融合加权代码异味强度因子软件缺陷预测模型
2022-12-30陈镜如黄子杰高建华
陈镜如,黄子杰,高建华
(1.上海师范大学 计算机科学与技术系,上海 200234;2.华东理工大学 计算机科学与工程系,上海 200237)
0 引 言
研究表明[1],分析与源代码质量相关的结构度量来预测缺陷及其发生倾向,但使用单一的结构度量作为特征没有取得良好的预测效果。缺陷预测是一种有监督学习的任务,它将特征因子作为一组独立变量,将类的缺陷倾向性作为因变量,训练机器学习分类器,并给出预测结果。文献[2]指出在添加代码异味强度作为软件缺陷的预测因子时,可以为模型带来信息增益,并提高缺陷模型的预测能力。
代码异味已经成为软件系统在维护软件质量方面造成复杂性的一个标志[3]。代码异味用于识别要重构的代码部分,以提高软件的整体可维护性[4]。代码异味与软件缺陷成正相关,并能对缺陷检测模型的性能产生积极影响[5]。使用文献[6]中提及的方法,将使用改进代码异味强度检测方法作为预测因子添加到预测模型中,分析预测模型性能。
机器学习技术在预测代码异味方面有很大的潜力,有助于检测这些异味并提高软件质量[7]。当进行特征选择和应用分类模型时,具有随机森林分类器的BFS森林分类器给出了最好的性能[8]。
Palomba等[9]认为与复杂/长源代码相关的异味通常被开发者视为重要威胁。代码异味一旦被引入,就难以被移除,因此应尽快将其重构[10],否则将会在代码实现和软件架构的粒度上引发更严重的问题[11],提升系统的易错性,进而导致软件缺陷[12,13]。研究表明,可以通过组合结构度量和阈值来检测代码异味[14],并进一步衡量代码异味强度表示其严重程度。
1 相关术语
1.1 本文涉及的代码异味
本文主要考虑以下6种代码异味:God Class、Data Class、Brain Method、Shotgun Surgery、Dispersed Coupling和Message Chain,因为这6种代码异味不仅是最常见的异味[15],而且与软件缺陷的相关性最强[5]。6种代码异味具体介绍如下。
God Class:类承担太多不同的职责,使得代码耦合性增强,内聚性降低。
Data Class:类的函数没有行为,仅用于存取类的属性。
Brain Method:集中实现多个函数功能的过大方法。
Shotgun Surgery:每一次子方法发生变化,都会触发其它几个类许多的变化的一个类。
Dispersed Coupling:与其它的类发生太多耦合的类。
Message Chains:过度耦合的函数调用链,在执行某个功能时,需要调用连续的多个方法。
上述代码异味的检测策略将在2.1节详述。
1.2 随机森林
随机森林是一种基于Bagging的集成学习方法,其核心思想是将Bootstrap方法应用到Cart算法中。
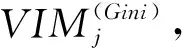
Gini指数的计算如式(1)所示
(1)
式中:K表示K个类别,pmk表示节点m中类别k所占的比例。
特征Xj在节点m的重要性,即节点m分枝前后的Gini指数变化量如式(2)所示
(2)
式中:GIl和GIr分别表示分枝后两个新节点的Gini指数。
特征Xj在决策树i中出现的节点在集合M中,那么Xj在第i棵树的重要性,如式(3)所示
(3)
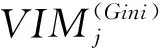
(4)
为了能够更方便的对特征重要性评分作比较,对其进行归一化处理,如式(5)所示
(5)
2 基于随机森林加权的代码异味强度
本文提出了一种基于随机森林的代码异味强度检测方法,对Fontana等[15]提出的代码异味强度计算公式进行了改进,给每个度量赋予相应的权值。本文提出的算法整体框架流程如图1所示:
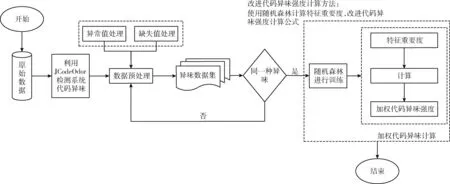
图1 加权强度因子总体流程
(1)获取软件系统源文件。
(2)使用JCodeOdor进行代码异味强度检测,导出数据。
(3)不同的检测策略对度量的选择各有侧重,且度量的区分度不同,依照JCodeOdor中检测策略中的度量整理数据,无需进行特征提取。
(4)将检测策略中的各个度量作为特征,代码异味强度作为标签,使用随机森林评估特征重要度。
(5)将特征重要度作为各个特征的权值,计算加权代码异味强度。本文在计算代码异味强度时使用检测策略中的度量。
本文提出的加权代码异味强度,体现了各个度量对异味强度的不同影响,求得的代码异味强度更为精确。
2.1 验证代码异味检测策略
JCodeOdor是一个代码异味检测器,它依赖于度量和阈值组成的检测策略来检测代码异味强度。其度量详情见文献[15],检测策略见表1。

表1 代码异味检测策略
不同的检测策略对度量的选择各有侧重,且度量的区分度不同,所以不同的检测规则结果存在一定的差异[16]。不仅如此,度量指标之间存在的相关性[17]可能会影响规则的检测效果。
为了验证规则中的度量对本文数据集的适切程度,本文衡量其相关性。若规则中存在高度相关的度量,说明规则可能会部分失效,且这些度量会造成多重共线性问题(multicollinearity)。通过因变量R,即Pearson系数的高低,可以计算自变量x1,x2,……xn,n∈[1,20] 之间的相关性。两个变量之间的Pearson相关系数,用两个变量之间的协方差和标准差的商来定义。
样本Pearson相关系数如式(6)所示
(6)
r的相关程度判断标准如下:[0.00,0.20)极低相关,[0.02,0.40)低相关,[0.40,0.60)中等相关,[0.60,0.80)高度相关,[0.80,1.0)极高相关。
2.2 数据预处理
JCodeOdor在检测代码异味强度时,对检测到的值进行标准化处理,将数值缩放到1到10之间便于比较,如式(7)所示
(7)
式中:min和max是在数据集[18]中包含的指标的统计分布中的最小值和最大值。JCodeOdor利用1到10范围内的数值和提供强度语义描述的标签来呈现代码异味强度,如图2所示。

图2 异味强度标签和范围
本文选用JCodeOdor作为检测工具来衡量代码异味强度因子,该工具基于度量进行检测。6种异味的阈值见表2[15]。
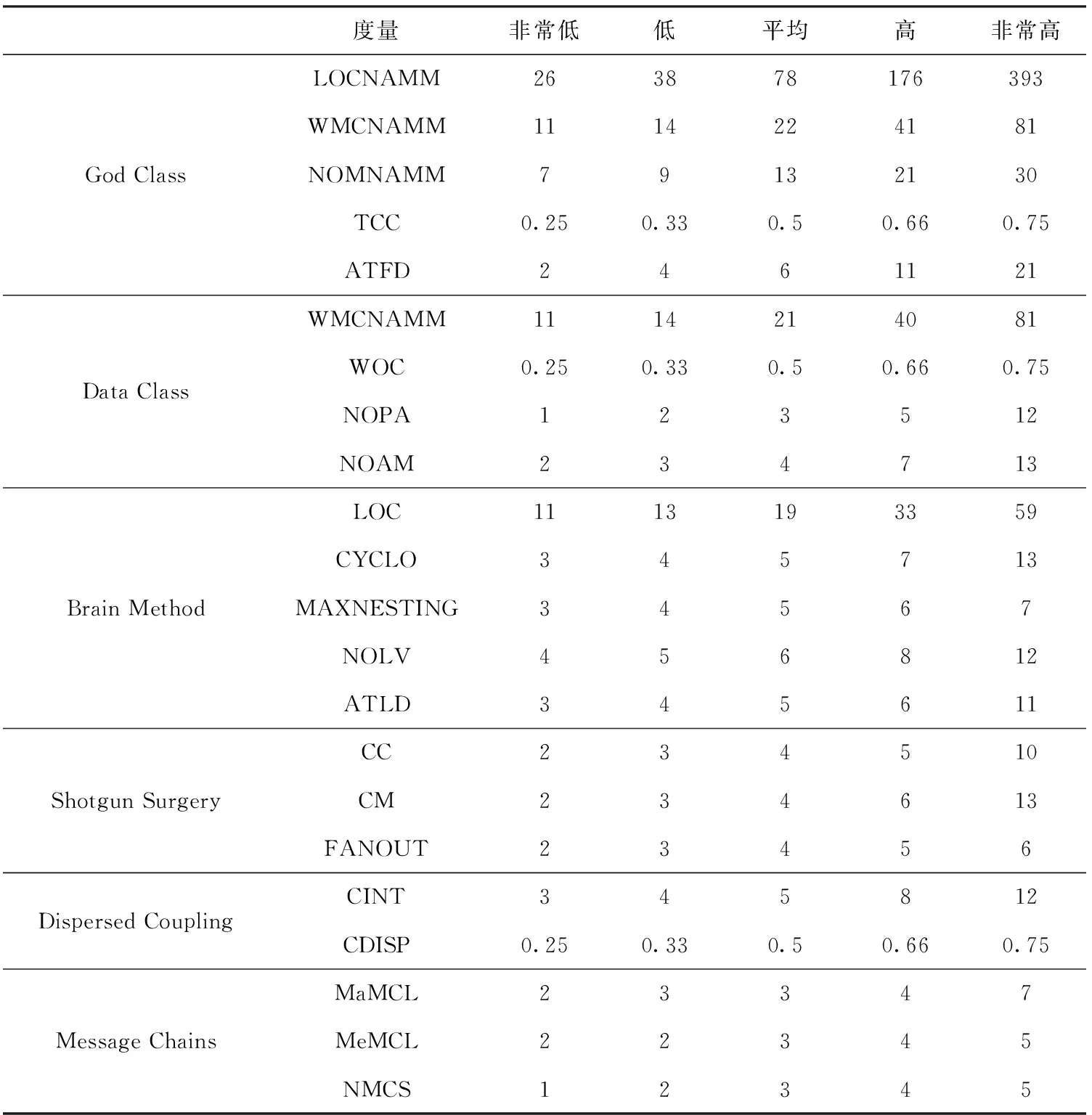
表2 6种异味的度量及其默认阈值
JCodeOdor在检测异味时使用检测策略中所有的度量并且对这些度量赋予相同的权重,如式(8)所示
(8)
式中:Int表示该代码异味的代码异味的强度,Metrici表示应用JCodeOdor测得的第i个度量的值,n为代码异味检测策略中所用到的度量的个数。
经对比各种分析计算方法,发现因子分析和主成分分析利用了数据信息的浓缩原理,利用方差解释率进行权值运算,可能会忽略部分因子,而随机森林计算权值可以解决这一问题。根据随机森林评估特征重要性来改进代码异味强度公式,加权代码异味强度的计算公式,如式(9)所示
(9)
式中:WInt表示该代码异味的加权代码异味的强度,ai为应用随机森林计算得出的特征重要度,Metrici表示应用JCodeOdor测得的第i个度量的值。
以Heritrix1.14.4为例,本文首先利用JCodeOdor对其系统进行检测,测得该系统中只有4种代码异味,即Brain Method、Disperse Coupling、Message Chain、Shotgun Surgery。部分代码异味度量值和代码异味强度的值(Intensity)的结果见表3。
2.3 权值计算
根据上文中检测出的数据,以Heritrix v1.14.4中的setAttribute(CrawlerSettings,Attribute)方法为例,它检测出具有Shotgun Surgery异味,其具有以下度量值:CC:8;CM:10;FANOUT:6。这些度量值满足Shotgun Surgery检测策略中定义的约束条件: CC≥HIGH(5)∧CM≥HIGH(6)∧FANOUT≥LOW(3)。
将得到的实际度量值与表2中这5个点的阈值进行比较,来定义检测规则中每个度量的强度标签,具体规则见式(10)
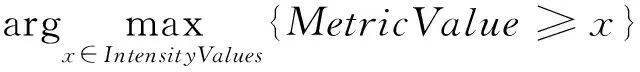
(10)
由上文的强度阈值和划分出的强度标签和范围,如表2和图2所示,可知,在Shotgun Surgery代码异味检测策略中的度量与强度标签相对应如下:CC=高,CM=高,FANOUT=非常高。
原代码异味强度计算公式为代码异味强度为其检测策略中各个度量强度的加和平均值,且每个强度标签与相应值范围的下限相关。
在本例中,CC和CM度量取标签高即7.75,FANOUT度量取标签非常高即10。将上述值带入式(8)求代码异味强度值,即式(11)所示
(11)
根据图2中的强度标签,代码异味强度因子值8.5与“高”强度标签相关,即在范围[7.75,10]内。
根据表3中的数据,应用随机森林评估特征重要度,并将得到的基尼系数作为度量的权值,故加权代码异味强度因子计算带入式(9),如式(12)所示
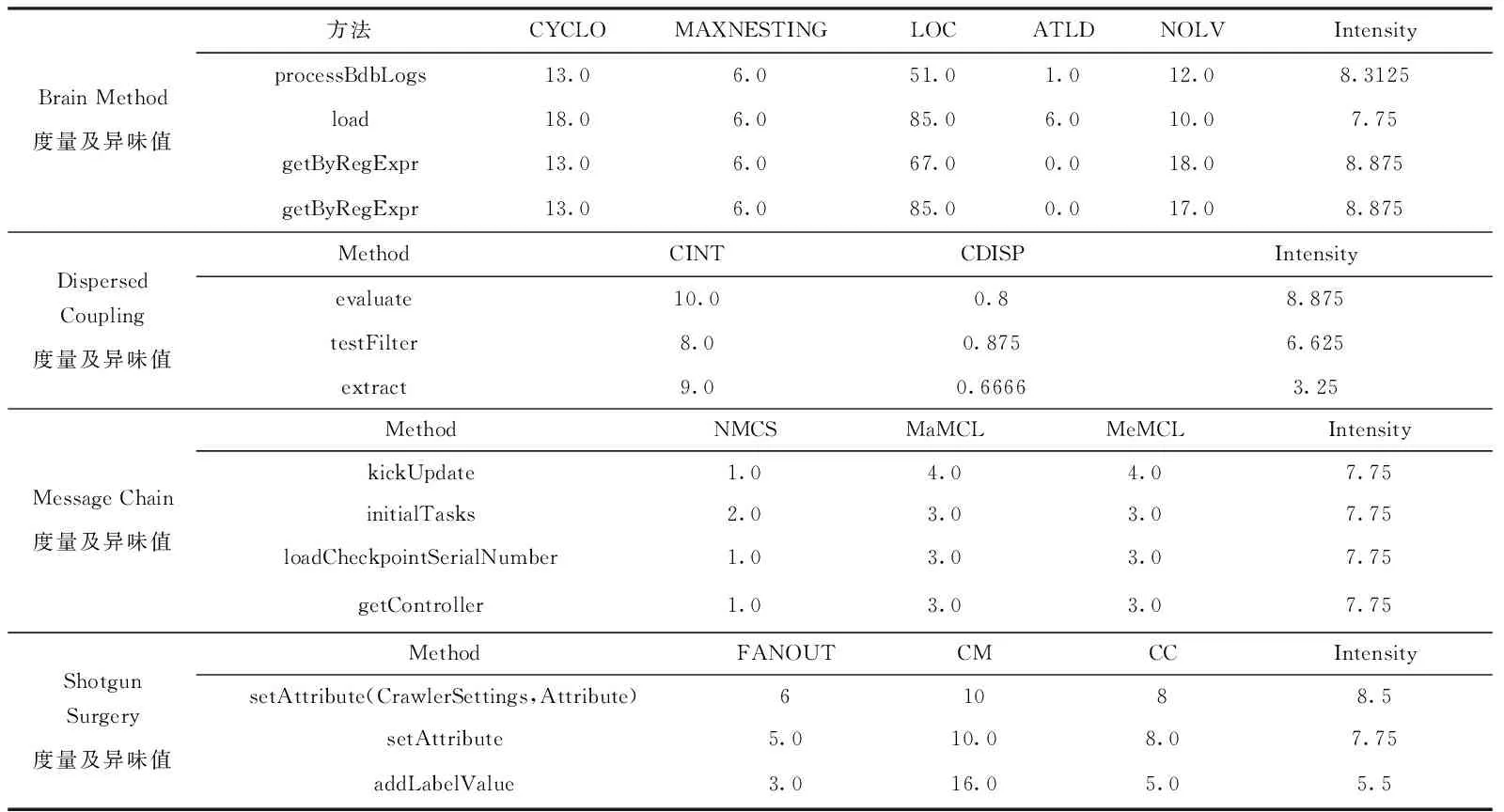
表3 Code Smell度量及其异味值
0.329×7.75+0.321×7.75+0.35×10=8.5
(12)
由图2中的强度标签来看,加权代码异味强度因子值8.5与“高”强度标签相关,即在范围[7.75,10]内。
3 实 验
将加权代码异味强度作为预测因子加入到现有的缺陷预测模型构建新模型,并将新模型与原本模型进行对比,评估代码异味强度的贡献。
本文提出的预测模型框架流程如图3所示:

图3 缺陷预测流程
(1)确定基本预测因子,构建基本软件缺陷预测模型;
(2)确定代码异味检测过程;
1)JCodeOdor检测软件系统源文件;
2)随机森林特征重要度评估;
3)加权代码异味强度计算;
(3)在基本缺陷预测模型的基础上加入加权代码异味强度作为预测因子,构建新模型;
(4)确定用于分类的机器学习技术;
本文在一个由Jureczko等[19]定义的20个软件度量组成的缺陷预测模型中测试代码异味强度作为预测因子的贡献。
3.1 实验环境
本文的实验在Intel(R) Core(TM)i7-5500U、4 GB内存的Windows 10环境下进行,实验的计算和分析使用Python完成。本文选取PROMISE数据集中的缺陷数据作为实验对象,本文用到的数据集见表4。
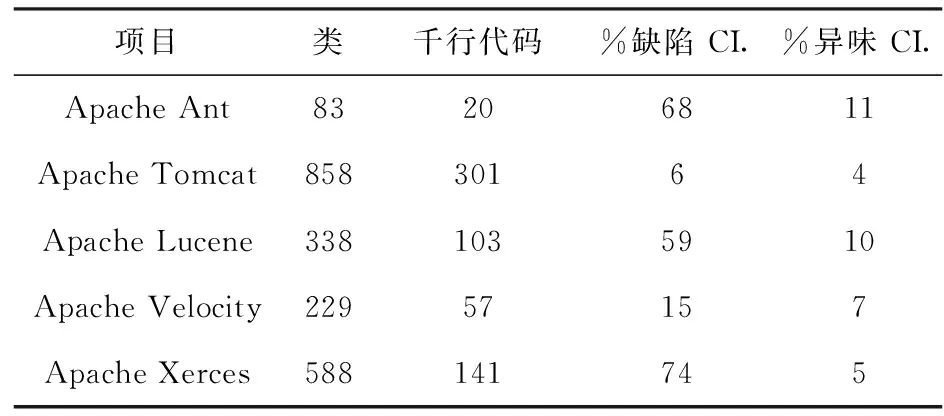
表4 实验项目
本文对这5个软件系统进行实验,并回答以下问题:
Q1:本文使用的检测策略规则是否适用于数据集?
Q2:本文所建构的模型是否能提升缺陷预测的性能?
Q3:与Fontana等提出的代码异味强度因子相比,加权代码异味强度作为预测因子是否能为缺陷预测模型带来增益?可带来多少增益?
3.2 实验过程
本文使用以下3种预测因子组合构建新模型,分析预测因子对模型贡献的模型,以直观地显示预测因子带来的模型性能提升,这些组合包括:
(1)基本模型:
基于Jureczko等[19]定义的20个软件度量的软件缺陷预测模型;
(2)基本模型+代码异味强度因子:
1)将20个软件度量和Fontana等提出的代码异味强度作为预测因子,对于没有异味的类,将其代码异味强度因子设为0,构建软件缺陷预测模型;
2)将20个软件度量和本文提出的加权代码异味强度作为预测因子,对于没有异味的类,将其代码异味强度因子设为0构建软件缺陷预测模型。
本文对比了文献[2]中使用的常见分类器,包括决策树、逻辑回归和简单逻辑回归等,发现简单逻辑回归的效果最好。这一实验结果和文献[2]的结果相吻合。
3.3 实验结果与分析
为了回答Q1,本文验证规则中的度量对数据集的适切程度,包括以下几个方面:①度量间是否存在高相关性;②度量是否包含多种衡量代码异味的角度。如代码异味常表现出的低内聚和高耦合,高复杂性等。因此,应考虑度量中是否包含内聚、耦合、复杂性和数据访问。
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。若存在相关性较过高的度量意味着多重共线性,机器学习模型和信息增益算法可能无法有效区分共线的特征,因此它们需要被移除。本文使用python检测到的度量之间的相关性(Heritrix1.14.4)如图4所示,线条上的数字为它们之间的相关性。本文发现,检测策略中的度量无显著的相关性,不会造成多重共线问题。
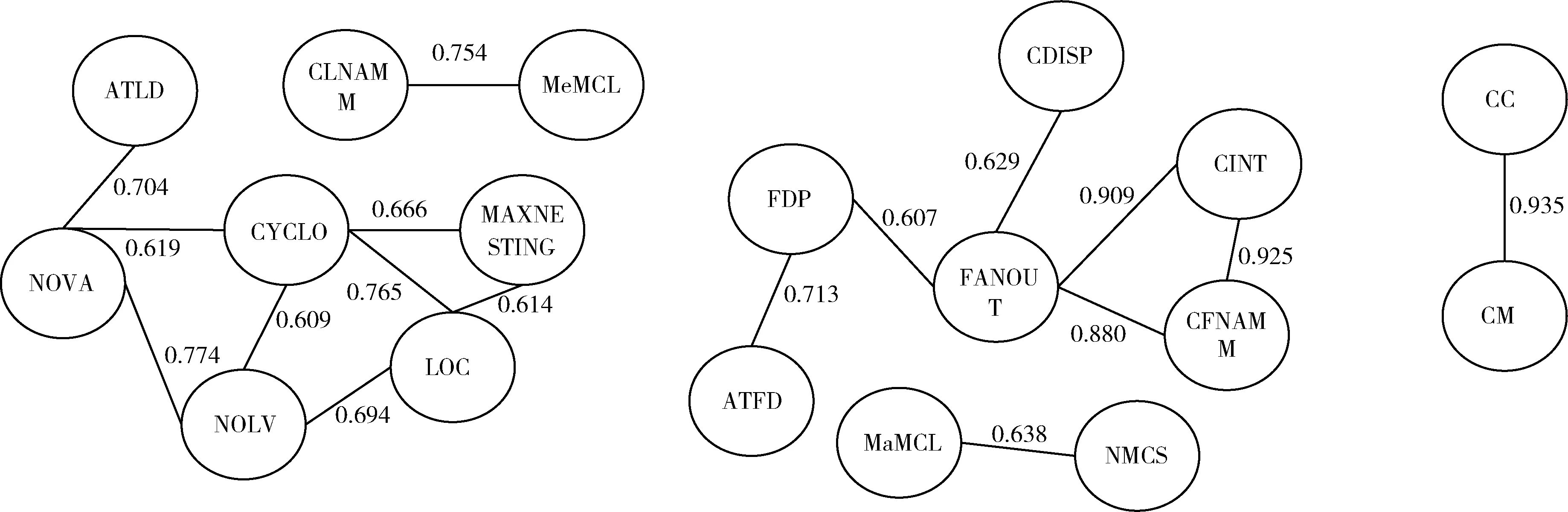
图4 度量相关性网络
由相关性图可知,各个度量之间有着复杂且多元的关系。具有极高相关性的有{FANOUT,CINT},{CINT,CFNAMM},{FANOUT,CFNAMM},{CC,CM};具有高度相关性的有:{ATLD,NOVA},{NOVA,NOLV},{CYCLO,LOC},{FDP,ATFD};具有极低相关性的有:{FANOUT,CM},{FANOUT,CC}。在同一异味下,检测策略之间的相关性多处于高度相关以下。本文发现,检测策略中的度量无显著的相关性,不会造成多重共线问题。
为了回答Q2,需要评估模型的性能。本文采用10次10折交叉验证。实验结果见表5、表6,表5是原始缺陷预测模型测得有关模型各项数据,表6是添加代码异味强度作为预测因子和添加加权代码异味强度作为预测因子时模型的各项数据。
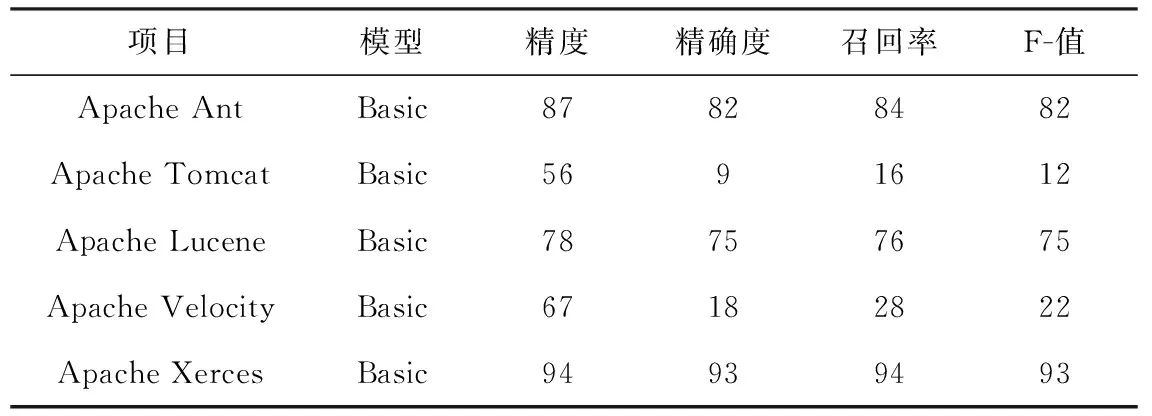
表5 原始模型结果
由表6可知,在基本预测模型中添加代码异味强度和加权代码异味强度作为预测因子后,能够实现高精度预测。对于Apache Velocity,在分别添加代码异味强度和改进计算公式后求得的加权代码异味强度作为模型的预测因子后,其模型精确度较原始模型分别提高25%和28%。这一结果意味着模型仅错误的分类了少部分数据。添加代码异味强度作为预测模型的预测因子时,可提高模型的精确度。图5描述了原软件缺陷预测模型与添加代码异味强度作为预测因子后的模型,模型的各项性能数据。值得注意的是,在基本模型运行良好的情况下,获得性能增量是相当困难的。尽管如此,在这种情况下,使用代码异味强度和加权代码异味强度作为预测因子时,依然能够提升模型的准确性。
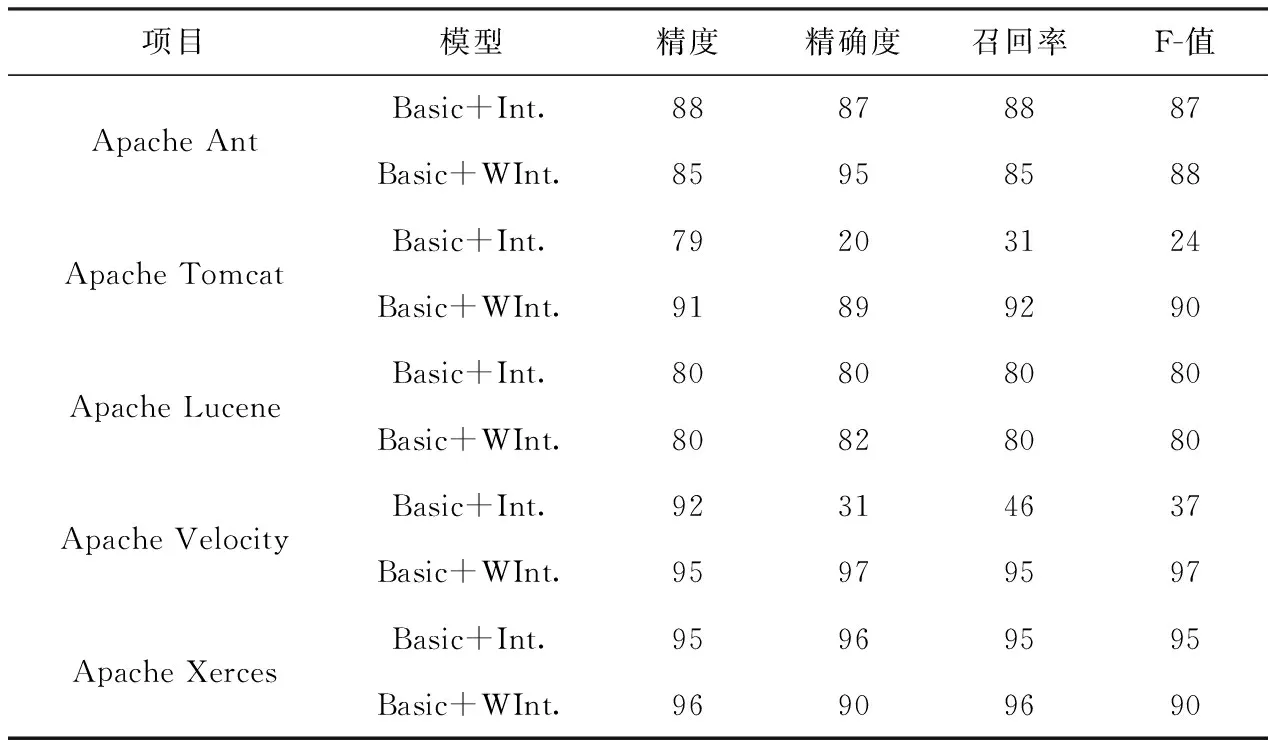
表6 改进模型结果
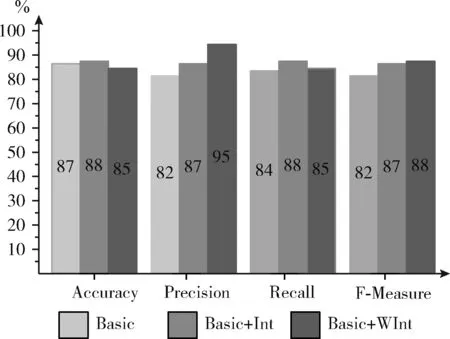
图5 Apache Velocity结果
在所有分析的项目中,增加代码异味强度和加权代码异味强度作为缺陷预测模型的预测因子时通常会提高基础缺陷预测模型的性能。
对于Q2,在基本模型中分别添加代码异味强度作为预测因子和加权代码异味强度作为预测因子后,均能够提高原预测模型的分类精确度。添加代码异味强度作为预测因子模型的分类精确度可提高25%,添加加权代码异味强度作为预测因子时比添加代码异味强度作为预测因子时,缺陷预测模型分类精确度可提升约3%。添加加权代码异味强度作为预测因子的缺陷预测模型的F-Measure比添加代码强度作为预测因子的缺陷预测模型提升约2%。
为了验证代码异味强度在预测模型中所做的贡献Q3,本文采用信息增益算法来量化代码异味强度作为预测因子时为预测模型提供的增益。信息增益见式(13)
InfoGain(M,pi)=H(M)-H(M|pi)
(13)
式中:M为预测模型, P={p1,p2……pn} 为模型的预测因子。函数H(M)表示包含预测因子pi的模型的熵,而函数H(M|pi) 表示不包括预测因子pi的熵,见式(14)
(14)
图6、图7展示了系统Apache Xerces和系统Apache Lucene排名前十的度量的信息增益。
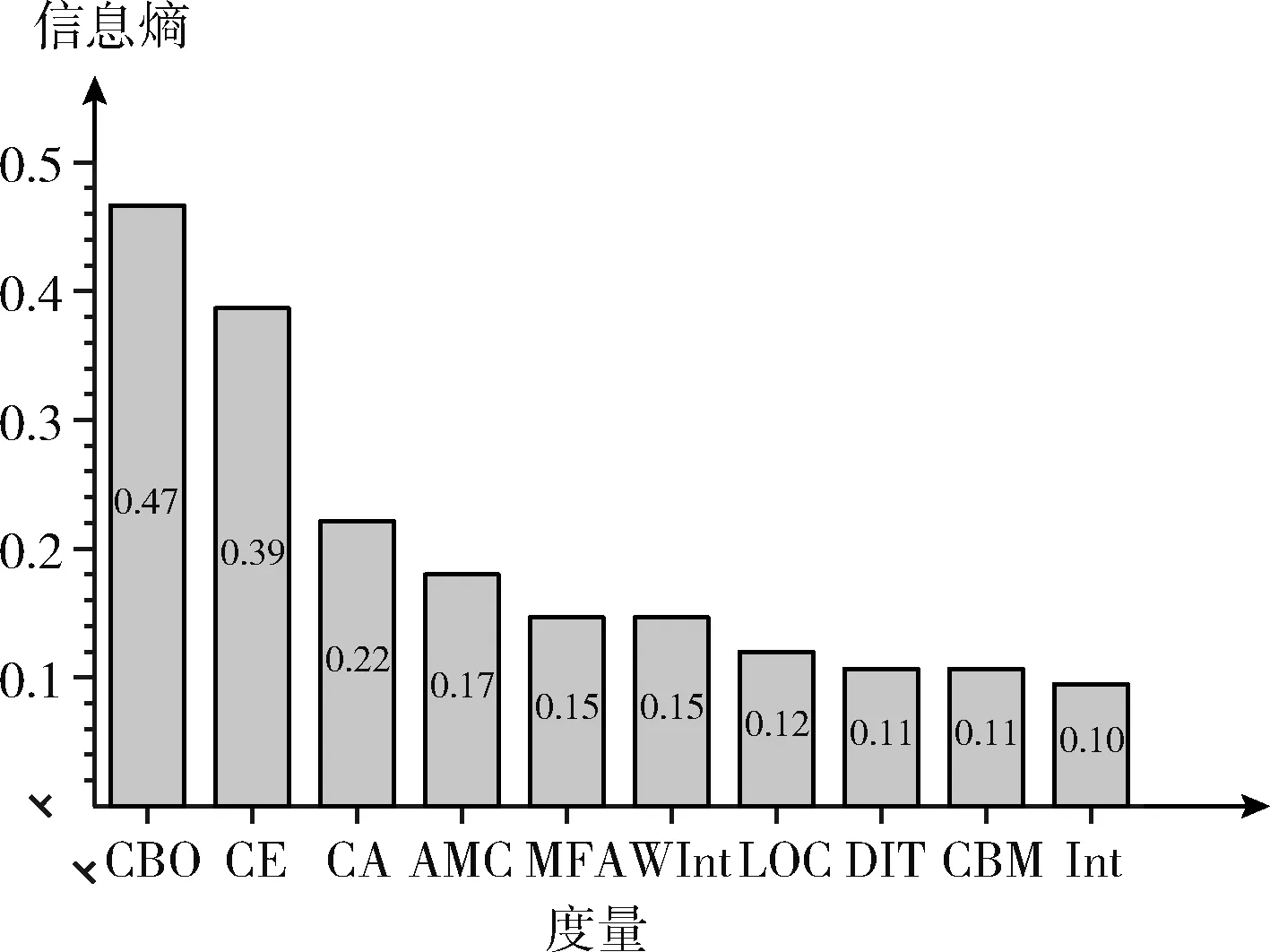
图6 Apache Xerces结果
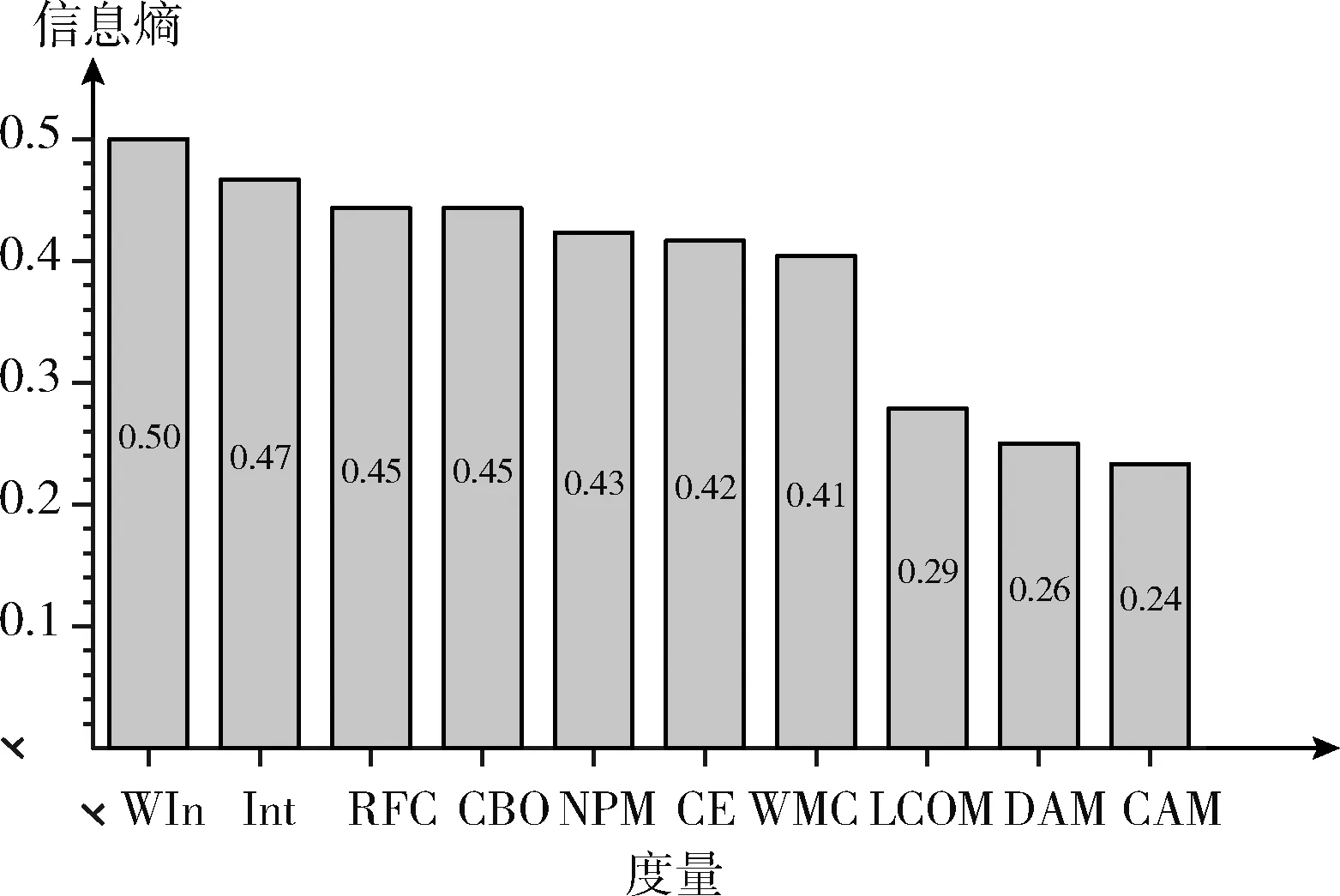
图7 Apache Lucene 结果
代码异味强度和改进公式后得到的加权代码异味强度在Apache Xerces系统中提供的信息增益最少,分别是0.1和0.15。在系统Apache Lucene系统中,与其它度量相比,代码异味强度因子和加权代码异味强度因子带来的信息增益最多,分别是0.50和0.47。在Apache Xerces项目中,基本模型的预测性能很高,获得增益较为困难,但当使用代码异味强度作为预测因子时可带来0.1的性能提升,而使用加权代码异味强度作为预测因子时可带来0.11的性能提升。在Apache Lucene项目中,代码异味强度作为预测因子时可带来0.47的性能提升,但用于计算代码异味强度的单个度量带来的性能提升却比它低。使用代码异味强度和加权代码异味强度作为预测因子相对比其衍生的单个度量具有更高的预测能力。
在所有研究项目中,代码异味强度和加权代码异味强度是模型最重要的预测因子之一。
对于Q3,改进公式得到的加权代码异味强度提供的增益要大于代码异味强度。Fontana等[14]提出的代码异味强度因子将影响代码异味的度量视为同等重要,不能精确地反映各个度量对代码异味强度的影响程度。本文提出的加权代码强度因子能够区分各个度量对代码异味强度的不同影响程度,测得的代码异味强度的值相对更为准确。综上所述,本文提出的加权代码异味强度在模型中作为预测因子时,相较于代码异味强度在模型中作为预测因子时,能够带来更多的增益。
4 结束语
代码异味强度可以评估代码异味的严重程度。Fontana等[14]提出了一种计算代码异味强度的方法,它作为缺陷预测模型的预测因子时可提高模型的性能。然而,这种代码异味强度的计算方法没有区分各个度量对代码异味强度的不同影响,测得的代码异味强度的精确度有待提高。本文通过对各个度量赋予相应的权值来改善这一问题。研究发现,改进公式后测得的加权代码异味强度更为精确。将加权代码异味强度作为预测因子添加到缺陷预测模型中,与原始模型和使用未加权代码异味的强度作为预测因子的模型相比,可提高缺陷预测模型的准确性。加权代码异味强度作为预测因子比代码异味强度作为预测因子时,能够为模型带来更高的信息增益。
本文为验证规则中的度量对本文数据集的适切程度,检验了各个度量之间的相关性,发现了{CC,CM}、{FANOUT,CINT}这两组度量呈高度相关关系,为对原始数据集进行处理时提供了依据。JCodeOdor中所提供的检测策略中各个度量之间并无显著相关性,不会造成多重共线问题,符合从各个角度考虑代码异味的思想。今后的工作包括:进一步研究其它代码异味的强度,提高加权代码异味强度作为预测因子的普适性;选用开源软件以外的软件种类,验证本文模型的普适性;进一步研究其它检测策略中的度量之间的相关性,并将其结合到代码异味强度中;研究代码异味之间的相关性与软件缺陷倾向性之间的关系。
