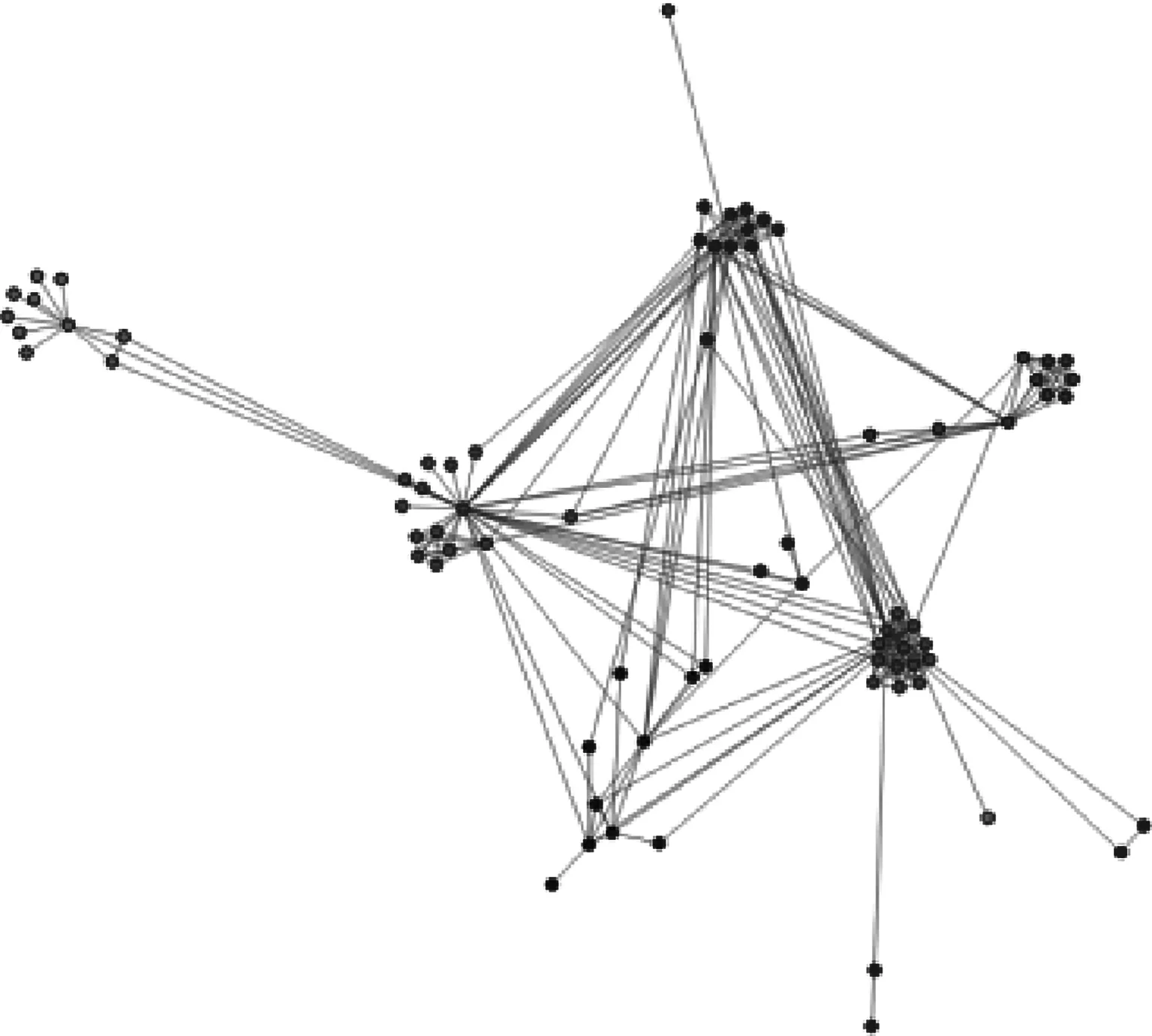
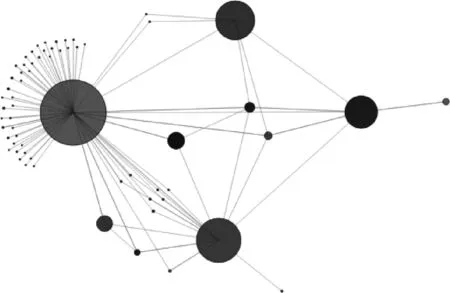
设定节点vi与节点vj相互连接,faij表示二者之间的引力。当d>k时,等式右边第一部分为正数;当d 为进一步对布局结果进行美化,使其符合人们的观察方式,在布局场景中心增加了一个中心力Fc,对所有节点产生引力,其中A3表示引力常数。 最终,节点vi所受到的合力为 F(vi)=Fa(vi)+Fr(vj) 2.3.2 算法步骤 VFDA算法具体步骤如下: (1)读取多层网络结构数据,输入网络G(V,E), 初始化所有节点位置 {Pv1,Pv2,Pv3,…} 和系统温度T。 (2)建立节点四叉树,并计算每个含有节点的子区域的质心位置。 (3)计算所有节点之间的斥力与相互连接的连个节点之间的引力,获得其速度与加速度,更新所有节点的位置 {Pv1,Pv2,Pv3,…}。 (4)根据当前迭代次数计算系统温度T,若温度达到阈值,则执行下一步,若温度高于阈值,则从第二步继续执行。 (5)输出所有节点的位置,完成布局。 根据模拟退火算法可知,系统在初始状态具有较高温度,通过参数T控制迭代过程中节点的运动速度,温度越高,节点运动越剧烈,位置的改变量就越大。随着迭代次数的增加,系统温度逐渐降低,节点位置的改变量逐渐减小。当参数T衰减至阈值时,系统达到稳定状态,所有节点处于静止状态。 当在有限的屏幕范围内对大规模复杂网络进行可视化处理时,大量的节点和边会发生拥挤、交叉或重叠等现象,从而影响人们辨别和理解复杂网络的结构。聚类算法在数据挖掘领域应用广泛,能够按照某些标准对数据进行分组,生成簇结构,同一簇内的个体存在某特性下相似的现象。将适用于数据分析的聚类算法与数据可视化的力导引算法相结合,能够有效帮助人们理解、分析其中的信息[15]。 层次聚类算法通过计算不同个体的相似度来逐步生成簇,相似度可以选择不同的度量标准,最终建立具有嵌套结构的层次树,适用于层次数据的聚类分析。因此,本文基于层次聚类算法,定义了一个显示层级结构的参数L,并将同一根节点下子节点之间的拓扑距离作为相似度的度量标准,采用由下至上的方式逐步建立复杂网络多细节层级模型。参数L决定在相应层级上显示聚类结果,参数L高时显示网络骨干结构,参数L低时则额外显示骨干结构下的低层级网络。 定义一个聚类c可由一个六元组 (sc1,sc2,dc,fc,Vc,Lc) 表示,sc1和sc2分别表示聚类c的两个子聚类,dc表示两个子聚类之间的距离,fc表示其父聚类,Vc表示此聚类中所包含的所有原始节点的集合,Lc则表示此聚类的结构层级。首先从最底层叶子节点开始聚类,设定叶子节点vi和vj可分别由 (null,null,0,null,vi,Lvj) 和 (null,null,0,null,vj,Lvj) 来表示,null表示空值。如果二者之间距离dij最近,则将二者进行合并,产生新聚类ck,此时ck可由 (vi,vj,dij,null,(vi,vj),Lck) 表示,而叶子节点vi和vj则分别更新为 (null,null,0,ck,vi,Lvi) 和 (null,null,0,ck,vj,Lvj)。 令父聚类的位置由其两个子聚类的平均位置确定,父聚类之间的连接关系由其子聚类间的连接关系确定。为突出显示聚类之间规模的差异,对聚类节点的半径进行可视化编码,设置其半径为所包含的原始节点的个数。由下至上递归地寻找距离最近且未被合并过的叶子节点或聚类进行合并,最终生成的网络层级结构可由图2的网络层次结构树状示意图表示。每个单独的叶子节点可看作叶子聚类,中间节点表示叶子节点合并后生成的聚类,根节点cg表示最终生成的聚类。为不同的聚类设置不通的显示层级L,当L为特定值时,截取当前显示层级以上的网络结构进行展示。 图2 网络层次结构树状示意图 为检验上述可视化方法的有效性,基于WebStorm软件和D3可视化工具开发了复杂网络可视化插件,进行基于浏览器的测试。本文选择测试的数据见表1,其中Data-1为某卫星网络结构数据,包含77个节点与254条边,节点主要为卫星节点与地面测控站,边可分为星间链路、星地链路与地地链路。Data-2为某大型网络结构数据,包含1831个节点与3429条边。上述两个数据集都为二层网络结构,为方便观察,已对不同分支下的节点进行了颜色的可视化编码,从表1可看出两个网络的社团内边数远大于社团间边数,尤其是Data-1数据,二者社团特征较为明显,社团内部节点之间联系紧密,各社团之间也存在较为稀疏的联系。通过FR算法与VFDA算法分别对两个数据集进行力导引布局,基于Data-2数据的布局结果构建网络层级结构,观察不同层级的网络结构并进行对比分析,期间设置相同的引力系数与斥力系数。 表1 实验数据集 首先用FR算法对Data-1数据进行布局,布局结果如图3所示。虽然能在边缘处分辨出几个社团结构,但在图的中间区域节点分布较为分散,导致不同子树下的子节点相互混杂,个别社团之间存在交叉现象,造成了视觉干扰。对Data-1数据用VFDA算法进行布局,布局结果如图4所示。Data-1网络可大致分为若干棵节点树,若干父节点组成了一个骨干网,每个父节点下连接着众多子节点,同时二者又与其它父节点或子节点存在着连接关系,大部分父节点与子节点组成了一个社团,也存在部分子节点自行组成一个小社团的情况,符合该卫星网络的真实形态。从图4可看出整个区域几乎不再存在节点混杂的现象,并且边的长度不再趋于平均化,不同子树之间的边长普遍大于某一子树内部的边长,层次结构更加明显。而受社团内外不同引力的作用,同一社团的节点更趋向布局在一起,不同社团在整体上更加分散,每个节点自带的斥力也避免了因节点过度聚拢而产生节点重叠的情况,这使得社团结构更加明显。 图3 Data-1FR算法布局结果 图4 Data-1VFDA算法布局结果 为进一步验证上述可视化方法的适用性,通过FR算法与VFDA算法分别对Data-2数据进行布局,并对布局结果(如图5和图6所示)进行对比分析。从图5可看出,当网络规模过大时,在不进行缩小的情况下,FR算法在有限的屏幕空间无法展示完整的网络拓扑结构,并且不同子树下节点之间存在严重的混乱交叉现象,节点与边的布局也呈现为一种杂乱无章的状态,给用户观察网络整体结构造成极大干扰。而从VFDA算法的布局结果来看,虽然仍有少数节点在屏幕之外,但已不影响用户对网络完整拓扑结构的观察与理解。且VFDA算法对于同一子树内的节点具有明显的聚拢作用,从布局结果可明显看出该网络的层次结构与各子树的布局情况,包括子树的位置分布与子树内的社团结构等,大部分子树都存在分支,父节点下的某一个子节点是另外几条分支子树的父节点。 图5 Data-2FR算法布局结果 图6 Data-2VFDA算法布局结果 对于复杂网络来说,其拓扑结构的展现效果主要取决于布局结果中是否存在大量节点与边的交叉混杂的现象,清晰明了的子树结构则有助于层次结构与社团结构的展示。因此,从比较父节点处的杂乱情况出发,选择Data-2中若干个父节点,将两种算法父节点处单位面积内的节点数目进行对比。如表2所示,同一个数据的不同算法结果表明VFDA能够聚拢同一子树下的节点,减轻子树之间的交叉重叠情况。与FR算法布局结果比较,VFDA算法能够更清晰地展示多层网络的社团结构与层次结构,其可视化结果更符合网络真实形态,也更具观赏性。 表2 FR算法与VFDA算法父节点附近节点数目对比 在VFDA算法布局的基础上,通过层次聚类算法建立网络多细节层级模型,展示网络特定层级结构,Data-2数据聚类后的布局结果如图7所示。从中可以看出,在该显示层级下,同一父节点下的子节点都已与其合并为一个聚类节点,其半径大小即表示所包含子节点的个数,聚类之间的连接关系也代表了所包含的子节点的连接关系。若所选网络具有更多层级,则可以依次由下至上再次进行聚类,并进行不同层级的视觉抽象。综上所述,该可视化方法可以让人们直接从视觉上简洁明了地清楚复杂网络不同层级的拓扑结构与同一层级内的社团结构。 图7 Data-2层次聚类布局结果 考虑到显示屏面积、数据规模等因素的影响,上述可视化方法不能尽善尽美地展现多层网络的拓扑结构,需要通过某些交互手段辅助人们获取、分析感兴趣的信息。基于JavaScript语言的D3相较于其它可视化工具,能够完美结合数据驱动的操作方式与可视化组件,并具有更加灵活的可视化交互方式[16]。 基于D3为上述可视化方法添加了多种交互式操作,如图8所示,常规的放大、缩小、平移、旋转操作能帮助用户从不同角度、不同尺度,观察不同区域的网络拓扑结构,兼顾宏观结构的概览与局部细节的分析。当用户对初始布局结果不满意时,可先用鼠标点击选中某个节点,再通过拖拽操作调整被选中节点的位置,直到布局结果为满意为止。由于在此过程中节点位置不断发生改变,网络布局也会不断进行迭代,最终达到稳定状态。标记操作通过突出显示特定的节点与边,有助于用户获得某个感兴趣的节点或聚类的连接关系。当鼠标悬停于特定节点上时,该节点会被标记并放大,与其相连的边与节点的边缘也会被标记,可清楚看出被选中节点与父节点、其它同一层级子节点的连接关系,也可看出该节点在社团内部的连接关系。 图8 交互操作 本文首先简要介绍了几种经典力导引算法的原理与优劣,针对目前复杂网络可视化研究方面的存在的不足与多层网络的结构特点,提出了一种基于力导引算法的复杂网络多细节层级可视化方法。首先对FR算法进行改进,通过引入Barnes-Hut算法优化斥力的计算,根据两个节点是否处于同一子树内来改变二者之间的引力,并增加了中心力,实现了多力导引布局,然后在多力导引布局结果上运用层次聚类算法进行网络多细节层级模型的构建并展示。从可视化结果的展示与分析来看,该可视化方法具有简便、直观的特点,能够良好地展现复杂网络的不同细节层级拓扑结构与同一细节层级下的社团结构,能允许用户通过多种灵活的交互操作实现高层次宏观结构的概览与低层级局部网络细节的分析。局限之处在于当网络规模变大时,难以在低层级网络结构的布局中分辨关键节点或高一层级的父节点。
2.4 基于层次聚类算法的网络多细节层级模型
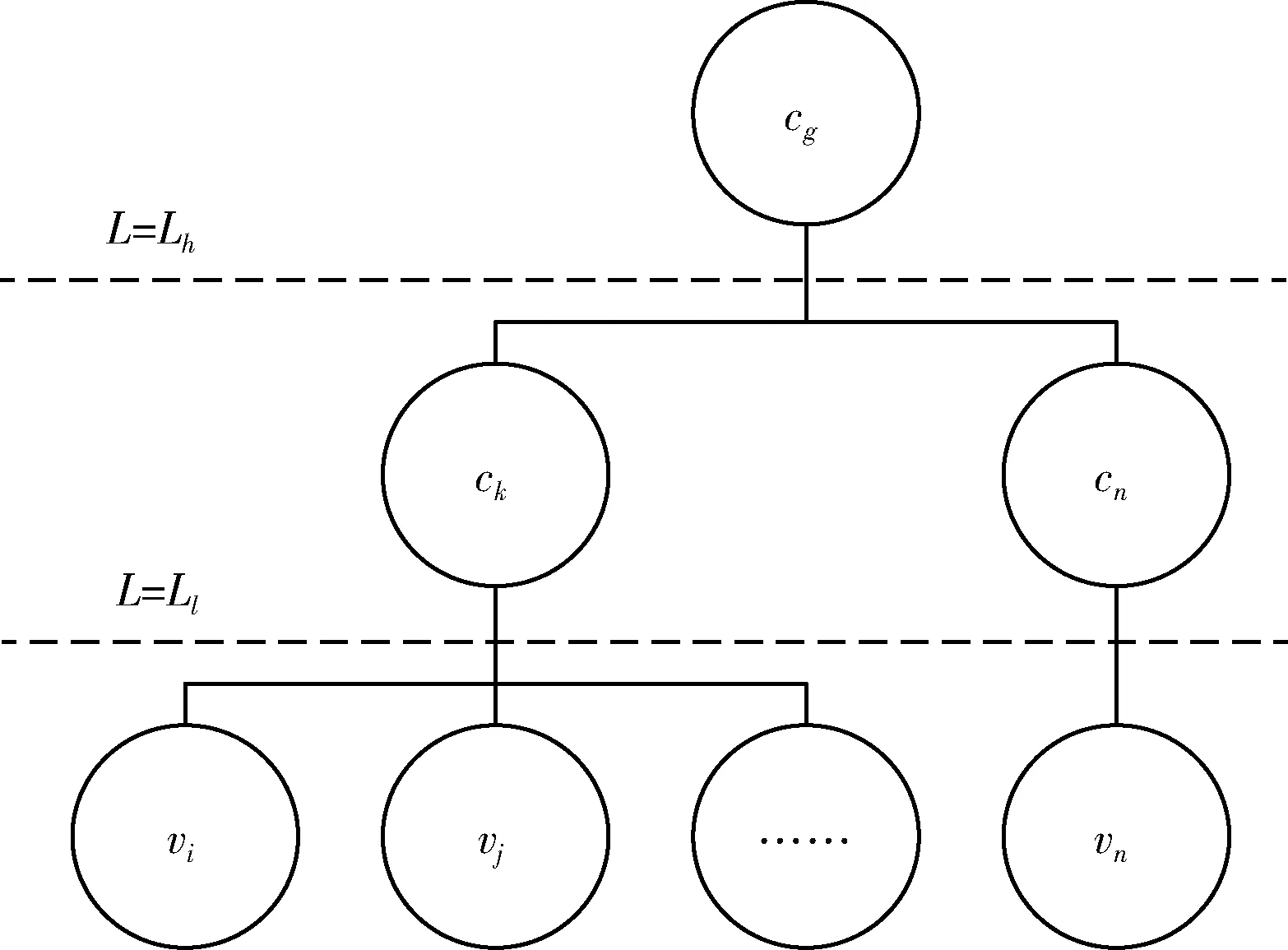
3 实验结果展示与分析
3.1 实验数据

3.2 可视化结果分析




3.3 交互方法

4 结束语
